Intel(R) 64 And IA 32 Architectures Software Developer's Manual, Volume 2A 253666 Intel64 Archtectures Developers Manual Insruction Set Reference, A M
253666-Intel64%20and%20IA-32%20Archtectures%20Software%20Developers%20Manual-Volume%202A-Insruction%20Set%20Reference%2C%20A-M
User Manual: Pdf
Open the PDF directly: View PDF ![]() .
.
Page Count: 848 [warning: Documents this large are best viewed by clicking the View PDF Link!]
- Chapter 1 About This Manual
- Chapter 2 Instruction Format
- 2.1 Instruction Format for Protected Mode, real-address Mode, and virtual-8086 mode
- 2.2 IA-32e Mode
- 2.3 INTEL® ADVANCED VECTOR EXTENSIONS (INTEL® AVX)
- 2.3.1 Instruction Format
- 2.3.2 VEX and the LOCK prefix
- 2.3.3 VEX and the 66H, F2H, and F3H prefixes
- 2.3.4 VEX and the REX prefix
- 2.3.5 The VEX Prefix
- 2.3.6 Instruction Operand Encoding and VEX.vvvv, ModR/M
- 2.3.7 The Opcode Byte
- 2.3.8 The MODRM, SIB, and Displacement Bytes
- 2.3.9 The Third Source Operand (Immediate Byte)
- 2.3.10 AVX Instructions and the Upper 128-bits of YMM registers
- 2.3.11 AVX Instruction Length
- 2.4 Instruction Exception Specification
- 2.4.1 Exceptions Type 1 (Aligned memory reference)
- 2.4.2 Exceptions Type 2 (>=16 Byte Memory Reference, Unaligned)
- 2.4.3 Exceptions Type 3 (<16 Byte memory argument)
- 2.4.4 Exceptions Type 4 (>=16 Byte mem arg no alignment, no floating-point exceptions)
- 2.4.5 Exceptions Type 5 (<16 Byte mem arg and no FP exceptions)
- 2.4.6 Exceptions Type 6 (VEX-Encoded Instructions Without Legacy SSE Analogues)
- 2.4.7 Exceptions Type 7 (No FP exceptions, no memory arg)
- 2.4.8 Exceptions Type 8 (AVX and no memory argument)
- 2.4.9 Exception Type 9 (Intel AVX)
- Chapter 3 Instruction Set Reference, A-M
- 3.1 Interpreting the Instruction Reference Pages
- 3.1.1 Instruction Format
- 3.1.1.1 Opcode Column in the Instruction Summary Table (Instructions without VEX prefix)
- 3.1.1.2 Opcode Column in the Instruction Summary Table (Instructions with VEX prefix)
- 3.1.1.3 Instruction Column in the Opcode Summary Table
- 3.1.1.4 Operand Encoding Column in the Instruction Summary Table
- 3.1.1.5 64/32-bit Mode Column in the Instruction Summary Table
- 3.1.1.6 CPUID Support Column in the Instruction Summary Table
- 3.1.1.7 Description Column in the Instruction Summary Table
- 3.1.1.8 Description Section
- 3.1.1.9 Operation Section
- 3.1.1.10 Intel® C/C++ Compiler Intrinsics Equivalents Section
- 3.1.1.11 Flags Affected Section
- 3.1.1.12 FPU Flags Affected Section
- 3.1.1.13 Protected Mode Exceptions Section
- 3.1.1.14 Real-Address Mode Exceptions Section
- 3.1.1.15 Virtual-8086 Mode Exceptions Section
- 3.1.1.16 Floating-Point Exceptions Section
- 3.1.1.17 SIMD Floating-Point Exceptions Section
- 3.1.1.18 Compatibility Mode Exceptions Section
- 3.1.1.19 64-Bit Mode Exceptions Section
- 3.1.1 Instruction Format
- 3.2 Instructions (A-M)
- AAA-ASCII Adjust After Addition
- AAD-ASCII Adjust AX Before Division
- AAM-ASCII Adjust AX After Multiply
- AAS-ASCII Adjust AL After Subtraction
- ADC-Add with Carry
- ADD-Add
- ADDPD-Add Packed Double-Precision Floating-Point Values
- ADDPS-Add Packed Single-Precision Floating-Point Values
- ADDSD-Add Scalar Double-Precision Floating-Point Values
- ADDSS-Add Scalar Single-Precision Floating-Point Values
- ADDSUBPD-Packed Double-FP Add/Subtract
- ADDSUBPS-Packed Single-FP Add/Subtract
- AESDEC-Perform One Round of an AES Decryption Flow
- AESDECLAST-Perform Last Round of an AES Decryption Flow
- AESENC-Perform One Round of an AES Encryption Flow
- AESENCLAST-Perform Last Round of an AES Encryption Flow
- AESIMC-Perform the AES InvMixColumn Transformation
- AESKEYGENASSIST-AES Round Key Generation Assist
- AND-Logical AND
- ANDPD-Bitwise Logical AND of Packed Double-Precision Floating- Point Values
- ANDPS-Bitwise Logical AND of Packed Single-Precision Floating-Point Values
- ANDNPD-Bitwise Logical AND NOT of Packed Double-Precision Floating-Point Values
- ANDNPS-Bitwise Logical AND NOT of Packed Single-Precision Floating-Point Values
- ARPL-Adjust RPL Field of Segment Selector
- BLENDPD - Blend Packed Double Precision Floating-Point Values
- BLENDPS - Blend Packed Single Precision Floating-Point Values
- BLENDVPD - Variable Blend Packed Double Precision Floating-Point Values
- BLENDVPS - Variable Blend Packed Single Precision Floating-Point Values
- BOUND-Check Array Index Against Bounds
- VBROADCAST-Load with Broadcast
- BSF-Bit Scan Forward
- BSR-Bit Scan Reverse
- BSWAP-Byte Swap
- BT-Bit Test
- BTC-Bit Test and Complement
- BTR-Bit Test and Reset
- BTS-Bit Test and Set
- CALL-Call Procedure
- CBW/CWDE/CDQE-Convert Byte to Word/Convert Word to Doubleword/Convert Doubleword to Quadword
- CLC-Clear Carry Flag
- CLD-Clear Direction Flag
- CLFLUSH-Flush Cache Line
- CLI - Clear Interrupt Flag
- CLTS-Clear Task-Switched Flag in CR0
- CMC-Complement Carry Flag
- CMOVcc-Conditional Move
- CMP-Compare Two Operands
- CMPPD-Compare Packed Double-Precision Floating-Point Values
- CMPPS-Compare Packed Single-Precision Floating-Point Values
- CMPS/CMPSB/CMPSW/CMPSD/CMPSQ-Compare String Operands
- CMPSD-Compare Scalar Double-Precision Floating-Point Values
- CMPSS-Compare Scalar Single-Precision Floating-Point Values
- CMPXCHG-Compare and Exchange
- CMPXCHG8B/CMPXCHG16B-Compare and Exchange Bytes
- COMISD-Compare Scalar Ordered Double-Precision Floating-Point Values and Set EFLAGS
- COMISS-Compare Scalar Ordered Single-Precision Floating-Point Values and Set EFLAGS
- CPUID-CPU Identification
- CRC32 - Accumulate CRC32 Value
- CVTDQ2PD-Convert Packed Dword Integers to Packed Double- Precision FP Values
- CVTDQ2PS-Convert Packed Dword Integers to Packed Single- Precision FP Values
- CVTPD2DQ-Convert Packed Double-Precision FP Values to Packed Dword Integers
- CVTPD2PI-Convert Packed Double-Precision FP Values to Packed Dword Integers
- CVTPD2PS-Convert Packed Double-Precision FP Values to Packed Single-Precision FP Values
- CVTPI2PD-Convert Packed Dword Integers to Packed Double- Precision FP Values
- CVTPI2PS-Convert Packed Dword Integers to Packed Single-Precision FP Values
- CVTPS2DQ-Convert Packed Single-Precision FP Values to Packed Dword Integers
- CVTPS2PD-Convert Packed Single-Precision FP Values to Packed Double-Precision FP Values
- CVTPS2PI-Convert Packed Single-Precision FP Values to Packed Dword Integers
- CVTSD2SI-Convert Scalar Double-Precision FP Value to Integer
- CVTSD2SS-Convert Scalar Double-Precision FP Value to Scalar Single- Precision FP Value
- CVTSI2SD-Convert Dword Integer to Scalar Double-Precision FP Value
- CVTSI2SS-Convert Dword Integer to Scalar Single-Precision FP Value
- CVTSS2SD-Convert Scalar Single-Precision FP Value to Scalar Double- Precision FP Value
- CVTSS2SI-Convert Scalar Single-Precision FP Value to Dword Integer
- CVTTPD2DQ-Convert with Truncation Packed Double-Precision FP Values to Packed Dword Integers
- CVTTPD2PI-Convert with Truncation Packed Double-Precision FP Values to Packed Dword Integers
- CVTTPS2DQ-Convert with Truncation Packed Single-Precision FP Values to Packed Dword Integers
- CVTTPS2PI-Convert with Truncation Packed Single-Precision FP Values to Packed Dword Integers
- CVTTSD2SI-Convert with Truncation Scalar Double-Precision FP Value to Signed Integer
- CVTTSS2SI-Convert with Truncation Scalar Single-Precision FP Value to Dword Integer
- CWD/CDQ/CQO-Convert Word to Doubleword/Convert Doubleword to Quadword
- DAA-Decimal Adjust AL after Addition
- DAS-Decimal Adjust AL after Subtraction
- DEC-Decrement by 1
- DIV-Unsigned Divide
- DIVPD-Divide Packed Double-Precision Floating-Point Values
- DIVPS-Divide Packed Single-Precision Floating-Point Values
- DIVSD-Divide Scalar Double-Precision Floating-Point Values
- DIVSS-Divide Scalar Single-Precision Floating-Point Values
- DPPD - Dot Product of Packed Double Precision Floating-Point Values
- DPPS - Dot Product of Packed Single Precision Floating-Point Values
- EMMS-Empty MMX Technology State
- ENTER-Make Stack Frame for Procedure Parameters
- VEXTRACTF128 - Extract Packed Floating-Point Values
- EXTRACTPS - Extract Packed Single Precision Floating-Point Value
- F2XM1-Compute 2x-1
- FABS-Absolute Value
- FADD/FADDP/FIADD-Add
- FBLD-Load Binary Coded Decimal
- FBSTP-Store BCD Integer and Pop
- FCHS-Change Sign
- FCLEX/FNCLEX-Clear Exceptions
- FCMOVcc-Floating-Point Conditional Move
- FCOMI/FCOMIP/ FUCOMI/FUCOMIP-Compare Floating Point Values and Set EFLAGS
- FCOS-Cosine
- FDECSTP-Decrement Stack-Top Pointer
- FDIV/FDIVP/FIDIV-Divide
- FDIVR/FDIVRP/FIDIVR-Reverse Divide
- FFREE-Free Floating-Point Register
- FICOM/FICOMP-Compare Integer
- FILD-Load Integer
- FINCSTP-Increment Stack-Top Pointer
- FINIT/FNINIT-Initialize Floating-Point Unit
- FIST/FISTP-Store Integer
- FISTTP-Store Integer with Truncation
- FLD-Load Floating Point Value
- FLD1/FLDL2T/FLDL2E/FLDPI/FLDLG2/FLDLN2/FLDZ-Load Constant
- FLDCW-Load x87 FPU Control Word
- FLDENV-Load x87 FPU Environment
- FMUL/FMULP/FIMUL-Multiply
- FNOP-No Operation
- FPATAN-Partial Arctangent
- FPREM-Partial Remainder
- FPREM1-Partial Remainder
- FPTAN-Partial Tangent
- FRNDINT-Round to Integer
- FRSTOR-Restore x87 FPU State
- FSAVE/FNSAVE-Store x87 FPU State
- FSCALE-Scale
- FSIN-Sine
- FSINCOS-Sine and Cosine
- FSQRT-Square Root
- FST/FSTP-Store Floating Point Value
- FSTCW/FNSTCW-Store x87 FPU Control Word
- FSTENV/FNSTENV-Store x87 FPU Environment
- FSTSW/FNSTSW-Store x87 FPU Status Word
- FSUB/FSUBP/FISUB-Subtract
- FSUBR/FSUBRP/FISUBR-Reverse Subtract
- FTST-TEST
- FUCOM/FUCOMP/FUCOMPP-Unordered Compare Floating Point Values
- FXAM-Examine ModR/M
- FXCH-Exchange Register Contents
- FXRSTOR-Restore x87 FPU, MMX , XMM, and MXCSR State
- FXSAVE-Save x87 FPU, MMX Technology, and SSE State
- FXTRACT-Extract Exponent and Significand
- FYL2X-Compute y * log2x
- FYL2XP1-Compute y * log2(x +1)
- HADDPD-Packed Double-FP Horizontal Add
- HADDPS-Packed Single-FP Horizontal Add
- HLT-Halt
- HSUBPD-Packed Double-FP Horizontal Subtract
- HSUBPS-Packed Single-FP Horizontal Subtract
- IDIV-Signed Divide
- IMUL-Signed Multiply
- IN-Input from Port
- INC-Increment by 1
- INS/INSB/INSW/INSD-Input from Port to String
- VINSERTF128 - Insert Packed Floating-Point Values
- INSERTPS - Insert Packed Single Precision Floating-Point Value
- INT n/INTO/INT 3-Call to Interrupt Procedure
- INVD-Invalidate Internal Caches
- INVLPG-Invalidate TLB Entry
- IRET/IRETD-Interrupt Return
- Jcc-Jump if Condition Is Met
- JMP-Jump
- LAHF-Load Status Flags into AH Register
- LAR-Load Access Rights Byte
- LDDQU-Load Unaligned Integer 128 Bits
- LDMXCSR-Load MXCSR Register
- LDS/LES/LFS/LGS/LSS-Load Far Pointer
- LEA-Load Effective Address
- LEAVE-High Level Procedure Exit
- LFENCE-Load Fence
- LGDT/LIDT-Load Global/Interrupt Descriptor Table Register
- LLDT-Load Local Descriptor Table Register
- LMSW-Load Machine Status Word
- LOCK-Assert LOCK# Signal Prefix
- LODS/LODSB/LODSW/LODSD/LODSQ-Load String
- LOOP/LOOPcc-Loop According to ECX Counter
- LSL-Load Segment Limit
- LTR-Load Task Register
- MASKMOVDQU-Store Selected Bytes of Double Quadword
- VMASKMOV-Conditional SIMD Packed Loads and Stores
- MASKMOVQ-Store Selected Bytes of Quadword
- MAXPD-Return Maximum Packed Double-Precision Floating-Point Values
- MAXPS-Return Maximum Packed Single-Precision Floating-Point Values
- MAXSD-Return Maximum Scalar Double-Precision Floating-Point Value
- MAXSS-Return Maximum Scalar Single-Precision Floating-Point Value
- MFENCE-Memory Fence
- MINPD-Return Minimum Packed Double-Precision Floating-Point Values
- MINPS-Return Minimum Packed Single-Precision Floating-Point Values
- MINSD-Return Minimum Scalar Double-Precision Floating-Point Value
- MINSS-Return Minimum Scalar Single-Precision Floating-Point Value
- MONITOR-Set Up Monitor Address
- MOV-Move
- MOV-Move to/from Control Registers
- MOV-Move to/from Debug Registers
- MOVAPD-Move Aligned Packed Double-Precision Floating-Point Values
- MOVAPS-Move Aligned Packed Single-Precision Floating-Point Values
- MOVBE-Move Data After Swapping Bytes
- MOVD/MOVQ-Move Doubleword/Move Quadword
- MOVDDUP-Move One Double-FP and Duplicate
- MOVDQA-Move Aligned Double Quadword
- MOVDQU-Move Unaligned Double Quadword
- MOVDQ2Q-Move Quadword from XMM to MMX Technology Register
- MOVHLPS- Move Packed Single-Precision Floating-Point Values High to Low
- MOVHPD-Move High Packed Double-Precision Floating-Point Value
- MOVHPS-Move High Packed Single-Precision Floating-Point Values
- MOVLHPS-Move Packed Single-Precision Floating-Point Values Low to High
- MOVLPD-Move Low Packed Double-Precision Floating-Point Value
- MOVLPS-Move Low Packed Single-Precision Floating-Point Values
- MOVMSKPD-Extract Packed Double-Precision Floating-Point Sign Mask
- MOVMSKPS-Extract Packed Single-Precision Floating-Point Sign Mask
- MOVNTDQA - Load Double Quadword Non-Temporal Aligned Hint
- MOVNTDQ-Store Double Quadword Using Non-Temporal Hint
- MOVNTI-Store Doubleword Using Non-Temporal Hint
- MOVNTPD-Store Packed Double-Precision Floating-Point Values Using Non-Temporal Hint
- MOVNTPS-Store Packed Single-Precision Floating-Point Values Using Non-Temporal Hint
- MOVNTQ-Store of Quadword Using Non-Temporal Hint
- MOVQ-Move Quadword
- MOVQ2DQ-Move Quadword from MMX Technology to XMM Register
- MOVS/MOVSB/MOVSW/MOVSD/MOVSQ-Move Data from String to String
- MOVSD-Move Scalar Double-Precision Floating-Point Value
- MOVSHDUP-Move Packed Single-FP High and Duplicate
- MOVSLDUP-Move Packed Single-FP Low and Duplicate
- MOVSS-Move Scalar Single-Precision Floating-Point Values
- MOVSX/MOVSXD-Move with Sign-Extension
- MOVUPD-Move Unaligned Packed Double-Precision Floating-Point Values
- MOVUPS-Move Unaligned Packed Single-Precision Floating-Point Values
- MOVZX-Move with Zero-Extend
- MPSADBW - Compute Multiple Packed Sums of Absolute Difference
- MUL-Unsigned Multiply
- MULPD-Multiply Packed Double-Precision Floating-Point Values
- MULPS-Multiply Packed Single-Precision Floating-Point Values
- MULSD-Multiply Scalar Double-Precision Floating-Point Values
- MULSS-Multiply Scalar Single-Precision Floating-Point Values
- MWAIT-Monitor Wait
- 3.1 Interpreting the Instruction Reference Pages

Intel® 64 and IA-32 Architectures
Software Developer’s Manual
Volume 2A:
Instruction Set Reference, A-M
NOTE: The Intel 64 and IA-32 Architectures Software Developer's Manual
consists of five volumes: Basic Architecture, Order Number 253665;
Instruction Set Reference A-M, Order Number 253666; Instruction Set
Reference N-Z, Order Number 253667; System Programming Guide,
Part 1, Order Number 253668; System Programming Guide, Part 2,
Order Number 253669. Refer to all five volumes when evaluating your
design needs.
Order Number: 253666-037US
January 2011

ii Vol. 2A
INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE,
EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANT-
ED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH
PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED
WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES
RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY
PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT.
UNLESS OTHERWISE AGREED IN WRITING BY INTEL, THE INTEL PRODUCTS ARE NOT DESIGNED NOR IN-
TENDED FOR ANY APPLICATION IN WHICH THE FAILURE OF THE INTEL PRODUCT COULD CREATE A SITUA-
TION WHERE PERSONAL INJURY OR DEATH MAY OCCUR.
Intel may make changes to specifications and product descriptions at any time, without notice. Designers
must not rely on the absence or characteristics of any features or instructions marked "reserved" or "unde-
fined." Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or
incompatibilities arising from future changes to them. The information here is subject to change without no-
tice. Do not finalize a design with this information.
The Intel® 64 architecture processors may contain design defects or errors known as errata. Current char-
acterized errata are available on request.
Intel® Hyper-Threading Technology requires a computer system with an Intel® processor supporting Hyper-
Threading Technology and an Intel® HT Technology enabled chipset, BIOS and operating system.
Performance will vary depending on the specific hardware and software you use. For more information, see
http://www.intel.com/technology/hyperthread/index.htm; including details on which processors support Intel HT
Technology.
Intel® Virtualization Technology requires a computer system with an enabled Intel® processor, BIOS, virtual
machine monitor (VMM) and for some uses, certain platform software enabled for it. Functionality, perfor-
mance or other benefits will vary depending on hardware and software configurations. Intel® Virtualization
Technology-enabled BIOS and VMM applications are currently in development.
64-bit computing on Intel architecture requires a computer system with a processor, chipset, BIOS, oper-
ating system, device drivers and applications enabled for Intel® 64 architecture. Processors will not operate
(including 32-bit operation) without an Intel® 64 architecture-enabled BIOS. Performance will vary de-
pending on your hardware and software configurations. Consult with your system vendor for more infor-
mation.
Enabling Execute Disable Bit functionality requires a PC with a processor with Execute Disable Bit capability
and a supporting operating system. Check with your PC manufacturer on whether your system delivers Ex-
ecute Disable Bit functionality.
Intel, Pentium, Intel Xeon, Intel NetBurst, Intel Core, Intel Core Solo, Intel Core Duo, Intel Core 2 Duo,
Intel Core 2 Extreme, Intel Pentium D, Itanium, Intel SpeedStep, MMX, Intel Atom, and VTune are trade-
marks or registered trademarks of Intel Corporation or its subsidiaries in the United States and other coun-
tries.
*Other names and brands may be claimed as the property of others.
Contact your local Intel sales office or your distributor to obtain the latest specifications and before placing
your product order.
Copies of documents which have an ordering number and are referenced in this document, or other Intel
literature, may be obtained by calling 1-800-548-4725, or by visiting Intel’s website at http://www.intel.com
Copyright © 1997-2011 Intel Corporation

Vol. 2A iii
CONTENTS
PAGE
CHAPTER 1
ABOUT THIS MANUAL
1.1 IA-32 PROCESSORS COVERED IN THIS MANUAL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-1
1.2 OVERVIEW OF VOLUME 2A AND 2B: INSTRUCTION SET REFERENCE . . . . . . . . . . . . . . . . . . 1-3
1.3 NOTATIONAL CONVENTIONS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-4
1.3.1 Bit and Byte Order . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-4
1.3.2 Reserved Bits and Software Compatibility. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-5
1.3.3 Instruction Operands . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-6
1.3.4 Hexadecimal and Binary Numbers. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-6
1.3.5 Segmented Addressing. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-6
1.3.6 Exceptions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-7
1.3.7 A New Syntax for CPUID, CR, and MSR Values . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-7
1.4 RELATED LITERATURE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-8
CHAPTER 2
INSTRUCTION FORMAT
2.1 INSTRUCTION FORMAT FOR PROTECTED MODE, REAL-ADDRESS MODE, AND
VIRTUAL-8086 MODE 2-1
2.1.1 Instruction Prefixes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-1
2.1.2 Opcodes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-3
2.1.3 ModR/M and SIB Bytes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-4
2.1.4 Displacement and Immediate Bytes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-4
2.1.5 Addressing-Mode Encoding of ModR/M and SIB Bytes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-4
2.2 IA-32E MODE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-9
2.2.1 REX Prefixes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-9
2.2.1.1 Encoding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-10
2.2.1.2 More on REX Prefix Fields . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-10
2.2.1.3 Displacement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-13
2.2.1.4 Direct Memory-Offset MOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-13
2.2.1.5 Immediates . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-14
2.2.1.6 RIP-Relative Addressing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-14
2.2.1.7 Default 64-Bit Operand Size . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-15
2.2.2 Additional Encodings for Control and Debug Registers . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-15
2.3 INTEL® ADVANCED VECTOR EXTENSIONS (INTEL® AVX) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-16
2.3.1 Instruction Format . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-16
2.3.2 VEX and the LOCK prefix . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-17
2.3.3 VEX and the 66H, F2H, and F3H prefixes. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-17
2.3.4 VEX and the REX prefix . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-17
2.3.5 The VEX Prefix . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-17
2.3.5.1 VEX Byte 0, bits[7:0]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-20
2.3.5.2 VEX Byte 1, bit [7] - ‘R’ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-20
2.3.5.3 3-byte VEX byte 1, bit[6] - ‘X’. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-20
2.3.5.4 3-byte VEX byte 1, bit[5] - ‘B’. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-20
2.3.5.5 3-byte VEX byte 2, bit[7] - ‘W’ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-20

CONTENTS
iv Vol. 2A
PAGE
2.3.5.6 2-byte VEX Byte 1, bits[6:3] and 3-byte VEX Byte 2, bits [6:3]- ‘vvvv’ the Source or
dest Register Specifier2-21
2.3.6 Instruction Operand Encoding and VEX.vvvv, ModR/M. . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-22
2.3.6.1 3-byte VEX byte 1, bits[4:0] - “m-mmmm” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-23
2.3.6.2 2-byte VEX byte 1, bit[2], and 3-byte VEX byte 2, bit [2]- “L”. . . . . . . . . . . . . . . . . . 2-24
2.3.6.3 2-byte VEX byte 1, bits[1:0], and 3-byte VEX byte 2, bits [1:0]- “pp” . . . . . . . . . . . 2-24
2.3.7 The Opcode Byte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-25
2.3.8 The MODRM, SIB, and Displacement Bytes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-25
2.3.9 The Third Source Operand (Immediate Byte). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-25
2.3.10 AVX Instructions and the Upper 128-bits of YMM registers . . . . . . . . . . . . . . . . . . . . . . 2-25
2.3.11 AVX Instruction Length . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-25
2.4 INSTRUCTION EXCEPTION SPECIFICATION . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-25
2.4.1 Exceptions Type 1 (Aligned memory reference) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-30
2.4.2 Exceptions . . . . . . . . . . . . . . . . . . . Type 2 (>=16 Byte Memory Reference, Unaligned)2-31
2.4.3 Exceptions Type 3 (<16 Byte memory argument). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-32
2.4.4 Exceptions Type 4 (>=16 Byte mem arg no alignment, no floating-point exceptions) .2-
33
2.4.5 Exceptions Type 5 (<16 Byte mem arg and no FP exceptions). . . . . . . . . . . . . . . . . . . . 2-34
2.4.6 Exceptions Type 6 (VEX-Encoded Instructions Without Legacy SSE Analogues). . . . 2-35
2.4.7 Exceptions Type 7 (No FP exceptions, no memory arg). . . . . . . . . . . . . . . . . . . . . . . . . . . 2-36
2.4.8 Exceptions Type 8 (AVX and no memory argument) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-37
2.4.9 Exception Type 9 (Intel AVX) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-38
CHAPTER 3
INSTRUCTION SET REFERENCE, A-M
3.1 INTERPRETING THE INSTRUCTION REFERENCE PAGES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-1
3.1.1 Instruction Format . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-1
3.1.1.1 Opcode Column in the Instruction Summary Table (Instructions without VEX prefix) .
3-2
3.1.1.2 Opcode Column in the Instruction Summary Table (Instructions with VEX prefix) 3-4
3.1.1.3 Instruction Column in the Opcode Summary Table . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-6
3.1.1.4 Operand Encoding Column in the Instruction Summary Table . . . . . . . . . . . . . . . . . . . 3-9
3.1.1.5 64/32-bit Mode Column in the Instruction Summary Table . . . . . . . . . . . . . . . . . . . . 3-10
3.1.1.6 CPUID Support Column in the Instruction Summary Table. . . . . . . . . . . . . . . . . . . . . . 3-11
3.1.1.7 Description Column in the Instruction Summary Table . . . . . . . . . . . . . . . . . . . . . . . . . 3-11
3.1.1.8 Description Section . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-11
3.1.1.9 Operation Section. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-11
3.1.1.10 Intel® C/C++ Compiler Intrinsics Equivalents Section . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-15
3.1.1.11 Flags Affected Section . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-18
3.1.1.12 FPU Flags Affected Section. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-18
3.1.1.13 Protected Mode Exceptions Section. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-19
3.1.1.14 Real-Address Mode Exceptions Section . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-20
3.1.1.15 Virtual-8086 Mode Exceptions Section. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-20
3.1.1.16 Floating-Point Exceptions Section. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-20
3.1.1.17 SIMD Floating-Point Exceptions Section . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-21
3.1.1.18 Compatibility Mode Exceptions Section. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-21
3.1.1.19 64-Bit Mode Exceptions Section . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-21

Vol. 2A v
CONTENTS
PAGE
3.2 INSTRUCTIONS (A-M) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-22
AAA—ASCII Adjust After Addition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-23
AAD—ASCII Adjust AX Before Division . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-25
AAM—ASCII Adjust AX After Multiply . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-27
AAS—ASCII Adjust AL After Subtraction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-29
ADC—Add with Carry . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-31
ADD—Add. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-35
ADDPD—Add Packed Double-Precision Floating-Point Values. . . . . . . . . . . . . . . . . . . . . .3-38
ADDPS—Add Packed Single-Precision Floating-Point Values. . . . . . . . . . . . . . . . . . . . . . .3-40
ADDSD—Add Scalar Double-Precision Floating-Point Values . . . . . . . . . . . . . . . . . . . . . . .3-42
ADDSS—Add Scalar Single-Precision Floating-Point Values . . . . . . . . . . . . . . . . . . . . . . . .3-44
ADDSUBPD—Packed Double-FP Add/Subtract . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-46
ADDSUBPS—Packed Single-FP Add/Subtract . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-49
AESDEC—Perform One Round of an AES Decryption Flow. . . . . . . . . . . . . . . . . . . . . . . . .3-52
AESDECLAST—Perform Last Round of an AES Decryption Flow . . . . . . . . . . . . . . . . . . .3-54
AESENC—Perform One Round of an AES Encryption Flow. . . . . . . . . . . . . . . . . . . . . . . . .3-56
AESENCLAST—Perform Last Round of an AES Encryption Flow . . . . . . . . . . . . . . . . . . .3-58
AESIMC—Perform the AES InvMixColumn Transformation. . . . . . . . . . . . . . . . . . . . . . . . .3-60
AESKEYGENASSIST—AES Round Key Generation Assist. . . . . . . . . . . . . . . . . . . . . . . . . . .3-62
AND—Logical AND . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-64
ANDPD—Bitwise Logical AND of Packed Double-Precision Floating-Point Values . . .3-67
ANDPS—Bitwise Logical AND of Packed Single-Precision Floating-Point Values . . . .3-69
ANDNPD—Bitwise Logical AND NOT of Packed Double-Precision Floating-Point Values .
3-71
ANDNPS—Bitwise Logical AND NOT of Packed Single-Precision Floating-Point Values 3-
73
ARPL—Adjust RPL Field of Segment Selector . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-75
BLENDPD — Blend Packed Double Precision Floating-Point Values. . . . . . . . . . . . . . . . .3-78
BLENDPS — Blend Packed Single Precision Floating-Point Values. . . . . . . . . . . . . . . . . .3-80
BLENDVPD — Variable Blend Packed Double Precision Floating-Point Values. . . . . . .3-83
BLENDVPS — Variable Blend Packed Single Precision Floating-Point Values. . . . . . . .3-86
BOUND—Check Array Index Against Bounds . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-89
VBROADCAST—Load with Broadcast . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-92
BSF—Bit Scan Forward . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-96
BSR—Bit Scan Reverse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-99
BSWAP—Byte Swap . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-102
BT—Bit Test . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-104
BTC—Bit Test and Complement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-107
BTR—Bit Test and Reset. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-110
BTS—Bit Test and Set . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-113
CALL—Call Procedure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-116
CBW/CWDE/CDQE—Convert Byte to Word/Convert Word to Doubleword/Convert Dou-
bleword to Quadword . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-135
CLC—Clear Carry Flag . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-137
CLD—Clear Direction Flag . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-138
CLFLUSH—Flush Cache Line . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-139
CLI — Clear Interrupt Flag . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-141

CONTENTS
vi Vol. 2A
PAGE
CLTS—Clear Task-Switched Flag in CR0 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-144
CMC—Complement Carry Flag . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-146
CMOVcc—Conditional Move . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-147
CMP—Compare Two Operands . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-154
CMPPD—Compare Packed Double-Precision Floating-Point Values . . . . . . . . . . . . . . .3-157
CMPPS—Compare Packed Single-Precision Floating-Point Values. . . . . . . . . . . . . . . . .3-167
CMPS/CMPSB/CMPSW/CMPSD/CMPSQ—Compare String Operands . . . . . . . . . . . . . . . 3-174
CMPSD—Compare Scalar Double-Precision Floating-Point Values. . . . . . . . . . . . . . . . . 3-180
CMPSS—Compare Scalar Single-Precision Floating-Point Values . . . . . . . . . . . . . . . . .3-186
CMPXCHG—Compare and Exchange . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-192
CMPXCHG8B/CMPXCHG16B—Compare and Exchange Bytes. . . . . . . . . . . . . . . . . . . . .3-195
COMISD—Compare Scalar Ordered Double-Precision Floating-Point Values and Set
EFLAGS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-198
COMISS—Compare Scalar Ordered Single-Precision Floating-Point Values and Set
EFLAGS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-200
CPUID—CPU Identification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-202
CRC32 — Accumulate CRC32 Value . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-238
CVTDQ2PD—Convert Packed Dword Integers to Packed Double-Precision FP Values. . 3-
242
CVTDQ2PS—Convert Packed Dword Integers to Packed Single-Precision FP Values. . .3-
245
CVTPD2DQ—Convert Packed Double-Precision FP Values to Packed Dword Integers. .3-
247
CVTPD2PI—Convert Packed Double-Precision FP Values to Packed Dword Integers. . .3-
250
CVTPD2PS—Convert Packed Double-Precision FP Values to Packed Single-Precision FP
Values . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-253
CVTPI2PD—Convert Packed Dword Integers to Packed Double-Precision FP Values. . . 3-
256
CVTPI2PS—Convert Packed Dword Integers to Packed Single-Precision FP Values . . . . 3-
259
CVTPS2DQ—Convert Packed Single-Precision FP Values to Packed Dword Integers. . .3-
262
CVTPS2PD—Convert Packed Single-Precision FP Values to Packed Double-Precision FP
Values . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-264
CVTPS2PI—Convert Packed Single-Precision FP Values to Packed Dword Integers . . . . 3-
267
CVTSD2SI—Convert Scalar Double-Precision FP Value to Integer . . . . . . . . . . . . . . . .3-270
CVTSD2SS—Convert Scalar Double-Precision FP Value to Scalar Single-Precision FP Val-
ue. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-272
CVTSI2SD—Convert Dword Integer to Scalar Double-Precision FP Value . . . . . . . . . 3-274
CVTSI2SS—Convert Dword Integer to Scalar Single-Precision FP Value. . . . . . . . . . . 3-276
CVTSS2SD—Convert Scalar Single-Precision FP Value to Scalar Double-Precision FP Val-
ue. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-278
CVTSS2SI—Convert Scalar Single-Precision FP Value to Dword Integer. . . . . . . . . . .3-280
CVTTPD2DQ—Convert with Truncation Packed Double-Precision FP Values to Packed
Dword Integers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-282

Vol. 2A vii
CONTENTS
PAGE
CVTTPD2PI—Convert with Truncation Packed Double-Precision FP Values to Packed
Dword Integers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-285
CVTTPS2DQ—Convert with Truncation Packed Single-Precision FP Values to Packed
Dword Integers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-288
CVTTPS2PI—Convert with Truncation Packed Single-Precision FP Values to Packed
Dword Integers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-291
CVTTSD2SI—Convert with Truncation Scalar Double-Precision FP Value to Signed Inte-
ger . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-294
CVTTSS2SI—Convert with Truncation Scalar Single-Precision FP Value to Dword Integer
3-296
CWD/CDQ/CQO—Convert Word to Doubleword/Convert Doubleword to Quadword3-298
DAA—Decimal Adjust AL after Addition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-300
DAS—Decimal Adjust AL after Subtraction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-302
DEC—Decrement by 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-304
DIV—Unsigned Divide . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-307
DIVPD—Divide Packed Double-Precision Floating-Point Values . . . . . . . . . . . . . . . . . . 3-311
DIVPS—Divide Packed Single-Precision Floating-Point Values . . . . . . . . . . . . . . . . . . . 3-313
DIVSD—Divide Scalar Double-Precision Floating-Point Values . . . . . . . . . . . . . . . . . . . 3-315
DIVSS—Divide Scalar Single-Precision Floating-Point Values. . . . . . . . . . . . . . . . . . . . . 3-317
DPPD — Dot Product of Packed Double Precision Floating-Point Values. . . . . . . . . . 3-319
DPPS — Dot Product of Packed Single Precision Floating-Point Values. . . . . . . . . . . 3-322
EMMS—Empty MMX Technology State . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-325
ENTER—Make Stack Frame for Procedure Parameters. . . . . . . . . . . . . . . . . . . . . . . . . . 3-327
VEXTRACTF128 — Extract Packed Floating-Point Values . . . . . . . . . . . . . . . . . . . . . . . 3-331
EXTRACTPS — Extract Packed Single Precision Floating-Point Value . . . . . . . . . . . . 3-333
F2XM1—Compute 2x–1. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-335
FABS—Absolute Value . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-337
FADD/FADDP/FIADD—Add . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-339
FBLD—Load Binary Coded Decimal. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-343
FBSTP—Store BCD Integer and Pop. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-345
FCHS—Change Sign . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-348
FCLEX/FNCLEX—Clear Exceptions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-350
FCMOVcc—Floating-Point Conditional Move . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-352
FCOMI/FCOMIP/ FUCOMI/FUCOMIP—Compare Floating Point Values and Set EFLAGS . 3-
358
FCOS—Cosine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-361
FDECSTP—Decrement Stack-Top Pointer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-363
FDIV/FDIVP/FIDIV—Divide. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-365
FDIVR/FDIVRP/FIDIVR—Reverse Divide . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-369
FFREE—Free Floating-Point Register . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-373
FICOM/FICOMP—Compare Integer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-374
FILD—Load Integer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-377
FINCSTP—Increment Stack-Top Pointer. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-379
FINIT/FNINIT—Initialize Floating-Point Unit. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-381
FIST/FISTP—Store Integer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-383
FISTTP—Store Integer with Truncation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-387
FLD—Load Floating Point Value . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-390

CONTENTS
viii Vol. 2A
PAGE
FLD1/FLDL2T/FLDL2E/FLDPI/FLDLG2/FLDLN2/FLDZ—Load Constant. . . . . . . . . . . .3-393
FLDCW—Load x87 FPU Control Word. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-395
FLDENV—Load x87 FPU Environment . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-397
FMUL/FMULP/FIMUL—Multiply . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-400
FNOP—No Operation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-404
FPATAN—Partial Arctangent . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-405
FPREM—Partial Remainder . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-408
FPREM1—Partial Remainder . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-411
FPTAN—Partial Tangent. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-414
FRNDINT—Round to Integer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-417
FRSTOR—Restore x87 FPU State . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-419
FSAVE/FNSAVE—Store x87 FPU State . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-422
FSCALE—Scale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-426
FSIN—Sine. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-428
FSINCOS—Sine and Cosine. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-430
FSQRT—Square Root. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-433
FST/FSTP—Store Floating Point Value . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-435
FSTCW/FNSTCW—Store x87 FPU Control Word . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-438
FSTENV/FNSTENV—Store x87 FPU Environment . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-441
FSTSW/FNSTSW—Store x87 FPU Status Word. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-444
FSUB/FSUBP/FISUB—Subtract . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-447
FSUBR/FSUBRP/FISUBR—Reverse Subtract . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-451
FTST—TEST . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-455
FUCOM/FUCOMP/FUCOMPP—Unordered Compare Floating Point Values . . . . . . . . . 3-457
FXAM—Examine ModR/M . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-460
FXCH—Exchange Register Contents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-462
FXRSTOR—Restore x87 FPU, MMX , XMM, and MXCSR State . . . . . . . . . . . . . . . . . . . .3-464
FXSAVE—Save x87 FPU, MMX Technology, and SSE State . . . . . . . . . . . . . . . . . . . . . . 3-468
FXTRACT—Extract Exponent and Significand . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-478
FYL2X—Compute y * log2x . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-480
FYL2XP1—Compute y * log2(x +1). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-482
HADDPD—Packed Double-FP Horizontal Add. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-484
HADDPS—Packed Single-FP Horizontal Add. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-487
HLT—Halt . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-491
HSUBPD—Packed Double-FP Horizontal Subtract . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-493
HSUBPS—Packed Single-FP Horizontal Subtract . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-496
IDIV—Signed Divide . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-500
IMUL—Signed Multiply . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-504
IN—Input from Port . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-509
INC—Increment by 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-511
INS/INSB/INSW/INSD—Input from Port to String . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-514
VINSERTF128 — Insert Packed Floating-Point Values . . . . . . . . . . . . . . . . . . . . . . . . . . .3-519
INSERTPS — Insert Packed Single Precision Floating-Point Value . . . . . . . . . . . . . . . . 3-521
INT n/INTO/INT 3—Call to Interrupt Procedure. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-525
INVD—Invalidate Internal Caches. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-541
INVLPG—Invalidate TLB Entry . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-543
IRET/IRETD—Interrupt Return . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-545

Vol. 2A ix
CONTENTS
PAGE
Jcc—Jump if Condition Is Met . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-556
JMP—Jump . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-564
LAHF—Load Status Flags into AH Register . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-575
LAR—Load Access Rights Byte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-577
LDDQU—Load Unaligned Integer 128 Bits. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-581
LDMXCSR—Load MXCSR Register . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-583
LDS/LES/LFS/LGS/LSS—Load Far Pointer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-585
LEA—Load Effective Address . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-591
LEAVE—High Level Procedure Exit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-594
LFENCE—Load Fence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-596
LGDT/LIDT—Load Global/Interrupt Descriptor Table Register. . . . . . . . . . . . . . . . . . . . 3-598
LLDT—Load Local Descriptor Table Register . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-601
LMSW—Load Machine Status Word . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-604
LOCK—Assert LOCK# Signal Prefix . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-606
LODS/LODSB/LODSW/LODSD/LODSQ—Load String . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-608
LOOP/LOOPcc—Loop According to ECX Counter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-612
LSL—Load Segment Limit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-615
LTR—Load Task Register . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-619
MASKMOVDQU—Store Selected Bytes of Double Quadword . . . . . . . . . . . . . . . . . . . . 3-622
VMASKMOV—Conditional SIMD Packed Loads and Stores . . . . . . . . . . . . . . . . . . . . . . . 3-624
MASKMOVQ—Store Selected Bytes of Quadword . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-628
MAXPD—Return Maximum Packed Double-Precision Floating-Point Values. . . . . . . 3-631
MAXPS—Return Maximum Packed Single-Precision Floating-Point Values. . . . . . . . 3-634
MAXSD—Return Maximum Scalar Double-Precision Floating-Point Value . . . . . . . . . 3-637
MAXSS—Return Maximum Scalar Single-Precision Floating-Point Value . . . . . . . . . 3-639
MFENCE—Memory Fence. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-641
MINPD—Return Minimum Packed Double-Precision Floating-Point Values . . . . . . . . 3-643
MINPS—Return Minimum Packed Single-Precision Floating-Point Values . . . . . . . . . 3-646
MINSD—Return Minimum Scalar Double-Precision Floating-Point Value . . . . . . . . . . 3-649
MINSS—Return Minimum Scalar Single-Precision Floating-Point Value . . . . . . . . . . . 3-651
MONITOR—Set Up Monitor Address . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-653
MOV—Move . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-656
MOV—Move to/from Control Registers. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-663
MOV—Move to/from Debug Registers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-667
MOVAPD—Move Aligned Packed Double-Precision Floating-Point Values. . . . . . . . . 3-669
MOVAPS—Move Aligned Packed Single-Precision Floating-Point Values. . . . . . . . . . 3-672
MOVBE—Move Data After Swapping Bytes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-675
MOVD/MOVQ—Move Doubleword/Move Quadword. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-678
MOVDDUP—Move One Double-FP and Duplicate. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-681
MOVDQA—Move Aligned Double Quadword . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-684
MOVDQU—Move Unaligned Double Quadword. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-687
MOVDQ2Q—Move Quadword from XMM to MMX Technology Register. . . . . . . . . . . 3-690
MOVHLPS— Move Packed Single-Precision Floating-Point Values High to Low . . . 3-692
MOVHPD—Move High Packed Double-Precision Floating-Point Value . . . . . . . . . . . . 3-694
MOVHPS—Move High Packed Single-Precision Floating-Point Values . . . . . . . . . . . . 3-696
MOVLHPS—Move Packed Single-Precision Floating-Point Values Low to High . . . . 3-698
MOVLPD—Move Low Packed Double-Precision Floating-Point Value . . . . . . . . . . . . . 3-700

CONTENTS
xVol. 2A
PAGE
MOVLPS—Move Low Packed Single-Precision Floating-Point Values. . . . . . . . . . . . . . 3-702
MOVMSKPD—Extract Packed Double-Precision Floating-Point Sign Mask . . . . . . . . .3-704
MOVMSKPS—Extract Packed Single-Precision Floating-Point Sign Mask . . . . . . . . . . 3-706
MOVNTDQA — Load Double Quadword Non-Temporal Aligned Hint . . . . . . . . . . . . . .3-709
MOVNTDQ—Store Double Quadword Using Non-Temporal Hint . . . . . . . . . . . . . . . . . .3-712
MOVNTI—Store Doubleword Using Non-Temporal Hint . . . . . . . . . . . . . . . . . . . . . . . . . .3-714
MOVNTPD—Store Packed Double-Precision Floating-Point Values Using Non-Temporal
Hint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-716
MOVNTPS—Store Packed Single-Precision Floating-Point Values Using Non-Temporal
Hint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-718
MOVNTQ—Store of Quadword Using Non-Temporal Hint . . . . . . . . . . . . . . . . . . . . . . . .3-720
MOVQ—Move Quadword . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-723
MOVQ2DQ—Move Quadword from MMX Technology to XMM Register . . . . . . . . . . .3-726
MOVS/MOVSB/MOVSW/MOVSD/MOVSQ—Move Data from String to String . . . . . . .3-728
MOVSD—Move Scalar Double-Precision Floating-Point Value . . . . . . . . . . . . . . . . . . . .3-733
MOVSHDUP—Move Packed Single-FP High and Duplicate . . . . . . . . . . . . . . . . . . . . . . . .3-736
MOVSLDUP—Move Packed Single-FP Low and Duplicate. . . . . . . . . . . . . . . . . . . . . . . . .3-739
MOVSS—Move Scalar Single-Precision Floating-Point Values. . . . . . . . . . . . . . . . . . . . . 3-742
MOVSX/MOVSXD—Move with Sign-Extension . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-745
MOVUPD—Move Unaligned Packed Double-Precision Floating-Point Values. . . . . . .3-748
MOVUPS—Move Unaligned Packed Single-Precision Floating-Point Values . . . . . . . .3-751
MOVZX—Move with Zero-Extend . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-754
MPSADBW — Compute Multiple Packed Sums of Absolute Difference . . . . . . . . . . . . 3-756
MUL—Unsigned Multiply . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-761
MULPD—Multiply Packed Double-Precision Floating-Point Values . . . . . . . . . . . . . . . . 3-764
MULPS—Multiply Packed Single-Precision Floating-Point Values . . . . . . . . . . . . . . . . .3-766
MULSD—Multiply Scalar Double-Precision Floating-Point Values . . . . . . . . . . . . . . . . . 3-768
MULSS—Multiply Scalar Single-Precision Floating-Point Values. . . . . . . . . . . . . . . . . . .3-770
MWAIT—Monitor Wait . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-772
CHAPTER 4
INSTRUCTION SET REFERENCE, N-Z
4.1 IMM8 CONTROL BYTE OPERATION FOR PCMPESTRI / PCMPESTRM / PCMPISTRI /
PCMPISTRM 4-1
4.1.1 General Description . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-1
4.1.2 Source Data Format. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-2
4.1.3 Aggregation Operation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-3
4.1.4 Polarity. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-4
4.1.5 Output Selection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-5
4.1.6 Valid/Invalid Override of Comparisons . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-5
4.1.7 Summary of Im8 Control byte. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-6
4.1.8 Diagram Comparison and Aggregation Process. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-7
4.2 INSTRUCTIONS (N-Z) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-7
NEG—Two's Complement Negation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-8
NOP—No Operation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-11
NOT—One's Complement Negation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-13
OR—Logical Inclusive OR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-15

Vol. 2A xi
CONTENTS
PAGE
ORPD—Bitwise Logical OR of Double-Precision Floating-Point Values . . . . . . . . . . . . . .4-18
ORPS—Bitwise Logical OR of Single-Precision Floating-Point Values . . . . . . . . . . . . . . .4-20
OUT—Output to Port . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-22
OUTS/OUTSB/OUTSW/OUTSD—Output String to Port . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-25
PABSB/PABSW/PABSD — Packed Absolute Value . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-31
PACKSSWB/PACKSSDW—Pack with Signed Saturation . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-35
PACKUSDW — Pack with Unsigned Saturation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-39
PACKUSWB—Pack with Unsigned Saturation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-41
PADDB/PADDW/PADDD—Add Packed Integers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-44
PADDQ—Add Packed Quadword Integers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-48
PADDSB/PADDSW—Add Packed Signed Integers with Signed Saturation. . . . . . . . . . .4-50
PADDUSB/PADDUSW—Add Packed Unsigned Integers with Unsigned Saturation . . .4-53
PALIGNR — Packed Align Right . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-56
PAND—Logical AND. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-58
PANDN—Logical AND NOT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-60
PAUSE—Spin Loop Hint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-62
PAVGB/PAVGW—Average Packed Integers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-64
PBLENDVB — Variable Blend Packed Bytes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-67
PBLENDW — Blend Packed Words . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-71
PCLMULQDQ - Carry-Less Multiplication Quadword . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-73
PCMPEQB/PCMPEQW/PCMPEQD— Compare Packed Data for Equal . . . . . . . . . . . . . . . .4-77
PCMPEQQ — Compare Packed Qword Data for Equal. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-81
PCMPESTRI — Packed Compare Explicit Length Strings, Return Index. . . . . . . . . . . . . .4-83
PCMPESTRM — Packed Compare Explicit Length Strings, Return Mask . . . . . . . . . . . . .4-85
PCMPGTB/PCMPGTW/PCMPGTD—Compare Packed Signed Integers for Greater Than. 4-
87
PCMPGTQ — Compare Packed Data for Greater Than . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-91
PCMPISTRI — Packed Compare Implicit Length Strings, Return Index . . . . . . . . . . . . . .4-93
PCMPISTRM — Packed Compare Implicit Length Strings, Return Mask. . . . . . . . . . . . . .4-95
VPERMILPD — Permute Double-Precision Floating-Point Values . . . . . . . . . . . . . . . . . . .4-97
VPERMILPS — Permute Single-Precision Floating-Point Values . . . . . . . . . . . . . . . . . . 4-101
VPERM2F128 — Permute Floating-Point Values . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-105
PEXTRB/PEXTRD/PEXTRQ — Extract Byte/Dword/Qword . . . . . . . . . . . . . . . . . . . . . . 4-108
PEXTRW—Extract Word. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-111
PHADDW/PHADDD — Packed Horizontal Add. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-114
PHADDSW — Packed Horizontal Add and Saturate. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-117
PHMINPOSUW — Packed Horizontal Word Minimum. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-119
PHSUBW/PHSUBD — Packed Horizontal Subtract. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-121
PHSUBSW — Packed Horizontal Subtract and Saturate . . . . . . . . . . . . . . . . . . . . . . . . . 4-124
PINSRB/PINSRD/PINSRQ — Insert Byte/Dword/Qword . . . . . . . . . . . . . . . . . . . . . . . . . . 4-126
PINSRW—Insert Word. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-129
PMADDUBSW — Multiply and Add Packed Signed and Unsigned Bytes . . . . . . . . . . . 4-132
PMADDWD—Multiply and Add Packed Integers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-134
PMAXSB — Maximum of Packed Signed Byte Integers . . . . . . . . . . . . . . . . . . . . . . . . . . 4-137
PMAXSD — Maximum of Packed Signed Dword Integers . . . . . . . . . . . . . . . . . . . . . . . . 4-140
PMAXSW—Maximum of Packed Signed Word Integers . . . . . . . . . . . . . . . . . . . . . . . . . . 4-142
PMAXUB—Maximum of Packed Unsigned Byte Integers . . . . . . . . . . . . . . . . . . . . . . . . 4-145

CONTENTS
xii Vol. 2A
PAGE
PMAXUD — Maximum of Packed Unsigned Dword Integers . . . . . . . . . . . . . . . . . . . . . . 4-148
PMAXUW — Maximum of Packed Word Integers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-150
PMINSB — Minimum of Packed Signed Byte Integers . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-152
PMINSD — Minimum of Packed Dword Integers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-155
PMINSW—Minimum of Packed Signed Word Integers . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-157
PMINUB—Minimum of Packed Unsigned Byte Integers . . . . . . . . . . . . . . . . . . . . . . . . . .4-160
PMINUD — Minimum of Packed Dword Integers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-163
PMINUW — Minimum of Packed Word Integers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-165
PMOVMSKB—Move Byte Mask . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-167
PMOVSX — Packed Move with Sign Extend . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-169
PMOVZX — Packed Move with Zero Extend . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-173
PMULDQ — Multiply Packed Signed Dword Integers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-177
PMULHRSW — Packed Multiply High with Round and Scale . . . . . . . . . . . . . . . . . . . . . .4-179
PMULHUW—Multiply Packed Unsigned Integers and Store High Result . . . . . . . . . . .4-182
PMULHW—Multiply Packed Signed Integers and Store High Result . . . . . . . . . . . . . . .4-185
PMULLD — Multiply Packed Signed Dword Integers and Store Low Result . . . . . . . .4-188
PMULLW—Multiply Packed Signed Integers and Store Low Result. . . . . . . . . . . . . . . . 4-190
PMULUDQ—Multiply Packed Unsigned Doubleword Integers . . . . . . . . . . . . . . . . . . . . . 4-193
POP—Pop a Value from the Stack . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-195
POPA/POPAD—Pop All General-Purpose Registers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-202
POPCNT — Return the Count of Number of Bits Set to 1 . . . . . . . . . . . . . . . . . . . . . . . .4-205
POPF/POPFD/POPFQ—Pop Stack into EFLAGS Register . . . . . . . . . . . . . . . . . . . . . . . . . 4-207
POR—Bitwise Logical OR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-211
PREFETCHh—Prefetch Data Into Caches . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-213
PSADBW—Compute Sum of Absolute Differences. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-216
PSHUFB — Packed Shuffle Bytes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-219
PSHUFD—Shuffle Packed Doublewords . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-222
PSHUFHW—Shuffle Packed High Words . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-224
PSHUFLW—Shuffle Packed Low Words. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-226
PSHUFW—Shuffle Packed Words. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-228
PSIGNB/PSIGNW/PSIGND — Packed SIGN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-231
PSLLDQ—Shift Double Quadword Left Logical . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-236
PSLLW/PSLLD/PSLLQ—Shift Packed Data Left Logical. . . . . . . . . . . . . . . . . . . . . . . . . . .4-238
PSRAW/PSRAD—Shift Packed Data Right Arithmetic . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-245
PSRLDQ—Shift Double Quadword Right Logical . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-250
PSRLW/PSRLD/PSRLQ—Shift Packed Data Right Logical. . . . . . . . . . . . . . . . . . . . . . . . .4-252
PSUBB/PSUBW/PSUBD—Subtract Packed Integers. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-258
PSUBQ—Subtract Packed Quadword Integers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-262
PSUBSB/PSUBSW—Subtract Packed Signed Integers with Signed Saturation . . . . .4-264
PSUBUSB/PSUBUSW—Subtract Packed Unsigned Integers with Unsigned Saturation . 4-
267
PTEST- Logical Compare. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-270
PUNPCKHBW/PUNPCKHWD/PUNPCKHDQ/PUNPCKHQDQ— Unpack High Data . . . . 4-274
PUNPCKLBW/PUNPCKLWD/PUNPCKLDQ/PUNPCKLQDQ—
Unpack Low Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-280
PUSH—Push Word, Doubleword or Quadword Onto the Stack. . . . . . . . . . . . . . . . . . . .4-285
PUSHA/PUSHAD—Push All General-Purpose Registers . . . . . . . . . . . . . . . . . . . . . . . . . .4-290

Vol. 2A xiii
CONTENTS
PAGE
PUSHF/PUSHFD—Push EFLAGS Register onto the Stack . . . . . . . . . . . . . . . . . . . . . . . . 4-293
PXOR—Logical Exclusive OR. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-296
RCL/RCR/ROL/ROR-—Rotate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-298
RCPPS—Compute Reciprocals of Packed Single-Precision Floating-Point Values . . 4-306
RCPSS—Compute Reciprocal of Scalar Single-Precision Floating-Point Values . . . . 4-309
RDMSR—Read from Model Specific Register. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-311
RDPMC—Read Performance-Monitoring Counters . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-313
RDTSC—Read Time-Stamp Counter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-319
RDTSCP—Read Time-Stamp Counter and Processor ID . . . . . . . . . . . . . . . . . . . . . . . . . . 4-321
REP/REPE/REPZ/REPNE/REPNZ—Repeat String Operation Prefix . . . . . . . . . . . . . . . 4-323
RET—Return from Procedure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-328
ROUNDPD — Round Packed Double Precision Floating-Point Values . . . . . . . . . . . . . 4-340
ROUNDPS — Round Packed Single Precision Floating-Point Values . . . . . . . . . . . . . . 4-343
ROUNDSD — Round Scalar Double Precision Floating-Point Values . . . . . . . . . . . . . . 4-346
ROUNDSS — Round Scalar Single Precision Floating-Point Values. . . . . . . . . . . . . . . . 4-348
RSM—Resume from System Management Mode. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-350
RSQRTPS—Compute Reciprocals of Square Roots of Packed Single-Precision Floating-
Point Values . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-352
RSQRTSS—Compute Reciprocal of Square Root of Scalar Single-Precision Floating-Point
Value . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-355
SAHF—Store AH into Flags. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-357
SAL/SAR/SHL/SHR—Shift . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-359
SBB—Integer Subtraction with Borrow . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-367
SCAS/SCASB/SCASW/SCASD—Scan String . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-371
SETcc—Set Byte on Condition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-376
SFENCE—Store Fence. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-381
SGDT—Store Global Descriptor Table Register. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-382
SHLD—Double Precision Shift Left. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-385
SHRD—Double Precision Shift Right . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-389
SHUFPD—Shuffle Packed Double-Precision Floating-Point Values . . . . . . . . . . . . . . . 4-393
SHUFPS—Shuffle Packed Single-Precision Floating-Point Values . . . . . . . . . . . . . . . . 4-396
SIDT—Store Interrupt Descriptor Table Register . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-400
SLDT—Store Local Descriptor Table Register. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-403
SMSW—Store Machine Status Word . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-405
SQRTPD—Compute Square Roots of Packed Double-Precision Floating-Point Values . 4-
408
SQRTPS—Compute Square Roots of Packed Single-Precision Floating-Point Values . . 4-
410
SQRTSD—Compute Square Root of Scalar Double-Precision Floating-Point Value. 4-413
SQRTSS—Compute Square Root of Scalar Single-Precision Floating-Point Value. . 4-415
VSTMXCSR—Store MXCSR Register State. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-417
STC—Set Carry Flag . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-418
STD—Set Direction Flag. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-419
STI—Set Interrupt Flag. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-420
STMXCSR—Store MXCSR Register State . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-423
STOS/STOSB/STOSW/STOSD/STOSQ—Store String. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-425
STR—Store Task Register. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-430

CONTENTS
xiv Vol. 2A
PAGE
SUB—Subtract . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-432
SUBPD—Subtract Packed Double-Precision Floating-Point Values . . . . . . . . . . . . . . . .4-435
SUBPS—Subtract Packed Single-Precision Floating-Point Values . . . . . . . . . . . . . . . . . 4-437
SUBSD—Subtract Scalar Double-Precision Floating-Point Values . . . . . . . . . . . . . . . . .4-440
SUBSS—Subtract Scalar Single-Precision Floating-Point Values . . . . . . . . . . . . . . . . . . 4-442
SWAPGS—Swap GS Base Register . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-444
SYSCALL—Fast System Call. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-446
SYSENTER—Fast System Call . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-448
SYSEXIT—Fast Return from Fast System Call . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-453
SYSRET—Return From Fast System Call . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-457
TEST—Logical Compare . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-459
VTESTPD/VTESTPS—Packed Bit Test . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-462
UCOMISD—Unordered Compare Scalar Double-Precision Floating-Point Values and Set
EFLAGS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-463
UCOMISS—Unordered Compare Scalar Single-Precision Floating-Point Values and Set
EFLAGS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-465
UD2—Undefined Instruction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-467
UNPCKHPD—Unpack and Interleave High Packed Double-Precision Floating-Point Values
4-468
UNPCKHPS—Unpack and Interleave High Packed Single-Precision Floating-Point Values
4-471
UNPCKLPD—Unpack and Interleave Low Packed Double-Precision Floating-Point Values
4-474
UNPCKLPS—Unpack and Interleave Low Packed Single-Precision Floating-Point Values
4-477
VERR/VERW—Verify a Segment for Reading or Writing . . . . . . . . . . . . . . . . . . . . . . . . .4-480
WAIT/FWAIT—Wait. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-483
WBINVD—Write Back and Invalidate Cache . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-485
WRMSR—Write to Model Specific Register . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-487
XADD—Exchange and Add. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-489
XCHG—Exchange Register/Memory with Register . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-492
XGETBV—Get Value of Extended Control Register . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-495
XLAT/XLATB—Table Look-up Translation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-497
XOR—Logical Exclusive OR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-500
XORPD—Bitwise Logical XOR for Double-Precision Floating-Point Values. . . . . . . . . 4-503
XORPS—Bitwise Logical XOR for Single-Precision Floating-Point Values. . . . . . . . . . 4-505
XRSTOR—Restore Processor Extended States. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-507
XSAVE—Save Processor Extended States . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-513
XSAVEOPT—Save Processor Extended States Optimized. . . . . . . . . . . . . . . . . . . . . . . . 4-517
XSETBV—Set Extended Control Register . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-521
VZEROALL—Zero All YMM Registers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-523
VZEROUPPER—Zero Upper Bits of YMM Registers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-525
CHAPTER 5
VMX INSTRUCTION REFERENCE
5.1 OVERVIEW. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5-1
5.2 CONVENTIONS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5-2

Vol. 2A xv
CONTENTS
PAGE
5.3 VMX INSTRUCTIONS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5-3
INVEPT— Invalidate Translations Derived from EPT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5-4
INVVPID— Invalidate Translations Based on VPID . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5-7
VMCALL—Call to VM Monitor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .5-11
VMCLEAR—Clear Virtual-Machine Control Structure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .5-13
VMLAUNCH/VMRESUME—Launch/Resume Virtual Machine . . . . . . . . . . . . . . . . . . . . . . .5-16
VMPTRLD—Load Pointer to Virtual-Machine Control Structure . . . . . . . . . . . . . . . . . . . .5-19
VMPTRST—Store Pointer to Virtual-Machine Control Structure . . . . . . . . . . . . . . . . . . .5-22
VMREAD—Read Field from Virtual-Machine Control Structure . . . . . . . . . . . . . . . . . . . . .5-24
VMRESUME—Resume Virtual Machine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .5-26
VMWRITE—Write Field to Virtual-Machine Control Structure . . . . . . . . . . . . . . . . . . . . . .5-27
VMXOFF—Leave VMX Operation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .5-29
VMXON—Enter VMX Operation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .5-31
5.4 VM INSTRUCTION ERROR NUMBERS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5-34
CHAPTER 6
SAFER MODE EXTENSIONS REFERENCE
6.1 OVERVIEW . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6-1
6.2 SMX FUNCTIONALITY . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6-1
6.2.1 Detecting and Enabling SMX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6-2
6.2.2 SMX Instruction Summary. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6-3
6.2.2.1 GETSEC[CAPABILITIES] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6-3
6.2.2.2 GETSEC[ENTERACCS] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6-4
6.2.2.3 GETSEC[EXITAC]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6-4
6.2.2.4 GETSEC[SENTER] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6-4
6.2.2.5 GETSEC[SEXIT] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6-5
6.2.2.6 GETSEC[PARAMETERS] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6-5
6.2.2.7 GETSEC[SMCTRL]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6-5
6.2.2.8 GETSEC[WAKEUP] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6-6
6.2.3 Measured Environment and SMX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6-6
6.3 GETSEC LEAF FUNCTIONS. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6-7
GETSEC[CAPABILITIES] - Report the SMX Capabilities . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6-9
GETSEC[ENTERACCS] - Execute Authenticated Chipset Code . . . . . . . . . . . . . . . . . . . . . .6-12
GETSEC[EXITAC]—Exit Authenticated Code Execution Mode . . . . . . . . . . . . . . . . . . . . . .6-23
GETSEC[SENTER]—Enter a Measured Environment . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .6-27
GETSEC[SEXIT]—Exit Measured Environment . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .6-39
GETSEC[PARAMETERS]—Report the SMX Parameters . . . . . . . . . . . . . . . . . . . . . . . . . . . .6-43
GETSEC[SMCTRL]—SMX Mode Control . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .6-49
GETSEC[WAKEUP]—Wake up sleeping processors in measured environment . . . . . . .6-52
APPENDIX A
OPCODE MAP
A.1 USING OPCODE TABLES. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-1
A.2 KEY TO ABBREVIATIONS. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-2
A.2.1 Codes for Addressing Method . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-2
A.2.2 Codes for Operand Type . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-3
A.2.3 Register Codes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-4

CONTENTS
xvi Vol. 2A
PAGE
A.2.4 Opcode Look-up Examples for One, Two,
and Three-Byte OpcodesA-5
A.2.4.1 One-Byte Opcode Instructions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-5
A.2.4.2 Two-Byte Opcode Instructions. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-6
A.2.4.3 Three-Byte Opcode Instructions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-7
A.2.4.4 VEX Prefix Instructions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-7
A.2.5 Superscripts Utilized in Opcode Tables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-8
A.3 ONE, TWO, AND THREE-BYTE OPCODE MAPS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-9
A.4 OPCODE EXTENSIONS FOR ONE-BYTE AND TWO-BYTE OPCODES . . . . . . . . . . . . . . . . . . . A-21
A.4.1 Opcode Look-up Examples Using Opcode Extensions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-21
A.4.2 Opcode Extension Tables. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-22
A.5 ESCAPE OPCODE INSTRUCTIONS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-24
A.5.1 Opcode Look-up Examples for Escape Instruction Opcodes . . . . . . . . . . . . . . . . . . . . . . . A-24
A.5.2 Escape Opcode Instruction Tables. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-24
A.5.2.1 Escape Opcodes with D8 as First Byte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-25
A.5.2.2 Escape Opcodes with D9 as First Byte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-26
A.5.2.3 Escape Opcodes with DA as First Byte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-27
A.5.2.4 Escape Opcodes with DB as First Byte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-28
A.5.2.5 Escape Opcodes with DC as First Byte. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-29
A.5.2.6 Escape Opcodes with DD as First Byte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-30
A.5.2.7 Escape Opcodes with DE as First Byte. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-31
A.5.2.8 Escape Opcodes with DF As First Byte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-32
APPENDIX B
INSTRUCTION FORMATS AND ENCODINGS
B.1 MACHINE INSTRUCTION FORMAT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-1
B.1.1 Legacy Prefixes. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-2
B.1.2 REX Prefixes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-2
B.1.3 Opcode Fields. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-2
B.1.4 Special Fields . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-2
B.1.4.1 Reg Field (reg) for Non-64-Bit Modes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-3
B.1.4.2 Reg Field (reg) for 64-Bit Mode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-4
B.1.4.3 Encoding of Operand Size (w) Bit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-5
B.1.4.4 Sign-Extend (s) Bit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-5
B.1.4.5 Segment Register (sreg) Field . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-6
B.1.4.6 Special-Purpose Register (eee) Field . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-6
B.1.4.7 Condition Test (tttn) Field . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-7
B.1.4.8 Direction (d) Bit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-8
B.1.5 Other Notes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-9
B.2 GENERAL-PURPOSE INSTRUCTION FORMATS AND ENCODINGS FOR NON-64-BIT MODES B-
9
B.2.1 General Purpose Instruction Formats and Encodings for 64-Bit Mode . . . . . . . . . . . . . B-24
B.3 PENTIUM® PROCESSOR FAMILY INSTRUCTION FORMATS AND ENCODINGS . . . . . . . . . . B-53
B.4 64-BIT MODE INSTRUCTION ENCODINGS FOR SIMD INSTRUCTION EXTENSIONS . . . . . . B-54
B.5 MMX INSTRUCTION FORMATS AND ENCODINGS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-55
B.5.1 Granularity Field (gg) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-55
B.5.2 MMX Technology and General-Purpose Register Fields (mmxreg and reg) . . . . . . . . . B-55

Vol. 2A xvii
CONTENTS
PAGE
B.5.3 MMX Instruction Formats and Encodings Table . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .B-55
B.6 PROCESSOR EXTENDED STATE INSTRUCTION FORMATS AND ENCODINGS. . . . . . . . . . . B-59
B.7 P6 FAMILY INSTRUCTION FORMATS AND ENCODINGS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-59
B.8 SSE INSTRUCTION FORMATS AND ENCODINGS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-60
B.9 SSE2 INSTRUCTION FORMATS AND ENCODINGS. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-69
B.9.1 Granularity Field (gg) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .B-69
B.10 SSE3 FORMATS AND ENCODINGS TABLE. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-86
B.11 SSSE3 FORMATS AND ENCODING TABLE. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-88
B.12 AESNI AND PCLMULQDQ INSTRUCTION FORMATS AND ENCODINGS . . . . . . . . . . . . . . . . . B-92
B.13 SPECIAL ENCODINGS FOR 64-BIT MODE. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-93
B.14 SSE4.1 FORMATS AND ENCODING TABLE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-97
B.15 SSE4.2 FORMATS AND ENCODING TABLE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-106
B.16 FLOATING-POINT INSTRUCTION FORMATS AND ENCODINGS . . . . . . . . . . . . . . . . . . . . . . . B-107
B.17 VMX INSTRUCTIONS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-114
B.18 SMX INSTRUCTIONS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-116
APPENDIX C
INTEL® C/C++ COMPILER INTRINSICS AND FUNCTIONAL EQUIVALENTS
C.1 SIMPLE INTRINSICS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . C-2
C.2 COMPOSITE INTRINSICS. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . C-17
FIGURES
Figure 1-1. Bit and Byte Order . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-5
Figure 1-2. Syntax for CPUID, CR, and MSR Data Presentation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-8
Figure 2-1. Intel 64 and IA-32 Architectures Instruction Format. . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-1
Figure 2-2. Table Interpretation of ModR/M Byte (C8H) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-5
Figure 2-3. Prefix Ordering in 64-bit Mode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-9
Figure 2-4. Memory Addressing Without an SIB Byte; REX.X Not Used . . . . . . . . . . . . . . . . . . . . .2-11
Figure 2-5. Register-Register Addressing (No Memory Operand); REX.X Not Used . . . . . . . . . .2-11
Figure 2-6. Memory Addressing With a SIB Byte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-12
Figure 2-7. Register Operand Coded in Opcode Byte; REX.X & REX.R Not Used . . . . . . . . . . . . .2-12
Figure 2-8. Instruction Encoding Format with VEX Prefix . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-17
Figure 2-9. VEX bitfields . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-19
Figure 3-1. Bit Offset for BIT[RAX, 21] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-14
Figure 3-2. Memory Bit Indexing. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-15
Figure 3-3. ADDSUBPD—Packed Double-FP Add/Subtract . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-47
Figure 3-4. ADDSUBPS—Packed Single-FP Add/Subtract . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-50
Figure 3-5. VBROADCASTSS Operation (VEX.256 encoded version) . . . . . . . . . . . . . . . . . . . . . . .3-93
Figure 3-6. VBROADCASTSS Operation (128-bit version) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-93
Figure 3-7. VBROADCASTSD Operation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-94
Figure 3-8. VBROADCASTF128 Operation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-94
Figure 3-9. Version Information Returned by CPUID in EAX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-213
Figure 3-10. Feature Information Returned in the ECX Register . . . . . . . . . . . . . . . . . . . . . . . . . . 3-216
Figure 3-11. Feature Information Returned in the EDX Register . . . . . . . . . . . . . . . . . . . . . . . . . . 3-219
Figure 3-12. Determination of Support for the Processor Brand String. . . . . . . . . . . . . . . . . . . . 3-229
Figure 3-13. Algorithm for Extracting Maximum Processor Frequency . . . . . . . . . . . . . . . . . . . . 3-232

CONTENTS
xviii Vol. 2A
PAGE
Figure 3-14. CVTDQ2PD (VEX.256 encoded version) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-243
Figure 3-15. VCVTPD2DQ (VEX.256 encoded version). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-248
Figure 3-16. VCVTPD2PS (VEX.256 encoded version) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-254
Figure 3-17. CVTPS2PD (VEX.256 encoded version). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-265
Figure 3-18. VCVTTPD2DQ (VEX.256 encoded version) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-283
Figure 3-19. HADDPD—Packed Double-FP Horizontal Add . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-485
Figure 3-20. VHADDPD operation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-485
Figure 3-21. HADDPS—Packed Single-FP Horizontal Add. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-488
Figure 3-22. VHADDPS operation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-488
Figure 3-23. HSUBPD—Packed Double-FP Horizontal Subtract . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-494
Figure 3-24. VHSUBPD operation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-494
Figure 3-25. HSUBPS—Packed Single-FP Horizontal Subtract . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-497
Figure 3-26. VHSUBPS operation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-497
Figure 3-27. MOVDDUP—Move One Double-FP and Duplicate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-682
Figure 3-28. MOVSHDUP—Move Packed Single-FP High and Duplicate. . . . . . . . . . . . . . . . . . . . .3-737
Figure 3-29. MOVSLDUP—Move Packed Single-FP Low and Duplicate . . . . . . . . . . . . . . . . . . . . .3-740
Figure 4-1. Operation of PCMPSTRx and PCMPESTRx . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-7
Figure 4-2. Operation of the PACKSSDW Instruction Using 64-bit Operands . . . . . . . . . . . . . . . 4-36
Figure 4-3. VPERMILPD operation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-98
Figure 4-4. VPERMILPD Shuffle Control . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-98
Figure 4-5. VPERMILPS Operation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-102
Figure 4-6. VPERMILPS Shuffle Control. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-102
Figure 4-7. VPERM2F128 Operation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-105
Figure 4-8. PMADDWD Execution Model Using 64-bit Operands . . . . . . . . . . . . . . . . . . . . . . . . . .4-135
Figure 4-9. PMULHUW and PMULHW Instruction Operation Using 64-bit Operands. . . . . . . . 4-183
Figure 4-10. PMULLU Instruction Operation Using 64-bit Operands . . . . . . . . . . . . . . . . . . . . . . .4-191
Figure 4-11. PSADBW Instruction Operation Using 64-bit Operands . . . . . . . . . . . . . . . . . . . . . . .4-217
Figure 4-12. PSHUB with 64-Bit Operands . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-221
Figure 4-13. PSHUFD Instruction Operation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-222
Figure 4-14. PSLLW, PSLLD, and PSLLQ Instruction Operation Using 64-bit Operand . . . . . . .4-240
Figure 4-15. PSRAW and PSRAD Instruction Operation Using a 64-bit Operand . . . . . . . . . . . .4-246
Figure 4-16. PSRLW, PSRLD, and PSRLQ Instruction Operation Using 64-bit Operand. . . . . . .4-254
Figure 4-17. PUNPCKHBW Instruction Operation Using 64-bit Operands . . . . . . . . . . . . . . . . . . . 4-275
Figure 4-18. PUNPCKLBW Instruction Operation Using 64-bit Operands . . . . . . . . . . . . . . . . . . .4-281
Figure 4-19. Bit Control Fields of Immediate Byte for ROUNDxx Instruction . . . . . . . . . . . . . . .4-341
Figure 4-20. SHUFPD Shuffle Operation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-394
Figure 4-21. SHUFPS Shuffle Operation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-397
Figure 4-22. UNPCKHPD Instruction High Unpack and Interleave Operation . . . . . . . . . . . . . . . . 4-469
Figure 4-23. UNPCKHPS Instruction High Unpack and Interleave Operation . . . . . . . . . . . . . . . . 4-472
Figure 4-24. UNPCKLPD Instruction Low Unpack and Interleave Operation . . . . . . . . . . . . . . . . 4-475
Figure 4-25. UNPCKLPS Instruction Low Unpack and Interleave Operation. . . . . . . . . . . . . . . . .4-478
Figure 5-1. INVEPT Descriptor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5-4
Figure 5-2. INVVPID Descriptor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5-8
Figure A-1. ModR/M Byte nnn Field (Bits 5, 4, and 3) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-21
Figure B-1. General Machine Instruction Format. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-1

Vol. 2A xix
CONTENTS
PAGE
TABLES
Table 2-1. 16-Bit Addressing Forms with the ModR/M Byte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-6
Table 2-2. 32-Bit Addressing Forms with the ModR/M Byte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-7
Table 2-3. 32-Bit Addressing Forms with the SIB Byte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-8
Table 2-4. REX Prefix Fields [BITS: 0100WRXB] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-11
Table 2-5. Special Cases of REX Encodings . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-13
Table 2-6. Direct Memory Offset Form of MOV . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-14
Table 2-7. RIP-Relative Addressing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-15
Table 2-8. VEX.vvvv to register name mapping . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-22
Table 2-9. Instructions with a VEX.vvvv destination . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-23
Table 2-10. VEX.m-mmmm interpretation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-24
Table 2-11. VEX.L interpretation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-24
Table 2-12. VEX.pp interpretation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-25
Table 2-13. Exception class description . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-26
Table 2-14. Instructions in each Exception Class . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-27
Table 2-15. #UD Exception and VEX.W=1 Encoding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-28
Table 2-16. #UD Exception and VEX.L Field Encoding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-29
Table 2-17. Type 1 Class Exception Conditions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-30
Table 2-18. Type 2 Class Exception Conditions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-31
Table 2-19. Type 3 Class Exception Conditions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-32
Table 2-20. Type 4 Class Exception Conditions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-33
Table 2-21. Type 5 Class Exception Conditions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-34
Table 2-22. Type 6 Class Exception Conditions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-35
Table 2-23. Type 7 Class Exception Conditions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-36
Table 2-24. Type 8 Class Exception Conditions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-37
Table 2-25. Type 9 Class Exception Conditions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-38
Table 3-1. Register Codes Associated With +rb, +rw, +rd, +ro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-3
Table 3-2. Range of Bit Positions Specified by Bit Offset Operands . . . . . . . . . . . . . . . . . . . . . . .3-15
Table 3-3. Intel 64 and IA-32 General Exceptions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-19
Table 3-4. x87 FPU Floating-Point Exceptions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-20
Table 3-5. SIMD Floating-Point Exceptions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-21
Table 3-6. Decision Table for CLI Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-141
Table 3-7. Comparison Predicate for CMPPD and CMPPS Instructions . . . . . . . . . . . . . . . . . . . 3-158
Table 3-8. Pseudo-Op and CMPPD Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-159
Table 3-9. Comparison Predicate for VCMPPD and VCMPPS Instructions . . . . . . . . . . . . . . . . 3-160
Table 3-10. Pseudo-Op and VCMPPD Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-162
Table 3-11. Pseudo-Ops and CMPPS. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-168
Table 3-12. Pseudo-Op and VCMPPS Implementation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-169
Table 3-13. Pseudo-Ops and CMPSD. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-181
Table 3-14. Pseudo-Op and VCMPSD Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-182
Table 3-15. Pseudo-Ops and CMPSS. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-187
Table 3-16. Pseudo-Op and VCMPSS Implementation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-188
Table 3-17. Information Returned by CPUID Instruction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-203
Table 3-18. Highest CPUID Source Operand for Intel 64 and IA-32 Processors . . . . . . . . . . . . 3-212
Table 3-19. Processor Type Field . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-214
Table 3-20. Feature Information Returned in the ECX Register . . . . . . . . . . . . . . . . . . . . . . . . . . 3-216

CONTENTS
xx Vol. 2A
PAGE
Table 3-21. More on Feature Information Returned in the EDX Register . . . . . . . . . . . . . . . . . . 3-220
Table 3-22. Encoding of CPUID Leaf 2 Descriptors . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-223
Table 3-23. Processor Brand String Returned with Pentium 4 Processor. . . . . . . . . . . . . . . . . .3-231
Table 3-24. Mapping of Brand Indices; and
Intel 64 and IA-32 Processor Brand Strings3-233
Table 3-25. DIV Action . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-308
Table 3-26. Results Obtained from F2XM1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-335
Table 3-27. Results Obtained from FABS. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-337
Table 3-28. FADD/FADDP/FIADD Results. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-340
Table 3-29. FBSTP Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-345
Table 3-30. FCHS Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-348
Table 3-31. FCOM/FCOMP/FCOMPP Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-354
Table 3-32. FCOMI/FCOMIP/ FUCOMI/FUCOMIP Results. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-358
Table 3-33. FCOS Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-361
Table 3-34. FDIV/FDIVP/FIDIV Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-366
Table 3-35. FDIVR/FDIVRP/FIDIVR Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-370
Table 3-36. FICOM/FICOMP Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-374
Table 3-37. FIST/FISTP Results. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-383
Table 3-38. FISTTP Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-387
Table 3-39. FMUL/FMULP/FIMUL Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-401
Table 3-40. FPATAN Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-406
Table 3-41. FPREM Results. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-408
Table 3-42. FPREM1 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-411
Table 3-43. FPTAN Results. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-414
Table 3-44. FSCALE Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-426
Table 3-45. FSIN Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-428
Table 3-46. FSINCOS Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-430
Table 3-47. FSQRT Results. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-433
Table 3-48. FSUB/FSUBP/FISUB Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-448
Table 3-49. FSUBR/FSUBRP/FISUBR Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-452
Table 3-50. FTST Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-455
Table 3-51. FUCOM/FUCOMP/FUCOMPP Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-457
Table 3-52. FXAM Results. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-460
Table 3-53. Non-64-bit-Mode Layout of FXSAVE and FXRSTOR
Memory Region3-468
Table 3-54. Field Definitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-470
Table 3-55. Recreating FSAVE Format . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-472
Table 3-56. Layout of the 64-bit-mode FXSAVE64 Map
(requires REX.W = 1)3-473
Table 3-57. Layout of the 64-bit-mode FXSAVE Map (REX.W = 0) . . . . . . . . . . . . . . . . . . . . . . . . 3-474
Table 3-58. FYL2X Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-480
Table 3-59. FYL2XP1 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-482
Table 3-60. IDIV Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3-501
Table 3-61. Decision Table . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-526
Table 3-62. Segment and Gate Types. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-578
Table 3-63. Non-64-bit Mode LEA Operation with Address and Operand Size Attributes . . .3-591
Table 3-64. 64-bit Mode LEA Operation with Address and Operand Size Attributes. . . . . . . .3-592

Vol. 2A xxi
CONTENTS
PAGE
Table 3-65. Segment and Gate Descriptor Types. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-616
Table 3-66. MUL Results. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-762
Table 3-67. MWAIT Extension Register (ECX) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-773
Table 3-68. MWAIT Hints Register (EAX) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-774
Table 4-1. Source Data Format . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-2
Table 4-2. Aggregation Operation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-3
Table 4-3. Aggregation Operation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-3
Table 4-4. Polarity . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-4
Table 4-5. Ouput Selection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-5
Table 4-6. Output Selection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-5
Table 4-7. Comparison Result for Each Element Pair BoolRes[i.j] . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-5
Table 4-8. Summary of Imm8 Control Byte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-6
Table 4-9. Recommended Multi-Byte Sequence of NOP Instruction . . . . . . . . . . . . . . . . . . . . . . .4-12
Table 4-10. PCLMULQDQ Quadword Selection of Immediate Byte . . . . . . . . . . . . . . . . . . . . . . . . . .4-73
Table 4-11. Pseudo-Op and PCLMULQDQ Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-74
Table 4-12. Valid General and Special Purpose Performance Counter Index Range for RDPMC . 4-
314
Table 4-13. Repeat Prefixes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-326
Table 4-14. Rounding Modes and Encoding of Rounding Control (RC) Field . . . . . . . . . . . . . . . . 4-341
Table 4-15. Decision Table for STI Results. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-421
Table 4-16. SWAPGS Operation Parameters . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-444
Table 4-17. MSRs Used By the SYSENTER and SYSEXIT Instructions . . . . . . . . . . . . . . . . . . . . . 4-448
Table 4-18. General Layout of XSAVE/XRSTOR Save Area . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-508
Table 4-19. XSAVE.HEADER Layout . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-508
Table 4-20. Processor Supplied Init Values XRSTOR May Use . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-509
Table 4-21. Reserved Bit Checking and XRSTOR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-509
Table 5-1. VM-Instruction Error Numbers. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .5-34
Table 6-1. Layout of IA32_FEATURE_CONTROL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6-2
Table 6-2. GETSEC Leaf Functions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6-3
Table 6-3. Getsec Capability Result Encoding (EBX = 0) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6-9
Table 6-4. Register State Initialization after GETSEC[ENTERACCS] . . . . . . . . . . . . . . . . . . . . . . . .6-15
Table 6-5. IA32_MISC_ENALBES MSR Initialization by ENTERACCS and SENTER . . . . . . . . . . .6-17
Table 6-6. Register State Initialization after GETSEC[SENTER] and GETSEC[WAKEUP] . . . . .6-31
Table 6-7. SMX Reporting Parameters Format. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .6-43
Table 6-8. TXT Feature Extensions Flags . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .6-44
Table 6-9. External Memory Types Using Parameter 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .6-46
Table 6-10. Default Parameter Values . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .6-46
Table 6-11. Supported Actions for GETSEC[SMCTRL(0)] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .6-50
Table 6-12. RLP MVMM JOIN Data Structure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .6-52
Table A-1. Superscripts Utilized in Opcode Tables. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .A-8
Table A-2. One-byte Opcode Map: (00H — F7H) * . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .A-11
Table A-3. Two-byte Opcode Map: 00H — 77H (First Byte is 0FH) *. . . . . . . . . . . . . . . . . . . . . . .A-13
Table A-4. Three-byte Opcode Map: 00H — F7H (First Two Bytes are 0F 38H) *. . . . . . . . . . .A-17
Table A-5. Three-byte Opcode Map: 00H — F7H (First two bytes are 0F 3AH) * . . . . . . . . . . .A-19
Table A-6. Opcode Extensions for One- and Two-byte Opcodes by Group Number * . . . . . . .A-22
Table A-7. D8 Opcode Map When ModR/M Byte is Within 00H to BFH * . . . . . . . . . . . . . . . . . . .A-25
Table A-8. D8 Opcode Map When ModR/M Byte is Outside 00H to BFH * . . . . . . . . . . . . . . . . . .A-25

CONTENTS
xxii Vol. 2A
PAGE
Table A-9. D9 Opcode Map When ModR/M Byte is Within 00H to BFH * . . . . . . . . . . . . . . . . . . . A-26
Table A-10. D9 Opcode Map When ModR/M Byte is Outside 00H to BFH *. . . . . . . . . . . . . . . . . . A-26
Table A-11. DA Opcode Map When ModR/M Byte is Within 00H to BFH * . . . . . . . . . . . . . . . . . . . A-27
Table A-12. DA Opcode Map When ModR/M Byte is Outside 00H to BFH *. . . . . . . . . . . . . . . . . . A-27
Table A-13. DB Opcode Map When ModR/M Byte is Within 00H to BFH * . . . . . . . . . . . . . . . . . . . A-28
Table A-14. DB Opcode Map When ModR/M Byte is Outside 00H to BFH *. . . . . . . . . . . . . . . . . . A-28
Table A-15. DC Opcode Map When ModR/M Byte is Within 00H to BFH * . . . . . . . . . . . . . . . . . . . A-29
Table A-16. DC Opcode Map When ModR/M Byte is Outside 00H to BFH *. . . . . . . . . . . . . . . . . . A-29
Table A-17. DD Opcode Map When ModR/M Byte is Within 00H to BFH * . . . . . . . . . . . . . . . . . . . A-30
Table A-18. DD Opcode Map When ModR/M Byte is Outside 00H to BFH *. . . . . . . . . . . . . . . . . . A-30
Table A-19. DE Opcode Map When ModR/M Byte is Within 00H to BFH * . . . . . . . . . . . . . . . . . . . A-31
Table A-20. DE Opcode Map When ModR/M Byte is Outside 00H to BFH *. . . . . . . . . . . . . . . . . . A-31
Table A-21. DF Opcode Map When ModR/M Byte is Within 00H to BFH * . . . . . . . . . . . . . . . . . . . A-32
Table A-22. DF Opcode Map When ModR/M Byte is Outside 00H to BFH *. . . . . . . . . . . . . . . . . . A-32
Table B-1. Special Fields Within Instruction Encodings . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-3
Table B-2. Encoding of reg Field When w Field is Not Present in Instruction. . . . . . . . . . . . . . . . B-3
Table B-4. Encoding of reg Field When w Field is Not Present in Instruction. . . . . . . . . . . . . . . . B-4
Table B-3. Encoding of reg Field When w Field is Present in Instruction. . . . . . . . . . . . . . . . . . . . B-4
Table B-5. Encoding of reg Field When w Field is Present in Instruction. . . . . . . . . . . . . . . . . . . . B-5
Table B-6. Encoding of Operand Size (w) Bit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-5
Table B-7. Encoding of Sign-Extend (s) Bit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-6
Table B-8. Encoding of the Segment Register (sreg) Field. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-6
Table B-9. Encoding of Special-Purpose Register (eee) Field . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-7
Table B-11. Encoding of Operation Direction (d) Bit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-8
Table B-10. Encoding of Conditional Test (tttn) Field. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-8
Table B-12. Notes on Instruction Encoding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-9
Table B-13. General Purpose Instruction Formats and Encodings
for Non-64-Bit ModesB-9
Table B-14. Special Symbols. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-24
Table B-15. General Purpose Instruction Formats and Encodings
for 64-Bit ModeB-24
Table B-16. Pentium Processor Family Instruction Formats and Encodings,
Non-64-Bit ModesB-53
Table B-17. Pentium Processor Family Instruction Formats and Encodings, 64-Bit Mode . . . . B-54
Table B-18. Encoding of Granularity of Data Field (gg) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-55
Table B-19. MMX Instruction Formats and Encodings . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-55
Table B-20. Formats and Encodings of XSAVE/XRSTOR/XGETBV/XSETBV Instructions . . . . . B-59
Table B-21. Formats and Encodings of P6 Family Instructions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-59
Table B-22. Formats and Encodings of SSE Floating-Point Instructions. . . . . . . . . . . . . . . . . . . . . B-61
Table B-23. Formats and Encodings of SSE Integer Instructions . . . . . . . . . . . . . . . . . . . . . . . . . . . B-67
Table B-24. Format and Encoding of SSE Cacheability & Memory Ordering Instructions . . . . . B-68
Table B-25. Encoding of Granularity of Data Field (gg) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-69
Table B-26. Formats and Encodings of SSE2 Floating-Point Instructions . . . . . . . . . . . . . . . . . . . B-70
Table B-27. Formats and Encodings of SSE2 Integer Instructions . . . . . . . . . . . . . . . . . . . . . . . . . B-78
Table B-28. Format and Encoding of SSE2 Cacheability Instructions . . . . . . . . . . . . . . . . . . . . . . . B-85
Table B-29. Formats and Encodings of SSE3 Floating-Point Instructions . . . . . . . . . . . . . . . . . . . B-86
Table B-30. Formats and Encodings for SSE3 Event Management Instructions . . . . . . . . . . . . . B-87

Vol. 2A xxiii
CONTENTS
PAGE
Table B-31. Formats and Encodings for SSE3 Integer and Move Instructions. . . . . . . . . . . . . . . .B-87
Table B-32. Formats and Encodings for SSSE3 Instructions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .B-88
Table B-33. Formats and Encodings of AESNI and PCLMULQDQ Instructions . . . . . . . . . . . . . . . .B-92
Table B-34. Special Case Instructions Promoted Using REX.W. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .B-94
Table B-35. Encodings of SSE4.1 instructions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .B-98
Table B-36. Encodings of SSE4.2 instructions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-106
Table B-37. General Floating-Point Instruction Formats . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-107
Table B-38. Floating-Point Instruction Formats and Encodings . . . . . . . . . . . . . . . . . . . . . . . . . . . B-108
Table B-39. Encodings for VMX Instructions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-114
Table B-40. Encodings for SMX Instructions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-116
Table C-1. Simple Intrinsics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . C-3
Table C-2. Composite Intrinsics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .C-17

CONTENTS
xxiv Vol. 2A
PAGE

Vol. 2A 1-1
CHAPTER 1
ABOUT THIS MANUAL
The Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volumes
2A & 2B: Instruction Set Reference (order numbers 253666 and 253667) are part of
a set that describes the architecture and programming environment of all Intel 64
and IA-32 architecture processors. Other volumes in this set are:
•The Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 1:
Basic Architecture (Order Number 253665).
•The Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volumes
3A & 3B: System Programming Guide (order numbers 253668 and 253669).
The Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 1,
describes the basic architecture and programming environment of Intel 64 and IA-32
processors. The Intel® 64 and IA-32 Architectures Software Developer’s Manual,
Volumes 2A & 2B, describe the instruction set of the processor and the opcode struc-
ture. These volumes apply to application programmers and to programmers who
write operating systems or executives. The Intel® 64 and IA-32 Architectures Soft-
ware Developer’s Manual, Volumes 3A & 3B, describe the operating-system support
environment of Intel 64 and IA-32 processors. These volumes target operating-
system and BIOS designers. In addition, the Intel® 64 and IA-32 Architectures Soft-
ware Developer’s Manual, Volume 3B, addresses the programming environment for
classes of software that host operating systems.
1.1 IA-32 PROCESSORS COVERED IN THIS MANUAL
This manual set includes information pertaining primarily to the most recent Intel 64
and IA-32 processors, which include:
•Pentium® processors
•P6 family processors
•Pentium® 4 processors
•Pentium® M processors
•Intel® Xeon® processors
•Pentium® D processors
•Pentium® processor Extreme Editions
•64-bit Intel® Xeon® processors
•Intel® Core™ Duo processor
•Intel® Core™ Solo processor
•Dual-Core Intel® Xeon® processor LV

1-2 Vol. 2A
ABOUT THIS MANUAL
•Intel® Core™2 Duo processor
•Intel® Core™2 Quad processor Q6000 series
•Intel® Xeon® processor 3000, 3200 series
•Intel® Xeon® processor 5000 series
•Intel® Xeon® processor 5100, 5300 series
•Intel® Core™2 Extreme processor X7000 and X6800 series
•Intel® Core™2 Extreme QX6000 series
•Intel® Xeon® processor 7100 series
•Intel® Pentium® Dual-Core processor
•Intel® Xeon® processor 7200, 7300 series
•Intel® Xeon® processor 5200, 5400, 7400 series
•Intel® CoreTM2 Extreme processor QX9000 and X9000 series
•Intel® CoreTM2 Quad processor Q9000 series
•Intel® CoreTM2 Duo processor E8000, T9000 series
•Intel® AtomTM processor family
•Intel® CoreTM i7 processor
•Intel® CoreTM i5 processor
P6 family processors are IA-32 processors based on the P6 family microarchitecture.
This includes the Pentium® Pro, Pentium® II, Pentium® III, and Pentium® III Xeon®
processors.
The Pentium® 4, Pentium® D, and Pentium® processor Extreme Editions are based
on the Intel NetBurst® microarchitecture. Most early Intel® Xeon® processors are
based on the Intel NetBurst® microarchitecture. Intel Xeon processor 5000, 7100
series are based on the Intel NetBurst® microarchitecture.
The Intel® Core™ Duo, Intel® Core™ Solo and dual-core Intel® Xeon® processor LV
are based on an improved Pentium® M processor microarchitecture.
The Intel® Xeon® processor 3000, 3200, 5100, 5300, 7200, and 7300 series, Intel®
Pentium® dual-core, Intel® Core™2 Duo, Intel® Core™2 Quad, and Intel® Core™2
Extreme processors are based on Intel® Core™ microarchitecture.
The Intel® Xeon® processor 5200, 5400, 7400 series, Intel® CoreTM2 Quad processor
Q9000 series, and Intel® CoreTM2 Extreme processors QX9000, X9000 series, Intel®
CoreTM2 processor E8000 series are based on Enhanced Intel® CoreTM microarchitec-
ture.
The Intel® AtomTM processor family is based on the Intel® AtomTM microarchitecture
and supports Intel 64 architecture.
The Intel® CoreTM i7 processor and the Intel® CoreTM i5 processor are based on the
Intel® microarchitecture code name Nehalem and support Intel 64 architecture.

Vol. 2A 1-3
ABOUT THIS MANUAL
Processors based on Intel® microarchitecture code name Westmere support Intel 64
architecture.
P6 family, Pentium® M, Intel® Core™ Solo, Intel® Core™ Duo processors, dual-core
Intel® Xeon® processor LV, and early generations of Pentium 4 and Intel Xeon
processors support IA-32 architecture. The Intel® AtomTM processor Z5xx series
support IA-32 architecture.
The Intel® Xeon® processor 3000, 3200, 5000, 5100, 5200, 5300, 5400, 7100,
7200, 7300, 7400 series, Intel® Core™2 Duo, Intel® Core™2 Extreme, Intel®
Core™2 Quad processors, Pentium® D processors, Pentium® Dual-Core processor,
newer generations of Pentium 4 and Intel Xeon processor family support Intel® 64
architecture.
IA-32 architecture is the instruction set architecture and programming environment
for Intel's 32-bit microprocessors.
Intel® 64 architecture is the instruction set architecture and programming environ-
ment which is the superset of Intel’s 32-bit and 64-bit architectures. It is compatible
with the IA-32 architecture.
1.2 OVERVIEW OF VOLUME 2A AND 2B: INSTRUCTION
SET REFERENCE
A description of Intel® 64 and IA-32 Architectures Software Developer’s Manual,
Volumes 2A & 2B, content follows:
Chapter 1 — About This Manual. Gives an overview of all five volumes of the
Intel® 64 and IA-32 Architectures Software Developer’s Manual. It also describes
the notational conventions in these manuals and lists related Intel® manuals and
documentation of interest to programmers and hardware designers.
Chapter 2 — Instruction Format. Describes the machine-level instruction format
used for all IA-32 instructions and gives the allowable encodings of prefixes, the
operand-identifier byte (ModR/M byte), the addressing-mode specifier byte (SIB
byte), and the displacement and immediate bytes.
Chapter 3 — Instruction Set Reference, A-M. Describes Intel 64 and IA-32
instructions in detail, including an algorithmic description of operations, the effect on
flags, the effect of operand- and address-size attributes, and the exceptions that
may be generated. The instructions are arranged in alphabetical order. General-
purpose, x87 FPU, Intel MMX™ technology, SSE/SSE2/SSE3/SSSE3/SSE4 exten-
sions, and system instructions are included.
Chapter 4 — Instruction Set Reference, N-Z. Continues the description of Intel
64 and IA-32 instructions started in Chapter 3. It provides the balance of the alpha-
betized list of instructions and starts Intel® 64 and IA-32 Architectures Software
Developer’s Manual, Volume 2B.

1-4 Vol. 2A
ABOUT THIS MANUAL
Chapter 5 — VMX Instruction Reference. Describes the virtual-machine exten-
sions (VMX). VMX is intended for a system executive to support virtualization of
processor hardware and a system software layer acting as a host to multiple guest
software environments.
Chapter 6— Safer Mode Extensions Reference. Describes the safer mode exten-
sions (SMX). SMX is intended for a system executive to support launching a
measured environment in a platform where the identity of the software controlling
the platform hardware can be measured for the purpose of making trust decisions.
Appendix A — Opcode Map. Gives an opcode map for the IA-32 instruction set.
Appendix B — Instruction Formats and Encodings. Gives the binary encoding of
each form of each IA-32 instruction.
Appendix C — Intel® C/C++ Compiler Intrinsics and Functional Equivalents.
Lists the Intel® C/C++ compiler intrinsics and their assembly code equivalents for
each of the IA-32 MMX and SSE/SSE2/SSE3 instructions.
1.3 NOTATIONAL CONVENTIONS
This manual uses specific notation for data-structure formats, for symbolic represen-
tation of instructions, and for hexadecimal and binary numbers. A review of this
notation makes the manual easier to read.
1.3.1 Bit and Byte Order
In illustrations of data structures in memory, smaller addresses appear toward the
bottom of the figure; addresses increase toward the top. Bit positions are numbered
from right to left. The numerical value of a set bit is equal to two raised to the power
of the bit position. IA-32 processors are “little endian” machines; this means the
bytes of a word are numbered starting from the least significant byte. Figure 1-1
illustrates these conventions.
Vol. 2A 1-5
ABOUT THIS MANUAL
1.3.2 Reserved Bits and Software Compatibility
In many register and memory layout descriptions, certain bits are marked as
reserved. When bits are marked as reserved, it is essential for compatibility with
future processors that software treat these bits as having a future, though unknown,
effect. The behavior of reserved bits should be regarded as not only undefined, but
unpredictable. Software should follow these guidelines in dealing with reserved bits:
•Do not depend on the states of any reserved bits when testing the values of
registers which contain such bits. Mask out the reserved bits before testing.
•Do not depend on the states of any reserved bits when storing to memory or to a
register.
•Do not depend on the ability to retain information written into any reserved bits.
•When loading a register, always load the reserved bits with the values indicated
in the documentation, if any, or reload them with values previously read from the
same register.
NOTE
Avoid any software dependence upon the state of reserved bits in
IA-32 registers. Depending upon the values of reserved register bits
will make software dependent upon the unspecified manner in which
the processor handles these bits. Programs that depend upon
reserved values risk incompatibility with future processors.
Figure 1-1. Bit and Byte Order
Byte 3
Data Structure
Byte 1
Byte 2 Byte 0
31 24 23 16 15 870
Lowest
Bit offset
28
24
20
16
12
8
4
0Address
Byte Offset
Highest
Address

1-6 Vol. 2A
ABOUT THIS MANUAL
1.3.3 Instruction Operands
When instructions are represented symbolically, a subset of the IA-32 assembly
language is used. In this subset, an instruction has the following format:
label: mnemonic argument1, argument2, argument3
where:
•A label is an identifier which is followed by a colon.
•A mnemonic is a reserved name for a class of instruction opcodes which have
the same function.
•The operands argument1, argument2, and argument3 are optional. There may
be from zero to three operands, depending on the opcode. When present, they
take the form of either literals or identifiers for data items. Operand identifiers
are either reserved names of registers or are assumed to be assigned to data
items declared in another part of the program (which may not be shown in the
example).
When two operands are present in an arithmetic or logical instruction, the right
operand is the source and the left operand is the destination.
For example:
LOADREG: MOV EAX, SUBTOTAL
In this example, LOADREG is a label, MOV is the mnemonic identifier of an opcode,
EAX is the destination operand, and SUBTOTAL is the source operand. Some
assembly languages put the source and destination in reverse order.
1.3.4 Hexadecimal and Binary Numbers
Base 16 (hexadecimal) numbers are represented by a string of hexadecimal digits
followed by the character H (for example, F82EH). A hexadecimal digit is a character
from the following set: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, and F.
Base 2 (binary) numbers are represented by a string of 1s and 0s, sometimes
followed by the character B (for example, 1010B). The “B” designation is only used in
situations where confusion as to the type of number might arise.
1.3.5 Segmented Addressing
The processor uses byte addressing. This means memory is organized and accessed
as a sequence of bytes. Whether one or more bytes are being accessed, a byte
address is used to locate the byte or bytes in memory. The range of memory that can
be addressed is called an address space.
The processor also supports segmented addressing. This is a form of addressing
where a program may have many independent address spaces, called segments.

Vol. 2A 1-7
ABOUT THIS MANUAL
For example, a program can keep its code (instructions) and stack in separate
segments. Code addresses would always refer to the code space, and stack
addresses would always refer to the stack space. The following notation is used to
specify a byte address within a segment:
Segment-register:Byte-address
For example, the following segment address identifies the byte at address FF79H in
the segment pointed by the DS register:
DS:FF79H
The following segment address identifies an instruction address in the code segment.
The CS register points to the code segment and the EIP register contains the address
of the instruction.
CS:EIP
1.3.6 Exceptions
An exception is an event that typically occurs when an instruction causes an error.
For example, an attempt to divide by zero generates an exception. However, some
exceptions, such as breakpoints, occur under other conditions. Some types of excep-
tions may provide error codes. An error code reports additional information about the
error. An example of the notation used to show an exception and error code is shown
below:
#PF(fault code)
This example refers to a page-fault exception under conditions where an error code
naming a type of fault is reported. Under some conditions, exceptions which produce
error codes may not be able to report an accurate code. In this case, the error code
is zero, as shown below for a general-protection exception:
#GP(0)
1.3.7 A New Syntax for CPUID, CR, and MSR Values
Obtain feature flags, status, and system information by using the CPUID instruction,
by checking control register bits, and by reading model-specific registers. We are
moving toward a new syntax to represent this information. See Figure 1-2.
1-8 Vol. 2A
ABOUT THIS MANUAL
1.4 RELATED LITERATURE
Literature related to Intel 64 and IA-32 processors is listed on-line at:
http://developer.intel.com/products/processor/manuals/index.htm
Some of the documents listed at this web site can be viewed on-line; others can be
ordered. The literature available is listed by Intel processor and then by the following
Figure 1-2. Syntax for CPUID, CR, and MSR Data Presentation
&RQWURO5HJLVWHU9DOXHV
0RGHO6SHFLILF5HJLVWHU9DOXHV
&38,'+(&;66(>ELW@
9DOXHRUUDQJHRIRXWSXW
&38,',QSXWDQG2XWSXW
2XWSXWUHJLVWHUDQGIHDWXUHIODJRUILHOG
QDPHZLWKELWSRVLWLRQV
&526);65>ELW@
)HDWXUHIODJRUILHOGQDPH
ZLWKELWSRVLWLRQV
9DOXHRUUDQJHRIRXWSXW
([DPSOH&5QDPH
)HDWXUHIODJRUILHOGQDPHZLWKELWSRVLWLRQV
,$B0,6&B(1$%/(6(1$%/()23&2'(>ELW@
9DOXHRUUDQJHRIRXWSXW
([DPSOH065QDPH
20
6RPHLQSXWVUHTXLUHYDOXHVLQ($;DQG(&;
7KLVLVUHSUHVHQWHGDV&38,'($; Q(&; Q
,IRQO\RQHYDOXHLVSUHVHQW($;LVLPSOLHG

Vol. 2A 1-9
ABOUT THIS MANUAL
literature types: applications notes, data sheets, manuals, papers, and specification
updates.
See also:
•The data sheet for a particular Intel 64 or IA-32 processor
•The specification update for a particular Intel 64 or IA-32 processor
•Intel® C++ Compiler documentation and online help
http://www.intel.com/cd/software/products/asmo-na/eng/index.htm
•Intel® Fortran Compiler documentation and online help
http://www.intel.com/cd/software/products/asmo-na/eng/index.htm
•Intel® VTune™ Performance Analyzer documentation and online help
http://www.intel.com/cd/software/products/asmo-na/eng/index.htm
•Intel® 64 and IA-32 Architectures Software Developer’s Manual (in five volumes)
http://developer.intel.com/products/processor/manuals/index.htm
•Intel® 64 and IA-32 Architectures Optimization Reference Manual
http://developer.intel.com/products/processor/manuals/index.htm
•Intel® Processor Identification with the CPUID Instruction, AP-485
http://www.intel.com/support/processors/sb/cs-009861.htm
•Intel 64 Architecture x2APIC Specification:
http://developer.intel.com/products/processor/manuals/index.htm
•Intel 64 Architecture Processor Topology Enumeration:
http://softwarecommunity.intel.com/articles/eng/3887.htm
•Intel® Trusted Execution Technology Measured Launched Environment
Programming Guide, http://www.intel.com/technology/security/index.htm
•Intel® SSE4 Programming Reference,
http://developer.intel.com/products/processor/manuals/index.htm
•Developing Multi-threaded Applications: A Platform Consistent Approach
http://cache-
www.intel.com/cd/00/00/05/15/51534_developing_multithreaded_applications.pdf
•Using Spin-Loops on Intel Pentium 4 Processor and Intel Xeon Processor MP
http://www3.intel.com/cd/ids/developer/asmo-
na/eng/dc/threading/knowledgebase/19083.htm
More relevant links are:
•Software network link:
http://softwarecommunity.intel.com/isn/home/
•Developer centers:
http://www.intel.com/cd/ids/developer/asmo-na/eng/dc/index.htm
•Processor support general link:
http://www.intel.com/support/processors/

1-10 Vol. 2A
ABOUT THIS MANUAL
•Software products and packages:
http://www.intel.com/cd/software/products/asmo-na/eng/index.htm
•Intel 64 and IA-32 processor manuals (printed or PDF downloads):
http://developer.intel.com/products/processor/manuals/index.htm
•Intel® Multi-Core Technology:
http://developer.intel.com/multi-core/index.htm
•Intel® Hyper-Threading Technology (Intel® HT Technology):
http://developer.intel.com/technology/hyperthread/
Vol. 2A 2-1
CHAPTER 2
INSTRUCTION FORMAT
This chapter describes the instruction format for all Intel 64 and IA-32 processors.
The instruction format for protected mode, real-address mode and virtual-8086
mode is described in Section 2.1. Increments provided for IA-32e mode and its sub-
modes are described in Section 2.2.
2.1 INSTRUCTION FORMAT FOR PROTECTED MODE,
REAL-ADDRESS MODE, AND VIRTUAL-8086 MODE
The Intel 64 and IA-32 architectures instruction encodings are subsets of the format
shown in Figure 2-1. Instructions consist of optional instruction prefixes (in any
order), primary opcode bytes (up to three bytes), an addressing-form specifier (if
required) consisting of the ModR/M byte and sometimes the SIB (Scale-Index-Base)
byte, a displacement (if required), and an immediate data field (if required).
2.1.1 Instruction Prefixes
Instruction prefixes are divided into four groups, each with a set of allowable prefix
codes. For each instruction, it is only useful to include up to one prefix code from
each of the four groups (Groups 1, 2, 3, 4). Groups 1 through 4 may be placed in any
order relative to each other.
•Group 1
— Lock and repeat prefixes:
Figure 2-1. Intel 64 and IA-32 Architectures Instruction Format
Instruction
Prefixes Opcode ModR/M SIB Displacement Immediate
Mod R/M
Reg/
Opcode
0
2
765 3
Scale Base
0
27 65 3
Index
Immediate
data of
1, 2, or 4
bytes or none
Address
displacement
of 1, 2, or 4
bytes or none
1 byte
(if required)
1 byte
(if required)
1-, 2-, or 3-byte
opcode
Up to four
prefixes of
1 byte each
(optional)

2-2 Vol. 2A
INSTRUCTION FORMAT
•LOCK prefix is encoded using F0H
•REPNE/REPNZ prefix is encoded using F2H. Repeat-Not-Zero prefix
applies only to string and input/output instructions. (F2H is also used as a
mandatory prefix for some instructions)
•REP or REPE/REPZ is encoded using F3H. Repeat prefix applies only to
string and input/output instructions.(F3H is also used as a mandatory
prefix for some instructions)
•Group 2
— Segment override prefixes:
•2EH—CS segment override (use with any branch instruction is reserved)
•36H—SS segment override prefix (use with any branch instruction is
reserved)
•3EH—DS segment override prefix (use with any branch instruction is
reserved)
•26H—ES segment override prefix (use with any branch instruction is
reserved)
•64H—FS segment override prefix (use with any branch instruction is
reserved)
•65H—GS segment override prefix (use with any branch instruction is
reserved)
— Branch hints:
•2EH—Branch not taken (used only with Jcc instructions)
•3EH—Branch taken (used only with Jcc instructions)
•Group 3
•Operand-size override prefix is encoded using 66H (66H is also used as a
mandatory prefix for some instructions).
•Group 4
•67H—Address-size override prefix
The LOCK prefix (F0H) forces an operation that ensures exclusive use of shared
memory in a multiprocessor environment. See “LOCK—Assert LOCK# Signal Prefix”
in Chapter 3, “Instruction Set Reference, A-M,” for a description of this prefix.
Repeat prefixes (F2H, F3H) cause an instruction to be repeated for each element of a
string. Use these prefixes only with string and I/O instructions (MOVS, CMPS, SCAS,
LODS, STOS, INS, and OUTS). Use of repeat prefixes and/or undefined opcodes with
other Intel 64 or IA-32 instructions is reserved; such use may cause unpredictable
behavior.
Some instructions may use F2H,F3H as a mandatory prefix to express distinct func-
tionality. A mandatory prefix generally should be placed after other optional prefixes
(exception to this is discussed in Section 2.2.1, “REX Prefixes”)

Vol. 2A 2-3
INSTRUCTION FORMAT
Branch hint prefixes (2EH, 3EH) allow a program to give a hint to the processor about
the most likely code path for a branch. Use these prefixes only with conditional
branch instructions (Jcc). Other use of branch hint prefixes and/or other undefined
opcodes with Intel 64 or IA-32 instructions is reserved; such use may cause unpre-
dictable behavior.
The operand-size override prefix allows a program to switch between 16- and 32-bit
operand sizes. Either size can be the default; use of the prefix selects the non-default
size.
Some SSE2/SSE3/SSSE3/SSE4 instructions and instructions using a three-byte
sequence of primary opcode bytes may use 66H as a mandatory prefix to express
distinct functionality. A mandatory prefix generally should be placed after other
optional prefixes (exception to this is discussed in Section 2.2.1, “REX Prefixes”)
Other use of the 66H prefix is reserved; such use may cause unpredictable behavior.
The address-size override prefix (67H) allows programs to switch between 16- and
32-bit addressing. Either size can be the default; the prefix selects the non-default
size. Using this prefix and/or other undefined opcodes when operands for the instruc-
tion do not reside in memory is reserved; such use may cause unpredictable
behavior.
2.1.2 Opcodes
A primary opcode can be 1, 2, or 3 bytes in length. An additional 3-bit opcode field is
sometimes encoded in the ModR/M byte. Smaller fields can be defined within the
primary opcode. Such fields define the direction of operation, size of displacements,
register encoding, condition codes, or sign extension. Encoding fields used by an
opcode vary depending on the class of operation.
Two-byte opcode formats for general-purpose and SIMD instructions consist of:
•An escape opcode byte 0FH as the primary opcode and a second opcode byte, or
•A mandatory prefix (66H, F2H, or F3H), an escape opcode byte, and a second
opcode byte (same as previous bullet)
For example, CVTDQ2PD consists of the following sequence: F3 0F E6. The first byte
is a mandatory prefix (it is not considered as a repeat prefix).
Three-byte opcode formats for general-purpose and SIMD instructions consist of:
•An escape opcode byte 0FH as the primary opcode, plus two additional opcode
bytes, or
•A mandatory prefix (66H, F2H, or F3H), an escape opcode byte, plus two
additional opcode bytes (same as previous bullet)
For example, PHADDW for XMM registers consists of the following sequence: 66 0F
38 01. The first byte is the mandatory prefix.
Valid opcode expressions are defined in Appendix A and Appendix B.

2-4 Vol. 2A
INSTRUCTION FORMAT
2.1.3 ModR/M and SIB Bytes
Many instructions that refer to an operand in memory have an addressing-form spec-
ifier byte (called the ModR/M byte) following the primary opcode. The ModR/M byte
contains three fields of information:
•The mod field combines with the r/m field to form 32 possible values: eight
registers and 24 addressing modes.
•The reg/opcode field specifies either a register number or three more bits of
opcode information. The purpose of the reg/opcode field is specified in the
primary opcode.
•The r/m field can specify a register as an operand or it can be combined with the
mod field to encode an addressing mode. Sometimes, certain combinations of
the mod field and the r/m field is used to express opcode information for some
instructions.
Certain encodings of the ModR/M byte require a second addressing byte (the SIB
byte). The base-plus-index and scale-plus-index forms of 32-bit addressing require
the SIB byte. The SIB byte includes the following fields:
•The scale field specifies the scale factor.
•The index field specifies the register number of the index register.
•The base field specifies the register number of the base register.
See Section 2.1.5 for the encodings of the ModR/M and SIB bytes.
2.1.4 Displacement and Immediate Bytes
Some addressing forms include a displacement immediately following the ModR/M
byte (or the SIB byte if one is present). If a displacement is required; it be 1, 2, or 4
bytes.
If an instruction specifies an immediate operand, the operand always follows any
displacement bytes. An immediate operand can be 1, 2 or 4 bytes.
2.1.5 Addressing-Mode Encoding of ModR/M and SIB Bytes
The values and corresponding addressing forms of the ModR/M and SIB bytes are
shown in Table 2-1 through Table 2-3: 16-bit addressing forms specified by the
ModR/M byte are in Table 2-1 and 32-bit addressing forms are in Table 2-2. Table 2-3
shows 32-bit addressing forms specified by the SIB byte. In cases where the
reg/opcode field in the ModR/M byte represents an extended opcode, valid encodings
are shown in Appendix B.
In Table 2-1 and Table 2-2, the Effective Address column lists 32 effective addresses
that can be assigned to the first operand of an instruction by using the Mod and R/M
fields of the ModR/M byte. The first 24 options provide ways of specifying a memory

Vol. 2A 2-5
INSTRUCTION FORMAT
location; the last eight (Mod = 11B) provide ways of specifying general-purpose,
MMX technology and XMM registers.
The Mod and R/M columns in Table 2-1 and Table 2-2 give the binary encodings of the
Mod and R/M fields required to obtain the effective address listed in the first column.
For example: see the row indicated by Mod = 11B, R/M = 000B. The row identifies
the general-purpose registers EAX, AX or AL; MMX technology register MM0; or XMM
register XMM0. The register used is determined by the opcode byte and the operand-
size attribute.
Now look at the seventh row in either table (labeled “REG =”). This row specifies the
use of the 3-bit Reg/Opcode field when the field is used to give the location of a
second operand. The second operand must be a general-purpose, MMX technology,
or XMM register. Rows one through five list the registers that may correspond to the
value in the table. Again, the register used is determined by the opcode byte along
with the operand-size attribute.
If the instruction does not require a second operand, then the Reg/Opcode field may
be used as an opcode extension. This use is represented by the sixth row in the
tables (labeled “/digit (Opcode)”). Note that values in row six are represented in
decimal form.
The body of Table 2-1 and Table 2-2 (under the label “Value of ModR/M Byte (in Hexa-
decimal)”) contains a 32 by 8 array that presents all of 256 values of the ModR/M
byte (in hexadecimal). Bits 3, 4 and 5 are specified by the column of the table in
which a byte resides. The row specifies bits 0, 1 and 2; and bits 6 and 7. The figure
below demonstrates interpretation of one table value.
Figure 2-2. Table Interpretation of ModR/M Byte (C8H)
Mod 11
RM 000
REG = 001
C8H 11001000
/digit (Opcode);

2-6 Vol. 2A
INSTRUCTION FORMAT
NOTES:
1. The default segment register is SS for the effective addresses containing a BP index, DS for other
effective addresses.
2. The disp16 nomenclature denotes a 16-bit displacement that follows the ModR/M byte and that is
added to the index.
3. The disp8 nomenclature denotes an 8-bit displacement that follows the ModR/M byte and that is
sign-extended and added to the index.
Table 2-1. 16-Bit Addressing Forms with the ModR/M Byte
r8(/r)
r16(/r)
r32(/r)
mm(/r)
xmm(/r)
(In decimal) /digit (Opcode)
(In binary) REG =
AL
AX
EAX
MM0
XMM0
0
000
CL
CX
ECX
MM1
XMM1
1
001
DL
DX
EDX
MM2
XMM2
2
010
BL
BX
EBX
MM3
XMM3
3
011
AH
SP
ESP
MM4
XMM4
4
100
CH
BP1
EBP
MM5
XMM5
5
101
DH
SI
ESI
MM6
XMM6
6
110
BH
DI
EDI
MM7
XMM7
7
111
Effective Address Mod R/M Value of ModR/M Byte (in Hexadecimal)
[BX+SI]
[BX+DI]
[BP+SI]
[BP+DI]
[SI]
[DI]
disp162
[BX]
00 000
001
010
011
100
101
110
111
00
01
02
03
04
05
06
07
08
09
0A
0B
0C
0D
0E
0F
10
11
12
13
14
15
16
17
18
19
1A
1B
1C
1D
1E
1F
20
21
22
23
24
25
26
27
28
29
2A
2B
2C
2D
2E
2F
30
31
32
33
34
35
36
37
38
39
3A
3B
3C
3D
3E
3F
[BX+SI]+disp83
[BX+DI]+disp8
[BP+SI]+disp8
[BP+DI]+disp8
[SI]+disp8
[DI]+disp8
[BP]+disp8
[BX]+disp8
01 000
001
010
011
100
101
110
111
40
41
42
43
44
45
46
47
48
49
4A
4B
4C
4D
4E
4F
50
51
52
53
54
55
56
57
58
59
5A
5B
5C
5D
5E
5F
60
61
62
63
64
65
66
67
68
69
6A
6B
6C
6D
6E
6F
70
71
72
73
74
75
76
77
78
79
7A
7B
7C
7D
7E
7F
[BX+SI]+disp16
[BX+DI]+disp16
[BP+SI]+disp16
[BP+DI]+disp16
[SI]+disp16
[DI]+disp16
[BP]+disp16
[BX]+disp16
10 000
001
010
011
100
101
110
111
80
81
82
83
84
85
86
87
88
89
8A
8B
8C
8D
8E
8F
90
91
92
93
94
95
96
97
98
99
9A
9B
9C
9D
9E
9F
A0
A1
A2
A3
A4
A5
A6
A7
A8
A9
AA
AB
AC
AD
AE
AF
B0
B1
B2
B3
B4
B5
B6
B7
B8
B9
BA
BB
BC
BD
BE
BF
EAX/AX/AL/MM0/XMM0
ECX/CX/CL/MM1/XMM1
EDX/DX/DL/MM2/XMM2
EBX/BX/BL/MM3/XMM3
ESP/SP/AHMM4/XMM4
EBP/BP/CH/MM5/XMM5
ESI/SI/DH/MM6/XMM6
EDI/DI/BH/MM7/XMM7
11 000
001
010
011
100
101
110
111
C0
C1
C2
C3
C4
C5
C6
C7
C8
C9
CA
CB
CC
CD
CE
CF
D0
D1
D2
D3
D4
D5
D6
D7
D8
D9
DA
DB
DC
DD
DE
DF
E0
EQ
E2
E3
E4
E5
E6
E7
E8
E9
EA
EB
EC
ED
EE
EF
F0
F1
F2
F3
F4
F5
F6
F7
F8
F9
FA
FB
FC
FD
FE
FF
Vol. 2A 2-7
INSTRUCTION FORMAT
NOTES:
1. The [--][--] nomenclature means a SIB follows the ModR/M byte.
2. The disp32 nomenclature denotes a 32-bit displacement that follows the ModR/M byte (or the SIB
byte if one is present) and that is added to the index.
3. The disp8 nomenclature denotes an 8-bit displacement that follows the ModR/M byte (or the SIB
byte if one is present) and that is sign-extended and added to the index.
Table 2-3 is organized to give 256 possible values of the SIB byte (in hexadecimal).
General purpose registers used as a base are indicated across the top of the table,
along with corresponding values for the SIB byte’s base field. Table rows in the body
Table 2-2. 32-Bit Addressing Forms with the ModR/M Byte
r8(/r)
r16(/r)
r32(/r)
mm(/r)
xmm(/r)
(In decimal) /digit (Opcode)
(In binary) REG =
AL
AX
EAX
MM0
XMM0
0
000
CL
CX
ECX
MM1
XMM1
1
001
DL
DX
EDX
MM2
XMM2
2
010
BL
BX
EBX
MM3
XMM3
3
011
AH
SP
ESP
MM4
XMM4
4
100
CH
BP
EBP
MM5
XMM5
5
101
DH
SI
ESI
MM6
XMM6
6
110
BH
DI
EDI
MM7
XMM7
7
111
Effective Address Mod R/M Value of ModR/M Byte (in Hexadecimal)
[EAX]
[ECX]
[EDX]
[EBX]
[--][--]1
disp322
[ESI]
[EDI]
00 000
001
010
011
100
101
110
111
00
01
02
03
04
05
06
07
08
09
0A
0B
0C
0D
0E
0F
10
11
12
13
14
15
16
17
18
19
1A
1B
1C
1D
1E
1F
20
21
22
23
24
25
26
27
28
29
2A
2B
2C
2D
2E
2F
30
31
32
33
34
35
36
37
38
39
3A
3B
3C
3D
3E
3F
[EAX]+disp83
[ECX]+disp8
[EDX]+disp8
[EBX]+disp8
[--][--]+disp8
[EBP]+disp8
[ESI]+disp8
[EDI]+disp8
01 000
001
010
011
100
101
110
111
40
41
42
43
44
45
46
47
48
49
4A
4B
4C
4D
4E
4F
50
51
52
53
54
55
56
57
58
59
5A
5B
5C
5D
5E
5F
60
61
62
63
64
65
66
67
68
69
6A
6B
6C
6D
6E
6F
70
71
72
73
74
75
76
77
78
79
7A
7B
7C
7D
7E
7F
[EAX]+disp32
[ECX]+disp32
[EDX]+disp32
[EBX]+disp32
[--][--]+disp32
[EBP]+disp32
[ESI]+disp32
[EDI]+disp32
10 000
001
010
011
100
101
110
111
80
81
82
83
84
85
86
87
88
89
8A
8B
8C
8D
8E
8F
90
91
92
93
94
95
96
97
98
99
9A
9B
9C
9D
9E
9F
A0
A1
A2
A3
A4
A5
A6
A7
A8
A9
AA
AB
AC
AD
AE
AF
B0
B1
B2
B3
B4
B5
B6
B7
B8
B9
BA
BB
BC
BD
BE
BF
EAX/AX/AL/MM0/XMM0
ECX/CX/CL/MM/XMM1
EDX/DX/DL/MM2/XMM2
EBX/BX/BL/MM3/XMM3
ESP/SP/AH/MM4/XMM4
EBP/BP/CH/MM5/XMM5
ESI/SI/DH/MM6/XMM6
EDI/DI/BH/MM7/XMM7
11 000
001
010
011
100
101
110
111
C0
C1
C2
C3
C4
C5
C6
C7
C8
C9
CA
CB
CC
CD
CE
CF
D0
D1
D2
D3
D4
D5
D6
D7
D8
D9
DA
DB
DC
DD
DE
DF
E0
E1
E2
E3
E4
E5
E6
E7
E8
E9
EA
EB
EC
ED
EE
EF
F0
F1
F2
F3
F4
F5
F6
F7
F8
F9
FA
FB
FC
FD
FE
FF

2-8 Vol. 2A
INSTRUCTION FORMAT
of the table indicate the register used as the index (SIB byte bits 3, 4 and 5) and the
scaling factor (determined by SIB byte bits 6 and 7).
NOTES:
1. The [*] nomenclature means a disp32 with no base if the MOD is 00B. Otherwise, [*] means disp8
or disp32 + [EBP]. This provides the following address modes:
MOD bits Effective Address
00 [scaled index] + disp32
01 [scaled index] + disp8 + [EBP]
10 [scaled index] + disp32 + [EBP]
Table 2-3. 32-Bit Addressing Forms with the SIB Byte
r32
(In decimal) Base =
(In binary) Base =
EAX
0
000
ECX
1
001
EDX
2
010
EBX
3
011
ESP
4
100
[*]
5
101
ESI
6
110
EDI
7
111
Scaled Index SS Index Value of SIB Byte (in Hexadecimal)
[EAX]
[ECX]
[EDX]
[EBX]
none
[EBP]
[ESI]
[EDI]
00 000
001
010
011
100
101
110
111
00
08
10
18
20
28
30
38
01
09
11
19
21
29
31
39
02
0A
12
1A
22
2A
32
3A
03
0B
13
1B
23
2B
33
3B
04
0C
14
1C
24
2C
34
3C
05
0D
15
1D
25
2D
35
3D
06
0E
16
1E
26
2E
36
3E
07
0F
17
1F
27
2F
37
3F
[EAX*2]
[ECX*2]
[EDX*2]
[EBX*2]
none
[EBP*2]
[ESI*2]
[EDI*2]
01 000
001
010
011
100
101
110
111
40
48
50
58
60
68
70
78
41
49
51
59
61
69
71
79
42
4A
52
5A
62
6A
72
7A
43
4B
53
5B
63
6B
73
7B
44
4C
54
5C
64
6C
74
7C
45
4D
55
5D
65
6D
75
7D
46
4E
56
5E
66
6E
76
7E
47
4F
57
5F
67
6F
77
7F
[EAX*4]
[ECX*4]
[EDX*4]
[EBX*4]
none
[EBP*4]
[ESI*4]
[EDI*4]
10 000
001
010
011
100
101
110
111
80
88
90
98
A0
A8
B0
B8
81
89
91
89
A1
A9
B1
B9
82
8A
92
9A
A2
AA
B2
BA
83
8B
93
9B
A3
AB
B3
BB
84
8C
94
9C
A4
AC
B4
BC
85
8D
95
9D
A5
AD
B5
BD
86
8E
96
9E
A6
AE
B6
BE
87
8F
97
9F
A7
AF
B7
BF
[EAX*8]
[ECX*8]
[EDX*8]
[EBX*8]
none
[EBP*8]
[ESI*8]
[EDI*8]
11 000
001
010
011
100
101
110
111
C0
C8
D0
D8
E0
E8
F0
F8
C1
C9
D1
D9
E1
E9
F1
F9
C2
CA
D2
DA
E2
EA
F2
FA
C3
CB
D3
DB
E3
EB
F3
FB
C4
CC
D4
DC
E4
EC
F4
FC
C5
CD
D5
DD
E5
ED
F5
FD
C6
CE
D6
DE
E6
EE
F6
FE
C7
CF
D7
DF
E7
EF
F7
FF

Vol. 2A 2-9
INSTRUCTION FORMAT
2.2 IA-32E MODE
IA-32e mode has two sub-modes. These are:
•Compatibility Mode. Enables a 64-bit operating system to run most legacy
protected mode software unmodified.
•64-Bit Mode. Enables a 64-bit operating system to run applications written to
access 64-bit address space.
2.2.1 REX Prefixes
REX prefixes are instruction-prefix bytes used in 64-bit mode. They do the following:
•Specify GPRs and SSE registers.
•Specify 64-bit operand size.
•Specify extended control registers.
Not all instructions require a REX prefix in 64-bit mode. A prefix is necessary only if
an instruction references one of the extended registers or uses a 64-bit operand. If a
REX prefix is used when it has no meaning, it is ignored.
Only one REX prefix is allowed per instruction. If used, the REX prefix byte must
immediately precede the opcode byte or the escape opcode byte (0FH). When a REX
prefix is used in conjunction with an instruction containing a mandatory prefix, the
mandatory prefix must come before the REX so the REX prefix can be immediately
preceding the opcode or the escape byte. For example, CVTDQ2PD with a REX prefix
should have REX placed between F3 and 0F E6. Other placements are ignored. The
instruction-size limit of 15 bytes still applies to instructions with a REX prefix. See
Figure 2-3.
Figure 2-3. Prefix Ordering in 64-bit Mode
REX
Immediate data
of 1, 2, or 4
bytes or none
Address
displacement of
1, 2, or 4 bytes
1 byte
(if required)
1 byte
(if required)
1-, 2-, or
3-byte
opcode
(optional)
Grp 1, Grp
2, Grp 3,
Grp 4
(optional)
Legacy
Prefix Opcode ModR/M SIB Displacement Immediate
Prefixes

2-10 Vol. 2A
INSTRUCTION FORMAT
2.2.1.1 Encoding
Intel 64 and IA-32 instruction formats specify up to three registers by using 3-bit
fields in the encoding, depending on the format:
•ModR/M: the reg and r/m fields of the ModR/M byte
•ModR/M with SIB: the reg field of the ModR/M byte, the base and index fields of
the SIB (scale, index, base) byte
•Instructions without ModR/M: the reg field of the opcode
In 64-bit mode, these formats do not change. Bits needed to define fields in the
64-bit context are provided by the addition of REX prefixes.
2.2.1.2 More on REX Prefix Fields
REX prefixes are a set of 16 opcodes that span one row of the opcode map and
occupy entries 40H to 4FH. These opcodes represent valid instructions (INC or DEC)
in IA-32 operating modes and in compatibility mode. In 64-bit mode, the same
opcodes represent the instruction prefix REX and are not treated as individual
instructions.
The single-byte-opcode form of INC/DEC instruction not available in 64-bit mode.
INC/DEC functionality is still available using ModR/M forms of the same instructions
(opcodes FF/0 and FF/1).
See Table 2-4 for a summary of the REX prefix format. Figure 2-4 though Figure 2-7
show examples of REX prefix fields in use. Some combinations of REX prefix fields are
invalid. In such cases, the prefix is ignored. Some additional information follows:
•Setting REX.W can be used to determine the operand size but does not solely
determine operand width. Like the 66H size prefix, 64-bit operand size override
has no effect on byte-specific operations.
•For non-byte operations: if a 66H prefix is used with prefix (REX.W = 1), 66H is
ignored.
•If a 66H override is used with REX and REX.W = 0, the operand size is 16 bits.
•REX.R modifies the ModR/M reg field when that field encodes a GPR, SSE, control
or debug register. REX.R is ignored when ModR/M specifies other registers or
defines an extended opcode.
•REX.X bit modifies the SIB index field.
•REX.B either modifies the base in the ModR/M r/m field or SIB base field; or it
modifies the opcode reg field used for accessing GPRs.
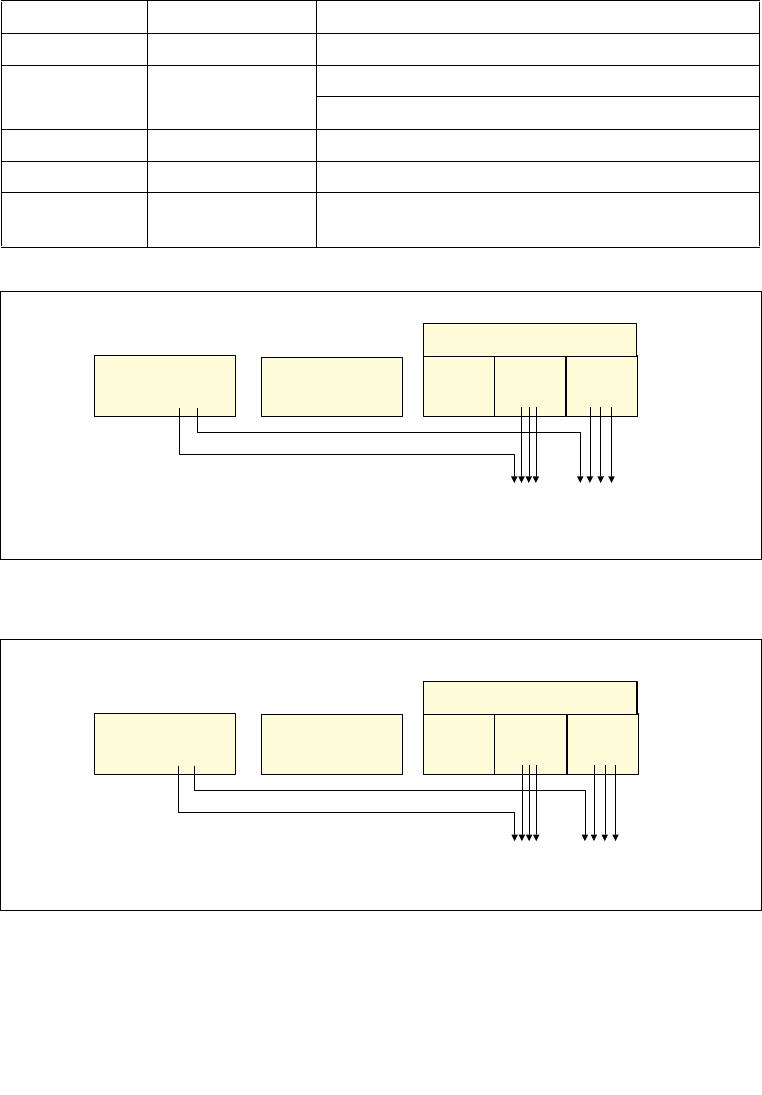
Vol. 2A 2-11
INSTRUCTION FORMAT
Table 2-4. REX Prefix Fields [BITS: 0100WRXB]
Field Name Bit Position Definition
- 7:4 0100
W 3 0 = Operand size determined by CS.D
1 = 64 Bit Operand Size
R 2 Extension of the ModR/M reg field
X 1 Extension of the SIB index field
B 0 Extension of the ModR/M r/m field, SIB base field, or
Opcode reg field
Figure 2-4. Memory Addressing Without an SIB Byte; REX.X Not Used
Figure 2-5. Register-Register Addressing (No Memory Operand); REX.X Not Used
5(;35(),;
:5%
2SFRGH PRG
UHJ UP
5UUU %EEE
0RG50%\WH
UUU EEE
20;ILJ
5(;35(),;
:5%
2SFRGH PRG
UHJ UP
5UUU %EEE
0RG50%\WH
UUU EEE
20;ILJ
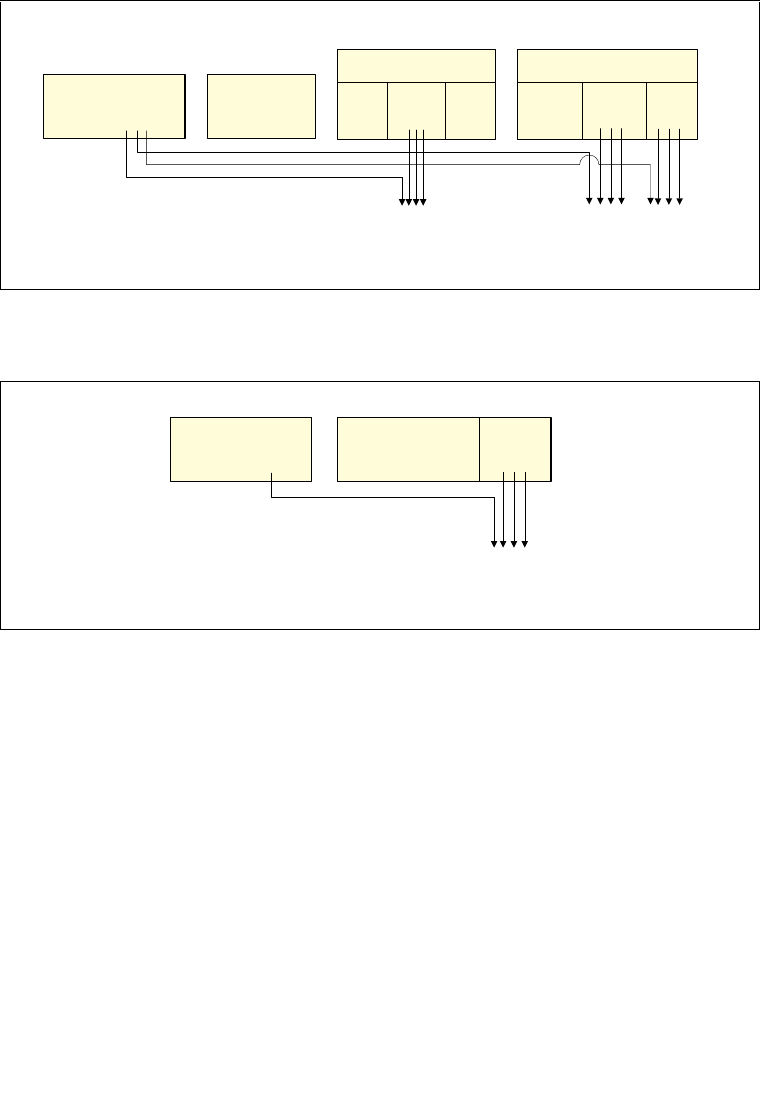
2-12 Vol. 2A
INSTRUCTION FORMAT
In the IA-32 architecture, byte registers (AH, AL, BH, BL, CH, CL, DH, and DL) are
encoded in the ModR/M byte’s reg field, the r/m field or the opcode reg field as regis-
ters 0 through 7. REX prefixes provide an additional addressing capability for byte-
registers that makes the least-significant byte of GPRs available for byte operations.
Certain combinations of the fields of the ModR/M byte and the SIB byte have special
meaning for register encodings. For some combinations, fields expanded by the REX
prefix are not decoded. Table 2-5 describes how each case behaves.
Figure 2-6. Memory Addressing With a SIB Byte
Figure 2-7. Register Operand Coded in Opcode Byte; REX.X & REX.R Not Used
PRG
0RG50%\WH
UP
UHJ
UUU
VFDOH
VV
6,%%\WH
5(;35(),;
:5;%
2SFRGH
5UUU
EDVH
%EEE
EEE
;[[[
LQGH[
[[[
20;ILJ
5(;35(),;
:%
2SFRGH
%EEE
UHJ
EEE
20;ILJ

Vol. 2A 2-13
INSTRUCTION FORMAT
2.2.1.3 Displacement
Addressing in 64-bit mode uses existing 32-bit ModR/M and SIB encodings. The
ModR/M and SIB displacement sizes do not change. They remain 8 bits or 32 bits and
are sign-extended to 64 bits.
2.2.1.4 Direct Memory-Offset MOVs
In 64-bit mode, direct memory-offset forms of the MOV instruction are extended to
specify a 64-bit immediate absolute address. This address is called a moffset. No
prefix is needed to specify this 64-bit memory offset. For these MOV instructions, the
Table 2-5. Special Cases of REX Encodings
ModR/M or
SIB
Sub-field
Encodings
Compatibility
Mode Operation
Compatibility
Mode Implications Additional Implications
ModR/M Byte mod != 11 SIB byte present. SIB byte required
for ESP-based
addressing.
REX prefix adds a fourth
bit (b) which is not
decoded (don't care).
SIB byte also required for
R12-based addressing.
r/m =
b*100(ESP)
ModR/M Byte mod = 0 Base register not
used.
EBP without a
displacement must
be done using
mod = 01 with
displacement of 0.
REX prefix adds a fourth
bit (b) which is not
decoded (don't care).
Using RBP or R13 without
displacement must be
done using mod = 01 with
a displacement of 0.
r/m =
b*101(EBP)
SIB Byte index =
0100(ESP)
Index register not
used.
ESP cannot be used
as an index
register.
REX prefix adds a fourth
bit (b) which is decoded.
There are no additional
implications. The
expanded index field
allows distinguishing RSP
from R12, therefore R12
can be used as an index.
SIB Byte base =
0101(EBP)
Base register is
unused if
mod = 0.
Base register
depends on mod
encoding.
REX prefix adds a fourth
bit (b) which is not
decoded.
This requires explicit
displacement to be used
with EBP/RBP or R13.
NOTES:
* Don’t care about value of REX.B

2-14 Vol. 2A
INSTRUCTION FORMAT
size of the memory offset follows the address-size default (64 bits in 64-bit mode).
See Table 2-6.
2.2.1.5 Immediates
In 64-bit mode, the typical size of immediate operands remains 32 bits. When the
operand size is 64 bits, the processor sign-extends all immediates to 64 bits prior to
their use.
Support for 64-bit immediate operands is accomplished by expanding the semantics
of the existing move (MOV reg, imm16/32) instructions. These instructions (opcodes
B8H – BFH) move 16-bits or 32-bits of immediate data (depending on the effective
operand size) into a GPR. When the effective operand size is 64 bits, these instruc-
tions can be used to load an immediate into a GPR. A REX prefix is needed to override
the 32-bit default operand size to a 64-bit operand size.
For example:
48 B8 8877665544332211 MOV RAX,1122334455667788H
2.2.1.6 RIP-Relative Addressing
A new addressing form, RIP-relative (relative instruction-pointer) addressing, is
implemented in 64-bit mode. An effective address is formed by adding displacement
to the 64-bit RIP of the next instruction.
In IA-32 architecture and compatibility mode, addressing relative to the instruction
pointer is available only with control-transfer instructions. In 64-bit mode, instruc-
tions that use ModR/M addressing can use RIP-relative addressing. Without RIP-rela-
tive addressing, all ModR/M instruction modes address memory relative to zero.
RIP-relative addressing allows specific ModR/M modes to address memory relative to
the 64-bit RIP using a signed 32-bit displacement. This provides an offset range of
±2GB from the RIP. Table 2-7 shows the ModR/M and SIB encodings for RIP-relative
addressing. Redundant forms of 32-bit displacement-addressing exist in the current
ModR/M and SIB encodings. There is one ModR/M encoding and there are several SIB
encodings. RIP-relative addressing is encoded using a redundant form.
In 64-bit mode, the ModR/M Disp32 (32-bit displacement) encoding is re-defined to
be RIP+Disp32 rather than displacement-only. See Table 2-7.
Table 2-6. Direct Memory Offset Form of MOV
Opcode Instruction
A0 MOV AL, moffset
A1 MOV EAX, moffset
A2 MOV moffset, AL
A3 MOV moffset, EAX

Vol. 2A 2-15
INSTRUCTION FORMAT
The ModR/M encoding for RIP-relative addressing does not depend on using prefix.
Specifically, the r/m bit field encoding of 101B (used to select RIP-relative
addressing) is not affected by the REX prefix. For example, selecting R13 (REX.B = 1,
r/m = 101B) with mod = 00B still results in RIP-relative addressing. The 4-bit r/m
field of REX.B combined with ModR/M is not fully decoded. In order to address R13
with no displacement, software must encode R13 + 0 using a 1-byte displacement of
zero.
RIP-relative addressing is enabled by 64-bit mode, not by a 64-bit address-size. The
use of the address-size prefix does not disable RIP-relative addressing. The effect of
the address-size prefix is to truncate and zero-extend the computed effective
address to 32 bits.
2.2.1.7 Default 64-Bit Operand Size
In 64-bit mode, two groups of instructions have a default operand size of 64 bits (do
not need a REX prefix for this operand size). These are:
•Near branches
•All instructions, except far branches, that implicitly reference the RSP
2.2.2 Additional Encodings for Control and Debug Registers
In 64-bit mode, more encodings for control and debug registers are available. The
REX.R bit is used to modify the ModR/M reg field when that field encodes a control or
debug register (see Table 2-4). These encodings enable the processor to address
CR8-CR15 and DR8- DR15. An additional control register (CR8) is defined in 64-bit
mode. CR8 becomes the Task Priority Register (TPR).
In the first implementation of IA-32e mode, CR9-CR15 and DR8-DR15 are not imple-
mented. Any attempt to access unimplemented registers results in an invalid-opcode
exception (#UD).
Table 2-7. RIP-Relative Addressing
ModR/M and SIB Sub-field
Encodings
Compatibility
Mode Operation
64-bit Mode
Operation
Additional Implications
in 64-bit mode
ModR/M
Byte
mod = 00 Disp32 RIP + Disp32 Must use SIB form with
normal (zero-based)
displacement addressing
r/m = 101 (none)
SIB Byte base = 101 (none) if mod = 00,
Disp32
Same as
legacy
None
index = 100 (none)
scale = 0, 1, 2, 4

2-16 Vol. 2A
INSTRUCTION FORMAT
2.3 INTEL® ADVANCED VECTOR EXTENSIONS (INTEL®
AVX)
Intel AVX instructions are encoded using an encoding scheme that combines prefix
bytes, opcode extension field, operand encoding fields, and vector length encoding
capability into a new prefix, referred to as VEX. In the VEX encoding scheme, the VEX
prefix may be two or three bytes long, depending on the instruction semantics.
Despite the two-byte or three-byte length of the VEX prefix, the VEX encoding format
provides a more compact representation/packing of the components of encoding an
instruction in Intel 64 architecture. The VEX encoding scheme also allows more head-
room for future growth of Intel 64 architecture.
2.3.1 Instruction Format
Instruction encoding using VEX prefix provides several advantages:
•Instruction syntax support for three operands and up-to four operands when
necessary. For example, the third source register used by VBLENDVPD is encoded
using bits 7:4 of the immediate byte.
•Encoding support for vector length of 128 bits (using XMM registers) and 256 bits
(using YMM registers)
•Encoding support for instruction syntax of non-destructive source operands.
•Elimination of escape opcode byte (0FH), SIMD prefix byte (66H, F2H, F3H) via a
compact bit field representation within the VEX prefix.
•Elimination of the need to use REX prefix to encode the extended half of general-
purpose register sets (R8-R15) for direct register access, memory addressing, or
accessing XMM8-XMM15 (including YMM8-YMM15).
•Flexible and more compact bit fields are provided in the VEX prefix to retain the
full functionality provided by REX prefix. REX.W, REX.X, REX.B functionalities are
provided in the three-byte VEX prefix only because only a subset of SIMD instruc-
tions need them.
•Extensibility for future instruction extensions without significant instruction
length increase.
Figure 2-8 shows the Intel 64 instruction encoding format with VEX prefix support.
Legacy instruction without a VEX prefix is fully supported and unchanged. The use of
VEX prefix in an Intel 64 instruction is optional, but a VEX prefix is required for Intel
64 instructions that operate on YMM registers or support three and four operand
syntax. VEX prefix is not a constant-valued, “single-purpose” byte like 0FH, 66H,
F2H, F3H in legacy SSE instructions. VEX prefix provides substantially richer capa-
bility than the REX prefix.

Vol. 2A 2-17
INSTRUCTION FORMAT
Figure 2-8. Instruction Encoding Format with VEX Prefix
2.3.2 VEX and the LOCK prefix
Any VEX-encoded instruction with a LOCK prefix preceding VEX will #UD.
2.3.3 VEX and the 66H, F2H, and F3H prefixes
Any VEX-encoded instruction with a 66H, F2H, or F3H prefix preceding VEX will #UD.
2.3.4 VEX and the REX prefix
Any VEX-encoded instruction with a REX prefix proceeding VEX will #UD.
2.3.5 The VEX Prefix
The VEX prefix is encoded in either the two-byte form (the first byte must be C5H) or
in the three-byte form (the first byte must be C4H). The two-byte VEX is used mainly
for 128-bit, scalar, and the most common 256-bit AVX instructions; while the three-
byte VEX provides a compact replacement of REX and 3-byte opcode instructions
(including AVX and FMA instructions). Beyond the first byte of the VEX prefix, it
consists of a number of bit fields providing specific capability, they are shown in
Figure 2-9.
The bit fields of the VEX prefix can be summarized by its functional purposes:
•Non-destructive source register encoding (applicable to three and four operand
syntax): This is the first source operand in the instruction syntax. It is
represented by the notation, VEX.vvvv. This field is encoded using 1’s
complement form (inverted form), i.e. XMM0/YMM0/R0 is encoded as 1111B,
XMM15/YMM15/R15 is encoded as 0000B.
•Vector length encoding: This 1-bit field represented by the notation VEX.L. L= 0
means vector length is 128 bits wide, L=1 means 256 bit vector. The value of this
field is written as VEX.128 or VEX.256 in this document to distinguish encoded
values of other VEX bit fields.
ModR/M
1
[Prefixes] [VEX]
OPCODE
[SIB]
[DISP] [IMM]
2,3
1
0,1 0,1,2,4 0,1# Bytes

2-18 Vol. 2A
INSTRUCTION FORMAT
•REX prefix functionality: Full REX prefix functionality is provided in the three-byte
form of VEX prefix. However the VEX bit fields providing REX functionality are
encoded using 1’s complement form, i.e. XMM0/YMM0/R0 is encoded as 1111B,
XMM15/YMM15/R15 is encoded as 0000B.
— Two-byte form of the VEX prefix only provides the equivalent functionality of
REX.R, using 1’s complement encoding. This is represented as VEX.R.
— Three-byte form of the VEX prefix provides REX.R, REX.X, REX.B functionality
using 1’s complement encoding and three dedicated bit fields represented as
VEX.R, VEX.X, VEX.B.
— Three-byte form of the VEX prefix provides the functionality of REX.W only to
specific instructions that need to override default 32-bit operand size for a
general purpose register to 64-bit size in 64-bit mode. For those applicable
instructions, VEX.W field provides the same functionality as REX.W. VEX.W
field can provide completely different functionality for other instructions.
Consequently, the use of REX prefix with VEX encoded instructions is not
allowed. However, the intent of the REX prefix for expanding register set is
reserved for future instruction set extensions using VEX prefix encoding format.
•Compaction of SIMD prefix: Legacy SSE instructions effectively use SIMD
prefixes (66H, F2H, F3H) as an opcode extension field. VEX prefix encoding
allows the functional capability of such legacy SSE instructions (operating on
XMM registers, bits 255:128 of corresponding YMM unmodified) to be encoded
using the VEX.pp field without the presence of any SIMD prefix. The VEX-encoded
128-bit instruction will zero-out bits 255:128 of the destination register. VEX-
encoded instruction may have 128 bit vector length or 256 bits length.
•Compaction of two-byte and three-byte opcode: More recently introduced legacy
SSE instructions employ two and three-byte opcode. The one or two leading
bytes are: 0FH, and 0FH 3AH/0FH 38H. The one-byte escape (0FH) and two-byte
escape (0FH 3AH, 0FH 38H) can also be interpreted as an opcode extension field.
The VEX.mmmmm field provides compaction to allow many legacy instruction to
be encoded without the constant byte sequence, 0FH, 0FH 3AH, 0FH 38H. These
VEX-encoded instruction may have 128 bit vector length or 256 bits length.
The VEX prefix is required to be the last prefix and immediately precedes the opcode
bytes. It must follow any other prefixes. If VEX prefix is present a REX prefix is not
supported.
The 3-byte VEX leaves room for future expansion with 3 reserved bits. REX and the
66h/F2h/F3h prefixes are reclaimed for future use.
VEX prefix has a two-byte form and a three byte form. If an instruction syntax can be
encoded using the two-byte form, it can also be encoded using the three byte form of
VEX. The latter increases the length of the instruction by one byte. This may be
helpful in some situations for code alignment.
The VEX prefix supports 256-bit versions of floating-point SSE, SSE2, SSE3, and
SSE4 instructions. Note, certain new instruction functionality can only be encoded
with the VEX prefix.

Vol. 2A 2-19
INSTRUCTION FORMAT
The VEX prefix will #UD on any instruction containing MMX register sources or desti-
nations.
Figure 2-9. VEX bitfields
11000100
1
670
vvvv
103 2
L
7
R: REX.R in 1’s complement (inverted) form
00000: Reserved for future use (will #UD)
00001: implied 0F leading opcode byte
00010: implied 0F 38 leading opcode bytes
00011: implied 0F 3A leading opcode bytes
00100-11111: Reserved for future use (will #UD)
Byte 0 Byte 2
(Bit Position)
vvvv: a register specifier (in 1’s complement form) or 1111 if unused.
670
R X B
Byte 1
pp: opcode extension providing equivalent functionality of a SIMD prefix
W: opcode specific (use like REX.W, or used for opcode
m-mmmm
5
m-mmmm:
W
L: Vector Length
0: Same as REX.R=1 (64-bit mode only)
1: Same as REX.R=0 (must be 1 in 32-bit mode)
4
pp
3-byte VEX
11000101
1
670
vvvv
103 2
L
7
R pp 2-byte VEX
B: REX.B in 1’s complement (inverted) form
0: Same as REX.B=1 (64-bit mode only)
1: Same as REX.B=0 (Ignored in 32-bit mode).
extension, or ignored, depending on the opcode byte)
0: scalar or 128-bit vector
1: 256-bit vector
00: None
01: 66
10: F3
11: F2
0: Same as REX.X=1 (64-bit mode only)
1: Same as REX.X=0 (must be 1 in 32-bit mode)
X: REX.X in 1’s complement (inverted) form

2-20 Vol. 2A
INSTRUCTION FORMAT
The following subsections describe the various fields in two or three-byte VEX prefix:
2.3.5.1 VEX Byte 0, bits[7:0]
VEX Byte 0, bits [7:0] must contain the value 11000101b (C5h) or 11000100b
(C4h). The 3-byte VEX uses the C4h first byte, while the 2-byte VEX uses the C5h
first byte.
2.3.5.2 VEX Byte 1, bit [7] - ‘R’
VEX Byte 1, bit [7] contains a bit analogous to a bit inverted REX.R. In protected and
compatibility modes the bit must be set to ‘1’ otherwise the instruction is LES or LDS.
This bit is present in both 2- and 3-byte VEX prefixes.
The usage of WRXB bits for legacy instructions is explained in detail section 2.2.1.2
of Intel 64 and IA-32 Architectures Software developer’s manual, Volume 2A.
This bit is stored in bit inverted format.
2.3.5.3 3-byte VEX byte 1, bit[6] - ‘X’
Bit[6] of the 3-byte VEX byte 1 encodes a bit analogous to a bit inverted REX.X. It is
an extension of the SIB Index field in 64-bit modes. In 32-bit modes, this bit must be
set to ‘1’ otherwise the instruction is LES or LDS.
This bit is available only in the 3-byte VEX prefix.
This bit is stored in bit inverted format.
2.3.5.4 3-byte VEX byte 1, bit[5] - ‘B’
Bit[5] of the 3-byte VEX byte 1 encodes a bit analogous to a bit inverted REX.B. In
64-bit modes, it is an extension of the ModR/M r/m field, or the SIB base field. In 32-
bit modes, this bit is ignored.
This bit is available only in the 3-byte VEX prefix.
This bit is stored in bit inverted format.
2.3.5.5 3-byte VEX byte 2, bit[7] - ‘W’
Bit[7] of the 3-byte VEX byte 2 is represented by the notation VEX.W. It can provide
following functions, depending on the specific opcode.
• For AVX instructions that have equivalent legacy SSE instructions (typically
these SSE instructions have a general-purpose register operand with its oper-
and size attribute promotable by REX.W), if REX.W promotes the operand size
attribute of the general-purpose register operand in legacy SSE instruction,
VEX.W has same meaning in the corresponding AVX equivalent form. In 32-bit
modes, VEX.W is silently ignored.

Vol. 2A 2-21
INSTRUCTION FORMAT
• For AVX instructions that have equivalent legacy SSE instructions (typically
these SSE instructions have operands with their operand size attribute fixed and
not promotable by REX.W), if REX.W is don’t care in legacy SSE instruction,
VEX.W is ignored in the corresponding AVX equivalent form irrespective of
mode.
• For new AVX instructions where VEX.W has no defined function (typically these
meant the combination of the opcode byte and VEX.mmmmm did not have any
equivalent SSE functions), VEX.W is reserved as zero and setting to other than
zero will cause instruction to #UD.
2.3.5.6 2-byte VEX Byte 1, bits[6:3] and 3-byte VEX Byte 2, bits [6:3]-
‘vvvv’ the Source or dest Register Specifier
In 32-bit mode the VEX first byte C4 and C5 alias onto the LES and LDS instructions.
To maintain compatibility with existing programs the VEX 2nd byte, bits [7:6] must
be 11b. To achieve this, the VEX payload bits are selected to place only inverted, 64-
bit valid fields (extended register selectors) in these upper bits.
The 2-byte VEX Byte 1, bits [6:3] and the 3-byte VEX, Byte 2, bits [6:3] encode a
field (shorthand VEX.vvvv) that for instructions with 2 or more source registers and
an XMM or YMM or memory destination encodes the first source register specifier
stored in inverted (1’s complement) form.
VEX.vvvv is not used by the instructions with one source (except certain shifts, see
below) or on instructions with no XMM or YMM or memory destination. If an instruc-
tion does not use VEX.vvvv then it should be set to 1111b otherwise instruction will
#UD.
In 64-bit mode all 4 bits may be used. See Table 2-8 for the encoding of the XMM or
YMM registers. In 32-bit and 16-bit modes bit 6 must be 1 (if bit 6 is not 1, the 2-byte
VEX version will generate LDS instruction and the 3-byte VEX version will ignore this
bit).
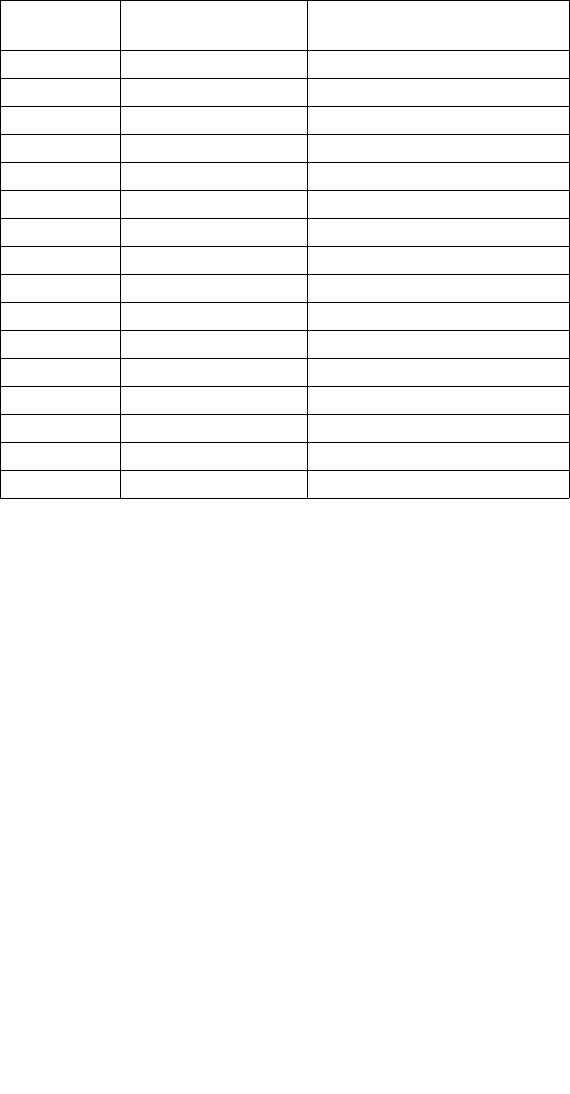
2-22 Vol. 2A
INSTRUCTION FORMAT
Table 2-8. VEX.vvvv to register name mapping
The VEX.vvvv field is encoded in bit inverted format for accessing a register oper-
and.
2.3.6 Instruction Operand Encoding and VEX.vvvv, ModR/M
VEX-encoded instructions support three-operand and four-operand instruction
syntax. Some VEX-encoded instructions have syntax with less than three operands,
e.g. VEX-encoded pack shift instructions support one source operand and one desti-
nation operand).
The roles of VEX.vvvv, reg field of ModR/M byte (ModR/M.reg), r/m field of ModR/M
byte (ModR/M.r/m) with respect to encoding destination and source operands vary
with different type of instruction syntax.
The role of VEX.vvvv can be summarized to three situations:
•VEX.vvvv encodes the first source register operand, specified in inverted (1’s
complement) form and is valid for instructions with 2 or more source operands.
•VEX.vvvv encodes the destination register operand, specified in 1’s complement
form for certain vector shifts. The instructions where VEX.vvvv is used as a
destination are listed in Table 2-9. The notation in the “Opcode” column in
Table 2-9 is described in detail in section 3.1.1.
VEX.vvvv Dest Register Valid in Legacy/Compatibility
32-bit modes?
1111B XMM0/YMM0 Valid
1110B XMM1/YMM1 Valid
1101B XMM2/YMM2 Valid
1100B XMM3/YMM3 Valid
1011B XMM4/YMM4 Valid
1010B XMM5/YMM5 Valid
1001B XMM6/YMM6 Valid
1000B XMM7/YMM7 Valid
0111B XMM8/YMM8 Invalid
0110B XMM9/YMM9 Invalid
0101B XMM10/YMM10 Invalid
0100B XMM11/YMM11 Invalid
0011B XMM12/YMM12 Invalid
0010B XMM13/YMM13 Invalid
0001B XMM14/YMM14 Invalid
0000B XMM15/YMM15 Invalid

Vol. 2A 2-23
INSTRUCTION FORMAT
•VEX.vvvv does not encode any operand, the field is reserved and should contain
1111b.
Table 2-9. Instructions with a VEX.vvvv destination
The role of ModR/M.r/m field can be summarized to two situations:
•ModR/M.r/m encodes the instruction operand that references a memory address.
•For some instructions that do not support memory addressing semantics,
ModR/M.r/m encodes either the destination register operand or a source register
operand.
The role of ModR/M.reg field can be summarized to two situations:
•ModR/M.reg encodes either the destination register operand or a source register
operand.
•For some instructions, ModR/M.reg is treated as an opcode extension and not
used to encode any instruction operand.
For instruction syntax that support four operands, VEX.vvvv, ModR/M.r/m,
ModR/M.reg encodes three of the four operands. The role of bits 7:4 of the imme-
diate byte serves the following situation:
•Imm8[7:4] encodes the third source register operand.
2.3.6.1 3-byte VEX byte 1, bits[4:0] - “m-mmmm”
Bits[4:0] of the 3-byte VEX byte 1 encode an implied leading opcode byte (0F, 0F 38,
or 0F 3A). Several bits are reserved for future use and will #UD unless 0.
Opcode Instruction mnemonic
VEX.NDD.128.66.0F 73 /7 ib VPSLLDQ xmm1, xmm2, imm8
VEX.NDD.128.66.0F 73 /3 ib VPSRLDQ xmm1, xmm2, imm8
VEX.NDD.128.66.0F 71 /2 ib VPSRLW xmm1, xmm2, imm8
VEX.NDD.128.66.0F 72 /2 ib VPSRLD xmm1, xmm2, imm8
VEX.NDD.128.66.0F 73 /2 ib VPSRLQ xmm1, xmm2, imm8
VEX.NDD.128.66.0F 71 /4 ib VPSRAW xmm1, xmm2, imm8
VEX.NDD.128.66.0F 72 /4 ib VPSRAD xmm1, xmm2, imm8
VEX.NDD.128.66.0F 71 /6 ib VPSLLW xmm1, xmm2, imm8
VEX.NDD.128.66.0F 72 /6 ib VPSLLD xmm1, xmm2, imm8
VEX.NDD.128.66.0F 73 /6 ib VPSLLQ xmm1, xmm2, imm8
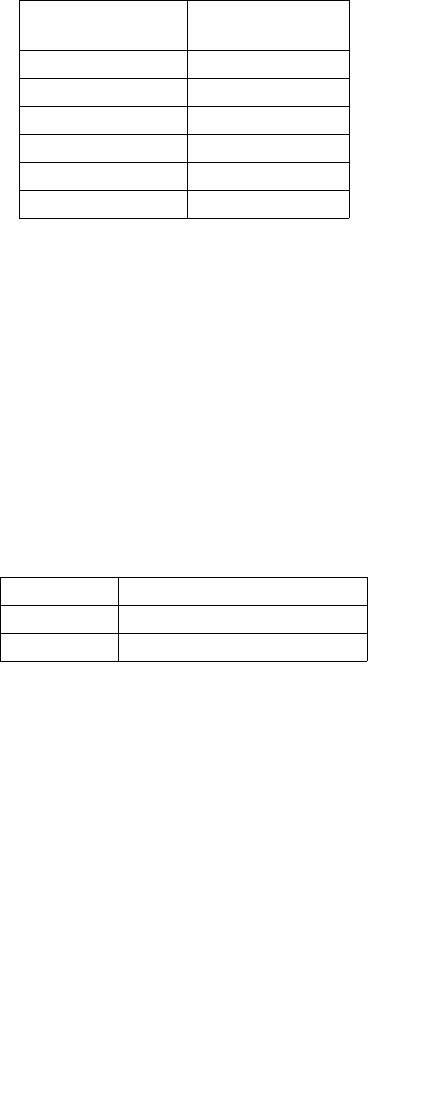
2-24 Vol. 2A
INSTRUCTION FORMAT
Table 2-10. VEX.m-mmmm interpretation
VEX.m-mmmm is only available on the 3-byte VEX. The 2-byte VEX implies a leading
0Fh opcode byte.
2.3.6.2 2-byte VEX byte 1, bit[2], and 3-byte VEX byte 2, bit [2]- “L”
The vector length field, VEX.L, is encoded in bit[2] of either the second byte of 2-byte
VEX, or the third byte of 3-byte VEX. If “VEX.L = 1”, it indicates 256-bit vector oper-
ation. “VEX.L = 0” indicates scalar and 128-bit vector operations.
The instruction VZEROUPPER is a special case that is encoded with VEX.L = 0,
although its operation zero’s bits 255:128 of all YMM registers accessible in the
current operating mode.
See the following table.
Table 2-11. VEX.L interpretation
2.3.6.3 2-byte VEX byte 1, bits[1:0], and 3-byte VEX byte 2, bits [1:0]-
“pp”
Up to one implied prefix is encoded by bits[1:0] of either the 2-byte VEX byte 1 or the
3-byte VEX byte 2. The prefix behaves as if it was encoded prior to VEX, but after all
other encoded prefixes.
See the following table.
VEX.m-mmmm Implied Leading
Opcode Bytes
00000B Reserved
00001B 0F
00010B 0F 38
00011B 0F 3A
00100-11111B Reserved
(2-byte VEX) 0F
VEX.L Vector Length
0 128-bit (or 32/64-bit scalar)
1 256-bit

Vol. 2A 2-25
INSTRUCTION FORMAT
Table 2-12. VEX.pp interpretation
2.3.7 The Opcode Byte
One (and only one) opcode byte follows the 2 or 3 byte VEX. Legal opcodes are spec-
ified in Appendix B, in color. Any instruction that uses illegal opcode will #UD.
2.3.8 The MODRM, SIB, and Displacement Bytes
The encodings are unchanged but the interpretation of reg_field or rm_field differs
(see above).
2.3.9 The Third Source Operand (Immediate Byte)
VEX-encoded instructions can support instruction with a four operand syntax.
VBLENDVPD, VBLENDVPS, and PBLENDVB use imm8[7:4] to encode one of the
source registers.
2.3.10 AVX Instructions and the Upper 128-bits of YMM registers
If an instruction with a destination XMM register is encoded with a VEX prefix, the
processor zeroes the upper bits (above bit 128) of the equivalent YMM register .
Legacy SSE instructions without VEX preserve the upper bits.
2.3.11 AVX Instruction Length
The AVX instructions described in this document (including VEX and ignoring other
prefixes) do not exceed 11 bytes in length, but may increase in the future. The
maximum length of an Intel 64 and IA-32 instruction remains 15 bytes.
2.4 INSTRUCTION EXCEPTION SPECIFICATION
To look up the exceptions of legacy 128-bit SIMD instruction, 128-bit VEX-encoded
instructions, and 256-bit VEX-encoded instruction, Table 2-13 summarizes the
pp Implies this prefix after other
prefixes but before VEX
00B None
01B 66
10B F3
11B F2
2-26 Vol. 2A
INSTRUCTION FORMAT
exception behavior into separate classes, with detailed exception conditions defined
in sub-sections 2.4.1 through 2.4.9. For example, ADDPS contains the entry:
“See Exceptions Type 2”
In this entry, “Type2” can be looked up in Table 2-13.
The instruction’s corresponding CPUID feature flag can be identified in the fourth
column of the Instruction summary table.
Note: #UD on CPUID feature flags=0 is not guaranteed in a virtualized environment
if the hardware supports the feature flag.
NOTE
Instructions that operate only with MMX, X87, or general-purpose
registers are not covered by the exception classes defined in this
section.
Table 2-13. Exception class description
See Table 2-14 for lists of instructions in each exception class.
Exception Class Instruction set Mem arg
Floating-Point
Exceptions
(#XM)
Type 1 AVX,
Legacy SSE
16/32 byte
explicitly aligned none
Type 2 AVX,
Legacy SSE
16/32 byte not
explicitly aligned yes
Type 3 AVX,
Legacy SSE < 16 byte yes
Type 4 AVX,
Legacy SSE
16/32 byte not
explicitly aligned no
Type 5 AVX,
Legacy SSE < 16 byte no
Type 6 AVX (no Legacy
SSE) Varies (At present,
none do)
Type 7 AVX,
Legacy SSE none none
Type 8 AVX none none
Type 9 AVX 4 byte none

Vol. 2A 2-27
INSTRUCTION FORMAT
Table 2-14. Instructions in each Exception Class
Exception Class Instruction
Type 1 (V)MOVAPD, (V)MOVAPS, (V)MOVDQA, (V)MOVNTDQ, (V)MOVNTDQA,
(V)MOVNTPD, (V)MOVNTPS
Type 2
(V)ADDPD, (V)ADDPS, (V)ADDSUBPD, (V)ADDSUBPS, (V)CMPPD, (V)CMPPS,
(V)CVTDQ2PS, (V)CVTPD2DQ, (V)CVTPD2PS, (V)CVTPS2DQ, (V)CVTTPD2DQ,
(V)CVTTPS2DQ, (V)DIVPD, (V)DIVPS, (V)DPPD*, (V)DPPS*, (V)HADDPD,
(V)HADDPS, (V)HSUBPD, (V)HSUBPS, (V)MAXPD, (V)MAXPS, (V)MINPD,
(V)MINPS, (V)MULPD, (V)MULPS, (V)ROUNDPD, (V)ROUNDPS, (V)SQRTPD,
(V)SQRTPS, (V)SUBPD, (V)SUBPS
Type 3
(V)ADDSD, (V)ADDSS, (V)CMPSD, (V)CMPSS, (V)COMISD, (V)COMISS,
(V)CVTPS2PD, (V)CVTSD2SI, (V)CVTSD2SS, (V)CVTSI2SD, (V)CVTSI2SS,
(V)CVTSS2SD, (V)CVTSS2SI, (V)CVTTSD2SI, (V)CVTTSS2SI, (V)DIVSD,
(V)DIVSS, (V)MAXSD, (V)MAXSS, (V)MINSD, (V)MINSS, (V)MULSD, (V)MULSS,
(V)ROUNDSD, (V)ROUNDSS, (V)SQRTSD, (V)SQRTSS, (V)SUBSD, (V)SUBSS,
(V)UCOMISD, (V)UCOMISS
Type 4
(V)AESDEC, (V)AESDECLAST, (V)AESENC, (V)AESENCLAST, (V)AESIMC,
(V)AESKEYGENASSIST, (V)ANDPD, (V)ANDPS, (V)ANDNPD, (V)ANDNPS,
(V)BLENDPD, (V)BLENDPS, VBLENDVPD, VBLENDVPS, (V)LDDQU,
(V)MASKMOVDQU, (V)PTEST, VTESTPS, VTESTPD, (V)MOVDQU*,
(V)MOVSHDUP, (V)MOVSLDUP, (V)MOVUPD*, (V)MOVUPS*, (V)MPSADBW,
(V)ORPD, (V)ORPS, (V)PABSB, (V)PABSW, (V)PABSD, (V)PACKSSWB,
(V)PACKSSDW, (V)PACKUSWB, (V)PACKUSDW, (V)PADDB, (V)PADDW,
(V)PADDD, (V)PADDQ, (V)PADDSB, (V)PADDSW, (V)PADDUSB, (V)PADDUSW,
(V)PALIGNR, (V)PAND, (V)PANDN, (V)PAVGB, (V)PAVGW, (V)PBLENDVB,
(V)PBLENDW, (V)PCMP(E/I)STRI/M, (V)PCMPEQB, (V)PCMPEQW, (V)PCMPEQD,
(V)PCMPEQQ, (V)PCMPGTB, (V)PCMPGTW, (V)PCMPGTD, (V)PCMPGTQ,
(V)PCLMULQDQ, (V)PHADDW, (V)PHADDD, (V)PHADDSW, (V)PHMINPOSUW,
(V)PHSUBD, (V)PHSUBW, (V)PHSUBSW,
(V)PMADDWD, (V)PMADDUBSW, (V)PMAXSB, (V)PMAXSW, (V)PMAXSD,
(V)PMAXUB, (V)PMAXUW, (V)PMAXUD, (V)PMINSB, (V)PMINSW, (V)PMINSD,
(V)PMINUB, (V)PMINUW, (V)PMINUD, (V)PMULHUW, (V)PMULHRSW,
(V)PMULHW, (V)PMULLW, (V)PMULLD, (V)PMULUDQ, (V)PMULDQ, (V)POR,
(V)PSADBW, (V)PSHUFB, (V)PSHUFD, (V)PSHUFHW, (V)PSHUFLW, (V)PSIGNB,
(V)PSIGNW, (V)PSIGND, (V)PSLLW, (V)PSLLD, (V)PSLLQ, (V)PSRAW, (V)PSRAD,
(V)PSRLW, (V)PSRLD, (V)PSRLQ, (V)PSUBB, (V)PSUBW, (V)PSUBD, (V)PSUBQ,
(V)PSUBSB, (V)PSUBSW, (V)PUNPCKHBW, (V)PUNPCKHWD, (V)PUNPCKHDQ,
(V)PUNPCKHQDQ, (V)PUNPCKLBW, (V)PUNPCKLWD, (V)PUNPCKLDQ,
(V)PUNPCKLQDQ, (V)PXOR, (V)RCPPS, (V)RSQRTPS, (V)SHUFPD, (V)SHUFPS,
(V)UNPCKHPD, (V)UNPCKHPS, (V)UNPCKLPD, (V)UNPCKLPS, (V)XORPD,
(V)XORPS
Type 5
(V)CVTDQ2PD, (V)EXTRACTPS, (V)INSERTPS, (V)MOVD, (V)MOVQ,
(V)MOVDDUP, (V)MOVLPD, (V)MOVLPS, (V)MOVHPD, (V)MOVHPS, (V)MOVSD,
(V)MOVSS, (V)PEXTRB, (V)PEXTRD, (V)PEXTRW, (V)PEXTRQ, (V)PINSRB,
(V)PINSRD, (V)PINSRW, (V)PINSRQ, (V)RCPSS, (V)RSQRTSS, (V)PMOVSX/ZX

2-28 Vol. 2A
INSTRUCTION FORMAT
(*) - Additional exception restrictions are present - see the Instruction description
for details
(**) - Instruction behavior on alignment check reporting with mask bits of less than
all 1s are the same as with mask bits of all 1s, i.e. no alignment checks are per-
formed.
Table 2-14 classifies exception behaviors for AVX instructions. Within each class of
exception conditions that are listed in Table 2-17 through Table 2-23, certain subsets
of AVX instructions may be subject to #UD exception depending on the encoded
value of the VEX.L field. Table 2-16 provides supplemental information of AVX
instructions that may be subject to #UD exception if encoded with incorrect values in
the VEX.W or VEX.L field.
Table 2-15. #UD Exception and VEX.W=1 Encoding
Type 6
VEXTRACTF128, VPERMILPD, VPERMILPS, VPERM2F128, VBROADCASTSS,
VBROADCASTSD, VBROADCASTF128, VINSERTF128, VMASKMOVPS**,
VMASKMOVPD**
Type 7
(V)MOVLHPS, (V)MOVHLPS, (V)MOVMSKPD, (V)MOVMSKPS, (V)PMOVMSKB,
(V)PSLLDQ, (V)PSRLDQ, (V)PSLLW, (V)PSLLD, (V)PSLLQ, (V)PSRAW,
(V)PSRAD, (V)PSRLW, (V)PSRLD, (V)PSRLQ
Type 8 VZEROALL, VZEROUPPER
Type 9 VLDMXCSR*, VSTMXCSR
Exception Class #UD If VEX.W = 1 in all modes #UD If VEX.W = 1 in
non-64-bit modes
Type 1
Type 2
Type 3
Type 4 VBLENDVPD, VBLENDVPS, VPBLENDVB,
VTESTPD, VTESTPS
Type 5 VPEXTRQ, VPINSRQ,
Type 6
VEXTRACTF128, VPERMILPD, VPERMILPS,
VPERM2F128, VBROADCASTSS, VBROADCASTSD,
VBROADCASTF128, VINSERTF128,
VMASKMOVPS, VMASKMOVPD
Type 7
Type 8
Type 9
Exception Class Instruction

Vol. 2A 2-29
INSTRUCTION FORMAT
Table 2-16. #UD Exception and VEX.L Field Encoding
Exception Class #UD If VEX.L = 0 #UD If VEX.L = 1
Type 1 VMOVNTDQA
Type 2 VDPPD
Type 3
Type 4
VMASKMOVDQU, VMPSADBW, VPABSB/W/D,
VPACKSSWB/DW, VPACKUSWB/DW,
VPADDB/W/D, VPADDQ, VPADDSB/W,
VPADDUSB/W, VPALIGNR, VPAND, VPANDN,
VPAVGB/W, VPBLENDVB, VPBLENDW,
VPCMP(E/I)STRI/M, VPCMPEQB/W/D/Q,
VPCMPGTB/W/D/Q, VPHADDW/D, VPHADDSW,
VPHMINPOSUW, VPHSUBD/W, VPHSUBSW,
VPMADDWD, VPMADDUBSW, VPMAXSB/W/D,
VPMAXUB/W/D, VPMINSB/W/D, VPMINUB/W/D,
VPMULHUW, VPMULHRSW, VPMULHW/LW,
VPMULLD, VPMULUDQ, VPMULDQ, VPOR,
VPSADBW, VPSHUFB/D, VPSHUFHW/LW,
VPSIGNB/W/D, VPSLLW/D/Q, VPSRAW/D,
VPSRLW/D/Q, VPSUBB/W/D/Q, VPSUBSB/W,
VPUNPCKHBW/WD/DQ, VPUNPCKHQDQ,
VPUNPCKLBW/WD/DQ, VPUNPCKLQDQ, VPXOR
Type 5
VEXTRACTPS, VINSERTPS, VMOVD, VMOVQ,
VMOVLPD, VMOVLPS, VMOVHPD, VMOVHPS,
VPEXTRB, VPEXTRD, VPEXTRW, VPEXTRQ,
VPINSRB, VPINSRD, VPINSRW, VPINSRQ,
VPMOVSX/ZX
Type 6
VEXTRACTF128,
VPERM2F128,
VBROADCASTSD,
VBROADCASTF128,
VINSERTF128,
Type 7
VMOVLHPS, VMOVHLPS, VPMOVMSKB,
VPSLLDQ, VPSRLDQ, VPSLLW, VPSLLD, VPSLLQ,
VPSRAW, VPSRAD, VPSRLW, VPSRLD, VPSRLQ
Type 8
Type 9 VLDMXCSR, VSTMXCSR

2-30 Vol. 2A
INSTRUCTION FORMAT
2.4.1 Exceptions Type 1 (Aligned memory reference)
Table 2-17. Type 1 Class Exception Conditions
Exception
Real
Virtual 80x86
Protected and
Compatibility
64-bit
Cause of Exception
Invalid Opcode,
#UD
XX VEX prefix.
XX
VEX prefix:
If XCR0[2:1] != ‘11b’.
If CR4.OSXSAVE[bit 18]=0.
XXXX
Legacy SSE instruction:
If CR0.EM[bit 2] = 1.
If CR4.OSFXSR[bit 9] = 0.
X X X X If preceded by a LOCK prefix (F0H).
XX
If any REX, F2, F3, or 66 prefixes precede a VEX
prefix.
X X X X If any corresponding CPUID feature flag is ‘0’.
Device Not Avail-
able, #NM X X X X If CR0.TS[bit 3]=1.
Stack, SS(0)
X For an illegal address in the SS segment.
XIf a memory address referencing the SS segment
is in a non-canonical form.
General Protec-
tion, #GP(0)
XX
VEX.256: Memory operand is not 32-byte
aligned.
VEX.128: Memory operand is not 16-byte
aligned.
XXXX
Legacy SSE: Memory operand is not 16-byte
aligned.
XFor an illegal memory operand effective address
in the CS, DS, ES, FS or GS segments.
X If the memory address is in a non-canonical form.
XX If any part of the operand lies outside the effec-
tive address space from 0 to FFFFH.
Page Fault
#PF(fault-code) X X X For a page fault.
Vol. 2A 2-31
INSTRUCTION FORMAT
2.4.2 Exceptions Type 2 (>=16 Byte Memory Reference,
Unaligned)
Table 2-18. Type 2 Class Exception Conditions
Exception
Real
Virtual 8086
Protected and
Compatibility
64-bit
Cause of Exception
Invalid Opcode,
#UD
XX VEX prefix.
XX XX
If an unmasked SIMD floating-point exception and
CR4.OSXMMEXCPT[bit 10] = 0.
XX
VEX prefix:
If XCR0[2:1] != ‘11b’.
If CR4.OSXSAVE[bit 18]=0.
XX XX
Legacy SSE instruction:
If CR0.EM[bit 2] = 1.
If CR4.OSFXSR[bit 9] = 0.
X X X X If preceded by a LOCK prefix (F0H).
XX
If any REX, F2, F3, or 66 prefixes precede a VEX
prefix.
X X X X If any corresponding CPUID feature flag is ‘0’.
Device Not Avail-
able, #NM XX XXIf CR0.TS[bit 3]=1.
Stack, SS(0)
X For an illegal address in the SS segment.
XIf a memory address referencing the SS segment is
in a non-canonical form.
General Protec-
tion, #GP(0)
XX XX
Legacy SSE: Memory operand is not 16-byte
aligned.
XFor an illegal memory operand effective address in
the CS, DS, ES, FS or GS segments.
X If the memory address is in a non-canonical form.
XX If any part of the operand lies outside the effective
address space from 0 to FFFFH.
Page Fault
#PF(fault-code) X X X For a page fault.
SIMD Floating-
point Exception,
#XM
XX XX
If an unmasked SIMD floating-point exception and
CR4.OSXMMEXCPT[bit 10] = 1.
2-32 Vol. 2A
INSTRUCTION FORMAT
2.4.3 Exceptions Type 3 (<16 Byte memory argument)
Table 2-19. Type 3 Class Exception Conditions
Exception
Real
Virtual 80x86
Protected and
Compatibility
64-bit
Cause of Exception
Invalid Opcode, #UD
XX VEX prefix.
XXXX
If an unmasked SIMD floating-point exception
and CR4.OSXMMEXCPT[bit 10] = 0.
XX
VEX prefix:
If XCR0[2:1] != ‘11b’.
If CR4.OSXSAVE[bit 18]=0.
XXXX
Legacy SSE instruction:
If CR0.EM[bit 2] = 1.
If CR4.OSFXSR[bit 9] = 0.
X X X X If preceded by a LOCK prefix (F0H).
XX
If any REX, F2, F3, or 66 prefixes precede a
VEX prefix.
X X X X If any corresponding CPUID feature flag is ‘0’.
Device Not Available,
#NM X X X X If CR0.TS[bit 3]=1.
Stack, SS(0)
X For an illegal address in the SS segment.
XIf a memory address referencing the SS seg-
ment is in a non-canonical form.
General Protection,
#GP(0)
XFor an illegal memory operand effective
address in the CS, DS, ES, FS or GS segments.
XIf the memory address is in a non-canonical
form.
XX If any part of the operand lies outside the
effective address space from 0 to FFFFH.
Page Fault
#PF(fault-code) X X X For a page fault.
Alignment Check
#AC(0) XXX
If alignment checking is enabled and an
unaligned memory reference is made while
the current privilege level is 3.
SIMD Floating-point
Exception, #XM XXXX
If an unmasked SIMD floating-point exception
and CR4.OSXMMEXCPT[bit 10] = 1.
Vol. 2A 2-33
INSTRUCTION FORMAT
2.4.4 Exceptions Type 4 (>=16 Byte mem arg no alignment, no
floating-point exceptions)
Table 2-20. Type 4 Class Exception Conditions
Exception
Real
Virtual 80x86
Protected and
Compatibility
64-bit
Cause of Exception
Invalid Opcode, #UD
XX VEX prefix.
XX
VEX prefix:
If XCR0[2:1] != ‘11b’.
If CR4.OSXSAVE[bit 18]=0.
XXXX
Legacy SSE instruction:
If CR0.EM[bit 2] = 1.
If CR4.OSFXSR[bit 9] = 0.
X X X X If preceded by a LOCK prefix (F0H).
XX
If any REX, F2, F3, or 66 prefixes precede a
VEX prefix.
X X X X If any corresponding CPUID feature flag is ‘0’.
Device Not Available,
#NM XXXXIf CR0.TS[bit 3]=1.
Stack, SS(0)
X For an illegal address in the SS segment.
XIf a memory address referencing the SS seg-
ment is in a non-canonical form.
General Protection,
#GP(0)
XXXX
Legacy SSE: Memory operand is not 16-byte
aligned.
XFor an illegal memory operand effective
address in the CS, DS, ES, FS or GS segments.
XIf the memory address is in a non-canonical
form.
XX If any part of the operand lies outside the
effective address space from 0 to FFFFH.
Page Fault
#PF(fault-code) X X X For a page fault.
2-34 Vol. 2A
INSTRUCTION FORMAT
2.4.5 Exceptions Type 5 (<16 Byte mem arg and no FP exceptions)
Table 2-21. Type 5 Class Exception Conditions
Exception
Real
Virtual 80x86
Protected and
Compatibility
64-bit
Cause of Exception
Invalid Opcode, #UD
XX VEX prefix.
XX
VEX prefix:
If XCR0[2:1] != ‘11b’.
If CR4.OSXSAVE[bit 18]=0.
XXXX
Legacy SSE instruction:
If CR0.EM[bit 2] = 1.
If CR4.OSFXSR[bit 9] = 0.
X X X X If preceded by a LOCK prefix (F0H).
XX
If any REX, F2, F3, or 66 prefixes precede a
VEX prefix.
X X X X If any corresponding CPUID feature flag is ‘0’.
Device Not Available,
#NM X X X X If CR0.TS[bit 3]=1.
Stack, SS(0)
X For an illegal address in the SS segment.
XIf a memory address referencing the SS seg-
ment is in a non-canonical form.
General Protection,
#GP(0)
XFor an illegal memory operand effective
address in the CS, DS, ES, FS or GS segments.
XIf the memory address is in a non-canonical
form.
XX If any part of the operand lies outside the
effective address space from 0 to FFFFH.
Page Fault
#PF(fault-code) X X X For a page fault.
Alignment Check
#AC(0) XXX
If alignment checking is enabled and an
unaligned memory reference is made while
the current privilege level is 3.

Vol. 2A 2-35
INSTRUCTION FORMAT
2.4.6 Exceptions Type 6 (VEX-Encoded Instructions Without
Legacy SSE Analogues)
Note: At present, the AVX instructions in this category do not generate floating-point
exceptions.
Table 2-22. Type 6 Class Exception Conditions
Exception
Real
Virtual 80x86
Protected and
Compatibility
64-bit
Cause of Exception
Invalid Opcode, #UD
XX VEX prefix.
XX
If XCR0[2:1] != ‘11b’.
If CR4.OSXSAVE[bit 18]=0.
X X If preceded by a LOCK prefix (F0H).
XX
If any REX, F2, F3, or 66 prefixes precede a
VEX prefix.
X X If any corresponding CPUID feature flag is ‘0’.
Device Not Available,
#NM XXIf CR0.TS[bit 3]=1.
Stack, SS(0)
X For an illegal address in the SS segment.
XIf a memory address referencing the SS seg-
ment is in a non-canonical form.
General Protection,
#GP(0)
XFor an illegal memory operand effective
address in the CS, DS, ES, FS or GS segments.
XIf the memory address is in a non-canonical
form.
Page Fault
#PF(fault-code) X X For a page fault.
Alignment Check
#AC(0) XX
For 4 or 8 byte memory references if align-
ment checking is enabled and an unaligned
memory reference is made while the current
privilege level is 3.
2-36 Vol. 2A
INSTRUCTION FORMAT
2.4.7 Exceptions Type 7 (No FP exceptions, no memory arg)
Table 2-23. Type 7 Class Exception Conditions
Exception
Real
Virtual 80x86
Protected and
Compatibility
64-bit
Cause of Exception
Invalid Opcode, #UD
XX VEX prefix.
XX
VEX prefix:
If XCR0[2:1] != ‘11b’.
If CR4.OSXSAVE[bit 18]=0.
XXXX
Legacy SSE instruction:
If CR0.EM[bit 2] = 1.
If CR4.OSFXSR[bit 9] = 0.
X X X X If preceded by a LOCK prefix (F0H).
XX
If any REX, F2, F3, or 66 prefixes precede a
VEX prefix.
X X X X If any corresponding CPUID feature flag is ‘0’.
Device Not Available,
#NM X X If CR0.TS[bit 3]=1.
Vol. 2A 2-37
INSTRUCTION FORMAT
2.4.8 Exceptions Type 8 (AVX and no memory argument)
Table 2-24. Type 8 Class Exception Conditions
Exception
Real
Virtual 80x86
Protected and
Compatibility
64-bit
Cause of Exception
Invalid Opcode, #UD X X Always in Real or Virtual 80x86 mode.
X X If XCR0[2:1] != ‘11b’.
If CR4.OSXSAVE[bit 18]=0.
If CPUID.01H.ECX.AVX[bit 28]=0.
If VEX.vvvv != 1111B.
X X X X If proceeded by a LOCK prefix (F0H).
Device Not Available,
#NM
X X If CR0.TS[bit 3]=1.
2-38 Vol. 2A
INSTRUCTION FORMAT
2.4.9 Exception Type 9 (Intel AVX)
Table 2-25. Type 9 Class Exception Conditions
Exception
Real
Virtual 80x86
Protected and
Compatibility
64-bit
Cause of Exception
Invalid Opcode, #UD
X X Always in Real or Virtual 80x86 mode.
XX
If CR4.OSXSAVE[bit 18]=0.
If CR0.EM[bit 2] = 1.
If CPUID.01H.ECX.AVX[bit 28]=0.
If VEX.L = 1.
X X If preceded by a LOCK prefix (F0H).
XX
If any REX, F2, F3, or 66 prefixes precede a
VEX prefix.
Device Not Available,
#NM X X If CR0.TS[bit 3]=1.
Stack, SS(0)
X For an illegal address in the SS segment.
XIf a memory address referencing the SS seg-
ment is in a non-canonical form.
General Protection,
#GP(0)
XFor an illegal memory operand effective
address in the CS, DS, ES, FS or GS segments.
XIf the memory address is in a non-canonical
form.
Page Fault
#PF(fault-code) X X For a page fault.
Alignment Check
#AC(0) XX
If alignment checking is enabled and an
unaligned memory reference is made while
the current privilege level is 3.
Vol. 2A 3-1
CHAPTER 3
INSTRUCTION SET REFERENCE, A-M
This chapter describes the instruction set for the Intel 64 and IA-32 architectures
(A-M) in IA-32e, protected, Virtual-8086, and real modes of operation. The set
includes general-purpose, x87 FPU, MMX, SSE/SSE2/SSE3/SSSE3/SSE4,
AESNI/PCLMULQDQ, AVX, and system instructions. See also Chapter 4, “Instruction
Set Reference, N-Z,” in the Intel® 64 and IA-32 Architectures Software Developer’s
Manual, Volume 2B.
For each instruction, each operand combination is described. A description of the
instruction and its operand, an operational description, a description of the effect of
the instructions on flags in the EFLAGS register, and a summary of exceptions that
can be generated are also provided.
3.1 INTERPRETING THE INSTRUCTION REFERENCE
PAGES
This section describes the format of information contained in the instruction refer-
ence pages in this chapter. It explains notational conventions and abbreviations used
in these sections.
3.1.1 Instruction Format
The following is an example of the format used for each instruction description in this
chapter. The heading below introduces the example. The table below provides an
example summary table.
CMC—Complement Carry Flag [this is an example]
Instruction Operand Encoding
Opcode Instruction Op/En 64/32-bit
Mode
CPUID
Feature Flag
Description
F5 CMC A V/V NA Complement carry flag.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA

3-2 Vol. 2A
INSTRUCTION SET REFERENCE, A-M
3.1.1.1 Opcode Column in the Instruction Summary Table (Instructions
without VEX prefix)
The “Opcode” column in the table above shows the object code produced for each
form of the instruction. When possible, codes are given as hexadecimal bytes in the
same order in which they appear in memory. Definitions of entries other than hexa-
decimal bytes are as follows:
•REX.W — Indicates the use of a REX prefix that affects operand size or
instruction semantics. The ordering of the REX prefix and other
optional/mandatory instruction prefixes are discussed Chapter 2. Note that REX
prefixes that promote legacy instructions to 64-bit behavior are not listed
explicitly in the opcode column.
•/digit — A digit between 0 and 7 indicates that the ModR/M byte of the
instruction uses only the r/m (register or memory) operand. The reg field
contains the digit that provides an extension to the instruction's opcode.
•/r — Indicates that the ModR/M byte of the instruction contains a register
operand and an r/m operand.
•cb, cw, cd, cp, co, ct — A 1-byte (cb), 2-byte (cw), 4-byte (cd), 6-byte (cp),
8-byte (co) or 10-byte (ct) value following the opcode. This value is used to
specify a code offset and possibly a new value for the code segment register.
•ib, iw, id, io — A 1-byte (ib), 2-byte (iw), 4-byte (id) or 8-byte (io) immediate
operand to the instruction that follows the opcode, ModR/M bytes or scale-
indexing bytes. The opcode determines if the operand is a signed value. All
words, doublewords and quadwords are given with the low-order byte first.
•+rb, +rw, +rd, +ro — A register code, from 0 through 7, added to the
hexadecimal byte given at the left of the plus sign to form a single opcode byte.
See Table 3-1 for the codes. The +ro columns in the table are applicable only in
64-bit mode.
•+i — A number used in floating-point instructions when one of the operands is
ST(i) from the FPU register stack. The number i (which can range from 0 to 7) is
added to the hexadecimal byte given at the left of the plus sign to form a single
opcode byte.
Vol. 2A 3-3
INSTRUCTION SET REFERENCE, A-M
Table 3-1. Register Codes Associated With +rb, +rw, +rd, +ro
byte register word register dword register quadword register
(64-Bit Mode only)
Register
REX.B
Reg Field
Register
REX.B
Reg Field
Register
REX.B
Reg Field
Register
REX.B
Reg Field
AL None 0 AX None 0 EAX None 0 RAX None 0
CL None 1 CX None 1 ECX None 1 RCX None 1
DL None 2 DX None 2 EDX None 2 RDX None 2
BL None 3 BX None 3 EBX None 3 RBX None 3
AH Not
encod
able
(N.E.)
4 SP None 4 ESP None 4 N/A N/A N/A
CH N.E. 5 BP None 5 EBP None 5 N/A N/A N/A
DH N.E. 6 SI None 6 ESI None 6 N/A N/A N/A
BH N.E. 7 DI None 7 EDI None 7 N/A N/A N/A
SPL Yes 4 SP None 4 ESP None 4 RSP None 4
BPL Yes 5 BP None 5 EBP None 5 RBP None 5
SIL Yes 6 SI None 6 ESI None 6 RSI None 6
DIL Yes 7 DI None 7 EDI None 7 RDI None 7
Registers R8 - R15 (see below): Available in 64-Bit Mode Only
R8L Yes 0 R8W Yes 0 R8D Yes 0 R8 Yes 0
R9L Yes 1 R9W Yes 1 R9D Yes 1 R9 Yes 1
R10L Yes 2 R10W Yes 2 R10D Yes 2 R10 Yes 2
R11L Yes 3 R11W Yes 3 R11D Yes 3 R11 Yes 3
R12L Yes 4 R12W Yes 4 R12D Yes 4 R12 Yes 4
R13L Yes 5 R13W Yes 5 R13D Yes 5 R13 Yes 5
R14L Yes 6 R14W Yes 6 R14D Yes 6 R14 Yes 6
R15L Yes 7 R15W Yes 7 R15D Yes 7 R15 Yes 7

3-4 Vol. 2A
INSTRUCTION SET REFERENCE, A-M
3.1.1.2 Opcode Column in the Instruction Summary Table (Instructions
with VEX prefix)
In the Instruction Summary Table, the Opcode column presents each instruction
encoded using the VEX prefix in following form (including the modR/M byte if appli-
cable, the immediate byte if applicable):
VEX.[NDS].[128,256].[66,F2,F3].0F/0F3A/0F38.[W0,W1] opcode [/r]
[/ib,/is4]
•VEX: indicates the presence of the VEX prefix is required. The VEX prefix can be
encoded using the three-byte form (the first byte is C4H), or using the two-byte
form (the first byte is C5H). The two-byte form of VEX only applies to those
instructions that do not require the following fields to be encoded:
VEX.mmmmm, VEX.W, VEX.X, VEX.B. Refer to Section 2.3 for more detail on the
VEX prefix.
The encoding of various sub-fields of the VEX prefix is described using the
following notations:
—NDS, NDD, DDS: specifies that VEX.vvvv field is valid for the encoding of a
register operand:
•VEX.NDS: VEX.vvvv encodes the first source register in an instruction
syntax where the content of source registers will be preserved.
•VEX.NDD: VEX.vvvv encodes the destination register that cannot be
encoded by ModR/M:reg field.
•VEX.DDS: VEX.vvvv encodes the second source register in a three-
operand instruction syntax where the content of first source register will
be overwritten by the result.
•If none of NDS, NDD, and DDS is present, VEX.vvvv must be 1111b (i.e.
VEX.vvvv does not encode an operand). The VEX.vvvv field can be
encoded using either the 2-byte or 3-byte form of the VEX prefix.
—128,256: VEX.L field can be 0 (denoted by VEX.128 or VEX.LZ) or 1
(denoted by VEX.256). The VEX.L field can be encoded using either the 2-
byte or 3-byte form of the VEX prefix. The presence of the notation VEX.256
or VEX.128 in the opcode column should be interpreted as follows:
•If VEX.256 is present in the opcode column: The semantics of the
instruction must be encoded with VEX.L = 1. An attempt to encode this
instruction with VEX.L= 0 can result in one of two situations: (a) if
VEX.128 version is defined, the processor will behave according to the
defined VEX.128 behavior; (b) an #UD occurs if there is no VEX.128
version defined.
•If VEX.128 is present in the opcode column but there is no VEX.256
version defined for the same opcode byte: Two situations apply: (a) For
VEX-encoded, 128-bit SIMD integer instructions, software must encode
the instruction with VEX.L = 0. The processor will treat the opcode byte
encoded with VEX.L= 1 by causing an #UD exception; (b) For VEX-

Vol. 2A 3-5
INSTRUCTION SET REFERENCE, A-M
encoded, 128-bit packed floating-point instructions, software must
encode the instruction with VEX.L = 0. The processor will treat the opcode
byte encoded with VEX.L= 1 by causing an #UD exception (e.g.
VMOVLPS).
•If VEX.LIG is present in the opcode column: The VEX.L value is ignored.
This generally applies to VEX-encoded scalar SIMD floating-point instruc-
tions. Scalar SIMD floating-point instruction can be distinguished from
the mnemonic of the instruction. Generally, the last two letters of the
instruction mnemonic would be either “SS“, “SD“, or “SI“ for SIMD
floating-point conversion instructions.
•If VEX.LZ is present in the opcode column: The VEX.L must be encoded to
be 0B, an #UD occurs if VEX.L is not zero.
—66,F2,F3: The presence or absence of these values map to the VEX.pp field
encodings. If absent, this corresponds to VEX.pp=00B. If present, the corre-
sponding VEX.pp value affects the “opcode” byte in the same way as if a
SIMD prefix (66H, F2H or F3H) does to the ensuing opcode byte. Thus a non-
zero encoding of VEX.pp may be considered as an implied 66H/F2H/F3H
prefix. The VEX.pp field may be encoded using either the 2-byte or 3-byte
form of the VEX prefix.
—0F,0F3A,0F38: The presence maps to a valid encoding of the VEX.mmmmm
field. Only three encoded values of VEX.mmmmm are defined as valid, corre-
sponding to the escape byte sequence of 0FH, 0F3AH and 0F38H. The effect
of a valid VEX.mmmmm encoding on the ensuing opcode byte is same as if
the corresponding escape byte sequence on the ensuing opcode byte for non-
VEX encoded instructions. Thus a valid encoding of VEX.mmmmm may be
consider as an implies escape byte sequence of either 0FH, 0F3AH or 0F38H.
The VEX.mmmmm field must be encoded using the 3-byte form of VEX
prefix.
—0F,0F3A,0F38 and 2-byte/3-byte VEX. The presence of 0F3A and 0F38 in
the opcode column implies that opcode can only be encoded by the three-
byte form of VEX. The presence of 0F in the opcode column does not preclude
the opcode to be encoded by the two-byte of VEX if the semantics of the
opcode does not require any subfield of VEX not present in the two-byte form
of the VEX prefix.
—W0: VEX.W=0.
—W1: VEX.W=1.
— The presence of W0/W1 in the opcode column applies to two situations: (a) it
is treated as an extended opcode bit, (b) the instruction semantics support an
operand size promotion to 64-bit of a general-purpose register operand or a
32-bit memory operand. The presence of W1 in the opcode column implies
the opcode must be encoded using the 3-byte form of the VEX prefix. The
presence of W0 in the opcode column does not preclude the opcode to be
encoded using the C5H form of the VEX prefix, if the semantics of the opcode

3-6 Vol. 2A
INSTRUCTION SET REFERENCE, A-M
does not require other VEX subfields not present in the two-byte form of the
VEX prefix. Please see Section 2.3 on the subfield definitions within VEX.
—WIG: can use C5H form (if not requiring VEX.mmmmm) or VEX.W value is
ignored in the C4H form of VEX prefix.
— If WIG is present, the instruction may be encoded using either the two-byte
form or the three-byte form of VEX. When encoding the instruction using the
three-byte form of VEX, the value of VEX.W is ignored.
•opcode: Instruction opcode.
•/is4: An 8-bit immediate byte is present containing a source register specifier in
imm[7:4] and instruction-specific payload in imm[3:0].
•In general, the encoding o f VEX.R, VEX.X, VEX.B field are not shown explicitly in
the opcode column. The encoding scheme of VEX.R, VEX.X, VEX.B fields must
follow the rules defined in Section 2.3.
3.1.1.3 Instruction Column in the Opcode Summary Table
The “Instruction” column gives the syntax of the instruction statement as it would
appear in an ASM386 program. The following is a list of the symbols used to repre-
sent operands in the instruction statements:
•rel8 — A relative address in the range from 128 bytes before the end of the
instruction to 127 bytes after the end of the instruction.
•rel16, rel32, rel64 — A relative address within the same code segment as the
instruction assembled. The rel16 symbol applies to instructions with an operand-
size attribute of 16 bits; the rel32 symbol applies to instructions with an
operand-size attribute of 32 bits; the rel64 symbol applies to instructions with an
operand-size attribute of 64 bits.
•ptr16:16, ptr16:32 and ptr16:64 — A far pointer, typically to a code segment
different from that of the instruction. The notation 16:16 indicates that the value
of the pointer has two parts. The value to the left of the colon is a 16-bit selector
or value destined for the code segment register. The value to the right
corresponds to the offset within the destination segment. The ptr16:16 symbol is
used when the instruction's operand-size attribute is 16 bits; the ptr16:32
symbol is used when the operand-size attribute is 32 bits; the ptr16:64 symbol is
used when the operand-size attribute is 64 bits.
•r8 — One of the byte general-purpose registers: AL, CL, DL, BL, AH, CH, DH, BH,
BPL, SPL, DIL and SIL; or one of the byte registers (R8L - R15L) available when
using REX.R and 64-bit mode.
•r16 — One of the word general-purpose registers: AX, CX, DX, BX, SP, BP, SI, DI;
or one of the word registers (R8-R15) available when using REX.R and 64-bit
mode.
•r32 — One of the doubleword general-purpose registers: EAX, ECX, EDX, EBX,
ESP, EBP, ESI, EDI; or one of the doubleword registers (R8D - R15D) available
when using REX.R in 64-bit mode.

Vol. 2A 3-7
INSTRUCTION SET REFERENCE, A-M
•r64 — One of the quadword general-purpose registers: RAX, RBX, RCX, RDX,
RDI, RSI, RBP, RSP, R8–R15. These are available when using REX.R and 64-bit
mode.
•imm8 — An immediate byte value. The imm8 symbol is a signed number
between –128 and +127 inclusive. For instructions in which imm8 is combined
with a word or doubleword operand, the immediate value is sign-extended to
form a word or doubleword. The upper byte of the word is filled with the topmost
bit of the immediate value.
•imm16 — An immediate word value used for instructions whose operand-size
attribute is 16 bits. This is a number between –32,768 and +32,767 inclusive.
•imm32 — An immediate doubleword value used for instructions whose
operand-size attribute is 32 bits. It allows the use of a number between
+2,147,483,647 and –2,147,483,648 inclusive.
•imm64 — An immediate quadword value used for instructions whose
operand-size attribute is 64 bits. The value allows the use of a number
between +9,223,372,036,854,775,807 and –9,223,372,036,854,775,808
inclusive.
•r/m8 — A byte operand that is either the contents of a byte general-purpose
register (AL, CL, DL, BL, AH, CH, DH, BH, BPL, SPL, DIL and SIL) or a byte from
memory. Byte registers R8L - R15L are available using REX.R in 64-bit mode.
•r/m16 — A word general-purpose register or memory operand used for instruc-
tions whose operand-size attribute is 16 bits. The word general-purpose registers
are: AX, CX, DX, BX, SP, BP, SI, DI. The contents of memory are found at the
address provided by the effective address computation. Word registers R8W -
R15W are available using REX.R in 64-bit mode.
•r/m32 — A doubleword general-purpose register or memory operand used for
instructions whose operand-size attribute is 32 bits. The doubleword general-
purpose registers are: EAX, ECX, EDX, EBX, ESP, EBP, ESI, EDI. The contents of
memory are found at the address provided by the effective address computation.
Doubleword registers R8D - R15D are available when using REX.R in 64-bit
mode.
•r/m64 — A quadword general-purpose register or memory operand used for
instructions whose operand-size attribute is 64 bits when using REX.W.
Quadword general-purpose registers are: RAX, RBX, RCX, RDX, RDI, RSI, RBP,
RSP, R8–R15; these are available only in 64-bit mode. The contents of memory
are found at the address provided by the effective address computation.
•m — A 16-, 32- or 64-bit operand in memory.
•m8 — A byte operand in memory, usually expressed as a variable or array name,
but pointed to by the DS:(E)SI or ES:(E)DI registers. In 64-bit mode, it is pointed
to by the RSI or RDI registers.
•m16 — A word operand in memory, usually expressed as a variable or array
name, but pointed to by the DS:(E)SI or ES:(E)DI registers. This nomenclature is
used only with the string instructions.

3-8 Vol. 2A
INSTRUCTION SET REFERENCE, A-M
•m32 — A doubleword operand in memory, usually expressed as a variable or
array name, but pointed to by the DS:(E)SI or ES:(E)DI registers. This nomen-
clature is used only with the string instructions.
•m64 — A memory quadword operand in memory.
•m128 — A memory double quadword operand in memory.
•m16:16, m16:32 & m16:64 — A memory operand containing a far pointer
composed of two numbers. The number to the left of the colon corresponds to the
pointer's segment selector. The number to the right corresponds to its offset.
•m16&32, m16&16, m32&32, m16&64 — A memory operand consisting of
data item pairs whose sizes are indicated on the left and the right side of the
ampersand. All memory addressing modes are allowed. The m16&16 and
m32&32 operands are used by the BOUND instruction to provide an operand
containing an upper and lower bounds for array indices. The m16&32 operand is
used by LIDT and LGDT to provide a word with which to load the limit field, and a
doubleword with which to load the base field of the corresponding GDTR and
IDTR registers. The m16&64 operand is used by LIDT and LGDT in 64-bit mode to
provide a word with which to load the limit field, and a quadword with which to
load the base field of the corresponding GDTR and IDTR registers.
•moffs8, moffs16, moffs32, moffs64 — A simple memory variable (memory
offset) of type byte, word, or doubleword used by some variants of the MOV
instruction. The actual address is given by a simple offset relative to the segment
base. No ModR/M byte is used in the instruction. The number shown with moffs
indicates its size, which is determined by the address-size attribute of the
instruction.
•Sreg — A segment register. The segment register bit assignments are ES = 0,
CS = 1, SS = 2, DS = 3, FS = 4, and GS = 5.
•m32fp, m64fp, m80fp — A single-precision, double-precision, and double
extended-precision (respectively) floating-point operand in memory. These
symbols designate floating-point values that are used as operands for x87 FPU
floating-point instructions.
•m16int, m32int, m64int — A word, doubleword, and quadword integer
(respectively) operand in memory. These symbols designate integers that are
used as operands for x87 FPU integer instructions.
•ST or ST(0) — The top element of the FPU register stack.
•ST(i) — The ith element from the top of the FPU register stack (i ← 0 through 7).
•mm — An MMX register. The 64-bit MMX registers are: MM0 through MM7.
•mm/m32 — The low order 32 bits of an MMX register or a 32-bit memory
operand. The 64-bit MMX registers are: MM0 through MM7. The contents of
memory are found at the address provided by the effective address computation.
•mm/m64 — An MMX register or a 64-bit memory operand. The 64-bit MMX
registers are: MM0 through MM7. The contents of memory are found at the
address provided by the effective address computation.

Vol. 2A 3-9
INSTRUCTION SET REFERENCE, A-M
•xmm — An XMM register. The 128-bit XMM registers are: XMM0 through XMM7;
XMM8 through XMM15 are available using REX.R in 64-bit mode.
•xmm/m32— An XMM register or a 32-bit memory operand. The 128-bit XMM
registers are XMM0 through XMM7; XMM8 through XMM15 are available using
REX.R in 64-bit mode. The contents of memory are found at the address provided
by the effective address computation.
•xmm/m64 — An XMM register or a 64-bit memory operand. The 128-bit SIMD
floating-point registers are XMM0 through XMM7; XMM8 through XMM15 are
available using REX.R in 64-bit mode. The contents of memory are found at the
address provided by the effective address computation.
•xmm/m128 — An XMM register or a 128-bit memory operand. The 128-bit XMM
registers are XMM0 through XMM7; XMM8 through XMM15 are available using
REX.R in 64-bit mode. The contents of memory are found at the address provided
by the effective address computation.
•<XMM0>— indicates implied use of the XMM0 register.
When there is ambiguity, xmm1 indicates the first source operand using an XMM
register and xmm2 the second source operand using an XMM register.
Some instructions use the XMM0 register as the third source operand, indicated
by <XMM0>. The use of the third XMM register operand is implicit in the instruc-
tion encoding and does not affect the ModR/M encoding.
•ymm — a YMM register. The 256-bit YMM registers are: YMM0 through YMM7;
YMM8 through YMM15 are available in 64-bit mode.
•m256 — A 32-byte operand in memory. This nomenclature is used only with AVX
instructions.
•ymm/m256 — a YMM register or 256-bit memory operand.
•<YMM0>— indicates use of the YMM0 register as an implicit argument.
•SRC1 — Denotes the first source operand in the instruction syntax of an
instruction encoded with the VEX prefix and having two or more source operands.
•SRC2 — Denotes the second source operand in the instruction syntax of an
instruction encoded with the VEX prefix and having two or more source operands.
•SRC3 — Denotes the third source operand in the instruction syntax of an
instruction encoded with the VEX prefix and having three source operands.
•SRC — The source in a AVX single-source instruction or the source in a Legacy
SSE instruction.
•DST — the destination in a AVX instruction. In Legacy SSE instructions can be
either the destination, first source, or both. This field is encoded by reg_field.
3.1.1.4 Operand Encoding Column in the Instruction Summary Table
The “operand encoding” column is abbreviated as Op/En in the Instruction Summary
table heading. Instruction operand encoding information is provided for each

3-10 Vol. 2A
INSTRUCTION SET REFERENCE, A-M
assembly instruction syntax using a letter to cross reference to a row entry in the
operand encoding definition table that follows the instruction summary table. The
operand encoding table in each instruction reference page lists each instruction
operand (according to each instruction syntax and operand ordering shown in the
instruction column) relative to the ModRM byte, VEX.vvvv field or additional operand
encoding placement.
NOTES
•The letters in the Op/En column of an instruction apply ONLY to
the encoding definition table immediately following the
instruction summary table.
•In the encoding definition table, the letter ‘r’ within a pair of
parenthesis denotes the content of the operand will be read by
the processor. The letter ‘w’ within a pair of parenthesis denotes
the content of the operand will be updated by the processor.
3.1.1.5 64/32-bit Mode Column in the Instruction Summary Table
The “64/32-bit Mode” column indicates whether the opcode sequence is supported in
(a) 64-bit mode or (b) the Compatibility mode and other IA-32 modes that apply in
conjunction with the CPUID feature flag associated specific instruction extensions.
The 64-bit mode support is to the left of the ‘slash’ and has the following notation:
•V — Supported.
•I — Not supported.
•N.E. — Indicates an instruction syntax is not encodable in 64-bit mode (it may
represent part of a sequence of valid instructions in other modes).
•N.P. — Indicates the REX prefix does not affect the legacy instruction in 64-bit
mode.
•N.I. — Indicates the opcode is treated as a new instruction in 64-bit mode.
•N.S. — Indicates an instruction syntax that requires an address override prefix in
64-bit mode and is not supported. Using an address override prefix in 64-bit
mode may result in model-specific execution behavior.
The Compatibility/Legacy Mode support is to the right of the ‘slash’ and has the fol-
lowing notation:
• V — Supported.
• I — Not supported.
• N.E. — Indicates an Intel 64 instruction mnemonics/syntax that is not encodable;
the opcode sequence is not applicable as an individual instruction in compatibility
mode or IA-32 mode. The opcode may represent a valid sequence of legacy IA-32
instructions.

Vol. 2A 3-11
INSTRUCTION SET REFERENCE, A-M
3.1.1.6 CPUID Support Column in the Instruction Summary Table
The fourth column holds abbreviated CPUID feature flags (e.g. appropriate bit in
CPUID.1.ECX, CPUID.1.EDX for SSE/SSE2/SSE3/SSSE3/SSE4.1/SSE4.2/AES-
NI/PCLMULQDQ/AVX support) that indicate processor support for the instruction.
If the corresponding flag is ‘0’, the instruction will #UD.
3.1.1.7 Description Column in the Instruction Summary Table
The “Description” column briefly explains forms of the instruction.
3.1.1.8 Description Section
Each instruction is then described by number of information sections. The “Descrip-
tion” section describes the purpose of the instructions and required operands in more
detail.
Summary of terms that may be used in the description section:
•Legacy SSE: Refers to SSE, SSE2, SSE3, SSSE3, SSE4, AESNI, PCLMULQDQ and
any future instruction sets referencing XMM registers and encoded without a VEX
prefix.
•VEX.vvvv. The VEX bitfield specifying a source or destination register (in 1’s
complement form).
•rm_field: shorthand for the ModR/M r/m field and any REX.B
•reg_field: shorthand for the ModR/M reg field and any REX.R
3.1.1.9 Operation Section
The “Operation” section contains an algorithm description (frequently written in
pseudo-code) for the instruction. Algorithms are composed of the following
elements:
•Comments are enclosed within the symbol pairs “(*” and “*)”.
•Compound statements are enclosed in keywords, such as: IF, THEN, ELSE and FI
for an if statement; DO and OD for a do statement; or CASE... OF for a case
statement.
•A register name implies the contents of the register. A register name enclosed in
brackets implies the contents of the location whose address is contained in that
register. For example, ES:[DI] indicates the contents of the location whose ES
segment relative address is in register DI. [SI] indicates the contents of the
address contained in register SI relative to the SI register’s default segment (DS)
or the overridden segment.
•Parentheses around the “E” in a general-purpose register name, such as (E)SI,
indicates that the offset is read from the SI register if the address-size attribute
is 16, from the ESI register if the address-size attribute is 32. Parentheses

3-12 Vol. 2A
INSTRUCTION SET REFERENCE, A-M
around the “R” in a general-purpose register name, (R)SI, in the presence of a
64-bit register definition such as (R)SI, indicates that the offset is read from the
64-bit RSI register if the address-size attribute is 64.
•Brackets are used for memory operands where they mean that the contents of
the memory location is a segment-relative offset. For example, [SRC] indicates
that the content of the source operand is a segment-relative offset.
•A ← B indicates that the value of B is assigned to A.
•The symbols =, ≠, >, <, ≥, and ≤ are relational operators used to compare two
values: meaning equal, not equal, greater or equal, less or equal, respectively. A
relational expression such as A ← B is TRUE if the value of A is equal to B;
otherwise it is FALSE.
•The expression “« COUNT” and “» COUNT” indicates that the destination operand
should be shifted left or right by the number of bits indicated by the count
operand.
The following identifiers are used in the algorithmic descriptions:
•OperandSize and AddressSize — The OperandSize identifier represents the
operand-size attribute of the instruction, which is 16, 32 or 64-bits. The
AddressSize identifier represents the address-size attribute, which is 16, 32 or
64-bits. For example, the following pseudo-code indicates that the operand-size
attribute depends on the form of the MOV instruction used.
IF Instruction ← MOVW
THEN OperandSize = 16;
ELSE
IF Instruction ← MOVD
THEN OperandSize = 32;
ELSE
IF Instruction ← MOVQ
THEN OperandSize = 64;
FI;
FI;
FI;
See “Operand-Size and Address-Size Attributes” in Chapter 3 of the Intel® 64
and IA-32 Architectures Software Developer’s Manual, Volume 1, for guidelines
on how these attributes are determined.
•StackAddrSize — Represents the stack address-size attribute associated with
the instruction, which has a value of 16, 32 or 64-bits. See “Address-Size
Attribute for Stack” in Chapter 6, “Procedure Calls, Interrupts, and Exceptions,” of
the Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 1.
•SRC — Represents the source operand.
•DEST — Represents the destination operand.
•VLMAX — The maximum vector register width pertaining to the instruction. This
is not the vector-length encoding in the instruction's prefix but is instead

Vol. 2A 3-13
INSTRUCTION SET REFERENCE, A-M
determined by the current value of XCR0. For existing processors, VLMAX is 256
whenever XCR0.YMM[bit 2] is 1. Future processors may defined new bits in XCR0
whose setting may imply other values for VLMAX.
VLMAX Definition
The following functions are used in the algorithmic descriptions:
•ZeroExtend(value) — Returns a value zero-extended to the operand-size
attribute of the instruction. For example, if the operand-size attribute is 32, zero
extending a byte value of –10 converts the byte from F6H to a doubleword value
of 000000F6H. If the value passed to the ZeroExtend function and the operand-
size attribute are the same size, ZeroExtend returns the value unaltered.
•SignExtend(value) — Returns a value sign-extended to the operand-size
attribute of the instruction. For example, if the operand-size attribute is 32, sign
extending a byte containing the value –10 converts the byte from F6H to a
doubleword value of FFFFFFF6H. If the value passed to the SignExtend function
and the operand-size attribute are the same size, SignExtend returns the value
unaltered.
•SaturateSignedWordToSignedByte — Converts a signed 16-bit value to a
signed 8-bit value. If the signed 16-bit value is less than –128, it is represented
by the saturated value -128 (80H); if it is greater than 127, it is represented by
the saturated value 127 (7FH).
•SaturateSignedDwordToSignedWord — Converts a signed 32-bit value to a
signed 16-bit value. If the signed 32-bit value is less than –32768, it is
represented by the saturated value –32768 (8000H); if it is greater than 32767,
it is represented by the saturated value 32767 (7FFFH).
•SaturateSignedWordToUnsignedByte — Converts a signed 16-bit value to an
unsigned 8-bit value. If the signed 16-bit value is less than zero, it is represented
by the saturated value zero (00H); if it is greater than 255, it is represented by
the saturated value 255 (FFH).
•SaturateToSignedByte — Represents the result of an operation as a signed
8-bit value. If the result is less than –128, it is represented by the saturated value
–128 (80H); if it is greater than 127, it is represented by the saturated value 127
(7FH).
•SaturateToSignedWord — Represents the result of an operation as a signed
16-bit value. If the result is less than –32768, it is represented by the saturated
value –32768 (8000H); if it is greater than 32767, it is represented by the
saturated value 32767 (7FFFH).
•SaturateToUnsignedByte — Represents the result of an operation as a signed
8-bit value. If the result is less than zero it is represented by the saturated value
XCR0 Component VLMAX
XCR0.YMM 256
3-14 Vol. 2A
INSTRUCTION SET REFERENCE, A-M
zero (00H); if it is greater than 255, it is represented by the saturated value 255
(FFH).
•SaturateToUnsignedWord — Represents the result of an operation as a signed
16-bit value. If the result is less than zero it is represented by the saturated value
zero (00H); if it is greater than 65535, it is represented by the saturated value
65535 (FFFFH).
•LowOrderWord(DEST * SRC) — Multiplies a word operand by a word operand
and stores the least significant word of the doubleword result in the destination
operand.
•HighOrderWord(DEST * SRC) — Multiplies a word operand by a word operand
and stores the most significant word of the doubleword result in the destination
operand.
•Push(value) — Pushes a value onto the stack. The number of bytes pushed is
determined by the operand-size attribute of the instruction. See the “Operation”
subsection of the “PUSH—Push Word, Doubleword or Quadword Onto the Stack”
section in Chapter 4 of the Intel® 64 and IA-32 Architectures Software
Developer’s Manual, Volume 2B.
•Pop() removes the value from the top of the stack and returns it. The statement
EAX ← Pop(); assigns to EAX the 32-bit value from the top of the stack. Pop will
return either a word, a doubleword or a quadword depending on the operand-size
attribute. See the “Operation” subsection in the “POP—Pop a Value from the
Stack” section of Chapter 4 of the Intel® 64 and IA-32 Architectures Software
Developer’s Manual, Volume 2B.
•PopRegisterStack — Marks the FPU ST(0) register as empty and increments
the FPU register stack pointer (TOP) by 1.
•Switch-Tasks — Performs a task switch.
•Bit(BitBase, BitOffset) — Returns the value of a bit within a bit string. The bit
string is a sequence of bits in memory or a register. Bits are numbered from low-
order to high-order within registers and within memory bytes. If the BitBase is a
register, the BitOffset can be in the range 0 to [15, 31, 63] depending on the
mode and register size. See Figure 3-1: the function Bit[RAX, 21] is illustrated.
Figure 3-1. Bit Offset for BIT[RAX, 21]
02131
Bit Offset ← 21
63
Vol. 2A 3-15
INSTRUCTION SET REFERENCE, A-M
If BitBase is a memory address, the BitOffset can range has different ranges
depending on the operand size (see Table 3-2).
The addressed bit is numbered (Offset MOD 8) within the byte at address
(BitBase + (BitOffset DIV 8)) where DIV is signed division with rounding towards
negative infinity and MOD returns a positive number (see Figure 3-2).
3.1.1.10 Intel® C/C++ Compiler Intrinsics Equivalents Section
The Intel C/C++ compiler intrinsics equivalents are special C/C++ coding extensions
that allow using the syntax of C function calls and C variables instead of hardware
registers. Using these intrinsics frees programmers from having to manage registers
and assembly programming. Further, the compiler optimizes the instruction sched-
uling so that executable run faster.
The following sections discuss the intrinsics API and the MMX technology and SIMD
floating-point intrinsics. Each intrinsic equivalent is listed with the instruction
description. There may be additional intrinsics that do not have an instruction equiv-
Table 3-2. Range of Bit Positions Specified by Bit Offset Operands
Operand Size Immediate BitOffset Register BitOffset
16 0 to 15 − 215 to 215 − 1
32 0 to 31 − 231 to 231 − 1
64 0 to 63 − 263 to 263 − 1
Figure 3-2. Memory Bit Indexing
BitBase +
07775 0 0
BitBase −
0777500
BitBase BitBase −
BitOffset ← +13
BitOffset ← −
BitBase − BitBase

3-16 Vol. 2A
INSTRUCTION SET REFERENCE, A-M
alent. It is strongly recommended that the reader reference the compiler documen-
tation for the complete list of supported intrinsics.
See Appendix C, “Intel® C/C++ Compiler Intrinsics and Functional Equivalents,” in
the Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 2B, for
more information on using intrinsics.
Intrinsics API
The benefit of coding with MMX technology intrinsics and the SSE/SSE2/SSE3 intrin-
sics is that you can use the syntax of C function calls and C variables instead of hard-
ware registers. This frees you from managing registers and programming assembly.
Further, the compiler optimizes the instruction scheduling so that your executable
runs faster. For each computational and data manipulation instruction in the new
instruction set, there is a corresponding C intrinsic that implements it directly. The
intrinsics allow you to specify the underlying implementation (instruction selection)
of an algorithm yet leave instruction scheduling and register allocation to the
compiler.
MMX™ Technology Intrinsics
The MMX technology intrinsics are based on a __m64 data type that represents the
specific contents of an MMX technology register. You can specify values in bytes,
short integers, 32-bit values, or a 64-bit object. The __m64 data type, however, is
not a basic ANSI C data type, and therefore you must observe the following usage
restrictions:
•Use __m64 data only on the left-hand side of an assignment, as a return value,
or as a parameter. You cannot use it with other arithmetic expressions (“+”, “>>”,
and so on).
•Use __m64 objects in aggregates, such as unions to access the byte elements
and structures; the address of an __m64 object may be taken.
•Use __m64 data only with the MMX technology intrinsics described in this manual
and Intel® C/C++ compiler documentation.
•See:
— http://www.intel.com/support/performancetools/
— Appendix C, “Intel® C/C++ Compiler Intrinsics and Functional Equivalents,”
in the Intel® 64 and IA-32 Architectures Software Developer’s Manual,
Volume 2B, for more information on using intrinsics.
— SSE/SSE2/SSE3 Intrinsics
— SSE/SSE2/SSE3 intrinsics all make use of the XMM registers of the Pentium
III, Pentium 4, and Intel Xeon processors. There are three data types
supported by these intrinsics: __m128, __m128d, and __m128i.

Vol. 2A 3-17
INSTRUCTION SET REFERENCE, A-M
•The __m128 data type is used to represent the contents of an XMM register used
by an SSE intrinsic. This is either four packed single-precision floating-point
values or a scalar single-precision floating-point value.
•The __m128d data type holds two packed double-precision floating-point values
or a scalar double-precision floating-point value.
•The __m128i data type can hold sixteen byte, eight word, or four doubleword, or
two quadword integer values.
The compiler aligns __m128, __m128d, and __m128i local and global data to
16-byte boundaries on the stack. To align integer, float, or double arrays, use the
declspec statement as described in Intel C/C++ compiler documentation. See
http://www.intel.com/support/performancetools/.
The __m128, __m128d, and __m128i data types are not basic ANSI C data types
and therefore some restrictions are placed on its usage:
•Use __m128, __m128d, and __m128i only on the left-hand side of an
assignment, as a return value, or as a parameter. Do not use it in other arithmetic
expressions such as “+” and “>>.”
•Do not initialize __m128, __m128d, and __m128i with literals; there is no way to
express 128-bit constants.
•Use __m128, __m128d, and __m128i objects in aggregates, such as unions (for
example, to access the float elements) and structures. The address of these
objects may be taken.
•Use __m128, __m128d, and __m128i data only with the intrinsics described in
this user’s guide. See Appendix C, “Intel® C/C++ Compiler Intrinsics and
Functional Equivalents,” in the Intel® 64 and IA-32 Architectures Software
Developer’s Manual, Volume 2B, for more information on using intrinsics.
The compiler aligns __m128, __m128d, and __m128i local data to 16-byte bound-
aries on the stack. Global __m128 data is also aligned on 16-byte boundaries. (To
align float arrays, you can use the alignment declspec described in the following
section.) Because the new instruction set treats the SIMD floating-point registers in
the same way whether you are using packed or scalar data, there is no __m32 data
type to represent scalar data as you might expect. For scalar operations, you should
use the __m128 objects and the “scalar” forms of the intrinsics; the compiler and the
processor implement these operations with 32-bit memory references.
The suffixes ps and ss are used to denote “packed single” and “scalar single” preci-
sion operations. The packed floats are represented in right-to-left order, with the
lowest word (right-most) being used for scalar operations: [z, y, x, w]. To explain
how memory storage reflects this, consider the following example.
The operation:
float a[4] ← { 1.0, 2.0, 3.0, 4.0 };
__m128 t ← _mm_load_ps(a);
Produces the same result as follows:

3-18 Vol. 2A
INSTRUCTION SET REFERENCE, A-M
__m128 t ← _mm_set_ps(4.0, 3.0, 2.0, 1.0);
In other words:
t ← [ 4.0, 3.0, 2.0, 1.0 ]
Where the “scalar” element is 1.0.
Some intrinsics are “composites” because they require more than one instruction to
implement them. You should be familiar with the hardware features provided by the
SSE, SSE2, SSE3, and MMX technology when writing programs with the intrinsics.
Keep the following important issues in mind:
•Certain intrinsics, such as _mm_loadr_ps and _mm_cmpgt_ss, are not directly
supported by the instruction set. While these intrinsics are convenient
programming aids, be mindful of their implementation cost.
•Data loaded or stored as __m128 objects must generally be 16-byte-aligned.
•Some intrinsics require that their argument be immediates, that is, constant
integers (literals), due to the nature of the instruction.
•The result of arithmetic operations acting on two NaN (Not a Number) arguments
is undefined. Therefore, floating-point operations using NaN arguments may not
match the expected behavior of the corresponding assembly instructions.
For a more detailed description of each intrinsic and additional information related to
its usage, refer to Intel C/C++ compiler documentation. See:
— http://www.intel.com/support/performancetools/
— Appendix C, “Intel® C/C++ Compiler Intrinsics and Functional Equivalents,”
in the Intel® 64 and IA-32 Architectures Software Developer’s Manual,
Volume 2B, for more information on using intrinsics.
3.1.1.11 Flags Affected Section
The “Flags Affected” section lists the flags in the EFLAGS register that are affected by
the instruction. When a flag is cleared, it is equal to 0; when it is set, it is equal to 1.
The arithmetic and logical instructions usually assign values to the status flags in a
uniform manner (see Appendix A, “EFLAGS Cross-Reference,” in the Intel® 64 and
IA-32 Architectures Software Developer’s Manual, Volume 1). Non-conventional
assignments are described in the “Operation” section. The values of flags listed as
undefined may be changed by the instruction in an indeterminate manner. Flags
that are not listed are unchanged by the instruction.
3.1.1.12 FPU Flags Affected Section
The floating-point instructions have an “FPU Flags Affected” section that describes
how each instruction can affect the four condition code flags of the FPU status word.

Vol. 2A 3-19
INSTRUCTION SET REFERENCE, A-M
3.1.1.13 Protected Mode Exceptions Section
The “Protected Mode Exceptions” section lists the exceptions that can occur when the
instruction is executed in protected mode and the reasons for the exceptions. Each
exception is given a mnemonic that consists of a pound sign (#) followed by two
letters and an optional error code in parentheses. For example, #GP(0) denotes a
general protection exception with an error code of 0. Table 3-3 associates each two-
letter mnemonic with the corresponding interrupt vector number and exception
name. See Chapter 6, “Interrupt and Exception Handling,” in the Intel® 64 and IA-32
Architectures Software Developer’s Manual, Volume 3A, for a detailed description of
the exceptions.
Application programmers should consult the documentation provided with their oper-
ating systems to determine the actions taken when exceptions occur.
Table 3-3. Intel 64 and IA-32 General Exceptions
Vector
No.
Name Source Protected
Mode1Real
Address
Mode
Virtual
8086
Mode
0#DE—Divide ErrorDIV and IDIV instructions. Yes Yes Yes
1 #DB—Debug Any code or data reference. Yes Yes Yes
3 #BP—Breakpoint INT 3 instruction. Yes Yes Yes
4 #OF—Overflow INTO instruction. Yes Yes Yes
5 #BR—BOUND Range
Exceeded
BOUND instruction. Yes Yes Yes
6#UD—Invalid
Opcode (Undefined
Opcode)
UD2 instruction or reserved
opcode.
Yes Yes Yes
7 #NM—Device Not
Available (No Math
Coprocessor)
Floating-point or WAIT/FWAIT
instruction.
Yes Yes Yes
8 #DF—Double Fault Any instruction that can
generate an exception, an
NMI, or an INTR.
Yes Yes Yes
10 #TS—Invalid TSS Task switch or TSS access. Yes Reserved Yes
11 #NP—Segment Not
Present
Loading segment registers or
accessing system segments.
Yes Reserved Yes
12 #SS—Stack
Segment Fault
Stack operations and SS
register loads.
Yes Yes Yes
13 #GP—General
Protection2
Any memory reference and
other protection checks.
Yes Yes Yes

3-20 Vol. 2A
INSTRUCTION SET REFERENCE, A-M
3.1.1.14 Real-Address Mode Exceptions Section
The “Real-Address Mode Exceptions” section lists the exceptions that can occur when
the instruction is executed in real-address mode (see Table 3-3).
3.1.1.15 Virtual-8086 Mode Exceptions Section
The “Virtual-8086 Mode Exceptions” section lists the exceptions that can occur when
the instruction is executed in virtual-8086 mode (see Table 3-3).
3.1.1.16 Floating-Point Exceptions Section
The “Floating-Point Exceptions” section lists exceptions that can occur when an x87
FPU floating-point instruction is executed. All of these exception conditions result in
a floating-point error exception (#MF, vector number 16) being generated. Table 3-4
associates a one- or two-letter mnemonic with the corresponding exception name.
See “Floating-Point Exception Conditions” in Chapter 8 of the Intel® 64 and IA-32
Architectures Software Developer’s Manual, Volume 1, for a detailed description of
these exceptions.
14 #PF—Page Fault Any memory reference. Yes Reserved Yes
16 #MF—Floating-Point
Error (Math Fault)
Floating-point or WAIT/FWAIT
instruction.
Yes Yes Yes
17 #AC—Alignment
Check
Any data reference in
memory.
Yes Reserved Yes
18 #MC—Machine
Check
Model dependent machine
check errors.
Yes Yes Yes
19 #XM—SIMD
Floating-Point
Numeric Error
SSE/SSE2/SSE3 floating-point
instructions.
Yes Yes Yes
NOTES:
1. Apply to protected mode, compatibility mode, and 64-bit mode.
2. In the real-address mode, vector 13 is the segment overrun exception.
Table 3-4. x87 FPU Floating-Point Exceptions
Mnemonic Name Source
Table 3-3. Intel 64 and IA-32 General Exceptions (Contd.)
Vector
No.
Name Source Protected
Mode1Real
Address
Mode
Virtual
8086
Mode
Vol. 2A 3-21
INSTRUCTION SET REFERENCE, A-M
3.1.1.17 SIMD Floating-Point Exceptions Section
The “SIMD Floating-Point Exceptions” section lists exceptions that can occur when an
SSE/SSE2/SSE3 floating-point instruction is executed. All of these exception condi-
tions result in a SIMD floating-point error exception (#XM, vector number 19) being
generated. Table 3-5 associates a one-letter mnemonic with the corresponding
exception name. For a detailed description of these exceptions, refer to ”SSE and
SSE2 Exceptions”, in Chapter 11 of the Intel® 64 and IA-32 Architectures Software
Developer’s Manual, Volume 1.
3.1.1.18 Compatibility Mode Exceptions Section
This section lists exceptions that occur within compatibility mode.
3.1.1.19 64-Bit Mode Exceptions Section
This section lists exceptions that occur within 64-bit mode.
#IS
#IA
Floating-point invalid operation:
- Stack overflow or underflow
- Invalid arithmetic operation
- x87 FPU stack overflow or underflow
- Invalid FPU arithmetic operation
#Z Floating-point divide-by-zero Divide-by-zero
#D Floating-point denormal operand Source operand that is a denormal number
#O Floating-point numeric overflow Overflow in result
#U Floating-point numeric underflow Underflow in result
#P Floating-point inexact result
(precision)
Inexact result (precision)
Table 3-5. SIMD Floating-Point Exceptions
Mnemonic Name Source
#I Floating-point invalid operation Invalid arithmetic operation or source operand
#Z Floating-point divide-by-zero Divide-by-zero
#D Floating-point denormal operand Source operand that is a denormal number
#O Floating-point numeric overflow Overflow in result
#U Floating-point numeric underflow Underflow in result
#P Floating-point inexact result Inexact result (precision)
Table 3-4. x87 FPU Floating-Point Exceptions

3-22 Vol. 2A
INSTRUCTION SET REFERENCE, A-M
3.2 INSTRUCTIONS (A-M)
The remainder of this chapter provides descriptions of Intel 64 and IA-32 instructions
(A-M). See also: Chapter 4, “Instruction Set Reference, N-Z,” in the Intel® 64 and
IA-32 Architectures Software Developer’s Manual, Volume 2B.

Vol. 2A 3-23
INSTRUCTION SET REFERENCE, A-M
AAA—ASCII Adjust After Addition
AAA—ASCII Adjust After Addition
Instruction Operand Encoding
Description
Adjusts the sum of two unpacked BCD values to create an unpacked BCD result. The
AL register is the implied source and destination operand for this instruction. The AAA
instruction is only useful when it follows an ADD instruction that adds (binary addi-
tion) two unpacked BCD values and stores a byte result in the AL register. The AAA
instruction then adjusts the contents of the AL register to contain the correct 1-digit
unpacked BCD result.
If the addition produces a decimal carry, the AH register increments by 1, and the CF
and AF flags are set. If there was no decimal carry, the CF and AF flags are cleared
and the AH register is unchanged. In either case, bits 4 through 7 of the AL register
are set to 0.
This instruction executes as described in compatibility mode and legacy mode. It is
not valid in 64-bit mode.
Operation
IF 64-Bit Mode
THEN
#UD;
ELSE
IF ((AL AND 0FH) > 9) or (AF = 1)
THEN
AL ← AL + 6;
AH ← AH + 1;
AF ← 1;
CF ← 1;
AL ← AL AND 0FH;
ELSE
AF ← 0;
CF ← 0;
AL ← AL AND 0FH;
FI;
Opcode Instruction Op/
En
64-bit
Mode
Compat/
Leg Mode
Description
37 AAA A Invalid Valid ASCII adjust AL after
addition.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA

3-24 Vol. 2A AAA—ASCII Adjust After Addition
INSTRUCTION SET REFERENCE, A-M
FI;
Flags Affected
The AF and CF flags are set to 1 if the adjustment results in a decimal carry; other-
wise they are set to 0. The OF, SF, ZF, and PF flags are undefined.
Protected Mode Exceptions
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as protected mode.
Compatibility Mode Exceptions
Same exceptions as protected mode.
64-Bit Mode Exceptions
#UD If in 64-bit mode.
Vol. 2A 3-25
INSTRUCTION SET REFERENCE, A-M
AAD—ASCII Adjust AX Before Division
AAD—ASCII Adjust AX Before Division
Instruction Operand Encoding
Description
Adjusts two unpacked BCD digits (the least-significant digit in the AL register and the
most-significant digit in the AH register) so that a division operation performed on
the result will yield a correct unpacked BCD value. The AAD instruction is only useful
when it precedes a DIV instruction that divides (binary division) the adjusted value in
the AX register by an unpacked BCD value.
The AAD instruction sets the value in the AL register to (AL + (10 * AH)), and then
clears the AH register to 00H. The value in the AX register is then equal to the binary
equivalent of the original unpacked two-digit (base 10) number in registers AH
and AL.
The generalized version of this instruction allows adjustment of two unpacked digits
of any number base (see the “Operation” section below), by setting the imm8 byte to
the selected number base (for example, 08H for octal, 0AH for decimal, or 0CH for
base 12 numbers). The AAD mnemonic is interpreted by all assemblers to mean
adjust ASCII (base 10) values. To adjust values in another number base, the instruc-
tion must be hand coded in machine code (D5 imm8).
This instruction executes as described in compatibility mode and legacy mode. It is
not valid in 64-bit mode.
Operation
IF 64-Bit Mode
THEN
#UD;
ELSE
tempAL ← AL;
tempAH ← AH;
AL ← (tempAL + (tempAH ∗ imm8)) AND FFH;
(* imm8 is set to 0AH for the AAD mnemonic.*)
Opcode Instruction Op/
En
64-bit
Mode
Compat/
Leg Mode
Description
D5 0A AAD A Invalid Valid ASCII adjust AX before
division.
D5 ib (No mnemonic) A Invalid Valid Adjust AX before division to
number base imm8.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA

3-26 Vol. 2A AAD—ASCII Adjust AX Before Division
INSTRUCTION SET REFERENCE, A-M
AH ← 0;
FI;
The immediate value (imm8) is taken from the second byte of the instruction.
Flags Affected
The SF, ZF, and PF flags are set according to the resulting binary value in the AL
register; the OF, AF, and CF flags are undefined.
Protected Mode Exceptions
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as protected mode.
Compatibility Mode Exceptions
Same exceptions as protected mode.
64-Bit Mode Exceptions
#UD If in 64-bit mode.
Vol. 2A 3-27
INSTRUCTION SET REFERENCE, A-M
AAM—ASCII Adjust AX After Multiply
AAM—ASCII Adjust AX After Multiply
Instruction Operand Encoding
Description
Adjusts the result of the multiplication of two unpacked BCD values to create a pair
of unpacked (base 10) BCD values. The AX register is the implied source and desti-
nation operand for this instruction. The AAM instruction is only useful when it follows
an MUL instruction that multiplies (binary multiplication) two unpacked BCD values
and stores a word result in the AX register. The AAM instruction then adjusts the
contents of the AX register to contain the correct 2-digit unpacked (base 10) BCD
result.
The generalized version of this instruction allows adjustment of the contents of the
AX to create two unpacked digits of any number base (see the “Operation” section
below). Here, the imm8 byte is set to the selected number base (for example, 08H
for octal, 0AH for decimal, or 0CH for base 12 numbers). The AAM mnemonic is inter-
preted by all assemblers to mean adjust to ASCII (base 10) values. To adjust to
values in another number base, the instruction must be hand coded in machine code
(D4 imm8).
This instruction executes as described in compatibility mode and legacy mode. It is
not valid in 64-bit mode.
Operation
IF 64-Bit Mode
THEN
#UD;
ELSE
tempAL ← AL;
AH ← tempAL / imm8; (* imm8 is set to 0AH for the AAM mnemonic *)
AL ← tempAL MOD imm8;
FI;
The immediate value (imm8) is taken from the second byte of the instruction.
Opcode Instruction Op/
En
64-bit
Mode
Compat/
Leg Mode
Description
D4 0A AAM A Invalid Valid ASCII adjust AX after
multiply.
D4 ib (No mnemonic) A Invalid Valid Adjust AX after multiply to
number base imm8.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA

3-28 Vol. 2A AAM—ASCII Adjust AX After Multiply
INSTRUCTION SET REFERENCE, A-M
Flags Affected
The SF, ZF, and PF flags are set according to the resulting binary value in the AL
register. The OF, AF, and CF flags are undefined.
Protected Mode Exceptions
#DE If an immediate value of 0 is used.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as protected mode.
Compatibility Mode Exceptions
Same exceptions as protected mode.
64-Bit Mode Exceptions
#UD If in 64-bit mode.

Vol. 2A 3-29
INSTRUCTION SET REFERENCE, A-M
AAS—ASCII Adjust AL After Subtraction
AAS—ASCII Adjust AL After Subtraction
Instruction Operand Encoding
Description
Adjusts the result of the subtraction of two unpacked BCD values to create a
unpacked BCD result. The AL register is the implied source and destination operand
for this instruction. The AAS instruction is only useful when it follows a SUB instruc-
tion that subtracts (binary subtraction) one unpacked BCD value from another and
stores a byte result in the AL register. The AAA instruction then adjusts the contents
of the AL register to contain the correct 1-digit unpacked BCD result.
If the subtraction produced a decimal carry, the AH register decrements by 1, and the
CF and AF flags are set. If no decimal carry occurred, the CF and AF flags are cleared,
and the AH register is unchanged. In either case, the AL register is left with its top
four bits set to 0.
This instruction executes as described in compatibility mode and legacy mode. It is
not valid in 64-bit mode.
Operation
IF 64-bit mode
THEN
#UD;
ELSE
IF ((AL AND 0FH) > 9) or (AF = 1)
THEN
AL ← AL – 6;
AH ← AH – 1;
AF ← 1;
CF ← 1;
AL ← AL AND 0FH;
ELSE
CF ← 0;
AF ← 0;
AL ← AL AND 0FH;
Opcode Instruction Op/
En
64-bit
Mode
Compat/
Leg Mode
Description
3F AAS A Invalid Valid ASCII adjust AL after
subtraction.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA

3-30 Vol. 2A AAS—ASCII Adjust AL After Subtraction
INSTRUCTION SET REFERENCE, A-M
FI;
FI;
Flags Affected
The AF and CF flags are set to 1 if there is a decimal borrow; otherwise, they are
cleared to 0. The OF, SF, ZF, and PF flags are undefined.
Protected Mode Exceptions
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as protected mode.
Compatibility Mode Exceptions
Same exceptions as protected mode.
64-Bit Mode Exceptions
#UD If in 64-bit mode.

Vol. 2A 3-31
INSTRUCTION SET REFERENCE, A-M
ADC—Add with Carry
ADC—Add with Carry
Opcode Instruction Op/
En
64-bit
Mode
Compat/
Leg Mode
Description
14 ib ADC AL, imm8 CValid Valid Add with carry imm8 to AL.
15 iw ADC AX, imm16 CValid Valid Add with carry imm16 to
AX.
15 id ADC EAX, imm32 CValid Valid Add with carry imm32 to
EAX.
REX.W + 15 id ADC RAX, imm32 CValid N.E. Add with carry imm32 sign
extended to 64-bits to RAX.
80 /2 ib ADC r/m8, imm8 BValid Valid Add with carry imm8 to
r/m8.
REX + 80 /2 ib ADC r/m8*, imm8 BValid N.E. Add with carry imm8 to
r/m8.
81 /2 iw ADC r/m16,
imm16
BValid Valid Add with carry imm16 to
r/m16.
81 /2 id ADC r/m32,
imm32
B Valid Valid Add with CF imm32 to
r/m32.
REX.W + 81 /2
id
ADC r/m64,
imm32
B Valid N.E. Add with CF imm32 sign
extended to 64-bits to
r/m64.
83 /2 ib ADC r/m16, imm8 B Valid Valid Add with CF sign-extended
imm8 to r/m16.
83 /2 ib ADC r/m32, imm8 B Valid Valid Add with CF sign-extended
imm8 into r/m32.
REX.W + 83 /2
ib
ADC r/m64, imm8 B Valid N.E. Add with CF sign-extended
imm8 into r/m64.
10 /rADC r/m8, r8 A Valid Valid Add with carry byte register
to r/m8.
REX + 10 /rADC r/m8*, r8*A Valid N.E. Add with carry byte register
to r/m64.
11 /rADC r/m16, r16 AValid Valid Add with carry r16 to
r/m16.
11 /rADC r/m32, r32 A Valid Valid Add with CF r32 to r/m32.
REX.W + 11 /rADC r/m64, r64 A Valid N.E. Add with CF r64 to r/m64.
12 /rADC r8, r/m8 A Valid Valid Add with carry r/m8 to byte
register.
REX + 12 /rADC r8*, r/m8*AValid N.E. Add with carry r/m64 to
byte register.
3-32 Vol. 2A ADC—Add with Carry
INSTRUCTION SET REFERENCE, A-M
Instruction Operand Encoding
Description
Adds the destination operand (first operand), the source operand (second operand),
and the carry (CF) flag and stores the result in the destination operand. The destina-
tion operand can be a register or a memory location; the source operand can be an
immediate, a register, or a memory location. (However, two memory operands
cannot be used in one instruction.) The state of the CF flag represents a carry from a
previous addition. When an immediate value is used as an operand, it is sign-
extended to the length of the destination operand format.
The ADC instruction does not distinguish between signed or unsigned operands.
Instead, the processor evaluates the result for both data types and sets the OF and
CF flags to indicate a carry in the signed or unsigned result, respectively. The SF flag
indicates the sign of the signed result.
The ADC instruction is usually executed as part of a multibyte or multiword addition
in which an ADD instruction is followed by an ADC instruction.
This instruction can be used with a LOCK prefix to allow the instruction to be
executed atomically.
In 64-bit mode, the instruction’s default operation size is 32 bits. Using a REX prefix
in the form of REX.R permits access to additional registers (R8-R15). Using a REX
prefix in the form of REX.W promotes operation to 64 bits. See the summary chart at
the beginning of this section for encoding data and limits.
Operation
DEST ← DEST + SRC + CF;
Opcode Instruction Op/
En
64-bit
Mode
Compat/
Leg Mode
Description
13 /rADC r16, r/m16 AValid Valid Add with carry r/m16 to
r16.
13 /rADC r32, r/m32 AValid Valid Add with CF r/m32 to r32.
REX.W + 13 /rADC r64, r/m64 AValid N.E. Add with CF r/m64 to r64.
NOTES:
*In 64-bit mode, r/m8 can not be encoded to access the following byte registers if a REX prefix is
used: AH, BH, CH, DH.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (r, w) ModRM:reg (r) NA NA
B ModRM:r/m (r, w) imm8 NA NA
C AL/AX/EAX/RAX imm8 NA NA

Vol. 2A 3-33
INSTRUCTION SET REFERENCE, A-M
ADC—Add with Carry
Flags Affected
The OF, SF, ZF, AF, CF, and PF flags are set according to the result.
Protected Mode Exceptions
#GP(0) If the destination is located in a non-writable segment.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register is used to access memory and it
contains a NULL segment selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used but the destination is not a memory
operand.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#UD If the LOCK prefix is used but the destination is not a memory
operand.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used but the destination is not a memory
operand.
Compatibility Mode Exceptions
Same exceptions as in protected mode.

3-34 Vol. 2A ADC—Add with Carry
INSTRUCTION SET REFERENCE, A-M
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used but the destination is not a memory
operand.

Vol. 2A 3-35
INSTRUCTION SET REFERENCE, A-M
ADD—Add
ADD—Add
Opcode Instruction Op/
En
64-bit
Mode
Compat/
Leg Mode
Description
04 ib ADD AL, imm8 C Valid Valid Add imm8 to AL.
05 iw ADD AX, imm16 C Valid Valid Add imm16 to AX.
05 id ADD EAX, imm32 C Valid Valid Add imm32 to EAX.
REX.W + 05 id ADD RAX, imm32 C Valid N.E. Add imm32 sign-extended
to 64-bits to RAX.
80 /0 ib ADD r/m8, imm8 B Valid Valid Add imm8 to r/m8.
REX + 80 /0 ib ADD r/m8*, imm8 B Valid N.E. Add sign-extended imm8 to
r/m64.
81 /0 iw ADD r/m16,
imm16
B Valid Valid Add imm16 to r/m16.
81 /0 id ADD r/m32,
imm32
B Valid Valid Add imm32 to r/m32.
REX.W + 81 /0
id
ADD r/m64,
imm32
B Valid N.E. Add imm32 sign-extended
to 64-bits to r/m64.
83 /0 ib ADD r/m16, imm8 B Valid Valid Add sign-extended imm8 to
r/m16.
83 /0 ib ADD r/m32, imm8 B Valid Valid Add sign-extended imm8 to
r/m32.
REX.W + 83 /0
ib
ADD r/m64, imm8 B Valid N.E. Add sign-extended imm8 to
r/m64.
00 /rADD r/m8, r8 A Valid Valid Add r8 to r/m8.
REX + 00 /rADD r/m8*, r8*A Valid N.E. Add r8 to r/m8.
01 /rADD r/m16, r16 A Valid Valid Add r16 to r/m16.
01 /rADD r/m32, r32 A Valid Valid Add r32 to r/m32.
REX.W + 01 /rADD r/m64, r64 A Valid N.E. Add r64 to r/m64.
02 /rADD r8, r/m8 A Valid Valid Add r/m8 to r8.
REX + 02 /rADD r8*, r/m8*A Valid N.E. Add r/m8 to r8.
03 /rADD r16, r/m16 A Valid Valid Add r/m16 to r16.
03 /rADD r32, r/m32 A Valid Valid Add r/m32 to r32.
REX.W + 03 /rADD r64, r/m64 A Valid N.E. Add r/m64 to r64.
NOTES:
*In 64-bit mode, r/m8 can not be encoded to access the following byte registers if a REX prefix is
used: AH, BH, CH, DH.

3-36 Vol. 2A ADD—Add
INSTRUCTION SET REFERENCE, A-M
Instruction Operand Encoding
Description
Adds the destination operand (first operand) and the source operand (second
operand) and then stores the result in the destination operand. The destination
operand can be a register or a memory location; the source operand can be an imme-
diate, a register, or a memory location. (However, two memory operands cannot be
used in one instruction.) When an immediate value is used as an operand, it is sign-
extended to the length of the destination operand format.
The ADD instruction performs integer addition. It evaluates the result for both signed
and unsigned integer operands and sets the OF and CF flags to indicate a carry (over-
flow) in the signed or unsigned result, respectively. The SF flag indicates the sign of
the signed result.
This instruction can be used with a LOCK prefix to allow the instruction to be
executed atomically.
In 64-bit mode, the instruction’s default operation size is 32 bits. Using a REX prefix
in the form of REX.R permits access to additional registers (R8-R15). Using a REX a
REX prefix in the form of REX.W promotes operation to 64 bits. See the summary
chart at the beginning of this section for encoding data and limits.
Operation
DEST ← DEST + SRC;
Flags Affected
The OF, SF, ZF, AF, CF, and PF flags are set according to the result.
Protected Mode Exceptions
#GP(0) If the destination is located in a non-writable segment.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register is used to access memory and it
contains a NULL segment selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:r/m (r, w) imm8 NA NA
C AL/AX/EAX/RAX imm8 NA NA

Vol. 2A 3-37
INSTRUCTION SET REFERENCE, A-M
ADD—Add
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used but the destination is not a memory
operand.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#UD If the LOCK prefix is used but the destination is not a memory
operand.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used but the destination is not a memory
operand.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used but the destination is not a memory
operand.

3-38 Vol. 2A ADDPD—Add Packed Double-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
ADDPD—Add Packed Double-Precision Floating-Point Values
Instruction Operand Encoding
Description
Performs a SIMD add of the two packed double-precision floating-point values from
the source operand (second operand) and the destination operand (first operand),
and stores the packed double-precision floating-point results in the destination
operand.
In 64-bit mode, using a REX prefix in the form of REX.R permits this instruction to
access additional registers (XMM8-XMM15).
128-bit Legacy SSE version: The second source can be an XMM register or an 128-bit
memory location. The destination is not distinct from the first source XMM register
and the upper bits (VLMAX-1:128) of the corresponding YMM register destination are
unmodified. See Chapter 11 in the Intel® 64 and IA-32 Architectures Software
Developer’s Manual, Volume 1, for an overview of SIMD double-precision floating-
point operation.
VEX.128 encoded version: the first source operand is an XMM register or 128-bit
memory location. The destination operand is an XMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are zeroed.
VEX.256 encoded version: The first source operand is a YMM register. The second
source operand can be a YMM register or a 256-bit memory location. The destination
operand is a YMM register.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 58 /r
ADDPD xmm1, xmm2/m128
A V/V SSE2 Add packed double-precision
floating-point values from
xmm2/m128 to xmm1.
VEX.NDS.128.66.0F.WIG 58 /r
VADDPD xmm1,xmm2, xmm3/m128
B V/V AVX Add packed double-precision
floating-point values from
xmm3/mem to xmm2 and
stores result in xmm1.
VEX.NDS.256.66.0F.WIG 58 /r
VADDPD ymm1, ymm2,
ymm3/m256
B V/V AVX Add packed double-precision
floating-point values from
ymm3/mem to ymm2 and
stores result in ymm1.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

Vol. 2A 3-39
INSTRUCTION SET REFERENCE, A-M
ADDPD—Add Packed Double-Precision Floating-Point Values
Operation
ADDPD (128-bit Legacy SSE version)
DEST[63:0] ← DEST[63:0] + SRC[63:0];
DEST[127:64] ← DEST[127:64] + SRC[127:64];
DEST[VLMAX-1:128] (Unmodified)
VADDPD (VEX.128 encoded version)
DEST[63:0] SRC1[63:0] + SRC2[63:0]
DEST[127:64] SRC1[127:64] + SRC2[127:64]
DEST[VLMAX-1:128] 0
VADDPD (VEX.256 encoded version)
DEST[63:0] SRC1[63:0] + SRC2[63:0]
DEST[127:64] SRC1[127:64] + SRC2[127:64]
DEST[191:128] SRC1[191:128] + SRC2[191:128]
DEST[255:192] SRC1[255:192] + SRC2[255:192]
.Intel C/C++ Compiler Intrinsic Equivalent
ADDPD __m128d _mm_add_pd (__m128d a, __m128d b)
VADDPD __m256d _mm256_add_pd (__m256d a, __m256d b)
SIMD Floating-Point Exceptions
Overflow, Underflow, Invalid, Precision, Denormal.
Other Exceptions
See Exceptions Type 2.

3-40 Vol. 2A ADDPS—Add Packed Single-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
ADDPS—Add Packed Single-Precision Floating-Point Values
Instruction Operand Encoding
Description
Performs a SIMD add of the four packed single-precision floating-point values from
the source operand (second operand) and the destination operand (first operand),
and stores the packed single-precision floating-point results in the destination
operand.
In 64-bit mode, using a REX prefix in the form of REX.R permits this instruction to
access additional registers (XMM8-XMM15).
128-bit Legacy SSE version: The second source can be an XMM register or an 128-bit
memory location. The destination is not distinct from the first source XMM register
and the upper bits (VLMAX-1:128) of the corresponding YMM register destination are
unmodified. See Chapter 10 in the Intel® 64 and IA-32 Architectures Software
Developer’s Manual, Volume 1, for an overview of SIMD single-precision floating-
point operation.
VEX.128 encoded version: the first source operand is an XMM register or 128-bit
memory location. The destination operand is an XMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are zeroed.
VEX.256 encoded version: The first source operand is a YMM register. The second
source operand can be a YMM register or a 256-bit memory location. The destination
operand is a YMM register.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
0F 58 /r
ADDPS xmm1, xmm2/m128
A V/V SSE Add packed single-precision
floating-point values from
xmm2/m128 to xmm1 and
stores result in xmm1.
VEX.NDS.128.0F.WIG 58 /r
VADDPS xmm1,xmm2, xmm3/m128
B V/V AVX Add packed single-precision
floating-point values from
xmm3/mem to xmm2 and
stores result in xmm1.
VEX.NDS.256.0F.WIG 58 /r
VADDPS ymm1, ymm2, ymm3/m256
B V/V AVX Add packed single-precision
floating-point values from
ymm3/mem to ymm2 and
stores result in ymm1.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r)) NA

Vol. 2A 3-41
INSTRUCTION SET REFERENCE, A-M
ADDPS—Add Packed Single-Precision Floating-Point Values
Operation
ADDPS (128-bit Legacy SSE version)
DEST[31:0] ← DEST[31:0] + SRC[31:0];
DEST[63:32] ← DEST[63:32] + SRC[63:32];
DEST[95:64] ← DEST[95:64] + SRC[95:64];
DEST[127:96] ← DEST[127:96] + SRC[127:96];
DEST[VLMAX-1:128] (Unmodified)
VADDPS (VEX.128 encoded version)
DEST[31:0] SRC1[31:0] + SRC2[31:0]
DEST[63:32] SRC1[63:32] + SRC2[63:32]
DEST[95:64] SRC1[95:64] + SRC2[95:64]
DEST[127:96] SRC1[127:96] + SRC2[127:96]
DEST[VLMAX-1:128] 0
VADDPS (VEX.256 encoded version)
DEST[31:0] SRC1[31:0] + SRC2[31:0]
DEST[63:32] SRC1[63:32] + SRC2[63:32]
DEST[95:64] SRC1[95:64] + SRC2[95:64]
DEST[127:96] SRC1[127:96] + SRC2[127:96]
DEST[159:128] SRC1[159:128] + SRC2[159:128]
DEST[191:160] SRC1[191:160] + SRC2[191:160]
DEST[223:192] SRC1[223:192] + SRC2[223:192]
DEST[255:224] SRC1[255:224] + SRC2[255:224]
Intel C/C++ Compiler Intrinsic Equivalent
ADDPS __m128 _mm_add_ps(__m128 a, __m128 b)
VADDPS __m256 _mm256_add_ps (__m256 a, __m256 b)
SIMD Floating-Point Exceptions
Overflow, Underflow, Invalid, Precision, Denormal.
Other Exceptions
See Exceptions Type 2.

3-42 Vol. 2A ADDSD—Add Scalar Double-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
ADDSD—Add Scalar Double-Precision Floating-Point Values
Instruction Operand Encoding
Description
Adds the low double-precision floating-point values from the source operand (second
operand) and the destination operand (first operand), and stores the double-preci-
sion floating-point result in the destination operand.
The source operand can be an XMM register or a 64-bit memory location. The desti-
nation operand is an XMM register. See Chapter 11 in the Intel® 64 and IA-32 Archi-
tectures Software Developer’s Manual, Volume 1, for an overview of a scalar double-
precision floating-point operation.
In 64-bit mode, using a REX prefix in the form of REX.R permits this instruction to
access additional registers (XMM8-XMM15).
128-bit Legacy SSE version: Bits (VLMAX-1:64) of the corresponding YMM destina-
tion register remain unchanged.
VEX.128 encoded version: Bits (127:64) of the XMM register destination are copied
from corresponding bits in the first source operand. Bits (VLMAX-1:128) of the desti-
nation YMM register are zeroed.
Operation
ADDSD (128-bit Legacy SSE version)
DEST[63:0] DEST[63:0] + SRC[63:0]
DEST[VLMAX-1:64] (Unmodified)
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F2 0F 58 /r
ADDSD xmm1, xmm2/m64
A V/V SSE2 Add the low double-
precision floating-point
value from xmm2/m64 to
xmm1.
VEX.NDS.LIG.F2.0F.WIG 58 /r
VADDSD xmm1, xmm2, xmm3/m64
B V/V AVX Add the low double-
precision floating-point
value from xmm3/mem to
xmm2 and store the result
in xmm1.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r)) NA

Vol. 2A 3-43
INSTRUCTION SET REFERENCE, A-M
ADDSD—Add Scalar Double-Precision Floating-Point Values
VADDSD (VEX.128 encoded version)
DEST[63:0] SRC1[63:0] + SRC2[63:0]
DEST[127:64] SRC1[127:64]
DEST[VLMAX-1:128] 0
Intel C/C++ Compiler Intrinsic Equivalent
ADDSD __m128d _mm_add_sd (m128d a, m128d b)
SIMD Floating-Point Exceptions
Overflow, Underflow, Invalid, Precision, Denormal.
Other Exceptions
See Exceptions Type 3.

3-44 Vol. 2A ADDSS—Add Scalar Single-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
ADDSS—Add Scalar Single-Precision Floating-Point Values
Instruction Operand Encoding
Description
Adds the low single-precision floating-point values from the source operand (second
operand) and the destination operand (first operand), and stores the single-precision
floating-point result in the destination operand.
The source operand can be an XMM register or a 32-bit memory location. The desti-
nation operand is an XMM register. See Chapter 10 in the Intel® 64 and IA-32 Archi-
tectures Software Developer’s Manual, Volume 1, for an overview of a scalar single-
precision floating-point operation.
In 64-bit mode, using a REX prefix in the form of REX.R permits this instruction to
access additional registers (XMM8-XMM15).
128-bit Legacy SSE version: Bits (VLMAX-1:32) of the corresponding YMM destina-
tion register remain unchanged.
VEX.128 encoded version: Bits (127:32) of the XMM register destination are copied
from corresponding bits in the first source operand. Bits (VLMAX-1:128) of the desti-
nation YMM register are zeroed.
Operation
ADDSS DEST, SRC (128-bit Legacy SSE version)
DEST[31:0] DEST[31:0] + SRC[31:0];
DEST[VLMAX-1:32] (Unmodified)
VADDSS DEST, SRC1, SRC2 (VEX.128 encoded version)
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F3 0F 58 /r
ADDSS xmm1, xmm2/m32
AV/V SSE Add the low single-precision
floating-point value from
xmm2/m32 to xmm1.
VEX.NDS.LIG.F3.0F.WIG 58 /r
VADDSS xmm1,xmm2, xmm3/m32
BV/V AVX Add the low single-precision
floating-point value from
xmm3/mem to xmm2 and
store the result in xmm1.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

Vol. 2A 3-45
INSTRUCTION SET REFERENCE, A-M
ADDSS—Add Scalar Single-Precision Floating-Point Values
DEST[31:0] SRC1[31:0] + SRC2[31:0]
DEST[127:32] SRC1[127:32]
DEST[VLMAX-1:128] 0
Intel C/C++ Compiler Intrinsic Equivalent
ADDSS __m128 _mm_add_ss(__m128 a, __m128 b)
SIMD Floating-Point Exceptions
Overflow, Underflow, Invalid, Precision, Denormal.
Other Exceptions
See Exceptions Type 3.

3-46 Vol. 2A ADDSUBPD—Packed Double-FP Add/Subtract
INSTRUCTION SET REFERENCE, A-M
ADDSUBPD—Packed Double-FP Add/Subtract
Instruction Operand Encoding
Description
Adds odd-numbered double-precision floating-point values of the first source
operand (second operand) with the corresponding double-precision floating-point
values from the second source operand (third operand); stores the result in the odd-
numbered values of the destination operand (first operand). Subtracts the even-
numbered double-precision floating-point values from the second source operand
from the corresponding double-precision floating values in the first source operand;
stores the result into the even-numbered values of the destination operand.
In 64-bit mode, using a REX prefix in the form of REX.R permits this instruction to
access additional registers (XMM8-XMM15).
128-bit Legacy SSE version: The second source can be an XMM register or an 128-bit
memory location. The destination is not distinct from the first source XMM register
and the upper bits (VLMAX-1:128) of the corresponding YMM register destination are
unmodified. See Figure 3-3.
VEX.128 encoded version: the first source operand is an XMM register or 128-bit
memory location. The destination operand is an XMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are zeroed.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F D0 /r
ADDSUBPD xmm1, xmm2/m128
A V/V SSE3 Add/subtract double-
precision floating-point
values from xmm2/m128 to
xmm1.
VEX.NDS.128.66.0F.WIG D0 /r
VADDSUBPD xmm1, xmm2,
xmm3/m128
B V/V AVX Add/subtract packed
double-precision floating-
point values from
xmm3/mem to xmm2 and
stores result in xmm1.
VEX.NDS.256.66.0F.WIG D0 /r
VADDSUBPD ymm1, ymm2,
ymm3/m256
B V/V AVX Add / subtract packed
double-precision floating-
point values from
ymm3/mem to ymm2 and
stores result in ymm1.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA
Vol. 2A 3-47
INSTRUCTION SET REFERENCE, A-M
ADDSUBPD—Packed Double-FP Add/Subtract
VEX.256 encoded version: The first source operand is a YMM register. The second
source operand can be a YMM register or a 256-bit memory location. The destination
operand is a YMM register.
Operation
ADDSUBPD (128-bit Legacy SSE version)
DEST[63:0] DEST[63:0] - SRC[63:0]
DEST[127:64] DEST[127:64] + SRC[127:64]
DEST[VLMAX-1:128] (Unmodified)
VADDSUBPD (VEX.128 encoded version)
DEST[63:0] SRC1[63:0] - SRC2[63:0]
DEST[127:64] SRC1[127:64] + SRC2[127:64]
DEST[VLMAX-1:128] 0
VADDSUBPD (VEX.256 encoded version)
DEST[63:0] SRC1[63:0] - SRC2[63:0]
DEST[127:64] SRC1[127:64] + SRC2[127:64]
DEST[191:128] SRC1[191:128] - SRC2[191:128]
DEST[255:192] SRC1[255:192] + SRC2[255:192]
Figure 3-3. ADDSUBPD—Packed Double-FP Add/Subtract
>@
[PP>@[PPP>@ [PP>@[PPP>@
>@
>@ >@
$''68%3'[PP[PPP
5(68/7
[PP
[PPP

3-48 Vol. 2A ADDSUBPD—Packed Double-FP Add/Subtract
INSTRUCTION SET REFERENCE, A-M
Intel C/C++ Compiler Intrinsic Equivalent
ADDSUBPD__m128d _mm_addsub_pd(__m128d a, __m128d b)
VADDSUBPD __m256d _mm256_addsub_pd (__m256d a, __m256d b)
Exceptions
When the source operand is a memory operand, it must be aligned on a 16-byte
boundary or a general-protection exception (#GP) will be generated.
SIMD Floating-Point Exceptions
Overflow, Underflow, Invalid, Precision, Denormal.
Other Exceptions
See Exceptions Type 2.
Vol. 2A 3-49
INSTRUCTION SET REFERENCE, A-M
ADDSUBPS—Packed Single-FP Add/Subtract
ADDSUBPS—Packed Single-FP Add/Subtract
Instruction Operand Encoding
Description
Adds odd-numbered single-precision floating-point values of the first source operand
(second operand) with the corresponding single-precision floating-point values from
the second source operand (third operand); stores the result in the odd-numbered
values of the destination operand (first operand). Subtracts the even-numbered
single-precision floating-point values from the second source operand from the
corresponding single-precision floating values in the first source operand; stores the
result into the even-numbered values of the destination operand.
In 64-bit mode, using a REX prefix in the form of REX.R permits this instruction to
access additional registers (XMM8-XMM15).
128-bit Legacy SSE version: The second source can be an XMM register or an 128-bit
memory location. The destination is not distinct from the first source XMM register
and the upper bits (VLMAX-1:128) of the corresponding YMM register destination are
unmodified. See Figure 3-4.
VEX.128 encoded version: the first source operand is an XMM register or 128-bit
memory location. The destination operand is an XMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are zeroed.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F2 0F D0 /r
ADDSUBPS xmm1, xmm2/m128
A V/V SSE3 Add/subtract single-
precision floating-point
values from xmm2/m128 to
xmm1.
VEX.NDS.128.F2.0F.WIG D0 /r
VADDSUBPS xmm1, xmm2,
xmm3/m128
B V/V AVX Add/subtract single-
precision floating-point
values from xmm3/mem to
xmm2 and stores result in
xmm1.
VEX.NDS.256.F2.0F.WIG D0 /r
VADDSUBPS ymm1, ymm2,
ymm3/m256
B V/V AVX Add / subtract single-
precision floating-point
values from ymm3/mem to
ymm2 and stores result in
ymm1.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA
3-50 Vol. 2A ADDSUBPS—Packed Single-FP Add/Subtract
INSTRUCTION SET REFERENCE, A-M
VEX.256 encoded version: The first source operand is a YMM register. The second
source operand can be a YMM register or a 256-bit memory location. The destination
operand is a YMM register.
Operation
ADDSUBPS (128-bit Legacy SSE version)
DEST[31:0] DEST[31:0] - SRC[31:0]
DEST[63:32] DEST[63:32] + SRC[63:32]
DEST[95:64] DEST[95:64] - SRC[95:64]
DEST[127:96] DEST[127:96] + SRC[127:96]
DEST[VLMAX-1:128] (Unmodified)
VADDSUBPS (VEX.128 encoded version)
DEST[31:0] SRC1[31:0] - SRC2[31:0]
DEST[63:32] SRC1[63:32] + SRC2[63:32]
DEST[95:64] SRC1[95:64] - SRC2[95:64]
DEST[127:96] SRC1[127:96] + SRC2[127:96]
DEST[VLMAX-1:128] 0
VADDSUBPS (VEX.256 encoded version)
DEST[31:0] SRC1[31:0] - SRC2[31:0]
DEST[63:32] SRC1[63:32] + SRC2[63:32]
DEST[95:64] SRC1[95:64] - SRC2[95:64]
Figure 3-4. ADDSUBPS—Packed Single-FP Add/Subtract
20
$''68%36[PP[PPP
5(68/7
[PP
[PP
P
[PP>@
[PPP>@
>@
[PP>@
[PPP>@
>@
[PP>@[PP
P>@
>@
[PP>@
[PPP>@
>@
>@ >@ >@ >@

Vol. 2A 3-51
INSTRUCTION SET REFERENCE, A-M
ADDSUBPS—Packed Single-FP Add/Subtract
DEST[127:96] SRC1[127:96] + SRC2[127:96]
DEST[159:128] SRC1[159:128] - SRC2[159:128]
DEST[191:160] SRC1[191:160] + SRC2[191:160]
DEST[223:192] SRC1[223:192] - SRC2[223:192]
DEST[255:224] SRC1[255:224] + SRC2[255:224].
Intel C/C++ Compiler Intrinsic Equivalent
ADDSUBPS __m128 _mm_addsub_ps(__m128 a, __m128 b)
VADDSUBPS __m256 _mm256_addsub_ps (__m256 a, __m256 b)
Exceptions
When the source operand is a memory operand, the operand must be aligned on a
16-byte boundary or a general-protection exception (#GP) will be generated.
SIMD Floating-Point Exceptions
Overflow, Underflow, Invalid, Precision, Denormal.
Other Exceptions
See Exceptions Type 2.

3-52 Vol. 2A AESDEC—Perform One Round of an AES Decryption Flow
INSTRUCTION SET REFERENCE, A-M
AESDEC—Perform One Round of an AES Decryption Flow
Instruction Operand Encoding
Description
This instruction performs a single round of the AES decryption flow using the Equiva-
lent Inverse Cipher, with the round key from the second source operand, operating
on a 128-bit data (state) from the first source operand, and store the result in the
destination operand.
Use the AESDEC instruction for all but the last decryption round. For the last decryp-
tion round, use the AESDECCLAST instruction.
128-bit Legacy SSE version: The first source operand and the destination operand
are the same and must be an XMM register. The second source operand can be an
XMM register or a 128-bit memory location. Bits (VLMAX-1:128) of the corre-
sponding YMM destination register remain unchanged.
VEX.128 encoded version: The first source operand and the destination operand are
XMM registers. The second source operand can be an XMM register or a 128-bit
memory location. Bits (VLMAX-1:128) of the destination YMM register are zeroed.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 38 DE /r
AESDEC xmm1, xmm2/m128
AV/V AES Perform one round of an
AES decryption flow, using
the Equivalent Inverse
Cipher, operating on a 128-
bit data (state) from xmm1
with a 128-bit round key
from xmm2/m128.
VEX.NDS.128.66.0F38.WIG DE /r
VAESDEC xmm1, xmm2,
xmm3/m128
BV/V Both AES
and
AVX flags
Perform one round of an
AES decryption flow, using
the Equivalent Inverse
Cipher, operating on a 128-
bit data (state) from xmm2
with a 128-bit round key
from xmm3/m128; store
the result in xmm1.
Op/En Operand 1 Operand2 Operand3 Operand4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

Vol. 2A 3-53
INSTRUCTION SET REFERENCE, A-M
AESDEC—Perform One Round of an AES Decryption Flow
Operation
AESDEC
STATE ← SRC1;
RoundKey ← SRC2;
STATE ← InvShiftRows( STATE );
STATE ← InvSubBytes( STATE );
STATE ← InvMixColumns( STATE );
DEST[127:0] ← STATE XOR RoundKey;
DEST[VLMAX-1:128] (Unmodified)
VAESDEC
STATE ← SRC1;
RoundKey ← SRC2;
STATE ← InvShiftRows( STATE );
STATE ← InvSubBytes( STATE );
STATE ← InvMixColumns( STATE );
DEST[127:0] ← STATE XOR RoundKey;
DEST[VLMAX-1:128] ← 0
Intel C/C++ Compiler Intrinsic Equivalent
(V)AESDEC __m128i _mm_aesdec (__m128i, __m128i)
SIMD Floating-Point Exceptions
None
Other Exceptions
See Exceptions Type 4.

3-54 Vol. 2A AESDECLAST—Perform Last Round of an AES Decryption Flow
INSTRUCTION SET REFERENCE, A-M
AESDECLAST—Perform Last Round of an AES Decryption Flow
Instruction Operand Encoding
Description
This instruction performs the last round of the AES decryption flow using the Equiva-
lent Inverse Cipher, with the round key from the second source operand, operating
on a 128-bit data (state) from the first source operand, and store the result in the
destination operand.
128-bit Legacy SSE version: The first source operand and the destination operand
are the same and must be an XMM register. The second source operand can be an
XMM register or a 128-bit memory location. Bits (VLMAX-1:128) of the corre-
sponding YMM destination register remain unchanged.
VEX.128 encoded version: The first source operand and the destination operand are
XMM registers. The second source operand can be an XMM register or a 128-bit
memory location. Bits (VLMAX-1:128) of the destination YMM register are zeroed.
Operation
AESDECLAST
Opcode Instruction Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 38 DF /r
AESDECLAST xmm1, xmm2/m128
A V/V AES Perform the last round of an
AES decryption flow, using
the Equivalent Inverse
Cipher, operating on a 128-
bit data (state) from xmm1
with a 128-bit round key
from xmm2/m128.
VEX.NDS.128.66.0F38.WIG DF /r
VAESDECLAST xmm1, xmm2,
xmm3/m128
BV/V Both AES
and
AVX flags
Perform the last round of an
AES decryption flow, using
the Equivalent Inverse
Cipher, operating on a 128-
bit data (state) from xmm2
with a 128-bit round key
from xmm3/m128; store
the result in xmm1.
Op/En Operand 1 Operand2 Operand3 Operand4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

Vol. 2A 3-55
INSTRUCTION SET REFERENCE, A-M
AESDECLAST—Perform Last Round of an AES Decryption Flow
STATE ← SRC1;
RoundKey ← SRC2;
STATE ← InvShiftRows( STATE );
STATE ← InvSubBytes( STATE );
DEST[127:0] ← STATE XOR RoundKey;
DEST[VLMAX-1:128] (Unmodified)
VAESDECLAST
STATE ← SRC1;
RoundKey ← SRC2;
STATE ← InvShiftRows( STATE );
STATE ← InvSubBytes( STATE );
DEST[127:0] ← STATE XOR RoundKey;
DEST[VLMAX-1:128] ← 0
Intel C/C++ Compiler Intrinsic Equivalent
(V)AESDECLAST __m128i _mm_aesdeclast (__m128i, __m128i)
SIMD Floating-Point Exceptions
None
Other Exceptions
See Exceptions Type 4.

3-56 Vol. 2A AESENC—Perform One Round of an AES Encryption Flow
INSTRUCTION SET REFERENCE, A-M
AESENC—Perform One Round of an AES Encryption Flow
Instruction Operand Encoding
Description
This instruction performs a single round of an AES encryption flow using a round key
from the second source operand, operating on 128-bit data (state) from the first
source operand, and store the result in the destination operand.
Use the AESENC instruction for all but the last encryption rounds. For the last encryp-
tion round, use the AESENCCLAST instruction.
128-bit Legacy SSE version: The first source operand and the destination operand
are the same and must be an XMM register. The second source operand can be an
XMM register or a 128-bit memory location. Bits (VLMAX-1:128) of the corre-
sponding YMM destination register remain unchanged.
VEX.128 encoded version: The first source operand and the destination operand are
XMM registers. The second source operand can be an XMM register or a 128-bit
memory location. Bits (VLMAX-1:128) of the destination YMM register are zeroed.
Operation
AESENC
Opcode Instruction Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 38 DC /r
AESENC xmm1, xmm2/m128
AV/V AES Perform one round of an
AES encryption flow, oper-
ating on a 128-bit data
(state) from xmm1 with a
128-bit round key from
xmm2/m128.
VEX.NDS.128.66.0F38.WIG DC /r
VAESENC xmm1, xmm2,
xmm3/m128
BV/V Both AES
and
AVX flags
Perform one round of an
AES encryption flow, operat-
ing on a 128-bit data (state)
from xmm2 with a 128-bit
round key from the
xmm3/m128; store the
result in xmm1.
Op/En Operand 1 Operand2 Operand3 Operand4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

Vol. 2A 3-57
INSTRUCTION SET REFERENCE, A-M
AESENC—Perform One Round of an AES Encryption Flow
STATE ← SRC1;
RoundKey ← SRC2;
STATE ← ShiftRows( STATE );
STATE ← SubBytes( STATE );
STATE ← MixColumns( STATE );
DEST[127:0] ← STATE XOR RoundKey;
DEST[VLMAX-1:128] (Unmodified)
VAESENC
STATE SRC1;
RoundKey SRC2;
STATE ShiftRows( STATE );
STATE SubBytes( STATE );
STATE MixColumns( STATE );
DEST[127:0] STATE XOR RoundKey;
DEST[VLMAX-1:128] 0
Intel C/C++ Compiler Intrinsic Equivalent
(V)AESENC __m128i _mm_aesenc (__m128i, __m128i)
SIMD Floating-Point Exceptions
None
Other Exceptions
See Exceptions Type 4.

3-58 Vol. 2A AESENCLAST—Perform Last Round of an AES Encryption Flow
INSTRUCTION SET REFERENCE, A-M
AESENCLAST—Perform Last Round of an AES Encryption Flow
Instruction Operand Encoding
Description
This instruction performs the last round of an AES encryption flow using a round key
from the second source operand, operating on 128-bit data (state) from the first
source operand, and store the result in the destination operand.
128-bit Legacy SSE version: The first source operand and the destination operand
are the same and must be an XMM register. The second source operand can be an
XMM register or a 128-bit memory location. Bits (VLMAX-1:128) of the corre-
sponding YMM destination register remain unchanged.
VEX.128 encoded version: The first source operand and the destination operand are
XMM registers. The second source operand can be an XMM register or a 128-bit
memory location. Bits (VLMAX-1:128) of the destination YMM register are zeroed.
Operation
AESENCLAST
STATE ← SRC1;
RoundKey ← SRC2;
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 38 DD /r
AESENCLAST xmm1, xmm2/m128
A V/V AES Perform the last round of an
AES encryption flow, oper-
ating on a 128-bit data
(state) from xmm1 with a
128-bit round key from
xmm2/m128.
VEX.NDS.128.66.0F38.WIG DD /r
VAESENCLAST xmm1, xmm2,
xmm3/m128
BV/V Both AES
and
AVX flags
Perform the last round of an
AES encryption flow, operat-
ing on a 128-bit data (state)
from xmm2 with a 128 bit
round key from
xmm3/m128; store the
result in xmm1.
Op/En Operand 1 Operand2 Operand3 Operand4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

Vol. 2A 3-59
INSTRUCTION SET REFERENCE, A-M
AESENCLAST—Perform Last Round of an AES Encryption Flow
STATE ← ShiftRows( STATE );
STATE ← SubBytes( STATE );
DEST[127:0] ← STATE XOR RoundKey;
DEST[VLMAX-1:128] (Unmodified)
VAESENCLAST
STATE SRC1;
RoundKey SRC2;
STATE ShiftRows( STATE );
STATE SubBytes( STATE );
DEST[127:0] STATE XOR RoundKey;
DEST[VLMAX-1:128] 0
Intel C/C++ Compiler Intrinsic Equivalent
(V)AESENCLAST __m128i _mm_aesenclast (__m128i, __m128i)
SIMD Floating-Point Exceptions
None
Other Exceptions
See Exceptions Type 4.

3-60 Vol. 2A AESIMC—Perform the AES InvMixColumn Transformation
INSTRUCTION SET REFERENCE, A-M
AESIMC—Perform the AES InvMixColumn Transformation
Instruction Operand Encoding
Description
Perform the InvMixColumns transformation on the source operand and store the
result in the destination operand. The destination operand is an XMM register. The
source operand can be an XMM register or a 128-bit memory location.
Note: the AESIMC instruction should be applied to the expanded AES round keys
(except for the first and last round key) in order to prepare them for decryption using
the “Equivalent Inverse Cipher” (defined in FIPS 197).
128-bit Legacy SSE version: Bits (VLMAX-1:128) of the corresponding YMM destina-
tion register remain unchanged.
VEX.128 encoded version: Bits (VLMAX-1:128) of the destination YMM register are
zeroed.
Operation
AESIMC
DEST[127:0] ← InvMixColumns( SRC );
DEST[VLMAX-1:128] (Unmodified)
VAESIMC
DEST[127:0] InvMixColumns( SRC );
DEST[VLMAX-1:128] 0;
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 38 DB /r
AESIMC xmm1, xmm2/m128
A V/V AES Perform the InvMixColumn
transformation on a 128-bit
round key from
xmm2/m128 and store the
result in xmm1.
VEX.128.66.0F38.WIG DB /r
VAESIMC xmm1, xmm2/m128
AV/V Both AES
and
AVX flags
Perform the InvMixColumn
transformation on a 128-bit
round key from
xmm2/m128 and store the
result in xmm1.
Op/En Operand 1 Operand2 Operand3 Operand4
A ModRM:reg (w) ModRM:r/m (r) NA NA

Vol. 2A 3-61
INSTRUCTION SET REFERENCE, A-M
AESIMC—Perform the AES InvMixColumn Transformation
Intel C/C++ Compiler Intrinsic Equivalent
(V)AESIMC __m128i _mm_aesimc (__m128i)
SIMD Floating-Point Exceptions
None
Other Exceptions
See Exceptions Type 4.

3-62 Vol. 2A AESKEYGENASSIST—AES Round Key Generation Assist
INSTRUCTION SET REFERENCE, A-M
AESKEYGENASSIST—AES Round Key Generation Assist
Instruction Operand Encoding
Description
Assist in expanding the AES cipher key, by computing steps towards generating a
round key for encryption, using 128-bit data specified in the source operand and an
8-bit round constant specified as an immediate, store the result in the destination
operand.
The destination operand is an XMM register. The source operand can be an XMM
register or a 128-bit memory location.
128-bit Legacy SSE version:Bits (VLMAX-1:128) of the corresponding YMM destina-
tion register remain unchanged.
VEX.128 encoded version: Bits (VLMAX-1:128) of the destination YMM register are
zeroed.
Operation
AESKEYGENASSIST
X3[31:0] ← SRC [127: 96];
X2[31:0] ← SRC [95: 64];
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 3A DF /r ib
AESKEYGENASSIST xmm1,
xmm2/m128, imm8
A V/V AES Assist in AES round key gen-
eration using an 8 bits
Round Constant (RCON)
specified in the immediate
byte, operating on 128 bits
of data specified in
xmm2/m128 and stores the
result in xmm1.
VEX.128.66.0F3A.WIG DF /r ib
VAESKEYGENASSIST xmm1,
xmm2/m128, imm8
AV/V Both AES
and
AVX flags
Assist in AES round key gen-
eration using 8 bits Round
Constant (RCON) specified in
the immediate byte, operat-
ing on 128 bits of data spec-
ified in xmm2/m128 and
stores the result in xmm1.
Op/En Operand 1 Operand2 Operand3 Operand4
A ModRM:reg (w) ModRM:r/m (r) imm8 NA

Vol. 2A 3-63
INSTRUCTION SET REFERENCE, A-M
AESKEYGENASSIST—AES Round Key Generation Assist
X1[31:0] ← SRC [63: 32];
X0[31:0] ← SRC [31: 0];
RCON[31:0] ← ZeroExtend(Imm8[7:0]);
DEST[31:0] ← SubWord(X1);
DEST[63:32 ] ← RotWord( SubWord(X1) ) XOR RCON;
DEST[95:64] ← SubWord(X3);
DEST[127:96] ← RotWord( SubWord(X3) ) XOR RCON;
DEST[VLMAX-1:128] (Unmodified)
VAESKEYGENASSIST
X3[31:0] SRC [127: 96];
X2[31:0] SRC [95: 64];
X1[31:0] SRC [63: 32];
X0[31:0] SRC [31: 0];
RCON[31:0] ZeroExtend(Imm8[7:0]);
DEST[31:0] SubWord(X1);
DEST[63:32 ] RotWord( SubWord(X1) ) XOR RCON;
DEST[95:64] SubWord(X3);
DEST[127:96] RotWord( SubWord(X3) ) XOR RCON;
DEST[VLMAX-1:128] 0;
Intel C/C++ Compiler Intrinsic Equivalent
(V)AESKEYGENASSIST __m128i _mm_aesimc (__m128i, const int)
SIMD Floating-Point Exceptions
None
Other Exceptions
See Exceptions Type 4.

3-64 Vol. 2A AND—Logical AND
INSTRUCTION SET REFERENCE, A-M
AND—Logical AND
Opcode Instruction Op/
En
64-bit
Mode
Compat/
Leg Mode
Description
24 ib AND AL, imm8 CValid Valid AL AND imm8.
25 iw AND AX, imm16 CValid Valid AX AND imm16.
25 id AND EAX, imm32 CValid Valid EAX AND imm32.
REX.W + 25 id AND RAX, imm32 C Valid N.E. RAX AND imm32 sign-
extended to 64-bits.
80 /4 ib AND r/m8, imm8 BValid Valid r/m8 AND imm8.
REX + 80 /4 ib AND r/m8*, imm8 BValid N.E. r/m8 AND imm8.
81 /4 iw AND r/m16,
imm16
BValid Valid r/m16 AND imm16.
81 /4 id AND r/m32,
imm32
BValid Valid r/m32 AND imm32.
REX.W + 81 /4
id
AND r/m64,
imm32
BValid N.E. r/m64 AND imm32 sign
extended to 64-bits.
83 /4 ib AND r/m16, imm8 BValid Valid r/m16 AND imm8 (sign-
extended).
83 /4 ib AND r/m32, imm8 BValid Valid r/m32 AND imm8 (sign-
extended).
REX.W + 83 /4
ib
AND r/m64, imm8 BValid N.E. r/m64 AND imm8 (sign-
extended).
20 /r AND r/m8, r8 AValid Valid r/m8 AND r8.
REX + 20 /r AND r/m8*, r8*AValid N.E. r/m64 AND r8 (sign-
extended).
21 /rAND r/m16, r16 AValid Valid r/m16 AND r16.
21 /rAND r/m32, r32 AValid Valid r/m32 AND r32.
REX.W + 21 /rAND r/m64, r64 AValid N.E. r/m64 AND r32.
22 /rAND r8, r/m8 AValid Valid r8 AND r/m8.
REX + 22 /rAND r8*, r/m8*AValid N.E. r/m64 AND r8 (sign-
extended).
23 /rAND r16, r/m16 AValid Valid r16 AND r/m16.
23 /rAND r32, r/m32 AValid Valid r32 AND r/m32.
REX.W + 23 /rAND r64, r/m64 AValid N.E. r64 AND r/m64.
NOTES:
*In 64-bit mode, r/m8 can not be encoded to access the following byte registers if a REX prefix is
used: AH, BH, CH, DH.

Vol. 2A 3-65
INSTRUCTION SET REFERENCE, A-M
AND—Logical AND
Instruction Operand Encoding
Description
Performs a bitwise AND operation on the destination (first) and source (second)
operands and stores the result in the destination operand location. The source
operand can be an immediate, a register, or a memory location; the destination
operand can be a register or a memory location. (However, two memory operands
cannot be used in one instruction.) Each bit of the result is set to 1 if both corre-
sponding bits of the first and second operands are 1; otherwise, it is set to 0.
This instruction can be used with a LOCK prefix to allow the it to be executed atomi-
cally.
In 64-bit mode, the instruction’s default operation size is 32 bits. Using a REX prefix
in the form of REX.R permits access to additional registers (R8-R15). Using a REX
prefix in the form of REX.W promotes operation to 64 bits. See the summary chart at
the beginning of this section for encoding data and limits.
Operation
DEST ← DEST AND SRC;
Flags Affected
The OF and CF flags are cleared; the SF, ZF, and PF flags are set according to the
result. The state of the AF flag is undefined.
Protected Mode Exceptions
#GP(0) If the destination operand points to a non-writable segment.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:r/m (r, w) imm8 NA NA
C AL/AX/EAX/RAX imm8 NA NA

3-66 Vol. 2A AND—Logical AND
INSTRUCTION SET REFERENCE, A-M
#UD If the LOCK prefix is used but the destination is not a memory
operand.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#UD If the LOCK prefix is used but the destination is not a memory
operand.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used but the destination is not a memory
operand.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used but the destination is not a memory
operand.

Vol. 2A 3-67
INSTRUCTION SET REFERENCE, A-M
ANDPD—Bitwise Logical AND of Packed Double-Precision Floating-Point Values
ANDPD—Bitwise Logical AND of Packed Double-Precision Floating-
Point Values
Instruction Operand Encoding
Description
Performs a bitwise logical AND of the two packed double-precision floating-point
values from the source operand (second operand) and the destination operand (first
operand), and stores the result in the destination operand.
In 64-bit mode, using a REX prefix in the form of REX.R permits this instruction to
access additional registers (XMM8-XMM15).
128-bit Legacy SSE version: The second source can be an XMM register or an 128-bit
memory location. The destination is not distinct from the first source XMM register
and the upper bits (VLMAX-1:128) of the corresponding YMM register destination are
unmodified.
VEX.128 encoded version: the first source operand is an XMM register or 128-bit
memory location. The destination operand is an XMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are zeroed.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 54 /r
ANDPD xmm1, xmm2/m128
A V/V SSE2 Return the bitwise logical
AND of packed double-
precision floating-point
values in xmm1 and
xmm2/m128.
VEX.NDS.128.66.0F.WIG 54 /r
VANDPD xmm1, xmm2,
xmm3/m128
B V/V AVX Return the bitwise logical
AND of packed double-
precision floating-point
values in xmm2 and
xmm3/mem.
VEX.NDS.256.66.0F.WIG 54 /r
VANDPD ymm1, ymm2,
ymm3/m256
B V/V AVX Return the bitwise logical
AND of packed double-
precision floating-point
values in ymm2 and
ymm3/mem.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

3-68 Vol. 2A ANDPD—Bitwise Logical AND of Packed Double-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
VEX.256 encoded version: The first source operand is a YMM register. The second
source operand can be a YMM register or a 256-bit memory location. The destination
operand is a YMM register.
Operation
ANDPD (128-bit Legacy SSE version)
DEST[63:0] DEST[63:0] BITWISE AND SRC[63:0]
DEST[127:64] DEST[127:64] BITWISE AND SRC[127:64]
DEST[VLMAX-1:128] (Unmodified)
VANDPD (VEX.128 encoded version)
DEST[63:0] SRC1[63:0] BITWISE AND SRC2[63:0]
DEST[127:64] SRC1[127:64] BITWISE AND SRC2[127:64]
DEST[VLMAX-1:128] 0
VANDPD (VEX.256 encoded version)
DEST[63:0] SRC1[63:0] BITWISE AND SRC2[63:0]
DEST[127:64] SRC1[127:64] BITWISE AND SRC2[127:64]
DEST[191:128] SRC1[191:128] BITWISE AND SRC2[191:128]
DEST[255:192] SRC1[255:192] BITWISE AND SRC2[255:192]
Intel C/C++ Compiler Intrinsic Equivalent
ANDPD __m128d _mm_and_pd(__m128d a, __m128d b)
VANDPD __m256d _mm256_and_pd (__m256d a, __m256d b)
SIMD Floating-Point Exceptions
None.
Other Exceptions
See Exceptions Type 4.

Vol. 2A 3-69
INSTRUCTION SET REFERENCE, A-M
ANDPS—Bitwise Logical AND of Packed Single-Precision Floating-Point Values
ANDPS—Bitwise Logical AND of Packed Single-Precision Floating-Point
Values
Instruction Operand Encoding
Description
Performs a bitwise logical AND of the four or eight packed single-precision floating-
point values from the first source operand and the second source operand, and
stores the result in the destination operand.
In 64-bit mode, using a REX prefix in the form of REX.R permits this instruction to
access additional registers (XMM8-XMM15).
128-bit Legacy SSE version: The second source can be an XMM register or an 128-bit
memory location. The destination is not distinct from the first source XMM register
and the upper bits (VLMAX-1:128) of the corresponding YMM register destination are
unmodified.
VEX.128 encoded version: the first source operand is an XMM register or 128-bit
memory location. The destination operand is an XMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are zeroed.
VEX.256 encoded version: The first source operand is a YMM register. The second
source operand can be a YMM register or a 256-bit memory location. The destination
operand is a YMM register.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
0F 54 /r
ANDPS xmm1, xmm2/m128
A V/V SSE Bitwise logical AND of
xmm2/m128 and xmm1.
VEX.NDS.128.0F.WIG 54 /r
VANDPS xmm1,xmm2, xmm3/m128
B V/V AVX Return the bitwise logical
AND of packed single-
precision floating-point
values in xmm2 and
xmm3/mem.
VEX.NDS.256.0F.WIG 54 /r
VANDPS ymm1, ymm2,
ymm3/m256
B V/V AVX Return the bitwise logical
AND of packed single-
precision floating-point
values in ymm2 and
ymm3/mem.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

3-70 Vol. 2A ANDPS—Bitwise Logical AND of Packed Single-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
Operation
ANDPS (128-bit Legacy SSE version)
DEST[31:0] DEST[31:0] BITWISE AND SRC[31:0]
DEST[63:32] DEST[63:32] BITWISE AND SRC[63:32]
DEST[95:64] DEST[95:64] BITWISE AND SRC[95:64]
DEST[127:96] DEST[127:96] BITWISE AND SRC[127:96]
DEST[VLMAX-1:128] (Unmodified)
VANDPS (VEX.128 encoded version)
DEST[31:0] SRC1[31:0] BITWISE AND SRC2[31:0]
DEST[63:32] SRC1[63:32] BITWISE AND SRC2[63:32]
DEST[95:64] SRC1[95:64] BITWISE AND SRC2[95:64]
DEST[127:96] SRC1[127:96] BITWISE AND SRC2[127:96]
DEST[VLMAX-1:128] 0
VANDPS (VEX.256 encoded version)
DEST[31:0] SRC1[31:0] BITWISE AND SRC2[31:0]
DEST[63:32] SRC1[63:32] BITWISE AND SRC2[63:32]
DEST[95:64] SRC1[95:64] BITWISE AND SRC2[95:64]
DEST[127:96] SRC1[127:96] BITWISE AND SRC2[127:96]
DEST[159:128] SRC1[159:128] BITWISE AND SRC2[159:128]
DEST[191:160] SRC1[191:160] BITWISE AND SRC2[191:160]
DEST[223:192] SRC1[223:192] BITWISE AND SRC2[223:192]
DEST[255:224] SRC1[255:224] BITWISE AND SRC2[255:224].
Intel C/C++ Compiler Intrinsic Equivalent
ANDPS __m128 _mm_and_ps(__m128 a, __m128 b)
VANDPS __m256 _mm256_and_ps (__m256 a, __m256 b)
SIMD Floating-Point Exceptions
None.
Other Exceptions
See Exceptions Type 4.

Vol. 2A 3-71
INSTRUCTION SET REFERENCE, A-M
ANDNPD—Bitwise Logical AND NOT of Packed Double-Precision Floating-Point Values
ANDNPD—Bitwise Logical AND NOT of Packed Double-Precision
Floating-Point Values
Instruction Operand Encoding
Description
Performs a bitwise logical AND NOT of the two or four packed double-precision
floating-point values from the first source operand and the second source operand,
and stores the result in the destination operand.
In 64-bit mode, using a REX prefix in the form of REX.R permits this instruction to
access additional registers (XMM8-XMM15).
128-bit Legacy SSE version: The second source can be an XMM register or an 128-bit
memory location. The destination is not distinct from the first source XMM register
and the upper bits (VLMAX-1:128) of the corresponding YMM register destination are
unmodified.
VEX.128 encoded version: the first source operand is an XMM register or 128-bit
memory location. The destination operand is an XMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are zeroed.
VEX.256 encoded version: The first source operand is a YMM register. The second
source operand can be a YMM register or a 256-bit memory location. The destination
operand is a YMM register.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 55 /r
ANDNPD xmm1, xmm2/m128
AV/V SSE2 Bitwise logical AND NOT of
xmm2/m128 and xmm1.
VEX.NDS.128.66.0F.WIG 55 /r
VANDNPD xmm1, xmm2,
xmm3/m128
B V/V AVX Return the bitwise logical
AND NOT of packed double-
precision floating-point
values in xmm2 and
xmm3/mem.
VEX.NDS.256.66.0F.WIG 55/r
VANDNPD ymm1, ymm2,
ymm3/m256
B V/V AVX Return the bitwise logical
AND NOT of packed double-
precision floating-point
values in ymm2 and
ymm3/mem.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

3-72 Vol. 2A ANDNPD—Bitwise Logical AND NOT of Packed Double-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
Operation
ANDNPD (128-bit Legacy SSE version)
DEST[63:0] (NOT(DEST[63:0])) BITWISE AND SRC[63:0]
DEST[127:64] (NOT(DEST[127:64])) BITWISE AND SRC[127:64]
DEST[VLMAX-1:128] (Unmodified)
VANDNPD (VEX.128 encoded version)
DEST[63:0] (NOT(SRC1[63:0])) BITWISE AND SRC2[63:0]
DEST[127:64] (NOT(SRC1[127:64])) BITWISE AND SRC2[127:64]
DEST[VLMAX-1:128] 0
VANDNPD (VEX.256 encoded version)
DEST[63:0] (NOT(SRC1[63:0])) BITWISE AND SRC2[63:0]
DEST[127:64] (NOT(SRC1[127:64])) BITWISE AND SRC2[127:64]
DEST[191:128] (NOT(SRC1[191:128])) BITWISE AND SRC2[191:128]
DEST[255:192] (NOT(SRC1[255:192])) BITWISE AND SRC2[255:192]
Intel C/C++ Compiler Intrinsic Equivalent
ANDNPD __m128d _mm_andnot_pd(__m128d a, __m128d b)
VANDNPD __m256d _mm256_andnot_pd (__m256d a, __m256d b)
SIMD Floating-Point Exceptions
None.
Other Exceptions
See Exceptions Type 4.

Vol. 2A 3-73
INSTRUCTION SET REFERENCE, A-M
ANDNPS—Bitwise Logical AND NOT of Packed Single-Precision Floating-Point Values
ANDNPS—Bitwise Logical AND NOT of Packed Single-Precision
Floating-Point Values
Instruction Operand Encoding
Description
Inverts the bits of the four packed single-precision floating-point values in the desti-
nation operand (first operand), performs a bitwise logical AND of the four packed
single-precision floating-point values in the source operand (second operand) and
the temporary inverted result, and stores the result in the destination operand.
In 64-bit mode, using a REX prefix in the form of REX.R permits this instruction to
access additional registers (XMM8-XMM15).
128-bit Legacy SSE version: The second source can be an XMM register or an 128-bit
memory location. The destination is not distinct from the first source XMM register
and the upper bits (VLMAX-1:128) of the corresponding YMM register destination are
unmodified.
VEX.128 encoded version: the first source operand is an XMM register or 128-bit
memory location. The destination operand is an XMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are zeroed.
VEX.256 encoded version: The first source operand is a YMM register. The second
source operand can be a YMM register or a 256-bit memory location. The destination
operand is a YMM register.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
0F 55 /r
ANDNPS xmm1, xmm2/m128
A V/V SSE Bitwise logical AND NOT of
xmm2/m128 and xmm1.
VEX.NDS.128.0F.WIG 55 /r
VANDNPS xmm1, xmm2,
xmm3/m128
B V/V AVX Return the bitwise logical
AND NOT of packed single-
precision floating-point
values in xmm2 and
xmm3/mem.
VEX.NDS.256.0F.WIG 55 /r
VANDNPS ymm1, ymm2,
ymm3/m256
B V/V AVX Return the bitwise logical
AND NOT of packed single-
precision floating-point
values in ymm2 and
ymm3/mem.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

3-74 Vol. 2A ANDNPS—Bitwise Logical AND NOT of Packed Single-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
Operation
ANDNPS (128-bit Legacy SSE version)
DEST[31:0] (NOT(DEST[31:0])) BITWISE AND SRC[31:0]
DEST[63:32] (NOT(DEST[63:32])) BITWISE AND SRC[63:32]
DEST[95:64] (NOT(DEST[95:64])) BITWISE AND SRC[95:64]
DEST[127:96] (NOT(DEST[127:96])) BITWISE AND SRC[127:96]
DEST[VLMAX-1:128] (Unmodified)
VANDNPS (VEX.128 encoded version)
DEST[31:0] (NOT(SRC1[31:0])) BITWISE AND SRC2[31:0]
DEST[63:32] (NOT(SRC1[63:32])) BITWISE AND SRC2[63:32]
DEST[95:64] (NOT(SRC1[95:64])) BITWISE AND SRC2[95:64]
DEST[127:96] (NOT(SRC1[127:96])) BITWISE AND SRC2[127:96]
DEST[VLMAX-1:128] 0
VANDNPS (VEX.256 encoded version)
DEST[31:0] (NOT(SRC1[31:0])) BITWISE AND SRC2[31:0]
DEST[63:32] (NOT(SRC1[63:32])) BITWISE AND SRC2[63:32]
DEST[95:64] (NOT(SRC1[95:64])) BITWISE AND SRC2[95:64]
DEST[127:96] (NOT(SRC1[127:96])) BITWISE AND SRC2[127:96]
DEST[159:128] (NOT(SRC1[159:128])) BITWISE AND SRC2[159:128]
DEST[191:160] (NOT(SRC1[191:160])) BITWISE AND SRC2[191:160]
DEST[223:192] (NOT(SRC1[223:192])) BITWISE AND SRC2[223:192]
DEST[255:224] (NOT(SRC1[255:224])) BITWISE AND SRC2[255:224].
Intel C/C++ Compiler Intrinsic Equivalent
ANDNPS __m128 _mm_andnot_ps(__m128 a, __m128 b)
VANDNPS __m256 _mm256_andnot_ps (__m256 a, __m256 b)
SIMD Floating-Point Exceptions
None.
Other Exceptions
See Exceptions Type 4.

Vol. 2A 3-75
INSTRUCTION SET REFERENCE, A-M
ARPL—Adjust RPL Field of Segment Selector
ARPL—Adjust RPL Field of Segment Selector
Instruction Operand Encoding
Description
Compares the RPL fields of two segment selectors. The first operand (the destination
operand) contains one segment selector and the second operand (source operand)
contains the other. (The RPL field is located in bits 0 and 1 of each operand.) If the
RPL field of the destination operand is less than the RPL field of the source operand,
the ZF flag is set and the RPL field of the destination operand is increased to match
that of the source operand. Otherwise, the ZF flag is cleared and no change is made
to the destination operand. (The destination operand can be a word register or a
memory location; the source operand must be a word register.)
The ARPL instruction is provided for use by operating-system procedures (however, it
can also be used by applications). It is generally used to adjust the RPL of a segment
selector that has been passed to the operating system by an application program to
match the privilege level of the application program. Here the segment selector
passed to the operating system is placed in the destination operand and segment
selector for the application program’s code segment is placed in the source operand.
(The RPL field in the source operand represents the privilege level of the application
program.) Execution of the ARPL instruction then ensures that the RPL of the
segment selector received by the operating system is no lower (does not have a
higher privilege) than the privilege level of the application program (the segment
selector for the application program’s code segment can be read from the stack
following a procedure call).
This instruction executes as described in compatibility mode and legacy mode. It is
not encodable in 64-bit mode.
See “Checking Caller Access Privileges” in Chapter 3, “Protected-Mode Memory
Management,” of the Intel® 64 and IA-32 Architectures Software Developer’s
Manual, Volume 3A, for more information about the use of this instruction.
Opcode Instruction Op/
En
64-bit
Mode
Compat/
Leg Mode
Description
63 /rARPL r/m16, r16 AN. E. Valid Adjust RPL of r/m16 to not
less than RPL of r16.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (w) ModRM:reg (r) NA NA

3-76 Vol. 2A ARPL—Adjust RPL Field of Segment Selector
INSTRUCTION SET REFERENCE, A-M
Operation
IF 64-BIT MODE
THEN
See MOVSXD;
ELSE
IF DEST[RPL) < SRC[RPL)
THEN
ZF ← 1;
DEST[RPL) ← SRC[RPL);
ELSE
ZF ← 0;
FI;
FI;
Flags Affected
The ZF flag is set to 1 if the RPL field of the destination operand is less than that of
the source operand; otherwise, it is set to 0.
Protected Mode Exceptions
#GP(0) If the destination is located in a non-writable segment.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register is used to access memory and it
contains a NULL segment selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#UD The ARPL instruction is not recognized in real-address mode.
If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#UD The ARPL instruction is not recognized in virtual-8086 mode.
If the LOCK prefix is used.

Vol. 2A 3-77
INSTRUCTION SET REFERENCE, A-M
ARPL—Adjust RPL Field of Segment Selector
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Not applicable.

3-78 Vol. 2A BLENDPD — Blend Packed Double Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
BLENDPD — Blend Packed Double Precision Floating-Point Values
Instruction Operand Encoding
Description
Double-precision floating-point values from the second source operand (third
operand) are conditionally merged with values from the first source operand (second
operand) and written to the destination operand (first operand). The immediate bits
[3:0] determine whether the corresponding double-precision floating-point value in
the destination is copied from the second source or first source. If a bit in the mask,
corresponding to a word, is “1", then the double-precision floating-point value in the
second source operand is copied, else the value in the first source operand is copied.
128-bit Legacy SSE version: The second source can be an XMM register or an 128-bit
memory location. The destination is not distinct from the first source XMM register
and the upper bits (VLMAX-1:128) of the corresponding YMM register destination are
unmodified.
VEX.128 encoded version: the first source operand is an XMM register. The second
source operand is an XMM register or 128-bit memory location. The destination
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 3A 0D /r ib
BLENDPD xmm1, xmm2/m128,
imm8
A V/V SSE4_1 Select packed DP-FP values
from xmm1 and
xmm2/m128 from mask
specified in imm8 and store
the values into xmm1.
VEX.NDS.128.66.0F3A.WIG 0D /r ib
VBLENDPD xmm1, xmm2,
xmm3/m128, imm8
B V/V AVX Select packed double-
precision floating-point
Values from xmm2 and
xmm3/m128 from mask in
imm8 and store the values
in xmm1.
VEX.NDS.256.66.0F3A.WIG 0D /r ib
VBLENDPD ymm1, ymm2,
ymm3/m256, imm8
B V/V AVX Select packed double-
precision floating-point
Values from ymm2 and
ymm3/m256 from mask in
imm8 and store the values
in ymm1.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) imm8 NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) imm8[3:0]

Vol. 2A 3-79
INSTRUCTION SET REFERENCE, A-M
BLENDPD — Blend Packed Double Precision Floating-Point Values
operand is an XMM register. The upper bits (VLMAX-1:128) of the corresponding YMM
register destination are zeroed.
VEX.256 encoded version: The first source operand is a YMM register. The second
source operand can be a YMM register or a 256-bit memory location. The destination
operand is a YMM register.
Operation
BLENDPD (128-bit Legacy SSE version)
IF (IMM8[0] = 0)THEN DEST[63:0] DEST[63:0]
ELSE DEST [63:0] SRC[63:0] FI
IF (IMM8[1] = 0) THEN DEST[127:64] DEST[127:64]
ELSE DEST [127:64] SRC[127:64] FI
DEST[VLMAX-1:128] (Unmodified)
VBLENDPD (VEX.128 encoded version)
IF (IMM8[0] = 0)THEN DEST[63:0] SRC1[63:0]
ELSE DEST [63:0] SRC2[63:0] FI
IF (IMM8[1] = 0) THEN DEST[127:64] SRC1[127:64]
ELSE DEST [127:64] SRC2[127:64] FI
DEST[VLMAX-1:128] 0
VBLENDPD (VEX.256 encoded version)
IF (IMM8[0] = 0)THEN DEST[63:0] SRC1[63:0]
ELSE DEST [63:0] SRC2[63:0] FI
IF (IMM8[1] = 0) THEN DEST[127:64] SRC1[127:64]
ELSE DEST [127:64] SRC2[127:64] FI
IF (IMM8[2] = 0) THEN DEST[191:128] SRC1[191:128]
ELSE DEST [191:128] SRC2[191:128] FI
IF (IMM8[3] = 0) THEN DEST[255:192] SRC1[255:192]
ELSE DEST [255:192] SRC2[255:192] FI
Intel C/C++ Compiler Intrinsic Equivalent
BLENDPD __m128d _mm_blend_pd (__m128d v1, __m128d v2, const int mask);
VBLENDPD __m256d _mm256_blend_pd (__m256d a, __m256d b, const int mask);
SIMD Floating-Point Exceptions
None
Other Exceptions
See Exceptions Type 4.

3-80 Vol. 2A BLENDPS — Blend Packed Single Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
BLENDPS — Blend Packed Single Precision Floating-Point Values
Instruction Operand Encoding
Description
Packed single-precision floating-point values from the second source operand (third
operand) are conditionally merged with values from the first source operand (second
operand) and written to the destination operand (first operand). The immediate bits
[7:0] determine whether the corresponding single precision floating-point value in
the destination is copied from the second source or first source. If a bit in the mask,
corresponding to a word, is “1", then the single-precision floating-point value in the
second source operand is copied, else the value in the first source operand is copied.
128-bit Legacy SSE version: The second source can be an XMM register or an 128-bit
memory location. The destination is not distinct from the first source XMM register
and the upper bits (VLMAX-1:128) of the corresponding YMM register destination are
unmodified.
VEX.128 encoded version: The first source operand an XMM register. The second
source operand is an XMM register or 128-bit memory location. The destination
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 3A 0C /r ib
BLENDPS xmm1, xmm2/m128,
imm8
A V/V SSE4_1 Select packed single
precision floating-point
values from xmm1 and
xmm2/m128 from mask
specified in imm8 and store
the values into xmm1.
VEX.NDS.128.66.0F3A.WIG 0C /r ib
VBLENDPS xmm1, xmm2,
xmm3/m128, imm8
B V/V AVX Select packed single-
precision floating-point
values from xmm2 and
xmm3/m128 from mask in
imm8 and store the values
in xmm1.
VEX.NDS.256.66.0F3A.WIG 0C /r ib
VBLENDPS ymm1, ymm2,
ymm3/m256, imm8
B V/V AVX Select packed single-
precision floating-point
values from ymm2 and
ymm3/m256 from mask in
imm8 and store the values
in ymm1.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) imm8 NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) imm8

Vol. 2A 3-81
INSTRUCTION SET REFERENCE, A-M
BLENDPS — Blend Packed Single Precision Floating-Point Values
operand is an XMM register. The upper bits (VLMAX-1:128) of the corresponding YMM
register destination are zeroed.
VEX.256 encoded version: The first source operand is a YMM register. The second
source operand can be a YMM register or a 256-bit memory location. The destination
operand is a YMM register.
Operation
BLENDPS (128-bit Legacy SSE version)
IF (IMM8[0] = 0) THEN DEST[31:0] DEST[31:0]
ELSE DEST [31:0] SRC[31:0] FI
IF (IMM8[1] = 0) THEN DEST[63:32] DEST[63:32]
ELSE DEST [63:32] SRC[63:32] FI
IF (IMM8[2] = 0) THEN DEST[95:64] DEST[95:64]
ELSE DEST [95:64] SRC[95:64] FI
IF (IMM8[3] = 0) THEN DEST[127:96] DEST[127:96]
ELSE DEST [127:96] SRC[127:96] FI
DEST[VLMAX-1:128] (Unmodified)
VBLENDPS (VEX.128 encoded version)
IF (IMM8[0] = 0) THEN DEST[31:0] SRC1[31:0]
ELSE DEST [31:0] SRC2[31:0] FI
IF (IMM8[1] = 0) THEN DEST[63:32] SRC1[63:32]
ELSE DEST [63:32] SRC2[63:32] FI
IF (IMM8[2] = 0) THEN DEST[95:64] SRC1[95:64]
ELSE DEST [95:64] SRC2[95:64] FI
IF (IMM8[3] = 0) THEN DEST[127:96] SRC1[127:96]
ELSE DEST [127:96] SRC2[127:96] FI
DEST[VLMAX-1:128] 0
VBLENDPS (VEX.256 encoded version)
IF (IMM8[0] = 0) THEN DEST[31:0] SRC1[31:0]
ELSE DEST [31:0] SRC2[31:0] FI
IF (IMM8[1] = 0) THEN DEST[63:32] SRC1[63:32]
ELSE DEST [63:32] SRC2[63:32] FI
IF (IMM8[2] = 0) THEN DEST[95:64] SRC1[95:64]
ELSE DEST [95:64] SRC2[95:64] FI
IF (IMM8[3] = 0) THEN DEST[127:96] SRC1[127:96]
ELSE DEST [127:96] SRC2[127:96] FI
IF (IMM8[4] = 0) THEN DEST[159:128] SRC1[159:128]
ELSE DEST [159:128] SRC2[159:128] FI
IF (IMM8[5] = 0) THEN DEST[191:160] SRC1[191:160]
ELSE DEST [191:160] SRC2[191:160] FI

3-82 Vol. 2A BLENDPS — Blend Packed Single Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
IF (IMM8[6] = 0) THEN DEST[223:192] SRC1[223:192]
ELSE DEST [223:192] SRC2[223:192] FI
IF (IMM8[7] = 0) THEN DEST[255:224] SRC1[255:224]
ELSE DEST [255:224] SRC2[255:224] FI.
Intel C/C++ Compiler Intrinsic Equivalent
BLENDPS __m128 _mm_blend_ps (__m128 v1, __m128 v2, const int mask);
VBLENDPS __m256 _mm256_blend_ps (__m256 a, __m256 b, const int mask);
SIMD Floating-Point Exceptions
None
Other Exceptions
See Exceptions Type 4.
Vol. 2A 3-83
INSTRUCTION SET REFERENCE, A-M
BLENDVPD — Variable Blend Packed Double Precision Floating-Point Values
BLENDVPD — Variable Blend Packed Double Precision Floating-Point
Values
Instruction Operand Encoding
Description
Conditionally copy each quadword data element of double-precision floating-point
value from the second source operand and the first source operand depending on
mask bits defined in the mask register operand. The mask bits are the most signifi-
cant bit in each quadword element of the mask register.
Each quadword element of the destination operand is copied from:
•the corresponding quadword element in the second source operand, If a mask bit
is “1"; or
•the corresponding quadword element in the first source operand, If a mask bit is
“0"
The register assignment of the implicit mask operand for BLENDVPD is defined to be
the architectural register XMM0.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 38 15 /r
BLENDVPD xmm1, xmm2/m128 ,
<XMM0>
A V/V SSE4_1 Select packed DP FP values
from xmm1 and xmm2 from
mask specified in XMM0 and
store the values in xmm1.
VEX.NDS.128.66.0F3A.W0 4B /r /is4
VBLENDVPD xmm1, xmm2,
xmm3/m128, xmm4
B V/V AVX Conditionally copy double-
precision floating-point
values from xmm2 or
xmm3/m128 to xmm1,
based on mask bits in the
mask operand, xmm4.
VEX.NDS.256.66.0F3A.W0 4B /r /is4
VBLENDVPD ymm1, ymm2,
ymm3/m256, ymm4
B V/V AVX Conditionally copy double-
precision floating-point
values from ymm2 or
ymm3/m256 to ymm1,
based on mask bits in the
mask operand, ymm4.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) implicit XMM0 NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) imm8[7:4]

3-84 Vol. 2A BLENDVPD — Variable Blend Packed Double Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
128-bit Legacy SSE version: The first source operand and the destination operand is
the same. Bits (VLMAX-1:128) of the corresponding YMM destination register remain
unchanged. The mask register operand is implicitly defined to be the architectural
register XMM0. An attempt to execute BLENDVPD with a VEX prefix will cause #UD.
VEX.128 encoded version: The first source operand and the destination operand are
XMM registers. The second source operand is an XMM register or 128-bit memory
location. The mask operand is the third source register, and encoded in bits[7:4] of
the immediate byte(imm8). The bits[3:0] of imm8 are ignored. In 32-bit mode,
imm8[7] is ignored. The upper bits (VLMAX-1:128) of the corresponding YMM
register (destination register) are zeroed. VEX.W must be 0, otherwise, the instruc-
tion will #UD.
VEX.256 encoded version: The first source operand and destination operand are YMM
registers. The second source operand can be a YMM register or a 256-bit memory
location. The mask operand is the third source register, and encoded in bits[7:4] of
the immediate byte(imm8). The bits[3:0] of imm8 are ignored. In 32-bit mode,
imm8[7] is ignored. VEX.W must be 0, otherwise, the instruction will #UD.
VBLENDVPD permits the mask to be any XMM or YMM register. In contrast,
BLENDVPD treats XMM0 implicitly as the mask and do not support non-destructive
destination operation.
Operation
BLENDVPD (128-bit Legacy SSE version)
MASK XMM0
IF (MASK[63] = 0) THEN DEST[63:0] DEST[63:0]
ELSE DEST [63:0] SRC[63:0] FI
IF (MASK[127] = 0) THEN DEST[127:64] DEST[127:64]
ELSE DEST [127:64] SRC[127:64] FI
DEST[VLMAX-1:128] (Unmodified)
VBLENDVPD (VEX.128 encoded version)
MASK SRC3
IF (MASK[63] = 0) THEN DEST[63:0] SRC1[63:0]
ELSE DEST [63:0] SRC2[63:0] FI
IF (MASK[127] = 0) THEN DEST[127:64] SRC1[127:64]
ELSE DEST [127:64] SRC2[127:64] FI
DEST[VLMAX-1:128] 0
VBLENDVPD (VEX.256 encoded version)
MASK SRC3
IF (MASK[63] = 0) THEN DEST[63:0] SRC1[63:0]
ELSE DEST [63:0] SRC2[63:0] FI
IF (MASK[127] = 0) THEN DEST[127:64] SRC1[127:64]
ELSE DEST [127:64] SRC2[127:64] FI

Vol. 2A 3-85
INSTRUCTION SET REFERENCE, A-M
BLENDVPD — Variable Blend Packed Double Precision Floating-Point Values
IF (MASK[191] = 0) THEN DEST[191:128] SRC1[191:128]
ELSE DEST [191:128] SRC2[191:128] FI
IF (MASK[255] = 0) THEN DEST[255:192] SRC1[255:192]
ELSE DEST [255:192] SRC2[255:192] FI
Intel C/C++ Compiler Intrinsic Equivalent
BLENDVPD __m128d _mm_blendv_pd(__m128d v1, __m128d v2, __m128d v3);
VBLENDVPD __m128 _mm_blendv_pd (__m128d a, __m128d b, __m128d mask);
VBLENDVPD __m256 _mm256_blendv_pd (__m256d a, __m256d b, __m256d mask);
SIMD Floating-Point Exceptions
None
Other Exceptions
See Exceptions Type 4; additionally
#UD If VEX.W = 1.

3-86 Vol. 2A BLENDVPS — Variable Blend Packed Single Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
BLENDVPS — Variable Blend Packed Single Precision Floating-Point
Values
Instruction Operand Encoding
Description
Conditionally copy each dword data element of single-precision floating-point value
from the second source operand and the first source operand depending on mask bits
defined in the mask register operand. The mask bits are the most significant bit in
each dword element of the mask register.
Each quadword element of the destination operand is copied from:
•the corresponding dword element in the second source operand, If a mask bit is
“1"; or
•the corresponding dword element in the first source operand, If a mask bit is “0"
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 38 14 /r
BLENDVPS xmm1, xmm2/m128,
<XMM0>
A V/V SSE4_1 Select packed single
precision floating-point
values from xmm1 and
xmm2/m128 from mask
specified in XMM0 and store
the values into xmm1.
VEX.NDS.128.66.0F3A.W0 4A /r /is4
VBLENDVPS xmm1, xmm2,
xmm3/m128, xmm4
B V/V AVX Conditionally copy single-
precision floating-point
values from xmm2 or
xmm3/m128 to xmm1,
based on mask bits in the
specified mask operand,
xmm4.
VEX.NDS.256.66.0F3A.W0 4A /r /is4
VBLENDVPS ymm1, ymm2,
ymm3/m256, ymm4
B V/V AVX Conditionally copy single-
precision floating-point
values from ymm2 or
ymm3/m256 to ymm1,
based on mask bits in the
specified mask register,
ymm4.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) implicit XMM0 NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) imm8[7:4]

Vol. 2A 3-87
INSTRUCTION SET REFERENCE, A-M
BLENDVPS — Variable Blend Packed Single Precision Floating-Point Values
The register assignment of the implicit mask operand for BLENDVPS is defined to be
the architectural register XMM0.
128-bit Legacy SSE version: The first source operand and the destination operand is
the same. Bits (VLMAX-1:128) of the corresponding YMM destination register remain
unchanged. The mask register operand is implicitly defined to be the architectural
register XMM0. An attempt to execute BLENDVPS with a VEX prefix will cause #UD.
VEX.128 encoded version: The first source operand and the destination operand are
XMM registers. The second source operand is an XMM register or 128-bit memory
location. The mask operand is the third source register, and encoded in bits[7:4] of
the immediate byte(imm8). The bits[3:0] of imm8 are ignored. In 32-bit mode,
imm8[7] is ignored. The upper bits (VLMAX-1:128) of the corresponding YMM
register (destination register) are zeroed. VEX.W must be 0, otherwise, the instruc-
tion will #UD.
VEX.256 encoded version: The first source operand and destination operand are YMM
registers. The second source operand can be a YMM register or a 256-bit memory
location. The mask operand is the third source register, and encoded in bits[7:4] of
the immediate byte(imm8). The bits[3:0] of imm8 are ignored. In 32-bit mode,
imm8[7] is ignored. VEX.W must be 0, otherwise, the instruction will #UD.
VBLENDVPS permits the mask to be any XMM or YMM register. In contrast,
BLENDVPS treats XMM0 implicitly as the mask and do not support non-destructive
destination operation.
Operation
BLENDVPS (128-bit Legacy SSE version)
MASK XMM0
IF (MASK[31] = 0) THEN DEST[31:0] DEST[31:0]
ELSE DEST [31:0] SRC[31:0] FI
IF (MASK[63] = 0) THEN DEST[63:32] DEST[63:32]
ELSE DEST [63:32] SRC[63:32] FI
IF (MASK[95] = 0) THEN DEST[95:64] DEST[95:64]
ELSE DEST [95:64] SRC[95:64] FI
IF (MASK[127] = 0) THEN DEST[127:96] DEST[127:96]
ELSE DEST [127:96] SRC[127:96] FI
DEST[VLMAX-1:128] (Unmodified)
VBLENDVPS (VEX.128 encoded version)
MASK SRC3
IF (MASK[31] = 0) THEN DEST[31:0] SRC1[31:0]
ELSE DEST [31:0] SRC2[31:0] FI
IF (MASK[63] = 0) THEN DEST[63:32] SRC1[63:32]
ELSE DEST [63:32] SRC2[63:32] FI
IF (MASK[95] = 0) THEN DEST[95:64] SRC1[95:64]
ELSE DEST [95:64] SRC2[95:64] FI

3-88 Vol. 2A BLENDVPS — Variable Blend Packed Single Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
IF (MASK[127] = 0) THEN DEST[127:96] SRC1[127:96]
ELSE DEST [127:96] SRC2[127:96] FI
DEST[VLMAX-1:128] 0
VBLENDVPS (VEX.256 encoded version)
MASK SRC3
IF (MASK[31] = 0) THEN DEST[31:0] SRC1[31:0]
ELSE DEST [31:0] SRC2[31:0] FI
IF (MASK[63] = 0) THEN DEST[63:32] SRC1[63:32]
ELSE DEST [63:32] SRC2[63:32] FI
IF (MASK[95] = 0) THEN DEST[95:64] SRC1[95:64]
ELSE DEST [95:64] SRC2[95:64] FI
IF (MASK[127] = 0) THEN DEST[127:96] SRC1[127:96]
ELSE DEST [127:96] SRC2[127:96] FI
IF (MASK[159] = 0) THEN DEST[159:128] SRC1[159:128]
ELSE DEST [159:128] SRC2[159:128] FI
IF (MASK[191] = 0) THEN DEST[191:160] SRC1[191:160]
ELSE DEST [191:160] SRC2[191:160] FI
IF (MASK[223] = 0) THEN DEST[223:192] SRC1[223:192]
ELSE DEST [223:192] SRC2[223:192] FI
IF (MASK[255] = 0) THEN DEST[255:224] SRC1[255:224]
ELSE DEST [255:224] SRC2[255:224] FI
Intel C/C++ Compiler Intrinsic Equivalent
BLENDVPS __m128 _mm_blendv_ps(__m128 v1, __m128 v2, __m128 v3);
VBLENDVPS __m128 _mm_blendv_ps (__m128 a, __m128 b, __m128 mask);
VBLENDVPS __m256 _mm256_blendv_ps (__m256 a, __m256 b, __m256 mask);
SIMD Floating-Point Exceptions
None
Other Exceptions
See Exceptions Type 4; additionally
#UD If VEX.W = 1.
Vol. 2A 3-89
INSTRUCTION SET REFERENCE, A-M
BOUND—Check Array Index Against Bounds
BOUND—Check Array Index Against Bounds
Instruction Operand Encoding
Description
BOUND determines if the first operand (array index) is within the bounds of an array
specified the second operand (bounds operand). The array index is a signed integer
located in a register. The bounds operand is a memory location that contains a pair of
signed doubleword-integers (when the operand-size attribute is 32) or a pair of
signed word-integers (when the operand-size attribute is 16). The first doubleword
(or word) is the lower bound of the array and the second doubleword (or word) is the
upper bound of the array. The array index must be greater than or equal to the lower
bound and less than or equal to the upper bound plus the operand size in bytes. If the
index is not within bounds, a BOUND range exceeded exception (#BR) is signaled.
When this exception is generated, the saved return instruction pointer points to the
BOUND instruction.
The bounds limit data structure (two words or doublewords containing the lower and
upper limits of the array) is usually placed just before the array itself, making the
limits addressable via a constant offset from the beginning of the array. Because the
address of the array already will be present in a register, this practice avoids extra
bus cycles to obtain the effective address of the array bounds.
This instruction executes as described in compatibility mode and legacy mode. It is
not valid in 64-bit mode.
Operation
IF 64bit Mode
THEN
#UD;
ELSE
IF (ArrayIndex < LowerBound OR ArrayIndex > UpperBound)
(* Below lower bound or above upper bound *)
Opcode Instruction Op/
En
64-bit
Mode
Compat/
Leg Mode
Description
62 /rBOUND r16,
m16&16
AInvalid Valid Check if r16 (array index) is
within bounds specified by
m16&16.
62 /rBOUND r32,
m32&32
AInvalid Valid Check if r32 (array index) is
within bounds specified by
m16&16.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r) ModRM:r/m (r) NA NA

3-90 Vol. 2A BOUND—Check Array Index Against Bounds
INSTRUCTION SET REFERENCE, A-M
THEN #BR; FI;
FI;
Flags Affected
None.
Protected Mode Exceptions
#BR If the bounds test fails.
#UD If second operand is not a memory location.
If the LOCK prefix is used.
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
Real-Address Mode Exceptions
#BR If the bounds test fails.
#UD If second operand is not a memory location.
If the LOCK prefix is used.
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
Virtual-8086 Mode Exceptions
#BR If the bounds test fails.
#UD If second operand is not a memory location.
If the LOCK prefix is used.
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.

Vol. 2A 3-91
INSTRUCTION SET REFERENCE, A-M
BOUND—Check Array Index Against Bounds
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#UD If in 64-bit mode.

3-92 Vol. 2A VBROADCAST—Load with Broadcast
INSTRUCTION SET REFERENCE, A-M
VBROADCAST—Load with Broadcast
Instruction Operand Encoding
Description
Load floating point values from the source operand (second operand) and broadcast
to all elements of the destination operand (first operand).
The destination operand is a YMM register. The source operand is either a 32-bit, 64-
bit, or 128-bit memory location. Register source encodings are reserved and will
#UD.
VBROADCASTSD and VBROADCASTF128 are only supported as 256-bit wide
versions. VBROADCASTSS is supported in both 128-bit and 256-bit wide versions.
Note: In VEX-encoded versions, VEX.vvvv is reserved and must be 1111b otherwise
instructions will #UD.
If VBROADCASTSD or VBROADCASTF128 is encoded with VEX.L= 0, an attempt to
execute the instruction encoded with VEX.L= 0 will cause an #UD exception.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
VEX.128.66.0F38.W0 18 /r
VBROADCASTSS xmm1, m32
A I/V AVX Broadcast single-precision
floating-point element in
mem to four locations in
xmm1.
VEX.256.66.0F38.W0 18 /r
VBROADCASTSS ymm1, m32
A V/V AVX Broadcast single-precision
floating-point element in
mem to eight locations in
ymm1.
VEX.256.66.0F38.W0 19 /r
VBROADCASTSD ymm1, m64
A V/V AVX Broadcast double-precision
floating-point element in
mem to four locations in
ymm1.
VEX.256.66.0F38.W0 1A /r
VBROADCASTF128 ymm1, m128
A V/V AVX Broadcast 128 bits of
floating-point data in mem
to low and high 128-bits in
ymm1.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA
Vol. 2A 3-93
INSTRUCTION SET REFERENCE, A-M
VBROADCAST—Load with Broadcast
Figure 3-5. VBROADCASTSS Operation (VEX.256 encoded version)
Figure 3-6. VBROADCASTSS Operation (128-bit version)
DEST
m32 X0
X0X0 X0X0 X0X0 X0X0
DEST
m32 X0
X0X0 X00X00 00
3-94 Vol. 2A VBROADCAST—Load with Broadcast
INSTRUCTION SET REFERENCE, A-M
Operation
VBROADCASTSS (128 bit version)
temp SRC[31:0]
DEST[31:0] temp
DEST[63:32] temp
DEST[95:64] temp
DEST[127:96] temp
DEST[VLMAX-1:128] 0
VBROADCASTSS (VEX.256 encoded version)
Figure 3-7. VBROADCASTSD Operation
Figure 3-8. VBROADCASTF128 Operation
DEST
m64 X0
X0X0X0X0
DEST
m128 X0
X0X0

Vol. 2A 3-95
INSTRUCTION SET REFERENCE, A-M
VBROADCAST—Load with Broadcast
temp SRC[31:0]
DEST[31:0] temp
DEST[63:32] temp
DEST[95:64] temp
DEST[127:96] temp
DEST[159:128] temp
DEST[191:160] temp
DEST[223:192] temp
DEST[255:224] temp
VBROADCASTSD (VEX.256 encoded version)
temp SRC[63:0]
DEST[63:0] temp
DEST[127:64] temp
DEST[191:128] temp
DEST[255:192] temp
VBROADCASTF128
temp SRC[127:0]
DEST[127:0] temp
DEST[VLMAX-1:128] temp
Intel C/C++ Compiler Intrinsic Equivalent
VBROADCASTSS __m128 _mm_broadcast_ss(float *a);
VBROADCASTSS __m256 _mm256_broadcast_ss(float *a);
VBROADCASTSD __m256d _mm256_broadcast_sd(double *a);
VBROADCASTF128 __m256 _mm256_broadcast_ps(__m128 * a);
VBROADCASTF128 __m256d _mm256_broadcast_pd(__m128d * a);
Flags Affected
None.
Other Exceptions
See Exceptions Type 6; additionally
#UD If VEX.L = 0 for VBROADCASTSD
If VEX.L = 0 for VBROADCASTF128
If VEX.W = 1.

3-96 Vol. 2A BSF—Bit Scan Forward
INSTRUCTION SET REFERENCE, A-M
BSF—Bit Scan Forward
Instruction Operand Encoding
Description
Searches the source operand (second operand) for the least significant set bit (1 bit).
If a least significant 1 bit is found, its bit index is stored in the destination operand
(first operand). The source operand can be a register or a memory location; the
destination operand is a register. The bit index is an unsigned offset from bit 0 of the
source operand. If the content of the source operand is 0, the content of the destina-
tion operand is undefined.
In 64-bit mode, the instruction’s default operation size is 32 bits. Using a REX prefix
in the form of REX.R permits access to additional registers (R8-R15). Using a REX
prefix in the form of REX.W promotes operation to 64 bits. See the summary chart at
the beginning of this section for encoding data and limits.
Operation
IF SRC = 0
THEN
ZF ← 1;
DEST is undefined;
ELSE
ZF ← 0;
temp ← 0;
WHILE Bit(SRC, temp) = 0
DO
temp ← temp + 1;
DEST ← temp;
OD;
FI;
Opcode Instruction Op/
En
64-bit
Mode
Compat/
Leg Mode
Description
0F BC /r BSF r16, r/m16 A Valid Valid Bit scan forward on r/m16.
0F BC /r BSF r32, r/m32 A Valid Valid Bit scan forward on r/m32.
REX.W + 0F BC BSF r64, r/m64 A Valid N.E. Bit scan forward on r/m64.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA

Vol. 2A 3-97
INSTRUCTION SET REFERENCE, A-M
BSF—Bit Scan Forward
Flags Affected
The ZF flag is set to 1 if all the source operand is 0; otherwise, the ZF flag is cleared.
The CF, OF, SF, AF, and PF, flags are undefined.
Protected Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.

3-98 Vol. 2A BSF—Bit Scan Forward
INSTRUCTION SET REFERENCE, A-M
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Vol. 2A 3-99
INSTRUCTION SET REFERENCE, A-M
BSR—Bit Scan Reverse
BSR—Bit Scan Reverse
Instruction Operand Encoding
Description
Searches the source operand (second operand) for the most significant set bit (1 bit).
If a most significant 1 bit is found, its bit index is stored in the destination operand
(first operand). The source operand can be a register or a memory location; the
destination operand is a register. The bit index is an unsigned offset from bit 0 of the
source operand. If the content source operand is 0, the content of the destination
operand is undefined.
In 64-bit mode, the instruction’s default operation size is 32 bits. Using a REX prefix
in the form of REX.R permits access to additional registers (R8-R15). Using a REX
prefix in the form of REX.W promotes operation to 64 bits. See the summary chart at
the beginning of this section for encoding data and limits.
Operation
IF SRC = 0
THEN
ZF ← 1;
DEST is undefined;
ELSE
ZF ← 0;
temp ← OperandSize – 1;
WHILE Bit(SRC, temp) = 0
DO
temp ← temp - 1;
DEST ← temp;
OD;
FI;
Opcode Instruction Op/
En
64-bit
Mode
Compat/
Leg Mode
Description
0F BD /r BSR r16, r/m16 A Valid Valid Bit scan reverse on r/m16.
0F BD /r BSR r32, r/m32 A Valid Valid Bit scan reverse on r/m32.
REX.W + 0F BD BSR r64, r/m64 A Valid N.E. Bit scan reverse on r/m64.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA

3-100 Vol. 2A BSR—Bit Scan Reverse
INSTRUCTION SET REFERENCE, A-M
Flags Affected
The ZF flag is set to 1 if all the source operand is 0; otherwise, the ZF flag is cleared.
The CF, OF, SF, AF, and PF, flags are undefined.
Protected Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.

Vol. 2A 3-101
INSTRUCTION SET REFERENCE, A-M
BSR—Bit Scan Reverse
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.

3-102 Vol. 2A BSWAP—Byte Swap
INSTRUCTION SET REFERENCE, A-M
BSWAP—Byte Swap
Instruction Operand Encoding
Description
Reverses the byte order of a 32-bit or 64-bit (destination) register. This instruction is
provided for converting little-endian values to big-endian format and vice versa. To
swap bytes in a word value (16-bit register), use the XCHG instruction. When the
BSWAP instruction references a 16-bit register, the result is undefined.
In 64-bit mode, the instruction’s default operation size is 32 bits. Using a REX prefix
in the form of REX.R permits access to additional registers (R8-R15). Using a REX
prefix in the form of REX.W promotes operation to 64 bits. See the summary chart at
the beginning of this section for encoding data and limits.
IA-32 Architecture Legacy Compatibility
The BSWAP instruction is not supported on IA-32 processors earlier than the
Intel486™ processor family. For compatibility with this instruction, software
should include functionally equivalent code for execution on Intel processors earlier
than the Intel486 processor family.
Operation
TEMP ← DEST
IF 64-bit mode AND OperandSize = 64
THEN
DEST[7:0] ← TEMP[63:56];
DEST[15:8] ← TEMP[55:48];
DEST[23:16] ← TEMP[47:40];
DEST[31:24] ← TEMP[39:32];
DEST[39:32] ← TEMP[31:24];
Opcode Instruction Op/
En
64-bit
Mode
Compat/
Leg Mode
Description
0F C8+rd BSWAP r32 A Valid* Valid Reverses the byte order of
a 32-bit register.
REX.W + 0F
C8+rd
BSWAP r64 A Valid N.E. Reverses the byte order of
a 64-bit register.
NOTES:
* See IA-32 Architecture Compatibility section below.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A reg (r, w) NA NA NA

Vol. 2A 3-103
INSTRUCTION SET REFERENCE, A-M
BSWAP—Byte Swap
DEST[47:40] ← TEMP[23:16];
DEST[55:48] ← TEMP[15:8];
DEST[63:56] ← TEMP[7:0];
ELSE
DEST[7:0] ← TEMP[31:24];
DEST[15:8] ← TEMP[23:16];
DEST[23:16] ← TEMP[15:8];
DEST[31:24] ← TEMP[7:0];
FI;
Flags Affected
None.
Exceptions (All Operating Modes)
#UD If the LOCK prefix is used.

3-104 Vol. 2A BT—Bit Test
INSTRUCTION SET REFERENCE, A-M
BT—Bit Test
Instruction Operand Encoding
Description
Selects the bit in a bit string (specified with the first operand, called the bit base) at
the bit-position designated by the bit offset (specified by the second operand) and
stores the value of the bit in the CF flag. The bit base operand can be a register or a
memory location; the bit offset operand can be a register or an immediate value:
•If the bit base operand specifies a register, the instruction takes the modulo 16,
32, or 64 of the bit offset operand (modulo size depends on the mode and
register size; 64-bit operands are available only in 64-bit mode).
•If the bit base operand specifies a memory location, the operand represents the
address of the byte in memory that contains the bit base (bit 0 of the specified
byte) of the bit string. The range of the bit position that can be referenced by the
offset operand depends on the operand size.
See also: Bit(BitBase, BitOffset) on page 3-14.
Some assemblers support immediate bit offsets larger than 31 by using the imme-
diate bit offset field in combination with the displacement field of the memory
operand. In this case, the low-order 3 or 5 bits (3 for 16-bit operands, 5 for 32-bit
operands) of the immediate bit offset are stored in the immediate bit offset field, and
the high-order bits are shifted and combined with the byte displacement in the
addressing mode by the assembler. The processor will ignore the high order bits if
they are not zero.
When accessing a bit in memory, the processor may access 4 bytes starting from the
memory address for a 32-bit operand size, using by the following relationship:
Opcode Instruction Op/
En
64-bit
Mode
Compat/
Leg Mode
Description
0F A3 BT r/m16, r16 A Valid Valid Store selected bit in CF flag.
0F A3 BT r/m32, r32 A Valid Valid Store selected bit in CF flag.
REX.W + 0F A3 BT r/m64, r64 A Valid N.E. Store selected bit in CF flag.
0F BA /4 ib BT r/m16, imm8 B Valid Valid Store selected bit in CF flag.
0F BA /4 ib BT r/m32, imm8 B Valid Valid Store selected bit in CF flag.
REX.W + 0F BA
/4 ib
BT r/m64, imm8 B Valid N.E. Store selected bit in CF flag.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (r) ModRM:reg (r) NA NA
B ModRM:r/m (r) imm8 NA NA

Vol. 2A 3-105
INSTRUCTION SET REFERENCE, A-M
BT—Bit Test
Effective Address + (4 ∗ (BitOffset DIV 32))
Or, it may access 2 bytes starting from the memory address for a 16-bit operand,
using this relationship:
Effective Address + (2 ∗ (BitOffset DIV 16))
It may do so even when only a single byte needs to be accessed to reach the given
bit. When using this bit addressing mechanism, software should avoid referencing
areas of memory close to address space holes. In particular, it should avoid refer-
ences to memory-mapped I/O registers. Instead, software should use the MOV
instructions to load from or store to these addresses, and use the register form of
these instructions to manipulate the data.
In 64-bit mode, the instruction’s default operation size is 32 bits. Using a REX prefix
in the form of REX.R permits access to additional registers (R8-R15). Using a REX
prefix in the form of REX.W promotes operation to 64 bit operands. See the summary
chart at the beginning of this section for encoding data and limits.
Operation
CF ← Bit(BitBase, BitOffset);
Flags Affected
The CF flag contains the value of the selected bit. The ZF flag is unaffected. The OF,
SF, AF, and PF flags are undefined.
Protected Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#UD If the LOCK prefix is used.

3-106 Vol. 2A BT—Bit Test
INSTRUCTION SET REFERENCE, A-M
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Vol. 2A 3-107
INSTRUCTION SET REFERENCE, A-M
BTC—Bit Test and Complement
BTC—Bit Test and Complement
Instruction Operand Encoding
Description
Selects the bit in a bit string (specified with the first operand, called the bit base) at
the bit-position designated by the bit offset operand (second operand), stores the
value of the bit in the CF flag, and complements the selected bit in the bit string. The
bit base operand can be a register or a memory location; the bit offset operand can
be a register or an immediate value:
•If the bit base operand specifies a register, the instruction takes the modulo 16,
32, or 64 of the bit offset operand (modulo size depends on the mode and
register size; 64-bit operands are available only in 64-bit mode). This allows any
bit position to be selected.
•If the bit base operand specifies a memory location, the operand represents the
address of the byte in memory that contains the bit base (bit 0 of the specified
byte) of the bit string. The range of the bit position that can be referenced by the
offset operand depends on the operand size.
See also: Bit(BitBase, BitOffset) on page 3-14.
Some assemblers support immediate bit offsets larger than 31 by using the imme-
diate bit offset field in combination with the displacement field of the memory
operand. See “BT—Bit Test” in this chapter for more information on this addressing
mechanism.
Opcode Instruction Op/
En
64-bit
Mode
Compat/
Leg Mode
Description
0F BB BTC r/m16, r16 A Valid Valid Store selected bit in CF flag
and complement.
0F BB BTC r/m32, r32 A Valid Valid Store selected bit in CF flag
and complement.
REX.W + 0F BB BTC r/m64, r64 A Valid N.E. Store selected bit in CF flag
and complement.
0F BA /7 ib BTC r/m16, imm8 B Valid Valid Store selected bit in CF flag
and complement.
0F BA /7 ib BTC r/m32, imm8 B Valid Valid Store selected bit in CF flag
and complement.
REX.W + 0F BA
/7 ib
BTC r/m64, imm8 B Valid N.E. Store selected bit in CF flag
and complement.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (r, w) ModRM:reg (r) NA NA
B ModRM:r/m (r, w) imm8 NA NA

3-108 Vol. 2A BTC—Bit Test and Complement
INSTRUCTION SET REFERENCE, A-M
This instruction can be used with a LOCK prefix to allow the instruction to be
executed atomically.
In 64-bit mode, the instruction’s default operation size is 32 bits. Using a REX prefix
in the form of REX.R permits access to additional registers (R8-R15). Using a REX
prefix in the form of REX.W promotes operation to 64 bits. See the summary chart at
the beginning of this section for encoding data and limits.
Operation
CF ← Bit(BitBase, BitOffset);
Bit(BitBase, BitOffset) ← NOT Bit(BitBase, BitOffset);
Flags Affected
The CF flag contains the value of the selected bit before it is complemented. The ZF
flag is unaffected. The OF, SF, AF, and PF flags are undefined.
Protected Mode Exceptions
#GP(0) If the destination operand points to a non-writable segment.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used but the destination is not a memory
operand.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#UD If the LOCK prefix is used but the destination is not a memory
operand.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.

Vol. 2A 3-109
INSTRUCTION SET REFERENCE, A-M
BTC—Bit Test and Complement
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used but the destination is not a memory
operand.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used but the destination is not a memory
operand.

3-110 Vol. 2A BTR—Bit Test and Reset
INSTRUCTION SET REFERENCE, A-M
BTR—Bit Test and Reset
Instruction Operand Encoding
Description
Selects the bit in a bit string (specified with the first operand, called the bit base) at
the bit-position designated by the bit offset operand (second operand), stores the
value of the bit in the CF flag, and clears the selected bit in the bit string to 0. The bit
base operand can be a register or a memory location; the bit offset operand can be a
register or an immediate value:
•If the bit base operand specifies a register, the instruction takes the modulo 16,
32, or 64 of the bit offset operand (modulo size depends on the mode and
register size; 64-bit operands are available only in 64-bit mode). This allows any
bit position to be selected.
•If the bit base operand specifies a memory location, the operand represents the
address of the byte in memory that contains the bit base (bit 0 of the specified
byte) of the bit string. The range of the bit position that can be referenced by the
offset operand depends on the operand size.
See also: Bit(BitBase, BitOffset) on page 3-14.
Some assemblers support immediate bit offsets larger than 31 by using the imme-
diate bit offset field in combination with the displacement field of the memory
operand. See “BT—Bit Test” in this chapter for more information on this addressing
mechanism.
Opcode Instruction Op/
En
64-bit
Mode
Compat/
Leg Mode
Description
0F B3 BTR r/m16, r16 A Valid Valid Store selected bit in CF flag
and clear.
0F B3 BTR r/m32, r32 A Valid Valid Store selected bit in CF flag
and clear.
REX.W + 0F B3 BTR r/m64, r64 A Valid N.E. Store selected bit in CF flag
and clear.
0F BA /6 ib BTR r/m16, imm8 B Valid Valid Store selected bit in CF flag
and clear.
0F BA /6 ib BTR r/m32, imm8 B Valid Valid Store selected bit in CF flag
and clear.
REX.W + 0F BA
/6 ib
BTR r/m64, imm8 B Valid N.E. Store selected bit in CF flag
and clear.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (r, w) ModRM:reg (r) NA NA
B ModRM:r/m (r, w) imm8 NA NA

Vol. 2A 3-111
INSTRUCTION SET REFERENCE, A-M
BTR—Bit Test and Reset
This instruction can be used with a LOCK prefix to allow the instruction to be
executed atomically.
In 64-bit mode, the instruction’s default operation size is 32 bits. Using a REX prefix
in the form of REX.R permits access to additional registers (R8-R15). Using a REX
prefix in the form of REX.W promotes operation to 64 bits. See the summary chart at
the beginning of this section for encoding data and limits.
Operation
CF ← Bit(BitBase, BitOffset);
Bit(BitBase, BitOffset) ← 0;
Flags Affected
The CF flag contains the value of the selected bit before it is cleared. The ZF flag is
unaffected. The OF, SF, AF, and PF flags are undefined.
Protected Mode Exceptions
#GP(0) If the destination operand points to a non-writable segment.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used but the destination is not a memory
operand.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#UD If the LOCK prefix is used but the destination is not a memory
operand.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.

3-112 Vol. 2A BTR—Bit Test and Reset
INSTRUCTION SET REFERENCE, A-M
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used but the destination is not a memory
operand.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used but the destination is not a memory
operand.
Vol. 2A 3-113
INSTRUCTION SET REFERENCE, A-M
BTS—Bit Test and Set
BTS—Bit Test and Set
Instruction Operand Encoding
Description
Selects the bit in a bit string (specified with the first operand, called the bit base) at
the bit-position designated by the bit offset operand (second operand), stores the
value of the bit in the CF flag, and sets the selected bit in the bit string to 1. The bit
base operand can be a register or a memory location; the bit offset operand can be a
register or an immediate value:
•If the bit base operand specifies a register, the instruction takes the modulo 16,
32, or 64 of the bit offset operand (modulo size depends on the mode and
register size; 64-bit operands are available only in 64-bit mode). This allows any
bit position to be selected.
•If the bit base operand specifies a memory location, the operand represents the
address of the byte in memory that contains the bit base (bit 0 of the specified
byte) of the bit string. The range of the bit position that can be referenced by the
offset operand depends on the operand size.
See also: Bit(BitBase, BitOffset) on page 3-14.
Some assemblers support immediate bit offsets larger than 31 by using the imme-
diate bit offset field in combination with the displacement field of the memory
operand. See “BT—Bit Test” in this chapter for more information on this addressing
mechanism.
Opcode Instruction Op/
En
64-bit
Mode
Compat/
Leg Mode
Description
0F AB BTS r/m16, r16 A Valid Valid Store selected bit in CF flag
and set.
0F AB BTS r/m32, r32 A Valid Valid Store selected bit in CF flag
and set.
REX.W + 0F AB BTS r/m64, r64 A Valid N.E. Store selected bit in CF flag
and set.
0F BA /5 ib BTS r/m16, imm8 B Valid Valid Store selected bit in CF flag
and set.
0F BA /5 ib BTS r/m32, imm8 B Valid Valid Store selected bit in CF flag
and set.
REX.W + 0F BA
/5 ib
BTS r/m64, imm8 B Valid N.E. Store selected bit in CF flag
and set.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (r, w) ModRM:reg (r) NA NA
B ModRM:r/m (r, w) imm8 NA NA

3-114 Vol. 2A BTS—Bit Test and Set
INSTRUCTION SET REFERENCE, A-M
This instruction can be used with a LOCK prefix to allow the instruction to be
executed atomically.
In 64-bit mode, the instruction’s default operation size is 32 bits. Using a REX prefix
in the form of REX.R permits access to additional registers (R8-R15). Using a REX
prefix in the form of REX.W promotes operation to 64 bits. See the summary chart at
the beginning of this section for encoding data and limits.
Operation
CF ← Bit(BitBase, BitOffset);
Bit(BitBase, BitOffset) ← 1;
Flags Affected
The CF flag contains the value of the selected bit before it is set. The ZF flag is unaf-
fected. The OF, SF, AF, and PF flags are undefined.
Protected Mode Exceptions
#GP(0) If the destination operand points to a non-writable segment.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used but the destination is not a memory
operand.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#UD If the LOCK prefix is used but the destination is not a memory
operand.
Virtual-8086 Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.

Vol. 2A 3-115
INSTRUCTION SET REFERENCE, A-M
BTS—Bit Test and Set
#SS If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used but the destination is not a memory
operand.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used but the destination is not a memory
operand.

3-116 Vol. 2A CALL—Call Procedure
INSTRUCTION SET REFERENCE, A-M
CALL—Call Procedure
Opcode Instruction Op/
En
64-bit
Mode
Compat/
Leg Mode
Description
E8 cw CALL rel16 B N.S. Valid Call near, relative,
displacement relative to
next instruction.
E8 cd CALL rel32 B Valid Valid Call near, relative,
displacement relative to
next instruction. 32-bit
displacement sign extended
to 64-bits in 64-bit mode.
FF /2 CALL r/m16 B N.E. Valid Call near, absolute indirect,
address given in r/m16.
FF /2 CALL r/m32 B N.E. Valid Call near, absolute indirect,
address given in r/m32.
FF /2 CALL r/m64 B Valid N.E. Call near, absolute indirect,
address given in r/m64.
9A cd CALL ptr16:16 A Invalid Valid Call far, absolute, address
given in operand.
9A cp CALL ptr16:32 A Invalid Valid Call far, absolute, address
given in operand.
FF /3 CALL m16:16 B Valid Valid Call far, absolute indirect
address given in m16:16.
In 32-bit mode: if selector
points to a gate, then RIP =
32-bit zero extended
displacement taken from
gate; else RIP = zero
extended 16-bit offset from
far pointer referenced in
the instruction.
FF /3 CALL m16:32 B Valid Valid In 64-bit mode: If selector
points to a gate, then RIP =
64-bit displacement taken
from gate; else RIP = zero
extended 32-bit offset from
far pointer referenced in
the instruction.
Vol. 2A 3-117
INSTRUCTION SET REFERENCE, A-M
CALL—Call Procedure
Instruction Operand Encoding
Description
Saves procedure linking information on the stack and branches to the called proce-
dure specified using the target operand. The target operand specifies the address of
the first instruction in the called procedure. The operand can be an immediate value,
a general-purpose register, or a memory location.
This instruction can be used to execute four types of calls:
•Near Call — A call to a procedure in the current code segment (the segment
currently pointed to by the CS register), sometimes referred to as an intra-
segment call.
•Far Call — A call to a procedure located in a different segment than the current
code segment, sometimes referred to as an inter-segment call.
•Inter-privilege-level far call — A far call to a procedure in a segment at a
different privilege level than that of the currently executing program or
procedure.
•Task switch — A call to a procedure located in a different task.
The latter two call types (inter-privilege-level call and task switch) can only be
executed in protected mode. See “Calling Procedures Using Call and RET” in Chapter
6 of the Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 1,
for additional information on near, far, and inter-privilege-level calls. See Chapter 7,
“Task Management,” in the Intel® 64 and IA-32 Architectures Software Devel-
oper’s Manual, Volume 3A, for information on performing task switches with the
CALL instruction.
Near Call. When executing a near call, the processor pushes the value of the EIP
register (which contains the offset of the instruction following the CALL instruction)
on the stack (for use later as a return-instruction pointer). The processor then
Opcode Instruction Op/
En
64-bit
Mode
Compat/
Leg Mode
Description
REX.W + FF /3 CALL m16:64 B Valid N.E. In 64-bit mode: If selector
points to a gate, then RIP =
64-bit displacement taken
from gate; else RIP = 64-bit
offset from far pointer
referenced in the
instruction.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
AOffset NA NA NA
B ModRM:r/m (r) NA NA NA

3-118 Vol. 2A CALL—Call Procedure
INSTRUCTION SET REFERENCE, A-M
branches to the address in the current code segment specified by the target operand.
The target operand specifies either an absolute offset in the code segment (an offset
from the base of the code segment) or a relative offset (a signed displacement rela-
tive to the current value of the instruction pointer in the EIP register; this value
points to the instruction following the CALL instruction). The CS register is not
changed on near calls.
For a near call absolute, an absolute offset is specified indirectly in a general-purpose
register or a memory location (r/m16, r/m32, or r/m64). The operand-size attribute
determines the size of the target operand (16, 32 or 64 bits). When in 64-bit mode,
the operand size for near call (and all near branches) is forced to 64-bits. Absolute
offsets are loaded directly into the EIP(RIP) register. If the operand size attribute is
16, the upper two bytes of the EIP register are cleared, resulting in a maximum
instruction pointer size of 16 bits. When accessing an absolute offset indirectly using
the stack pointer [ESP] as the base register, the base value used is the value of the
ESP before the instruction executes.
A relative offset (rel16 or rel32) is generally specified as a label in assembly code. But
at the machine code level, it is encoded as a signed, 16- or 32-bit immediate value.
This value is added to the value in the EIP(RIP) register. In 64-bit mode the relative
offset is always a 32-bit immediate value which is sign extended to 64-bits before it
is added to the value in the RIP register for the target calculation. As with absolute
offsets, the operand-size attribute determines the size of the target operand (16, 32,
or 64 bits). In 64-bit mode the target operand will always be 64-bits because the
operand size is forced to 64-bits for near branches.
Far Calls in Real-Address or Virtual-8086 Mode. When executing a far call in real-
address or virtual-8086 mode, the processor pushes the current value of both the CS
and EIP registers on the stack for use as a return-instruction pointer. The processor
then performs a “far branch” to the code segment and offset specified with the target
operand for the called procedure. The target operand specifies an absolute far
address either directly with a pointer (ptr16:16 or ptr16:32) or indirectly with a
memory location (m16:16 or m16:32). With the pointer method, the segment and
offset of the called procedure is encoded in the instruction using a 4-byte (16-bit
operand size) or 6-byte (32-bit operand size) far address immediate. With the indi-
rect method, the target operand specifies a memory location that contains a 4-byte
(16-bit operand size) or 6-byte (32-bit operand size) far address. The operand-size
attribute determines the size of the offset (16 or 32 bits) in the far address. The far
address is loaded directly into the CS and EIP registers. If the operand-size attribute
is 16, the upper two bytes of the EIP register are cleared.
Far Calls in Protected Mode. When the processor is operating in protected mode, the
CALL instruction can be used to perform the following types of far calls:
•Far call to the same privilege level
•Far call to a different privilege level (inter-privilege level call)
•Task switch (far call to another task)
In protected mode, the processor always uses the segment selector part of the far
address to access the corresponding descriptor in the GDT or LDT. The descriptor

Vol. 2A 3-119
INSTRUCTION SET REFERENCE, A-M
CALL—Call Procedure
type (code segment, call gate, task gate, or TSS) and access rights determine the
type of call operation to be performed.
If the selected descriptor is for a code segment, a far call to a code segment at the
same privilege level is performed. (If the selected code segment is at a different priv-
ilege level and the code segment is non-conforming, a general-protection exception
is generated.) A far call to the same privilege level in protected mode is very similar
to one carried out in real-address or virtual-8086 mode. The target operand specifies
an absolute far address either directly with a pointer (ptr16:16 or ptr16:32) or indi-
rectly with a memory location (m16:16 or m16:32). The operand- size attribute
determines the size of the offset (16 or 32 bits) in the far address. The new code
segment selector and its descriptor are loaded into CS register; the offset from the
instruction is loaded into the EIP register.
A call gate (described in the next paragraph) can also be used to perform a far call to
a code segment at the same privilege level. Using this mechanism provides an extra
level of indirection and is the preferred method of making calls between 16-bit and
32-bit code segments.
When executing an inter-privilege-level far call, the code segment for the procedure
being called must be accessed through a call gate. The segment selector specified by
the target operand identifies the call gate. The target operand can specify the call
gate segment selector either directly with a pointer (ptr16:16 or ptr16:32) or indi-
rectly with a memory location (m16:16 or m16:32). The processor obtains the
segment selector for the new code segment and the new instruction pointer (offset)
from the call gate descriptor. (The offset from the target operand is ignored when a
call gate is used.)
On inter-privilege-level calls, the processor switches to the stack for the privilege
level of the called procedure. The segment selector for the new stack segment is
specified in the TSS for the currently running task. The branch to the new code
segment occurs after the stack switch. (Note that when using a call gate to perform
a far call to a segment at the same privilege level, no stack switch occurs.) On the
new stack, the processor pushes the segment selector and stack pointer for the
calling procedure’s stack, an optional set of parameters from the calling procedures
stack, and the segment selector and instruction pointer for the calling procedure’s
code segment. (A value in the call gate descriptor determines how many parameters
to copy to the new stack.) Finally, the processor branches to the address of the
procedure being called within the new code segment.
Executing a task switch with the CALL instruction is similar to executing a call
through a call gate. The target operand specifies the segment selector of the task
gate for the new task activated by the switch (the offset in the target operand is
ignored). The task gate in turn points to the TSS for the new task, which contains the
segment selectors for the task’s code and stack segments. Note that the TSS also
contains the EIP value for the next instruction that was to be executed before the
calling task was suspended. This instruction pointer value is loaded into the EIP
register to re-start the calling task.
The CALL instruction can also specify the segment selector of the TSS directly, which
eliminates the indirection of the task gate. See Chapter 7, “Task Management,” in the

3-120 Vol. 2A CALL—Call Procedure
INSTRUCTION SET REFERENCE, A-M
Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 3A, for
information on the mechanics of a task switch.
When you execute at task switch with a CALL instruction, the nested task flag (NT) is
set in the EFLAGS register and the new TSS’s previous task link field is loaded with
the old task’s TSS selector. Code is expected to suspend this nested task by executing
an IRET instruction which, because the NT flag is set, automatically uses the previous
task link to return to the calling task. (See “Task Linking” in Chapter 7 of the Intel®
64 and IA-32 Architectures Software Developer’s Manual, Volume 3A, for information
on nested tasks.) Switching tasks with the CALL instruction differs in this regard from
JMP instruction. JMP does not set the NT flag and therefore does not expect an IRET
instruction to suspend the task.
Mixing 16-Bit and 32-Bit Calls. When making far calls between 16-bit and 32-bit code
segments, use a call gate. If the far call is from a 32-bit code segment to a 16-bit
code segment, the call should be made from the first 64 KBytes of the 32-bit code
segment. This is because the operand-size attribute of the instruction is set to 16, so
only a 16-bit return address offset can be saved. Also, the call should be made using
a 16-bit call gate so that 16-bit values can be pushed on the stack. See Chapter 18,
“Mixing 16-Bit and 32-Bit Code,” in the Intel® 64 and IA-32 Architectures Software
Developer’s Manual, Volume 3A, for more information.
Far Calls in Compatibility Mode. When the processor is operating in compatibility
mode, the CALL instruction can be used to perform the following types of far calls:
•Far call to the same privilege level, remaining in compatibility mode
•Far call to the same privilege level, transitioning to 64-bit mode
•Far call to a different privilege level (inter-privilege level call), transitioning to 64-
bit mode
Note that a CALL instruction can not be used to cause a task switch in compatibility
mode since task switches are not supported in IA-32e mode.
In compatibility mode, the processor always uses the segment selector part of the far
address to access the corresponding descriptor in the GDT or LDT. The descriptor
type (code segment, call gate) and access rights determine the type of call operation
to be performed.
If the selected descriptor is for a code segment, a far call to a code segment at the
same privilege level is performed. (If the selected code segment is at a different priv-
ilege level and the code segment is non-conforming, a general-protection exception
is generated.) A far call to the same privilege level in compatibility mode is very
similar to one carried out in protected mode. The target operand specifies an abso-
lute far address either directly with a pointer (ptr16:16 or ptr16:32) or indirectly with
a memory location (m16:16 or m16:32). The operand-size attribute determines the
size of the offset (16 or 32 bits) in the far address. The new code segment selector
and its descriptor are loaded into CS register and the offset from the instruction is
loaded into the EIP register. The difference is that 64-bit mode may be entered. This
specified by the L bit in the new code segment descriptor.

Vol. 2A 3-121
INSTRUCTION SET REFERENCE, A-M
CALL—Call Procedure
Note that a 64-bit call gate (described in the next paragraph) can also be used to
perform a far call to a code segment at the same privilege level. However, using this
mechanism requires that the target code segment descriptor have the L bit set,
causing an entry to 64-bit mode.
When executing an inter-privilege-level far call, the code segment for the procedure
being called must be accessed through a 64-bit call gate. The segment selector spec-
ified by the target operand identifies the call gate. The target operand can specify the
call gate segment selector either directly with a pointer (ptr16:16 or ptr16:32) or
indirectly with a memory location (m16:16 or m16:32). The processor obtains the
segment selector for the new code segment and the new instruction pointer (offset)
from the 16-byte call gate descriptor. (The offset from the target operand is ignored
when a call gate is used.)
On inter-privilege-level calls, the processor switches to the stack for the privilege
level of the called procedure. The segment selector for the new stack segment is set
to NULL. The new stack pointer is specified in the TSS for the currently running task.
The branch to the new code segment occurs after the stack switch. (Note that when
using a call gate to perform a far call to a segment at the same privilege level, an
implicit stack switch occurs as a result of entering 64-bit mode. The SS selector is
unchanged, but stack segment accesses use a segment base of 0x0, the limit is
ignored, and the default stack size is 64-bits. The full value of RSP is used for the
offset, of which the upper 32-bits are undefined.) On the new stack, the processor
pushes the segment selector and stack pointer for the calling procedure’s stack and
the segment selector and instruction pointer for the calling procedure’s code
segment. (Parameter copy is not supported in IA-32e mode.) Finally, the processor
branches to the address of the procedure being called within the new code segment.
Near/(Far) Calls in 64-bit Mode. When the processor is operating in 64-bit mode, the
CALL instruction can be used to perform the following types of far calls:
•Far call to the same privilege level, transitioning to compatibility mode
•Far call to the same privilege level, remaining in 64-bit mode
•Far call to a different privilege level (inter-privilege level call), remaining in 64-bit
mode
Note that in this mode the CALL instruction can not be used to cause a task switch in
64-bit mode since task switches are not supported in IA-32e mode.
In 64-bit mode, the processor always uses the segment selector part of the far
address to access the corresponding descriptor in the GDT or LDT. The descriptor
type (code segment, call gate) and access rights determine the type of call operation
to be performed.
If the selected descriptor is for a code segment, a far call to a code segment at the
same privilege level is performed. (If the selected code segment is at a different priv-
ilege level and the code segment is non-conforming, a general-protection exception
is generated.) A far call to the same privilege level in 64-bit mode is very similar to
one carried out in compatibility mode. The target operand specifies an absolute far
address indirectly with a memory location (m16:16, m16:32 or m16:64). The form
of CALL with a direct specification of absolute far address is not defined in 64-bit

3-122 Vol. 2A CALL—Call Procedure
INSTRUCTION SET REFERENCE, A-M
mode. The operand-size attribute determines the size of the offset (16, 32, or 64
bits) in the far address. The new code segment selector and its descriptor are loaded
into the CS register; the offset from the instruction is loaded into the EIP register. The
new code segment may specify entry either into compatibility or 64-bit mode, based
on the L bit value.
A 64-bit call gate (described in the next paragraph) can also be used to perform a far
call to a code segment at the same privilege level. However, using this mechanism
requires that the target code segment descriptor have the L bit set.
When executing an inter-privilege-level far call, the code segment for the procedure
being called must be accessed through a 64-bit call gate. The segment selector spec-
ified by the target operand identifies the call gate. The target operand can only
specify the call gate segment selector indirectly with a memory location (m16:16,
m16:32 or m16:64). The processor obtains the segment selector for the new code
segment and the new instruction pointer (offset) from the 16-byte call gate
descriptor. (The offset from the target operand is ignored when a call gate is used.)
On inter-privilege-level calls, the processor switches to the stack for the privilege
level of the called procedure. The segment selector for the new stack segment is set
to NULL. The new stack pointer is specified in the TSS for the currently running task.
The branch to the new code segment occurs after the stack switch.
Note that when using a call gate to perform a far call to a segment at the same priv-
ilege level, an implicit stack switch occurs as a result of entering 64-bit mode. The SS
selector is unchanged, but stack segment accesses use a segment base of 0x0, the
limit is ignored, and the default stack size is 64-bits. (The full value of RSP is used for
the offset.) On the new stack, the processor pushes the segment selector and stack
pointer for the calling procedure’s stack and the segment selector and instruction
pointer for the calling procedure’s code segment. (Parameter copy is not supported in
IA-32e mode.) Finally, the processor branches to the address of the procedure being
called within the new code segment.
Operation
IF near call
THEN IF near relative call
THEN
IF OperandSize = 64
THEN
tempDEST ← SignExtend(DEST); (* DEST is rel32 *)
tempRIP ← RIP + tempDEST;
IF stack not large enough for a 8-byte return address
THEN #SS(0); FI;
Push(RIP);
RIP ← tempRIP;
FI;
IF OperandSize = 32

Vol. 2A 3-123
INSTRUCTION SET REFERENCE, A-M
CALL—Call Procedure
THEN
tempEIP ← EIP + DEST; (* DEST is rel32 *)
IF tempEIP is not within code segment limit THEN #GP(0); FI;
IF stack not large enough for a 4-byte return address
THEN #SS(0); FI;
Push(EIP);
EIP ← tempEIP;
FI;
IF OperandSize = 16
THEN
tempEIP ← (EIP + DEST) AND 0000FFFFH; (* DEST is rel16 *)
IF tempEIP is not within code segment limit THEN #GP(0); FI;
IF stack not large enough for a 2-byte return address
THEN #SS(0); FI;
Push(IP);
EIP ← tempEIP;
FI;
ELSE (* Near absolute call *)
IF OperandSize = 64
THEN
tempRIP ← DEST; (* DEST is r/m64 *)
IF stack not large enough for a 8-byte return address
THEN #SS(0); FI;
Push(RIP);
RIP ← tempRIP;
FI;
IF OperandSize = 32
THEN
tempEIP ← DEST; (* DEST is r/m32 *)
IF tempEIP is not within code segment limit THEN #GP(0); FI;
IF stack not large enough for a 4-byte return address
THEN #SS(0); FI;
Push(EIP);
EIP ← tempEIP;
FI;
IF OperandSize = 16
THEN
tempEIP ← DEST AND 0000FFFFH; (* DEST is r/m16 *)
IF tempEIP is not within code segment limit THEN #GP(0); FI;
IF stack not large enough for a 2-byte return address
THEN #SS(0); FI;
Push(IP);
EIP ← tempEIP;

3-124 Vol. 2A CALL—Call Procedure
INSTRUCTION SET REFERENCE, A-M
FI;
FI;rel/abs
FI; near
IF far call and (PE = 0 or (PE = 1 and VM = 1)) (* Real-address or virtual-8086 mode *)
THEN
IF OperandSize = 32
THEN
IF stack not large enough for a 6-byte return address
THEN #SS(0); FI;
IF DEST[31:16] is not zero THEN #GP(0); FI;
Push(CS); (* Padded with 16 high-order bits *)
Push(EIP);
CS ← DEST[47:32]; (* DEST is ptr16:32 or [m16:32] *)
EIP ← DEST[31:0]; (* DEST is ptr16:32 or [m16:32] *)
ELSE (* OperandSize = 16 *)
IF stack not large enough for a 4-byte return address
THEN #SS(0); FI;
Push(CS);
Push(IP);
CS ← DEST[31:16]; (* DEST is ptr16:16 or [m16:16] *)
EIP ← DEST[15:0]; (* DEST is ptr16:16 or [m16:16]; clear upper 16 bits *)
FI;
FI;
IF far call and (PE = 1 and VM = 0) (* Protected mode or IA-32e Mode, not virtual-8086 mode*)
THEN
IF segment selector in target operand NULL
THEN #GP(0); FI;
IF segment selector index not within descriptor table limits
THEN #GP(new code segment selector); FI;
Read type and access rights of selected segment descriptor;
IF IA32_EFER.LMA = 0
THEN
IF segment type is not a conforming or nonconforming code segment, call
gate, task gate, or TSS
THEN #GP(segment selector); FI;
ELSE
IF segment type is not a conforming or nonconforming code segment or
64-bit call gate,
THEN #GP(segment selector); FI;
FI;
Depending on type and access rights:

Vol. 2A 3-125
INSTRUCTION SET REFERENCE, A-M
CALL—Call Procedure
GO TO CONFORMING-CODE-SEGMENT;
GO TO NONCONFORMING-CODE-SEGMENT;
GO TO CALL-GATE;
GO TO TASK-GATE;
GO TO TASK-STATE-SEGMENT;
FI;
CONFORMING-CODE-SEGMENT:
IF L bit = 1 and D bit = 1 and IA32_EFER.LMA = 1
THEN GP(new code segment selector); FI;
IF DPL > CPL
THEN #GP(new code segment selector); FI;
IF segment not present
THEN #NP(new code segment selector); FI;
IF stack not large enough for return address
THEN #SS(0); FI;
tempEIP ← DEST(Offset);
IF OperandSize = 16
THEN
tempEIP ← tempEIP AND 0000FFFFH; FI; (* Clear upper 16 bits *)
IF (EFER.LMA = 0 or target mode = Compatibility mode) and (tempEIP outside new code
segment limit)
THEN #GP(0); FI;
IF tempEIP is non-canonical
THEN #GP(0); FI;
IF OperandSize = 32
THEN
Push(CS); (* Padded with 16 high-order bits *)
Push(EIP);
CS ← DEST(CodeSegmentSelector);
(* Segment descriptor information also loaded *)
CS(RPL) ← CPL;
EIP ← tempEIP;
ELSE
IF OperandSize = 16
THEN
Push(CS);
Push(IP);
CS ← DEST(CodeSegmentSelector);
(* Segment descriptor information also loaded *)
CS(RPL) ← CPL;
EIP ← tempEIP;
ELSE (* OperandSize = 64 *)

3-126 Vol. 2A CALL—Call Procedure
INSTRUCTION SET REFERENCE, A-M
Push(CS); (* Padded with 48 high-order bits *)
Push(RIP);
CS ← DEST(CodeSegmentSelector);
(* Segment descriptor information also loaded *)
CS(RPL) ← CPL;
RIP ← tempEIP;
FI;
FI;
END;
NONCONFORMING-CODE-SEGMENT:
IF L-Bit = 1 and D-BIT = 1 and IA32_EFER.LMA = 1
THEN GP(new code segment selector); FI;
IF (RPL > CPL) or (DPL ≠ CPL)
THEN #GP(new code segment selector); FI;
IF segment not present
THEN #NP(new code segment selector); FI;
IF stack not large enough for return address
THEN #SS(0); FI;
tempEIP ← DEST(Offset);
IF OperandSize = 16
THEN tempEIP ← tempEIP AND 0000FFFFH; FI; (* Clear upper 16 bits *)
IF (EFER.LMA = 0 or target mode = Compatibility mode) and (tempEIP outside new code
segment limit)
THEN #GP(0); FI;
IF tempEIP is non-canonical
THEN #GP(0); FI;
IF OperandSize = 32
THEN
Push(CS); (* Padded with 16 high-order bits *)
Push(EIP);
CS ← DEST(CodeSegmentSelector);
(* Segment descriptor information also loaded *)
CS(RPL) ← CPL;
EIP ← tempEIP;
ELSE
IF OperandSize = 16
THEN
Push(CS);
Push(IP);
CS ← DEST(CodeSegmentSelector);
(* Segment descriptor information also loaded *)
CS(RPL) ← CPL;
EIP ← tempEIP;

Vol. 2A 3-127
INSTRUCTION SET REFERENCE, A-M
CALL—Call Procedure
ELSE (* OperandSize = 64 *)
Push(CS); (* Padded with 48 high-order bits *)
Push(RIP);
CS ← DEST(CodeSegmentSelector);
(* Segment descriptor information also loaded *)
CS(RPL) ← CPL;
RIP ← tempEIP;
FI;
FI;
END;
CALL-GATE:
IF call gate (DPL < CPL) or (RPL > DPL)
THEN #GP(call-gate selector); FI;
IF call gate not present
THEN #NP(call-gate selector); FI;
IF call-gate code-segment selector is NULL
THEN #GP(0); FI;
IF call-gate code-segment selector index is outside descriptor table limits
THEN #GP(call-gate code-segment selector); FI;
Read call-gate code-segment descriptor;
IF call-gate code-segment descriptor does not indicate a code segment
or call-gate code-segment descriptor DPL > CPL
THEN #GP(call-gate code-segment selector); FI;
IF IA32_EFER.LMA = 1 AND (call-gate code-segment descriptor is
not a 64-bit code segment or call-gate code-segment descriptor has both L-bit and D-bit set)
THEN #GP(call-gate code-segment selector); FI;
IF call-gate code segment not present
THEN #NP(call-gate code-segment selector); FI;
IF call-gate code segment is non-conforming and DPL < CPL
THEN go to MORE-PRIVILEGE;
ELSE go to SAME-PRIVILEGE;
FI;
END;
MORE-PRIVILEGE:
IF current TSS is 32-bit
THEN
TSSstackAddress ← (new code-segment DPL ∗ 8) + 4;
IF (TSSstackAddress + 5) > current TSS limit
THEN #TS(current TSS selector); FI;
NewSS ← 2 bytes loaded from (TSS base + TSSstackAddress + 4);
NewESP ← 4 bytes loaded from (TSS base + TSSstackAddress);
ELSE

3-128 Vol. 2A CALL—Call Procedure
INSTRUCTION SET REFERENCE, A-M
IF current TSS is 16-bit
THEN
TSSstackAddress ← (new code-segment DPL ∗ 4) + 2
IF (TSSstackAddress + 3) > current TSS limit
THEN #TS(current TSS selector); FI;
NewSS ← 2 bytes loaded from (TSS base + TSSstackAddress + 2);
NewESP ← 2 bytes loaded from (TSS base + TSSstackAddress);
ELSE (* current TSS is 64-bit *)
TSSstackAddress ← (new code-segment DPL ∗ 8) + 4;
IF (TSSstackAddress + 7) > current TSS limit
THEN #TS(current TSS selector); FI;
NewSS ← new code-segment DPL; (* NULL selector with RPL = new CPL *)
NewRSP ← 8 bytes loaded from (current TSS base + TSSstackAddress);
FI;
FI;
IF IA32_EFER.LMA = 0 and NewSS is NULL
THEN #TS(NewSS); FI;
Read new code-segment descriptor and new stack-segment descriptor;
IF IA32_EFER.LMA = 0 and (NewSS RPL ≠ new code-segment DPL
or new stack-segment DPL ≠ new code-segment DPL or new stack segment is not a
writable data segment)
THEN #TS(NewSS); FI
IF IA32_EFER.LMA = 0 and new stack segment not present
THEN #SS(NewSS); FI;
IF CallGateSize = 32
THEN
IF new stack does not have room for parameters plus 16 bytes
THEN #SS(NewSS); FI;
IF CallGate(InstructionPointer) not within new code-segment limit
THEN #GP(0); FI;
SS ← newSS; (* Segment descriptor information also loaded *)
ESP ← newESP;
CS:EIP ← CallGate(CS:InstructionPointer);
(* Segment descriptor information also loaded *)
Push(oldSS:oldESP); (* From calling procedure *)
temp ← parameter count from call gate, masked to 5 bits;
Push(parameters from calling procedure’s stack, temp)
Push(oldCS:oldEIP); (* Return address to calling procedure *)
ELSE
IF CallGateSize = 16
THEN
IF new stack does not have room for parameters plus 8 bytes
THEN #SS(NewSS); FI;
IF (CallGate(InstructionPointer) AND FFFFH) not in new code-segment limit

Vol. 2A 3-129
INSTRUCTION SET REFERENCE, A-M
CALL—Call Procedure
THEN #GP(0); FI;
SS ← newSS; (* Segment descriptor information also loaded *)
ESP ← newESP;
CS:IP ← CallGate(CS:InstructionPointer);
(* Segment descriptor information also loaded *)
Push(oldSS:oldESP); (* From calling procedure *)
temp ← parameter count from call gate, masked to 5 bits;
Push(parameters from calling procedure’s stack, temp)
Push(oldCS:oldEIP); (* Return address to calling procedure *)
ELSE (* CallGateSize = 64 *)
IF pushing 32 bytes on the stack would use a non-canonical address
THEN #SS(NewSS); FI;
IF (CallGate(InstructionPointer) is non-canonical)
THEN #GP(0); FI;
SS ← NewSS; (* NewSS is NULL)
RSP ← NewESP;
CS:IP ← CallGate(CS:InstructionPointer);
(* Segment descriptor information also loaded *)
Push(oldSS:oldESP); (* From calling procedure *)
Push(oldCS:oldEIP); (* Return address to calling procedure *)
FI;
FI;
CPL ← CodeSegment(DPL)
CS(RPL) ← CPL
END;
SAME-PRIVILEGE:
IF CallGateSize = 32
THEN
IF stack does not have room for 8 bytes
THEN #SS(0); FI;
IF CallGate(InstructionPointer) not within code segment limit
THEN #GP(0); FI;
CS:EIP ← CallGate(CS:EIP) (* Segment descriptor information also loaded *)
Push(oldCS:oldEIP); (* Return address to calling procedure *)
ELSE
If CallGateSize = 16
THEN
IF stack does not have room for 4 bytes
THEN #SS(0); FI;
IF CallGate(InstructionPointer) not within code segment limit
THEN #GP(0); FI;
CS:IP ← CallGate(CS:instruction pointer);

3-130 Vol. 2A CALL—Call Procedure
INSTRUCTION SET REFERENCE, A-M
(* Segment descriptor information also loaded *)
Push(oldCS:oldIP); (* Return address to calling procedure *)
ELSE (* CallGateSize = 64)
IF pushing 16 bytes on the stack touches non-canonical addresses
THEN #SS(0); FI;
IF RIP non-canonical
THEN #GP(0); FI;
CS:IP ← CallGate(CS:instruction pointer);
(* Segment descriptor information also loaded *)
Push(oldCS:oldIP); (* Return address to calling procedure *)
FI;
FI;
CS(RPL) ← CPL
END;
TASK-GATE:
IF task gate DPL < CPL or RPL
THEN #GP(task gate selector); FI;
IF task gate not present
THEN #NP(task gate selector); FI;
Read the TSS segment selector in the task-gate descriptor;
IF TSS segment selector local/global bit is set to local
or index not within GDT limits
THEN #GP(TSS selector); FI;
Access TSS descriptor in GDT;
IF TSS descriptor specifies that the TSS is busy (low-order 5 bits set to 00001)
THEN #GP(TSS selector); FI;
IF TSS not present
THEN #NP(TSS selector); FI;
SWITCH-TASKS (with nesting) to TSS;
IF EIP not within code segment limit
THEN #GP(0); FI;
END;
TASK-STATE-SEGMENT:
IF TSS DPL < CPL or RPL
or TSS descriptor indicates TSS not available
THEN #GP(TSS selector); FI;
IF TSS is not present
THEN #NP(TSS selector); FI;
SWITCH-TASKS (with nesting) to TSS;
IF EIP not within code segment limit
THEN #GP(0); FI;

Vol. 2A 3-131
INSTRUCTION SET REFERENCE, A-M
CALL—Call Procedure
END;
Flags Affected
All flags are affected if a task switch occurs; no flags are affected if a task switch does
not occur.
Protected Mode Exceptions
#GP(0) If the target offset in destination operand is beyond the new
code segment limit.
If the segment selector in the destination operand is NULL.
If the code segment selector in the gate is NULL.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register is used to access memory and it
contains a NULL segment selector.
#GP(selector) If a code segment or gate or TSS selector index is outside
descriptor table limits.
If the segment descriptor pointed to by the segment selector in
the destination operand is not for a conforming-code segment,
nonconforming-code segment, call gate, task gate, or task state
segment.
If the DPL for a nonconforming-code segment is not equal to the
CPL or the RPL for the segment’s segment selector is greater
than the CPL.
If the DPL for a conforming-code segment is greater than the
CPL.
If the DPL from a call-gate, task-gate, or TSS segment
descriptor is less than the CPL or than the RPL of the call-gate,
task-gate, or TSS’s segment selector.
If the segment descriptor for a segment selector from a call gate
does not indicate it is a code segment.
If the segment selector from a call gate is beyond the descriptor
table limits.
If the DPL for a code-segment obtained from a call gate is
greater than the CPL.
If the segment selector for a TSS has its local/global bit set for
local.
If a TSS segment descriptor specifies that the TSS is busy or not
available.

3-132 Vol. 2A CALL—Call Procedure
INSTRUCTION SET REFERENCE, A-M
#SS(0) If pushing the return address, parameters, or stack segment
pointer onto the stack exceeds the bounds of the stack segment,
when no stack switch occurs.
If a memory operand effective address is outside the SS
segment limit.
#SS(selector) If pushing the return address, parameters, or stack segment
pointer onto the stack exceeds the bounds of the stack segment,
when a stack switch occurs.
If the SS register is being loaded as part of a stack switch and
the segment pointed to is marked not present.
If stack segment does not have room for the return address,
parameters, or stack segment pointer, when stack switch
occurs.
#NP(selector) If a code segment, data segment, stack segment, call gate, task
gate, or TSS is not present.
#TS(selector) If the new stack segment selector and ESP are beyond the end
of the TSS.
If the new stack segment selector is NULL.
If the RPL of the new stack segment selector in the TSS is not
equal to the DPL of the code segment being accessed.
If DPL of the stack segment descriptor for the new stack
segment is not equal to the DPL of the code segment descriptor.
If the new stack segment is not a writable data segment.
If segment-selector index for stack segment is outside
descriptor table limits.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the target offset is beyond the code segment limit.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the target offset is beyond the code segment limit.
#PF(fault-code) If a page fault occurs.

Vol. 2A 3-133
INSTRUCTION SET REFERENCE, A-M
CALL—Call Procedure
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
#GP(selector) If a memory address accessed by the selector is in non-canon-
ical space.
#GP(0) If the target offset in the destination operand is non-canonical.
64-Bit Mode Exceptions
#GP(0) If a memory address is non-canonical.
If target offset in destination operand is non-canonical.
If the segment selector in the destination operand is NULL.
If the code segment selector in the 64-bit gate is NULL.
#GP(selector) If code segment or 64-bit call gate is outside descriptor table
limits.
If code segment or 64-bit call gate overlaps non-canonical
space.
If the segment descriptor pointed to by the segment selector in
the destination operand is not for a conforming-code segment,
nonconforming-code segment, or 64-bit call gate.
If the segment descriptor pointed to by the segment selector in
the destination operand is a code segment and has both the D-
bit and the L- bit set.
If the DPL for a nonconforming-code segment is not equal to the
CPL, or the RPL for the segment’s segment selector is greater
than the CPL.
If the DPL for a conforming-code segment is greater than the
CPL.
If the DPL from a 64-bit call-gate is less than the CPL or than the
RPL of the 64-bit call-gate.
If the upper type field of a 64-bit call gate is not 0x0.
If the segment selector from a 64-bit call gate is beyond the
descriptor table limits.
If the DPL for a code-segment obtained from a 64-bit call gate is
greater than the CPL.
If the code segment descriptor pointed to by the selector in the
64-bit gate doesn't have the L-bit set and the D-bit clear.
If the segment descriptor for a segment selector from the 64-bit
call gate does not indicate it is a code segment.

3-134 Vol. 2A CALL—Call Procedure
INSTRUCTION SET REFERENCE, A-M
#SS(0) If pushing the return offset or CS selector onto the stack
exceeds the bounds of the stack segment when no stack switch
occurs.
If a memory operand effective address is outside the SS
segment limit.
If the stack address is in a non-canonical form.
#SS(selector) If pushing the old values of SS selector, stack pointer, EFLAGS,
CS selector, offset, or error code onto the stack violates the
canonical boundary when a stack switch occurs.
#NP(selector) If a code segment or 64-bit call gate is not present.
#TS(selector) If the load of the new RSP exceeds the limit of the TSS.
#UD (64-bit mode only) If a far call is direct to an absolute address in
memory.
If the LOCK prefix is used.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
Vol. 2A 3-135
INSTRUCTION SET REFERENCE, A-M
CBW/CWDE/CDQE—Convert Byte to Word/Convert Word to Doubleword/Convert Double-
word to Quadword
CBW/CWDE/CDQE—Convert Byte to Word/Convert Word to
Doubleword/Convert Doubleword to Quadword
Instruction Operand Encoding
Description
Double the size of the source operand by means of sign extension. The CBW (convert
byte to word) instruction copies the sign (bit 7) in the source operand into every bit
in the AH register. The CWDE (convert word to doubleword) instruction copies the
sign (bit 15) of the word in the AX register into the high 16 bits of the EAX register.
CBW and CWDE reference the same opcode. The CBW instruction is intended for use
when the operand-size attribute is 16; CWDE is intended for use when the operand-
size attribute is 32. Some assemblers may force the operand size. Others may treat
these two mnemonics as synonyms (CBW/CWDE) and use the setting of the
operand-size attribute to determine the size of values to be converted.
In 64-bit mode, the default operation size is the size of the destination register. Use
of the REX.W prefix promotes this instruction (CDQE when promoted) to operate on
64-bit operands. In which case, CDQE copies the sign (bit 31) of the doubleword in
the EAX register into the high 32 bits of RAX.
Operation
IF OperandSize = 16 (* Instruction = CBW *)
THEN
AX ← SignExtend(AL);
ELSE IF (OperandSize = 32, Instruction = CWDE)
EAX ← SignExtend(AX); FI;
ELSE (* 64-Bit Mode, OperandSize = 64, Instruction = CDQE*)
RAX ← SignExtend(EAX);
FI;
Flags Affected
None.
Opcode Instruction Op/
En
64-bit
Mode
Compat/
Leg Mode
Description
98 CBW A Valid Valid AX ← sign-extend of AL.
98 CWDE A Valid Valid EAX ← sign-extend of AX.
REX.W + 98 CDQE A Valid N.E. RAX ← sign-extend of EAX.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA

3-136 Vol. 2A CBW/CWDE/CDQE—Convert Byte to Word/Convert Word to Doubleword/Convert Double-
word to Quadword
INSTRUCTION SET REFERENCE, A-M
Exceptions (All Operating Modes)
#UD If the LOCK prefix is used.

Vol. 2A 3-137
INSTRUCTION SET REFERENCE, A-M
CLC—Clear Carry Flag
CLC—Clear Carry Flag
Instruction Operand Encoding
Description
Clears the CF flag in the EFLAGS register. Operation is the same in all non-64-bit
modes and 64-bit mode.
Operation
CF ← 0;
Flags Affected
The CF flag is set to 0. The OF, ZF, SF, AF, and PF flags are unaffected.
Exceptions (All Operating Modes)
#UD If the LOCK prefix is used.
Opcode Instruction Op/
En
64-bit
Mode
Compat/
Leg Mode
Description
F8 CLC A Valid Valid Clear CF flag.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA

3-138 Vol. 2A CLD—Clear Direction Flag
INSTRUCTION SET REFERENCE, A-M
CLD—Clear Direction Flag
Instruction Operand Encoding
Description
Clears the DF flag in the EFLAGS register. When the DF flag is set to 0, string opera-
tions increment the index registers (ESI and/or EDI). Operation is the same in all
non-64-bit modes and 64-bit mode.
Operation
DF ← 0;
Flags Affected
The DF flag is set to 0. The CF, OF, ZF, SF, AF, and PF flags are unaffected.
Exceptions (All Operating Modes)
#UD If the LOCK prefix is used.
Opcode Instruction Op/
En
64-bit
Mode
Compat/
Leg Mode
Description
FC CLD A Valid Valid Clear DF flag.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA

Vol. 2A 3-139
INSTRUCTION SET REFERENCE, A-M
CLFLUSH—Flush Cache Line
CLFLUSH—Flush Cache Line
Instruction Operand Encoding
Description
Invalidates the cache line that contains the linear address specified with the source
operand from all levels of the processor cache hierarchy (data and instruction). The
invalidation is broadcast throughout the cache coherence domain. If, at any level of
the cache hierarchy, the line is inconsistent with memory (dirty) it is written to
memory before invalidation. The source operand is a byte memory location.
The availability of CLFLUSH is indicated by the presence of the CPUID feature flag
CLFSH (bit 19 of the EDX register, see “CPUID—CPU Identification” in this chapter).
The aligned cache line size affected is also indicated with the CPUID instruction (bits
8 through 15 of the EBX register when the initial value in the EAX register is 1).
The memory attribute of the page containing the affected line has no effect on the
behavior of this instruction. It should be noted that processors are free to specula-
tively fetch and cache data from system memory regions assigned a memory-type
allowing for speculative reads (such as, the WB, WC, and WT memory types).
PREFETCHh instructions can be used to provide the processor with hints for this spec-
ulative behavior. Because this speculative fetching can occur at any time and is not
tied to instruction execution, the CLFLUSH instruction is not ordered with respect to
PREFETCHh instructions or any of the speculative fetching mechanisms (that is, data
can be speculatively loaded into a cache line just before, during, or after the execu-
tion of a CLFLUSH instruction that references the cache line).
CLFLUSH is only ordered by the MFENCE instruction. It is not guaranteed to be
ordered by any other fencing or serializing instructions or by another CLFLUSH
instruction. For example, software can use an MFENCE instruction to ensure that
previous stores are included in the write-back.
The CLFLUSH instruction can be used at all privilege levels and is subject to all
permission checking and faults associated with a byte load (and in addition, a
CLFLUSH instruction is allowed to flush a linear address in an execute-only segment).
Like a load, the CLFLUSH instruction sets the A bit but not the D bit in the page
tables.
The CLFLUSH instruction was introduced with the SSE2 extensions; however,
because it has its own CPUID feature flag, it can be implemented in IA-32 processors
Opcode Instruction Op/
En
64-bit
Mode
Compat/
Leg Mode
Description
0F AE /7 CLFLUSH m8 A Valid Valid Flushes cache line
containing m8.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (w) NA NA NA

3-140 Vol. 2A CLFLUSH—Flush Cache Line
INSTRUCTION SET REFERENCE, A-M
that do not include the SSE2 extensions. Also, detecting the presence of the SSE2
extensions with the CPUID instruction does not guarantee that the CLFLUSH instruc-
tion is implemented in the processor.
CLFLUSH operation is the same in non-64-bit modes and 64-bit mode.
Operation
Flush_Cache_Line(SRC);
Intel C/C++ Compiler Intrinsic Equivalents
CLFLUSH void _mm_clflush(void const *p)
Protected Mode Exceptions
#GP(0) For an illegal memory operand effective address in the CS, DS,
ES, FS or GS segments.
#SS(0) For an illegal address in the SS segment.
#PF(fault-code) For a page fault.
#UD If CPUID.01H:EDX.CLFSH[bit 19] = 0.
If the LOCK prefix is used.
Real-Address Mode Exceptions
GP If any part of the operand lies outside the effective address
space from 0 to FFFFH.
#UD If CPUID.01H:EDX.CLFSH[bit 19] = 0.
If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
Same exceptions as in real address mode.
#PF(fault-code) For a page fault.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#PF(fault-code) For a page fault.
#UD If CPUID.01H:EDX.CLFSH[bit 19] = 0.
If the LOCK prefix is used.
Vol. 2A 3-141
INSTRUCTION SET REFERENCE, A-M
CLI — Clear Interrupt Flag
CLI — Clear Interrupt Flag
Instruction Operand Encoding
Description
If protected-mode virtual interrupts are not enabled, CLI clears the IF flag in the
EFLAGS register. No other flags are affected. Clearing the IF flag causes the
processor to ignore maskable external interrupts. The IF flag and the CLI and STI
instruction have no affect on the generation of exceptions and NMI interrupts.
When protected-mode virtual interrupts are enabled, CPL is 3, and IOPL is less than
3; CLI clears the VIF flag in the EFLAGS register, leaving IF unaffected. Table 3-6 indi-
cates the action of the CLI instruction depending on the processor operating mode
and the CPL/IOPL of the running program or procedure.
CLI operation is the same in non-64-bit modes and 64-bit mode.
Operation
IF PE = 0
Opcode Instruction Op/
En
64-bit
Mode
Compat/
Leg Mode
Description
FA CLI A Valid Valid Clear interrupt flag;
interrupts disabled when
interrupt flag cleared.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA
Table 3-6. Decision Table for CLI Results
PE VM IOPL CPL PVI VIP VME CLI Result
0XXXXXXIF = 0
10
≥ CPL X X X X IF = 0
10
< CPL 3 1 X X VIF = 0
10
< CPL < 3X X XGP Fault
10
< CPL X 0 X X GP Fault
113XXXXIF = 0
11
< 3X X X 1VIF = 0
11
< 3X X X 0GP Fault
NOTES:
* X = This setting has no impact.

3-142 Vol. 2A CLI — Clear Interrupt Flag
INSTRUCTION SET REFERENCE, A-M
THEN
IF ← 0; (* Reset Interrupt Flag *)
ELSE
IF VM = 0;
THEN
IF IOPL ≥ CPL
THEN
IF ← 0; (* Reset Interrupt Flag *)
ELSE
IF ((IOPL < CPL) and (CPL = 3) and (PVI = 1))
THEN
VIF ← 0; (* Reset Virtual Interrupt Flag *)
ELSE
#GP(0);
FI;
FI;
ELSE (* VM = 1 *)
IF IOPL = 3
THEN
IF ← 0; (* Reset Interrupt Flag *)
ELSE
IF (IOPL < 3) AND (VME = 1)
THEN
VIF ← 0; (* Reset Virtual Interrupt Flag *)
ELSE
#GP(0);
FI;
FI;
FI;
FI;
Flags Affected
If protected-mode virtual interrupts are not enabled, IF is set to 0 if the CPL is equal
to or less than the IOPL; otherwise, it is not affected. The other flags in the EFLAGS
register are unaffected.
When protected-mode virtual interrupts are enabled, CPL is 3, and IOPL is less than
3; CLI clears the VIF flag in the EFLAGS register, leaving IF unaffected.
Protected Mode Exceptions
#GP(0) If the CPL is greater (has less privilege) than the IOPL of the
current program or procedure.
#UD If the LOCK prefix is used.

Vol. 2A 3-143
INSTRUCTION SET REFERENCE, A-M
CLI — Clear Interrupt Flag
Real-Address Mode Exceptions
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If the CPL is greater (has less privilege) than the IOPL of the
current program or procedure.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#GP(0) If the CPL is greater (has less privilege) than the IOPL of the
current program or procedure.
#UD If the LOCK prefix is used.

3-144 Vol. 2A CLTS—Clear Task-Switched Flag in CR0
INSTRUCTION SET REFERENCE, A-M
CLTS—Clear Task-Switched Flag in CR0
Instruction Operand Encoding
Description
Clears the task-switched (TS) flag in the CR0 register. This instruction is intended for
use in operating-system procedures. It is a privileged instruction that can only be
executed at a CPL of 0. It is allowed to be executed in real-address mode to allow
initialization for protected mode.
The processor sets the TS flag every time a task switch occurs. The flag is used to
synchronize the saving of FPU context in multitasking applications. See the descrip-
tion of the TS flag in the section titled “Control Registers” in Chapter 2 of the Intel®
64 and IA-32 Architectures Software Developer’s Manual, Volume 3A, for more infor-
mation about this flag.
CLTS operation is the same in non-64-bit modes and 64-bit mode.
See Chapter 22, “VMX Non-Root Operation,” of the Intel® 64 and IA-32 Architectures
Software Developer’s Manual, Volume 3B, for more information about the behavior
of this instruction in VMX non-root operation.
Operation
CR0.TS[bit 3] ← 0;
Flags Affected
The TS flag in CR0 register is cleared.
Protected Mode Exceptions
#GP(0) If the current privilege level is not 0.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#UD If the LOCK prefix is used.
Opcode Instruction Op/
En
64-bit
Mode
Compat/
Leg Mode
Description
0F 06 CLTS A Valid Valid Clears TS flag in CR0.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA

Vol. 2A 3-145
INSTRUCTION SET REFERENCE, A-M
CLTS—Clear Task-Switched Flag in CR0
Virtual-8086 Mode Exceptions
#GP(0) CLTS is not recognized in virtual-8086 mode.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#GP(0) If the CPL is greater than 0.
#UD If the LOCK prefix is used.

3-146 Vol. 2A CMC—Complement Carry Flag
INSTRUCTION SET REFERENCE, A-M
CMC—Complement Carry Flag
Instruction Operand Encoding
Description
Complements the CF flag in the EFLAGS register. CMC operation is the same in non-
64-bit modes and 64-bit mode.
Operation
EFLAGS.CF[bit 0]← NOT EFLAGS.CF[bit 0];
Flags Affected
The CF flag contains the complement of its original value. The OF, ZF, SF, AF, and PF
flags are unaffected.
Exceptions (All Operating Modes)
#UD If the LOCK prefix is used.
Opcode Instruction Op/
En
64-bit
Mode
Compat/
Leg Mode
Description
F5 CMC A Valid Valid Complement CF flag.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA

Vol. 2A 3-147
INSTRUCTION SET REFERENCE, A-M
CMOVcc—Conditional Move
CMOVcc—Conditional Move
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F 47 /r CMOVA r16, r/m16 A Valid Valid Move if above (CF=0 and
ZF=0).
0F 47 /r CMOVA r32, r/m32 A Valid Valid Move if above (CF=0 and
ZF=0).
REX.W + 0F 47
/r
CMOVA r64, r/m64 A Valid N.E. Move if above (CF=0 and
ZF=0).
0F 43 /r CMOVAE r16, r/m16 A Valid Valid Move if above or equal
(CF=0).
0F 43 /r CMOVAE r32, r/m32 A Valid Valid Move if above or equal
(CF=0).
REX.W + 0F 43
/r
CMOVAE r64, r/m64 A Valid N.E. Move if above or equal
(CF=0).
0F 42 /r CMOVB r16, r/m16 A Valid Valid Move if below (CF=1).
0F 42 /r CMOVB r32, r/m32 A Valid Valid Move if below (CF=1).
REX.W + 0F 42
/r
CMOVB r64, r/m64 A Valid N.E. Move if below (CF=1).
0F 46 /r CMOVBE r16, r/m16 A Valid Valid Move if below or equal
(CF=1 or ZF=1).
0F 46 /r CMOVBE r32, r/m32 A Valid Valid Move if below or equal
(CF=1 or ZF=1).
REX.W + 0F 46
/r
CMOVBE r64, r/m64 AValid N.E. Move if below or equal
(CF=1 or ZF=1).
0F 42 /r CMOVC r16, r/m16 A Valid Valid Move if carry (CF=1).
0F 42 /r CMOVC r32, r/m32 A Valid Valid Move if carry (CF=1).
REX.W + 0F 42
/r
CMOVC r64, r/m64 A Valid N.E. Move if carry (CF=1).
0F 44 /r CMOVE r16, r/m16 A Valid Valid Move if equal (ZF=1).
0F 44 /r CMOVE r32, r/m32 A Valid Valid Move if equal (ZF=1).
REX.W + 0F 44
/r
CMOVE r64, r/m64 AValid N.E. Move if equal (ZF=1).
0F 4F /r CMOVG r16, r/m16 A Valid Valid Move if greater (ZF=0 and
SF=OF).
0F 4F /r CMOVG r32, r/m32 A Valid Valid Move if greater (ZF=0 and
SF=OF).
REX.W + 0F 4F
/r
CMOVG r64, r/m64 A V/N.E. NA Move if greater (ZF=0 and
SF=OF).

3-148 Vol. 2A CMOVcc—Conditional Move
INSTRUCTION SET REFERENCE, A-M
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F 4D /r CMOVGE r16, r/m16 A Valid Valid Move if greater or equal
(SF=OF).
0F 4D /r CMOVGE r32, r/m32 A Valid Valid Move if greater or equal
(SF=OF).
REX.W + 0F 4D
/r
CMOVGE r64, r/m64 A Valid N.E. Move if greater or equal
(SF=OF).
0F 4C /r CMOVL r16, r/m16 A Valid Valid Move if less (SF≠ OF).
0F 4C /r CMOVL r32, r/m32 A Valid Valid Move if less (SF≠ OF).
REX.W + 0F 4C
/r
CMOVL r64, r/m64 A Valid N.E. Move if less (SF≠ OF).
0F 4E /r CMOVLE r16, r/m16 A Valid Valid Move if less or equal (ZF=1
or SF≠ OF).
0F 4E /r CMOVLE r32, r/m32 A Valid Valid Move if less or equal (ZF=1
or SF≠ OF).
REX.W + 0F 4E
/r
CMOVLE r64, r/m64 A Valid N.E. Move if less or equal (ZF=1
or SF≠ OF).
0F 46 /r CMOVNA r16, r/m16 A Valid Valid Move if not above (CF=1 or
ZF=1).
0F 46 /r CMOVNA r32, r/m32 A Valid Valid Move if not above (CF=1 or
ZF=1).
REX.W + 0F 46
/r
CMOVNA r64, r/m64 A Valid N.E. Move if not above (CF=1 or
ZF=1).
0F 42 /r CMOVNAE r16,
r/m16
A Valid Valid Move if not above or equal
(CF=1).
0F 42 /r CMOVNAE r32,
r/m32
A Valid Valid Move if not above or equal
(CF=1).
REX.W + 0F 42
/r
CMOVNAE r64,
r/m64
A Valid N.E. Move if not above or equal
(CF=1).
0F 43 /r CMOVNB r16, r/m16 A Valid Valid Move if not below (CF=0).
0F 43 /r CMOVNB r32, r/m32 A Valid Valid Move if not below (CF=0).
REX.W + 0F 43
/r
CMOVNB r64, r/m64 A Valid N.E. Move if not below (CF=0).
0F 47 /r CMOVNBE r16,
r/m16
A Valid Valid Move if not below or equal
(CF=0 and ZF=0).
0F 47 /r CMOVNBE r32,
r/m32
A Valid Valid Move if not below or equal
(CF=0 and ZF=0).

Vol. 2A 3-149
INSTRUCTION SET REFERENCE, A-M
CMOVcc—Conditional Move
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
REX.W + 0F 47
/r
CMOVNBE r64,
r/m64
A Valid N.E. Move if not below or equal
(CF=0 and ZF=0).
0F 43 /r CMOVNC r16, r/m16 A Valid Valid Move if not carry (CF=0).
0F 43 /r CMOVNC r32, r/m32 A Valid Valid Move if not carry (CF=0).
REX.W + 0F 43
/r
CMOVNC r64, r/m64 A Valid N.E. Move if not carry (CF=0).
0F 45 /r CMOVNE r16, r/m16 A Valid Valid Move if not equal (ZF=0).
0F 45 /r CMOVNE r32, r/m32 A Valid Valid Move if not equal (ZF=0).
REX.W + 0F 45
/r
CMOVNE r64, r/m64 A Valid N.E. Move if not equal (ZF=0).
0F 4E /r CMOVNG r16, r/m16 A Valid Valid Move if not greater (ZF=1
or SF≠ OF).
0F 4E /r CMOVNG r32, r/m32 A Valid Valid Move if not greater (ZF=1
or SF≠ OF).
REX.W + 0F 4E
/r
CMOVNG r64, r/m64 A Valid N.E. Move if not greater (ZF=1
or SF≠ OF).
0F 4C /r CMOVNGE r16,
r/m16
A Valid Valid Move if not greater or equal
(SF≠ OF).
0F 4C /r CMOVNGE r32,
r/m32
A Valid Valid Move if not greater or equal
(SF≠ OF).
REX.W + 0F 4C
/r
CMOVNGE r64,
r/m64
A Valid N.E. Move if not greater or equal
(SF≠ OF).
0F 4D /r CMOVNL r16, r/m16 A Valid Valid Move if not less (SF=OF).
0F 4D /r CMOVNL r32, r/m32 A Valid Valid Move if not less (SF=OF).
REX.W + 0F 4D
/r
CMOVNL r64, r/m64 AValid N.E. Move if not less (SF=OF).
0F 4F /r CMOVNLE r16,
r/m16
A Valid Valid Move if not less or equal
(ZF=0 and SF=OF).
0F 4F /r CMOVNLE r32,
r/m32
A Valid Valid Move if not less or equal
(ZF=0 and SF=OF).
REX.W + 0F 4F
/r
CMOVNLE r64,
r/m64
A Valid N.E. Move if not less or equal
(ZF=0 and SF=OF).
0F 41 /r CMOVNO r16, r/m16 A Valid Valid Move if not overflow
(OF=0).
0F 41 /r CMOVNO r32, r/m32 A Valid Valid Move if not overflow
(OF=0).

3-150 Vol. 2A CMOVcc—Conditional Move
INSTRUCTION SET REFERENCE, A-M
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
REX.W + 0F 41
/r
CMOVNO r64, r/m64 A Valid N.E. Move if not overflow
(OF=0).
0F 4B /r CMOVNP r16, r/m16 A Valid Valid Move if not parity (PF=0).
0F 4B /r CMOVNP r32, r/m32 A Valid Valid Move if not parity (PF=0).
REX.W + 0F 4B
/r
CMOVNP r64, r/m64 A Valid N.E. Move if not parity (PF=0).
0F 49 /r CMOVNS r16, r/m16 A Valid Valid Move if not sign (SF=0).
0F 49 /r CMOVNS r32, r/m32 A Valid Valid Move if not sign (SF=0).
REX.W + 0F 49
/r
CMOVNS r64, r/m64 A Valid N.E. Move if not sign (SF=0).
0F 45 /r CMOVNZ r16, r/m16 A Valid Valid Move if not zero (ZF=0).
0F 45 /r CMOVNZ r32, r/m32 A Valid Valid Move if not zero (ZF=0).
REX.W + 0F 45
/r
CMOVNZ r64, r/m64 A Valid N.E. Move if not zero (ZF=0).
0F 40 /r CMOVO r16, r/m16 A Valid Valid Move if overflow (OF=1).
0F 40 /r CMOVO r32, r/m32 A Valid Valid Move if overflow (OF=1).
REX.W + 0F 40
/r
CMOVO r64, r/m64 A Valid N.E. Move if overflow (OF=1).
0F 4A /r CMOVP r16, r/m16 AValid Valid Move if parity (PF=1).
0F 4A /r CMOVP r32, r/m32 AValid Valid Move if parity (PF=1).
REX.W + 0F 4A
/r
CMOVP r64, r/m64 A Valid N.E. Move if parity (PF=1).
0F 4A /r CMOVPE r16, r/m16 A Valid Valid Move if parity even (PF=1).
0F 4A /r CMOVPE r32, r/m32 A Valid Valid Move if parity even (PF=1).
REX.W + 0F 4A
/r
CMOVPE r64, r/m64 A Valid N.E. Move if parity even (PF=1).
0F 4B /r CMOVPO r16, r/m16 A Valid Valid Move if parity odd (PF=0).
0F 4B /r CMOVPO r32, r/m32 A Valid Valid Move if parity odd (PF=0).
REX.W + 0F 4B
/r
CMOVPO r64, r/m64 A Valid N.E. Move if parity odd (PF=0).
0F 48 /r CMOVS r16, r/m16 AValid Valid Move if sign (SF=1).
0F 48 /r CMOVS r32, r/m32 AValid Valid Move if sign (SF=1).
REX.W + 0F 48
/r
CMOVS r64, r/m64 A Valid N.E. Move if sign (SF=1).
0F 44 /r CMOVZ r16, r/m16 AValid Valid Move if zero (ZF=1).

Vol. 2A 3-151
INSTRUCTION SET REFERENCE, A-M
CMOVcc—Conditional Move
Instruction Operand Encoding
Description
The CMOVcc instructions check the state of one or more of the status flags in the
EFLAGS register (CF, OF, PF, SF, and ZF) and perform a move operation if the flags are
in a specified state (or condition). A condition code (cc) is associated with each
instruction to indicate the condition being tested for. If the condition is not satisfied,
a move is not performed and execution continues with the instruction following the
CMOVcc instruction.
These instructions can move 16-bit, 32-bit or 64-bit values from memory to a
general-purpose register or from one general-purpose register to another. Condi-
tional moves of 8-bit register operands are not supported.
The condition for each CMOVcc mnemonic is given in the description column of the
above table. The terms “less” and “greater” are used for comparisons of signed inte-
gers and the terms “above” and “below” are used for unsigned integers.
Because a particular state of the status flags can sometimes be interpreted in two
ways, two mnemonics are defined for some opcodes. For example, the CMOVA
(conditional move if above) instruction and the CMOVNBE (conditional move if not
below or equal) instruction are alternate mnemonics for the opcode 0F 47H.
The CMOVcc instructions were introduced in P6 family processors; however, these
instructions may not be supported by all IA-32 processors. Software can determine if
the CMOVcc instructions are supported by checking the processor’s feature informa-
tion with the CPUID instruction (see “CPUID—CPU Identification” in this chapter).
In 64-bit mode, the instruction’s default operation size is 32 bits. Use of the REX.R
prefix permits access to additional registers (R8-R15). Use of the REX.W prefix
promotes operation to 64 bits. See the summary chart at the beginning of this
section for encoding data and limits.
Operation
temp ← SRC
IF condition TRUE
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F 44 /r CMOVZ r32, r/m32 A Valid Valid Move if zero (ZF=1).
REX.W + 0F 44
/r
CMOVZ r64, r/m64 A Valid N.E. Move if zero (ZF=1).
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA

3-152 Vol. 2A CMOVcc—Conditional Move
INSTRUCTION SET REFERENCE, A-M
THEN
DEST ← temp;
FI;
ELSE
IF (OperandSize = 32 and IA-32e mode active)
THEN
DEST[63:32] ← 0;
FI;
FI;
Flags Affected
None.
Protected Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.

Vol. 2A 3-153
INSTRUCTION SET REFERENCE, A-M
CMOVcc—Conditional Move
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.

3-154 Vol. 2A CMP—Compare Two Operands
INSTRUCTION SET REFERENCE, A-M
CMP—Compare Two Operands
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
3C ib CMP AL, imm8 DValid Valid Compare imm8 with AL.
3D iw CMP AX, imm16 DValid Valid Compare imm16 with AX.
3D id CMP EAX, imm32 DValid Valid Compare imm32 with EAX.
REX.W + 3D id CMP RAX, imm32 D Valid N.E. Compare imm32 sign-
extended to 64-bits with
RAX.
80 /7 ib CMP r/m8, imm8 CValid Valid Compare imm8 with r/m8.
REX + 80 /7 ib CMP r/m8*, imm8 C Valid N.E. Compare imm8 with r/m8.
81 /7 iw CMP r/m16,
imm16
CValid Valid Compare imm16 with
r/m16.
81 /7 id CMP r/m32,
imm32
CValid Valid Compare imm32 with
r/m32.
REX.W + 81 /7
id
CMP r/m64,
imm32
C Valid N.E. Compare imm32 sign-
extended to 64-bits with
r/m64.
83 /7 ib CMP r/m16, imm8 CValid Valid Compare imm8 with r/m16.
83 /7 ib CMP r/m32, imm8 CValid Valid Compare imm8 with r/m32.
REX.W + 83 /7
ib
CMP r/m64, imm8 C Valid N.E. Compare imm8 with r/m64.
38 /rCMP r/m8, r8 BValid Valid Compare r8 with r/m8.
REX + 38 /rCMP r/m8*, r8*B Valid N.E. Compare r8 with r/m8.
39 /rCMP r/m16, r16 BValid Valid Compare r16 with r/m16.
39 /rCMP r/m32, r32 BValid Valid Compare r32 with r/m32.
REX.W + 39 /rCMP r/m64,r64 B Valid N.E. Compare r64 with r/m64.
3A /rCMP r8, r/m8 AValid Valid Compare r/m8 with r8.
REX + 3A /rCMP r8*, r/m8*A Valid N.E. Compare r/m8 with r8.
3B /rCMP r16, r/m16 AValid Valid Compare r/m16 with r16.
3B /rCMP r32, r/m32 AValid Valid Compare r/m32 with r32.
REX.W + 3B /rCMP r64, r/m64 A Valid N.E. Compare r/m64 with r64.
NOTES:
* In 64-bit mode, r/m8 can not be encoded to access the following byte registers if a REX prefix is
used: AH, BH, CH, DH.

Vol. 2A 3-155
INSTRUCTION SET REFERENCE, A-M
CMP—Compare Two Operands
Instruction Operand Encoding
Description
Compares the first source operand with the second source operand and sets the
status flags in the EFLAGS register according to the results. The comparison is
performed by subtracting the second operand from the first operand and then setting
the status flags in the same manner as the SUB instruction. When an immediate
value is used as an operand, it is sign-extended to the length of the first operand.
The condition codes used by the Jcc, CMOVcc, and SETcc instructions are based on
the results of a CMP instruction. Appendix B, “EFLAGS Condition Codes,” in the
Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 1, shows
the relationship of the status flags and the condition codes.
In 64-bit mode, the instruction’s default operation size is 32 bits. Use of the REX.R
prefix permits access to additional registers (R8-R15). Use of the REX.W prefix
promotes operation to 64 bits. See the summary chart at the beginning of this
section for encoding data and limits.
Operation
temp ← SRC1 − SignExtend(SRC2);
ModifyStatusFlags; (* Modify status flags in the same manner as the SUB instruction*)
Flags Affected
The CF, OF, SF, ZF, AF, and PF flags are set according to the result.
Protected Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:r/m (r, w) ModRM:reg (w) NA NA
C ModRM:r/m (r, w) imm8 NA NA
D AL/AX/EAX/RAX imm8 NA NA

3-156 Vol. 2A CMP—Compare Two Operands
INSTRUCTION SET REFERENCE, A-M
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.

Vol. 2A 3-157
INSTRUCTION SET REFERENCE, A-M
CMPPD—Compare Packed Double-Precision Floating-Point Values
CMPPD—Compare Packed Double-Precision Floating-Point Values
Instruction Operand Encoding
Description
Performs a SIMD compare of the packed double-precision floating-point values in the
source operand (second operand) and the destination operand (first operand) and
returns the results of the comparison to the destination operand. The comparison
predicate operand (third operand) specifies the type of comparison performed on
each of the pairs of packed values. The result of each comparison is a quadword
mask of all 1s (comparison true) or all 0s (comparison false).
128-bit Legacy SSE version: The first source and destination operand (first operand)
is an XMM register. The second source operand (second operand) can be an XMM
register or 128-bit memory location. The comparison predicate operand is an 8-bit
immediate, bits 2:0 of the immediate define the type of comparison to be performed
(see Table 3-7). Bits 7:3 of the immediate is reserved. Bits (VLMAX-1:128) of the
corresponding YMM destination register remain unchanged. Two comparisons are
performed with results written to bits 127:0 of the destination operand.
Opcode/
Instruction
Op/
En
64/32-
bit Mode
CPUID
Feature
Flag
Description
66 0F C2 /r ib
CMPPD xmm1, xmm2/m128, imm8
A V/V SSE2 Compare packed double-
precision floating-point
values in xmm2/m128 and
xmm1 using imm8 as
comparison predicate.
VEX.NDS.128.66.0F.WIG C2 /r ib
VCMPPD xmm1, xmm2, xmm3/m128,
imm8
B V/V AVX Compare packed double-
precision floating-point
values in xmm3/m128 and
xmm2 using bits 4:0 of
imm8 as a comparison
predicate.
VEX.NDS.256.66.0F.WIG C2 /r ib
VCMPPD ymm1, ymm2, ymm3/m256,
imm8
B V/V AVX Compare packed double-
precision floating-point
values in ymm3/m256 and
ymm2 using bits 4:0 of
imm8 as a comparison
predicate.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) imm8 NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

3-158 Vol. 2A CMPPD—Compare Packed Double-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
The unordered relationship is true when at least one of the two source operands
being compared is a NaN; the ordered relationship is true when neither source
operand is a NaN.
A subsequent computational instruction that uses the mask result in the destination
operand as an input operand will not generate an exception, because a mask of all 0s
corresponds to a floating-point value of +0.0 and a mask of all 1s corresponds to a
QNaN.
Note that the processors with “CPUID.1H:ECX.AVX =0” do not implement the
greater-than, greater-than-or-equal, not-greater-than, and not-greater-than-or-
equal relations. These comparisons can be made either by using the inverse relation-
ship (that is, use the “not-less-than-or-equal” to make a “greater-than” comparison)
or by using software emulation. When using software emulation, the program must
Table 3-7. Comparison Predicate for CMPPD and CMPPS Instructions
Predi-
cate
imm8
Encod-
ing
Description Relation where:
A Is 1st Operand
B Is 2nd
Operand
Emulation Result if
NaN
Operand
QNaN
Oper-and
Signals
Invalid
EQ 000B Equal A = BFalseNo
LT 001B Less-than A < BFalseYes
LE 010B Less-than-or-equal A ≤ BFalseYes
Greater than A > BSwap
Operands,
Use LT
False Yes
Greater-than-or-
equal
A ≥ BSwap
Operands,
Use LE
False Yes
UNORD 011B Unordered A, B = Unordered True No
NEQ 100B Not-equal A ≠ B True No
NLT 101B Not-less-than NOT(A < B) True Yes
NLE 110B Not-less-than-or-
equal
NOT(A ≤ B) True Yes
Not-greater-than NOT(A > B) Swap
Operands,
Use NLT
True Yes
Not-greater-than-
or-equal
NOT(A ≥ B) Swap
Operands,
Use NLE
True Yes
ORD 111B Ordered A , B = Ordered False No

Vol. 2A 3-159
INSTRUCTION SET REFERENCE, A-M
CMPPD—Compare Packed Double-Precision Floating-Point Values
swap the operands (copying registers when necessary to protect the data that will
now be in the destination), and then perform the compare using a different predi-
cate. The predicate to be used for these emulations is listed in Table 3-7 under the
heading Emulation.
Compilers and assemblers may implement the following two-operand pseudo-ops in
addition to the three-operand CMPPD instruction, for processors with
“CPUID.1H:ECX.AVX =0”. See Table 3-8. Compiler should treat reserved Imm8
values as illegal syntax.
:
The greater-than relations that the processor does not implement, require more than
one instruction to emulate in software and therefore should not be implemented as
pseudo-ops. (For these, the programmer should reverse the operands of the corre-
sponding less than relations and use move instructions to ensure that the mask is
moved to the correct destination register and that the source operand is left intact.)
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
Enhanced Comparison Predicate for VEX-Encoded VCMPPD
VEX.128 encoded version: The first source operand (second operand) is an XMM
register. The second source operand (third operand) can be an XMM register or a
128-bit memory location. Bits (VLMAX-1:128) of the destination YMM register are
zeroed. Two comparisons are performed with results written to bits 127:0 of the
destination operand.
VEX.256 encoded version: The first source operand (second operand) is a YMM
register. The second source operand (third operand) can be a YMM register or a 256-
bit memory location. The destination operand (first operand) is a YMM register. Four
comparisons are performed with results written to the destination operand.
The comparison predicate operand is an 8-bit immediate:
•For instructions encoded using the VEX prefix, bits 4:0 define the type of
comparison to be performed (see Table 3-9). Bits 5 through 7 of the immediate
are reserved.
Table 3-8. Pseudo-Op and CMPPD Implementation
Pseudo-Op CMPPD Implementation
CMPEQPD xmm1, xmm2 CMPPD xmm1, xmm2, 0
CMPLTPD xmm1, xmm2 CMPPD xmm1, xmm2, 1
CMPLEPD xmm1, xmm2 CMPPD xmm1, xmm2, 2
CMPUNORDPD xmm1, xmm2 CMPPD xmm1, xmm2, 3
CMPNEQPD xmm1, xmm2 CMPPD xmm1, xmm2, 4
CMPNLTPD xmm1, xmm2 CMPPD xmm1, xmm2, 5
CMPNLEPD xmm1, xmm2 CMPPD xmm1, xmm2, 6
CMPORDPD xmm1, xmm2 CMPPD xmm1, xmm2, 7
3-160 Vol. 2A CMPPD—Compare Packed Double-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
Table 3-9. Comparison Predicate for VCMPPD and VCMPPS Instructions
Predicate imm8
Value
Description Result: A Is 1st Operand, B Is 2nd Operand Signals
#IA on
QNAN
A >B A < B A = B Unordered1
EQ_OQ
(EQ)
0H Equal (ordered, non-
signaling)
False False True False No
LT_OS
(LT)
1H Less-than (ordered,
signaling)
False True False False Yes
LE_OS
(LE)
2H Less-than-or-equal
(ordered, signaling)
False True True False Yes
UNORD_
Q
(UNORD)
3H Unordered (non-
signaling)
False False False True No
NEQ_UQ
(NEQ)
4H Not-equal
(unordered, non-
signaling)
True True False True No
NLT_US
(NLT)
5H Not-less-than
(unordered,
signaling)
True False True True Yes
NLE_US
(NLE)
6H Not-less-than-or-
equal (unordered,
signaling)
True False False True Yes
ORD_Q
(ORD)
7H Ordered (non-
signaling)
True True True False No
EQ_UQ 8H Equal (unordered,
non-signaling)
False False True True No
NGE_US
(NGE)
9H Not-greater-than-or-
equal (unordered,
signaling)
False True False True Yes
NGT_US
(NGT)
AH Not-greater-than
(unordered, signal-
ing)
False True True True Yes
FALSE_O
Q(FALSE)
BH False (ordered, non-
signaling)
False False False False No
NEQ_OQ CH Not-equal (ordered,
non-signaling)
True True False False No
GE_OS
(GE)
DH Greater-than-or-
equal (ordered, sig-
naling)
True False True False Yes
Vol. 2A 3-161
INSTRUCTION SET REFERENCE, A-M
CMPPD—Compare Packed Double-Precision Floating-Point Values
GT_OS
(GT)
EH Greater-than
(ordered, signaling)
True False False False Yes
TRUE_U
Q(TRUE)
FH True (unordered,
non-signaling)
True True True True No
EQ_OS 10H Equal (ordered, sig-
naling)
False False True False Yes
LT_OQ 11H Less-than (ordered,
nonsignaling)
False True False False No
LE_OQ 12H Less-than-or-equal
(ordered, nonsignal-
ing)
False True True False No
UNORD_
S
13H Unordered (signal-
ing)
False False False True Yes
NEQ_US 14H Not-equal (unor-
dered, signaling)
True True False True Yes
NLT_UQ 15H Not-less-than (unor-
dered, nonsignaling)
True False True True No
NLE_UQ 16H Not-less-than-or-
equal (unordered,
nonsignaling)
True False False True No
ORD_S 17H Ordered (signaling) True True True False Yes
EQ_US 18H Equal (unordered,
signaling)
False False True True Yes
NGE_UQ 19H Not-greater-than-or-
equal (unordered,
nonsignaling)
False True False True No
NGT_UQ 1AH Not-greater-than
(unordered, nonsig-
naling)
False True True True No
FALSE_O
S
1BH False (ordered, sig-
naling)
False False False False Yes
NEQ_OS 1CH Not-equal (ordered,
signaling)
True True False False Yes
Table 3-9. Comparison Predicate for VCMPPD and VCMPPS Instructions (Contd.)
Predicate imm8
Value
Description Result: A Is 1st Operand, B Is 2nd Operand Signals
#IA on
QNAN
A >B A < B A = B Unordered1
3-162 Vol. 2A CMPPD—Compare Packed Double-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
Processors with “CPUID.1H:ECX.AVX =1” implement the full complement of 32 pred-
icates shown in Table 3-9, software emulation is no longer needed. Compilers and
assemblers may implement the following three-operand pseudo-ops in addition to
the four-operand VCMPPD instruction. See Table 3-10, where the notations of reg1
reg2, and reg3 represent either XMM registers or YMM registers. Compiler should
treat reserved Imm8 values as illegal syntax. Alternately, intrinsics can map the
pseudo-ops to pre-defined constants to support a simpler intrinsic interface.
:
GE_OQ 1DH Greater-than-or-
equal (ordered, non-
signaling)
True False True False No
GT_OQ 1EH Greater-than
(ordered, nonsignal-
ing)
True False False False No
TRUE_US 1FH True (unordered, sig-
naling)
True True True True Yes
NOTES:
1. If either operand A or B is a NAN.
Table 3-10. Pseudo-Op and VCMPPD Implementation
Pseudo-Op CMPPD Implementation
VCMPEQPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 0
VCMPLTPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 1
VCMPLEPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 2
VCMPUNORDPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 3
VCMPNEQPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 4
VCMPNLTPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 5
VCMPNLEPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 6
VCMPORDPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 7
VCMPEQ_UQPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 8
VCMPNGEPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 9
VCMPNGTPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 0AH
VCMPFALSEPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 0BH
VCMPNEQ_OQPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 0CH
Table 3-9. Comparison Predicate for VCMPPD and VCMPPS Instructions (Contd.)
Predicate imm8
Value
Description Result: A Is 1st Operand, B Is 2nd Operand Signals
#IA on
QNAN
A >B A < B A = B Unordered1

Vol. 2A 3-163
INSTRUCTION SET REFERENCE, A-M
CMPPD—Compare Packed Double-Precision Floating-Point Values
Operation
CASE (COMPARISON PREDICATE) OF
0: OP3 EQ_OQ; OP5 EQ_OQ;
1: OP3 LT_OS; OP5 LT_OS;
2: OP3 LE_OS; OP5 LE_OS;
3: OP3 UNORD_Q; OP5 UNORD_Q;
4: OP3 NEQ_UQ; OP5 NEQ_UQ;
5: OP3 NLT_US; OP5 NLT_US;
6: OP3 NLE_US; OP5 NLE_US;
7: OP3 ORD_Q; OP5 ORD_Q;
8: OP5 EQ_UQ;
9: OP5 NGE_US;
VCMPGEPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 0DH
VCMPGTPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 0EH
VCMPTRUEPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 0FH
VCMPEQ_OSPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 10H
VCMPLT_OQPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 11H
VCMPLE_OQPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 12H
VCMPUNORD_SPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 13H
VCMPNEQ_USPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 14H
VCMPNLT_UQPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 15H
VCMPNLE_UQPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 16H
VCMPORD_SPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 17H
VCMPEQ_USPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 18H
VCMPNGE_UQPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 19H
VCMPNGT_UQPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 1AH
VCMPFALSE_OSPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 1BH
VCMPNEQ_OSPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 1CH
VCMPGE_OQPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 1DH
VCMPGT_OQPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 1EH
VCMPTRUE_USPD reg1, reg2, reg3 VCMPPD reg1, reg2, reg3, 1FH
Table 3-10. Pseudo-Op and VCMPPD Implementation
Pseudo-Op CMPPD Implementation

3-164 Vol. 2A CMPPD—Compare Packed Double-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
10: OP5 NGT_US;
11: OP5 FALSE_OQ;
12: OP5 NEQ_OQ;
13: OP5 GE_OS;
14: OP5 GT_OS;
15: OP5 TRUE_UQ;
16: OP5 EQ_OS;
17: OP5 LT_OQ;
18: OP5 LE_OQ;
19: OP5 UNORD_S;
20: OP5 NEQ_US;
21: OP5 NLT_UQ;
22: OP5 NLE_UQ;
23: OP5 ORD_S;
24: OP5 EQ_US;
25: OP5 NGE_UQ;
26: OP5 NGT_UQ;
27: OP5 FALSE_OS;
28: OP5 NEQ_OS;
29: OP5 GE_OQ;
30: OP5 GT_OQ;
31: OP5 TRUE_US;
DEFAULT: Reserved;
CMPPD (128-bit Legacy SSE version)
CMP0 SRC1[63:0] OP3 SRC2[63:0];
CMP1 SRC1[127:64] OP3 SRC2[127:64];
IF CMP0 = TRUE
THEN DEST[63:0] FFFFFFFFFFFFFFFFH;
ELSE DEST[63:0] 0000000000000000H; FI;
IF CMP1 = TRUE
THEN DEST[127:64] FFFFFFFFFFFFFFFFH;
ELSE DEST[127:64] 0000000000000000H; FI;
DEST[VLMAX-1:128] (Unmodified)
VCMPPD (VEX.128 encoded version)
CMP0 SRC1[63:0] OP5 SRC2[63:0];
CMP1 SRC1[127:64] OP5 SRC2[127:64];
IF CMP0 = TRUE
THEN DEST[63:0] FFFFFFFFFFFFFFFFH;
ELSE DEST[63:0] 0000000000000000H; FI;
IF CMP1 = TRUE
THEN DEST[127:64] FFFFFFFFFFFFFFFFH;

Vol. 2A 3-165
INSTRUCTION SET REFERENCE, A-M
CMPPD—Compare Packed Double-Precision Floating-Point Values
ELSE DEST[127:64] 0000000000000000H; FI;
DEST[VLMAX-1:128] 0
VCMPPD (VEX.256 encoded version)
CMP0 SRC1[63:0] OP5 SRC2[63:0];
CMP1 SRC1[127:64] OP5 SRC2[127:64];
CMP2 SRC1[191:128] OP5 SRC2[191:128];
CMP3 SRC1[255:192] OP5 SRC2[255:192];
IF CMP0 = TRUE
THEN DEST[63:0] FFFFFFFFFFFFFFFFH;
ELSE DEST[63:0] 0000000000000000H; FI;
IF CMP1 = TRUE
THEN DEST[127:64] FFFFFFFFFFFFFFFFH;
ELSE DEST[127:64] 0000000000000000H; FI;
IF CMP2 = TRUE
THEN DEST[191:128] FFFFFFFFFFFFFFFFH;
ELSE DEST[191:128] 0000000000000000H; FI;
IF CMP3 = TRUE
THEN DEST[255:192] FFFFFFFFFFFFFFFFH;
ELSE DEST[255:192] 0000000000000000H; FI;
Intel C/C++ Compiler Intrinsic Equivalents
CMPPD for equality __m128d _mm_cmpeq_pd(__m128d a, __m128d b)
CMPPD for less-than__m128d _mm_cmplt_pd(__m128d a, __m128d b)
CMPPD for less-than-or-equal__m128d _mm_cmple_pd(__m128d a, __m128d b)
CMPPD for greater-than__m128d _mm_cmpgt_pd(__m128d a, __m128d b)
CMPPD for greater-than-or-equal__m128d _mm_cmpge_pd(__m128d a, __m128d b)
CMPPD for inequality __m128d _mm_cmpneq_pd(__m128d a, __m128d b)
CMPPD for not-less-than __m128d _mm_cmpnlt_pd(__m128d a, __m128d b)
CMPPD for not-greater-than __m128d _mm_cmpngt_pd(__m128d a, __m128d b)
CMPPD for not-greater-than-or-equal__m128d _mm_cmpnge_pd(__m128d a, __m128d b)
CMPPD for ordered __m128d _mm_cmpord_pd(__m128d a, __m128d b)
CMPPD for unordered__m128d _mm_cmpunord_pd(__m128d a, __m128d b)
CMPPD for not-less-than-or-equal__m128d _mm_cmpnle_pd(__m128d a, __m128d b)
VCMPPD __m256 _mm256_cmp_pd(__m256 a, __m256 b, const int imm)
VCMPPD __m128 _mm_cmp_pd(__m128 a, __m128 b, const int imm)

3-166 Vol. 2A CMPPD—Compare Packed Double-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
SIMD Floating-Point Exceptions
Invalid if SNaN operand and invalid if QNaN and predicate as listed in above table,
Denormal.
Other Exceptions
See Exceptions Type 2.

Vol. 2A 3-167
INSTRUCTION SET REFERENCE, A-M
CMPPS—Compare Packed Single-Precision Floating-Point Values
CMPPS—Compare Packed Single-Precision Floating-Point Values
Instruction Operand Encoding
Description
Performs a SIMD compare of the packed single-precision floating-point values in the
source operand (second operand) and the destination operand (first operand) and
returns the results of the comparison to the destination operand. The comparison
predicate operand (third operand) specifies the type of comparison performed on
each of the pairs of packed values. The result of each comparison is a doubleword
mask of all 1s (comparison true) or all 0s (comparison false).
128-bit Legacy SSE version: The first source and destination operand (first operand)
is an XMM register. The second source operand (second operand) can be an XMM
register or 128-bit memory location. The comparison predicate operand is an 8-bit
immediate, bits 2:0 of the immediate define the type of comparison to be performed
(see Table 3-7). Bits 7:3 of the immediate is reserved. Bits (VLMAX-1:128) of the
corresponding YMM destination register remain unchanged. Four comparisons are
performed with results written to bits 127:0 of the destination operand.
Opcode/
Instruction
Op/
En
64/32-
bit Mode
CPUID
Feature
Flag
Description
0F C2 /r ib
CMPPS xmm1, xmm2/m128, imm8
A V/V SSE Compare packed single-
precision floating-point
values in xmm2/mem and
xmm1 using imm8 as
comparison predicate.
VEX.NDS.128.0F.WIG C2 /r ib
VCMPPS xmm1, xmm2, xmm3/m128,
imm8
B V/V AVX Compare packed single-
precision floating-point
values in xmm3/m128 and
xmm2 using bits 4:0 of
imm8 as a comparison
predicate.
VEX.NDS.256.0F.WIG C2 /r ib
VCMPPS ymm1, ymm2, ymm3/m256,
imm8
B V/V AVX Compare packed single-
precision floating-point
values in ymm3/m256 and
ymm2 using bits 2:0 of
imm8 as a comparison
predicate.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) imm8 NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

3-168 Vol. 2A CMPPS—Compare Packed Single-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
The unordered relationship is true when at least one of the two source operands
being compared is a NaN; the ordered relationship is true when neither source
operand is a NaN.
A subsequent computational instruction that uses the mask result in the destination
operand as an input operand will not generate a fault, because a mask of all 0s corre-
sponds to a floating-point value of +0.0 and a mask of all 1s corresponds to a QNaN.
Note that processors with “CPUID.1H:ECX.AVX =0” do not implement the “greater-
than”, “greater-than-or-equal”, “not-greater than”, and “not-greater-than-or-equal
relations” predicates. These comparisons can be made either by using the inverse
relationship (that is, use the “not-less-than-or-equal” to make a “greater-than”
comparison) or by using software emulation. When using software emulation, the
program must swap the operands (copying registers when necessary to protect the
data that will now be in the destination), and then perform the compare using a
different predicate. The predicate to be used for these emulations is listed in Table
3-7 under the heading Emulation.
Compilers and assemblers may implement the following two-operand pseudo-ops in
addition to the three-operand CMPPS instruction, for processors with
“CPUID.1H:ECX.AVX =0”. See Table 3-11. Compiler should treat reserved Imm8
values as illegal syntax.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
The greater-than relations not implemented by processor require more than one
instruction to emulate in software and therefore should not be implemented as
pseudo-ops. (For these, the programmer should reverse the operands of the corre-
sponding less than relations and use move instructions to ensure that the mask is
moved to the correct destination register and that the source operand is left intact.)
Enhanced Comparison Predicate for VEX-Encoded VCMPPS
Table 3-11. Pseudo-Ops and CMPPS
Pseudo-Op Implementation
CMPEQPS xmm1, xmm2 CMPPS xmm1, xmm2, 0
CMPLTPS xmm1, xmm2 CMPPS xmm1, xmm2, 1
CMPLEPS xmm1, xmm2 CMPPS xmm1, xmm2, 2
CMPUNORDPS xmm1, xmm2 CMPPS xmm1, xmm2, 3
CMPNEQPS xmm1, xmm2 CMPPS xmm1, xmm2, 4
CMPNLTPS xmm1, xmm2 CMPPS xmm1, xmm2, 5
CMPNLEPS xmm1, xmm2 CMPPS xmm1, xmm2, 6
CMPORDPS xmm1, xmm2 CMPPS xmm1, xmm2, 7
Vol. 2A 3-169
INSTRUCTION SET REFERENCE, A-M
CMPPS—Compare Packed Single-Precision Floating-Point Values
VEX.128 encoded version: The first source operand (second operand) is an XMM
register. The second source operand (third operand) can be an XMM register or a
128-bit memory location. Bits (VLMAX-1:128) of the destination YMM register are
zeroed. Four comparisons are performed with results written to bits 127:0 of the
destination operand.
VEX.256 encoded version: The first source operand (second operand) is a YMM
register. The second source operand (third operand) can be a YMM register or a 256-
bit memory location. The destination operand (first operand) is a YMM register. Eight
comparisons are performed with results written to the destination operand.
The comparison predicate operand is an 8-bit immediate:
•For instructions encoded using the VEX prefix, bits 4:0 define the type of
comparison to be performed (see Table 3-9). Bits 5 through 7 of the immediate
are reserved.
Processors with “CPUID.1H:ECX.AVX =1” implement the full complement of 32 pred-
icates shown in Table 3-9, software emulation is no longer needed. Compilers and
assemblers may implement the following three-operand pseudo-ops in addition to
the four-operand VCMPPS instruction. See Table 3-12, where the notation of reg1
and reg2 represent either XMM registers or YMM registers. Compiler should treat
reserved Imm8 values as illegal syntax. Alternately, intrinsics can map the pseudo-
ops to pre-defined constants to support a simpler intrinsic interface.
:Table 3-12. Pseudo-Op and VCMPPS Implementation
Pseudo-Op CMPPS Implementation
VCMPEQPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 0
VCMPLTPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 1
VCMPLEPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 2
VCMPUNORDPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 3
VCMPNEQPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 4
VCMPNLTPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 5
VCMPNLEPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 6
VCMPORDPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 7
VCMPEQ_UQPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 8
VCMPNGEPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 9
VCMPNGTPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 0AH
VCMPFALSEPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 0BH
VCMPNEQ_OQPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 0CH
VCMPGEPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 0DH
VCMPGTPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 0EH

3-170 Vol. 2A CMPPS—Compare Packed Single-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
Operation
CASE (COMPARISON PREDICATE) OF
0: OP3 EQ_OQ; OP5 EQ_OQ;
1: OP3 LT_OS; OP5 LT_OS;
2: OP3 LE_OS; OP5 LE_OS;
3: OP3 UNORD_Q; OP5 UNORD_Q;
4: OP3 NEQ_UQ; OP5 NEQ_UQ;
5: OP3 NLT_US; OP5 NLT_US;
6: OP3 NLE_US; OP5 NLE_US;
7: OP3 ORD_Q; OP5 ORD_Q;
8: OP5 EQ_UQ;
9: OP5 NGE_US;
10: OP5 NGT_US;
11: OP5 FALSE_OQ;
12: OP5 NEQ_OQ;
13: OP5 GE_OS;
14: OP5 GT_OS;
VCMPTRUEPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 0FH
VCMPEQ_OSPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 10H
VCMPLT_OQPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 11H
VCMPLE_OQPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 12H
VCMPUNORD_SPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 13H
VCMPNEQ_USPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 14H
VCMPNLT_UQPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 15H
VCMPNLE_UQPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 16H
VCMPORD_SPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 17H
VCMPEQ_USPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 18H
VCMPNGE_UQPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 19H
VCMPNGT_UQPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 1AH
VCMPFALSE_OSPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 1BH
VCMPNEQ_OSPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 1CH
VCMPGE_OQPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 1DH
VCMPGT_OQPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 1EH
VCMPTRUE_USPS reg1, reg2, reg3 VCMPPS reg1, reg2, reg3, 1FH
Table 3-12. Pseudo-Op and VCMPPS Implementation
Pseudo-Op CMPPS Implementation

Vol. 2A 3-171
INSTRUCTION SET REFERENCE, A-M
CMPPS—Compare Packed Single-Precision Floating-Point Values
15: OP5 TRUE_UQ;
16: OP5 EQ_OS;
17: OP5 LT_OQ;
18: OP5 LE_OQ;
19: OP5 UNORD_S;
20: OP5 NEQ_US;
21: OP5 NLT_UQ;
22: OP5 NLE_UQ;
23: OP5 ORD_S;
24: OP5 EQ_US;
25: OP5 NGE_UQ;
26: OP5 NGT_UQ;
27: OP5 FALSE_OS;
28: OP5 NEQ_OS;
29: OP5 GE_OQ;
30: OP5 GT_OQ;
31: OP5 TRUE_US;
DEFAULT: Reserved
EASC;
CMPPS (128-bit Legacy SSE version)
CMP0 SRC1[31:0] OP3 SRC2[31:0];
CMP1 SRC1[63:32] OP3 SRC2[63:32];
CMP2 SRC1[95:64] OP3 SRC2[95:64];
CMP3 SRC1[127:96] OP3 SRC2[127:96];
IF CMP0 = TRUE
THEN DEST[31:0] FFFFFFFFH;
ELSE DEST[31:0] 000000000H; FI;
IF CMP1 = TRUE
THEN DEST[63:32] FFFFFFFFH;
ELSE DEST[63:32] 000000000H; FI;
IF CMP2 = TRUE
THEN DEST[95:64] FFFFFFFFH;
ELSE DEST[95:64] 000000000H; FI;
IF CMP3 = TRUE
THEN DEST[127:96] FFFFFFFFH;
ELSE DEST[127:96] 000000000H; FI;
DEST[VLMAX-1:128] (Unmodified)
VCMPPS (VEX.128 encoded version)
CMP0 SRC1[31:0] OP5 SRC2[31:0];
CMP1 SRC1[63:32] OP5 SRC2[63:32];
CMP2 SRC1[95:64] OP5 SRC2[95:64];

3-172 Vol. 2A CMPPS—Compare Packed Single-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
CMP3 SRC1[127:96] OP5 SRC2[127:96];
IF CMP0 = TRUE
THEN DEST[31:0] FFFFFFFFH;
ELSE DEST[31:0] 000000000H; FI;
IF CMP1 = TRUE
THEN DEST[63:32] FFFFFFFFH;
ELSE DEST[63:32] 000000000H; FI;
IF CMP2 = TRUE
THEN DEST[95:64] FFFFFFFFH;
ELSE DEST[95:64] 000000000H; FI;
IF CMP3 = TRUE
THEN DEST[127:96] FFFFFFFFH;
ELSE DEST[127:96] 000000000H; FI;
DEST[VLMAX-1:128] 0
VCMPPS (VEX.256 encoded version)
CMP0 SRC1[31:0] OP5 SRC2[31:0];
CMP1 SRC1[63:32] OP5 SRC2[63:32];
CMP2 SRC1[95:64] OP5 SRC2[95:64];
CMP3 SRC1[127:96] OP5 SRC2[127:96];
CMP4 SRC1[159:128] OP5 SRC2[159:128];
CMP5 SRC1[191:160] OP5 SRC2[191:160];
CMP6 SRC1[223:192] OP5 SRC2[223:192];
CMP7 SRC1[255:224] OP5 SRC2[255:224];
IF CMP0 = TRUE
THEN DEST[31:0] FFFFFFFFH;
ELSE DEST[31:0] 000000000H; FI;
IF CMP1 = TRUE
THEN DEST[63:32] FFFFFFFFH;
ELSE DEST[63:32] 000000000H; FI;
IF CMP2 = TRUE
THEN DEST[95:64] FFFFFFFFH;
ELSE DEST[95:64] 000000000H; FI;
IF CMP3 = TRUE
THEN DEST[127:96] FFFFFFFFH;
ELSE DEST[127:96] 000000000H; FI;
IF CMP4 = TRUE
THEN DEST[159:128] FFFFFFFFH;
ELSE DEST[159:128] 000000000H; FI;
IF CMP5 = TRUE
THEN DEST[191:160] FFFFFFFFH;
ELSE DEST[191:160] 000000000H; FI;
IF CMP6 = TRUE

Vol. 2A 3-173
INSTRUCTION SET REFERENCE, A-M
CMPPS—Compare Packed Single-Precision Floating-Point Values
THEN DEST[223:192] FFFFFFFFH;
ELSE DEST[223:192] 000000000H; FI;
IF CMP7 = TRUE
THEN DEST[255:224] FFFFFFFFH;
ELSE DEST[255:224] 000000000H; FI;
Intel C/C++ Compiler Intrinsic Equivalents
CMPPS for equality __m128 _mm_cmpeq_ps(__m128 a, __m128 b)
CMPPS for less-than__m128 _mm_cmplt_ps(__m128 a, __m128 b)
CMPPS for less-than-or-equal__m128 _mm_cmple_ps(__m128 a, __m128 b)
CMPPS for greater-than __m128 _mm_cmpgt_ps(__m128 a, __m128 b)
CMPPS for greater-than-or-equal__m128 _mm_cmpge_ps(__m128 a, __m128 b)
CMPPS for inequality __m128 _mm_cmpneq_ps(__m128 a, __m128 b)
CMPPS for not-less-than __m128 _mm_cmpnlt_ps(__m128 a, __m128 b)
CMPPS for not-greater-than __m128 _mm_cmpngt_ps(__m128 a, __m128 b)
CMPPS for not-greater-than-or-equal__m128 _mm_cmpnge_ps(__m128 a, __m128 b)
CMPPS for ordered__m128 _mm_cmpord_ps(__m128 a, __m128 b)
CMPPS for unordered__m128 _mm_cmpunord_ps(__m128 a, __m128 b)
CMPPS for not-less-than-or-equal__m128 _mm_cmpnle_ps(__m128 a, __m128 b)
VCMPPS __m256 _mm256_cmp_ps(__m256 a, __m256 b, const int imm)
VCMPPS __m128 _mm_cmp_ps(__m128 a, __m128 b, const int imm)
SIMD Floating-Point Exceptions
Invalid if SNaN operand and invalid if QNaN and predicate as listed in above table,
Denormal.
Other Exceptions
See Exceptions Type 2.

3-174 Vol. 2A CMPS/CMPSB/CMPSW/CMPSD/CMPSQ—Compare String Operands
INSTRUCTION SET REFERENCE, A-M
CMPS/CMPSB/CMPSW/CMPSD/CMPSQ—Compare String Operands
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
A6 CMPS m8, m8 A Valid Valid For legacy mode, compare
byte at address DS:(E)SI
with byte at address
ES:(E)DI; For 64-bit mode
compare byte at address
(R|E)SI to byte at address
(R|E)DI. The status flags are
set accordingly.
A7 CMPS m16, m16 A Valid Valid For legacy mode, compare
word at address DS:(E)SI
with word at address
ES:(E)DI; For 64-bit mode
compare word at address
(R|E)SI with word at address
(R|E)DI. The status flags are
set accordingly.
A7 CMPS m32, m32 A Valid Valid For legacy mode, compare
dword at address DS:(E)SI at
dword at address ES:(E)DI;
For 64-bit mode compare
dword at address (R|E)SI at
dword at address (R|E)DI.
The status flags are set
accordingly.
REX.W + A7 CMPS m64, m64 A Valid N.E. Compares quadword at
address (R|E)SI with
quadword at address (R|E)DI
and sets the status flags
accordingly.
A6 CMPSB A Valid Valid For legacy mode, compare
byte at address DS:(E)SI
with byte at address
ES:(E)DI; For 64-bit mode
compare byte at address
(R|E)SI with byte at address
(R|E)DI. The status flags are
set accordingly.

Vol. 2A 3-175
INSTRUCTION SET REFERENCE, A-M
CMPS/CMPSB/CMPSW/CMPSD/CMPSQ—Compare String Operands
Instruction Operand Encoding
Description
Compares the byte, word, doubleword, or quadword specified with the first source
operand with the byte, word, doubleword, or quadword specified with the second
source operand and sets the status flags in the EFLAGS register according to the
results.
Both source operands are located in memory. The address of the first source operand
is read from DS:SI, DS:ESI or RSI (depending on the address-size attribute of the
instruction is 16, 32, or 64, respectively). The address of the second source operand
is read from ES:DI, ES:EDI or RDI (again depending on the address-size attribute of
the instruction is 16, 32, or 64). The DS segment may be overridden with a segment
override prefix, but the ES segment cannot be overridden.
At the assembly-code level, two forms of this instruction are allowed: the “explicit-
operands” form and the “no-operands” form. The explicit-operands form (specified
with the CMPS mnemonic) allows the two source operands to be specified explicitly.
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
A7 CMPSW A Valid Valid For legacy mode, compare
word at address DS:(E)SI
with word at address
ES:(E)DI; For 64-bit mode
compare word at address
(R|E)SI with word at address
(R|E)DI. The status flags are
set accordingly.
A7 CMPSD A Valid Valid For legacy mode, compare
dword at address DS:(E)SI
with dword at address
ES:(E)DI; For 64-bit mode
compare dword at address
(R|E)SI with dword at
address (R|E)DI. The status
flags are set accordingly.
REX.W + A7 CMPSQ A Valid N.E. Compares quadword at
address (R|E)SI with
quadword at address (R|E)DI
and sets the status flags
accordingly.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA

3-176 Vol. 2A CMPS/CMPSB/CMPSW/CMPSD/CMPSQ—Compare String Operands
INSTRUCTION SET REFERENCE, A-M
Here, the source operands should be symbols that indicate the size and location of
the source values. This explicit-operand form is provided to allow documentation.
However, note that the documentation provided by this form can be misleading. That
is, the source operand symbols must specify the correct type (size) of the operands
(bytes, words, or doublewords, quadwords), but they do not have to specify the
correct location. Locations of the source operands are always specified by the
DS:(E)SI (or RSI) and ES:(E)DI (or RDI) registers, which must be loaded correctly
before the compare string instruction is executed.
The no-operands form provides “short forms” of the byte, word, and doubleword
versions of the CMPS instructions. Here also the DS:(E)SI (or RSI) and ES:(E)DI (or
RDI) registers are assumed by the processor to specify the location of the source
operands. The size of the source operands is selected with the mnemonic: CMPSB
(byte comparison), CMPSW (word comparison), CMPSD (doubleword comparison),
or CMPSQ (quadword comparison using REX.W).
After the comparison, the (E/R)SI and (E/R)DI registers increment or decrement
automatically according to the setting of the DF flag in the EFLAGS register. (If the DF
flag is 0, the (E/R)SI and (E/R)DI register increment; if the DF flag is 1, the registers
decrement.) The registers increment or decrement by 1 for byte operations, by 2 for
word operations, 4 for doubleword operations. If operand size is 64, RSI and RDI
registers increment by 8 for quadword operations.
The CMPS, CMPSB, CMPSW, CMPSD, and CMPSQ instructions can be preceded by the
REP prefix for block comparisons. More often, however, these instructions will be
used in a LOOP construct that takes some action based on the setting of the status
flags before the next comparison is made. See “REP/REPE/REPZ
/REPNE/REPNZ—Repeat String Operation Prefix” in Chapter 4 of the Intel® 64 and
IA-32 Architectures Software Developer’s Manual, Volume 2B, for a description of the
REP prefix.
In 64-bit mode, the instruction’s default address size is 64 bits, 32 bit address size is
supported using the prefix 67H. Use of the REX.W prefix promotes doubleword oper-
ation to 64 bits (see CMPSQ). See the summary chart at the beginning of this section
for encoding data and limits.
Operation
temp ← SRC1 - SRC2;
SetStatusFlags(temp);
IF (64-Bit Mode)
THEN
IF (Byte comparison)
THEN IF DF = 0
THEN
(R|E)SI ← (R|E)SI + 1;
(R|E)DI ← (R|E)DI + 1;
ELSE

Vol. 2A 3-177
INSTRUCTION SET REFERENCE, A-M
CMPS/CMPSB/CMPSW/CMPSD/CMPSQ—Compare String Operands
(R|E)SI ← (R|E)SI – 1;
(R|E)DI ← (R|E)DI – 1;
FI;
ELSE IF (Word comparison)
THEN IF DF = 0
THEN
(R|E)SI ← (R|E)SI + 2;
(R|E)DI ← (R|E)DI + 2;
ELSE
(R|E)SI ← (R|E)SI – 2;
(R|E)DI ← (R|E)DI – 2;
FI;
ELSE IF (Doubleword comparison)
THEN IF DF = 0
THEN
(R|E)SI ← (R|E)SI + 4;
(R|E)DI ← (R|E)DI + 4;
ELSE
(R|E)SI ← (R|E)SI – 4;
(R|E)DI ← (R|E)DI – 4;
FI;
ELSE (* Quadword comparison *)
THEN IF DF = 0
(R|E)SI ← (R|E)SI + 8;
(R|E)DI ← (R|E)DI + 8;
ELSE
(R|E)SI ← (R|E)SI – 8;
(R|E)DI ← (R|E)DI – 8;
FI;
FI;
ELSE (* Non-64-bit Mode *)
IF (byte comparison)
THEN IF DF = 0
THEN
(E)SI ← (E)SI + 1;
(E)DI ← (E)DI + 1;
ELSE
(E)SI ← (E)SI – 1;
(E)DI ← (E)DI – 1;
FI;
ELSE IF (Word comparison)
THEN IF DF = 0
(E)SI ← (E)SI + 2;

3-178 Vol. 2A CMPS/CMPSB/CMPSW/CMPSD/CMPSQ—Compare String Operands
INSTRUCTION SET REFERENCE, A-M
(E)DI ← (E)DI + 2;
ELSE
(E)SI ← (E)SI – 2;
(E)DI ← (E)DI – 2;
FI;
ELSE (* Doubleword comparison *)
THEN IF DF = 0
(E)SI ← (E)SI + 4;
(E)DI ← (E)DI + 4;
ELSE
(E)SI ← (E)SI – 4;
(E)DI ← (E)DI – 4;
FI;
FI;
FI;
Flags Affected
The CF, OF, SF, ZF, AF, and PF flags are set according to the temporary result of the
comparison.
Protected Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#UD If the LOCK prefix is used.

Vol. 2A 3-179
INSTRUCTION SET REFERENCE, A-M
CMPS/CMPSB/CMPSW/CMPSD/CMPSQ—Compare String Operands
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.

3-180 Vol. 2A CMPSD—Compare Scalar Double-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
CMPSD—Compare Scalar Double-Precision Floating-Point Values
Instruction Operand Encoding
Description
Compares the low double-precision floating-point values in the source operand
(second operand) and the destination operand (first operand) and returns the results
of the comparison to the destination operand. The comparison predicate operand
(third operand) specifies the type of comparison performed. The comparison result is
a quadword mask of all 1s (comparison true) or all 0s (comparison false).
128-bit Legacy SSE version: The first source and destination operand (first operand)
is an XMM register. The second source operand (second operand) can be an XMM
register or 64-bit memory location. The comparison predicate operand is an 8-bit
immediate, bits 2:0 of the immediate define the type of comparison to be performed
(see Table 3-7). Bits 7:3 of the immediate is reserved. Bits (VLMAX-1:64) of the
corresponding YMM destination register remain unchanged.
The unordered relationship is true when at least one of the two source operands
being compared is a NaN; the ordered relationship is true when neither source
operand is a NaN.
A subsequent computational instruction that uses the mask result in the destination
operand as an input operand will not generate a fault, because a mask of all 0s corre-
sponds to a floating-point value of +0.0 and a mask of all 1s corresponds to a QNaN.
Note that processors with “CPUID.1H:ECX.AVX =0” do not implement the “greater-
than”, “greater-than-or-equal”, “not-greater than”, and “not-greater-than-or-equal
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F2 0F C2 /r ib
CMPSD xmm1, xmm2/m64, imm8
A V/V SSE2 Compare low double-
precision floating-point
value in xmm2/m64 and
xmm1 using imm8 as
comparison predicate.
VEX.NDS.LIG.F2.0F.WIG C2 /r ib
VCMPSD xmm1, xmm2, xmm3/m64,
imm8
B V/V AVX Compare low double
precision floating-point
value in xmm3/m64 and
xmm2 using bits 4:0 of
imm8 as comparison
predicate.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) imm8 NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

Vol. 2A 3-181
INSTRUCTION SET REFERENCE, A-M
CMPSD—Compare Scalar Double-Precision Floating-Point Values
relations” predicates. These comparisons can be made either by using the inverse
relationship (that is, use the “not-less-than-or-equal” to make a “greater-than”
comparison) or by using software emulation. When using software emulation, the
program must swap the operands (copying registers when necessary to protect the
data that will now be in the destination operand), and then perform the compare
using a different predicate. The predicate to be used for these emulations is listed in
Table 3-7 under the heading Emulation.
Compilers and assemblers may implement the following two-operand pseudo-ops in
addition to the three-operand CMPSD instruction, for processors with
“CPUID.1H:ECX.AVX =0”. See Table 3-13. Compiler should treat reserved Imm8
values as illegal syntax.
The greater-than relations not implemented in the processor require more than one
instruction to emulate in software and therefore should not be implemented as
pseudo-ops. (For these, the programmer should reverse the operands of the corre-
sponding less than relations and use move instructions to ensure that the mask is
moved to the correct destination register and that the source operand is left intact.)
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
Enhanced Comparison Predicate for VEX-Encoded VCMPSD
VEX.128 encoded version: The first source operand (second operand) is an XMM
register. The second source operand (third operand) can be an XMM register or a 64-
bit memory location. Bits (VLMAX-1:128) of the destination YMM register are zeroed.
The comparison predicate operand is an 8-bit immediate:
•For instructions encoded using the VEX prefix, bits 4:0 define the type of
comparison to be performed (see Table 3-9). Bits 5 through 7 of the immediate
are reserved.
Processors with “CPUID.1H:ECX.AVX =1” implement the full complement of 32 pred-
icates shown in Table 3-9, software emulation is no longer needed. Compilers and
Table 3-13. Pseudo-Ops and CMPSD
Pseudo-Op Implementation
CMPEQSD xmm1, xmm2 CMPSD xmm1,xmm2, 0
CMPLTSD xmm1, xmm2 CMPSD xmm1,xmm2, 1
CMPLESD xmm1, xmm2 CMPSD xmm1,xmm2, 2
CMPUNORDSD xmm1, xmm2 CMPSD xmm1,xmm2, 3
CMPNEQSD xmm1, xmm2 CMPSD xmm1,xmm2, 4
CMPNLTSD xmm1, xmm2 CMPSD xmm1,xmm2, 5
CMPNLESD xmm1, xmm2 CMPSD xmm1,xmm2, 6
CMPORDSD xmm1, xmm2 CMPSD xmm1,xmm2, 7

3-182 Vol. 2A CMPSD—Compare Scalar Double-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
assemblers may implement the following three-operand pseudo-ops in addition to
the four-operand VCMPSD instruction. See Table 3-14, where the notations of reg1
reg2, and reg3 represent either XMM registers or YMM registers. Compiler should
treat reserved Imm8 values as illegal syntax. Alternately, intrinsics can map the
pseudo-ops to pre-defined constants to support a simpler intrinsic interface.
:Table 3-14. Pseudo-Op and VCMPSD Implementation
Pseudo-Op CMPSD Implementation
VCMPEQSD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 0
VCMPLTSD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 1
VCMPLESD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 2
VCMPUNORDSD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 3
VCMPNEQSD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 4
VCMPNLTSD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 5
VCMPNLESD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 6
VCMPORDSD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 7
VCMPEQ_UQSD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 8
VCMPNGESD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 9
VCMPNGTSD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 0AH
VCMPFALSESD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 0BH
VCMPNEQ_OQSD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 0CH
VCMPGESD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 0DH
VCMPGTSD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 0EH
VCMPTRUESD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 0FH
VCMPEQ_OSSD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 10H
VCMPLT_OQSD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 11H
VCMPLE_OQSD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 12H
VCMPUNORD_SSD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 13H
VCMPNEQ_USSD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 14H
VCMPNLT_UQSD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 15H
VCMPNLE_UQSD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 16H
VCMPORD_SSD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 17H
VCMPEQ_USSD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 18H
VCMPNGE_UQSD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 19H
VCMPNGT_UQSD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 1AH
Vol. 2A 3-183
INSTRUCTION SET REFERENCE, A-M
CMPSD—Compare Scalar Double-Precision Floating-Point Values
Operation
CASE (COMPARISON PREDICATE) OF
0: OP3 EQ_OQ; OP5 EQ_OQ;
1: OP3 LT_OS; OP5 LT_OS;
2: OP3 LE_OS; OP5 LE_OS;
3: OP3 UNORD_Q; OP5 UNORD_Q;
4: OP3 NEQ_UQ; OP5 NEQ_UQ;
5: OP3 NLT_US; OP5 NLT_US;
6: OP3 NLE_US; OP5 NLE_US;
7: OP3 ORD_Q; OP5 ORD_Q;
8: OP5 EQ_UQ;
9: OP5 NGE_US;
10: OP5 NGT_US;
11: OP5 FALSE_OQ;
12: OP5 NEQ_OQ;
13: OP5 GE_OS;
14: OP5 GT_OS;
15: OP5 TRUE_UQ;
16: OP5 EQ_OS;
17: OP5 LT_OQ;
18: OP5 LE_OQ;
19: OP5 UNORD_S;
20: OP5 NEQ_US;
21: OP5 NLT_UQ;
22: OP5 NLE_UQ;
23: OP5 ORD_S;
24: OP5 EQ_US;
25: OP5 NGE_UQ;
26: OP5 NGT_UQ;
27: OP5 FALSE_OS;
28: OP5 NEQ_OS;
VCMPFALSE_OSSD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 1BH
VCMPNEQ_OSSD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 1CH
VCMPGE_OQSD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 1DH
VCMPGT_OQSD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 1EH
VCMPTRUE_USSD reg1, reg2, reg3 VCMPSD reg1, reg2, reg3, 1FH
Table 3-14. Pseudo-Op and VCMPSD Implementation
Pseudo-Op CMPSD Implementation

3-184 Vol. 2A CMPSD—Compare Scalar Double-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
29: OP5 GE_OQ;
30: OP5 GT_OQ;
31: OP5 TRUE_US;
DEFAULT: Reserved
ESAC;
CMPSD (128-bit Legacy SSE version)
CMP0 DEST[63:0] OP3 SRC[63:0];
IF CMP0 = TRUE
THEN DEST[63:0] FFFFFFFFFFFFFFFFH;
ELSE DEST[63:0] 0000000000000000H; FI;
DEST[VLMAX-1:64] (Unmodified)
VCMPSD (VEX.128 encoded version)
CMP0 SRC1[63:0] OP5 SRC2[63:0];
IF CMP0 = TRUE
THEN DEST[63:0] FFFFFFFFFFFFFFFFH;
ELSE DEST[63:0] 0000000000000000H; FI;
DEST[127:64] SRC1[127:64]
DEST[VLMAX-1:128] 0
Intel C/C++ Compiler Intrinsic Equivalents
CMPSD for equality__m128d _mm_cmpeq_sd(__m128d a, __m128d b)
CMPSD for less-than__m128d _mm_cmplt_sd(__m128d a, __m128d b)
CMPSD for less-than-or-equal__m128d _mm_cmple_sd(__m128d a, __m128d b)
CMPSD for greater-than__m128d _mm_cmpgt_sd(__m128d a, __m128d b)
CMPSD for greater-than-or-equal__m128d _mm_cmpge_sd(__m128d a, __m128d b)
CMPSD for inequality__m128d _mm_cmpneq_sd(__m128d a, __m128d b)
CMPSD for not-less-than__m128d _mm_cmpnlt_sd(__m128d a, __m128d b)
CMPSD for not-greater-than__m128d _mm_cmpngt_sd(__m128d a, __m128d b)
CMPSD for not-greater-than-or-equal__m128d _mm_cmpnge_sd(__m128d a, __m128d b)
CMPSD for ordered__m128d _mm_cmpord_sd(__m128d a, __m128d b)
CMPSD for unordered__m128d _mm_cmpunord_sd(__m128d a, __m128d b)
CMPSD for not-less-than-or-equal__m128d _mm_cmpnle_sd(__m128d a, __m128d b)
VCMPSD __m128 _mm_cmp_sd(__m128 a, __m128 b, const int imm)
SIMD Floating-Point Exceptions
Invalid if SNaN operand, Invalid if QNaN and predicate as listed in above table,
Denormal.

Vol. 2A 3-185
INSTRUCTION SET REFERENCE, A-M
CMPSD—Compare Scalar Double-Precision Floating-Point Values
Other Exceptions
See Exceptions Type 3.

3-186 Vol. 2A CMPSS—Compare Scalar Single-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
CMPSS—Compare Scalar Single-Precision Floating-Point Values
Instruction Operand Encoding
Description
Compares the low single-precision floating-point values in the source operand
(second operand) and the destination operand (first operand) and returns the results
of the comparison to the destination operand. The comparison predicate operand
(third operand) specifies the type of comparison performed. The comparison result is
a doubleword mask of all 1s (comparison true) or all 0s (comparison false).
128-bit Legacy SSE version: The first source and destination operand (first operand)
is an XMM register. The second source operand (second operand) can be an XMM
register or 64-bit memory location. The comparison predicate operand is an 8-bit
immediate, bits 2:0 of the immediate define the type of comparison to be performed
(see Table 3-7). Bits 7:3 of the immediate is reserved. Bits (VLMAX-1:32) of the
corresponding YMM destination register remain unchanged.
The unordered relationship is true when at least one of the two source operands
being compared is a NaN; the ordered relationship is true when neither source
operand is a NaN
A subsequent computational instruction that uses the mask result in the destination
operand as an input operand will not generate a fault, since a mask of all 0s corre-
sponds to a floating-point value of +0.0 and a mask of all 1s corresponds to a QNaN.
Note that processors with “CPUID.1H:ECX.AVX =0” do not implement the “greater-
than”, “greater-than-or-equal”, “not-greater than”, and “not-greater-than-or-equal
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F3 0F C2 /r ib
CMPSS xmm1, xmm2/m32, imm8
A V/V SSE Compare low single-
precision floating-point
value in xmm2/m32 and
xmm1 using imm8 as
comparison predicate.
VEX.NDS.LIG.F3.0F.WIG C2 /r ib
VCMPSS xmm1, xmm2, xmm3/m32,
imm8
B V/V AVX Compare low single
precision floating-point
value in xmm3/m32 and
xmm2 using bits 4:0 of
imm8 as comparison
predicate.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) imm8 NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

Vol. 2A 3-187
INSTRUCTION SET REFERENCE, A-M
CMPSS—Compare Scalar Single-Precision Floating-Point Values
relations” predicates. These comparisons can be made either by using the inverse
relationship (that is, use the “not-less-than-or-equal” to make a “greater-than”
comparison) or by using software emulation. When using software emulation, the
program must swap the operands (copying registers when necessary to protect the
data that will now be in the destination operand), and then perform the compare
using a different predicate. The predicate to be used for these emulations is listed in
Table 3-7 under the heading Emulation.
Compilers and assemblers may implement the following two-operand pseudo-ops in
addition to the three-operand CMPSS instruction, for processors with
“CPUID.1H:ECX.AVX =0”. See Table 3-15. Compiler should treat reserved Imm8
values as illegal syntax.
The greater-than relations not implemented in the processor require more than one
instruction to emulate in software and therefore should not be implemented as
pseudo-ops. (For these, the programmer should reverse the operands of the corre-
sponding less than relations and use move instructions to ensure that the mask is
moved to the correct destination register and that the source operand is left intact.)
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
Enhanced Comparison Predicate for VEX-Encoded VCMPSD
VEX.128 encoded version: The first source operand (second operand) is an XMM
register. The second source operand (third operand) can be an XMM register or a 32-
bit memory location. Bits (VLMAX-1:128) of the destination YMM register are zeroed.
The comparison predicate operand is an 8-bit immediate:
•For instructions encoded using the VEX prefix, bits 4:0 define the type of
comparison to be performed (see Table 3-9). Bits 5 through 7 of the immediate
are reserved.
Processors with “CPUID.1H:ECX.AVX =1” implement the full complement of 32 pred-
icates shown in Table 3-9, software emulation is no longer needed. Compilers and
Table 3-15. Pseudo-Ops and CMPSS
Pseudo-Op CMPSS Implementation
CMPEQSS xmm1, xmm2 CMPSS xmm1, xmm2, 0
CMPLTSS xmm1, xmm2 CMPSS xmm1, xmm2, 1
CMPLESS xmm1, xmm2 CMPSS xmm1, xmm2, 2
CMPUNORDSS xmm1, xmm2 CMPSS xmm1, xmm2, 3
CMPNEQSS xmm1, xmm2 CMPSS xmm1, xmm2, 4
CMPNLTSS xmm1, xmm2 CMPSS xmm1, xmm2, 5
CMPNLESS xmm1, xmm2 CMPSS xmm1, xmm2, 6
CMPORDSS xmm1, xmm2 CMPSS xmm1, xmm2, 7

3-188 Vol. 2A CMPSS—Compare Scalar Single-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
assemblers may implement the following three-operand pseudo-ops in addition to
the four-operand VCMPSS instruction. See Table 3-16, where the notations of reg1
reg2, and reg3 represent either XMM registers or YMM registers. Compiler should
treat reserved Imm8 values as illegal syntax. Alternately, intrinsics can map the
pseudo-ops to pre-defined constants to support a simpler intrinsic interface.
:Table 3-16. Pseudo-Op and VCMPSS Implementation
Pseudo-Op CMPSS Implementation
VCMPEQSS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 0
VCMPLTSS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 1
VCMPLESS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 2
VCMPUNORDSS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 3
VCMPNEQSS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 4
VCMPNLTSS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 5
VCMPNLESS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 6
VCMPORDSS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 7
VCMPEQ_UQSS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 8
VCMPNGESS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 9
VCMPNGTSS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 0AH
VCMPFALSESS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 0BH
VCMPNEQ_OQSS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 0CH
VCMPGESS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 0DH
VCMPGTSS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 0EH
VCMPTRUESS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 0FH
VCMPEQ_OSSS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 10H
VCMPLT_OQSS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 11H
VCMPLE_OQSS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 12H
VCMPUNORD_SSS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 13H
VCMPNEQ_USSS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 14H
VCMPNLT_UQSS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 15H
VCMPNLE_UQSS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 16H
VCMPORD_SSS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 17H
VCMPEQ_USSS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 18H
VCMPNGE_UQSS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 19H
VCMPNGT_UQSS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 1AH
Vol. 2A 3-189
INSTRUCTION SET REFERENCE, A-M
CMPSS—Compare Scalar Single-Precision Floating-Point Values
Operation
CASE (COMPARISON PREDICATE) OF
0: OP3 EQ_OQ; OP5 EQ_OQ;
1: OP3 LT_OS; OP5 LT_OS;
2: OP3 LE_OS; OP5 LE_OS;
3: OP3 UNORD_Q; OP5 UNORD_Q;
4: OP3 NEQ_UQ; OP5 NEQ_UQ;
5: OP3 NLT_US; OP5 NLT_US;
6: OP3 NLE_US; OP5 NLE_US;
7: OP3 ORD_Q; OP5 ORD_Q;
8: OP5 EQ_UQ;
9: OP5 NGE_US;
10: OP5 NGT_US;
11: OP5 FALSE_OQ;
12: OP5 NEQ_OQ;
13: OP5 GE_OS;
14: OP5 GT_OS;
15: OP5 TRUE_UQ;
16: OP5 EQ_OS;
17: OP5 LT_OQ;
18: OP5 LE_OQ;
19: OP5 UNORD_S;
20: OP5 NEQ_US;
21: OP5 NLT_UQ;
22: OP5 NLE_UQ;
23: OP5 ORD_S;
24: OP5 EQ_US;
25: OP5 NGE_UQ;
26: OP5 NGT_UQ;
27: OP5 FALSE_OS;
28: OP5 NEQ_OS;
29: OP5 GE_OQ;
30: OP5 GT_OQ;
VCMPFALSE_OSSS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 1BH
VCMPNEQ_OSSS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 1CH
VCMPGE_OQSS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 1DH
VCMPGT_OQSS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 1EH
VCMPTRUE_USSS reg1, reg2, reg3 VCMPSS reg1, reg2, reg3, 1FH
Table 3-16. Pseudo-Op and VCMPSS Implementation
Pseudo-Op CMPSS Implementation

3-190 Vol. 2A CMPSS—Compare Scalar Single-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
31: OP5 TRUE_US;
DEFAULT: Reserved
ESAC;
CMPSS (128-bit Legacy SSE version)
CMP0 DEST[31:0] OP3 SRC[31:0];
IF CMP0 = TRUE
THEN DEST[31:0] FFFFFFFFH;
ELSE DEST[31:0] 00000000H; FI;
DEST[VLMAX-1:32] (Unmodified)
VCMPSS (VEX.128 encoded version)
CMP0 SRC1[31:0] OP5 SRC2[31:0];
IF CMP0 = TRUE
THEN DEST[31:0] FFFFFFFFH;
ELSE DEST[31:0] 00000000H; FI;
DEST[127:32] SRC1[127:32]
DEST[VLMAX-1:128] 0
Intel C/C++ Compiler Intrinsic Equivalents
CMPSS for equality__m128 _mm_cmpeq_ss(__m128 a, __m128 b)
CMPSS for less-than__m128 _mm_cmplt_ss(__m128 a, __m128 b)
CMPSS for less-than-or-equal__m128 _mm_cmple_ss(__m128 a, __m128 b)
CMPSS for greater-than__m128 _mm_cmpgt_ss(__m128 a, __m128 b)
CMPSS for greater-than-or-equal__m128 _mm_cmpge_ss(__m128 a, __m128 b)
CMPSS for inequality__m128 _mm_cmpneq_ss(__m128 a, __m128 b)
CMPSS for not-less-than__m128 _mm_cmpnlt_ss(__m128 a, __m128 b)
CMPSS for not-greater-than__m128 _mm_cmpngt_ss(__m128 a, __m128 b)
CMPSS for not-greater-than-or-equal__m128 _mm_cmpnge_ss(__m128 a, __m128 b)
CMPSS for ordered__m128 _mm_cmpord_ss(__m128 a, __m128 b)
CMPSS for unordered__m128 _mm_cmpunord_ss(__m128 a, __m128 b)
CMPSS for not-less-than-or-equal__m128 _mm_cmpnle_ss(__m128 a, __m128 b)
VCMPSS __m128 _mm_cmp_ss(__m128 a, __m128 b, const int imm)
SIMD Floating-Point Exceptions
Invalid if SNaN operand, Invalid if QNaN and predicate as listed in above table,
Denormal.

Vol. 2A 3-191
INSTRUCTION SET REFERENCE, A-M
CMPSS—Compare Scalar Single-Precision Floating-Point Values
Other Exceptions
See Exceptions Type 3.

3-192 Vol. 2A CMPXCHG—Compare and Exchange
INSTRUCTION SET REFERENCE, A-M
CMPXCHG—Compare and Exchange
Instruction Operand Encoding
Description
Compares the value in the AL, AX, EAX, or RAX register with the first operand (desti-
nation operand). If the two values are equal, the second operand (source operand) is
loaded into the destination operand. Otherwise, the destination operand is loaded
into the AL, AX, EAX or RAX register. RAX register is available only in 64-bit mode.
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F B0/rCMPXCHG r/m8, r8 A Valid Valid* Compare AL with r/m8. If
equal, ZF is set and r8 is
loaded into r/m8. Else, clear
ZF and load r/m8 into AL.
REX + 0F B0/rCMPXCHG
r/m8**,r8
A Valid N.E. Compare AL with r/m8. If
equal, ZF is set and r8 is
loaded into r/m8. Else, clear
ZF and load r/m8 into AL.
0F B1/rCMPXCHG r/m16,
r16
A Valid Valid* Compare AX with r/m16. If
equal, ZF is set and r16 is
loaded into r/m16. Else,
clear ZF and load r/m16 into
AX.
0F B1/rCMPXCHG r/m32,
r32
A Valid Valid* Compare EAX with r/m32. If
equal, ZF is set and r32 is
loaded into r/m32. Else,
clear ZF and load r/m32 into
EAX.
REX.W + 0F
B1/r
CMPXCHG r/m64,
r64
A Valid N.E. Compare RAX with r/m64. If
equal, ZF is set and r64 is
loaded into r/m64. Else,
clear ZF and load r/m64 into
RAX.
NOTES:
* See the IA-32 Architecture Compatibility section below.
** In 64-bit mode, r/m8 can not be encoded to access the following byte registers if a REX prefix is
used: AH, BH, CH, DH.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (r, w) ModRM:reg (r) NA NA

Vol. 2A 3-193
INSTRUCTION SET REFERENCE, A-M
CMPXCHG—Compare and Exchange
This instruction can be used with a LOCK prefix to allow the instruction to be
executed atomically. To simplify the interface to the processor’s bus, the destination
operand receives a write cycle without regard to the result of the comparison. The
destination operand is written back if the comparison fails; otherwise, the source
operand is written into the destination. (The processor never produces a locked read
without also producing a locked write.)
In 64-bit mode, the instruction’s default operation size is 32 bits. Use of the REX.R
prefix permits access to additional registers (R8-R15). Use of the REX.W prefix
promotes operation to 64 bits. See the summary chart at the beginning of this
section for encoding data and limits.
IA-32 Architecture Compatibility
This instruction is not supported on Intel processors earlier than the Intel486 proces-
sors.
Operation
(* Accumulator = AL, AX, EAX, or RAX depending on whether a byte, word, doubleword, or
quadword comparison is being performed *)
IF accumulator = DEST
THEN
ZF ← 1;
DEST ← SRC;
ELSE
ZF ← 0;
accumulator ← DEST;
FI;
Flags Affected
The ZF flag is set if the values in the destination operand and register AL, AX, or EAX
are equal; otherwise it is cleared. The CF, PF, AF, SF, and OF flags are set according to
the results of the comparison operation.
Protected Mode Exceptions
#GP(0) If the destination is located in a non-writable segment.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.

3-194 Vol. 2A CMPXCHG—Compare and Exchange
INSTRUCTION SET REFERENCE, A-M
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used but the destination is not a memory
operand.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#UD If the LOCK prefix is used but the destination is not a memory
operand.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used but the destination is not a memory
operand.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used but the destination is not a memory
operand.

Vol. 2A 3-195
INSTRUCTION SET REFERENCE, A-M
CMPXCHG8B/CMPXCHG16B—Compare and Exchange Bytes
CMPXCHG8B/CMPXCHG16B—Compare and Exchange Bytes
Instruction Operand Encoding
Description
Compares the 64-bit value in EDX:EAX (or 128-bit value in RDX:RAX if operand size
is 128 bits) with the operand (destination operand). If the values are equal, the
64-bit value in ECX:EBX (or 128-bit value in RCX:RBX) is stored in the destination
operand. Otherwise, the value in the destination operand is loaded into EDX:EAX (or
RDX:RAX). The destination operand is an 8-byte memory location (or 16-byte
memory location if operand size is 128 bits). For the EDX:EAX and ECX:EBX register
pairs, EDX and ECX contain the high-order 32 bits and EAX and EBX contain the low-
order 32 bits of a 64-bit value. For the RDX:RAX and RCX:RBX register pairs, RDX
and RCX contain the high-order 64 bits and RAX and RBX contain the low-order
64bits of a 128-bit value.
This instruction can be used with a LOCK prefix to allow the instruction to be
executed atomically. To simplify the interface to the processor’s bus, the destination
operand receives a write cycle without regard to the result of the comparison. The
destination operand is written back if the comparison fails; otherwise, the source
operand is written into the destination. (The processor never produces a locked read
without also producing a locked write.)
In 64-bit mode, default operation size is 64 bits. Use of the REX.W prefix promotes
operation to 128 bits. Note that CMPXCHG16B requires that the destination
(memory) operand be 16-byte aligned. See the summary chart at the beginning of
this section for encoding data and limits. For information on the CPUID flag that indi-
cates CMPXCHG16B, see page 3-216.
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F C7 /1 m64 CMPXCHG8B m64 A Valid Valid* Compare EDX:EAX with
m64. If equal, set ZF and
load ECX:EBX into m64. Else,
clear ZF and load m64 into
EDX:EAX.
REX.W + 0F C7
/1 m128
CMPXCHG16B
m128
A Valid N.E. Compare RDX:RAX with
m128. If equal, set ZF and
load RCX:RBX into m128.
Else, clear ZF and load m128
into RDX:RAX.
NOTES:
*See IA-32 Architecture Compatibility section below.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (r, w) NA NA NA

3-196 Vol. 2A CMPXCHG8B/CMPXCHG16B—Compare and Exchange Bytes
INSTRUCTION SET REFERENCE, A-M
IA-32 Architecture Compatibility
This instruction encoding is not supported on Intel processors earlier than the
Pentium processors.
Operation
IF (64-Bit Mode and OperandSize = 64)
THEN
IF (RDX:RAX = DEST)
ZF ← 1;
DEST ← RCX:RBX;
ELSE
ZF ← 0;
RDX:RAX ← DEST;
FI
ELSE
IF (EDX:EAX = DEST)
ZF ← 1;
DEST ← ECX:EBX;
ELSE
ZF ← 0;
EDX:EAX ← DEST;
FI;
FI;
Flags Affected
The ZF flag is set if the destination operand and EDX:EAX are equal; otherwise it is
cleared. The CF, PF, AF, SF, and OF flags are unaffected.
Protected Mode Exceptions
#UD If the destination is not a memory operand.
#GP(0) If the destination is located in a non-writable segment.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.

Vol. 2A 3-197
INSTRUCTION SET REFERENCE, A-M
CMPXCHG8B/CMPXCHG16B—Compare and Exchange Bytes
Real-Address Mode Exceptions
#UD If the destination operand is not a memory location.
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
Virtual-8086 Mode Exceptions
#UD If the destination operand is not a memory location.
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
If memory operand for CMPXCHG16B is not aligned on a 16-byte
boundary.
If CPUID.01H:ECX.CMPXCHG16B[bit 13] = 0.
#UD If the destination operand is not a memory location.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
3-198 Vol. 2A COMISD—Compare Scalar Ordered Double-Precision Floating-Point Values and Set
EFLAGS
INSTRUCTION SET REFERENCE, A-M
COMISD—Compare Scalar Ordered Double-Precision Floating-Point
Values and Set EFLAGS
Instruction Operand Encoding
Description
Compares the double-precision floating-point values in the low quadwords of
operand 1 (first operand) and operand 2 (second operand), and sets the ZF, PF, and
CF flags in the EFLAGS register according to the result (unordered, greater than, less
than, or equal). The OF, SF and AF flags in the EFLAGS register are set to 0. The unor-
dered result is returned if either source operand is a NaN (QNaN or SNaN).
Operand 1 is an XMM register; operand 2 can be an XMM register or a 64 bit memory
location.
The COMISD instruction differs from the UCOMISD instruction in that it signals a
SIMD floating-point invalid operation exception (#I) when a source operand is either
a QNaN or SNaN. The UCOMISD instruction signals an invalid numeric exception only
if a source operand is an SNaN.
The EFLAGS register is not updated if an unmasked SIMD floating-point exception is
generated.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
Note: In VEX-encoded versions, VEX.vvvv is reserved and must be 1111b, otherwise
instructions will #UD.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 2F /r
COMISD xmm1, xmm2/m64
A V/V SSE2 Compare low double-
precision floating-point
values in xmm1 and
xmm2/mem64 and set the
EFLAGS flags accordingly.
VEX.LIG.66.0F.WIG 2F /r
VCOMISD xmm1, xmm2/m64
AV/V AVX Compare low double
precision floating-point
values in xmm1 and
xmm2/mem64 and set the
EFLAGS flags accordingly.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r) ModRM:r/m (r) NA NA

Vol. 2A 3-199
INSTRUCTION SET REFERENCE, A-M
COMISD—Compare Scalar Ordered Double-Precision Floating-Point Values and Set
EFLAGS
Operation
RESULT ← OrderedCompare(DEST[63:0] <> SRC[63:0]) {
(* Set EFLAGS *) CASE (RESULT) OF
UNORDERED: ZF,PF,CF ← 111;
GREATER_THAN: ZF,PF,CF ← 000;
LESS_THAN: ZF,PF,CF ← 001;
EQUAL: ZF,PF,CF ← 100;
ESAC;
OF, AF, SF ← 0; }
Intel C/C++ Compiler Intrinsic Equivalents
int _mm_comieq_sd (__m128d a, __m128d b)
int _mm_comilt_sd (__m128d a, __m128d b)
int _mm_comile_sd (__m128d a, __m128d b)
int _mm_comigt_sd (__m128d a, __m128d b)
int _mm_comige_sd (__m128d a, __m128d b)
int _mm_comineq_sd (__m128d a, __m128d b)
SIMD Floating-Point Exceptions
Invalid (if SNaN or QNaN operands), Denormal.
Other Exceptions
See Exceptions Type 3; additionally
#UD If VEX.vvvv != 1111B.
3-200 Vol. 2A COMISS—Compare Scalar Ordered Single-Precision Floating-Point Values and Set EFLAGS
INSTRUCTION SET REFERENCE, A-M
COMISS—Compare Scalar Ordered Single-Precision Floating-Point
Values and Set EFLAGS
Instruction Operand Encoding
Description
Compares the single-precision floating-point values in the low doublewords of
operand 1 (first operand) and operand 2 (second operand), and sets the ZF, PF, and
CF flags in the EFLAGS register according to the result (unordered, greater than, less
than, or equal). The OF, SF, and AF flags in the EFLAGS register are set to 0. The
unordered result is returned if either source operand is a NaN (QNaN or SNaN).
Operand 1 is an XMM register; Operand 2 can be an XMM register or a 32 bit memory
location.
The COMISS instruction differs from the UCOMISS instruction in that it signals a
SIMD floating-point invalid operation exception (#I) when a source operand is either
a QNaN or SNaN. The UCOMISS instruction signals an invalid numeric exception only
if a source operand is an SNaN.
The EFLAGS register is not updated if an unmasked SIMD floating-point exception is
generated.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
Note: In VEX-encoded versions, VEX.vvvv is reserved and must be 1111b, otherwise
instructions will #UD.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
0F 2F /r
COMISS xmm1, xmm2/m32
A V/V SSE Compare low single-
precision floating-point
values in xmm1 and
xmm2/mem32 and set the
EFLAGS flags accordingly.
VEX.LIG.0F 2F.WIG /r
VCOMISS xmm1, xmm2/m32
A V/V AVX Compare low single
precision floating-point
values in xmm1 and
xmm2/mem32 and set the
EFLAGS flags accordingly.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r) ModRM:r/m (r) NA NA

Vol. 2A 3-201
INSTRUCTION SET REFERENCE, A-M
COMISS—Compare Scalar Ordered Single-Precision Floating-Point Values and Set EFLAGS
Operation
RESULT ← OrderedCompare(SRC1[31:0] <> SRC2[31:0]) {
(* Set EFLAGS *) CASE (RESULT) OF
UNORDERED: ZF,PF,CF ← 111;
GREATER_THAN: ZF,PF,CF ← 000;
LESS_THAN: ZF,PF,CF ← 001;
EQUAL: ZF,PF,CF ← 100;
ESAC;
OF,AF,SF ← 0; }
Intel C/C++ Compiler Intrinsic Equivalents
int _mm_comieq_ss (__m128 a, __m128 b)
int _mm_comilt_ss (__m128 a, __m128 b)
int _mm_comile_ss (__m128 a, __m128 b)
int _mm_comigt_ss (__m128 a, __m128 b)
int _mm_comige_ss (__m128 a, __m128 b)
int _mm_comineq_ss (__m128 a, __m128 b)
SIMD Floating-Point Exceptions
Invalid (if SNaN or QNaN operands), Denormal.
Other Exceptions
See Exceptions Type 3; additionally
#UD If VEX.vvvv != 1111B.

3-202 Vol. 2A CPUID—CPU Identification
INSTRUCTION SET REFERENCE, A-M
CPUID—CPU Identification
Instruction Operand Encoding
Description
The ID flag (bit 21) in the EFLAGS register indicates support for the CPUID instruc-
tion. If a software procedure can set and clear this flag, the processor executing the
procedure supports the CPUID instruction. This instruction operates the same in non-
64-bit modes and 64-bit mode.
CPUID returns processor identification and feature information in the EAX, EBX, ECX,
and EDX registers.1 The instruction’s output is dependent on the contents of the EAX
register upon execution (in some cases, ECX as well). For example, the following
pseudocode loads EAX with 00H and causes CPUID to return a Maximum Return
Value and the Vendor Identification String in the appropriate registers:
MOV EAX, 00H
CPUID
Table 3-17 shows information returned, depending on the initial value loaded into the
EAX register. Table 3-18 shows the maximum CPUID input value recognized for each
family of IA-32 processors on which CPUID is implemented.
Two types of information are returned: basic and extended function information. If a
value entered for CPUID.EAX is higher than the maximum input value for basic or
extended function for that processor then the data for the highest basic information
leaf is returned. For example, using the Intel Core i7 processor, the following is true:
CPUID.EAX = 05H (* Returns MONITOR/MWAIT leaf. *)
CPUID.EAX = 0AH (* Returns Architectural Performance Monitoring leaf. *)
CPUID.EAX = 0BH (* Returns Extended Topology Enumeration leaf. *)
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F A2 CPUID A Valid Valid Returns processor
identification and feature
information to the EAX,
EBX, ECX, and EDX
registers, as determined by
input entered in EAX (in
some cases, ECX as well).
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA
1. On Intel 64 processors, CPUID clears the high 32 bits of the RAX/RBX/RCX/RDX registers in all
modes.

Vol. 2A 3-203
INSTRUCTION SET REFERENCE, A-M
CPUID—CPU Identification
CPUID.EAX = 0CH (* INVALID: Returns the same information as CPUID.EAX = 0BH. *)
CPUID.EAX = 80000008H (* Returns linear/physical address size data. *)
CPUID.EAX = 8000000AH (* INVALID: Returns same information as CPUID.EAX = 0BH. *)
If a value entered for CPUID.EAX is less than or equal to the maximum input value
and the leaf is not supported on that processor then 0 is returned in all the registers.
For example, using the Intel Core i7 processor, the following is true:
CPUID.EAX = 07H (*Returns EAX=EBX=ECX=EDX=0. *)
When CPUID returns the highest basic leaf information as a result of an invalid input
EAX value, any dependence on input ECX value in the basic leaf is honored.
CPUID can be executed at any privilege level to serialize instruction execution. Seri-
alizing instruction execution guarantees that any modifications to flags, registers,
and memory for previous instructions are completed before the next instruction is
fetched and executed.
See also:
“Serializing Instructions” in Chapter 8, “Multiple-Processor Management,” in the
Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 3A
“Caching Translation Information” in Chapter 4, “Paging,” in the Intel® 64 and IA-32
Architectures Software Developer’s Manual, Volume 3A.
Table 3-17. Information Returned by CPUID Instruction
Initial EAX
Value Information Provided about the Processor
Basic CPUID Information
0H EAX
EBX
ECX
EDX
Maximum Input Value for Basic CPUID Information (see Table 3-18)
“Genu”
“ntel”
“ineI”
01H EAX
EBX
ECX
EDX
Version Information: Type, Family, Model, and Stepping ID (see
Figure 3-9)
Bits 07-00: Brand Index
Bits 15-08: CLFLUSH line size (Value ∗ 8 = cache line size in bytes)
Bits 23-16: Maximum number of addressable IDs for logical processors
in this physical package*.
Bits 31-24: Initial APIC ID
Feature Information (see Figure 3-10 and Table 3-20)
Feature Information (see Figure 3-11 and Table 3-21)
NOTES:
* The nearest power-of-2 integer that is not smaller than EBX[23:16]
is the number of unique initial APIC IDs reserved for addressing dif-
ferent logical processors in a physical package.
3-204 Vol. 2A CPUID—CPU Identification
INSTRUCTION SET REFERENCE, A-M
02H EAX
EBX
ECX
EDX
Cache and TLB Information (see Table 3-22)
Cache and TLB Information
Cache and TLB Information
Cache and TLB Information
03H EAX
EBX
ECX
EDX
Reserved.
Reserved.
Bits 00-31 of 96 bit processor serial number. (Available in Pentium III
processor only; otherwise, the value in this register is reserved.)
Bits 32-63 of 96 bit processor serial number. (Available in Pentium III
processor only; otherwise, the value in this register is reserved.)
NOTES:
Processor serial number (PSN) is not supported in the Pentium 4 pro-
cessor or later. On all models, use the PSN flag (returned using
CPUID) to check for PSN support before accessing the feature.
See AP-485, Intel Processor Identification and the CPUID Instruc-
tion (Order Number 241618) for more information on PSN.
CPUID leaves > 3 < 80000000 are visible only when
IA32_MISC_ENABLE.BOOT_NT4[bit 22] = 0 (default).
Deterministic Cache Parameters Leaf
04H NOTES:
Leaf 04H output depends on the initial value in ECX.
See also: “INPUT EAX = 4: Returns Deterministic Cache Parameters
for each level on page 3-227.
EAX Bits 04-00: Cache Type Field
0 = Null - No more caches
1 = Data Cache
2 = Instruction Cache
3 = Unified Cache
4-31 = Reserved
Bits 07-05: Cache Level (starts at 1)
Bit 08: Self Initializing cache level (does not need SW initialization)
Bit 09: Fully Associative cache
Bits 13-10: Reserved
Bits 25-14: Maximum number of addressable IDs for logical processors
sharing this cache*, **
Bits 31-26: Maximum number of addressable IDs for processor cores in
the physical package*, ***, ****
Table 3-17. Information Returned by CPUID Instruction (Contd.)
Initial EAX
Value Information Provided about the Processor

Vol. 2A 3-205
INSTRUCTION SET REFERENCE, A-M
CPUID—CPU Identification
EBX Bits 11-00: L = System Coherency Line Size*
Bits 21-12: P = Physical Line partitions*
Bits 31-22: W = Ways of associativity*
ECX Bits 31-00: S = Number of Sets*
EDX Bit 0: Write-Back Invalidate/Invalidate
0 = WBINVD/INVD from threads sharing this cache acts upon lower
level caches for threads sharing this cache.
1 = WBINVD/INVD is not guaranteed to act upon lower level caches
of non-originating threads sharing this cache.
Bit 1: Cache Inclusiveness
0 = Cache is not inclusive of lower cache levels.
1 = Cache is inclusive of lower cache levels.
Bit 2: Complex Cache Indexing
0 = Direct mapped cache.
1 = A complex function is used to index the cache, potentially using
all address bits.
Bits 31-03: Reserved = 0
NOTES:
* Add one to the return value to get the result.
** The nearest power-of-2 integer that is not smaller than (1 +
EAX[25:14]) is the number of unique initial APIC IDs reserved for
addressing different logical processors sharing this cache
*** The nearest power-of-2 integer that is not smaller than (1 +
EAX[31:26]) is the number of unique Core_IDs reserved for address-
ing different processor cores in a physical package. Core ID is a sub-
set of bits of the initial APIC ID.
****The returned value is constant for valid initial values in ECX. Valid
ECX values start from 0.
MONITOR/MWAIT Leaf
05H EAX Bits 15-00: Smallest monitor-line size in bytes (default is processor's
monitor granularity)
Bits 31-16: Reserved = 0
EBX Bits 15-00: Largest monitor-line size in bytes (default is processor's
monitor granularity)
Bits 31-16: Reserved = 0
Table 3-17. Information Returned by CPUID Instruction (Contd.)
Initial EAX
Value Information Provided about the Processor

3-206 Vol. 2A CPUID—CPU Identification
INSTRUCTION SET REFERENCE, A-M
ECX Bit 00: Enumeration of Monitor-Mwait extensions (beyond EAX and
EBX registers) supported
Bit 01: Supports treating interrupts as break-event for MWAIT, even
when interrupts disabled
Bits 31 - 02: Reserved
EDX Bits 03 - 00: Number of C0* sub C-states supported using MWAIT
Bits 07 - 04: Number of C1* sub C-states supported using MWAIT
Bits 11 - 08: Number of C2* sub C-states supported using MWAIT
Bits 15 - 12: Number of C3* sub C-states supported using MWAIT
Bits 19 - 16: Number of C4* sub C-states supported using MWAIT
Bits 31 - 20: Reserved = 0
NOTE:
* The definition of C0 through C4 states for MWAIT extension are pro-
cessor-specific C-states, not ACPI C-states.
Thermal and Power Management Leaf
06H EAX
EBX
Bit 00: Digital temperature sensor is supported if set
Bit 01: Intel Turbo Boost Technology Available (see description of
IA32_MISC_ENABLE[38]).
Bit 02: ARAT. APIC-Timer-always-running feature is supported if set.
Bit 03: Reserved
Bit 04: PLN. Power limit notification controls are supported if set.
Bit 05: ECMD. Clock modulation duty cycle extension is supported if set.
Bit 06: PTM. Package thermal management is supported if set.
Bits 31 - 07: Reserved
Bits 03 - 00: Number of Interrupt Thresholds in Digital Thermal Sensor
Bits 31 - 04: Reserved
ECX Bit 00: Hardware Coordination Feedback Capability (Presence of
IA32_MPERF and IA32_APERF). The capability to provide a measure of
delivered processor performance (since last reset of the counters), as
a percentage of expected processor performance at frequency speci-
fied in CPUID Brand String
Bits 02 - 01: Reserved = 0
Bit 03: The processor supports performance-energy bias preference if
CPUID.06H:ECX.SETBH[bit 3] is set and it also implies the presence of a
new architectural MSR called IA32_ENERGY_PERF_BIAS (1B0H)
Bits 31 - 04: Reserved = 0
EDX Reserved = 0
Direct Cache Access Information Leaf
Table 3-17. Information Returned by CPUID Instruction (Contd.)
Initial EAX
Value Information Provided about the Processor

Vol. 2A 3-207
INSTRUCTION SET REFERENCE, A-M
CPUID—CPU Identification
09H EAX
EBX
ECX
EDX
Value of bits [31:0] of IA32_PLATFORM_DCA_CAP MSR (address
1F8H)
Reserved
Reserved
Reserved
Architectural Performance Monitoring Leaf
0AH EAX Bits 07 - 00: Version ID of architectural performance monitoring
Bits 15- 08: Number of general-purpose performance monitoring
counter per logical processor
Bits 23 - 16: Bit width of general-purpose, performance monitoring
counter
Bits 31 - 24: Length of EBX bit vector to enumerate architectural per-
formance monitoring events
EBX Bit 00: Core cycle event not available if 1
Bit 01: Instruction retired event not available if 1
Bit 02: Reference cycles event not available if 1
Bit 03: Last-level cache reference event not available if 1
Bit 04: Last-level cache misses event not available if 1
Bit 05: Branch instruction retired event not available if 1
Bit 06: Branch mispredict retired event not available if 1
Bits 31- 07: Reserved = 0
ECX Reserved = 0
EDX Bits 04 - 00: Number of fixed-function performance counters (if Ver-
sion ID > 1)
Bits 12- 05: Bit width of fixed-function performance counters (if Ver-
sion ID > 1)
Reserved = 0
Extended Topology Enumeration Leaf
0BH NOTES:
Most of Leaf 0BH output depends on the initial value in ECX.
EDX output do not vary with initial value in ECX.
ECX[7:0] output always reflect initial value in ECX.
All other output value for an invalid initial value in ECX are 0.
Leaf 0BH exists if EBX[15:0] is not zero.
Table 3-17. Information Returned by CPUID Instruction (Contd.)
Initial EAX
Value Information Provided about the Processor

3-208 Vol. 2A CPUID—CPU Identification
INSTRUCTION SET REFERENCE, A-M
EAX Bits 04-00: Number of bits to shift right on x2APIC ID to get a unique
topology ID of the next level type*. All logical processors with the
same next level ID share current level.
Bits 31-05: Reserved.
EBX Bits 15 - 00: Number of logical processors at this level type. The num-
ber reflects configuration as shipped by Intel**.
Bits 31- 16: Reserved.
ECX Bits 07 - 00: Level number. Same value in ECX input
Bits 15 - 08: Level type***.
Bits 31 - 16:: Reserved.
EDX Bits 31- 00: x2APIC ID the current logical processor.
NOTES:
* Software should use this field (EAX[4:0]) to enumerate processor
topology of the system.
** Software must not use EBX[15:0] to enumerate processor topology
of the system. This value in this field (EBX[15:0]) is only intended for
display/diagnostic purposes. The actual number of logical processors
available to BIOS/OS/Applications may be different from the value of
EBX[15:0], depending on software and platform hardware configura-
tions.
*** The value of the “level type” field is not related to level numbers in
any way, higher “level type” values do not mean higher levels. Level
type field has the following encoding:
0 : invalid
1 : SMT
2 : Core
3-255 : Reserved
Processor Extended State Enumeration Main Leaf (EAX = 0DH, ECX = 0)
0DH NOTES:
Leaf 0DH main leaf (ECX = 0).
EAX Bits 31-00: Reports the valid bit fields of the lower 32 bits of XCR0. If
a bit is 0, the corresponding bit field in XCR0 is reserved.
EBX Bits 31-00: Maximum size (bytes, from the beginning of the
XSAVE/XRSTOR save area) required by enabled features in XCR0. May
be different than ECX if some features at the end of the XSAVE save
area are not enabled.
Table 3-17. Information Returned by CPUID Instruction (Contd.)
Initial EAX
Value Information Provided about the Processor

Vol. 2A 3-209
INSTRUCTION SET REFERENCE, A-M
CPUID—CPU Identification
ECX Bit 31-00: Maximum size (bytes, from the beginning of the
XSAVE/XRSTOR save area) of the XSAVE/XRSTOR save area required
by all supported features in the processor, i.e all the valid bit fields in
XCR0.
EDX Bit 31-00: Reports the valid bit fields of the upper 32 bits of XCR0. If a
bit is 0, the corresponding bit field in XCR0 is reserved.
Processor Extended State Enumeration Sub-leaf (EAX = 0DH, ECX = 1)
EAX
EBX
ECX
EDX
Reserved
Reserved
Reserved
Reserved
Processor Extended State Enumeration Sub-leaves (EAX = 0DH, ECX = n, n > 1)
0DH NOTES:
Leaf 0DH output depends on the initial value in ECX.
If ECX contains an invalid sub leaf index, EAX/EBX/ECX/EDX return 0.
Each valid sub-leaf index maps to a valid bit in the XCR0 register
starting at bit position 2
EAX Bits 31-0: The size in bytes (from the offset specified in EBX) of the
save area for an extended state feature associated with a valid sub-
leaf index, n. This field reports 0 if the sub-leaf index, n, is invalid*.
EBX Bits 31-0: The offset in bytes of this extended state component’s save
area from the beginning of the XSAVE/XRSTOR area.
This field reports 0 if the sub-leaf index, n, is invalid*.
ECX This field reports 0 if the sub-leaf index, n, is invalid*; otherwise it is
reserved.
EDX This field reports 0 if the sub-leaf index, n, is invalid*; otherwise it is
reserved.
Unimplemented CPUID Leaf Functions
40000000H
-
4FFFFFFFH
Invalid. No existing or future CPU will return processor identification or
feature information if the initial EAX value is in the range 40000000H
to 4FFFFFFFH.
Extended Function CPUID Information
80000000H EAX Maximum Input Value for Extended Function CPUID Information (see
Table 3-18).
Table 3-17. Information Returned by CPUID Instruction (Contd.)
Initial EAX
Value Information Provided about the Processor

3-210 Vol. 2A CPUID—CPU Identification
INSTRUCTION SET REFERENCE, A-M
EBX
ECX
EDX
Reserved
Reserved
Reserved
80000001H EAX
EBX
ECX
Extended Processor Signature and Feature Bits.
Reserved
Bit 00: LAHF/SAHF available in 64-bit mode
Bits 31-01 Reserved
EDX Bits 10-00: Reserved
Bit 11: SYSCALL/SYSRET available (when in 64-bit mode)
Bits 19-12: Reserved = 0
Bit 20: Execute Disable Bit available
Bits 25-21: Reserved = 0
Bit 26: 1-GByte pages are available if 1
Bit 27: RDTSCP and IA32_TSC_AUX are available if 1
Bits 28: Reserved = 0
Bit 29: Intel® 64 Architecture available if 1
Bits 31-30: Reserved = 0
80000002H EAX
EBX
ECX
EDX
Processor Brand String
Processor Brand String Continued
Processor Brand String Continued
Processor Brand String Continued
80000003H EAX
EBX
ECX
EDX
Processor Brand String Continued
Processor Brand String Continued
Processor Brand String Continued
Processor Brand String Continued
80000004H EAX
EBX
ECX
EDX
Processor Brand String Continued
Processor Brand String Continued
Processor Brand String Continued
Processor Brand String Continued
80000005H EAX
EBX
ECX
EDX
Reserved = 0
Reserved = 0
Reserved = 0
Reserved = 0
80000006H EAX
EBX
Reserved = 0
Reserved = 0
Table 3-17. Information Returned by CPUID Instruction (Contd.)
Initial EAX
Value Information Provided about the Processor

Vol. 2A 3-211
INSTRUCTION SET REFERENCE, A-M
CPUID—CPU Identification
INPUT EAX = 0: Returns CPUID’s Highest Value for Basic Processor Information and
the Vendor Identification String
When CPUID executes with EAX set to 0, the processor returns the highest value the
CPUID recognizes for returning basic processor information. The value is returned in
the EAX register (see Table 3-18) and is processor specific.
A vendor identification string is also returned in EBX, EDX, and ECX. For Intel
processors, the string is “GenuineIntel” and is expressed:
ECX
EDX
Bits 07-00: Cache Line size in bytes
Bits 11-08: Reserved
Bits 15-12: L2 Associativity field *
Bits 31-16: Cache size in 1K units
Reserved = 0
NOTES:
* L2 associativity field encodings:
00H - Disabled
01H - Direct mapped
02H - 2-way
04H - 4-way
06H - 8-way
08H - 16-way
0FH - Fully associative
80000007H EAX
EBX
ECX
EDX
Reserved = 0
Reserved = 0
Reserved = 0
Bits 07-00: Reserved = 0
Bit 08: Invariant TSC available if 1
Bits 31-09: Reserved = 0
80000008H EAX Linear/Physical Address size
Bits 07-00: #Physical Address Bits*
Bits 15-8: #Linear Address Bits
Bits 31-16: Reserved = 0
EBX
ECX
EDX
Reserved = 0
Reserved = 0
Reserved = 0
NOTES:
* If CPUID.80000008H:EAX[7:0] is supported, the maximum physical
address number supported should come from this field.
Table 3-17. Information Returned by CPUID Instruction (Contd.)
Initial EAX
Value Information Provided about the Processor
3-212 Vol. 2A CPUID—CPU Identification
INSTRUCTION SET REFERENCE, A-M
EBX ← 756e6547h (* "Genu", with G in the low eight bits of BL *)
EDX ← 49656e69h (* "ineI", with i in the low eight bits of DL *)
ECX ← 6c65746eh (* "ntel", with n in the low eight bits of CL *)
INPUT EAX = 80000000H: Returns CPUID’s Highest Value for Extended Processor
Information
When CPUID executes with EAX set to 80000000H, the processor returns the highest
value the processor recognizes for returning extended processor information. The
value is returned in the EAX register (see Table 3-18) and is processor specific.
Table 3-18. Highest CPUID Source Operand for Intel 64 and IA-32 Processors
Intel 64 or IA-32 Processors
Highest Value in EAX
Basic Information Extended Function
Information
Earlier Intel486 Processors CPUID Not Implemented CPUID Not Implemented
Later Intel486 Processors and
Pentium Processors
01H Not Implemented
Pentium Pro and Pentium II
Processors, Intel® Celeron®
Processors
02H Not Implemented
Pentium III Processors 03H Not Implemented
Pentium 4 Processors 02H 80000004H
Intel Xeon Processors 02H 80000004H
Pentium M Processor 02H 80000004H
Pentium 4 Processor
supporting Hyper-Threading
Technology
05H 80000008H
Pentium D Processor (8xx) 05H 80000008H
Pentium D Processor (9xx) 06H 80000008H
Intel Core Duo Processor 0AH 80000008H
Intel Core 2 Duo Processor 0AH 80000008H
Intel Xeon Processor 3000,
5100, 5200, 5300, 5400
Series
0AH 80000008H
Intel Core 2 Duo Processor
8000 Series
0DH 80000008H
Intel Xeon Processor 5200,
5400 Series
0AH 80000008H
Vol. 2A 3-213
INSTRUCTION SET REFERENCE, A-M
CPUID—CPU Identification
IA32_BIOS_SIGN_ID Returns Microcode Update Signature
For processors that support the microcode update facility, the IA32_BIOS_SIGN_ID
MSR is loaded with the update signature whenever CPUID executes. The signature is
returned in the upper DWORD. For details, see Chapter 9 in the Intel® 64 and IA-32
Architectures Software Developer’s Manual, Volume 3A.
INPUT EAX = 1: Returns Model, Family, Stepping Information
When CPUID executes with EAX set to 1, version information is returned in EAX (see
Figure 3-9). For example: model, family, and processor type for the Intel Xeon
processor 5100 series is as follows:
•Model — 1111B
•Family — 0101B
•Processor Type — 00B
See Table 3-19 for available processor type values. Stepping IDs are provided as
needed.
Intel Atom Processor 0AH 80000008H
Intel Core i7 Processor 0BH 80000008H
Figure 3-9. Version Information Returned by CPUID in EAX
Table 3-18. Highest CPUID Source Operand for Intel 64 and IA-32 Processors
Intel 64 or IA-32 Processors
Highest Value in EAX
Basic Information Extended Function
Information
OM16525
Processor Type
034781112131415161920272831
EAX
Family (0FH for the Pentium 4 Processor Family)
Model
Extended
Family ID
Extended
Model ID
Family
ID Model Stepping
ID
Extended Family ID (0)
Extended Model ID (0)
Reserved

3-214 Vol. 2A CPUID—CPU Identification
INSTRUCTION SET REFERENCE, A-M
NOTE
See Chapter 14 in the Intel® 64 and IA-32 Architectures Software
Developer’s Manual, Volume 1, for information on identifying earlier
IA-32 processors.
The Extended Family ID needs to be examined only when the Family ID is 0FH. Inte-
grate the fields into a display using the following rule:
IF Family_ID ≠ 0FH
THEN DisplayFamily = Family_ID;
ELSE DisplayFamily = Extended_Family_ID + Family_ID;
(* Right justify and zero-extend 4-bit field. *)
FI;
(* Show DisplayFamily as HEX field. *)
The Extended Model ID needs to be examined only when the Family ID is 06H or 0FH.
Integrate the field into a display using the following rule:
IF (Family_ID = 06H or Family_ID = 0FH)
THEN DisplayModel = (Extended_Model_ID « 4) + Model_ID;
(* Right justify and zero-extend 4-bit field; display Model_ID as HEX field.*)
ELSE DisplayModel = Model_ID;
FI;
(* Show DisplayModel as HEX field. *)
INPUT EAX = 1: Returns Additional Information in EBX
When CPUID executes with EAX set to 1, additional information is returned to the
EBX register:
•Brand index (low byte of EBX) — this number provides an entry into a brand
string table that contains brand strings for IA-32 processors. More information
about this field is provided later in this section.
•CLFLUSH instruction cache line size (second byte of EBX) — this number
indicates the size of the cache line flushed with CLFLUSH instruction in 8-byte
increments. This field was introduced in the Pentium 4 processor.
Table 3-19. Processor Type Field
Type Encoding
Original OEM Processor 00B
Intel OverDrive® Processor 01B
Dual processor (not applicable to Intel486
processors)
10B
Intel reserved 11B

Vol. 2A 3-215
INSTRUCTION SET REFERENCE, A-M
CPUID—CPU Identification
•Local APIC ID (high byte of EBX) — this number is the 8-bit ID that is assigned to
the local APIC on the processor during power up. This field was introduced in the
Pentium 4 processor.
INPUT EAX = 1: Returns Feature Information in ECX and EDX
When CPUID executes with EAX set to 1, feature information is returned in ECX and
EDX.
•Figure 3-10 and Table 3-20 show encodings for ECX.
•Figure 3-11 and Table 3-21 show encodings for EDX.
For all feature flags, a 1 indicates that the feature is supported. Use Intel to properly
interpret feature flags.
NOTE
Software must confirm that a processor feature is present using
feature flags returned by CPUID prior to using the feature. Software
should not depend on future offerings retaining all features.
3-216 Vol. 2A CPUID—CPU Identification
INSTRUCTION SET REFERENCE, A-M
Figure 3-10. Feature Information Returned in the ECX Register
Table 3-20. Feature Information Returned in the ECX Register
Bit # Mnemonic Description
0 SSE3 Streaming SIMD Extensions 3 (SSE3). A value of 1 indicates the
processor supports this technology.
1PCLMULQDQPCLMULQDQ. A value of 1 indicates the processor supports the
PCLMULQDQ instruction
2DTES64 64-bit DS Area. A value of 1 indicates the processor supports DS
area using 64-bit layout
3 MONITOR MONITOR/MWAIT. A value of 1 indicates the processor supports
this feature.
OM16524b
CNXT-ID — L1 Context ID
012345678910111213141516171819202122232425262728293031
ECX
TM2 — Thermal Monitor 2
EST — Enhanced Intel SpeedStep® Technology
DS-CPL — CPL Qualified Debug Store
MONITOR — MONITOR/MWAIT
PCLMULQDQ — Carryless Multiplication
Reserved
CMPXCHG16B
SMX — Safer Mode Extensions
xTPR Update Control
SSSE3 — SSSE3 Extensions
PDCM — Perf/Debug Capability MSR
VMX — Virtual Machine Extensions
SSE4_1 — SSE4.1
OSXSAVE
SSE4_2 — SSE4.2
DCA — Direct Cache Access
x2APIC
POPCNT
XSAVE
AVX
AES
FMA — Fused Multiply Add
SSE3 — SSE3 Extensions
PCID — Process-context Identifiers
0
DTES64 — 64-bit DS Area
MOVBE
TSC-Deadline

Vol. 2A 3-217
INSTRUCTION SET REFERENCE, A-M
CPUID—CPU Identification
4 DS-CPL CPL Qualified Debug Store. A value of 1 indicates the processor
supports the extensions to the Debug Store feature to allow for
branch message storage qualified by CPL.
5VMX Virtual Machine Extensions. A value of 1 indicates that the
processor supports this technology
6SMX Safer Mode Extensions. A value of 1 indicates that the
processor supports this technology. See Chapter 6, “Safer Mode
Extensions Reference”.
7 EIST Enhanced Intel SpeedStep® technology. A value of 1 indicates
that the processor supports this technology.
8 TM2 Thermal Monitor 2. A value of 1 indicates whether the processor
supports this technology.
9 SSSE3 A value of 1 indicates the presence of the Supplemental
Streaming SIMD Extensions 3 (SSSE3). A value of 0 indicates the
instruction extensions are not present in the processor
10 CNXT-ID L1 Context ID. A value of 1 indicates the L1 data cache mode can
be set to either adaptive mode or shared mode. A value of 0
indicates this feature is not supported. See definition of the
IA32_MISC_ENABLE MSR Bit 24 (L1 Data Cache Context Mode)
for details.
11 Reserved Reserved
12 FMA A value of 1 indicates the processor supports FMA extensions
using YMM state.
13 CMPXCHG16B CMPXCHG16B Available. A value of 1 indicates that the feature
is available. See the “CMPXCHG8B/CMPXCHG16B—Compare and
Exchange Bytes” section in this chapter for a description.
14 xTPR Update
Control
xTPR Update Control. A value of 1 indicates that the processor
supports changing IA32_MISC_ENABLE[bit 23].
15 PDCM Perfmon and Debug Capability: A value of 1 indicates the
processor supports the performance and debug feature indication
MSR IA32_PERF_CAPABILITIES.
16 Reserved Reserved
17 PCID Process-context identifiers. A value of 1 indicates that the
processor supports PCIDs and that software may set CR4.PCIDE
to 1.
18 DCA A value of 1 indicates the processor supports the ability to
prefetch data from a memory mapped device.
19 SSE4.1 A value of 1 indicates that the processor supports SSE4.1.
20 SSE4.2 A value of 1 indicates that the processor supports SSE4.2.
Table 3-20. Feature Information Returned in the ECX Register (Contd.)
Bit # Mnemonic Description

3-218 Vol. 2A CPUID—CPU Identification
INSTRUCTION SET REFERENCE, A-M
21 x2APIC A value of 1 indicates that the processor supports x2APIC
feature.
22 MOVBE A value of 1 indicates that the processor supports MOVBE
instruction.
23 POPCNT A value of 1 indicates that the processor supports the POPCNT
instruction.
24 TSC-Deadline A value of 1 indicates that the processor’s local APIC timer
supports one-shot operation using a TSC deadline value.
25 AESNI A value of 1 indicates that the processor supports the AESNI
instruction extensions.
26 XSAVE A value of 1 indicates that the processor supports the
XSAVE/XRSTOR processor extended states feature, the
XSETBV/XGETBV instructions, and XCR0.
27 OSXSAVE A value of 1 indicates that the OS has enabled XSETBV/XGETBV
instructions to access XCR0, and support for processor extended
state management using XSAVE/XRSTOR.
28 AVX A value of 1 indicates the processor supports the AVX instruction
extensions.
30 - 29 Reserved Reserved
31 Not Used Always returns 0
Table 3-20. Feature Information Returned in the ECX Register (Contd.)
Bit # Mnemonic Description
Vol. 2A 3-219
INSTRUCTION SET REFERENCE, A-M
CPUID—CPU Identification
Figure 3-11. Feature Information Returned in the EDX Register
20
3%(±3HQG%UN(1
(';
70±7KHUP0RQLWRU
+77±0XOWLWKUHDGLQJ
66±6HOI6QRRS
66(±66(([WHQVLRQV
66(±66(([WHQVLRQV
);65±);6$9();56725
00;±00;7HFKQRORJ\
$&3,±7KHUPDO0RQLWRUDQG&ORFN&WUO
'6±'HEXJ6WRUH
&/)6+±&)/86+LQVWUXFWLRQ
361±3URFHVVRU6HULDO1XPEHU
36(±3DJH6L]H([WHQVLRQ
3$7±3DJH$WWULEXWH7DEOH
&029±&RQGLWLRQDO0RYH&RPSDUH,QVWUXFWLRQ
0&$±0DFKLQH&KHFN$UFKLWHFWXUH
3*(±37(*OREDO%LW
0755±0HPRU\7\SH5DQJH5HJLVWHUV
6(3±6<6(17(5DQG6<6(;,7
$3,&±$3,&RQ&KLS
&;±&03;&+*%,QVW
0&(±0DFKLQH&KHFN([FHSWLRQ
3$(±3K\VLFDO$GGUHVV([WHQVLRQV
065±5'065DQG:50656XSSRUW
76&±7LPH6WDPS&RXQWHU
36(±3DJH6L]H([WHQVLRQV
'(±'HEXJJLQJ([WHQVLRQV
90(±9LUWXDO0RGH(QKDQFHPHQW
)38±[)38RQ&KLS
5HVHUYHG

3-220 Vol. 2A CPUID—CPU Identification
INSTRUCTION SET REFERENCE, A-M
Table 3-21. More on Feature Information Returned in the EDX Register
Bit # Mnemonic Description
0 FPU Floating Point Unit On-Chip. The processor contains an x87 FPU.
1 VME Virtual 8086 Mode Enhancements. Virtual 8086 mode enhancements,
including CR4.VME for controlling the feature, CR4.PVI for protected mode
virtual interrupts, software interrupt indirection, expansion of the TSS with
the software indirection bitmap, and EFLAGS.VIF and EFLAGS.VIP flags.
2 DE Debugging Extensions. Support for I/O breakpoints, including CR4.DE for
controlling the feature, and optional trapping of accesses to DR4 and DR5.
3 PSE Page Size Extension. Large pages of size 4 MByte are supported, including
CR4.PSE for controlling the feature, the defined dirty bit in PDE (Page
Directory Entries), optional reserved bit trapping in CR3, PDEs, and PTEs.
4 TSC Time Stamp Counter. The RDTSC instruction is supported, including
CR4.TSD for controlling privilege.
5 MSR Model Specific Registers RDMSR and WRMSR Instructions. The RDMSR
and WRMSR instructions are supported. Some of the MSRs are
implementation dependent.
6 PAE Physical Address Extension. Physical addresses greater than 32 bits are
supported: extended page table entry formats, an extra level in the page
translation tables is defined, 2-MByte pages are supported instead of 4
Mbyte pages if PAE bit is 1.
7 MCE Machine Check Exception. Exception 18 is defined for Machine Checks,
including CR4.MCE for controlling the feature. This feature does not define
the model-specific implementations of machine-check error logging,
reporting, and processor shutdowns. Machine Check exception handlers may
have to depend on processor version to do model specific processing of the
exception, or test for the presence of the Machine Check feature.
8 CX8 CMPXCHG8B Instruction. The compare-and-exchange 8 bytes (64 bits)
instruction is supported (implicitly locked and atomic).
9 APIC APIC On-Chip. The processor contains an Advanced Programmable Interrupt
Controller (APIC), responding to memory mapped commands in the physical
address range FFFE0000H to FFFE0FFFH (by default - some processors
permit the APIC to be relocated).
10 Reserved Reserved
11 SEP SYSENTER and SYSEXIT Instructions. The SYSENTER and SYSEXIT and
associated MSRs are supported.
12 MTRR Memory Type Range Registers. MTRRs are supported. The MTRRcap MSR
contains feature bits that describe what memory types are supported, how
many variable MTRRs are supported, and whether fixed MTRRs are
supported.

Vol. 2A 3-221
INSTRUCTION SET REFERENCE, A-M
CPUID—CPU Identification
13 PGE Page Global Bit. The global bit is supported in paging-structure entries that
map a page, indicating TLB entries that are common to different processes
and need not be flushed. The CR4.PGE bit controls this feature.
14 MCA Machine Check Architecture. The Machine Check Architecture, which
provides a compatible mechanism for error reporting in P6 family, Pentium
4, Intel Xeon processors, and future processors, is supported. The MCG_CAP
MSR contains feature bits describing how many banks of error reporting
MSRs are supported.
15 CMOV Conditional Move Instructions. The conditional move instruction CMOV is
supported. In addition, if x87 FPU is present as indicated by the CPUID.FPU
feature bit, then the FCOMI and FCMOV instructions are supported
16 PAT Page Attribute Table. Page Attribute Table is supported. This feature
augments the Memory Type Range Registers (MTRRs), allowing an
operating system to specify attributes of memory accessed through a linear
address on a 4KB granularity.
17 PSE-36 36-Bit Page Size Extension. 4-MByte pages addressing physical memory
beyond 4 GBytes are supported with 32-bit paging. This feature indicates
that upper bits of the physical address of a 4-MByte page are encoded in
bits 20:13 of the page-directory entry. Such physical addresses are limited
by MAXPHYADDR and may be up to 40 bits in size.
18 PSN Processor Serial Number. The processor supports the 96-bit processor
identification number feature and the feature is enabled.
19 CLFSH CLFLUSH Instruction. CLFLUSH Instruction is supported.
20 Reserved Reserved
21 DS Debug Store. The processor supports the ability to write debug information
into a memory resident buffer. This feature is used by the branch trace
store (BTS) and precise event-based sampling (PEBS) facilities (see Chapter
20, “Introduction to Virtual-Machine Extensions,” in the Intel® 64 and IA-32
Architectures Software Developer’s Manual, Volume 3B).
22 ACPI Thermal Monitor and Software Controlled Clock Facilities. The processor
implements internal MSRs that allow processor temperature to be
monitored and processor performance to be modulated in predefined duty
cycles under software control.
23 MMX Intel MMX Technology. The processor supports the Intel MMX technology.
24 FXSR FXSAVE and FXRSTOR Instructions. The FXSAVE and FXRSTOR
instructions are supported for fast save and restore of the floating point
context. Presence of this bit also indicates that CR4.OSFXSR is available for
an operating system to indicate that it supports the FXSAVE and FXRSTOR
instructions.
Table 3-21. More on Feature Information Returned in the EDX Register (Contd.)
Bit # Mnemonic Description

3-222 Vol. 2A CPUID—CPU Identification
INSTRUCTION SET REFERENCE, A-M
INPUT EAX = 2: TLB/Cache/Prefetch Information Returned in EAX, EBX, ECX, EDX
When CPUID executes with EAX set to 2, the processor returns information about the
processor’s internal TLBs, cache and prefetch hardware in the EAX, EBX, ECX, and
EDX registers. The information is reported in encoded form and fall into the following
categories:
•The least-significant byte in register EAX (register AL) indicates the number of
times the CPUID instruction must be executed with an input value of 2 to get a
complete description of the processor’s TLB/Cache/Prefetch hardware. The Intel
Xeon processor 7400 series will return a 1.
•The most significant bit (bit 31) of each register indicates whether the register
contains valid information (set to 0) or is reserved (set to 1).
•If a register contains valid information, the information is contained in 1 byte
descriptors. There are four types of encoding values for the byte descriptor, the
encoding type is noted in the second column of Table 3-22. Table 3-22 lists the
encoding of these descriptors. Note that the order of descriptors in the EAX, EBX,
ECX, and EDX registers is not defined; that is, specific bytes are not designated
to contain descriptors for specific cache, prefetch, or TLB types. The descriptors
may appear in any order. Note also a processor may report a general descriptor
type (FFH) and not report any byte descriptor of “cache type“ via CPUID leaf 2.
25 SSE SSE. The processor supports the SSE extensions.
26 SSE2 SSE2. The processor supports the SSE2 extensions.
27 SS Self Snoop. The processor supports the management of conflicting memory
types by performing a snoop of its own cache structure for transactions
issued to the bus.
28 HTT Multi-Threading. The physical processor package is capable of supporting
more than one logical processor.
29 TM Thermal Monitor. The processor implements the thermal monitor
automatic thermal control circuitry (TCC).
30 Reserved Reserved
31 PBE Pending Break Enable. The processor supports the use of the
FERR#/PBE# pin when the processor is in the stop-clock state (STPCLK# is
asserted) to signal the processor that an interrupt is pending and that the
processor should return to normal operation to handle the interrupt. Bit 10
(PBE enable) in the IA32_MISC_ENABLE MSR enables this capability.
Table 3-21. More on Feature Information Returned in the EDX Register (Contd.)
Bit # Mnemonic Description

Vol. 2A 3-223
INSTRUCTION SET REFERENCE, A-M
CPUID—CPU Identification
Table 3-22. Encoding of CPUID Leaf 2 Descriptors
Value Type Description
00H General Null descriptor, this byte contains no information
01H TLB Instruction TLB: 4 KByte pages, 4-way set associative, 32 entries
02H TLB Instruction TLB: 4 MByte pages, fully associative, 2 entries
03H TLB Data TLB: 4 KByte pages, 4-way set associative, 64 entries
04H TLB Data TLB: 4 MByte pages, 4-way set associative, 8 entries
05H TLB Data TLB1: 4 MByte pages, 4-way set associative, 32 entries
06H Cache 1st-level instruction cache: 8 KBytes, 4-way set associative, 32 byte line size
08H Cache 1st-level instruction cache: 16 KBytes, 4-way set associative, 32 byte line
size
09H Cache 1st-level instruction cache: 32KBytes, 4-way set associative, 64 byte line size
0AH Cache 1st-level data cache: 8 KBytes, 2-way set associative, 32 byte line size
0BH TLB Instruction TLB: 4 MByte pages, 4-way set associative, 4 entries
0CH Cache 1st-level data cache: 16 KBytes, 4-way set associative, 32 byte line size
0DH Cache 1st-level data cache: 16 KBytes, 4-way set associative, 64 byte line size
0EH Cache 1st-level data cache: 24 KBytes, 6-way set associative, 64 byte line size
21H Cache 2nd-level cache: 256 KBytes, 8-way set associative, 64 byte line size
22H Cache 3rd-level cache: 512 KBytes, 4-way set associative, 64 byte line size, 2 lines
per sector
23H Cache 3rd-level cache: 1 MBytes, 8-way set associative, 64 byte line size, 2 lines per
sector
25H Cache 3rd-level cache: 2 MBytes, 8-way set associative, 64 byte line size, 2 lines per
sector
29H Cache 3rd-level cache: 4 MBytes, 8-way set associative, 64 byte line size, 2 lines per
sector
2CH Cache 1st-level data cache: 32 KBytes, 8-way set associative, 64 byte line size
30H Cache 1st-level instruction cache: 32 KBytes, 8-way set associative, 64 byte line
size
40H Cache No 2nd-level cache or, if processor contains a valid 2nd-level cache, no 3rd-
level cache
41H Cache 2nd-level cache: 128 KBytes, 4-way set associative, 32 byte line size
42H Cache 2nd-level cache: 256 KBytes, 4-way set associative, 32 byte line size
43H Cache 2nd-level cache: 512 KBytes, 4-way set associative, 32 byte line size
44H Cache 2nd-level cache: 1 MByte, 4-way set associative, 32 byte line size
45H Cache 2nd-level cache: 2 MByte, 4-way set associative, 32 byte line size
3-224 Vol. 2A CPUID—CPU Identification
INSTRUCTION SET REFERENCE, A-M
46H Cache 3rd-level cache: 4 MByte, 4-way set associative, 64 byte line size
47H Cache 3rd-level cache: 8 MByte, 8-way set associative, 64 byte line size
48H Cache 2nd-level cache: 3MByte, 12-way set associative, 64 byte line size
49H Cache 3rd-level cache: 4MB, 16-way set associative, 64-byte line size (Intel Xeon
processor MP, Family 0FH, Model 06H);
2nd-level cache: 4 MByte, 16-way set associative, 64 byte line size
4AH Cache 3rd-level cache: 6MByte, 12-way set associative, 64 byte line size
4BH Cache 3rd-level cache: 8MByte, 16-way set associative, 64 byte line size
4CH Cache 3rd-level cache: 12MByte, 12-way set associative, 64 byte line size
4DH Cache 3rd-level cache: 16MByte, 16-way set associative, 64 byte line size
4EH Cache 2nd-level cache: 6MByte, 24-way set associative, 64 byte line size
4FH TLB Instruction TLB: 4 KByte pages, 32 entries
50H TLB Instruction TLB: 4 KByte and 2-MByte or 4-MByte pages, 64 entries
51H TLB Instruction TLB: 4 KByte and 2-MByte or 4-MByte pages, 128 entries
52H TLB Instruction TLB: 4 KByte and 2-MByte or 4-MByte pages, 256 entries
55H TLB Instruction TLB: 2-MByte or 4-MByte pages, fully associative, 7 entries
56H TLB Data TLB0: 4 MByte pages, 4-way set associative, 16 entries
57H TLB Data TLB0: 4 KByte pages, 4-way associative, 16 entries
59H TLB Data TLB0: 4 KByte pages, fully associative, 16 entries
5AH TLB Data TLB0: 2-MByte or 4 MByte pages, 4-way set associative, 32 entries
5BH TLB Data TLB: 4 KByte and 4 MByte pages, 64 entries
5CH TLB Data TLB: 4 KByte and 4 MByte pages,128 entries
5DH TLB Data TLB: 4 KByte and 4 MByte pages,256 entries
60H Cache 1st-level data cache: 16 KByte, 8-way set associative, 64 byte line size
66H Cache 1st-level data cache: 8 KByte, 4-way set associative, 64 byte line size
67H Cache 1st-level data cache: 16 KByte, 4-way set associative, 64 byte line size
68H Cache 1st-level data cache: 32 KByte, 4-way set associative, 64 byte line size
70H Cache Trace cache: 12 K-μop, 8-way set associative
71H Cache Trace cache: 16 K-μop, 8-way set associative
72H Cache Trace cache: 32 K-μop, 8-way set associative
76H TLB Instruction TLB: 2M/4M pages, fully associative, 8 entries
78H Cache 2nd-level cache: 1 MByte, 4-way set associative, 64byte line size
Table 3-22. Encoding of CPUID Leaf 2 Descriptors (Contd.)
Value Type Description

Vol. 2A 3-225
INSTRUCTION SET REFERENCE, A-M
CPUID—CPU Identification
79H Cache 2nd-level cache: 128 KByte, 8-way set associative, 64 byte line size, 2 lines
per sector
7AH Cache 2nd-level cache: 256 KByte, 8-way set associative, 64 byte line size, 2 lines
per sector
7BH Cache 2nd-level cache: 512 KByte, 8-way set associative, 64 byte line size, 2 lines
per sector
7CH Cache 2nd-level cache: 1 MByte, 8-way set associative, 64 byte line size, 2 lines per
sector
7DH Cache 2nd-level cache: 2 MByte, 8-way set associative, 64byte line size
7FH Cache 2nd-level cache: 512 KByte, 2-way set associative, 64-byte line size
80H Cache 2nd-level cache: 512 KByte, 8-way set associative, 64-byte line size
82H Cache 2nd-level cache: 256 KByte, 8-way set associative, 32 byte line size
83H Cache 2nd-level cache: 512 KByte, 8-way set associative, 32 byte line size
84H Cache 2nd-level cache: 1 MByte, 8-way set associative, 32 byte line size
85H Cache 2nd-level cache: 2 MByte, 8-way set associative, 32 byte line size
86H Cache 2nd-level cache: 512 KByte, 4-way set associative, 64 byte line size
87H Cache 2nd-level cache: 1 MByte, 8-way set associative, 64 byte line size
B0H TLB Instruction TLB: 4 KByte pages, 4-way set associative, 128 entries
B1H TLB Instruction TLB: 2M pages, 4-way, 8 entries or 4M pages, 4-way, 4 entries
B2H TLB Instruction TLB: 4KByte pages, 4-way set associative, 64 entries
B3H TLB Data TLB: 4 KByte pages, 4-way set associative, 128 entries
B4H TLB Data TLB1: 4 KByte pages, 4-way associative, 256 entries
BAH TLB Data TLB1: 4 KByte pages, 4-way associative, 64 entries
C0H TLB Data TLB: 4 KByte and 4 MByte pages, 4-way associative, 8 entries
CAH STLB Shared 2nd-Level TLB: 4 KByte pages, 4-way associative, 512 entries
D0H Cache 3rd-level cache: 512 KByte, 4-way set associative, 64 byte line size
D1H Cache 3rd-level cache: 1 MByte, 4-way set associative, 64 byte line size
D2H Cache 3rd-level cache: 2 MByte, 4-way set associative, 64 byte line size
D6H Cache 3rd-level cache: 1 MByte, 8-way set associative, 64 byte line size
D7H Cache 3rd-level cache: 2 MByte, 8-way set associative, 64 byte line size
D8H Cache 3rd-level cache: 4 MByte, 8-way set associative, 64 byte line size
DCH Cache 3rd-level cache: 1.5 MByte, 12-way set associative, 64 byte line size
DDH Cache 3rd-level cache: 3 MByte, 12-way set associative, 64 byte line size
DEH Cache 3rd-level cache: 6 MByte, 12-way set associative, 64 byte line size
Table 3-22. Encoding of CPUID Leaf 2 Descriptors (Contd.)
Value Type Description

3-226 Vol. 2A CPUID—CPU Identification
INSTRUCTION SET REFERENCE, A-M
Example 3-1. Example of Cache and TLB Interpretation
The first member of the family of Pentium 4 processors returns the following informa-
tion about caches and TLBs when the CPUID executes with an input value of 2:
EAX 66 5B 50 01H
EBX 0H
ECX 0H
EDX 00 7A 70 00H
Which means:
•The least-significant byte (byte 0) of register EAX is set to 01H. This indicates
that CPUID needs to be executed once with an input value of 2 to retrieve
complete information about caches and TLBs.
•The most-significant bit of all four registers (EAX, EBX, ECX, and EDX) is set to 0,
indicating that each register contains valid 1-byte descriptors.
•Bytes 1, 2, and 3 of register EAX indicate that the processor has:
— 50H - a 64-entry instruction TLB, for mapping 4-KByte and 2-MByte or 4-
MByte pages.
— 5BH - a 64-entry data TLB, for mapping 4-KByte and 4-MByte pages.
— 66H - an 8-KByte 1st level data cache, 4-way set associative, with a 64-Byte
cache line size.
•The descriptors in registers EBX and ECX are valid, but contain NULL descriptors.
•Bytes 0, 1, 2, and 3 of register EDX indicate that the processor has:
— 00H - NULL descriptor.
— 70H - Trace cache: 12 K-μop, 8-way set associative.
E2H Cache 3rd-level cache: 2 MByte, 16-way set associative, 64 byte line size
E3H Cache 3rd-level cache: 4 MByte, 16-way set associative, 64 byte line size
E4H Cache 3rd-level cache: 8 MByte, 16-way set associative, 64 byte line size
EAH Cache 3rd-level cache: 12MByte, 24-way set associative, 64 byte line size
EBH Cache 3rd-level cache: 18MByte, 24-way set associative, 64 byte line size
ECH Cache 3rd-level cache: 24MByte, 24-way set associative, 64 byte line size
F0H Prefetch 64-Byte prefetching
F1H Prefetch 128-Byte prefetching
FFH General CPUID leaf 2 does not report cache descriptor information, use CPUID leaf 4 to
query cache parameters
Table 3-22. Encoding of CPUID Leaf 2 Descriptors (Contd.)
Value Type Description

Vol. 2A 3-227
INSTRUCTION SET REFERENCE, A-M
CPUID—CPU Identification
— 7AH - a 256-KByte 2nd level cache, 8-way set associative, with a sectored,
64-byte cache line size.
— 00H - NULL descriptor.
INPUT EAX = 04H: Returns Deterministic Cache Parameters for Each Level
When CPUID executes with EAX set to 04H and ECX contains an index value, the
processor returns encoded data that describe a set of deterministic cache parame-
ters (for the cache level associated with the input in ECX). Valid index values start
from 0.
Software can enumerate the deterministic cache parameters for each level of the
cache hierarchy starting with an index value of 0, until the parameters report the
value associated with the cache type field is 0. The architecturally defined fields
reported by deterministic cache parameters are documented in Table 3-17.
This Cache Size in Bytes
= (Ways + 1) * (Partitions + 1) * (Line_Size + 1) * (Sets + 1)
= (EBX[31:22] + 1) * (EBX[21:12] + 1) * (EBX[11:0] + 1) * (ECX + 1)
The CPUID leaf 04H also reports data that can be used to derive the topology of
processor cores in a physical package. This information is constant for all valid index
values. Software can query the raw data reported by executing CPUID with EAX=04H
and ECX=0 and use it as part of the topology enumeration algorithm described in
Chapter 8, “Multiple-Processor Management,” in the Intel® 64 and IA-32 Architec-
tures Software Developer’s Manual, Volume 3A.
INPUT EAX = 05H: Returns MONITOR and MWAIT Features
When CPUID executes with EAX set to 05H, the processor returns information about
features available to MONITOR/MWAIT instructions. The MONITOR instruction is used
for address-range monitoring in conjunction with MWAIT instruction. The MWAIT
instruction optionally provides additional extensions for advanced power manage-
ment. See Table 3-17.
INPUT EAX = 06H: Returns Thermal and Power Management Features
When CPUID executes with EAX set to 06H, the processor returns information about
thermal and power management features. See Table 3-17.
INPUT EAX = 09H: Returns Direct Cache Access Information
When CPUID executes with EAX set to 09H, the processor returns information about
Direct Cache Access capabilities. See Table 3-17.

3-228 Vol. 2A CPUID—CPU Identification
INSTRUCTION SET REFERENCE, A-M
INPUT EAX = 0AH: Returns Architectural Performance Monitoring Features
When CPUID executes with EAX set to 0AH, the processor returns information about
support for architectural performance monitoring capabilities. Architectural perfor-
mance monitoring is supported if the version ID (see Table 3-17) is greater than
Pn 0. See Table 3-17.
For each version of architectural performance monitoring capability, software must
enumerate this leaf to discover the programming facilities and the architectural
performance events available in the processor. The details are described in Chapter
20, “Introduction to Virtual-Machine Extensions,” in the Intel® 64 and IA-32 Archi-
tectures Software Developer’s Manual, Volume 3B.
INPUT EAX = 0BH: Returns Extended Topology Information
When CPUID executes with EAX set to 0BH, the processor returns information about
extended topology enumeration data. Software must detect the presence of CPUID
leaf 0BH by verifying (a) the highest leaf index supported by CPUID is >= 0BH, and
(b) CPUID.0BH:EBX[15:0] reports a non-zero value. See Table 3-17.
INPUT EAX = 0DH: Returns Processor Extended States Enumeration Information
When CPUID executes with EAX set to 0DH and ECX = 0, the processor returns infor-
mation about the bit-vector representation of all processor state extensions that are
supported in the processor and storage size requirements of the XSAVE/XRSTOR
area. See Table 3-17.
When CPUID executes with EAX set to 0DH and ECX = n (n > 1, and is a valid sub-
leaf index), the processor returns information about the size and offset of each
processor extended state save area within the XSAVE/XRSTOR area. See Table 3-17.
Software can use the forward-extendable technique depicted below to query the
valid sub-leaves and obtain size and offset information for each processor extended
state save area:
For i = 2 to 62 // sub-leaf 1 is reserved
IF (CPUID.(EAX=0DH, ECX=0):VECTOR[i] = 1 ) // VECTOR is the 64-bit value of EDX:EAX
Execute CPUID.(EAX=0DH, ECX = i) to examine size and offset for sub-leaf i;
FI;
METHODS FOR RETURNING BRANDING INFORMATION
Use the following techniques to access branding information:
1. Processor brand string method; this method also returns the processor’s
maximum operating frequency
2. Processor brand index; this method uses a software supplied brand string table.
These two methods are discussed in the following sections. For methods that are
available in early processors, see Section: “Identification of Earlier IA-32 Processors”
Vol. 2A 3-229
INSTRUCTION SET REFERENCE, A-M
CPUID—CPU Identification
in Chapter 14 of the Intel® 64 and IA-32 Architectures Software Developer’s Manual,
Volume 1.
The Processor Brand String Method
Figure 3-12 describes the algorithm used for detection of the brand string. Processor
brand identification software should execute this algorithm on all Intel 64 and IA-32
processors.
This method (introduced with Pentium 4 processors) returns an ASCII brand identifi-
cation string and the maximum operating frequency of the processor to the EAX,
EBX, ECX, and EDX registers.
Figure 3-12. Determination of Support for the Processor Brand String
OM15194
IF (EAX & 0x80000000)
CPUID
IF (EAX Return Value
≥0x80000004)
CPUID
Function
Supported
True ≥
Extended
EAX Return Value =
Max. Extended CPUID
Function Index
Input: EAX=
0x80000000
Processor Brand
String Not
Supported
False
Processor Brand
String Supported
True

3-230 Vol. 2A CPUID—CPU Identification
INSTRUCTION SET REFERENCE, A-M
How Brand Strings Work
To use the brand string method, execute CPUID with EAX input of 8000002H through
80000004H. For each input value, CPUID returns 16 ASCII characters using EAX,
EBX, ECX, and EDX. The returned string will be NULL-terminated.
Table 3-23 shows the brand string that is returned by the first processor in the
Pentium 4 processor family.

Vol. 2A 3-231
INSTRUCTION SET REFERENCE, A-M
CPUID—CPU Identification
Extracting the Maximum Processor Frequency from Brand Strings
Figure 3-13 provides an algorithm which software can use to extract the maximum
processor operating frequency from the processor brand string.
NOTE
When a frequency is given in a brand string, it is the maximum
qualified frequency of the processor, not the frequency at which the
processor is currently running.
Table 3-23. Processor Brand String Returned with Pentium 4 Processor
EAX Input Value Return Values ASCII Equivalent
80000002H EAX = 20202020H
EBX = 20202020H
ECX = 20202020H
EDX = 6E492020H
“ ”
“”
“”
“nI ”
80000003H EAX = 286C6574H
EBX = 50202952H
ECX = 69746E65H
EDX = 52286D75H
“(let”
“P )R”
“itne”
“R(mu”
80000004H EAX = 20342029H
EBX = 20555043H
ECX = 30303531H
EDX = 007A484DH
“ 4 )”
“ UPC”
“0051”
“\0zHM”
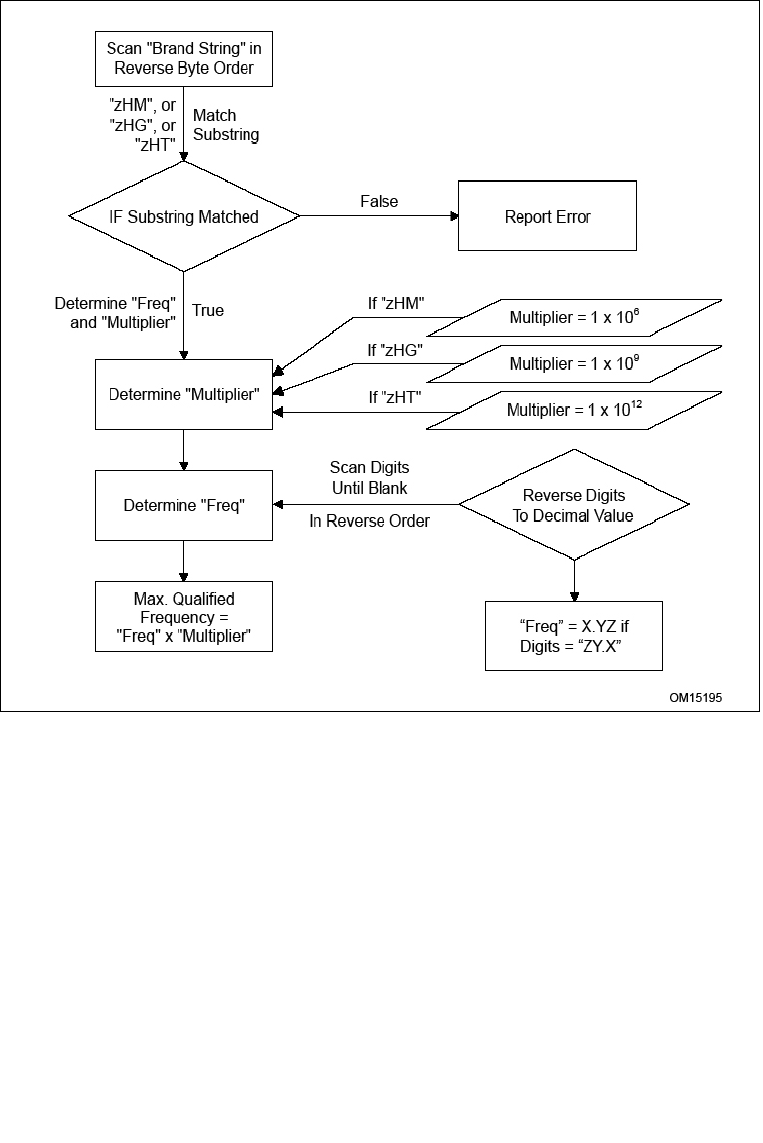
3-232 Vol. 2A CPUID—CPU Identification
INSTRUCTION SET REFERENCE, A-M
The Processor Brand Index Method
The brand index method (introduced with Pentium® III Xeon® processors) provides
an entry point into a brand identification table that is maintained in memory by
system software and is accessible from system- and user-level code. In this table,
each brand index is associate with an ASCII brand identification string that identifies
the official Intel family and model number of a processor.
When CPUID executes with EAX set to 1, the processor returns a brand index to the
low byte in EBX. Software can then use this index to locate the brand identification
string for the processor in the brand identification table. The first entry (brand index
0) in this table is reserved, allowing for backward compatibility with processors that
Figure 3-13. Algorithm for Extracting Maximum Processor Frequency

Vol. 2A 3-233
INSTRUCTION SET REFERENCE, A-M
CPUID—CPU Identification
do not support the brand identification feature. Starting with processor signature
family ID = 0FH, model = 03H, brand index method is no longer supported. Use
brand string method instead.
Table 3-24 shows brand indices that have identification strings associated with them.
Table 3-24. Mapping of Brand Indices; and
Intel 64 and IA-32 Processor Brand Strings
Brand Index Brand String
00H This processor does not support the brand identification feature
01H Intel(R) Celeron(R) processor1
02H Intel(R) Pentium(R) III processor1
03H Intel(R) Pentium(R) III Xeon(R) processor; If processor signature =
000006B1h, then Intel(R) Celeron(R) processor
04H Intel(R) Pentium(R) III processor
06H Mobile Intel(R) Pentium(R) III processor-M
07H Mobile Intel(R) Celeron(R) processor1
08H Intel(R) Pentium(R) 4 processor
09H Intel(R) Pentium(R) 4 processor
0AH Intel(R) Celeron(R) processor1
0BH Intel(R) Xeon(R) processor; If processor signature = 00000F13h, then Intel(R)
Xeon(R) processor MP
0CH Intel(R) Xeon(R) processor MP
0EH Mobile Intel(R) Pentium(R) 4 processor-M; If processor signature =
00000F13h, then Intel(R) Xeon(R) processor
0FH Mobile Intel(R) Celeron(R) processor1
11H Mobile Genuine Intel(R) processor
12H Intel(R) Celeron(R) M processor
13H Mobile Intel(R) Celeron(R) processor1
14H Intel(R) Celeron(R) processor
15H Mobile Genuine Intel(R) processor
16H Intel(R) Pentium(R) M processor
17H Mobile Intel(R) Celeron(R) processor1
18H – 0FFH RESERVED
NOTES:
1. Indicates versions of these processors that were introduced after the Pentium III

3-234 Vol. 2A CPUID—CPU Identification
INSTRUCTION SET REFERENCE, A-M
IA-32 Architecture Compatibility
CPUID is not supported in early models of the Intel486 processor or in any IA-32
processor earlier than the Intel486 processor.
Operation
IA32_BIOS_SIGN_ID MSR ← Update with installed microcode revision number;
CASE (EAX) OF
EAX = 0:
EAX ← Highest basic function input value understood by CPUID;
EBX ← Vendor identification string;
EDX ← Vendor identification string;
ECX ← Vendor identification string;
BREAK;
EAX = 1H:
EAX[3:0] ← Stepping ID;
EAX[7:4] ← Model;
EAX[11:8] ← Family;
EAX[13:12] ← Processor type;
EAX[15:14] ← Reserved;
EAX[19:16] ← Extended Model;
EAX[27:20] ← Extended Family;
EAX[31:28] ← Reserved;
EBX[7:0] ← Brand Index; (* Reserved if the value is zero. *)
EBX[15:8] ← CLFLUSH Line Size;
EBX[16:23] ← Reserved; (* Number of threads enabled = 2 if MT enable fuse set. *)
EBX[24:31] ← Initial APIC ID;
ECX ← Feature flags; (* See Figure 3-10. *)
EDX ← Feature flags; (* See Figure 3-11. *)
BREAK;
EAX = 2H:
EAX ← Cache and TLB information;
EBX
← Cache and TLB information;
ECX
← Cache and TLB information;
EDX ← Cache and TLB information;
BREAK;
EAX = 3H:
EAX ← Reserved;
EBX
← Reserved;
ECX
← ProcessorSerialNumber[31:0];
(* Pentium III processors only, otherwise reserved. *)
EDX ← ProcessorSerialNumber[63:32];
(* Pentium III processors only, otherwise reserved. *

Vol. 2A 3-235
INSTRUCTION SET REFERENCE, A-M
CPUID—CPU Identification
BREAK
EAX = 4H:
EAX ← Deterministic Cache Parameters Leaf; (* See Table 3-17. *)
EBX ← Deterministic Cache Parameters Leaf;
ECX
← Deterministic Cache Parameters Leaf;
EDX ← Deterministic Cache Parameters Leaf;
BREAK;
EAX = 5H:
EAX ← MONITOR/MWAIT Leaf; (* See Table 3-17. *)
EBX
← MONITOR/MWAIT Leaf;
ECX
← MONITOR/MWAIT Leaf;
EDX ← MONITOR/MWAIT Leaf;
BREAK;
EAX = 6H:
EAX ← Thermal and Power Management Leaf; (* See Table 3-17. *)
EBX
← Thermal and Power Management Leaf;
ECX
← Thermal and Power Management Leaf;
EDX ← Thermal and Power Management Leaf;
BREAK;
EAX = 7H or 8H:
EAX ← Reserved = 0;
EBX
← Reserved = 0;
ECX
← Reserved = 0;
EDX ← Reserved = 0;
BREAK;
EAX = 9H:
EAX ← Direct Cache Access Information Leaf; (* See Table 3-17. *)
EBX
← Direct Cache Access Information Leaf;
ECX
← Direct Cache Access Information Leaf;
EDX ← Direct Cache Access Information Leaf;
BREAK;
EAX = AH:
EAX ← Architectural Performance Monitoring Leaf; (* See Table 3-17. *)
EBX
← Architectural Performance Monitoring Leaf;
ECX
← Architectural Performance Monitoring Leaf;
EDX ← Architectural Performance Monitoring Leaf;
BREAK
EAX = BH:
EAX ← Extended Topology Enumeration Leaf; (* See Table 3-17. *)
EBX ← Extended Topology Enumeration Leaf;
ECX
← Extended Topology Enumeration Leaf;
EDX ← Extended Topology Enumeration Leaf;
BREAK;

3-236 Vol. 2A CPUID—CPU Identification
INSTRUCTION SET REFERENCE, A-M
EAX = CH:
EAX ← Reserved = 0;
EBX
← Reserved = 0;
ECX
← Reserved = 0;
EDX ← Reserved = 0;
BREAK;
EAX = DH:
EAX ← Processor Extended State Enumeration Leaf; (* See Table 3-17. *)
EBX
← Processor Extended State Enumeration Leaf;
ECX
← Processor Extended State Enumeration Leaf;
EDX ← Processor Extended State Enumeration Leaf;
BREAK;
BREAK;
EAX = 80000000H:
EAX ← Highest extended function input value understood by CPUID;
EBX ← Reserved;
ECX ← Reserved;
EDX ← Reserved;
BREAK;
EAX = 80000001H:
EAX ← Reserved;
EBX ← Reserved;
ECX ← Extended Feature Bits (* See Table 3-17.*);
EDX ← Extended Feature Bits (* See Table 3-17. *);
BREAK;
EAX = 80000002H:
EAX ← Processor Brand String;
EBX ← Processor Brand String, continued;
ECX ← Processor Brand String, continued;
EDX ← Processor Brand String, continued;
BREAK;
EAX = 80000003H:
EAX ← Processor Brand String, continued;
EBX ← Processor Brand String, continued;
ECX ← Processor Brand String, continued;
EDX ← Processor Brand String, continued;
BREAK;
EAX = 80000004H:
EAX ← Processor Brand String, continued;
EBX ← Processor Brand String, continued;
ECX ← Processor Brand String, continued;
EDX ← Processor Brand String, continued;
BREAK;

Vol. 2A 3-237
INSTRUCTION SET REFERENCE, A-M
CPUID—CPU Identification
EAX = 80000005H:
EAX ← Reserved = 0;
EBX ← Reserved = 0;
ECX ← Reserved = 0;
EDX ← Reserved = 0;
BREAK;
EAX = 80000006H:
EAX ← Reserved = 0;
EBX ← Reserved = 0;
ECX ← Cache information;
EDX ← Reserved = 0;
BREAK;
EAX = 80000007H:
EAX ← Reserved = 0;
EBX ← Reserved = 0;
ECX ← Reserved = 0;
EDX ← Reserved = Misc Feature Flags;
BREAK;
EAX = 80000008H:
EAX ← Reserved = Physical Address Size Information;
EBX ← Reserved = Virtual Address Size Information;
ECX ← Reserved = 0;
EDX ← Reserved = 0;
BREAK;
EAX >= 40000000H and EAX <= 4FFFFFFFH:
DEFAULT: (* EAX = Value outside of recognized range for CPUID. *)
(* If the highest basic information leaf data depend on ECX input value, ECX is honored.*)
EAX ← Reserved; (* Information returned for highest basic information leaf. *)
EBX ← Reserved; (* Information returned for highest basic information leaf. *)
ECX ← Reserved; (* Information returned for highest basic information leaf. *)
EDX ← Reserved; (* Information returned for highest basic information leaf. *)
BREAK;
ESAC;
Flags Affected
None.
Exceptions (All Operating Modes)
#UD If the LOCK prefix is used.
In earlier IA-32 processors that do not support the CPUID
instruction, execution of the instruction results in an invalid
opcode (#UD) exception being generated.

3-238 Vol. 2A CRC32 — Accumulate CRC32 Value
INSTRUCTION SET REFERENCE, A-M
CRC32 — Accumulate CRC32 Value
Instruction Operand Encoding
Description
Starting with an initial value in the first operand (destination operand), accumulates
a CRC32 (polynomial 0x11EDC6F41) value for the second operand (source operand)
and stores the result in the destination operand. The source operand can be a
register or a memory location. The destination operand must be an r32 or r64
register. If the destination is an r64 register, then the 32-bit result is stored in the
least significant double word and 00000000H is stored in the most significant double
word of the r64 register.
The initial value supplied in the destination operand is a double word integer stored
in the r32 register or the least significant double word of the r64 register. To incre-
mentally accumulate a CRC32 value, software retains the result of the previous
CRC32 operation in the destination operand, then executes the CRC32 instruction
again with new input data in the source operand. Data contained in the source
operand is processed in reflected bit order. This means that the most significant bit of
the source operand is treated as the least significant bit of the quotient, and so on,
for all the bits of the source operand. Likewise, the result of the CRC operation is
stored in the destination operand in reflected bit order. This means that the most
significant bit of the resulting CRC (bit 31) is stored in the least significant bit of the
destination operand (bit 0), and so on, for all the bits of the CRC.
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
F2 0F 38 F0 /r CRC32 r32, r/m8 A Valid Valid Accumulate CRC32 on r/m8.
F2 REX 0F 38
F0 /r
CRC32 r32, r/m8* A Valid N.E. Accumulate CRC32 on r/m8.
F2 0F 38 F1 /r CRC32 r32, r/m16 A Valid Valid Accumulate CRC32 on
r/m16.
F2 0F 38 F1 /r CRC32 r32, r/m32 A Valid Valid Accumulate CRC32 on
r/m32.
F2 REX.W 0F 38
F0 /r
CRC32 r64, r/m8 A Valid N.E. Accumulate CRC32 on r/m8.
F2 REX.W 0F 38
F1 /r
CRC32 r64, r/m64 A Valid N.E. Accumulate CRC32 on
r/m64.
NOTES:
*In 64-bit mode, r/m8 can not be encoded to access the following byte registers if a REX prefix is
used: AH, BH, CH, DH.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA

Vol. 2A 3-239
INSTRUCTION SET REFERENCE, A-M
CRC32 — Accumulate CRC32 Value
Operation
Notes:
BIT_REFLECT64: DST[63-0] = SRC[0-63]
BIT_REFLECT32: DST[31-0] = SRC[0-31]
BIT_REFLECT16: DST[15-0] = SRC[0-15]
BIT_REFLECT8: DST[7-0] = SRC[0-7]
MOD2: Remainder from Polynomial division modulus 2
CRC32 instruction for 64-bit source operand and 64-bit destination operand:
TEMP1[63-0] BIT_REFLECT64 (SRC[63-0])
TEMP2[31-0] BIT_REFLECT32 (DEST[31-0])
TEMP3[95-0] TEMP1[63-0] « 32
TEMP4[95-0] TEMP2[31-0] « 64
TEMP5[95-0] TEMP3[95-0] XOR TEMP4[95-0]
TEMP6[31-0] TEMP5[95-0] MOD2 11EDC6F41H
DEST[31-0] BIT_REFLECT (TEMP6[31-0])
DEST[63-32] 00000000H
CRC32 instruction for 32-bit source operand and 32-bit destination operand:
TEMP1[31-0] BIT_REFLECT32 (SRC[31-0])
TEMP2[31-0] BIT_REFLECT32 (DEST[31-0])
TEMP3[63-0] TEMP1[31-0] « 32
TEMP4[63-0] TEMP2[31-0] « 32
TEMP5[63-0] TEMP3[63-0] XOR TEMP4[63-0]
TEMP6[31-0] TEMP5[63-0] MOD2 11EDC6F41H
DEST[31-0] BIT_REFLECT (TEMP6[31-0])
CRC32 instruction for 16-bit source operand and 32-bit destination operand:
TEMP1[15-0] BIT_REFLECT16 (SRC[15-0])
TEMP2[31-0] BIT_REFLECT32 (DEST[31-0])
TEMP3[47-0] TEMP1[15-0] « 32
TEMP4[47-0] TEMP2[31-0] « 16
TEMP5[47-0] TEMP3[47-0] XOR TEMP4[47-0]
TEMP6[31-0] TEMP5[47-0] MOD2 11EDC6F41H
DEST[31-0] BIT_REFLECT (TEMP6[31-0])
CRC32 instruction for 8-bit source operand and 64-bit destination operand:
TEMP1[7-0] BIT_REFLECT8(SRC[7-0])
TEMP2[31-0] BIT_REFLECT32 (DEST[31-0])
TEMP3[39-0] TEMP1[7-0] « 32
TEMP4[39-0] TEMP2[31-0] « 8
TEMP5[39-0] TEMP3[39-0] XOR TEMP4[39-0]

3-240 Vol. 2A CRC32 — Accumulate CRC32 Value
INSTRUCTION SET REFERENCE, A-M
TEMP6[31-0] TEMP5[39-0] MOD2 11EDC6F41H
DEST[31-0] BIT_REFLECT (TEMP6[31-0])
DEST[63-32] 00000000H
CRC32 instruction for 8-bit source operand and 32-bit destination operand:
TEMP1[7-0] BIT_REFLECT8(SRC[7-0])
TEMP2[31-0] BIT_REFLECT32 (DEST[31-0])
TEMP3[39-0] TEMP1[7-0] « 32
TEMP4[39-0] TEMP2[31-0] « 8
TEMP5[39-0] TEMP3[39-0] XOR TEMP4[39-0]
TEMP6[31-0] TEMP5[39-0] MOD2 11EDC6F41H
DEST[31-0] BIT_REFLECT (TEMP6[31-0])
Flags Affected
None
Intel C/C++ Compiler Intrinsic Equivalent
unsigned int _mm_crc32_u8( unsigned int crc, unsigned char data )
unsigned int _mm_crc32_u16( unsigned int crc, unsigned short data )
unsigned int _mm_crc32_u32( unsigned int crc, unsigned int data )
unsinged __int64 _mm_crc32_u64( unsinged __int64 crc, unsigned __int64 data )
SIMD Floating Point Exceptions
None
Protected Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS or GS segments.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF (fault-code) For a page fault.
#UD If CPUID.01H:ECX.SSE4_2 [Bit 20] = 0.
If LOCK prefix is used.
Real Mode Exceptions
#GP(0) If any part of the operand lies outside of the effective address
space from 0 to 0FFFFH.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#UD If CPUID.01H:ECX.SSE4_2 [Bit 20] = 0.
If LOCK prefix is used.

Vol. 2A 3-241
INSTRUCTION SET REFERENCE, A-M
CRC32 — Accumulate CRC32 Value
Virtual 8086 Mode Exceptions
#GP(0) If any part of the operand lies outside of the effective address
space from 0 to 0FFFFH.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF (fault-code) For a page fault.
#UD If CPUID.01H:ECX.SSE4_2 [Bit 20] = 0.
If LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in Protected Mode.
64-Bit Mode Exceptions
#GP(0) If the memory address is in a non-canonical form.
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#PF (fault-code) For a page fault.
#UD If CPUID.01H:ECX.SSE4_2 [Bit 20] = 0.
If LOCK prefix is used.

3-242 Vol. 2A CVTDQ2PD—Convert Packed Dword Integers to Packed Double-Precision FP Values
INSTRUCTION SET REFERENCE, A-M
CVTDQ2PD—Convert Packed Dword Integers to Packed Double-
Precision FP Values
Instruction Operand Encoding
Description
Converts two packed signed doubleword integers in the source operand (second
operand) to two packed double-precision floating-point values in the destination
operand (first operand).
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
128-bit Legacy SSE version: The source operand is an XMM register or 64- bit
memory location. The destination operation is an XMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are unmodified.
VEX.128 encoded version: The source operand is an XMM register or 64- bit memory
location. The destination operation is a YMM register. The upper bits (VLMAX-1:128)
of the corresponding YMM register destination are zeroed.
VEX.256 encoded version: The source operand is an XMM register or 128- bit
memory location. The destination operation is a YMM register.
Note: In VEX-encoded versions, VEX.vvvv is reserved and must be 1111b, otherwise
instructions will #UD.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F3 0F E6
CVTDQ2PD xmm1, xmm2/m64
A V/V SSE2 Convert two packed signed
doubleword integers from
xmm2/m128 to two packed
double-precision floating-
point values in xmm1.
VEX.128.F3.0F.WIG E6 /r
VCVTDQ2PD xmm1, xmm2/m64
AV/V AVX Convert two packed signed
doubleword integers from
xmm2/mem to two packed
double-precision floating-
point values in xmm1.
VEX.256.F3.0F.WIG E6 /r
VCVTDQ2PD ymm1, xmm2/m128
A V/V AVX Convert four packed signed
doubleword integers from
xmm2/mem to four packed
double-precision floating-
point values in ymm1.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA

Vol. 2A 3-243
INSTRUCTION SET REFERENCE, A-M
CVTDQ2PD—Convert Packed Dword Integers to Packed Double-Precision FP Values
Figure 3-14. CVTDQ2PD (VEX.256 encoded version)
Operation
CVTDQ2PD (128-bit Legacy SSE version)
DEST[63:0] Convert_Integer_To_Double_Precision_Floating_Point(SRC[31:0])
DEST[127:64] Convert_Integer_To_Double_Precision_Floating_Point(SRC[63:32])
DEST[VLMAX-1:128] (unmodified)
VCVTDQ2PD (VEX.128 encoded version)
DEST[63:0] Convert_Integer_To_Double_Precision_Floating_Point(SRC[31:0])
DEST[127:64] Convert_Integer_To_Double_Precision_Floating_Point(SRC[63:32])
DEST[VLMAX-1:128] 0
VCVTDQ2PD (VEX.256 encoded version)
DEST[63:0] Convert_Integer_To_Double_Precision_Floating_Point(SRC[31:0])
DEST[127:64] Convert_Integer_To_Double_Precision_Floating_Point(SRC[63:32])
DEST[191:128] Convert_Integer_To_Double_Precision_Floating_Point(SRC[95:64])
DEST[255:192] Convert_Integer_To_Double_Precision_Floating_Point(SRC[127:96)
Intel C/C++ Compiler Intrinsic Equivalent
CVTDQ2PD __m128d _mm_cvtepi32_pd(__m128i a)
VCVTDQ2PD __m256d _mm256_cvtepi32_pd (__m128i src)
SIMD Floating-Point Exceptions
None.
Other Exceptions
See Exceptions Type 5; additionally
DEST
SRC X0X1X2X3
X3 X2
X1 X0

3-244 Vol. 2A CVTDQ2PD—Convert Packed Dword Integers to Packed Double-Precision FP Values
INSTRUCTION SET REFERENCE, A-M
#UD If VEX.vvvv != 1111B.

Vol. 2A 3-245
INSTRUCTION SET REFERENCE, A-M
CVTDQ2PS—Convert Packed Dword Integers to Packed Single-Precision FP Values
CVTDQ2PS—Convert Packed Dword Integers to Packed Single-
Precision FP Values
Instruction Operand Encoding
Description
Converts four packed signed doubleword integers in the source operand (second
operand) to four packed single-precision floating-point values in the destination
operand (first operand).
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
128-bit Legacy SSE version: The source operand is an XMM register or 128- bit
memory location. The destination operation is an XMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are unmodified.
VEX.128 encoded version: The source operand is an XMM register or 128- bit
memory location. The destination operation is a YMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are zeroed.
VEX.256 encoded version: The source operand is a YMM register or 256- bit memory
location. The destination operation is a YMM register.
Note: In VEX-encoded versions, VEX.vvvv is reserved and must be 1111b, otherwise
instructions will #UD.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
0F 5B /r
CVTDQ2PS xmm1, xmm2/m128
A V/V SSE2 Convert four packed signed
doubleword integers from
xmm2/m128 to four packed
single-precision floating-
point values in xmm1.
VEX.128.0F.WIG 5B /r
VCVTDQ2PS xmm1, xmm2/m128
A V/V AVX Convert four packed signed
doubleword integers from
xmm2/mem to four packed
single-precision floating-
point values in xmm1.
VEX.256.0F.WIG 5B /r
VCVTDQ2PS ymm1, ymm2/m256
A V/V AVX Convert eight packed signed
doubleword integers from
ymm2/mem to eight packed
single-precision floating-
point values in ymm1.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA

3-246 Vol. 2A CVTDQ2PS—Convert Packed Dword Integers to Packed Single-Precision FP Values
INSTRUCTION SET REFERENCE, A-M
Operation
CVTDQ2PS (128-bit Legacy SSE version)
DEST[31:0] Convert_Integer_To_Single_Precision_Floating_Point(SRC[31:0])
DEST[63:32] Convert_Integer_To_Single_Precision_Floating_Point(SRC[63:32])
DEST[95:64] Convert_Integer_To_Single_Precision_Floating_Point(SRC[95:64])
DEST[127:96] Convert_Integer_To_Single_Precision_Floating_Point(SRC[127z:96)
DEST[VLMAX-1:128] (unmodified)
VCVTDQ2PS (VEX.128 encoded version)
DEST[31:0] Convert_Integer_To_Single_Precision_Floating_Point(SRC[31:0])
DEST[63:32] Convert_Integer_To_Single_Precision_Floating_Point(SRC[63:32])
DEST[95:64] Convert_Integer_To_Single_Precision_Floating_Point(SRC[95:64])
DEST[127:96] Convert_Integer_To_Single_Precision_Floating_Point(SRC[127z:96)
DEST[VLMAX-1:128] 0
VCVTDQ2PS (VEX.256 encoded version)
DEST[31:0] Convert_Integer_To_Single_Precision_Floating_Point(SRC[31:0])
DEST[63:32] Convert_Integer_To_Single_Precision_Floating_Point(SRC[63:32])
DEST[95:64] Convert_Integer_To_Single_Precision_Floating_Point(SRC[95:64])
DEST[127:96] Convert_Integer_To_Single_Precision_Floating_Point(SRC[127z:96)
DEST[159:128] Convert_Integer_To_Single_Precision_Floating_Point(SRC[159:128])
DEST[191:160] Convert_Integer_To_Single_Precision_Floating_Point(SRC[191:160])
DEST[223:192] Convert_Integer_To_Single_Precision_Floating_Point(SRC[223:192])
DEST[255:224] Convert_Integer_To_Single_Precision_Floating_Point(SRC[255:224)
Intel C/C++ Compiler Intrinsic Equivalent
CVTDQ2PS __m128 _mm_cvtepi32_ps(__m128i a)
VCVTDQ2PS __m256 _mm256_cvtepi32_ps (__m256i src)
SIMD Floating-Point Exceptions
Precision.
Other Exceptions
See Exceptions Type 2; additionally
#UD If VEX.vvvv != 1111B.
Vol. 2A 3-247
INSTRUCTION SET REFERENCE, A-M
CVTPD2DQ—Convert Packed Double-Precision FP Values to Packed Dword Integers
CVTPD2DQ—Convert Packed Double-Precision FP Values to Packed
Dword Integers
Instruction Operand Encoding
Description
Converts two packed double-precision floating-point values in the source operand
(second operand) to two packed signed doubleword integers in the destination
operand (first operand).
The source operand can be an XMM register or a 128-bit memory location. The desti-
nation operand is an XMM register. The result is stored in the low quadword of the
destination operand and the high quadword is cleared to all 0s.
When a conversion is inexact, the value returned is rounded according to the
rounding control bits in the MXCSR register. If a converted result is larger than the
maximum signed doubleword integer, the floating-point invalid exception is raised,
and if this exception is masked, the indefinite integer value (80000000H) is returned.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
128-bit Legacy SSE version: The source operand is an XMM register or 128- bit
memory location. The destination operation is an XMM register. Bits[127:64] of the
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F2 0F E6
CVTPD2DQ xmm1, xmm2/m128
A V/V SSE2 Convert two packed double-
precision floating-point
values from xmm2/m128 to
two packed signed
doubleword integers in
xmm1.
VEX.128.F2.0F.WIG E6 /r
VCVTPD2DQ xmm1, xmm2/m128
A V/V AVX Convert two packed double-
precision floating-point
values in xmm2/mem to two
signed doubleword integers
in xmm1.
VEX.256.F2.0F.WIG E6 /r
VCVTPD2DQ xmm1, ymm2/m256
A V/V AVX Convert four packed double-
precision floating-point
values in ymm2/mem to
four signed doubleword
integers in xmm1.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA
3-248 Vol. 2A CVTPD2DQ—Convert Packed Double-Precision FP Values to Packed Dword Integers
INSTRUCTION SET REFERENCE, A-M
destination XMM register are zeroed. However, the upper bits (VLMAX-1:128) of the
corresponding YMM register destination are unmodified.
VEX.128 encoded version: The source operand is an XMM register or 128- bit
memory location. The destination operation is a YMM register. The upper bits
(VLMAX-1:64) of the corresponding YMM register destination are zeroed.
VEX.256 encoded version: The source operand is a YMM register or 256- bit memory
location. The destination operation is an XMM register. The upper bits (255:128) of
the corresponding YMM register destination are zeroed.
Note: In VEX-encoded versions, VEX.vvvv is reserved and must be 1111b, otherwise
instructions will #UD.
Figure 3-15. VCVTPD2DQ (VEX.256 encoded version)
Operation
CVTPD2DQ (128-bit Legacy SSE version)
DEST[31:0] Convert_Double_Precision_Floating_Point_To_Integer(SRC[63:0])
DEST[63:32] Convert_Double_Precision_Floating_Point_To_Integer(SRC[127:64])
DEST[127:64] 0
DEST[VLMAX-1:128] (unmodified)
VCVTPD2DQ (VEX.128 encoded version)
DEST[31:0] Convert_Double_Precision_Floating_Point_To_Integer(SRC[63:0])
DEST[63:32] Convert_Double_Precision_Floating_Point_To_Integer(SRC[127:64])
DEST[VLMAX-1:64] 0
VCVTPD2DQ (VEX.256 encoded version)
DEST[31:0] Convert_Double_Precision_Floating_Point_To_Integer(SRC[63:0])
DEST[63:32] Convert_Double_Precision_Floating_Point_To_Integer(SRC[127:64])
DEST
SRC
X0X1X2X3
X3 X2
X1 X0
0

Vol. 2A 3-249
INSTRUCTION SET REFERENCE, A-M
CVTPD2DQ—Convert Packed Double-Precision FP Values to Packed Dword Integers
DEST[95:64] Convert_Double_Precision_Floating_Point_To_Integer(SRC[191:128])
DEST[127:96] Convert_Double_Precision_Floating_Point_To_Integer(SRC[255:192)
DEST[255:128] 0
Intel C/C++ Compiler Intrinsic Equivalent
CVTPD2DQ __m128i _mm_cvtpd_epi32 (__m128d src)
CVTPD2DQ __m128i _mm256_cvtpd_epi32 (__m256d src)
SIMD Floating-Point Exceptions
Invalid, Precision.
Other Exceptions
See Exceptions Type 2; additionally
#UD If VEX.vvvv != 1111B.

3-250 Vol. 2A CVTPD2PI—Convert Packed Double-Precision FP Values to Packed Dword Integers
INSTRUCTION SET REFERENCE, A-M
CVTPD2PI—Convert Packed Double-Precision FP Values to Packed
Dword Integers
Instruction Operand Encoding
Description
Converts two packed double-precision floating-point values in the source operand
(second operand) to two packed signed doubleword integers in the destination
operand (first operand).
The source operand can be an XMM register or a 128-bit memory location. The desti-
nation operand is an MMX technology register.
When a conversion is inexact, the value returned is rounded according to the
rounding control bits in the MXCSR register. If a converted result is larger than the
maximum signed doubleword integer, the floating-point invalid exception is raised,
and if this exception is masked, the indefinite integer value (80000000H) is returned.
This instruction causes a transition from x87 FPU to MMX technology operation (that
is, the x87 FPU top-of-stack pointer is set to 0 and the x87 FPU tag word is set to all
0s [valid]). If this instruction is executed while an x87 FPU floating-point exception is
pending, the exception is handled before the CVTPD2PI instruction is executed.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
Operation
DEST[31:0] ← Convert_Double_Precision_Floating_Point_To_Integer32(SRC[63:0]);
DEST[63:32] ← Convert_Double_Precision_Floating_Point_To_Integer32(SRC[127:64]);
Intel C/C++ Compiler Intrinsic Equivalent
CVTPD1PI __m64 _mm_cvtpd_pi32(__m128d a)
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
66 0F 2D /rCVTPD2PI mm,
xmm/m128
A Valid Valid Convert two packed double-
precision floating-point
values from xmm/m128 to
two packed signed
doubleword integers in mm.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA

Vol. 2A 3-251
INSTRUCTION SET REFERENCE, A-M
CVTPD2PI—Convert Packed Double-Precision FP Values to Packed Dword Integers
SIMD Floating-Point Exceptions
Invalid, Precision.
Protected Mode Exceptions
#GP(0) For an illegal memory operand effective address in the CS, DS,
ES, FS or GS segments.
If a memory operand is not aligned on a 16-byte boundary,
regardless of segment.
#SS(0) For an illegal address in the SS segment.
#PF(fault-code) For a page fault.
#MF If there is a pending x87 FPU exception.
#NM If CR0.TS[bit 3] = 1.
#XM If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 1.
#UD If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 0.
If CR0.EM[bit 2] = 1.
If CR4.OSFXSR[bit 9] = 0.
If CPUID.01H:EDX.SSE2[bit 26] = 0.
If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand is not aligned on a 16-byte boundary,
regardless of segment.
If any part of the operand lies outside the effective address
space from 0 to FFFFH.
#NM If CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#XM If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 1.
#UD If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 0.
If CR0.EM[bit 2] = 1.
If CR4.OSFXSR[bit 9] = 0.
If CPUID.01H:EDX.SSE2[bit 26] = 0.
If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
Same exceptions as in real address mode.

3-252 Vol. 2A CVTPD2PI—Convert Packed Double-Precision FP Values to Packed Dword Integers
INSTRUCTION SET REFERENCE, A-M
#PF(fault-code) For a page fault.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
If memory operand is not aligned on a 16-byte boundary,
regardless of segment.
#PF(fault-code) For a page fault.
#MF If there is a pending x87 FPU exception.
#NM If CR0.TS[bit 3] = 1.
#XM If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 1.
#UD If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 0.
If CR0.EM[bit 2] = 1.
If CR4.OSFXSR[bit 9] = 0.
If CPUID.01H:EDX.SSE2[bit 26] = 0.
If the LOCK prefix is used.

Vol. 2A 3-253
INSTRUCTION SET REFERENCE, A-M
CVTPD2PS—Convert Packed Double-Precision FP Values to Packed Single-Precision FP
Values
CVTPD2PS—Convert Packed Double-Precision FP Values to Packed
Single-Precision FP Values
Instruction Operand Encoding
Description
Converts two packed double-precision floating-point values in the source operand
(second operand) to two packed single-precision floating-point values in the destina-
tion operand (first operand).
When a conversion is inexact, the value returned is rounded according to the
rounding control bits in the MXCSR register.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
128-bit Legacy SSE version: The source operand is an XMM register or 128- bit
memory location. The destination operation is an XMM register. Bits[127:64] of the
destination XMM register are zeroed. However, the upper bits (VLMAX-1:128) of the
corresponding YMM register destination are unmodified.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 5A /r
CVTPD2PS xmm1, xmm2/m128
A V/V SSE2 Convert two packed double-
precision floating-point
values in xmm2/m128 to
two packed single-precision
floating-point values in
xmm1.
VEX.128.66.0F.WIG 5A /r
VCVTPD2PS xmm1, xmm2/m128
A V/V AVX Convert two packed double-
precision floating-point
values in xmm2/mem to two
single-precision floating-
point values in xmm1.
VEX.256.66.0F.WIG 5A /r
VCVTPD2PS xmm1, ymm2/m256
A V/V AVX Convert four packed double-
precision floating-point
values in ymm2/mem to
four single-precision
floating-point values in
xmm1.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA
3-254 Vol. 2A CVTPD2PS—Convert Packed Double-Precision FP Values to Packed Single-Precision FP
Values
INSTRUCTION SET REFERENCE, A-M
VEX.128 encoded version: The source operand is an XMM register or 128- bit
memory location. The destination operation is a YMM register. The upper bits
(VLMAX-1:64) of the corresponding YMM register destination are zeroed.
VEX.256 encoded version: The source operand is a YMM register or 256- bit memory
location. The destination operation is an XMM register. The upper bits (255:128) of
the corresponding YMM register destination are zeroed.
Note: In VEX-encoded versions, VEX.vvvv is reserved and must be 1111b otherwise
instructions will #UD.
Figure 3-16. VCVTPD2PS (VEX.256 encoded version)
Operation
CVTPD2PS (128-bit Legacy SSE version)
DEST[31:0] Convert_Double_Precision_To_Single_Precision_Floating_Point(SRC[63:0])
DEST[63:32] Convert_Double_Precision_To_Single_Precision_Floating_Point(SRC[127:64])
DEST[127:64] 0
DEST[VLMAX-1:128] (unmodified)
VCVTPD2PS (VEX.128 encoded version)
DEST[31:0] Convert_Double_Precision_To_Single_Precision_Floating_Point(SRC[63:0])
DEST[63:32] Convert_Double_Precision_To_Single_Precision_Floating_Point(SRC[127:64])
DEST[VLMAX-1:64] 0
VCVTPD2PS (VEX.256 encoded version)
DEST[31:0] Convert_Double_Precision_To_Single_Precision_Floating_Point(SRC[63:0])
DEST[63:32] Convert_Double_Precision_To_Single_Precision_Floating_Point(SRC[127:64])
DEST[95:64] Convert_Double_Precision_To_Single_Precision_Floating_Point(SRC[191:128])
DEST[127:96] Convert_Double_Precision_To_Single_Precision_Floating_Point(SRC[255:192)
DEST
SRC
X0X1X2X3
X3 X2
X1 X0
0

Vol. 2A 3-255
INSTRUCTION SET REFERENCE, A-M
CVTPD2PS—Convert Packed Double-Precision FP Values to Packed Single-Precision FP
Values
DEST[255:128] 0
Intel C/C++ Compiler Intrinsic Equivalent
CVTPD2PS __m128 _mm_cvtpd_ps(__m128d a)
CVTPD2PS __m256 _mm256_cvtpd_ps (__m256d a)
SIMD Floating-Point Exceptions
Overflow, Underflow, Invalid, Precision, Denormal.
Other Exceptions
See Exceptions Type 2; additionally
#UD If VEX.vvvv != 1111B.

3-256 Vol. 2A CVTPI2PD—Convert Packed Dword Integers to Packed Double-Precision FP Values
INSTRUCTION SET REFERENCE, A-M
CVTPI2PD—Convert Packed Dword Integers to Packed Double-
Precision FP Values
Instruction Operand Encoding
Description
Converts two packed signed doubleword integers in the source operand (second
operand) to two packed double-precision floating-point values in the destination
operand (first operand).
The source operand can be an MMX technology register or a 64-bit memory location.
The destination operand is an XMM register. In addition, depending on the operand
configuration:
•For operands xmm, mm: the instruction causes a transition from x87 FPU to
MMX technology operation (that is, the x87 FPU top-of-stack pointer is set to 0
and the x87 FPU tag word is set to all 0s [valid]). If this instruction is executed
while an x87 FPU floating-point exception is pending, the exception is handled
before the CVTPI2PD instruction is executed.
•For operands xmm, m64: the instruction does not cause a transition to MMX
technology and does not take x87 FPU exceptions.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
Operation
DEST[63:0] ← Convert_Integer_To_Double_Precision_Floating_Point(SRC[31:0]);
DEST[127:64] ← Convert_Integer_To_Double_Precision_Floating_Point(SRC[63:32]);
Intel C/C++ Compiler Intrinsic Equivalent
CVTPI2PD __m128d _mm_cvtpi32_pd(__m64 a)
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
66 0F 2A /rCVTPI2PD xmm,
mm/m64*
A Valid Valid Convert two packed signed
doubleword integers from
mm/mem64 to two packed
double-precision floating-
point values in xmm.
NOTES:
*Operation is different for different operand sets; see the Description section.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA

Vol. 2A 3-257
INSTRUCTION SET REFERENCE, A-M
CVTPI2PD—Convert Packed Dword Integers to Packed Double-Precision FP Values
SIMD Floating-Point Exceptions
Precision.
Protected Mode Exceptions
#GP(0) For an illegal memory operand effective address in the CS, DS,
ES, FS or GS segments.
#SS(0) For an illegal address in the SS segment.
#PF(fault-code) For a page fault.
#NM If CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If CR0.EM[bit 2] = 1.
If CR4.OSFXSR[bit 9] = 0.
If CPUID.01H:EDX.SSE2[bit 26] = 0.
If the LOCK prefix is used.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
Real-Address Mode Exceptions
GP If any part of the operand lies outside the effective address
space from 0 to FFFFH.
#NM If CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If CR0.EM[bit 2] = 1.
If CR4.OSFXSR[bit 9] = 0.
If CPUID.01H:EDX.SSE2[bit 26] = 0.
If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
Same exceptions as in real address mode.
#PF(fault-code) For a page fault.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.

3-258 Vol. 2A CVTPI2PD—Convert Packed Dword Integers to Packed Double-Precision FP Values
INSTRUCTION SET REFERENCE, A-M
#GP(0) If the memory address is in a non-canonical form.
#PF(fault-code) For a page fault.
#NM If CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If CR0.EM[bit 2] = 1.
If CR4.OSFXSR[bit 9] = 0.
If CPUID.01H:EDX.SSE2[bit 26] = 0.
If the LOCK prefix is used.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.

Vol. 2A 3-259
INSTRUCTION SET REFERENCE, A-M
CVTPI2PS—Convert Packed Dword Integers to Packed Single-Precision FP Values
CVTPI2PS—Convert Packed Dword Integers to Packed Single-Precision
FP Values
Instruction Operand Encoding
Description
Converts two packed signed doubleword integers in the source operand (second
operand) to two packed single-precision floating-point values in the destination
operand (first operand).
The source operand can be an MMX technology register or a 64-bit memory location.
The destination operand is an XMM register. The results are stored in the low quad-
word of the destination operand, and the high quadword remains unchanged. When
a conversion is inexact, the value returned is rounded according to the rounding
control bits in the MXCSR register.
This instruction causes a transition from x87 FPU to MMX technology operation (that
is, the x87 FPU top-of-stack pointer is set to 0 and the x87 FPU tag word is set to all
0s [valid]). If this instruction is executed while an x87 FPU floating-point exception is
pending, the exception is handled before the CVTPI2PS instruction is executed.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
Operation
DEST[31:0] ← Convert_Integer_To_Single_Precision_Floating_Point(SRC[31:0]);
DEST[63:32] ← Convert_Integer_To_Single_Precision_Floating_Point(SRC[63:32]);
(* High quadword of destination unchanged *)
Intel C/C++ Compiler Intrinsic Equivalent
CVTPI2PS __m128 _mm_cvtpi32_ps(__m128 a, __m64 b)
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F 2A /rCVTPI2PS xmm,
mm/m64
A Valid Valid Convert two signed
doubleword integers from
mm/m64 to two single-
precision floating-point
values in xmm.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA

3-260 Vol. 2A CVTPI2PS—Convert Packed Dword Integers to Packed Single-Precision FP Values
INSTRUCTION SET REFERENCE, A-M
SIMD Floating-Point Exceptions
Precision.
Protected Mode Exceptions
#GP(0) For an illegal memory operand effective address in the CS, DS,
ES, FS or GS segments.
#SS(0) For an illegal address in the SS segment.
#PF(fault-code) For a page fault.
#NM If CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#XM If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 1.
#UD If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 0.
If CR0.EM[bit 2] = 1.
If CR4.OSFXSR[bit 9] = 0.
If CPUID.01H:EDX.SSE[bit 25] = 0.
If the LOCK prefix is used.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
Real-Address Mode Exceptions
GP If any part of the operand lies outside the effective address
space from 0 to FFFFH.
#NM If CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#XM If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 1.
#UD If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 0.
If CR0.EM[bit 2] = 1.
If CR4.OSFXSR[bit 9] = 0.
If CPUID.01H:EDX.SSE[bit 25] = 0.
If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
Same exceptions as in real address mode.
#PF(fault-code) For a page fault.

Vol. 2A 3-261
INSTRUCTION SET REFERENCE, A-M
CVTPI2PS—Convert Packed Dword Integers to Packed Single-Precision FP Values
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#PF(fault-code) For a page fault.
#NM If CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#XM If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 1.
#UD If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 0.
If CR0.EM[bit 2] = 1.
If CR4.OSFXSR[bit 9] = 0.
If CPUID.01H:EDX.SSE[bit 25] = 0.
If the LOCK prefix is used.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
3-262 Vol. 2A CVTPS2DQ—Convert Packed Single-Precision FP Values to Packed Dword Integers
INSTRUCTION SET REFERENCE, A-M
CVTPS2DQ—Convert Packed Single-Precision FP Values to Packed
Dword Integers
Instruction Operand Encoding
Description
Converts four or eight packed single-precision floating-point values in the source
operand to four or eight signed doubleword integers in the destination operand.
When a conversion is inexact, the value returned is rounded according to the
rounding control bits in the MXCSR register. If a converted result is larger than the
maximum signed doubleword integer, the floating-point invalid exception is raised,
and if this exception is masked, the indefinite integer value (80000000H) is returned.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
128-bit Legacy SSE version: The source operand is an XMM register or 128- bit
memory location. The destination operation is an XMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are unmodified.
VEX.128 encoded version: The source operand is an XMM register or 128- bit
memory location. The destination operation is a YMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are zeroed.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 5B /r
CVTPS2DQ xmm1, xmm2/m128
A V/V SSE2 Convert four packed single-
precision floating-point
values from xmm2/m128 to
four packed signed
doubleword integers in
xmm1.
VEX.128.66.0F.WIG 5B /r
VCVTPS2DQ xmm1, xmm2/m128
A V/V AVX Convert four packed single
precision floating-point
values from xmm2/mem to
four packed signed
doubleword values in xmm1.
VEX.256.66.0F.WIG 5B /r
VCVTPS2DQ ymm1, ymm2/m256
A V/V AVX Convert eight packed single
precision floating-point
values from ymm2/mem to
eight packed signed
doubleword values in ymm1.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA

Vol. 2A 3-263
INSTRUCTION SET REFERENCE, A-M
CVTPS2DQ—Convert Packed Single-Precision FP Values to Packed Dword Integers
VEX.256 encoded version: The source operand is a YMM register or 256- bit memory
location. The destination operation is a YMM register.
Note: In VEX-encoded versions, VEX.vvvv is reserved and must be 1111b otherwise
instructions will #UD.
Operation
CVTPS2DQ (128-bit Legacy SSE version)
DEST[31:0] Convert_Single_Precision_Floating_Point_To_Integer(SRC[31:0])
DEST[63:32] Convert_Single_Precision_Floating_Point_To_Integer(SRC[63:32])
DEST[95:64] Convert_Single_Precision_Floating_Point_To_Integer(SRC[95:64])
DEST[127:96] Convert_Single_Precision_Floating_Point_To_Integer(SRC[127:96])
DEST[VLMAX-1:128] (unmodified)
VCVTPS2DQ (VEX.128 encoded version)
DEST[31:0] Convert_Single_Precision_Floating_Point_To_Integer(SRC[31:0])
DEST[63:32] Convert_Single_Precision_Floating_Point_To_Integer(SRC[63:32])
DEST[95:64] Convert_Single_Precision_Floating_Point_To_Integer(SRC[95:64])
DEST[127:96] Convert_Single_Precision_Floating_Point_To_Integer(SRC[127:96])
DEST[VLMAX-1:128] 0
VCVTPS2DQ (VEX.256 encoded version)
DEST[31:0] Convert_Single_Precision_Floating_Point_To_Integer(SRC[31:0])
DEST[63:32] Convert_Single_Precision_Floating_Point_To_Integer(SRC[63:32])
DEST[95:64] Convert_Single_Precision_Floating_Point_To_Integer(SRC[95:64])
DEST[127:96] Convert_Single_Precision_Floating_Point_To_Integer(SRC[127:96)
DEST[159:128] Convert_Single_Precision_Floating_Point_To_Integer(SRC[159:128])
DEST[191:160] Convert_Single_Precision_Floating_Point_To_Integer(SRC[191:160])
DEST[223:192] Convert_Single_Precision_Floating_Point_To_Integer(SRC[223:192])
DEST[255:224] Convert_Single_Precision_Floating_Point_To_Integer(SRC[255:224])
Intel C/C++ Compiler Intrinsic Equivalent
CVTPS2DQ __m128i _mm_cvtps_epi32(__m128 a)
VCVTPS2DQ __ m256i _mm256_cvtps_epi32 (__m256 a)
SIMD Floating-Point Exceptions
Invalid, Precision.
Other Exceptions
See Exceptions Type 2; additionally
#UD If VEX.vvvv != 1111B.
3-264 Vol. 2A CVTPS2PD—Convert Packed Single-Precision FP Values to Packed Double-Precision FP
Values
INSTRUCTION SET REFERENCE, A-M
CVTPS2PD—Convert Packed Single-Precision FP Values to Packed
Double-Precision FP Values
Instruction Operand Encoding
Description
Converts two or four packed single-precision floating-point values in the source
operand (second operand) to two or four packed double-precision floating-point
values in the destination operand (first operand).
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
128-bit Legacy SSE version: The source operand is an XMM register or 64- bit
memory location. The destination operation is an XMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are unmodified.
VEX.128 encoded version: The source operand is an XMM register or 64- bit memory
location. The destination operation is a YMM register. The upper bits (VLMAX-1:128)
of the corresponding YMM register destination are zeroed.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
0F 5A /r
CVTPS2PD xmm1, xmm2/m64
A V/V SSE2 Convert two packed single-
precision floating-point
values in xmm2/m64 to two
packed double-precision
floating-point values in
xmm1.
VEX.128.0F.WIG 5A /r
VCVTPS2PD xmm1, xmm2/m64
AV/V AVX Convert two packed single-
precision floating-point
values in xmm2/mem to two
packed double-precision
floating-point values in
xmm1.
VEX.256.0F.WIG 5A /r
VCVTPS2PD ymm1, xmm2/m128
A V/V AVX Convert four packed single-
precision floating-point
values in xmm2/mem to
four packed double-
precision floating-point
values in ymm1.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA

Vol. 2A 3-265
INSTRUCTION SET REFERENCE, A-M
CVTPS2PD—Convert Packed Single-Precision FP Values to Packed Double-Precision FP
Values
VEX.256 encoded version: The source operand is an XMM register or 128- bit
memory location. The destination operation is a YMM register.
Note: In VEX-encoded versions, VEX.vvvv is reserved and must be 1111b otherwise
instructions will #UD.
Figure 3-17. CVTPS2PD (VEX.256 encoded version)
Operation
CVTPS2PD (128-bit Legacy SSE version)
DEST[63:0] Convert_Single_Precision_To_Double_Precision_Floating_Point(SRC[31:0])
DEST[127:64] Convert_Single_Precision_To_Double_Precision_Floating_Point(SRC[63:32])
DEST[VLMAX-1:128] (unmodified)
VCVTPS2PD (VEX.128 encoded version)
DEST[63:0] Convert_Single_Precision_To_Double_Precision_Floating_Point(SRC[31:0])
DEST[127:64] Convert_Single_Precision_To_Double_Precision_Floating_Point(SRC[63:32])
DEST[VLMAX-1:128] 0
VCVTPS2PD (VEX.256 encoded version)
DEST[63:0] Convert_Single_Precision_To_Double_Precision_Floating_Point(SRC[31:0])
DEST[127:64] Convert_Single_Precision_To_Double_Precision_Floating_Point(SRC[63:32])
DEST[191:128] Convert_Single_Precision_To_Double_Precision_Floating_Point(SRC[95:64])
DEST[255:192] Convert_Single_Precision_To_Double_Precision_Floating_Point(SRC[127:96)
Intel C/C++ Compiler Intrinsic Equivalent
CVTPS2PD __m128d _mm_cvtps_pd(__m128 a)
VCVTPS2PD __m256d _mm256_cvtps_pd (__m128 a)
DEST
SRC X0X1X2X3
X3 X2
X1 X0

3-266 Vol. 2A CVTPS2PD—Convert Packed Single-Precision FP Values to Packed Double-Precision FP
Values
INSTRUCTION SET REFERENCE, A-M
SIMD Floating-Point Exceptions
Invalid, Denormal.
Other Exceptions
See Exceptions Type 3; additionally
#UDIf VEX.vvvv != 1111B.

Vol. 2A 3-267
INSTRUCTION SET REFERENCE, A-M
CVTPS2PI—Convert Packed Single-Precision FP Values to Packed Dword Integers
CVTPS2PI—Convert Packed Single-Precision FP Values to Packed
Dword Integers
Instruction Operand Encoding
Description
Converts two packed single-precision floating-point values in the source operand
(second operand) to two packed signed doubleword integers in the destination
operand (first operand).
The source operand can be an XMM register or a 128-bit memory location. The desti-
nation operand is an MMX technology register. When the source operand is an XMM
register, the two single-precision floating-point values are contained in the low quad-
word of the register. When a conversion is inexact, the value returned is rounded
according to the rounding control bits in the MXCSR register. If a converted result is
larger than the maximum signed doubleword integer, the floating-point invalid
exception is raised, and if this exception is masked, the indefinite integer value
(80000000H) is returned.
CVTPS2PI causes a transition from x87 FPU to MMX technology operation (that is, the
x87 FPU top-of-stack pointer is set to 0 and the x87 FPU tag word is set to all 0s
[valid]). If this instruction is executed while an x87 FPU floating-point exception is
pending, the exception is handled before the CVTPS2PI instruction is executed.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
Operation
DEST[31:0] ← Convert_Single_Precision_Floating_Point_To_Integer(SRC[31:0]);
DEST[63:32] ← Convert_Single_Precision_Floating_Point_To_Integer(SRC[63:32]);
Intel C/C++ Compiler Intrinsic Equivalent
CVTPS2PI __m64 _mm_cvtps_pi32(__m128 a)
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F 2D /rCVTPS2PI mm,
xmm/m64
A Valid Valid Convert two packed single-
precision floating-point
values from xmm/m64 to
two packed signed
doubleword integers in mm.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA

3-268 Vol. 2A CVTPS2PI—Convert Packed Single-Precision FP Values to Packed Dword Integers
INSTRUCTION SET REFERENCE, A-M
SIMD Floating-Point Exceptions
Invalid, Precision.
Protected Mode Exceptions
#GP(0) For an illegal memory operand effective address in the CS, DS,
ES, FS or GS segments.
#SS(0) For an illegal address in the SS segment.
#PF(fault-code) For a page fault.
#MF If there is a pending x87 FPU exception.
#NM If CR0.TS[bit 3] = 1.
#XM If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 1.
#UD If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 0.
If CR0.EM[bit 2] = 1.
If CR4.OSFXSR[bit 9] = 0.
If CPUID.01H:EDX.SSE[bit 25] = 0.
If the LOCK prefix is used.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
Real-Address Mode Exceptions
GP If any part of the operand lies outside the effective address
space from 0 to FFFFH.
#NM If CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#XM If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 1.
#UD If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 0.
If CR0.EM[bit 2] = 1.
If CR4.OSFXSR[bit 9] = 0.
If CPUID.01H:EDX.SSE[bit 25] = 0.
If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
Same exceptions as in real address mode.
#PF(fault-code) For a page fault.

Vol. 2A 3-269
INSTRUCTION SET REFERENCE, A-M
CVTPS2PI—Convert Packed Single-Precision FP Values to Packed Dword Integers
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#PF(fault-code) For a page fault.
#NM If CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#XM If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 1.
#UD If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 0.
If CR0.EM[bit 2] = 1.
If CR4.OSFXSR[bit 9] = 0.
If CPUID.01H:EDX.SSE[bit 25] = 0.
If the LOCK prefix is used.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
3-270 Vol. 2A CVTSD2SI—Convert Scalar Double-Precision FP Value to Integer
INSTRUCTION SET REFERENCE, A-M
CVTSD2SI—Convert Scalar Double-Precision FP Value to Integer
Instruction Operand Encoding
Description
Converts a double-precision floating-point value in the source operand (second
operand) to a signed doubleword integer in the destination operand (first operand).
The source operand can be an XMM register or a 64-bit memory location. The desti-
nation operand is a general-purpose register. When the source operand is an XMM
register, the double-precision floating-point value is contained in the low quadword of
the register.
When a conversion is inexact, the value returned is rounded according to the
rounding control bits in the MXCSR register. If a converted result is larger than the
maximum signed doubleword integer, the floating-point invalid exception is raised,
and if this exception is masked, the indefinite integer value (80000000H) is returned.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F2 0F 2D /r
CVTSD2SI r32, xmm/m64
A V/V SSE2 Convert one double-
precision floating-point
value from xmm/m64 to
one signed doubleword
integer r32.
F2 REX.W 0F 2D /r
CVTSD2SI r64, xmm/m64
A V/N.E. SSE2 Convert one double-
precision floating-point
value from xmm/m64 to
one signed quadword
integer sign-extended into
r64.
VEX.LIG.F2.0F.W0 2D /r
VCVTSD2SI r32, xmm1/m64
A V/V AVX Convert one double
precision floating-point
value from xmm1/m64 to
one signed doubleword
integer r32.
VEX.LIG.F2.0F.W1 2D /r
VCVTSD2SI r64, xmm1/m64
A V/N.E. AVX Convert one double
precision floating-point
value from xmm1/m64 to
one signed quadword
integer sign-extended into
r64.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA

Vol. 2A 3-271
INSTRUCTION SET REFERENCE, A-M
CVTSD2SI—Convert Scalar Double-Precision FP Value to Integer
In 64-bit mode, the instruction can access additional registers (XMM8-XMM15,
R8-R15) when used with a REX.R prefix. Use of the REX.W prefix promotes the
instruction to 64-bit operation. See the summary chart at the beginning of this
section for encoding data and limits.
Legacy SSE instructions: Use of the REX.W prefix promotes the instruction to 64-bit
operation. See the summary chart at the beginning of this section for encoding data
and limits.
Note: In VEX-encoded versions, VEX.vvvv is reserved and must be 1111b, otherwise
instructions will #UD.
Operation
IF 64-Bit Mode and OperandSize = 64
THEN
DEST[63:0] ← Convert_Double_Precision_Floating_Point_To_Integer64(SRC[63:0]);
ELSE
DEST[31:0] ← Convert_Double_Precision_Floating_Point_To_Integer32(SRC[63:0]);
FI;
Intel C/C++ Compiler Intrinsic Equivalent
int _mm_cvtsd_si32(__m128d a)
__int64 _mm_cvtsd_si64(__m128d a)
SIMD Floating-Point Exceptions
Invalid, Precision.
Other Exceptions
See Exceptions Type 3; additionally
#UD If VEX.vvvv != 1111B.

3-272 Vol. 2A CVTSD2SS—Convert Scalar Double-Precision FP Value to Scalar Single-Precision FP Val-
ue
INSTRUCTION SET REFERENCE, A-M
CVTSD2SS—Convert Scalar Double-Precision FP Value to Scalar Single-
Precision FP Value
Instruction Operand Encoding
Description
Converts a double-precision floating-point value in the source operand (second
operand) to a single-precision floating-point value in the destination operand (first
operand).
The source operand can be an XMM register or a 64-bit memory location. The desti-
nation operand is an XMM register. When the source operand is an XMM register, the
double-precision floating-point value is contained in the low quadword of the register.
The result is stored in the low doubleword of the destination operand, and the upper
3 doublewords are left unchanged. When the conversion is inexact, the value
returned is rounded according to the rounding control bits in the MXCSR register.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
128-bit Legacy SSE version: The destination and first source operand are the same.
Bits (VLMAX-1:32) of the corresponding YMM destination register remain unchanged.
VEX.128 encoded version: Bits (127:64) of the XMM register destination are copied
from corresponding bits in the first source operand. Bits (VLMAX-1:128) of the desti-
nation YMM register are zeroed.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F2 0F 5A /r
CVTSD2SS xmm1, xmm2/m64
A V/V SSE2 Convert one double-
precision floating-point
value in xmm2/m64 to one
single-precision floating-
point value in xmm1.
VEX.NDS.LIG.F2.0F.WIG 5A /r
VCVTSD2SS xmm1,xmm2,
xmm3/m64
B V/V AVX Convert one double-
precision floating-point
value in xmm3/m64 to one
single-precision floating-
point value and merge with
high bits in xmm2.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

Vol. 2A 3-273
INSTRUCTION SET REFERENCE, A-M
CVTSD2SS—Convert Scalar Double-Precision FP Value to Scalar Single-Precision FP Val-
ue
Operation
CVTSD2SS (128-bit Legacy SSE version)
DEST[31:0] Convert_Double_Precision_To_Single_Precision_Floating_Point(SRC[63:0]);
(* DEST[VLMAX-1:32] Unmodified *)
VCVTSD2SS (VEX.128 encoded version)
DEST[31:0] Convert_Double_Precision_To_Single_Precision_Floating_Point(SRC2[63:0]);
DEST[127:32] SRC1[127:32]
DEST[VLMAX-1:128] 0
Intel C/C++ Compiler Intrinsic Equivalent
CVTSD2SS __m128 _mm_cvtsd_ss(__m128 a, __m128d b)
SIMD Floating-Point Exceptions
Overflow, Underflow, Invalid, Precision, Denormal.
Other Exceptions
See Exceptions Type 3.

3-274 Vol. 2A CVTSI2SD—Convert Dword Integer to Scalar Double-Precision FP Value
INSTRUCTION SET REFERENCE, A-M
CVTSI2SD—Convert Dword Integer to Scalar Double-Precision FP Value
Instruction Operand Encoding
Description
Converts a signed doubleword integer (or signed quadword integer if operand size is
64 bits) in the second source operand to a double-precision floating-point value in
the destination operand. The result is stored in the low quadword of the destination
operand, and the high quadword left unchanged. When conversion is inexact, the
value returned is rounded according to the rounding control bits in the MXCSR
register.
Legacy SSE instructions: Use of the REX.W prefix promotes the instruction to 64-bit
operands. See the summary chart at the beginning of this section for encoding data
and limits.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F2 0F 2A /r
CVTSI2SD xmm, r/m32
A V/V SSE2 Convert one signed
doubleword integer from
r/m32 to one double-
precision floating-point
value in xmm.
F2 REX.W 0F 2A /r
CVTSI2SD xmm, r/m64
A V/N.E. SSE2 Convert one signed
quadword integer from
r/m64 to one double-
precision floating-point
value in xmm.
VEX.NDS.LIG.F2.0F.W0 2A /r
VCVTSI2SD xmm1, xmm2, r/m32
B V/V AVX Convert one signed
doubleword integer from
r/m32 to one double-
precision floating-point
value in xmm1.
VEX.NDS.LIG.F2.0F.W1 2A /r
VCVTSI2SD xmm1, xmm2, r/m64
B V/N.E. AVX Convert one signed
quadword integer from
r/m64 to one double-
precision floating-point
value in xmm1.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

Vol. 2A 3-275
INSTRUCTION SET REFERENCE, A-M
CVTSI2SD—Convert Dword Integer to Scalar Double-Precision FP Value
The second source operand can be a general-purpose register or a 32/64-bit memory
location. The first source and destination operands are XMM registers.
128-bit Legacy SSE version: The destination and first source operand are the same.
Bits (VLMAX-1:64) of the corresponding YMM destination register remain unchanged.
VEX.128 encoded version: Bits (127:64) of the XMM register destination are copied
from corresponding bits in the first source operand. Bits (VLMAX-1:128) of the desti-
nation YMM register are zeroed.
Operation
CVTSI2SD
IF 64-Bit Mode And OperandSize = 64
THEN
DEST[63:0] Convert_Integer_To_Double_Precision_Floating_Point(SRC[63:0]);
ELSE
DEST[63:0] Convert_Integer_To_Double_Precision_Floating_Point(SRC[31:0]);
FI;
DEST[VLMAX-1:64] (Unmodified)
VCVTSI2SD
IF 64-Bit Mode And OperandSize = 64
THEN
DEST[63:0] Convert_Integer_To_Double_Precision_Floating_Point(SRC2[63:0]);
ELSE
DEST[63:0] Convert_Integer_To_Double_Precision_Floating_Point(SRC2[31:0]);
FI;
DEST[127:64] SRC1[127:64]
DEST[VLMAX-1:128] 0
Intel C/C++ Compiler Intrinsic Equivalent
CVTSI2SD __m128d _mm_cvtsi32_sd(__m128d a, int b)
CVTSI2SD __m128d _mm_cvtsi64_sd(__m128d a, __int64 b)
SIMD Floating-Point Exceptions
Precision.
Other Exceptions
See Exceptions Type 3.

3-276 Vol. 2A CVTSI2SS—Convert Dword Integer to Scalar Single-Precision FP Value
INSTRUCTION SET REFERENCE, A-M
CVTSI2SS—Convert Dword Integer to Scalar Single-Precision FP Value
Instruction Operand Encoding
Description
Converts a signed doubleword integer (or signed quadword integer if operand size is
64 bits) in the source operand (second operand) to a single-precision floating-point
value in the destination operand (first operand). The source operand can be a
general-purpose register or a memory location. The destination operand is an XMM
register. The result is stored in the low doubleword of the destination operand, and
the upper three doublewords are left unchanged. When a conversion is inexact, the
value returned is rounded according to the rounding control bits in the MXCSR
register.
Legacy SSE instructions: In 64-bit mode, the instruction can access additional regis-
ters (XMM8-XMM15, R8-R15) when used with a REX.R prefix. Use of the REX.W
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F3 0F 2A /r
CVTSI2SS xmm, r/m32
A V/V SSE Convert one signed
doubleword integer from
r/m32 to one single-
precision floating-point
value in xmm.
F3 REX.W 0F 2A /r
CVTSI2SS xmm, r/m64
A V/N.E. SSE Convert one signed
quadword integer from
r/m64 to one single-
precision floating-point
value in xmm.
VEX.NDS.LIG.F3.0F.W0 2A /r
VCVTSI2SS xmm1, xmm2, r/m32
B V/V AVX Convert one signed
doubleword integer from
r/m32 to one single-
precision floating-point
value in xmm1.
VEX.NDS.LIG.F3.0F.W1 2A /r
VCVTSI2SS xmm1, xmm2, r/m64
B V/N.E. AVX Convert one signed
quadword integer from
r/m64 to one single-
precision floating-point
value in xmm1.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

Vol. 2A 3-277
INSTRUCTION SET REFERENCE, A-M
CVTSI2SS—Convert Dword Integer to Scalar Single-Precision FP Value
prefix promotes the instruction to 64-bit operands. See the summary chart at the
beginning of this section for encoding data and limits.
128-bit Legacy SSE version: The destination and first source operand are the same.
Bits (VLMAX-1:32) of the corresponding YMM destination register remain unchanged.
VEX.128 encoded version: Bits (127:32) of the XMM register destination are copied
from corresponding bits in the first source operand. Bits (VLMAX-1:128) of the desti-
nation YMM register are zeroed.
Operation
CVTSI2SS (128-bit Legacy SSE version)
IF 64-Bit Mode And OperandSize = 64
THEN
DEST[31:0] Convert_Integer_To_Single_Precision_Floating_Point(SRC[63:0]);
ELSE
DEST[31:0] Convert_Integer_To_Single_Precision_Floating_Point(SRC[31:0]);
FI;
DEST[VLMAX-1:32] (Unmodified)
VCVTSI2SS (VEX.128 encoded version)
IF 64-Bit Mode And OperandSize = 64
THEN
DEST[31:0] Convert_Integer_To_Single_Precision_Floating_Point(SRC[63:0]);
ELSE
DEST[31:0] Convert_Integer_To_Single_Precision_Floating_Point(SRC[31:0]);
FI;
DEST[127:32] SRC1[127:32]
DEST[VLMAX-1:128] 0
Intel C/C++ Compiler Intrinsic Equivalent
CVTSI2SS __m128 _mm_cvtsi32_ss(__m128 a, int b)
CVTSI2SS __m128 _mm_cvtsi64_ss(__m128 a, __int64 b)
SIMD Floating-Point Exceptions
Precision.
Other Exceptions
See Exceptions Type 3.

3-278 Vol. 2A CVTSS2SD—Convert Scalar Single-Precision FP Value to Scalar Double-Precision FP Val-
ue
INSTRUCTION SET REFERENCE, A-M
CVTSS2SD—Convert Scalar Single-Precision FP Value to Scalar Double-
Precision FP Value
Instruction Operand Encoding
Description
Converts a single-precision floating-point value in the source operand (second
operand) to a double-precision floating-point value in the destination operand (first
operand). The source operand can be an XMM register or a 32-bit memory location.
The destination operand is an XMM register. When the source operand is an XMM
register, the single-precision floating-point value is contained in the low doubleword
of the register. The result is stored in the low quadword of the destination operand,
and the high quadword is left unchanged.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
128-bit Legacy SSE version: The destination and first source operand are the same.
Bits (VLMAX-1:64) of the corresponding YMM destination register remain unchanged.
VEX.128 encoded version: Bits (127:64) of the XMM register destination are copied
from corresponding bits in the first source operand. Bits (VLMAX-1:128) of the desti-
nation YMM register are zeroed.
Operation
CVTSS2SD (128-bit Legacy SSE version)
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F3 0F 5A /r
CVTSS2SD xmm1, xmm2/m32
A V/V SSE2 Convert one single-precision
floating-point value in
xmm2/m32 to one double-
precision floating-point
value in xmm1.
VEX.NDS.LIG.F3.0F.WIG 5A /r
VCVTSS2SD xmm1, xmm2,
xmm3/m32
B V/V AVX Convert one single-precision
floating-point value in
xmm3/m32 to one double-
precision floating-point
value and merge with high
bits of xmm2.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

Vol. 2A 3-279
INSTRUCTION SET REFERENCE, A-M
CVTSS2SD—Convert Scalar Single-Precision FP Value to Scalar Double-Precision FP Val-
ue
DEST[63:0] Convert_Single_Precision_To_Double_Precision_Floating_Point(SRC[31:0]);
DEST[VLMAX-1:64] (Unmodified)
VCVTSS2SD (VEX.128 encoded version)
DEST[63:0] Convert_Single_Precision_To_Double_Precision_Floating_Point(SRC2[31:0])
DEST[127:64] SRC1[127:64]
DEST[VLMAX-1:128] 0
Intel C/C++ Compiler Intrinsic Equivalent
CVTSS2SD __m128d _mm_cvtss_sd(__m128d a, __m128 b)
SIMD Floating-Point Exceptions
Invalid, Denormal.
Other Exceptions
See Exceptions Type 3.
3-280 Vol. 2A CVTSS2SI—Convert Scalar Single-Precision FP Value to Dword Integer
INSTRUCTION SET REFERENCE, A-M
CVTSS2SI—Convert Scalar Single-Precision FP Value to Dword Integer
Instruction Operand Encoding
Description
Converts a single-precision floating-point value in the source operand (second
operand) to a signed doubleword integer (or signed quadword integer if operand size
is 64 bits) in the destination operand (first operand). The source operand can be an
XMM register or a memory location. The destination operand is a general-purpose
register. When the source operand is an XMM register, the single-precision floating-
point value is contained in the low doubleword of the register.
When a conversion is inexact, the value returned is rounded according to the
rounding control bits in the MXCSR register. If a converted result is larger than the
maximum signed doubleword integer, the floating-point invalid exception is raised,
and if this exception is masked, the indefinite integer value (80000000H) is returned.
In 64-bit mode, the instruction can access additional registers (XMM8-XMM15,
R8-R15) when used with a REX.R prefix. Use of the REX.W prefix promotes the
instruction to 64-bit operands. See the summary chart at the beginning of this
section for encoding data and limits.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F3 0F 2D /r
CVTSS2SI r32, xmm/m32
A V/V SSE Convert one single-precision
floating-point value from
xmm/m32 to one signed
doubleword integer in r32.
F3 REX.W 0F 2D /r
CVTSS2SI r64, xmm/m32
A V/N.E. SSE Convert one single-precision
floating-point value from
xmm/m32 to one signed
quadword integer in r64.
VEX.LIG.F3.0F.W0 2D /r
VCVTSS2SI r32, xmm1/m32
A V/V AVX Convert one single-precision
floating-point value from
xmm1/m32 to one signed
doubleword integer in r32.
VEX.LIG.F3.0F.W1 2D /r
VCVTSS2SI r64, xmm1/m32
A V/N.E. AVX Convert one single-precision
floating-point value from
xmm1/m32 to one signed
quadword integer in r64.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA

Vol. 2A 3-281
INSTRUCTION SET REFERENCE, A-M
CVTSS2SI—Convert Scalar Single-Precision FP Value to Dword Integer
Legacy SSE instructions: In 64-bit mode, Use of the REX.W prefix promotes the
instruction to 64-bit operands. See the summary chart at the beginning of this
section for encoding data and limits.
Note: In VEX-encoded versions, VEX.vvvv is reserved and must be 1111b, otherwise
instructions will #UD.
Operation
IF 64-bit Mode and OperandSize = 64
THEN
DEST[64:0] ← Convert_Single_Precision_Floating_Point_To_Integer(SRC[31:0]);
ELSE
DEST[31:0] ← Convert_Single_Precision_Floating_Point_To_Integer(SRC[31:0]);
FI;
Intel C/C++ Compiler Intrinsic Equivalent
int _mm_cvtss_si32(__m128d a)
__int64 _mm_cvtss_si64(__m128d a)
SIMD Floating-Point Exceptions
Invalid, Precision.
Other Exceptions
See Exceptions Type 3; additionally
#UFD If VEX.vvvv != 1111B.
3-282 Vol. 2A CVTTPD2DQ—Convert with Truncation Packed Double-Precision FP Values to Packed
Dword Integers
INSTRUCTION SET REFERENCE, A-M
CVTTPD2DQ—Convert with Truncation Packed Double-Precision FP
Values to Packed Dword Integers
Instruction Operand Encoding
Description
Converts two or four packed double-precision floating-point values in the source
operand (second operand) to two or four packed signed doubleword integers in the
destination operand (first operand).
When a conversion is inexact, a truncated (round toward zero) value is returned.If a
converted result is larger than the maximum signed doubleword integer, the floating-
point invalid exception is raised, and if this exception is masked, the indefinite
integer value (80000000H) is returned.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
128-bit Legacy SSE version: The source operand is an XMM register or 128- bit
memory location. The destination operation is an XMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are unmodified.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F E6
CVTTPD2DQ xmm1, xmm2/m128
A V/V SSE2 Convert two packed double-
precision floating-point
values from xmm2/m128 to
two packed signed
doubleword integers in
xmm1 using truncation.
VEX.128.66.0F.WIG E6 /r
VCVTTPD2DQ xmm1, xmm2/m128
A V/V AVX Convert two packed double-
precision floating-point
values in xmm2/mem to two
signed doubleword integers
in xmm1 using truncation.
VEX.256.66.0F.WIG E6 /r
VCVTTPD2DQ xmm1, ymm2/m256
A V/V AVX Convert four packed double-
precision floating-point
values in ymm2/mem to
four signed doubleword
integers in xmm1 using
truncation.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA
Vol. 2A 3-283
INSTRUCTION SET REFERENCE, A-M
CVTTPD2DQ—Convert with Truncation Packed Double-Precision FP Values to Packed
Dword Integers
VEX.128 encoded version: The source operand is an XMM register or 128- bit
memory location. The destination operation is a YMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are zeroed.
VEX.256 encoded version: The source operand is a YMM register or 256- bit memory
location. The destination operation is an XMM register. The upper bits (255:128) of
the corresponding YMM register destination are zeroed.
Note: In VEX-encoded versions, VEX.vvvv is reserved and must be 1111b, otherwise
instructions will #UD.
Figure 3-18. VCVTTPD2DQ (VEX.256 encoded version)
Operation
CVTTPD2DQ (128-bit Legacy SSE version)
DEST[31:0] Convert_Double_Precision_Floating_Point_To_Integer_Truncate(SRC[63:0])
DEST[63:32] Convert_Double_Precision_Floating_Point_To_Integer_Truncate(SRC[127:64])
DEST[127:64] 0
DEST[VLMAX-1:128] (unmodified)
VCVTTPD2DQ (VEX.128 encoded version)
DEST[31:0] Convert_Double_Precision_Floating_Point_To_Integer_Truncate(SRC[63:0])
DEST[63:32] Convert_Double_Precision_Floating_Point_To_Integer_Truncate(SRC[127:64])
DEST[VLMAX-1:64] 0
VCVTTPD2DQ (VEX.256 encoded version)
DEST[31:0] Convert_Double_Precision_Floating_Point_To_Integer_Truncate(SRC[63:0])
DEST[63:32] Convert_Double_Precision_Floating_Point_To_Integer_Truncate(SRC[127:64])
DEST[95:64] Convert_Double_Precision_Floating_Point_To_Integer_Truncate(SRC[191:128])
DEST[127:96] Convert_Double_Precision_Floating_Point_To_Integer_Truncate(SRC[255:192)
DEST
SRC
X0X1X2X3
X3 X2
X1 X0
0

3-284 Vol. 2A CVTTPD2DQ—Convert with Truncation Packed Double-Precision FP Values to Packed
Dword Integers
INSTRUCTION SET REFERENCE, A-M
DEST[255:128] 0
Intel C/C++ Compiler Intrinsic Equivalent
CVTTPD2DQ __m128i _mm_cvttpd_epi32(__m128d a)
VCVTTPD2DQ __m128i _mm256_cvttpd_epi32 (__m256d src)
SIMD Floating-Point Exceptions
Invalid, Precision.
Other Exceptions
See Exceptions Type 2; additionally
#UFD If VEX.vvvv != 1111B.

Vol. 2A 3-285
INSTRUCTION SET REFERENCE, A-M
CVTTPD2PI—Convert with Truncation Packed Double-Precision FP Values to Packed
Dword Integers
CVTTPD2PI—Convert with Truncation Packed Double-Precision FP
Values to Packed Dword Integers
Instruction Operand Encoding
Description
Converts two packed double-precision floating-point values in the source operand
(second operand) to two packed signed doubleword integers in the destination
operand (first operand). The source operand can be an XMM register or a 128-bit
memory location. The destination operand is an MMX technology register.
When a conversion is inexact, a truncated (round toward zero) result is returned. If a
converted result is larger than the maximum signed doubleword integer, the floating-
point invalid exception is raised, and if this exception is masked, the indefinite
integer value (80000000H) is returned.
This instruction causes a transition from x87 FPU to MMX technology operation (that
is, the x87 FPU top-of-stack pointer is set to 0 and the x87 FPU tag word is set to all
0s [valid]). If this instruction is executed while an x87 FPU floating-point exception is
pending, the exception is handled before the CVTTPD2PI instruction is executed.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
Operation
DEST[31:0] ← Convert_Double_Precision_Floating_Point_To_Integer32_Truncate(SRC[63:0]);
DEST[63:32] ← Convert_Double_Precision_Floating_Point_To_Integer32_
Truncate(SRC[127:64]);
Intel C/C++ Compiler Intrinsic Equivalent
CVTTPD1PI __m64 _mm_cvttpd_pi32(__m128d a)
Opcode/
Instruction
Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
66 0F 2C /r
CVTTPD2PI mm, xmm/m128
A Valid Valid Convert two packer double-
precision floating-point
values from xmm/m128 to
two packed signed
doubleword integers in mm
using truncation.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA

3-286 Vol. 2A CVTTPD2PI—Convert with Truncation Packed Double-Precision FP Values to Packed
Dword Integers
INSTRUCTION SET REFERENCE, A-M
SIMD Floating-Point Exceptions
Invalid, Precision.
Protected Mode Exceptions
#GP(0) For an illegal memory operand effective address in the CS, DS,
ES, FS or GS segments.
If a memory operand is not aligned on a 16-byte boundary,
regardless of segment.
#SS(0) For an illegal address in the SS segment.
#PF(fault-code) For a page fault.
#MF If there is a pending x87 FPU exception.
#NM If CR0.TS[bit 3] = 1.
#XM If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 1.
#UD If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 0.
If CR0.EM[bit 2] = 1.
If CR4.OSFXSR[bit 9] = 0.
If CPUID.01H:EDX.SSE2[bit 26] = 0.
If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand is not aligned on a 16-byte boundary,
regardless of segment.
If any part of the operand lies outside the effective address
space from 0 to FFFFH.
#NM If CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#XM If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 1.
#UD If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 0.
If CR0.EM[bit 2] = 1.
If CR4.OSFXSR[bit 9] = 0.
If CPUID.01H:EDX.SSE2[bit 26] = 0.
If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
Same exceptions as in real address mode.

Vol. 2A 3-287
INSTRUCTION SET REFERENCE, A-M
CVTTPD2PI—Convert with Truncation Packed Double-Precision FP Values to Packed
Dword Integers
#PF(fault-code) For a page fault.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
If memory operand is not aligned on a 16-byte boundary,
regardless of segment.
#PF(fault-code) For a page fault.
#NM If CR0.TS[bit 3] = 1.
#XM If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 1.
#UD If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 0.
If CR0.EM[bit 2] = 1.
If CR4.OSFXSR[bit 9] = 0.
If CPUID.01H:EDX.SSE2[bit 26] = 0.
If the LOCK prefix is used.
3-288 Vol. 2A CVTTPS2DQ—Convert with Truncation Packed Single-Precision FP Values to Packed
Dword Integers
INSTRUCTION SET REFERENCE, A-M
CVTTPS2DQ—Convert with Truncation Packed Single-Precision FP
Values to Packed Dword Integers
Instruction Operand Encoding
Description
Converts four or eight packed single-precision floating-point values in the source
operand to four or eight signed doubleword integers in the destination operand.
When a conversion is inexact, a truncated (round toward zero) value is returned.If a
converted result is larger than the maximum signed doubleword integer, the floating-
point invalid exception is raised, and if this exception is masked, the indefinite
integer value (80000000H) is returned.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
128-bit Legacy SSE version: The source operand is an XMM register or 128- bit
memory location. The destination operation is an XMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are unmodified.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F3 0F 5B /r
CVTTPS2DQ xmm1, xmm2/m128
A V/V SSE2 Convert four single-
precision floating-point
values from xmm2/m128 to
four signed doubleword
integers in xmm1 using
truncation.
VEX.128.F3.0F.WIG 5B /r
VCVTTPS2DQ xmm1, xmm2/m128
A V/V AVX Convert four packed single
precision floating-point
values from xmm2/mem to
four packed signed
doubleword values in xmm1
using truncation.
VEX.256.F3.0F.WIG 5B /r
VCVTTPS2DQ ymm1, ymm2/m256
A V/V AVX Convert eight packed single
precision floating-point
values from ymm2/mem to
eight packed signed
doubleword values in ymm1
using truncation.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA

Vol. 2A 3-289
INSTRUCTION SET REFERENCE, A-M
CVTTPS2DQ—Convert with Truncation Packed Single-Precision FP Values to Packed
Dword Integers
VEX.128 encoded version: The source operand is an XMM register or 128- bit
memory location. The destination operation is a YMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are zeroed.
VEX.256 encoded version: The source operand is a YMM register or 256- bit memory
location. The destination operation is a YMM register.
Note: In VEX-encoded versions, VEX.vvvv is reserved and must be 1111b otherwise
instructions will #UD.
Operation
CVTTPS2DQ (128-bit Legacy SSE version)
DEST[31:0] Convert_Single_Precision_Floating_Point_To_Integer_Truncate(SRC[31:0])
DEST[63:32] Convert_Single_Precision_Floating_Point_To_Integer_Truncate(SRC[63:32])
DEST[95:64] Convert_Single_Precision_Floating_Point_To_Integer_Truncate(SRC[95:64])
DEST[127:96] Convert_Single_Precision_Floating_Point_To_Integer_Truncate(SRC[127:96])
DEST[VLMAX-1:128] (unmodified)
VCVTTPS2DQ (VEX.128 encoded version)
DEST[31:0] Convert_Single_Precision_Floating_Point_To_Integer_Truncate(SRC[31:0])
DEST[63:32] Convert_Single_Precision_Floating_Point_To_Integer_Truncate(SRC[63:32])
DEST[95:64] Convert_Single_Precision_Floating_Point_To_Integer_Truncate(SRC[95:64])
DEST[127:96] Convert_Single_Precision_Floating_Point_To_Integer_Truncate(SRC[127:96])
DEST[VLMAX-1:128] 0
VCVTTPS2DQ (VEX.256 encoded version)
DEST[31:0] Convert_Single_Precision_Floating_Point_To_Integer_Truncate(SRC[31:0])
DEST[63:32] Convert_Single_Precision_Floating_Point_To_Integer_Truncate(SRC[63:32])
DEST[95:64] Convert_Single_Precision_Floating_Point_To_Integer_Truncate(SRC[95:64])
DEST[127:96] Convert_Single_Precision_Floating_Point_To_Integer_Truncate(SRC[127:96)
DEST[159:128] Convert_Single_Precision_Floating_Point_To_Integer_Truncate(SRC[159:128])
DEST[191:160] Convert_Single_Precision_Floating_Point_To_Integer_Truncate(SRC[191:160])
DEST[223:192] Convert_Single_Precision_Floating_Point_To_Integer_Truncate(SRC[223:192])
DEST[255:224] Convert_Single_Precision_Floating_Point_To_Integer_Truncate(SRC[255:224])
Intel C/C++ Compiler Intrinsic Equivalent
CVTTPS2DQ __m128i _mm_cvttps_epi32(__m128 a)
VCVTTPS2DQ __m256i _mm256_cvttps_epi32 (__m256 a)
SIMD Floating-Point Exceptions
Invalid, Precision.

3-290 Vol. 2A CVTTPS2DQ—Convert with Truncation Packed Single-Precision FP Values to Packed
Dword Integers
INSTRUCTION SET REFERENCE, A-M
Other Exceptions
See Exceptions Type 2; additionally
#UD If VEX.vvvv != 1111B.

Vol. 2A 3-291
INSTRUCTION SET REFERENCE, A-M
CVTTPS2PI—Convert with Truncation Packed Single-Precision FP Values to Packed
Dword Integers
CVTTPS2PI—Convert with Truncation Packed Single-Precision FP
Values to Packed Dword Integers
Instruction Operand Encoding
Description
Converts two packed single-precision floating-point values in the source operand
(second operand) to two packed signed doubleword integers in the destination
operand (first operand). The source operand can be an XMM register or a 64-bit
memory location. The destination operand is an MMX technology register. When the
source operand is an XMM register, the two single-precision floating-point values are
contained in the low quadword of the register.
When a conversion is inexact, a truncated (round toward zero) result is returned. If a
converted result is larger than the maximum signed doubleword integer, the floating-
point invalid exception is raised, and if this exception is masked, the indefinite
integer value (80000000H) is returned.
This instruction causes a transition from x87 FPU to MMX technology operation (that
is, the x87 FPU top-of-stack pointer is set to 0 and the x87 FPU tag word is set to all
0s [valid]). If this instruction is executed while an x87 FPU floating-point exception is
pending, the exception is handled before the CVTTPS2PI instruction is executed.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
Operation
DEST[31:0] ← Convert_Single_Precision_Floating_Point_To_Integer_Truncate(SRC[31:0]);
DEST[63:32] ← Convert_Single_Precision_Floating_Point_To_Integer_Truncate(SRC[63:32]);
Intel C/C++ Compiler Intrinsic Equivalent
CVTTPS2PI __m64 _mm_cvttps_pi32(__m128 a)
Opcode/
Instruction
Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F 2C /r
CVTTPS2PI mm, xmm/m64
A Valid Valid Convert two single-
precision floating-point
values from xmm/m64 to
two signed doubleword
signed integers in mm using
truncation.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA

3-292 Vol. 2A CVTTPS2PI—Convert with Truncation Packed Single-Precision FP Values to Packed
Dword Integers
INSTRUCTION SET REFERENCE, A-M
SIMD Floating-Point Exceptions
Invalid, Precision.
Protected Mode Exceptions
#GP(0) For an illegal memory operand effective address in the CS, DS,
ES, FS or GS segments.
#SS(0) For an illegal address in the SS segment.
#PF(fault-code) For a page fault.
#MF If there is a pending x87 FPU exception.
#NM If CR0.TS[bit 3] = 1.
#XM If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 1.
#UD If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 0.
If CR0.EM[bit 2] = 1.
If CR4.OSFXSR[bit 9] = 0.
If CPUID.01H:EDX.SSE[bit 25] = 0.
If the LOCK prefix is used.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
Real-Address Mode Exceptions
GP If any part of the operand lies outside the effective address
space from 0 to FFFFH.
#NM If CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#XM If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 1.
#UD If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 0.
If CR0.EM[bit 2] = 1.
If CR4.OSFXSR[bit 9] = 0.
If CPUID.01H:EDX.SSE[bit 25] = 0.
If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
Same exceptions as in real address mode.
#PF(fault-code) For a page fault.

Vol. 2A 3-293
INSTRUCTION SET REFERENCE, A-M
CVTTPS2PI—Convert with Truncation Packed Single-Precision FP Values to Packed
Dword Integers
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#PF(fault-code) For a page fault.
#NM If CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#XM If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 1.
#UD If an unmasked SIMD floating-point exception and CR4.OSXM-
MEXCPT[bit 10] = 0.
If CR0.EM[bit 2] = 1.
If CR4.OSFXSR[bit 9] = 0.
If CPUID.01H:EDX.SSE[bit 25] = 0.
If the LOCK prefix is used.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
3-294 Vol. 2A CVTTSD2SI—Convert with Truncation Scalar Double-Precision FP Value to Signed Inte-
ger
INSTRUCTION SET REFERENCE, A-M
CVTTSD2SI—Convert with Truncation Scalar Double-Precision FP Value
to Signed Integer
Instruction Operand Encoding
Description
Converts a double-precision floating-point value in the source operand (second
operand) to a signed doubleword integer (or signed quadword integer if operand size
is 64 bits) in the destination operand (first operand). The source operand can be an
XMM register or a 64-bit memory location. The destination operand is a general
purpose register. When the source operand is an XMM register, the double-precision
floating-point value is contained in the low quadword of the register.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F2 0F 2C /r
CVTTSD2SI r32, xmm/m64
A V/V SSE2 Convert one double-
precision floating-point
value from xmm/m64 to
one signed doubleword
integer in r32 using
truncation.
F2 REX.W 0F 2C /r
CVTTSD2SI r64, xmm/m64
A V/N.E. SSE2 Convert one double
precision floating-point
value from xmm/m64 to
one signedquadword
integer in r64 using
truncation.
VEX.LIG.F2.0F.W0 2C /r
VCVTTSD2SI r32, xmm1/m64
AV/V AVX Convert one double-
precision floating-point
value from xmm1/m64 to
one signed doubleword
integer in r32 using
truncation.
VEX.LIG.F2.0F.W1 2C /r
VCVTTSD2SI r64, xmm1/m64
A V/N.E. AVX Convert one double
precision floating-point
value from xmm1/m64 to
one signed quadword
integer in r64 using
truncation.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA

Vol. 2A 3-295
INSTRUCTION SET REFERENCE, A-M
CVTTSD2SI—Convert with Truncation Scalar Double-Precision FP Value to Signed Inte-
ger
When a conversion is inexact, a truncated (round toward zero) result is returned. If a
converted result is larger than the maximum signed doubleword integer, the floating
point invalid exception is raised. If this exception is masked, the indefinite integer
value (80000000H) is returned.
Legacy SSE instructions: In 64-bit mode, Use of the REX.W prefix promotes the
instruction to 64-bit operation. See the summary chart at the beginning of this
section for encoding data and limits.
Note: In VEX-encoded versions, VEX.vvvv is reserved and must be 1111b, otherwise
instructions will #UD.
Operation
IF 64-Bit Mode and OperandSize = 64
THEN
DEST[63:0] ← Convert_Double_Precision_Floating_Point_To_
Integer64_Truncate(SRC[63:0]);
ELSE
DEST[31:0] ← Convert_Double_Precision_Floating_Point_To_
Integer32_Truncate(SRC[63:0]);
FI;
Intel C/C++ Compiler Intrinsic Equivalent
int _mm_cvttsd_si32(__m128d a)
__int64 _mm_cvttsd_si64(__m128d a)
SIMD Floating-Point Exceptions
Invalid, Precision.
Other Exceptions
See Exceptions Type 3; additionally
#UD If VEX.vvvv != 1111B.
3-296 Vol. 2A CVTTSS2SI—Convert with Truncation Scalar Single-Precision FP Value to Dword Integer
INSTRUCTION SET REFERENCE, A-M
CVTTSS2SI—Convert with Truncation Scalar Single-Precision FP Value
to Dword Integer
Instruction Operand Encoding
Description
Converts a single-precision floating-point value in the source operand (second
operand) to a signed doubleword integer (or signed quadword integer if operand size
is 64 bits) in the destination operand (first operand). The source operand can be an
XMM register or a 32-bit memory location. The destination operand is a general-
purpose register. When the source operand is an XMM register, the single-precision
floating-point value is contained in the low doubleword of the register.
When a conversion is inexact, a truncated (round toward zero) result is returned. If a
converted result is larger than the maximum signed doubleword integer, the floating-
point invalid exception is raised. If this exception is masked, the indefinite integer
value (80000000H) is returned.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F3 0F 2C /r
CVTTSS2SI r32, xmm/m32
A V/V SSE Convert one single-precision
floating-point value from
xmm/m32 to one signed
doubleword integer in r32
using truncation.
F3 REX.W 0F 2C /r
CVTTSS2SI r64, xmm/m32
A V/N.E. SSE Convert one single-precision
floating-point value from
xmm/m32 to one signed
quadword integer in r64
using truncation.
VEX.LIG.F3.0F.W0 2C /r
VCVTTSS2SI r32, xmm1/m32
A V/V AVX Convert one single-precision
floating-point value from
xmm1/m32 to one signed
doubleword integer in r32
using truncation.
VEX.LIG.F3.0F.W1 2C /r
VCVTTSS2SI r64, xmm1/m32
A V/N.E. AVX Convert one single-precision
floating-point value from
xmm1/m32 to one signed
quadword integer in r64
using truncation.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA

Vol. 2A 3-297
INSTRUCTION SET REFERENCE, A-M
CVTTSS2SI—Convert with Truncation Scalar Single-Precision FP Value to Dword Integer
Legacy SSE instructions: In 64-bit mode, the instruction can access additional regis-
ters (XMM8-XMM15, R8-R15) when used with a REX.R prefix. Use of the REX.W
prefix promotes the instruction to 64-bit operation. See the summary chart at the
beginning of this section for encoding data and limits.
Note: In VEX-encoded versions, VEX.vvvv is reserved and must be 1111b, otherwise
instructions will #UD.
Operation
IF 64-Bit Mode and OperandSize = 64
THEN
DEST[63:0] ← Convert_Single_Precision_Floating_Point_To_
Integer_Truncate(SRC[31:0]);
ELSE
DEST[31:0] ← Convert_Single_Precision_Floating_Point_To_
Integer_Truncate(SRC[31:0]);
FI;
Intel C/C++ Compiler Intrinsic Equivalent
int _mm_cvttss_si32(__m128d a)
__int64 _mm_cvttss_si64(__m128d a)
SIMD Floating-Point Exceptions
Invalid, Precision.
Other Exceptions
See Exceptions Type 3; additionally
#UD If VEX.vvvv != 1111B.
3-298 Vol. 2A CWD/CDQ/CQO—Convert Word to Doubleword/Convert Doubleword to Quadword
INSTRUCTION SET REFERENCE, A-M
CWD/CDQ/CQO—Convert Word to Doubleword/Convert Doubleword to
Quadword
Instruction Operand Encoding
Description
Doubles the size of the operand in register AX, EAX, or RAX (depending on the
operand size) by means of sign extension and stores the result in registers DX:AX,
EDX:EAX, or RDX:RAX, respectively. The CWD instruction copies the sign (bit 15) of
the value in the AX register into every bit position in the DX register. The CDQ
instruction copies the sign (bit 31) of the value in the EAX register into every bit posi-
tion in the EDX register. The CQO instruction (available in 64-bit mode only) copies
the sign (bit 63) of the value in the RAX register into every bit position in the RDX
register.
The CWD instruction can be used to produce a doubleword dividend from a word
before word division. The CDQ instruction can be used to produce a quadword divi-
dend from a doubleword before doubleword division. The CQO instruction can be
used to produce a double quadword dividend from a quadword before a quadword
division.
The CWD and CDQ mnemonics reference the same opcode. The CWD instruction is
intended for use when the operand-size attribute is 16 and the CDQ instruction for
when the operand-size attribute is 32. Some assemblers may force the operand size
to 16 when CWD is used and to 32 when CDQ is used. Others may treat these
mnemonics as synonyms (CWD/CDQ) and use the current setting of the operand-
size attribute to determine the size of values to be converted, regardless of the
mnemonic used.
In 64-bit mode, use of the REX.W prefix promotes operation to 64 bits. The CQO
mnemonics reference the same opcode as CWD/CDQ. See the summary chart at the
beginning of this section for encoding data and limits.
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
99 CWD A Valid Valid DX:AX ← sign-extend of AX.
99 CDQ A Valid Valid EDX:EAX ← sign-extend of
EAX.
REX.W + 99 CQO A Valid N.E. RDX:RAX← sign-extend of
RAX.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA

Vol. 2A 3-299
INSTRUCTION SET REFERENCE, A-M
CWD/CDQ/CQO—Convert Word to Doubleword/Convert Doubleword to Quadword
Operation
IF OperandSize = 16 (* CWD instruction *)
THEN
DX ← SignExtend(AX);
ELSE IF OperandSize = 32 (* CDQ instruction *)
EDX ← SignExtend(EAX); FI;
ELSE IF 64-Bit Mode and OperandSize = 64 (* CQO instruction*)
RDX ← SignExtend(RAX); FI;
FI;
Flags Affected
None.
Exceptions (All Operating Modes)
#UD If the LOCK prefix is used.

3-300 Vol. 2A DAA—Decimal Adjust AL after Addition
INSTRUCTION SET REFERENCE, A-M
DAA—Decimal Adjust AL after Addition
Instruction Operand Encoding
Description
Adjusts the sum of two packed BCD values to create a packed BCD result. The AL
register is the implied source and destination operand. The DAA instruction is only
useful when it follows an ADD instruction that adds (binary addition) two 2-digit,
packed BCD values and stores a byte result in the AL register. The DAA instruction
then adjusts the contents of the AL register to contain the correct 2-digit, packed
BCD result. If a decimal carry is detected, the CF and AF flags are set accordingly.
This instruction executes as described above in compatibility mode and legacy mode.
It is not valid in 64-bit mode.
Operation
IF 64-Bit Mode
THEN
#UD;
ELSE
old_AL ← AL;
old_CF ← CF;
CF ← 0;
IF (((AL AND 0FH) > 9) or AF = 1)
THEN
AL ← AL + 6;
CF ← old_CF or (Carry from AL ← AL + 6);
AF ← 1;
ELSE
AF ← 0;
FI;
IF ((old_AL > 99H) or (old_CF = 1))
THEN
AL ← AL + 60H;
CF ← 1;
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
27 DAA A Invalid Valid Decimal adjust AL after
addition.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA

Vol. 2A 3-301
INSTRUCTION SET REFERENCE, A-M
DAA—Decimal Adjust AL after Addition
ELSE
CF ← 0;
FI;
FI;
Example
ADD AL, BL Before: AL=79H BL=35H EFLAGS(OSZAPC)=XXXXXX
After: AL=AEH BL=35H EFLAGS(0SZAPC)=110000
DAA Before: AL=AEH BL=35H EFLAGS(OSZAPC)=110000
After: AL=14H BL=35H EFLAGS(0SZAPC)=X00111
DAA Before: AL=2EH BL=35H EFLAGS(OSZAPC)=110000
After: AL=34H BL=35H EFLAGS(0SZAPC)=X00101
Flags Affected
The CF and AF flags are set if the adjustment of the value results in a decimal carry
in either digit of the result (see the “Operation” section above). The SF, ZF, and PF
flags are set according to the result. The OF flag is undefined.
Protected Mode Exceptions
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
#UD If the LOCK prefix is used.
64-Bit Mode Exceptions
#UD If in 64-bit mode.

3-302 Vol. 2A DAS—Decimal Adjust AL after Subtraction
INSTRUCTION SET REFERENCE, A-M
DAS—Decimal Adjust AL after Subtraction
Instruction Operand Encoding
Description
Adjusts the result of the subtraction of two packed BCD values to create a packed
BCD result. The AL register is the implied source and destination operand. The DAS
instruction is only useful when it follows a SUB instruction that subtracts (binary
subtraction) one 2-digit, packed BCD value from another and stores a byte result in
the AL register. The DAS instruction then adjusts the contents of the AL register to
contain the correct 2-digit, packed BCD result. If a decimal borrow is detected, the CF
and AF flags are set accordingly.
This instruction executes as described above in compatibility mode and legacy mode.
It is not valid in 64-bit mode.
Operation
IF 64-Bit Mode
THEN
#UD;
ELSE
old_AL ← AL;
old_CF ← CF;
CF ← 0;
IF (((AL AND 0FH) > 9) or AF = 1)
THEN
AL ← AL - 6;
CF ← old_CF or (Borrow from AL ← AL − 6);
AF ← 1;
ELSE
AF ← 0;
FI;
IF ((old_AL > 99H) or (old_CF = 1))
THEN
AL ← AL − 60H;
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
2F DAS A Invalid Valid Decimal adjust AL after
subtraction.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA

Vol. 2A 3-303
INSTRUCTION SET REFERENCE, A-M
DAS—Decimal Adjust AL after Subtraction
CF ← 1;
FI;
FI;
Example
SUB AL, BL Before: AL = 35H, BL = 47H, EFLAGS(OSZAPC) = XXXXXX
After: AL = EEH, BL = 47H, EFLAGS(0SZAPC) = 010111
DAA Before: AL = EEH, BL = 47H, EFLAGS(OSZAPC) = 010111
After: AL = 88H, BL = 47H, EFLAGS(0SZAPC) = X10111
Flags Affected
The CF and AF flags are set if the adjustment of the value results in a decimal borrow
in either digit of the result (see the “Operation” section above). The SF, ZF, and PF
flags are set according to the result. The OF flag is undefined.
Protected Mode Exceptions
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
#UD If the LOCK prefix is used.
64-Bit Mode Exceptions
#UD If in 64-bit mode.

3-304 Vol. 2A DEC—Decrement by 1
INSTRUCTION SET REFERENCE, A-M
DEC—Decrement by 1
Instruction Operand Encoding
Description
Subtracts 1 from the destination operand, while preserving the state of the CF flag.
The destination operand can be a register or a memory location. This instruction
allows a loop counter to be updated without disturbing the CF flag. (To perform a
decrement operation that updates the CF flag, use a SUB instruction with an imme-
diate operand of 1.)
This instruction can be used with a LOCK prefix to allow the instruction to be
executed atomically.
In 64-bit mode, DEC r16 and DEC r32 are not encodable (because opcodes 48H
through 4FH are REX prefixes). Otherwise, the instruction’s 64-bit mode default
operation size is 32 bits. Use of the REX.R prefix permits access to additional regis-
ters (R8-R15). Use of the REX.W prefix promotes operation to 64 bits.
See the summary chart at the beginning of this section for encoding data and limits.
Operation
DEST ← DEST – 1;
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
FE /1 DEC r/m8 AValid Valid Decrement r/m8 by 1.
REX + FE /1 DEC r/m8*AValid N.E. Decrement r/m8 by 1.
FF /1 DEC r/m16 AValid Valid Decrement r/m16 by 1.
FF /1 DEC r/m32 AValid Valid Decrement r/m32 by 1.
REX.W + FF /1 DEC r/m64 AValid N.E. Decrement r/m64 by 1.
48+rw DEC r16 BN.E. Valid Decrement r16 by 1.
48+rd DEC r32 BN.E. Valid Decrement r32 by 1.
NOTES:
* In 64-bit mode, r/m8 can not be encoded to access the following byte registers if a REX prefix is
used: AH, BH, CH, DH.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (r, w) NA NA NA
B reg (r, w) NA NA NA

Vol. 2A 3-305
INSTRUCTION SET REFERENCE, A-M
DEC—Decrement by 1
Flags Affected
The CF flag is not affected. The OF, SF, ZF, AF, and PF flags are set according to the
result.
Protected Mode Exceptions
#GP(0) If the destination operand is located in a non-writable segment.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used but the destination is not a memory
operand.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#UD If the LOCK prefix is used but the destination is not a memory
operand.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used but the destination is not a memory
operand.
Compatibility Mode Exceptions
Same exceptions as in protected mode.

3-306 Vol. 2A DEC—Decrement by 1
INSTRUCTION SET REFERENCE, A-M
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used but the destination is not a memory
operand.

Vol. 2A 3-307
INSTRUCTION SET REFERENCE, A-M
DIV—Unsigned Divide
DIV—Unsigned Divide
Instruction Operand Encoding
Description
Divides unsigned the value in the AX, DX:AX, EDX:EAX, or RDX:RAX registers (divi-
dend) by the source operand (divisor) and stores the result in the AX (AH:AL),
DX:AX, EDX:EAX, or RDX:RAX registers. The source operand can be a general-
purpose register or a memory location. The action of this instruction depends on the
operand size (dividend/divisor). Division using 64-bit operand is available only in
64-bit mode.
Non-integral results are truncated (chopped) towards 0. The remainder is always less
than the divisor in magnitude. Overflow is indicated with the #DE (divide error)
exception rather than with the CF flag.
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
F6 /6 DIV r/m8 A Valid Valid Unsigned divide AX by r/m8,
with result stored in AL ←
Quotient, AH ← Remainder.
REX + F6 /6 DIV r/m8*A Valid N.E. Unsigned divide AX by r/m8,
with result stored in AL ←
Quotient, AH ← Remainder.
F7 /6 DIV r/m16 A Valid Valid Unsigned divide DX:AX by
r/m16, with result stored in
AX ← Quotient, DX ←
Remainder.
F7 /6 DIV r/m32 A Valid Valid Unsigned divide EDX:EAX by
r/m32, with result stored in
EAX ← Quotient, EDX ←
Remainder.
REX.W + F7 /6 DIV r/m64 A Valid N.E. Unsigned divide RDX:RAX
by r/m64, with result stored
in RAX ← Quotient, RDX ←
Remainder.
NOTES:
* In 64-bit mode, r/m8 can not be encoded to access the following byte registers if a REX prefix is
used: AH, BH, CH, DH.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (w) NA NA NA

3-308 Vol. 2A DIV—Unsigned Divide
INSTRUCTION SET REFERENCE, A-M
In 64-bit mode, the instruction’s default operation size is 32 bits. Use of the REX.R
prefix permits access to additional registers (R8-R15). Use of the REX.W prefix
promotes operation to 64 bits. In 64-bit mode when REX.W is applied, the instruction
divides the unsigned value in RDX:RAX by the source operand and stores the
quotient in RAX, the remainder in RDX.
See the summary chart at the beginning of this section for encoding data and limits.
See Table 3-25.
Operation
IF SRC = 0
THEN #DE; FI; (* Divide Error *)
IF OperandSize = 8 (* Word/Byte Operation *)
THEN
temp ← AX / SRC;
IF temp > FFH
THEN #DE; (* Divide error *)
ELSE
AL ← temp;
AH ← AX MOD SRC;
FI;
ELSE IF OperandSize = 16 (* Doubleword/word operation *)
THEN
temp ← DX:AX / SRC;
IF temp > FFFFH
THEN #DE; (* Divide error *)
ELSE
AX ← temp;
DX ← DX:AX MOD SRC;
FI;
FI;
ELSE IF Operandsize = 32 (* Quadword/doubleword operation *)
THEN
temp ← EDX:EAX / SRC;
Table 3-25. DIV Action
Operand Size Dividend Divisor Quotient Remainder
Maximum
Quotient
Word/byte AX r/m8 AL AH 255
Doubleword/word DX:AX r/m16 AX DX 65,535
Quadword/doubleword EDX:EAX r/m32 EAX EDX 232 − 1
Doublequadword/
quadword
RDX:RAX r/m64 RAX RDX 264 − 1

Vol. 2A 3-309
INSTRUCTION SET REFERENCE, A-M
DIV—Unsigned Divide
IF temp > FFFFFFFFH
THEN #DE; (* Divide error *)
ELSE
EAX ← temp;
EDX ← EDX:EAX MOD SRC;
FI;
FI;
ELSE IF 64-Bit Mode and Operandsize = 64 (* Doublequadword/quadword operation *)
THEN
temp ← RDX:RAX / SRC;
IF temp > FFFFFFFFFFFFFFFFH
THEN #DE; (* Divide error *)
ELSE
RAX ← temp;
RDX ← RDX:RAX MOD SRC;
FI;
FI;
FI;
Flags Affected
The CF, OF, SF, ZF, AF, and PF flags are undefined.
Protected Mode Exceptions
#DE If the source operand (divisor) is 0
If the quotient is too large for the designated register.
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#DE If the source operand (divisor) is 0.
If the quotient is too large for the designated register.
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.

3-310 Vol. 2A DIV—Unsigned Divide
INSTRUCTION SET REFERENCE, A-M
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#DE If the source operand (divisor) is 0.
If the quotient is too large for the designated register.
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#DE If the source operand (divisor) is 0
If the quotient is too large for the designated register.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Vol. 2A 3-311
INSTRUCTION SET REFERENCE, A-M
DIVPD—Divide Packed Double-Precision Floating-Point Values
DIVPD—Divide Packed Double-Precision Floating-Point Values
Instruction Operand Encoding
Description
Performs an SIMD divide of the two or four packed double-precision floating-point
values in the first source operand by the two or four packed double-precision
floating-point values in the second source operand. See Chapter 11 in the Intel® 64
and IA-32 Architectures Software Developer’s Manual, Volume 1, for an overview of
a SIMD double-precision floating-point operation.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
128-bit Legacy SSE version: The second source can be an XMM register or an 128-bit
memory location. The destination is not distinct from the first source XMM register
and the upper bits (VLMAX-1:128) of the corresponding YMM register destination are
unmodified.
VEX.128 encoded version: the first source operand is an XMM register or 128-bit
memory location. The destination operand is an XMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are zeroed.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 5E /r
DIVPD xmm1, xmm2/m128
A V/V SSE2 Divide packed double-
precision floating-point
values in xmm1 by packed
double-precision floating-
point values xmm2/m128.
VEX.NDS.128.66.0F.WIG 5E /r
VDIVPD xmm1, xmm2, xmm3/m128
B V/V AVX Divide packed double-
precision floating-point
values in xmm2 by packed
double-precision floating-
point values in xmm3/mem.
VEX.NDS.256.66.0F.WIG 5E /r
VDIVPD ymm1, ymm2, ymm3/m256
B V/V AVX Divide packed double-
precision floating-point
values in ymm2 by packed
double-precision floating-
point values in ymm3/mem.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

3-312 Vol. 2A DIVPD—Divide Packed Double-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
VEX.256 encoded version: The first source operand is a YMM register. The second
source operand can be a YMM register or a 256-bit memory location. The destination
operand is a YMM register.
Operation
DIVPD (128-bit Legacy SSE version)
DEST[63:0] SRC1[63:0] / SRC2[63:0]
DEST[127:64] SRC1[127:64] / SRC2[127:64]
DEST[VLMAX-1:128] (Unmodified)
VDIVPD (VEX.128 encoded version)
DEST[63:0] SRC1[63:0] / SRC2[63:0]
DEST[127:64] SRC1[127:64] / SRC2[127:64]
DEST[VLMAX-1:128] 0
VDIVPD (VEX.256 encoded version)
DEST[63:0] SRC1[63:0] / SRC2[63:0]
DEST[127:64] SRC1[127:64] / SRC2[127:64]
DEST[191:128] SRC1[191:128] / SRC2[191:128]
DEST[255:192] SRC1[255:192] / SRC2[255:192]
Intel C/C++ Compiler Intrinsic Equivalent
DIVPD __m128d _mm_div_pd(__m128d a, __m128d b)
VDIVPD __m256d _mm256_div_pd (__m256d a, __m256d b);
SIMD Floating-Point Exceptions
Overflow, Underflow, Invalid, Divide-by-Zero, Precision, Denormal.
Other Exceptions
See Exceptions Type 2.
Vol. 2A 3-313
INSTRUCTION SET REFERENCE, A-M
DIVPS—Divide Packed Single-Precision Floating-Point Values
DIVPS—Divide Packed Single-Precision Floating-Point Values
Instruction Operand Encoding
Description
Performs an SIMD divide of the four or eight packed single-precision floating-point
values in the first source operand by the four or eight packed single-precision
floating-point values in the second source operand. See Chapter 10 in the Intel® 64
and IA-32 Architectures Software Developer’s Manual, Volume 1, for an overview of
a SIMD single-precision floating-point operation.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
128-bit Legacy SSE version: The second source can be an XMM register or an 128-bit
memory location. The destination is not distinct from the first source XMM register
and the upper bits (VLMAX-1:128) of the corresponding YMM register destination are
unmodified.
VEX.128 encoded version: the first source operand is an XMM register or 128-bit
memory location. The destination operand is an XMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are zeroed.
Opcode Instruction Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
0F 5E /rDIVPS xmm1,
xmm2/m128
A V/V SSE Divide packed single-
precision floating-point
values in xmm1 by packed
single-precision floating-
point values xmm2/m128.
VEX.NDS.128.0F.WIG 5E /r
VDIVPS xmm1, xmm2, xmm3/m128
B V/V AVX Divide packed single-
precision floating-point
values in xmm2 by packed
double-precision floating-
point values in xmm3/mem.
VEX.NDS.256.0F.WIG 5E /r
VDIVPS ymm1, ymm2, ymm3/m256
B V/V AVX Divide packed single-
precision floating-point
values in ymm2 by packed
double-precision floating-
point values in ymm3/mem.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

3-314 Vol. 2A DIVPS—Divide Packed Single-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
VEX.256 encoded version: The first source operand is a YMM register. The second
source operand can be a YMM register or a 256-bit memory location. The destination
operand is a YMM register.
Operation
DIVPS (128-bit Legacy SSE version)
DEST[31:0] SRC1[31:0] / SRC2[31:0]
DEST[63:32] SRC1[63:32] / SRC2[63:32]
DEST[95:64] SRC1[95:64] / SRC2[95:64]
DEST[127:96] SRC1[127:96] / SRC2[127:96]
DEST[VLMAX-1:128] (Unmodified)
VDIVPS (VEX.128 encoded version)
DEST[31:0] SRC1[31:0] / SRC2[31:0]
DEST[63:32] SRC1[63:32] / SRC2[63:32]
DEST[95:64] SRC1[95:64] / SRC2[95:64]
DEST[127:96] SRC1[127:96] / SRC2[127:96]
DEST[VLMAX-1:128] 0
VDIVPS (VEX.256 encoded version)
DEST[31:0] SRC1[31:0] / SRC2[31:0]
DEST[63:32] SRC1[63:32] / SRC2[63:32]
DEST[95:64] SRC1[95:64] / SRC2[95:64]
DEST[127:96] SRC1[127:96] / SRC2[127:96]
DEST[159:128] SRC1[159:128] / SRC2[159:128]
DEST[191:160] SRC1[191:160] / SRC2[191:160]
DEST[223:192] SRC1[223:192] / SRC2[223:192]
DEST[255:224] SRC1[255:224] / SRC2[255:224].
Intel C/C++ Compiler Intrinsic Equivalent
DIVPS __m128 _mm_div_ps(__m128 a, __m128 b)
VDIVPS __m256 _mm256_div_ps (__m256 a, __m256 b);
SIMD Floating-Point Exceptions
Overflow, Underflow, Invalid, Divide-by-Zero, Precision, Denormal.
Other Exceptions
See Exceptions Type 2.
Vol. 2A 3-315
INSTRUCTION SET REFERENCE, A-M
DIVSD—Divide Scalar Double-Precision Floating-Point Values
DIVSD—Divide Scalar Double-Precision Floating-Point Values
Instruction Operand Encoding
Description
Divides the low double-precision floating-point value in the first source operand by
the low double-precision floating-point value in the second source operand, and
stores the double-precision floating-point result in the destination operand. The
second source operand can be an XMM register or a 64-bit memory location. The first
source and destination hyperons are XMM registers. The high quadword of the desti-
nation operand is copied from the high quadword of the first source operand. See
Chapter 11 in the Intel® 64 and IA-32 Architectures Software Developer’s Manual,
Volume 1, for an overview of a scalar double-precision floating-point operation.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
128-bit Legacy SSE version: The first source operand and the destination operand
are the same. Bits (VLMAX-1:64) of the corresponding YMM destination register
remain unchanged.
VEX.128 encoded version: Bits (VLMAX-1:128) of the destination YMM register are
zeroed.
Operation
DIVSD (128-bit Legacy SSE version)
DEST[63:0] DEST[63:0] / SRC[63:0]
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F2 0F 5E /r
DIVSD xmm1, xmm2/m64
AV/V SSE2 Divide low double-precision
floating-point value n xmm1
by low double-precision
floating-point value in
xmm2/mem64.
VEX.NDS.LIG.F2.0F.WIG 5E /r
VDIVSD xmm1, xmm2, xmm3/m64
A V/V AVX Divide low double-precision
floating point values in
xmm2 by low double
precision floating-point
value in xmm3/mem64.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

3-316 Vol. 2A DIVSD—Divide Scalar Double-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
DEST[VLMAX-1:64] (Unmodified)
VDIVSD (VEX.128 encoded version)
DEST[63:0] SRC1[63:0] / SRC2[63:0]
DEST[127:64] SRC1[127:64]
DEST[VLMAX-1:128] 0
Intel C/C++ Compiler Intrinsic Equivalent
DIVSD __m128d _mm_div_sd (m128d a, m128d b)
SIMD Floating-Point Exceptions
Overflow, Underflow, Invalid, Divide-by-Zero, Precision, Denormal.
Other Exceptions
See Exceptions Type 3.
Vol. 2A 3-317
INSTRUCTION SET REFERENCE, A-M
DIVSS—Divide Scalar Single-Precision Floating-Point Values
DIVSS—Divide Scalar Single-Precision Floating-Point Values
Instruction Operand Encoding
Description
Divides the low single-precision floating-point value in the first source operand by the
low single-precision floating-point value in the second source operand, and stores
the single-precision floating-point result in the destination operand. The second
source operand can be an XMM register or a 32-bit memory location. The first source
and destination operands are XMM registers. The three high-order doublewords of
the destination are copied from the same dwords of the first source operand. See
Chapter 10 in the Intel® 64 and IA-32 Architectures Software Developer’s Manual,
Volume 1, for an overview of a scalar single-precision floating-point operation.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
128-bit Legacy SSE version: The first source operand and the destination operand
are the same. Bits (VLMAX-1:32) of the corresponding YMM destination register
remain unchanged.
VEX.128 encoded version: Bits (VLMAX-1:128) of the destination YMM register are
zeroed.
Operation
DIVSS (128-bit Legacy SSE version)
DEST[31:0] DEST[31:0] / SRC[31:0]
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F3 0F 5E /r
DIVSS xmm1, xmm2/m32
A V/V SSE Divide low single-precision
floating-point value in
xmm1 by low single-
precision floating-point
value in xmm2/m32.
VEX.NDS.LIG.F3.0F.WIG 5E /r
VDIVSS xmm1, xmm2, xmm3/m32
B V/V AVX Divide low single-precision
floating point value in xmm2
by low single precision
floating-point value in
xmm3/m32.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

3-318 Vol. 2A DIVSS—Divide Scalar Single-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
DEST[VLMAX-1:32] (Unmodified)
VDIVSS (VEX.128 encoded version)
DEST[31:0] SRC1[31:0] / SRC2[31:0]
DEST[127:32] SRC1[127:32]
DEST[VLMAX-1:128] 0
Intel C/C++ Compiler Intrinsic Equivalent
DIVSS __m128 _mm_div_ss(__m128 a, __m128 b)
SIMD Floating-Point Exceptions
Overflow, Underflow, Invalid, Divide-by-Zero, Precision, Denormal.
Other Exceptions
See Exceptions Type 3.

Vol. 2A 3-319
INSTRUCTION SET REFERENCE, A-M
DPPD — Dot Product of Packed Double Precision Floating-Point Values
DPPD — Dot Product of Packed Double Precision Floating-Point Values
Instruction Operand Encoding
Description
Conditionally multiplies the packed double-precision floating-point values in the
destination operand (first operand) with the packed double-precision floating-point
values in the source (second operand) depending on a mask extracted from bits
[5:4] of the immediate operand (third operand). If a condition mask bit is zero, the
corresponding multiplication is replaced by a value of 0.0.
The two resulting double-precision values are summed into an intermediate result.
The intermediate result is conditionally broadcasted to the destination using a broad-
cast mask specified by bits [1:0] of the immediate byte.
If a broadcast mask bit is "1", the intermediate result is copied to the corresponding
qword element in the destination operand. If a broadcast mask bit is zero, the corre-
sponding element in the destination is set to zero.
DPPS follows the NaN forwarding rules stated in the Software Developer’s Manual,
vol. 1, table 4.7. These rules do not cover horizontal prioritization of NaNs. Horizontal
propagation of NaNs to the destination and the positioning of those NaNs in the desti-
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 3A 41 /r ib
DPPD xmm1, xmm2/m128, imm8
A V/V SSE4_1 Selectively multiply packed
DP floating-point values
from xmm1 with packed DP
floating-point values from
xmm2, add and selectively
store the packed DP
floating-point values to
xmm1.
VEX.NDS.128.66.0F3A.WIG 41 /r ib
VDPPD xmm1,xmm2, xmm3/m128,
imm8
B V/V AVX Selectively multiply packed
DP floating-point values
from xmm2 with packed DP
floating-point values from
xmm3, add and selectively
store the packed DP
floating-point values to
xmm1.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) imm8 NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

3-320 Vol. 2A DPPD — Dot Product of Packed Double Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
nation is implementation dependent. NaNs on the input sources or computationally
generated NaNs will have at least one NaN propagated to the destination.
128-bit Legacy SSE version: The second source can be an XMM register or an 128-bit
memory location. The destination is not distinct from the first source XMM register
and the upper bits (VLMAX-1:128) of the corresponding YMM register destination are
unmodified.
VEX.128 encoded version: the first source operand is an XMM register or 128-bit
memory location. The destination operand is an XMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are zeroed.
If VDPPD is encoded with VEX.L= 1, an attempt to execute the instruction encoded
with VEX.L= 1 will cause an #UD exception.
Operation
DP_primitive (SRC1, SRC2)
IF (imm8[4] = 1)
THEN Temp1[63:0] DEST[63:0] * SRC[63:0];
ELSE Temp1[63:0] +0.0; FI;
IF (imm8[5] = 1)
THEN Temp1[127:64] DEST[127:64] * SRC[127:64];
ELSE Temp1[127:64] +0.0; FI;
Temp2[63:0] Temp1[63:0] + Temp1[127:64];
IF (imm8[0] = 1)
THEN DEST[63:0] Temp2[63:0];
ELSE DEST[63:0] +0.0; FI;
IF (imm8[1] = 1)
THEN DEST[127:64] Temp2[63:0];
ELSE DEST[127:64] +0.0; FI;
DPPD (128-bit Legacy SSE version)
DEST[127:0]DP_Primitive(SRC1[127:0], SRC2[127:0]);
DEST[VLMAX-1:128] (Unmodified)
VDPPD (VEX.128 encoded version)
DEST[127:0]DP_Primitive(SRC1[127:0], SRC2[127:0]);
DEST[VLMAX-1:128] 0
Flags Affected
None

Vol. 2A 3-321
INSTRUCTION SET REFERENCE, A-M
DPPD — Dot Product of Packed Double Precision Floating-Point Values
Intel C/C++ Compiler Intrinsic Equivalent
DPPD __m128d _mm_dp_pd ( __m128d a, __m128d b, const int mask);
SIMD Floating-Point Exceptions
Overflow, Underflow, Invalid, Precision, Denormal
Exceptions are determined separately for each add and multiply operation.
Unmasked exceptions will leave the destination untouched.
Other Exceptions
See Exceptions Type 2; additionally
#UD If VEX.L= 1.
3-322 Vol. 2A DPPS — Dot Product of Packed Single Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
DPPS — Dot Product of Packed Single Precision Floating-Point Values
Instruction Operand Encoding
Description
Conditionally multiplies the packed single precision floating-point values in the desti-
nation operand (first operand) with the packed single-precision floats in the source
(second operand) depending on a mask extracted from the high 4 bits of the imme-
diate byte (third operand). If a condition mask bit in Imm8[7:4] is zero, the corre-
sponding multiplication is replaced by a value of 0.0.
The four resulting single-precision values are summed into an intermediate result.
The intermediate result is conditionally broadcasted to the destination using a broad-
cast mask specified by bits [3:0] of the immediate byte..
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 3A 40 /r ib
DPPS xmm1, xmm2/m128, imm8
AV/V SSE4_1Selectively multiply packed
SP floating-point values
from xmm1 with packed SP
floating-point values from
xmm2, add and selectively
store the packed SP
floating-point values or zero
values to xmm1.
VEX.NDS.128.66.0F3A.WIG 40 /r ib
VDPPS xmm1,xmm2, xmm3/m128,
imm8
B V/V AVX Multiply packed SP floating
point values from xmm1
with packed SP floating
point values from
xmm2/mem selectively add
and store to xmm1.
VEX.NDS.256.66.0F3A.WIG 40 /r ib
VDPPS ymm1, ymm2, ymm3/m256,
imm8
B V/V AVX Multiply packed single-
precision floating-point
values from ymm2 with
packed SP floating point
values from ymm3/mem,
selectively add pairs of
elements and store to
ymm1.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) imm8 NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

Vol. 2A 3-323
INSTRUCTION SET REFERENCE, A-M
DPPS — Dot Product of Packed Single Precision Floating-Point Values
If a broadcast mask bit is "1", the intermediate result is copied to the corresponding
dword element in the destination operand. If a broadcast mask bit is zero, the corre-
sponding element in the destination is set to zero.
DPPS follows the NaN forwarding rules stated in the Software Developer’s Manual,
vol. 1, table 4.7. These rules do not cover horizontal prioritization of NaNs. Horizontal
propagation of NaNs to the destination and the positioning of those NaNs in the desti-
nation is implementation dependent. NaNs on the input sources or computationally
generated NaNs will have at least one NaN propagated to the destination.
128-bit Legacy SSE version: The second source can be an XMM register or an 128-bit
memory location. The destination is not distinct from the first source XMM register
and the upper bits (VLMAX-1:128) of the corresponding YMM register destination are
unmodified.
VEX.128 encoded version: the first source operand is an XMM register or 128-bit
memory location. The destination operand is an XMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are zeroed.
VEX.256 encoded version: The first source operand is a YMM register. The second
source operand can be a YMM register or a 256-bit memory location. The destination
operand is a YMM register.
Operation
DP_primitive (SRC1, SRC2)
IF (imm8[4] = 1)
THEN Temp1[31:0] DEST[31:0] * SRC[31:0];
ELSE Temp1[31:0] +0.0; FI;
IF (imm8[5] = 1)
THEN Temp1[63:32] DEST[63:32] * SRC[63:32];
ELSE Temp1[63:32] +0.0; FI;
IF (imm8[6] = 1)
THEN Temp1[95:64] DEST[95:64] * SRC[95:64];
ELSE Temp1[95:64] +0.0; FI;
IF (imm8[7] = 1)
THEN Temp1[127:96] DEST[127:96] * SRC[127:96];
ELSE Temp1[127:96] +0.0; FI;
Temp2[31:0] Temp1[31:0] + Temp1[63:32];
Temp3[31:0] Temp1[95:64] + Temp1[127:96];
Temp4[31:0] Temp2[31:0] + Temp3[31:0];
IF (imm8[0] = 1)
THEN DEST[31:0] Temp4[31:0];
ELSE DEST[31:0] +0.0; FI;
IF (imm8[1] = 1)

3-324 Vol. 2A DPPS — Dot Product of Packed Single Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
THEN DEST[63:32] Temp4[31:0];
ELSE DEST[63:32] +0.0; FI;
IF (imm8[2] = 1)
THEN DEST[95:64] Temp4[31:0];
ELSE DEST[95:64] +0.0; FI;
IF (imm8[3] = 1)
THEN DEST[127:96] Temp4[31:0];
ELSE DEST[127:96] +0.0; FI;
DPP (128-bit Legacy SSE version)
DEST[127:0]DP_Primitive(SRC1[127:0], SRC2[127:0]);
DEST[VLMAX-1:128] (Unmodified)
VDPPS (VEX.128 encoded version)
DEST[127:0]DP_Primitive(SRC1[127:0], SRC2[127:0]);
DEST[VLMAX-1:128] 0
VDPPS (VEX.256 encoded version)
DEST[127:0]DP_Primitive(SRC1[127:0], SRC2[127:0]);
DEST[255:128]DP_Primitive(SRC1[255:128], SRC2[255:128]);
Intel C/C++ Compiler Intrinsic Equivalent
(V)DPPS __m128 _mm_dp_ps ( __m128 a, __m128 b, const int mask);
VDPPS __m256 _mm256_dp_ps ( __m256 a, __m256 b, const int mask);
SIMD Floating-Point Exceptions
Overflow, Underflow, Invalid, Precision, Denormal
Exceptions are determined separately for each add and multiply operation, in the
order of their execution. Unmasked exceptions will leave the destination operands
unchanged.
Other Exceptions
See Exceptions Type 2.

Vol. 2A 3-325
INSTRUCTION SET REFERENCE, A-M
EMMS—Empty MMX Technology State
EMMS—Empty MMX Technology State
Instruction Operand Encoding
Description
Sets the values of all the tags in the x87 FPU tag word to empty (all 1s). This opera-
tion marks the x87 FPU data registers (which are aliased to the MMX technology
registers) as available for use by x87 FPU floating-point instructions. (See Figure 8-7
in the Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 1, for
the format of the x87 FPU tag word.) All other MMX instructions (other than the
EMMS instruction) set all the tags in x87 FPU tag word to valid (all 0s).
The EMMS instruction must be used to clear the MMX technology state at the end of
all MMX technology procedures or subroutines and before calling other procedures or
subroutines that may execute x87 floating-point instructions. If a floating-point
instruction loads one of the registers in the x87 FPU data register stack before the
x87 FPU tag word has been reset by the EMMS instruction, an x87 floating-point
register stack overflow can occur that will result in an x87 floating-point exception or
incorrect result.
EMMS operation is the same in non-64-bit modes and 64-bit mode.
Operation
x87FPUTagWord ← FFFFH;
Intel C/C++ Compiler Intrinsic Equivalent
void _mm_empty()
Flags Affected
None.
Protected Mode Exceptions
#UD If CR0.EM[bit 2] = 1.
#NM If CR0.TS[bit 3] = 1.
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F 77 EMMS A Valid Valid Set the x87 FPU tag word
to empty.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA

3-326 Vol. 2A EMMS—Empty MMX Technology State
INSTRUCTION SET REFERENCE, A-M
#MF If there is a pending FPU exception.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.

Vol. 2A 3-327
INSTRUCTION SET REFERENCE, A-M
ENTER—Make Stack Frame for Procedure Parameters
ENTER—Make Stack Frame for Procedure Parameters
Instruction Operand Encoding
Description
Creates a stack frame for a procedure. The first operand (size operand) specifies the
size of the stack frame (that is, the number of bytes of dynamic storage allocated on
the stack for the procedure). The second operand (nesting level operand) gives the
lexical nesting level (0 to 31) of the procedure. The nesting level determines the
number of stack frame pointers that are copied into the “display area” of the new
stack frame from the preceding frame. Both of these operands are immediate values.
The stack-size attribute determines whether the BP (16 bits), EBP (32 bits), or RBP
(64 bits) register specifies the current frame pointer and whether SP (16 bits), ESP
(32 bits), or RSP (64 bits) specifies the stack pointer. In 64-bit mode, stack-size
attribute is always 64-bits.
The ENTER and companion LEAVE instructions are provided to support block struc-
tured languages. The ENTER instruction (when used) is typically the first instruction
in a procedure and is used to set up a new stack frame for a procedure. The LEAVE
instruction is then used at the end of the procedure (just before the RET instruction)
to release the stack frame.
If the nesting level is 0, the processor pushes the frame pointer from the BP/EBP/RBP
register onto the stack, copies the current stack pointer from the SP/ESP/RSP
register into the BP/EBP/RBP register, and loads the SP/ESP/RSP register with the
current stack-pointer value minus the value in the size operand. For nesting levels of
1 or greater, the processor pushes additional frame pointers on the stack before
adjusting the stack pointer. These additional frame pointers provide the called proce-
dure with access points to other nested frames on the stack. See “Procedure Calls for
Block-Structured Languages” in Chapter 6 of the Intel® 64 and IA-32 Architectures
Software Developer’s Manual, Volume 1, for more information about the actions of
the ENTER instruction.
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
C8 iw 00 ENTER imm16, 0 A Valid Valid Create a stack frame for a
procedure.
C8 iw 01 ENTER imm16,1 A Valid Valid Create a nested stack frame
for a procedure.
C8 iw ib ENTER imm16,
imm8
A Valid Valid Create a nested stack frame
for a procedure.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
Aiw imm8 NA NA

3-328 Vol. 2A ENTER—Make Stack Frame for Procedure Parameters
INSTRUCTION SET REFERENCE, A-M
The ENTER instruction causes a page fault whenever a write using the final value of
the stack pointer (within the current stack segment) would do so.
In 64-bit mode, default operation size is 64 bits; 32-bit operation size cannot be
encoded.
Operation
NestingLevel ← NestingLevel MOD 32
IF 64-Bit Mode (StackSize = 64)
THEN
Push(RBP);
FrameTemp ← RSP;
ELSE IF StackSize = 32
THEN
Push(EBP);
FrameTemp ← ESP; FI;
ELSE (* StackSize = 16 *)
Push(BP);
FrameTemp ← SP;
FI;
IF NestingLevel = 0
THEN GOTO CONTINUE;
FI;
IF (NestingLevel > 1)
THEN FOR i ← 1 to (NestingLevel - 1)
DO
IF 64-Bit Mode (StackSize = 64)
THEN
RBP ← RBP - 8;
Push([RBP]); (* Quadword push *)
ELSE IF OperandSize = 32
THEN
IF StackSize = 32
EBP ← EBP - 4;
Push([EBP]); (* Doubleword push *)
ELSE (* StackSize = 16 *)
BP ← BP - 4;
Push([BP]); (* Doubleword push *)
FI;
FI;
ELSE (* OperandSize = 16 *)
IF StackSize = 32
THEN

Vol. 2A 3-329
INSTRUCTION SET REFERENCE, A-M
ENTER—Make Stack Frame for Procedure Parameters
EBP ← EBP - 2;
Push([EBP]); (* Word push *)
ELSE (* StackSize = 16 *)
BP ← BP - 2;
Push([BP]); (* Word push *)
FI;
FI;
OD;
FI;
IF 64-Bit Mode (StackSize = 64)
THEN
Push(FrameTemp); (* Quadword push *)
ELSE IF OperandSize = 32
THEN
Push(FrameTemp); FI; (* Doubleword push *)
ELSE (* OperandSize = 16 *)
Push(FrameTemp); (* Word push *)
FI;
CONTINUE:
IF 64-Bit Mode (StackSize = 64)
THEN
RBP ← FrameTemp;
RSP ← RSP − Size;
ELSE IF StackSize = 32
THEN
EBP ← FrameTemp;
ESP ← ESP − Size; FI;
ELSE (* StackSize = 16 *)
BP ← FrameTemp;
SP ← SP − Size;
FI;
END;
Flags Affected
None.
Protected Mode Exceptions
#SS(0) If the new value of the SP or ESP register is outside the stack
segment limit.

3-330 Vol. 2A ENTER—Make Stack Frame for Procedure Parameters
INSTRUCTION SET REFERENCE, A-M
#PF(fault-code) If a page fault occurs or if a write using the final value of the
stack pointer (within the current stack segment) would cause a
page fault.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#SS If the new value of the SP or ESP register is outside the stack
segment limit.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#SS(0) If the new value of the SP or ESP register is outside the stack
segment limit.
#PF(fault-code) If a page fault occurs or if a write using the final value of the
stack pointer (within the current stack segment) would cause a
page fault.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If the stack address is in a non-canonical form.
#PF(fault-code) If a page fault occurs or if a write using the final value of the
stack pointer (within the current stack segment) would cause a
page fault.
#UD If the LOCK prefix is used.

Vol. 2A 3-331
INSTRUCTION SET REFERENCE, A-M
VEXTRACTF128 — Extract Packed Floating-Point Values
VEXTRACTF128 — Extract Packed Floating-Point Values
Instruction Operand Encoding
Description
Extracts 128-bits of packed floating-point values from the source operand (second
operand) at an 128-bit offset from imm8[0] into the destination operand (first
operand). The destination may be either an XMM register or an 128-bit memory loca-
tion.
VEX.vvvv is reserved and must be 1111b otherwise instructions will #UD.
The high 7 bits of the immediate are ignored.
If VEXTRACTF128 is encoded with VEX.L= 0, an attempt to execute the instruction
encoded with VEX.L= 0 will cause an #UD exception.
Operation
VEXTRACTF128 (memory destination form)
CASE (imm8[0]) OF
0: DEST[127:0] SRC1[127:0]
1: DEST[127:0] SRC1[255:128]
ESAC.
VEXTRACTF128 (register destination form)
CASE (imm8[0]) OF
0: DEST[127:0] SRC1[127:0]
1: DEST[127:0] SRC1[255:128]
ESAC.
DEST[VLMAX-1:128] 0
Intel C/C++ Compiler Intrinsic Equivalent
VEXTRACTF128 __m128 _mm256_extractf128_ps (__m256 a, int offset);
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
VEX.256.66.0F3A.W0 19 /r ib
VEXTRACTF128 xmm1/m128,
ymm2, imm8
A V/V AVX Extract 128 bits of packed
floating-point values from
ymm2 and store results in
xmm1/mem.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (w) ModRM:reg (r) NA NA

3-332 Vol. 2A VEXTRACTF128 — Extract Packed Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
VEXTRACTF128 __m128d _mm256_extractf128_pd (__m256d a, int offset);
VEXTRACTF128 __m128i_mm256_extractf128_si256(__m256i a, int offset);
SIMD Floating-Point Exceptions
None
Other Exceptions
See Exceptions Type 6; additionally
#UD If VEX.L= 0
If VEX.W=1.
Vol. 2A 3-333
INSTRUCTION SET REFERENCE, A-M
EXTRACTPS — Extract Packed Single Precision Floating-Point Value
EXTRACTPS — Extract Packed Single Precision Floating-Point Value
Instruction Operand Encoding
Description
Extracts a single-precision floating-point value from the source operand (second
operand) at the 32-bit offset specified from imm8. Immediate bits higher than the
most significant offset for the vector length are ignored.
The extracted single-precision floating-point value is stored in the low 32-bits of the
destination operand
In 64-bit mode, destination register operand has default operand size of 64 bits. The
upper 32-bits of the register are filled with zero. REX.W is ignored.
128-bit Legacy SSE version: When a REX.W prefix is used in 64-bit mode with a
general purpose register (GPR) as a destination operand, the packed single quantity
is zero extended to 64 bits.
VEX.128 encoded version: When VEX.128.66.0F3A.W1 17 form is used in 64-bit
mode with a general purpose register (GPR) as a destination operand, the packed
single quantity is zero extended to 64 bits. VEX.vvvv is reserved and must be 1111b
otherwise instructions will #UD.
The source register is an XMM register. Imm8[1:0] determine the starting DWORD
offset from which to extract the 32-bit floating-point value.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 3A 17
/r ib
EXTRACTPS reg/m32, xmm2, imm8
A V/V SSE4_1 Extract a single-precision
floating-point value from
xmm2 at the source offset
specified by imm8 and store
the result to reg or m32.
The upper 32 bits of r64 is
zeroed if reg is r64.
VEX.128.66.0F3A.WIG 17 /r ib
VEXTRACTPS r/m32, xmm1, imm8
A V/V AVX Extract one single-precision
floating-point value from
xmm1 at the offset
specified by imm8 and store
the result in reg or m32.
Zero extend the results in
64-bit register if applicable.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (w) ModRM:reg (r) imm8 NA

3-334 Vol. 2A EXTRACTPS — Extract Packed Single Precision Floating-Point Value
INSTRUCTION SET REFERENCE, A-M
If VEXTRACTPS is encoded with VEX.L= 1, an attempt to execute the instruction
encoded with VEX.L= 1 will cause an #UD exception.
Operation
EXTRACTPS (128-bit Legacy SSE version)
SRC_OFFSET IMM8[1:0]
IF ( 64-Bit Mode and DEST is register)
DEST[31:0] (SRC[127:0] » (SRC_OFFET*32)) AND 0FFFFFFFFh
DEST[63:32] 0
ELSE
DEST[31:0] (SRC[127:0] » (SRC_OFFET*32)) AND 0FFFFFFFFh
FI
VEXTRACTPS (VEX.128 encoded version)
SRC_OFFSET IMM8[1:0]
IF ( 64-Bit Mode and DEST is register)
DEST[31:0] (SRC[127:0] » (SRC_OFFET*32)) AND 0FFFFFFFFh
DEST[63:32] 0
ELSE
DEST[31:0] (SRC[127:0] » (SRC_OFFET*32)) AND 0FFFFFFFFh
FI
Intel C/C++ Compiler Intrinsic Equivalent
EXTRACTPS _mm_extractmem_ps (float *dest, __m128 a, const int nidx);
EXTRACTPS __m128 _mm_extract_ps (__m128 a, const int nidx);
SIMD Floating-Point Exceptions
None
Other Exceptions
See Exceptions Type 5; additionally
#UD If VEX.L= 1.

Vol. 2A 3-335
INSTRUCTION SET REFERENCE, A-M
F2XM1—Compute 2x–1
F2XM1—Compute 2x–1
Description
Computes the exponential value of 2 to the power of the source operand minus 1.
The source operand is located in register ST(0) and the result is also stored in ST(0).
The value of the source operand must lie in the range –1.0 to +1.0. If the source
value is outside this range, the result is undefined.
The following table shows the results obtained when computing the exponential
value of various classes of numbers, assuming that neither overflow nor underflow
occurs.
Values other than 2 can be exponentiated using the following formula:
xy ← 2(y ∗ log2x)
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
ST(0) ← (2ST(0) − 1);
FPU Flags Affected
C1 Set to 0 if stack underflow occurred.
Set if result was rounded up; cleared otherwise.
C0, C2, C3 Undefined.
Floating-Point Exceptions
#IS Stack underflow occurred.
#IA Source operand is an SNaN value or unsupported format.
#D Source is a denormal value.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D9 F0 F2XM1 Valid Valid Replace ST(0) with (2ST(0) – 1).
Table 3-26. Results Obtained from F2XM1
ST(0) SRC ST(0) DEST
− 1.0 to −0− 0.5 to − 0
− 0− 0
+ 0+ 0
+ 0 to +1.0 + 0 to 1.0

3-336 Vol. 2A F2XM1—Compute 2x–1
INSTRUCTION SET REFERENCE, A-M
#U Result is too small for destination format.
#P Value cannot be represented exactly in destination format.
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.
Vol. 2A 3-337
INSTRUCTION SET REFERENCE, A-M
FABS—Absolute Value
FABS—Absolute Value
Description
Clears the sign bit of ST(0) to create the absolute value of the operand. The following
table shows the results obtained when creating the absolute value of various classes
of numbers.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
ST(0) ← |ST(0)|;
FPU Flags Affected
C1 Set to 0 if stack underflow occurred; otherwise, set to 0.
C0, C2, C3 Undefined.
Floating-Point Exceptions
#IS Stack underflow occurred.
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#UD If the LOCK prefix is used.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D9 E1 FABS Valid Valid Replace ST with its absolute value.
Table 3-27. Results Obtained from FABS
ST(0) SRC ST(0) DEST
− •+ •
− F+ F
− 0+ 0
+ 0+ 0
+ F+ F
+ •+ •
NaN NaN
NOTES:
FMeans finite floating-point value.

3-338 Vol. 2A FABS—Absolute Value
INSTRUCTION SET REFERENCE, A-M
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.

Vol. 2A 3-339
INSTRUCTION SET REFERENCE, A-M
FADD/FADDP/FIADD—Add
FADD/FADDP/FIADD—Add
Description
Adds the destination and source operands and stores the sum in the destination loca-
tion. The destination operand is always an FPU register; the source operand can be a
register or a memory location. Source operands in memory can be in single-precision
or double-precision floating-point format or in word or doubleword integer format.
The no-operand version of the instruction adds the contents of the ST(0) register to
the ST(1) register. The one-operand version adds the contents of a memory location
(either a floating-point or an integer value) to the contents of the ST(0) register. The
two-operand version, adds the contents of the ST(0) register to the ST(i) register or
vice versa. The value in ST(0) can be doubled by coding:
FADD ST(0), ST(0);
The FADDP instructions perform the additional operation of popping the FPU register
stack after storing the result. To pop the register stack, the processor marks the
ST(0) register as empty and increments the stack pointer (TOP) by 1. (The no-
operand version of the floating-point add instructions always results in the register
stack being popped. In some assemblers, the mnemonic for this instruction is FADD
rather than FADDP.)
The FIADD instructions convert an integer source operand to double extended-preci-
sion floating-point format before performing the addition.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D8 /0 FADD m32fp Valid Valid Add m32fp to ST(0) and store result
in ST(0).
DC /0 FADD m64fp Valid Valid Add m64fp to ST(0) and store result
in ST(0).
D8 C0+i FADD ST(0), ST(i) Valid Valid Add ST(0) to ST(i) and store result in
ST(0).
DC C0+i FADD ST(i), ST(0) Valid Valid Add ST(i) to ST(0) and store result in
ST(i).
DE C0+i FADDP ST(i), ST(0) Valid Valid Add ST(0) to ST(i), store result in
ST(i), and pop the register stack.
DE C1 FADDP Valid Valid Add ST(0) to ST(1), store result in
ST(1), and pop the register stack.
DA /0 FIADD m32int Valid Valid Add m32int to ST(0) and store
result in ST(0).
DE /0 FIADD m16int Valid Valid Add m16int to ST(0) and store
result in ST(0).
3-340 Vol. 2A FADD/FADDP/FIADD—Add
INSTRUCTION SET REFERENCE, A-M
The table on the following page shows the results obtained when adding various
classes of numbers, assuming that neither overflow nor underflow occurs.
When the sum of two operands with opposite signs is 0, the result is +0, except for
the round toward −∞ mode, in which case the result is −0. When the source operand
is an integer 0, it is treated as a +0.
When both operand are infinities of the same sign, the result is ∞ of the expected
sign. If both operands are infinities of opposite signs, an invalid-operation exception
is generated. See Table 3-28.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
IF Instruction = FIADD
THEN
DEST ← DEST + ConvertToDoubleExtendedPrecisionFP(SRC);
ELSE (* Source operand is floating-point value *)
DEST ← DEST + SRC;
FI;
IF Instruction = FADDP
THEN
PopRegisterStack;
FI;
Table 3-28. FADD/FADDP/FIADD Results
DEST
- ∞− F− 0+ 0 + F+ ∞NaN
- ∞- ∞- ∞- ∞ - ∞- ∞*NaN
− F or − I- ∞− FSRCSRC± F or ± 0+ ∞NaN
SRC −0- ∞DEST − 0± 0DEST+ ∞NaN
+ 0- ∞ DEST ± 0+ 0DEST+ ∞NaN
+ F or + I- ∞± F or ± 0SRC SRC + F+ ∞NaN
+ ∞*+ ∞+ ∞+ ∞+ ∞+ ∞NaN
NaN NaN NaN NaN NaN NaN NaN NaN
NOTES:
F Means finite floating-point value.
IMeans integer.
* Indicates floating-point invalid-arithmetic-operand (#IA) exception.

Vol. 2A 3-341
INSTRUCTION SET REFERENCE, A-M
FADD/FADDP/FIADD—Add
FPU Flags Affected
C1 Set to 0 if stack underflow occurred.
Set if result was rounded up; cleared otherwise.
C0, C2, C3 Undefined.
Floating-Point Exceptions
#IS Stack underflow occurred.
#IA Operand is an SNaN value or unsupported format.
Operands are infinities of unlike sign.
#D Source operand is a denormal value.
#U Result is too small for destination format.
#O Result is too large for destination format.
#P Value cannot be represented exactly in destination format.
Protected Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.

3-342 Vol. 2A FADD/FADDP/FIADD—Add
INSTRUCTION SET REFERENCE, A-M
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.

Vol. 2A 3-343
INSTRUCTION SET REFERENCE, A-M
FBLD—Load Binary Coded Decimal
FBLD—Load Binary Coded Decimal
Description
Converts the BCD source operand into double extended-precision floating-point
format and pushes the value onto the FPU stack. The source operand is loaded
without rounding errors. The sign of the source operand is preserved, including that
of −0.
The packed BCD digits are assumed to be in the range 0 through 9; the instruction
does not check for invalid digits (AH through FH). Attempting to load an invalid
encoding produces an undefined result.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
TOP ← TOP − 1;
ST(0) ← ConvertToDoubleExtendedPrecisionFP(SRC);
FPU Flags Affected
C1 Set to 1 if stack overflow occurred; otherwise, set to 0.
C0, C2, C3 Undefined.
Floating-Point Exceptions
#IS Stack overflow occurred.
Protected Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
DF /4 FBLD m80 dec Valid Valid Convert BCD value to floating-point and
push onto the FPU stack.

3-344 Vol. 2A FBLD—Load Binary Coded Decimal
INSTRUCTION SET REFERENCE, A-M
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Vol. 2A 3-345
INSTRUCTION SET REFERENCE, A-M
FBSTP—Store BCD Integer and Pop
FBSTP—Store BCD Integer and Pop
Description
Converts the value in the ST(0) register to an 18-digit packed BCD integer, stores the
result in the destination operand, and pops the register stack. If the source value is a
non-integral value, it is rounded to an integer value, according to rounding mode
specified by the RC field of the FPU control word. To pop the register stack, the
processor marks the ST(0) register as empty and increments the stack pointer (TOP)
by 1.
The destination operand specifies the address where the first byte destination value
is to be stored. The BCD value (including its sign bit) requires 10 bytes of space in
memory.
The following table shows the results obtained when storing various classes of
numbers in packed BCD format.
If the converted value is too large for the destination format, or if the source operand
is an ∞, SNaN, QNAN, or is in an unsupported format, an invalid-arithmetic-operand
condition is signaled. If the invalid-operation exception is not masked, an invalid-
arithmetic-operand exception (#IA) is generated and no value is stored in the desti-
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
DF /6 FBSTP m80bcd Valid Valid Store ST(0) in m80bcd and pop ST(0).
Table 3-29. FBSTP Results
ST(0) DEST
− • or Value Too Large for DEST Format *
F ≤ − 1− D
−1 < F < -0**
− 0 − 0
+ 0+ 0
+ 0 < F < +1**
F ≥ +1+ D
+ • or Value Too Large for DEST Format *
NaN *
NOTES:
FMeans finite floating-point value.
D Means packed-BCD number.
* Indicates floating-point invalid-operation (#IA) exception.
** ±0 or ±1, depending on the rounding mode.

3-346 Vol. 2A FBSTP—Store BCD Integer and Pop
INSTRUCTION SET REFERENCE, A-M
nation operand. If the invalid-operation exception is masked, the packed BCD indef-
inite value is stored in memory.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
DEST ← BCD(ST(0));
PopRegisterStack;
FPU Flags Affected
C1 Set to 0 if stack underflow occurred.
Set if result was rounded up; cleared otherwise.
C0, C2, C3 Undefined.
Floating-Point Exceptions
#IS Stack underflow occurred.
#IA Converted value that exceeds 18 BCD digits in length.
Source operand is an SNaN, QNaN, ±∞, or in an unsupported
format.
#P Value cannot be represented exactly in destination format.
Protected Mode Exceptions
#GP(0) If a segment register is being loaded with a segment selector
that points to a non-writable segment.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.

Vol. 2A 3-347
INSTRUCTION SET REFERENCE, A-M
FBSTP—Store BCD Integer and Pop
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.

3-348 Vol. 2A FCHS—Change Sign
INSTRUCTION SET REFERENCE, A-M
FCHS—Change Sign
Description
Complements the sign bit of ST(0). This operation changes a positive value into a
negative value of equal magnitude or vice versa. The following table shows the
results obtained when changing the sign of various classes of numbers.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
SignBit(ST(0)) ← NOT (SignBit(ST(0)));
FPU Flags Affected
C1 Set to 0 if stack underflow occurred; otherwise, set to 0.
C0, C2, C3 Undefined.
Floating-Point Exceptions
#IS Stack underflow occurred.
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#UD If the LOCK prefix is used.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D9 E0 FCHS Valid Valid Complements sign of ST(0).
Table 3-30. FCHS Results
ST(0) SRC ST(0) DEST
− • + •
− F+ F
− 0+ 0
+ 0− 0
+ F− F
+ • − •
NaN NaN
NOTES:
* F means finite floating-point value.

Vol. 2A 3-349
INSTRUCTION SET REFERENCE, A-M
FCHS—Change Sign
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.

3-350 Vol. 2A FCLEX/FNCLEX—Clear Exceptions
INSTRUCTION SET REFERENCE, A-M
FCLEX/FNCLEX—Clear Exceptions
Description
Clears the floating-point exception flags (PE, UE, OE, ZE, DE, and IE), the exception
summary status flag (ES), the stack fault flag (SF), and the busy flag (B) in the FPU
status word. The FCLEX instruction checks for and handles any pending unmasked
floating-point exceptions before clearing the exception flags; the FNCLEX instruction
does not.
The assembler issues two instructions for the FCLEX instruction (an FWAIT instruc-
tion followed by an FNCLEX instruction), and the processor executes each of these
instructions separately. If an exception is generated for either of these instructions,
the save EIP points to the instruction that caused the exception.
IA-32 Architecture Compatibility
When operating a Pentium or Intel486 processor in MS-DOS* compatibility mode, it
is possible (under unusual circumstances) for an FNCLEX instruction to be inter-
rupted prior to being executed to handle a pending FPU exception. See the section
titled “No-Wait FPU Instructions Can Get FPU Interrupt in Window” in Appendix D of
the Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 1, for a
description of these circumstances. An FNCLEX instruction cannot be interrupted in
this way on a Pentium 4, Intel Xeon, or P6 family processor.
This instruction affects only the x87 FPU floating-point exception flags. It does not
affect the SIMD floating-point exception flags in the MXCRS register.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
FPUStatusWord[0:7] ← 0;
FPUStatusWord[15] ← 0;
Opcode* Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
9B DB E2 FCLEX Valid Valid Clear floating-point exception flags after
checking for pending unmasked floating-
point exceptions.
DB E2 FNCLEX*Valid Valid Clear floating-point exception flags
without checking for pending unmasked
floating-point exceptions.
NOTES:
* See IA-32 Architecture Compatibility section below.

Vol. 2A 3-351
INSTRUCTION SET REFERENCE, A-M
FCLEX/FNCLEX—Clear Exceptions
FPU Flags Affected
The PE, UE, OE, ZE, DE, IE, ES, SF, and B flags in the FPU status word are cleared.
The C0, C1, C2, and C3 flags are undefined.
Floating-Point Exceptions
None.
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.

3-352 Vol. 2A FCMOVcc—Floating-Point Conditional Move
INSTRUCTION SET REFERENCE, A-M
FCMOVcc—Floating-Point Conditional Move
Description
Tests the status flags in the EFLAGS register and moves the source operand (second
operand) to the destination operand (first operand) if the given test condition is true.
The condition for each mnemonic os given in the Description column above and in
Chapter 8 in the Intel® 64 and IA-32 Architectures Software Developer’s Manual,
Volume 1. The source operand is always in the ST(i) register and the destination
operand is always ST(0).
The FCMOVcc instructions are useful for optimizing small IF constructions. They also
help eliminate branching overhead for IF operations and the possibility of branch
mispredictions by the processor.
A processor may not support the FCMOVcc instructions. Software can check if the
FCMOVcc instructions are supported by checking the processor’s feature information
with the CPUID instruction (see “COMISS—Compare Scalar Ordered Single-Precision
Floating-Point Values and Set EFLAGS” in this chapter). If both the CMOV and FPU
feature bits are set, the FCMOVcc instructions are supported.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
IA-32 Architecture Compatibility
The FCMOVcc instructions were introduced to the IA-32 Architecture in the P6 family
processors and are not available in earlier IA-32 processors.
Opcode* Instruction 64-Bit
Mode
Compat/
Leg Mode*
Description
DA C0+i FCMOVB ST(0), ST(i) Valid Valid Move if below (CF=1).
DA C8+i FCMOVE ST(0), ST(i) Valid Valid Move if equal (ZF=1).
DA D0+i FCMOVBE ST(0), ST(i) Valid Valid Move if below or equal (CF=1 or
ZF=1).
DA D8+i FCMOVU ST(0), ST(i) Valid Valid Move if unordered (PF=1).
DB C0+i FCMOVNB ST(0), ST(i) Valid Valid Move if not below (CF=0).
DB C8+i FCMOVNE ST(0), ST(i) Valid Valid Move if not equal (ZF=0).
DB D0+i FCMOVNBE ST(0), ST(i) Valid Valid Move if not below or equal (CF=0
and ZF=0).
DB D8+i FCMOVNU ST(0), ST(i) Valid Valid Move if not unordered (PF=0).
NOTES:
* See IA-32 Architecture Compatibility section below.

Vol. 2A 3-353
INSTRUCTION SET REFERENCE, A-M
FCMOVcc—Floating-Point Conditional Move
Operation
IF condition TRUE
THEN ST(0) ← ST(i);
FI;
FPU Flags Affected
C1 Set to 0 if stack underflow occurred.
C0, C2, C3 Undefined.
Floating-Point Exceptions
#IS Stack underflow occurred.
Integer Flags Affected
None.
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.

3-354 Vol. 2A FCMOVcc—Floating-Point Conditional Move
INSTRUCTION SET REFERENCE, A-M
FCOM/FCOMP/FCOMPP—Compare Floating Point Values
Description
Compares the contents of register ST(0) and source value and sets condition code
flags C0, C2, and C3 in the FPU status word according to the results (see the table
below). The source operand can be a data register or a memory location. If no source
operand is given, the value in ST(0) is compared with the value in ST(1). The sign of
zero is ignored, so that –0.0 is equal to +0.0.
This instruction checks the class of the numbers being compared (see
“FXAM—Examine ModR/M” in this chapter). If either operand is a NaN or is in an
unsupported format, an invalid-arithmetic-operand exception (#IA) is raised and, if
the exception is masked, the condition flags are set to “unordered.” If the invalid-
arithmetic-operand exception is unmasked, the condition code flags are not set.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D8 /2 FCOM m32fp Valid Valid Compare ST(0) with m32fp.
DC /2 FCOM m64fp Valid Valid Compare ST(0) with m64fp.
D8 D0+i FCOM ST(i) Valid Valid Compare ST(0) with ST(i).
D8 D1 FCOM Valid Valid Compare ST(0) with ST(1).
D8 /3 FCOMP m32fp Valid Valid Compare ST(0) with m32fp and
pop register stack.
DC /3 FCOMP m64fp Valid Valid Compare ST(0) with m64fp and
pop register stack.
D8 D8+i FCOMP ST(i) Valid Valid Compare ST(0) with ST(i) and pop
register stack.
D8 D9 FCOMP Valid Valid Compare ST(0) with ST(1) and pop
register stack.
DE D9 FCOMPP Valid Valid Compare ST(0) with ST(1) and pop
register stack twice.
Table 3-31. FCOM/FCOMP/FCOMPP Results
Condition C3 C2 C0
ST(0) > SRC 0 0 0
ST(0) < SRC 0 0 1
ST(0) = SRC 1 0 0
Unordered* 1 1 1
NOTES:
* Flags not set if unmasked invalid-arithmetic-operand (#IA) exception is generated.

Vol. 2A 3-355
INSTRUCTION SET REFERENCE, A-M
FCMOVcc—Floating-Point Conditional Move
The FCOMP instruction pops the register stack following the comparison operation
and the FCOMPP instruction pops the register stack twice following the comparison
operation. To pop the register stack, the processor marks the ST(0) register as
empty and increments the stack pointer (TOP) by 1.
The FCOM instructions perform the same operation as the FUCOM instructions. The
only difference is how they handle QNaN operands. The FCOM instructions raise an
invalid-arithmetic-operand exception (#IA) when either or both of the operands is a
NaN value or is in an unsupported format. The FUCOM instructions perform the same
operation as the FCOM instructions, except that they do not generate an invalid-
arithmetic-operand exception for QNaNs.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
CASE (relation of operands) OF
ST > SRC: C3, C2, C0 ← 000;
ST < SRC: C3, C2, C0 ← 001;
ST = SRC: C3, C2, C0 ← 100;
ESAC;
IF ST(0) or SRC = NaN or unsupported format
THEN
#IA
IF FPUControlWord.IM = 1
THEN
C3, C2, C0 ← 111;
FI;
FI;
IF Instruction = FCOMP
THEN
PopRegisterStack;
FI;
IF Instruction = FCOMPP
THEN
PopRegisterStack;
PopRegisterStack;
FI;
FPU Flags Affected
C1 Set to 0 if stack underflow occurred; otherwise, set to 0.
C0, C2, C3 See table on previous page.

3-356 Vol. 2A FCMOVcc—Floating-Point Conditional Move
INSTRUCTION SET REFERENCE, A-M
Floating-Point Exceptions
#IS Stack underflow occurred.
#IA One or both operands are NaN values or have unsupported
formats.
Register is marked empty.
#D One or both operands are denormal values.
Protected Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.

Vol. 2A 3-357
INSTRUCTION SET REFERENCE, A-M
FCMOVcc—Floating-Point Conditional Move
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
3-358 Vol. 2A FCOMI/FCOMIP/ FUCOMI/FUCOMIP—Compare Floating Point Values and Set EFLAGS
INSTRUCTION SET REFERENCE, A-M
FCOMI/FCOMIP/ FUCOMI/FUCOMIP—Compare Floating Point Values and
Set EFLAGS
Description
Performs an unordered comparison of the contents of registers ST(0) and ST(i) and
sets the status flags ZF, PF, and CF in the EFLAGS register according to the results
(see the table below). The sign of zero is ignored for comparisons, so that –0.0 is
equal to +0.0.
An unordered comparison checks the class of the numbers being compared (see
“FXAM—Examine ModR/M” in this chapter). The FUCOMI/FUCOMIP instructions
perform the same operations as the FCOMI/FCOMIP instructions. The only difference
is that the FUCOMI/FUCOMIP instructions raise the invalid-arithmetic-operand
exception (#IA) only when either or both operands are an SNaN or are in an unsup-
ported format; QNaNs cause the condition code flags to be set to unordered, but do
not cause an exception to be generated. The FCOMI/FCOMIP instructions raise an
invalid-operation exception when either or both of the operands are a NaN value of
any kind or are in an unsupported format.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
DB F0+i FCOMI ST, ST(i) Valid Valid Compare ST(0) with ST(i) and set status
flags accordingly.
DF F0+i FCOMIP ST, ST(i) Valid Valid Compare ST(0) with ST(i), set status flags
accordingly, and pop register stack.
DB E8+i FUCOMI ST, ST(i) Valid Valid Compare ST(0) with ST(i), check for
ordered values, and set status flags
accordingly.
DF E8+i FUCOMIP ST, ST(i) Valid Valid Compare ST(0) with ST(i), check for
ordered values, set status flags
accordingly, and pop register stack.
Table 3-32. FCOMI/FCOMIP/ FUCOMI/FUCOMIP Results
Comparison Results* ZF PF CF
ST0 > ST(i) 0 0 0
ST0 < ST(i) 0 0 1
ST0 = ST(i) 1 0 0
Unordered** 1 1 1
NOTES:
* See the IA-32 Architecture Compatibility section below.
** Flags not set if unmasked invalid-arithmetic-operand (#IA) exception is generated.

Vol. 2A 3-359
INSTRUCTION SET REFERENCE, A-M
FCOMI/FCOMIP/ FUCOMI/FUCOMIP—Compare Floating Point Values and Set EFLAGS
If the operation results in an invalid-arithmetic-operand exception being raised, the
status flags in the EFLAGS register are set only if the exception is masked.
The FCOMI/FCOMIP and FUCOMI/FUCOMIP instructions clear the OF flag in the
EFLAGS register (regardless of whether an invalid-operation exception is detected).
The FCOMIP and FUCOMIP instructions also pop the register stack following the
comparison operation. To pop the register stack, the processor marks the ST(0)
register as empty and increments the stack pointer (TOP) by 1.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
IA-32 Architecture Compatibility
The FCOMI/FCOMIP/FUCOMI/FUCOMIP instructions were introduced to the IA-32
Architecture in the P6 family processors and are not available in earlier IA-32 proces-
sors.
Operation
CASE (relation of operands) OF
ST(0) > ST(i): ZF, PF, CF ← 000;
ST(0) < ST(i): ZF, PF, CF ← 001;
ST(0) = ST(i): ZF, PF, CF ← 100;
ESAC;
IF Instruction is FCOMI or FCOMIP
THEN
IF ST(0) or ST(i) = NaN or unsupported format
THEN
#IA
IF FPUControlWord.IM = 1
THEN
ZF, PF, CF ← 111;
FI;
FI;
FI;
IF Instruction is FUCOMI or FUCOMIP
THEN
IF ST(0) or ST(i) = QNaN, but not SNaN or unsupported format
THEN
ZF, PF, CF ← 111;
ELSE (* ST(0) or ST(i) is SNaN or unsupported format *)
#IA;
IF FPUControlWord.IM = 1
THEN

3-360 Vol. 2A FCOMI/FCOMIP/ FUCOMI/FUCOMIP—Compare Floating Point Values and Set EFLAGS
INSTRUCTION SET REFERENCE, A-M
ZF, PF, CF ← 111;
FI;
FI;
FI;
IF Instruction is FCOMIP or FUCOMIP
THEN
PopRegisterStack;
FI;
FPU Flags Affected
C1 Set to 0 if stack underflow occurred; otherwise, set to 0.
C0, C2, C3 Not affected.
Floating-Point Exceptions
#IS Stack underflow occurred.
#IA (FCOMI or FCOMIP instruction) One or both operands are NaN
values or have unsupported formats.
(FUCOMI or FUCOMIP instruction) One or both operands are
SNaN values (but not QNaNs) or have undefined formats.
Detection of a QNaN value does not raise an invalid-operand
exception.
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.
Vol. 2A 3-361
INSTRUCTION SET REFERENCE, A-M
FCOS—Cosine
FCOS—Cosine
Description
Computes the cosine of the source operand in register ST(0) and stores the result in
ST(0). The source operand must be given in radians and must be within the range −
263 to +263. The following table shows the results obtained when taking the cosine of
various classes of numbers.
If the source operand is outside the acceptable range, the C2 flag in the FPU status
word is set, and the value in register ST(0) remains unchanged. The instruction does
not raise an exception when the source operand is out of range. It is up to the
program to check the C2 flag for out-of-range conditions. Source values outside the
range −263 to +263 can be reduced to the range of the instruction by subtracting an
appropriate integer multiple of 2π or by using the FPREM instruction with a divisor of
2π. See the section titled “Pi” in Chapter 8 of the Intel® 64 and IA-32 Architectures
Software Developer’s Manual, Volume 1, for a discussion of the proper value to use
for π in performing such reductions.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
IF |ST(0)| < 263
THEN
C2 ← 0;
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D9 FF FCOS Valid Valid Replace ST(0) with its cosine.
Table 3-33. FCOS Results
ST(0) SRC ST(0) DEST
− •*
− F−1 to +1
− 0+ 1
+ 0+ 1
+ F− 1 to + 1
+ •*
NaN NaN
NOTES:
FMeans finite floating-point value.
* Indicates floating-point invalid-arithmetic-operand (#IA) exception.

3-362 Vol. 2A FCOS—Cosine
INSTRUCTION SET REFERENCE, A-M
ST(0) ← cosine(ST(0));
ELSE (* Source operand is out-of-range *)
C2 ← 1;
FI;
FPU Flags Affected
C1 Set to 0 if stack underflow occurred.
Set if result was rounded up; cleared otherwise.
Undefined if C2 is 1.
C2 Set to 1 if outside range (−263 < source operand < +263); other-
wise, set to 0.
C0, C3 Undefined.
Floating-Point Exceptions
#IS Stack underflow occurred.
#IA Source operand is an SNaN value, ∞, or unsupported format.
#D Source is a denormal value.
#P Value cannot be represented exactly in destination format.
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.

Vol. 2A 3-363
INSTRUCTION SET REFERENCE, A-M
FDECSTP—Decrement Stack-Top Pointer
FDECSTP—Decrement Stack-Top Pointer
Description
Subtracts one from the TOP field of the FPU status word (decrements the top-of-
stack pointer). If the TOP field contains a 0, it is set to 7. The effect of this instruction
is to rotate the stack by one position. The contents of the FPU data registers and tag
register are not affected.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
IF TOP = 0
THEN TOP ← 7;
ELSE TOP ← TOP – 1;
FI;
FPU Flags Affected
The C1 flag is set to 0. The C0, C2, and C3 flags are undefined.
Floating-Point Exceptions
None.
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D9 F6 FDECSTP Valid Valid Decrement TOP field in FPU status
word.

3-364 Vol. 2A FDECSTP—Decrement Stack-Top Pointer
INSTRUCTION SET REFERENCE, A-M
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.

Vol. 2A 3-365
INSTRUCTION SET REFERENCE, A-M
FDIV/FDIVP/FIDIV—Divide
FDIV/FDIVP/FIDIV—Divide
Description
Divides the destination operand by the source operand and stores the result in the
destination location. The destination operand (dividend) is always in an FPU register;
the source operand (divisor) can be a register or a memory location. Source oper-
ands in memory can be in single-precision or double-precision floating-point format,
word or doubleword integer format.
The no-operand version of the instruction divides the contents of the ST(1) register
by the contents of the ST(0) register. The one-operand version divides the contents
of the ST(0) register by the contents of a memory location (either a floating-point or
an integer value). The two-operand version, divides the contents of the ST(0)
register by the contents of the ST(i) register or vice versa.
The FDIVP instructions perform the additional operation of popping the FPU register
stack after storing the result. To pop the register stack, the processor marks the
ST(0) register as empty and increments the stack pointer (TOP) by 1. The no-
operand version of the floating-point divide instructions always results in the register
stack being popped. In some assemblers, the mnemonic for this instruction is FDIV
rather than FDIVP.
The FIDIV instructions convert an integer source operand to double extended-preci-
sion floating-point format before performing the division. When the source operand
is an integer 0, it is treated as a +0.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D8 /6 FDIV m32fp Valid Valid Divide ST(0) by m32fp and store
result in ST(0).
DC /6 FDIV m64fp Valid Valid Divide ST(0) by m64fp and store
result in ST(0).
D8 F0+i FDIV ST(0), ST(i) Valid Valid Divide ST(0) by ST(i) and store result
in ST(0).
DC F8+i FDIV ST(i), ST(0) Valid Valid Divide ST(i) by ST(0) and store result
in ST(i).
DE F8+i FDIVP ST(i), ST(0) Valid Valid Divide ST(i) by ST(0), store result in
ST(i), and pop the register stack.
DE F9 FDIVP Valid Valid Divide ST(1) by ST(0), store result in
ST(1), and pop the register stack.
DA /6 FIDIV m32int Valid Valid Divide ST(0) by m32int and store
result in ST(0).
DE /6 FIDIV m16int Valid Valid Divide ST(0) by m64int and store
result in ST(0).
3-366 Vol. 2A FDIV/FDIVP/FIDIV—Divide
INSTRUCTION SET REFERENCE, A-M
If an unmasked divide-by-zero exception (#Z) is generated, no result is stored; if the
exception is masked, an ∞ of the appropriate sign is stored in the destination
operand.
The following table shows the results obtained when dividing various classes of
numbers, assuming that neither overflow nor underflow occurs.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
IF SRC = 0
THEN
#Z;
ELSE
IF Instruction is FIDIV
THEN
DEST ← DEST / ConvertToDoubleExtendedPrecisionFP(SRC);
ELSE (* Source operand is floating-point value *)
DEST ← DEST / SRC;
FI;
FI;
Table 3-34. FDIV/FDIVP/FIDIV Results
DEST
− •− F− 0+ 0+F+ • NaN
− • *+ 0+ 0− 0− 0* NaN
−F+ •+ F+ 0− 0− F− •NaN
−I+ •+ F+ 0− 0− F− •NaN
SRC −0+ • ******− • NaN
+0− •******+ • NaN
+I− •−F−0+0+ F+ • NaN
+F− •−F−0+0+ F+ • NaN
+ • *−0−0+0+ 0* NaN
NaN NaN NaN NaN NaN NaN NaN NaN
NOTES:
F Means finite floating-point value.
IMeans integer.
* Indicates floating-point invalid-arithmetic-operand (#IA) exception.
** Indicates floating-point zero-divide (#Z) exception.

Vol. 2A 3-367
INSTRUCTION SET REFERENCE, A-M
FDIV/FDIVP/FIDIV—Divide
IF Instruction = FDIVP
THEN
PopRegisterStack;
FI;
FPU Flags Affected
C1 Set to 0 if stack underflow occurred.
Set if result was rounded up; cleared otherwise.
C0, C2, C3 Undefined.
Floating-Point Exceptions
#IS Stack underflow occurred.
#IA Operand is an SNaN value or unsupported format.
±∞ / ±∞; ±0 / ±0
#D Source is a denormal value.
#Z DEST / ±0, where DEST is not equal to ±0.
#U Result is too small for destination format.
#O Result is too large for destination format.
#P Value cannot be represented exactly in destination format.
Protected Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#UD If the LOCK prefix is used.

3-368 Vol. 2A FDIV/FDIVP/FIDIV—Divide
INSTRUCTION SET REFERENCE, A-M
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.

Vol. 2A 3-369
INSTRUCTION SET REFERENCE, A-M
FDIVR/FDIVRP/FIDIVR—Reverse Divide
FDIVR/FDIVRP/FIDIVR—Reverse Divide
Description
Divides the source operand by the destination operand and stores the result in the
destination location. The destination operand (divisor) is always in an FPU register;
the source operand (dividend) can be a register or a memory location. Source oper-
ands in memory can be in single-precision or double-precision floating-point format,
word or doubleword integer format.
These instructions perform the reverse operations of the FDIV, FDIVP, and FIDIV
instructions. They are provided to support more efficient coding.
The no-operand version of the instruction divides the contents of the ST(0) register
by the contents of the ST(1) register. The one-operand version divides the contents
of a memory location (either a floating-point or an integer value) by the contents of
the ST(0) register. The two-operand version, divides the contents of the ST(i)
register by the contents of the ST(0) register or vice versa.
The FDIVRP instructions perform the additional operation of popping the FPU register
stack after storing the result. To pop the register stack, the processor marks the
ST(0) register as empty and increments the stack pointer (TOP) by 1. The no-
operand version of the floating-point divide instructions always results in the register
stack being popped. In some assemblers, the mnemonic for this instruction is FDIVR
rather than FDIVRP.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D8 /7 FDIVR m32fp Valid Valid Divide m32fp by ST(0) and store result
in ST(0).
DC /7 FDIVR m64fp Valid Valid Divide m64fp by ST(0) and store result
in ST(0).
D8 F8+i FDIVR ST(0), ST(i) Valid Valid Divide ST(i) by ST(0) and store result in
ST(0).
DC F0+i FDIVR ST(i), ST(0) Valid Valid Divide ST(0) by ST(i) and store result in
ST(i).
DE F0+i FDIVRP ST(i), ST(0) Valid Valid Divide ST(0) by ST(i), store result in
ST(i), and pop the register stack.
DE F1 FDIVRP Valid Valid Divide ST(0) by ST(1), store result in
ST(1), and pop the register stack.
DA /7 FIDIVR m32int Valid Valid Divide m32int by ST(0) and store result
in ST(0).
DE /7 FIDIVR m16int Valid Valid Divide m16int by ST(0) and store result
in ST(0).
3-370 Vol. 2A FDIVR/FDIVRP/FIDIVR—Reverse Divide
INSTRUCTION SET REFERENCE, A-M
The FIDIVR instructions convert an integer source operand to double extended-preci-
sion floating-point format before performing the division.
If an unmasked divide-by-zero exception (#Z) is generated, no result is stored; if the
exception is masked, an ∞ of the appropriate sign is stored in the destination
operand.
The following table shows the results obtained when dividing various classes of
numbers, assuming that neither overflow nor underflow occurs.
When the source operand is an integer 0, it is treated as a +0. This instruction’s oper-
ation is the same in non-64-bit modes and 64-bit mode.
Operation
IF DEST = 0
THEN
#Z;
ELSE
IF Instruction = FIDIVR
THEN
DEST ← ConvertToDoubleExtendedPrecisionFP(SRC) / DEST;
ELSE (* Source operand is floating-point value *)
Table 3-35. FDIVR/FDIVRP/FIDIVR Results
DEST
− • − F− 0+ 0+ F+ • NaN
− •*+ • + • − •− •*NaN
SRC − F+ 0+ F** **− F − 0NaN
− I+ 0+ F** **− F − 0NaN
− 0+ 0+ 0* *− 0− 0NaN
+ 0− 0− 0* *+ 0+ 0NaN
+ I− 0− F** **+ F + 0NaN
+ F− 0− F** **+ F+ 0NaN
+ • *− •− •+ • + • *NaN
NaN NaN NaN NaN NaN NaN NaN NaN
NOTES:
F Means finite floating-point value.
IMeans integer.
* Indicates floating-point invalid-arithmetic-operand (#IA) exception.
** Indicates floating-point zero-divide (#Z) exception.

Vol. 2A 3-371
INSTRUCTION SET REFERENCE, A-M
FDIVR/FDIVRP/FIDIVR—Reverse Divide
DEST ← SRC / DEST;
FI;
FI;
IF Instruction = FDIVRP
THEN
PopRegisterStack;
FI;
FPU Flags Affected
C1 Set to 0 if stack underflow occurred.
Set if result was rounded up; cleared otherwise.
C0, C2, C3 Undefined.
Floating-Point Exceptions
#IS Stack underflow occurred.
#IA Operand is an SNaN value or unsupported format.
±∞ / ±∞; ±0 / ±0
#D Source is a denormal value.
#Z SRC / ±0, where SRC is not equal to ±0.
#U Result is too small for destination format.
#O Result is too large for destination format.
#P Value cannot be represented exactly in destination format.
Protected Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.

3-372 Vol. 2A FDIVR/FDIVRP/FIDIVR—Reverse Divide
INSTRUCTION SET REFERENCE, A-M
#SS If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.

Vol. 2A 3-373
INSTRUCTION SET REFERENCE, A-M
FFREE—Free Floating-Point Register
FFREE—Free Floating-Point Register
Description
Sets the tag in the FPU tag register associated with register ST(i) to empty (11B).
The contents of ST(i) and the FPU stack-top pointer (TOP) are not affected.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
TAG(i) ← 11B;
FPU Flags Affected
C0, C1, C2, C3 undefined.
Floating-Point Exceptions
None.
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
DD C0+i FFREE ST(i) Valid Valid Sets tag for ST(i) to empty.
3-374 Vol. 2A FICOM/FICOMP—Compare Integer
INSTRUCTION SET REFERENCE, A-M
FICOM/FICOMP—Compare Integer
Description
Compares the value in ST(0) with an integer source operand and sets the condition
code flags C0, C2, and C3 in the FPU status word according to the results (see table
below). The integer value is converted to double extended-precision floating-point
format before the comparison is made.
These instructions perform an “unordered comparison.” An unordered comparison
also checks the class of the numbers being compared (see “FXAM—Examine
ModR/M” in this chapter). If either operand is a NaN or is in an undefined format, the
condition flags are set to “unordered.”
The sign of zero is ignored, so that –0.0 ← +0.0.
The FICOMP instructions pop the register stack following the comparison. To pop the
register stack, the processor marks the ST(0) register empty and increments the
stack pointer (TOP) by 1.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
CASE (relation of operands) OF
ST(0) > SRC: C3, C2, C0 ← 000;
ST(0) < SRC: C3, C2, C0 ← 001;
ST(0) = SRC: C3, C2, C0 ← 100;
Unordered: C3, C2, C0 ← 111;
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
DE /2 FICOM m16int Valid Valid Compare ST(0) with m16int.
DA /2 FICOM m32int Valid Valid Compare ST(0) with m32int.
DE /3 FICOMP m16int Valid Valid Compare ST(0) with m16int and pop
stack register.
DA /3 FICOMP m32int Valid Valid Compare ST(0) with m32int and pop
stack register.
Table 3-36. FICOM/FICOMP Results
Condition C3 C2 C0
ST(0) > SRC 0 0 0
ST(0) < SRC 0 0 1
ST(0) = SRC 1 0 0
Unordered 1 1 1

Vol. 2A 3-375
INSTRUCTION SET REFERENCE, A-M
FICOM/FICOMP—Compare Integer
ESAC;
IF Instruction = FICOMP
THEN
PopRegisterStack;
FI;
FPU Flags Affected
C1 Set to 0 if stack underflow occurred; otherwise, set to 0.
C0, C2, C3 See table on previous page.
Floating-Point Exceptions
#IS Stack underflow occurred.
#IA One or both operands are NaN values or have unsupported
formats.
#D One or both operands are denormal values.
Protected Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.

3-376 Vol. 2A FICOM/FICOMP—Compare Integer
INSTRUCTION SET REFERENCE, A-M
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.

Vol. 2A 3-377
INSTRUCTION SET REFERENCE, A-M
FILD—Load Integer
FILD—Load Integer
Description
Converts the signed-integer source operand into double extended-precision floating-
point format and pushes the value onto the FPU register stack. The source operand
can be a word, doubleword, or quadword integer. It is loaded without rounding
errors. The sign of the source operand is preserved.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
TOP ← TOP − 1;
ST(0) ← ConvertToDoubleExtendedPrecisionFP(SRC);
FPU Flags Affected
C1 Set to 1 if stack overflow occurred; set to 0 otherwise.
C0, C2, C3 Undefined.
Floating-Point Exceptions
#IS Stack overflow occurred.
Protected Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
DF /0 FILD m16int Valid Valid Push m16int onto the FPU register
stack.
DB /0 FILD m32int Valid Valid Push m32int onto the FPU register
stack.
DF /5 FILD m64int Valid Valid Push m64int onto the FPU register
stack.

3-378 Vol. 2A FILD—Load Integer
INSTRUCTION SET REFERENCE, A-M
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.

Vol. 2A 3-379
INSTRUCTION SET REFERENCE, A-M
FINCSTP—Increment Stack-Top Pointer
FINCSTP—Increment Stack-Top Pointer
Description
Adds one to the TOP field of the FPU status word (increments the top-of-stack
pointer). If the TOP field contains a 7, it is set to 0. The effect of this instruction is to
rotate the stack by one position. The contents of the FPU data registers and tag
register are not affected. This operation is not equivalent to popping the stack,
because the tag for the previous top-of-stack register is not marked empty.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
IF TOP = 7
THEN TOP ← 0;
ELSE TOP ← TOP + 1;
FI;
FPU Flags Affected
The C1 flag is set to 0. The C0, C2, and C3 flags are undefined.
Floating-Point Exceptions
None.
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D9 F7 FINCSTP Valid Valid Increment the TOP field in the FPU
status register.

3-380 Vol. 2A FINCSTP—Increment Stack-Top Pointer
INSTRUCTION SET REFERENCE, A-M
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.
Vol. 2A 3-381
INSTRUCTION SET REFERENCE, A-M
FINIT/FNINIT—Initialize Floating-Point Unit
FINIT/FNINIT—Initialize Floating-Point Unit
Description
Sets the FPU control, status, tag, instruction pointer, and data pointer registers to
their default states. The FPU control word is set to 037FH (round to nearest, all
exceptions masked, 64-bit precision). The status word is cleared (no exception flags
set, TOP is set to 0). The data registers in the register stack are left unchanged, but
they are all tagged as empty (11B). Both the instruction and data pointers are
cleared.
The FINIT instruction checks for and handles any pending unmasked floating-point
exceptions before performing the initialization; the FNINIT instruction does not.
The assembler issues two instructions for the FINIT instruction (an FWAIT instruction
followed by an FNINIT instruction), and the processor executes each of these instruc-
tions in separately. If an exception is generated for either of these instructions, the
save EIP points to the instruction that caused the exception.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
IA-32 Architecture Compatibility
When operating a Pentium or Intel486 processor in MS-DOS compatibility mode, it is
possible (under unusual circumstances) for an FNINIT instruction to be interrupted
prior to being executed to handle a pending FPU exception. See the section titled
“No-Wait FPU Instructions Can Get FPU Interrupt in Window” in Appendix D of the
Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 1, for a
description of these circumstances. An FNINIT instruction cannot be interrupted in
this way on a Pentium 4, Intel Xeon, or P6 family processor.
In the Intel387 math coprocessor, the FINIT/FNINIT instruction does not clear the
instruction and data pointers.
This instruction affects only the x87 FPU. It does not affect the XMM and MXCSR
registers.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
9B DB E3 FINIT Valid Valid Initialize FPU after checking for pending
unmasked floating-point exceptions.
DB E3 FNINIT*Valid Valid Initialize FPU without checking for
pending unmasked floating-point
exceptions.
NOTES:
* See IA-32 Architecture Compatibility section below.

3-382 Vol. 2A FINIT/FNINIT—Initialize Floating-Point Unit
INSTRUCTION SET REFERENCE, A-M
Operation
FPUControlWord ← 037FH;
FPUStatusWord ← 0;
FPUTagWord ← FFFFH;
FPUDataPointer ← 0;
FPUInstructionPointer ← 0;
FPULastInstructionOpcode ← 0;
FPU Flags Affected
C0, C1, C2, C3 set to 0.
Floating-Point Exceptions
None.
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.

Vol. 2A 3-383
INSTRUCTION SET REFERENCE, A-M
FIST/FISTP—Store Integer
FIST/FISTP—Store Integer
Description
The FIST instruction converts the value in the ST(0) register to a signed integer and
stores the result in the destination operand. Values can be stored in word or double-
word integer format. The destination operand specifies the address where the first
byte of the destination value is to be stored.
The FISTP instruction performs the same operation as the FIST instruction and then
pops the register stack. To pop the register stack, the processor marks the ST(0)
register as empty and increments the stack pointer (TOP) by 1. The FISTP instruction
also stores values in quadword integer format.
The following table shows the results obtained when storing various classes of
numbers in integer format.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
DF /2 FIST m16int Valid Valid Store ST(0) in m16int.
DB /2 FIST m32int Valid Valid Store ST(0) in m32int.
DF /3 FISTP m16int Valid Valid Store ST(0) in m16int and pop
register stack.
DB /3 FISTP m32int Valid Valid Store ST(0) in m32int and pop
register stack.
DF /7 FISTP m64int Valid Valid Store ST(0) in m64int and pop
register stack.
Table 3-37. FIST/FISTP Results
ST(0) DEST
−• or Value Too Large for DEST Format *
F ≤ −1− I
−1 < F < −0**
− 00
+ 00
+ 0 < F < + 1**
F ≥ + 1 + I
+• or Value Too Large for DEST Format *

3-384 Vol. 2A FIST/FISTP—Store Integer
INSTRUCTION SET REFERENCE, A-M
If the source value is a non-integral value, it is rounded to an integer value, according
to the rounding mode specified by the RC field of the FPU control word.
If the converted value is too large for the destination format, or if the source operand
is an ∞, SNaN, QNAN, or is in an unsupported format, an invalid-arithmetic-operand
condition is signaled. If the invalid-operation exception is not masked, an invalid-
arithmetic-operand exception (#IA) is generated and no value is stored in the desti-
nation operand. If the invalid-operation exception is masked, the integer indefinite
value is stored in memory.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
DEST ← Integer(ST(0));
IF Instruction = FISTP
THEN
PopRegisterStack;
FI;
FPU Flags Affected
C1 Set to 0 if stack underflow occurred.
Indicates rounding direction of if the inexact exception (#P) is
generated: 0 ← not roundup; 1 ← roundup.
Set to 0 otherwise.
C0, C2, C3 Undefined.
Floating-Point Exceptions
#IS Stack underflow occurred.
#IA Converted value is too large for the destination format.
Source operand is an SNaN, QNaN, ±∞, or unsupported format.
#P Value cannot be represented exactly in destination format.
NaN *
NOTES:
F Means finite floating-point value.
IMeans integer.
* Indicates floating-point invalid-operation (#IA) exception.
** 0 or ±1, depending on the rounding mode.
Table 3-37. FIST/FISTP Results (Contd.)
ST(0) DEST

Vol. 2A 3-385
INSTRUCTION SET REFERENCE, A-M
FIST/FISTP—Store Integer
Protected Mode Exceptions
#GP(0) If the destination is located in a non-writable segment.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register is used to access memory and it
contains a NULL segment selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.

3-386 Vol. 2A FIST/FISTP—Store Integer
INSTRUCTION SET REFERENCE, A-M
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Vol. 2A 3-387
INSTRUCTION SET REFERENCE, A-M
FISTTP—Store Integer with Truncation
FISTTP—Store Integer with Truncation
Description
FISTTP converts the value in ST into a signed integer using truncation (chop) as
rounding mode, transfers the result to the destination, and pop ST. FISTTP accepts
word, short integer, and long integer destinations.
The following table shows the results obtained when storing various classes of
numbers in integer format.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
DEST ← ST;
pop ST;
Flags Affected
C1 is cleared; C0, C2, C3 undefined.
Opcode Instruction 64-Bit Mode Compat/
Leg Mode
Description
DF /1 FISTTP m16int Valid Valid Store ST(0) in m16int with
truncation.
DB /1 FISTTP m32int Valid Valid Store ST(0) in m32int with
truncation.
DD /1 FISTTP m64int Valid Valid Store ST(0) in m64int with
truncation.
Table 3-38. FISTTP Results
ST(0) DEST
−• or Value Too Large for DEST Format *
F≤ − 1− I
− 1 <F<+ 10
FŠ+ 1+ I
+• or Value Too Large for DEST Format *
NaN *
NOTES:
FMeans finite floating-point value.
ΙMeans integer.
∗Indicates floating-point invalid-operation (#IA) exception.

3-388 Vol. 2A FISTTP—Store Integer with Truncation
INSTRUCTION SET REFERENCE, A-M
Numeric Exceptions
Invalid, Stack Invalid (stack underflow), Precision.
Protected Mode Exceptions
#GP(0) If the destination is in a nonwritable segment.
For an illegal memory operand effective address in the CS, DS,
ES, FS or GS segments.
#SS(0) For an illegal address in the SS segment.
#PF(fault-code) For a page fault.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#NM If CR0.EM[bit 2] = 1.
If CR0.TS[bit 3] = 1.
#UD If CPUID.01H:ECX.SSE3[bit 0] = 0.
If the LOCK prefix is used.
Real Address Mode Exceptions
GP(0) If any part of the operand would lie outside of the effective
address space from 0 to 0FFFFH.
#NM If CR0.EM[bit 2] = 1.
If CR0.TS[bit 3] = 1.
#UD If CPUID.01H:ECX.SSE3[bit 0] = 0.
If the LOCK prefix is used.
Virtual 8086 Mode Exceptions
GP(0) If any part of the operand would lie outside of the effective
address space from 0 to 0FFFFH.
#NM If CR0.EM[bit 2] = 1.
If CR0.TS[bit 3] = 1.
#UD If CPUID.01H:ECX.SSE3[bit 0] = 0.
If the LOCK prefix is used.
#PF(fault-code) For a page fault.
#AC(0) For unaligned memory reference if the current privilege is 3.
Compatibility Mode Exceptions
Same exceptions as in protected mode.

Vol. 2A 3-389
INSTRUCTION SET REFERENCE, A-M
FISTTP—Store Integer with Truncation
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
If the LOCK prefix is used.

3-390 Vol. 2A FLD—Load Floating Point Value
INSTRUCTION SET REFERENCE, A-M
FLD—Load Floating Point Value
Description
Pushes the source operand onto the FPU register stack. The source operand can be in
single-precision, double-precision, or double extended-precision floating-point
format. If the source operand is in single-precision or double-precision floating-point
format, it is automatically converted to the double extended-precision floating-point
format before being pushed on the stack.
The FLD instruction can also push the value in a selected FPU register [ST(i)] onto the
stack. Here, pushing register ST(0) duplicates the stack top.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
IF SRC is ST(i)
THEN
temp ← ST(i);
FI;
TOP ← TOP − 1;
IF SRC is memory-operand
THEN
ST(0) ← ConvertToDoubleExtendedPrecisionFP(SRC);
ELSE (* SRC is ST(i) *)
ST(0) ← temp;
FI;
FPU Flags Affected
C1 Set to 1 if stack overflow occurred; otherwise, set to 0.
C0, C2, C3 Undefined.
Floating-Point Exceptions
#IS Stack underflow or overflow occurred.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D9 /0 FLD m32fp Valid Valid Push m32fp onto the FPU register stack.
DD /0 FLD m64fp Valid Valid Push m64fp onto the FPU register stack.
DB /5 FLD m80fp Valid Valid Push m80fp onto the FPU register stack.
D9 C0+i FLD ST(i) Valid Valid Push ST(i) onto the FPU register stack.

Vol. 2A 3-391
INSTRUCTION SET REFERENCE, A-M
FLD—Load Floating Point Value
#IA Source operand is an SNaN. Does not occur if the source
operand is in double extended-precision floating-point format
(FLD m80fp or FLD ST(i)).
#D Source operand is a denormal value. Does not occur if the
source operand is in double extended-precision floating-point
format.
Protected Mode Exceptions
#GP(0) If destination is located in a non-writable segment.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register is used to access memory and it
contains a NULL segment selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.

3-392 Vol. 2A FLD—Load Floating Point Value
INSTRUCTION SET REFERENCE, A-M
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.

Vol. 2A 3-393
INSTRUCTION SET REFERENCE, A-M
FLD1/FLDL2T/FLDL2E/FLDPI/FLDLG2/FLDLN2/FLDZ—Load Constant
FLD1/FLDL2T/FLDL2E/FLDPI/FLDLG2/FLDLN2/FLDZ—Load Constant
Description
Push one of seven commonly used constants (in double extended-precision floating-
point format) onto the FPU register stack. The constants that can be loaded with
these instructions include +1.0, +0.0, log210, log2e, π, log102, and loge2. For each
constant, an internal 66-bit constant is rounded (as specified by the RC field in the
FPU control word) to double extended-precision floating-point format. The inexact-
result exception (#P) is not generated as a result of the rounding, nor is the C1 flag
set in the x87 FPU status word if the value is rounded up.
See the section titled “Pi” in Chapter 8 of the Intel® 64 and IA-32 Architectures Soft-
ware Developer’s Manual, Volume 1, for a description of the π constant.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
IA-32 Architecture Compatibility
When the RC field is set to round-to-nearest, the FPU produces the same constants
that is produced by the Intel 8087 and Intel 287 math coprocessors.
Operation
TOP ← TOP − 1;
ST(0) ← CONSTANT;
FPU Flags Affected
C1 Set to 1 if stack overflow occurred; otherwise, set to 0.
C0, C2, C3 Undefined.
Opcode* Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D9 E8 FLD1 Valid Valid Push +1.0 onto the FPU register stack.
D9 E9 FLDL2T Valid Valid Push log210 onto the FPU register stack.
D9 EA FLDL2E Valid Valid Push log2e onto the FPU register stack.
D9 EB FLDPI Valid Valid Push π onto the FPU register stack.
D9 EC FLDLG2 Valid Valid Push log102 onto the FPU register stack.
D9 ED FLDLN2 Valid Valid Push loge2 onto the FPU register stack.
D9 EE FLDZ Valid Valid Push +0.0 onto the FPU register stack.
NOTES:
* See IA-32 Architecture Compatibility section below.

3-394 Vol. 2A FLD1/FLDL2T/FLDL2E/FLDPI/FLDLG2/FLDLN2/FLDZ—Load Constant
INSTRUCTION SET REFERENCE, A-M
Floating-Point Exceptions
#IS Stack overflow occurred.
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.

Vol. 2A 3-395
INSTRUCTION SET REFERENCE, A-M
FLDCW—Load x87 FPU Control Word
FLDCW—Load x87 FPU Control Word
Description
Loads the 16-bit source operand into the FPU control word. The source operand is a
memory location. This instruction is typically used to establish or change the FPU’s
mode of operation.
If one or more exception flags are set in the FPU status word prior to loading a new
FPU control word and the new control word unmasks one or more of those excep-
tions, a floating-point exception will be generated upon execution of the next
floating-point instruction (except for the no-wait floating-point instructions, see the
section titled “Software Exception Handling” in Chapter 8 of the Intel® 64 and IA-32
Architectures Software Developer’s Manual, Volume 1). To avoid raising exceptions
when changing FPU operating modes, clear any pending exceptions (using the FCLEX
or FNCLEX instruction) before loading the new control word.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
FPUControlWord ← SRC;
FPU Flags Affected
C0, C1, C2, C3 undefined.
Floating-Point Exceptions
None; however, this operation might unmask a pending exception in the FPU status
word. That exception is then generated upon execution of the next “waiting” floating-
point instruction.
Protected Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register is used to access memory and it
contains a NULL segment selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D9 /5 FLDCW m2byte Valid Valid Load FPU control word from m2byte.

3-396 Vol. 2A FLDCW—Load x87 FPU Control Word
INSTRUCTION SET REFERENCE, A-M
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.

Vol. 2A 3-397
INSTRUCTION SET REFERENCE, A-M
FLDENV—Load x87 FPU Environment
FLDENV—Load x87 FPU Environment
Description
Loads the complete x87 FPU operating environment from memory into the FPU regis-
ters. The source operand specifies the first byte of the operating-environment data in
memory. This data is typically written to the specified memory location by a FSTENV
or FNSTENV instruction.
The FPU operating environment consists of the FPU control word, status word, tag
word, instruction pointer, data pointer, and last opcode. Figures 8-9 through 8-12 in
the Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 1, show
the layout in memory of the loaded environment, depending on the operating mode
of the processor (protected or real) and the current operand-size attribute (16-bit or
32-bit). In virtual-8086 mode, the real mode layouts are used.
The FLDENV instruction should be executed in the same operating mode as the corre-
sponding FSTENV/FNSTENV instruction.
If one or more unmasked exception flags are set in the new FPU status word, a
floating-point exception will be generated upon execution of the next floating-point
instruction (except for the no-wait floating-point instructions, see the section titled
“Software Exception Handling” in Chapter 8 of the Intel® 64 and IA-32 Architectures
Software Developer’s Manual, Volume 1). To avoid generating exceptions when
loading a new environment, clear all the exception flags in the FPU status word that
is being loaded.
If a page or limit fault occurs during the execution of this instruction, the state of the
x87 FPU registers as seen by the fault handler may be different than the state being
loaded from memory. In such situations, the fault handler should ignore the status of
the x87 FPU registers, handle the fault, and return. The FLDENV instruction will then
complete the loading of the x87 FPU registers with no resulting context inconsis-
tency.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
FPUControlWord ← SRC[FPUControlWord];
FPUStatusWord ← SRC[FPUStatusWord];
FPUTagWord ← SRC[FPUTagWord];
FPUDataPointer ← SRC[FPUDataPointer];
FPUInstructionPointer ← SRC[FPUInstructionPointer];
FPULastInstructionOpcode ← SRC[FPULastInstructionOpcode];
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D9 /4 FLDENV m14/28byte Valid Valid Load FPU environment from
m14byte or m28byte.

3-398 Vol. 2A FLDENV—Load x87 FPU Environment
INSTRUCTION SET REFERENCE, A-M
FPU Flags Affected
The C0, C1, C2, C3 flags are loaded.
Floating-Point Exceptions
None; however, if an unmasked exception is loaded in the status word, it is generated
upon execution of the next “waiting” floating-point instruction.
Protected Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register is used to access memory and it
contains a NULL segment selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.

Vol. 2A 3-399
INSTRUCTION SET REFERENCE, A-M
FLDENV—Load x87 FPU Environment
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.

3-400 Vol. 2A FMUL/FMULP/FIMUL—Multiply
INSTRUCTION SET REFERENCE, A-M
FMUL/FMULP/FIMUL—Multiply
Description
Multiplies the destination and source operands and stores the product in the destina-
tion location. The destination operand is always an FPU data register; the source
operand can be an FPU data register or a memory location. Source operands in
memory can be in single-precision or double-precision floating-point format or in
word or doubleword integer format.
The no-operand version of the instruction multiplies the contents of the ST(1)
register by the contents of the ST(0) register and stores the product in the ST(1)
register. The one-operand version multiplies the contents of the ST(0) register by the
contents of a memory location (either a floating point or an integer value) and stores
the product in the ST(0) register. The two-operand version, multiplies the contents of
the ST(0) register by the contents of the ST(i) register, or vice versa, with the result
being stored in the register specified with the first operand (the destination
operand).
The FMULP instructions perform the additional operation of popping the FPU register
stack after storing the product. To pop the register stack, the processor marks the
ST(0) register as empty and increments the stack pointer (TOP) by 1. The no-
operand version of the floating-point multiply instructions always results in the
register stack being popped. In some assemblers, the mnemonic for this instruction
is FMUL rather than FMULP.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D8 /1 FMUL m32fp Valid Valid Multiply ST(0) by m32fp and store
result in ST(0).
DC /1 FMUL m64fp Valid Valid Multiply ST(0) by m64fp and store
result in ST(0).
D8 C8+i FMUL ST(0), ST(i) Valid Valid Multiply ST(0) by ST(i) and store result
in ST(0).
DC C8+i FMUL ST(i), ST(0) Valid Valid Multiply ST(i) by ST(0) and store result
in ST(i).
DE C8+i FMULP ST(i), ST(0) Valid Valid Multiply ST(i) by ST(0), store result in
ST(i), and pop the register stack.
DE C9 FMULP Valid Valid Multiply ST(1) by ST(0), store result in
ST(1), and pop the register stack.
DA /1 FIMUL m32int Valid Valid Multiply ST(0) by m32int and store
result in ST(0).
DE /1 FIMUL m16int Valid Valid Multiply ST(0) by m16int and store
result in ST(0).

Vol. 2A 3-401
INSTRUCTION SET REFERENCE, A-M
FMUL/FMULP/FIMUL—Multiply
The FIMUL instructions convert an integer source operand to double extended-
precision floating-point format before performing the multiplication.
The sign of the result is always the exclusive-OR of the source signs, even if one or
more of the values being multiplied is 0 or ∞. When the source operand is an integer
0, it is treated as a +0.
The following table shows the results obtained when multiplying various classes of
numbers, assuming that neither overflow nor underflow occurs.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
IF Instruction = FIMUL
THEN
DEST ← DEST ∗ ConvertToDoubleExtendedPrecisionFP(SRC);
ELSE (* Source operand is floating-point value *)
DEST ← DEST ∗ SRC;
FI;
IF Instruction = FMULP
THEN
PopRegisterStack;
FI;
Table 3-39. FMUL/FMULP/FIMUL Results
DEST
−•−F−0+0+F+•NaN
−•+•+•**−•−•NaN
−F+•+F+0−0− F−•NaN
−I+•+F+0−0−F−•NaN
SRC −0*+0+0−0−0*NaN
+0*−0−0+0+0*NaN
+I−•−F−0+0+F+•NaN
+F−•−F−0+0+F+•NaN
+•−•−•**+•+•NaN
NaN NaN NaN NaN NaN NaN NaN NaN
NOTES:
F Means finite floating-point value.
IMeans Integer.
* Indicates invalid-arithmetic-operand (#IA) exception.

3-402 Vol. 2A FMUL/FMULP/FIMUL—Multiply
INSTRUCTION SET REFERENCE, A-M
FPU Flags Affected
C1 Set to 0 if stack underflow occurred.
Set if result was rounded up; cleared otherwise.
C0, C2, C3 Undefined.
Floating-Point Exceptions
#IS Stack underflow occurred.
#IA Operand is an SNaN value or unsupported format.
One operand is ±0 and the other is ±∞.
#D Source operand is a denormal value.
#U Result is too small for destination format.
#O Result is too large for destination format.
#P Value cannot be represented exactly in destination format.
Protected Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register is used to access memory and it
contains a NULL segment selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.

Vol. 2A 3-403
INSTRUCTION SET REFERENCE, A-M
FMUL/FMULP/FIMUL—Multiply
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.

3-404 Vol. 2A FNOP—No Operation
INSTRUCTION SET REFERENCE, A-M
FNOP—No Operation
Description
Performs no FPU operation. This instruction takes up space in the instruction stream
but does not affect the FPU or machine context, except the EIP register.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
FPU Flags Affected
C0, C1, C2, C3 undefined.
Floating-Point Exceptions
None.
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D9 D0 FNOP Valid Valid No operation is performed.

Vol. 2A 3-405
INSTRUCTION SET REFERENCE, A-M
FPATAN—Partial Arctangent
FPATAN—Partial Arctangent
Description
Computes the arctangent of the source operand in register ST(1) divided by the
source operand in register ST(0), stores the result in ST(1), and pops the FPU
register stack. The result in register ST(0) has the same sign as the source operand
ST(1) and a magnitude less than +π.
The FPATAN instruction returns the angle between the X axis and the line from the
origin to the point (X,Y), where Y (the ordinate) is ST(1) and X (the abscissa) is
ST(0). The angle depends on the sign of X and Y independently, not just on the sign
of the ratio Y/X. This is because a point (−X,Y) is in the second quadrant, resulting in
an angle between π/2 and π, while a point (X,−Y) is in the fourth quadrant, resulting
in an angle between 0 and −π/2. A point (−X,−Y) is in the third quadrant, giving an
angle between −π/2 and −π.
The following table shows the results obtained when computing the arctangent of
various classes of numbers, assuming that underflow does not occur.
Opcode* Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D9 F3 FPATAN Valid Valid Replace ST(1) with arctan(ST(1)/ST(0)) and pop
the register stack.
NOTES:
* See IA-32 Architecture Compatibility section below.
3-406 Vol. 2A FPATAN—Partial Arctangent
INSTRUCTION SET REFERENCE, A-M
There is no restriction on the range of source operands that FPATAN can accept.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
IA-32 Architecture Compatibility
The source operands for this instruction are restricted for the 80287 math copro-
cessor to the following range:
0 ≤ |ST(1)| < |ST(0)| < +∞
Operation
ST(1) ← arctan(ST(1) / ST(0));
PopRegisterStack;
Table 3-40. FPATAN Results
ST(0)
-•− F− 0+ 0+ F+ •NaN
-•− 3π/4*− π/2 − π/2 − π/2 − π/2 − π/4*NaN
ST(1) −F-p −π to −π/2−π/2 −π/2 −π/2 to −
0
- 0 NaN
−0-p -p -p
*− 0*− 0− 0NaN
+0+p+ p + π*+ 0*+ 0+ 0NaN
+F+p+π to +π/2+ π/2+π/2+π/2 to
+0
+ 0NaN
+•+3π/4*+π/2+π/2+π/2+ π/2+ π/4*NaN
NaN NaN NaN NaN NaN NaN NaN NaN
NOTES:
F Means finite floating-point value.
* Table 8-10 in the Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 1,
specifies that the ratios 0/0 and •/• generate the floating-point invalid arithmetic-operation
exception and, if this exception is masked, the floating-point QNaN indefinite value is returned.
With the FPATAN instruction, the 0/0 or •/• value is actually not calculated using division.
Instead, the arctangent of the two variables is derived from a standard mathematical formula-
tion that is generalized to allow complex numbers as arguments. In this complex variable formu-
lation, arctangent(0,0) etc. has well defined values. These values are needed to develop a library
to compute transcendental functions with complex arguments, based on the FPU functions that
only allow floating-point values as arguments.

Vol. 2A 3-407
INSTRUCTION SET REFERENCE, A-M
FPATAN—Partial Arctangent
FPU Flags Affected
C1 Set to 0 if stack underflow occurred.
Set if result was rounded up; cleared otherwise.
C0, C2, C3 Undefined.
Floating-Point Exceptions
#IS Stack underflow occurred.
#IA Source operand is an SNaN value or unsupported format.
#D Source operand is a denormal value.
#U Result is too small for destination format.
#P Value cannot be represented exactly in destination format.
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.
3-408 Vol. 2A FPREM—Partial Remainder
INSTRUCTION SET REFERENCE, A-M
FPREM—Partial Remainder
Description
Computes the remainder obtained from dividing the value in the ST(0) register (the
dividend) by the value in the ST(1) register (the divisor or modulus), and stores the
result in ST(0). The remainder represents the following value:
Remainder ← ST(0) − (Q ∗ ST(1))
Here, Q is an integer value that is obtained by truncating the floating-point number
quotient of [ST(0) / ST(1)] toward zero. The sign of the remainder is the same as the
sign of the dividend. The magnitude of the remainder is less than that of the
modulus, unless a partial remainder was computed (as described below).
This instruction produces an exact result; the inexact-result exception does not occur
and the rounding control has no effect. The following table shows the results
obtained when computing the remainder of various classes of numbers, assuming
that underflow does not occur.
When the result is 0, its sign is the same as that of the dividend. When the modulus
is ∞, the result is equal to the value in ST(0).
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D9 F8 FPREM Valid Valid Replace ST(0) with the remainder obtained
from dividing ST(0) by ST(1).
Table 3-41. FPREM Results
ST(1)
-•-F -0 +0 +F +•NaN
-•******NaN
ST(0) -F ST(0) -F or -0 ** ** -F or -0 ST(0) NaN
-0 -0 -0 * * -0 -0 NaN
+0 +0 +0 * * +0 +0 NaN
+F ST(0) +F or +0 ** ** +F or +0 ST(0) NaN
+•******NaN
NaN NaN NaN NaN NaN NaN NaN NaN
NOTES:
F Means finite floating-point value.
* Indicates floating-point invalid-arithmetic-operand (#IA) exception.
** Indicates floating-point zero-divide (#Z) exception.

Vol. 2A 3-409
INSTRUCTION SET REFERENCE, A-M
FPREM—Partial Remainder
The FPREM instruction does not compute the remainder specified in IEEE Std 754.
The IEEE specified remainder can be computed with the FPREM1 instruction. The
FPREM instruction is provided for compatibility with the Intel 8087 and Intel287 math
coprocessors.
The FPREM instruction gets its name “partial remainder” because of the way it
computes the remainder. This instruction arrives at a remainder through iterative
subtraction. It can, however, reduce the exponent of ST(0) by no more than 63 in one
execution of the instruction. If the instruction succeeds in producing a remainder that
is less than the modulus, the operation is complete and the C2 flag in the FPU status
word is cleared. Otherwise, C2 is set, and the result in ST(0) is called the partial
remainder. The exponent of the partial remainder will be less than the exponent of
the original dividend by at least 32. Software can re-execute the instruction (using
the partial remainder in ST(0) as the dividend) until C2 is cleared. (Note that while
executing such a remainder-computation loop, a higher-priority interrupting routine
that needs the FPU can force a context switch in-between the instructions in the
loop.)
An important use of the FPREM instruction is to reduce the arguments of periodic
functions. When reduction is complete, the instruction stores the three least-signifi-
cant bits of the quotient in the C3, C1, and C0 flags of the FPU status word. This infor-
mation is important in argument reduction for the tangent function (using a modulus
of π/4), because it locates the original angle in the correct one of eight sectors of the
unit circle.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
D ← exponent(ST(0)) – exponent(ST(1));
IF D < 64
THEN
Q ← Integer(TruncateTowardZero(ST(0) / ST(1)));
ST(0) ← ST(0) – (ST(1) ∗ Q);
C2 ← 0;
C0, C3, C1 ← LeastSignificantBits(Q); (* Q2, Q1, Q0 *)
ELSE
C2 ← 1;
N ← An implementation-dependent number between 32 and 63;
QQ ← Integer(TruncateTowardZero((ST(0) / ST(1)) / 2(D − N)));
ST(0) ← ST(0) – (ST(1) ∗ QQ ∗ 2(D − N));
FI;

3-410 Vol. 2A FPREM—Partial Remainder
INSTRUCTION SET REFERENCE, A-M
FPU Flags Affected
C0 Set to bit 2 (Q2) of the quotient.
C1 Set to 0 if stack underflow occurred; otherwise, set to least
significant bit of quotient (Q0).
C2 Set to 0 if reduction complete; set to 1 if incomplete.
C3 Set to bit 1 (Q1) of the quotient.
Floating-Point Exceptions
#IS Stack underflow occurred.
#IA Source operand is an SNaN value, modulus is 0, dividend is ∞, or
unsupported format.
#D Source operand is a denormal value.
#U Result is too small for destination format.
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.
Vol. 2A 3-411
INSTRUCTION SET REFERENCE, A-M
FPREM1—Partial Remainder
FPREM1—Partial Remainder
Description
Computes the IEEE remainder obtained from dividing the value in the ST(0) register
(the dividend) by the value in the ST(1) register (the divisor or modulus), and stores
the result in ST(0). The remainder represents the following value:
Remainder ← ST(0) − (Q ∗ ST(1))
Here, Q is an integer value that is obtained by rounding the floating-point number
quotient of [ST(0) / ST(1)] toward the nearest integer value. The magnitude of the
remainder is less than or equal to half the magnitude of the modulus, unless a partial
remainder was computed (as described below).
This instruction produces an exact result; the precision (inexact) exception does not
occur and the rounding control has no effect. The following table shows the results
obtained when computing the remainder of various classes of numbers, assuming
that underflow does not occur.
When the result is 0, its sign is the same as that of the dividend. When the modulus
is ∞, the result is equal to the value in ST(0).
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D9 F5 FPREM1 Valid Valid Replace ST(0) with the IEEE remainder
obtained from dividing ST(0) by ST(1).
Table 3-42. FPREM1 Results
ST(1)
- •− F− 0+ 0+ F+•NaN
- •******NaN
ST(0) − FST(0)±F or −0** ** ± F or −
0
ST(0) NaN
− 0− 0− 0* *− 0-0NaN
+ 0+ 0+ 0* *+ 0+0NaN
+ FST(0)± F or + 0** ** ± F or +
0
ST(0) NaN
+•******NaN
NaN NaN NaN NaN NaN NaN NaN NaN
NOTES:
F Means finite floating-point value.
* Indicates floating-point invalid-arithmetic-operand (#IA) exception.
** Indicates floating-point zero-divide (#Z) exception.

3-412 Vol. 2A FPREM1—Partial Remainder
INSTRUCTION SET REFERENCE, A-M
The FPREM1 instruction computes the remainder specified in IEEE Standard 754.
This instruction operates differently from the FPREM instruction in the way that it
rounds the quotient of ST(0) divided by ST(1) to an integer (see the “Operation”
section below).
Like the FPREM instruction, FPREM1 computes the remainder through iterative
subtraction, but can reduce the exponent of ST(0) by no more than 63 in one execu-
tion of the instruction. If the instruction succeeds in producing a remainder that is
less than one half the modulus, the operation is complete and the C2 flag in the FPU
status word is cleared. Otherwise, C2 is set, and the result in ST(0) is called the
partial remainder. The exponent of the partial remainder will be less than the expo-
nent of the original dividend by at least 32. Software can re-execute the instruction
(using the partial remainder in ST(0) as the dividend) until C2 is cleared. (Note that
while executing such a remainder-computation loop, a higher-priority interrupting
routine that needs the FPU can force a context switch in-between the instructions in
the loop.)
An important use of the FPREM1 instruction is to reduce the arguments of periodic
functions. When reduction is complete, the instruction stores the three least-signifi-
cant bits of the quotient in the C3, C1, and C0 flags of the FPU status word. This infor-
mation is important in argument reduction for the tangent function (using a modulus
of π/4), because it locates the original angle in the correct one of eight sectors of the
unit circle.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
D ← exponent(ST(0)) – exponent(ST(1));
IF D < 64
THEN
Q ← Integer(RoundTowardNearestInteger(ST(0) / ST(1)));
ST(0) ← ST(0) – (ST(1) ∗ Q);
C2 ← 0;
C0, C3, C1 ← LeastSignificantBits(Q); (* Q2, Q1, Q0 *)
ELSE
C2 ← 1;
N ← An implementation-dependent number between 32 and 63;
QQ ← Integer(TruncateTowardZero((ST(0) / ST(1)) / 2(D − N)));
ST(0) ← ST(0) – (ST(1) ∗ QQ ∗ 2(D − N));
FI;
FPU Flags Affected
C0 Set to bit 2 (Q2) of the quotient.
C1 Set to 0 if stack underflow occurred; otherwise, set to least
significant bit of quotient (Q0).

Vol. 2A 3-413
INSTRUCTION SET REFERENCE, A-M
FPREM1—Partial Remainder
C2 Set to 0 if reduction complete; set to 1 if incomplete.
C3 Set to bit 1 (Q1) of the quotient.
Floating-Point Exceptions
#IS Stack underflow occurred.
#IA Source operand is an SNaN value, modulus (divisor) is 0, divi-
dend is ∞, or unsupported format.
#D Source operand is a denormal value.
#U Result is too small for destination format.
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.
3-414 Vol. 2A FPTAN—Partial Tangent
INSTRUCTION SET REFERENCE, A-M
FPTAN—Partial Tangent
Description
Computes the tangent of the source operand in register ST(0), stores the result in
ST(0), and pushes a 1.0 onto the FPU register stack. The source operand must be
given in radians and must be less than ±263. The following table shows the
unmasked results obtained when computing the partial tangent of various classes of
numbers, assuming that underflow does not occur.
If the source operand is outside the acceptable range, the C2 flag in the FPU status
word is set, and the value in register ST(0) remains unchanged. The instruction does
not raise an exception when the source operand is out of range. It is up to the
program to check the C2 flag for out-of-range conditions. Source values outside the
range −263 to +263 can be reduced to the range of the instruction by subtracting an
appropriate integer multiple of 2π or by using the FPREM instruction with a divisor of
2π. See the section titled “Pi” in Chapter 8 of the Intel® 64 and IA-32 Architectures
Software Developer’s Manual, Volume 1, for a discussion of the proper value to use
for π in performing such reductions.
The value 1.0 is pushed onto the register stack after the tangent has been computed
to maintain compatibility with the Intel 8087 and Intel287 math coprocessors. This
operation also simplifies the calculation of other trigonometric functions. For
instance, the cotangent (which is the reciprocal of the tangent) can be computed by
executing a FDIVR instruction after the FPTAN instruction.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D9 F2 FPTAN Valid Valid Replace ST(0) with its tangent and
push 1 onto the FPU stack.
Table 3-43. FPTAN Results
ST(0) SRC ST(0) DEST
-•*
- F − F to + F
− 0- 0
+ 0+ 0
+ F− F to + F
+•*
NaN NaN
NOTES:
F Means finite floating-point value.
* Indicates floating-point invalid-arithmetic-operand (#IA) exception.

Vol. 2A 3-415
INSTRUCTION SET REFERENCE, A-M
FPTAN—Partial Tangent
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
IF ST(0) < 263
THEN
C2 ← 0;
ST(0) ← tan(ST(0));
TOP ← TOP − 1;
ST(0) ← 1.0;
ELSE (* Source operand is out-of-range *)
C2 ← 1;
FI;
FPU Flags Affected
C1 Set to 0 if stack underflow occurred; set to 1 if stack overflow
occurred.
Set if result was rounded up; cleared otherwise.
C2 Set to 1 if outside range (−263 < source operand < +263); other-
wise, set to 0.
C0, C3 Undefined.
Floating-Point Exceptions
#IS Stack underflow or overflow occurred.
#IA Source operand is an SNaN value, ∞, or unsupported format.
#D Source operand is a denormal value.
#U Result is too small for destination format.
#P Value cannot be represented exactly in destination format.
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.

3-416 Vol. 2A FPTAN—Partial Tangent
INSTRUCTION SET REFERENCE, A-M
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.

Vol. 2A 3-417
INSTRUCTION SET REFERENCE, A-M
FRNDINT—Round to Integer
FRNDINT—Round to Integer
Description
Rounds the source value in the ST(0) register to the nearest integral value,
depending on the current rounding mode (setting of the RC field of the FPU control
word), and stores the result in ST(0).
If the source value is ∞, the value is not changed. If the source value is not an integral
value, the floating-point inexact-result exception (#P) is generated.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
ST(0) ← RoundToIntegralValue(ST(0));
FPU Flags Affected
C1 Set to 0 if stack underflow occurred.
Set if result was rounded up; cleared otherwise.
C0, C2, C3 Undefined.
Floating-Point Exceptions
#IS Stack underflow occurred.
#IA Source operand is an SNaN value or unsupported format.
#D Source operand is a denormal value.
#P Source operand is not an integral value.
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D9 FC FRNDINT Valid Valid Round ST(0) to an integer.

3-418 Vol. 2A FRNDINT—Round to Integer
INSTRUCTION SET REFERENCE, A-M
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.

Vol. 2A 3-419
INSTRUCTION SET REFERENCE, A-M
FRSTOR—Restore x87 FPU State
FRSTOR—Restore x87 FPU State
Description
Loads the FPU state (operating environment and register stack) from the memory
area specified with the source operand. This state data is typically written to the
specified memory location by a previous FSAVE/FNSAVE instruction.
The FPU operating environment consists of the FPU control word, status word, tag
word, instruction pointer, data pointer, and last opcode. Figures 8-9 through 8-12 in
the Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 1, show
the layout in memory of the stored environment, depending on the operating mode
of the processor (protected or real) and the current operand-size attribute (16-bit or
32-bit). In virtual-8086 mode, the real mode layouts are used. The contents of the
FPU register stack are stored in the 80 bytes immediately following the operating
environment image.
The FRSTOR instruction should be executed in the same operating mode as the
corresponding FSAVE/FNSAVE instruction.
If one or more unmasked exception bits are set in the new FPU status word, a
floating-point exception will be generated. To avoid raising exceptions when loading
a new operating environment, clear all the exception flags in the FPU status word
that is being loaded.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
FPUControlWord ← SRC[FPUControlWord];
FPUStatusWord ← SRC[FPUStatusWord];
FPUTagWord ← SRC[FPUTagWord];
FPUDataPointer ← SRC[FPUDataPointer];
FPUInstructionPointer ← SRC[FPUInstructionPointer];
FPULastInstructionOpcode ← SRC[FPULastInstructionOpcode];
ST(0) ← SRC[ST(0)];
ST(1) ← SRC[ST(1)];
ST(2) ← SRC[ST(2)];
ST(3) ← SRC[ST(3)];
ST(4) ← SRC[ST(4)];
ST(5) ← SRC[ST(5)];
ST(6) ← SRC[ST(6)];
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
DD /4 FRSTOR m94/108byte Valid Valid Load FPU state from
m94byte or m108byte.

3-420 Vol. 2A FRSTOR—Restore x87 FPU State
INSTRUCTION SET REFERENCE, A-M
ST(7) ← SRC[ST(7)];
FPU Flags Affected
The C0, C1, C2, C3 flags are loaded.
Floating-Point Exceptions
None; however, this operation might unmask an existing exception that has been
detected but not generated, because it was masked. Here, the exception is gener-
ated at the completion of the instruction.
Protected Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register is used to access memory and it
contains a NULL segment selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.

Vol. 2A 3-421
INSTRUCTION SET REFERENCE, A-M
FRSTOR—Restore x87 FPU State
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.

3-422 Vol. 2A FSAVE/FNSAVE—Store x87 FPU State
INSTRUCTION SET REFERENCE, A-M
FSAVE/FNSAVE—Store x87 FPU State
Description
Stores the current FPU state (operating environment and register stack) at the spec-
ified destination in memory, and then re-initializes the FPU. The FSAVE instruction
checks for and handles pending unmasked floating-point exceptions before storing
the FPU state; the FNSAVE instruction does not.
The FPU operating environment consists of the FPU control word, status word, tag
word, instruction pointer, data pointer, and last opcode. Figures 8-9 through 8-12 in
the Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 1, show
the layout in memory of the stored environment, depending on the operating mode
of the processor (protected or real) and the current operand-size attribute (16-bit or
32-bit). In virtual-8086 mode, the real mode layouts are used. The contents of the
FPU register stack are stored in the 80 bytes immediately follow the operating envi-
ronment image.
The saved image reflects the state of the FPU after all floating-point instructions
preceding the FSAVE/FNSAVE instruction in the instruction stream have been
executed.
After the FPU state has been saved, the FPU is reset to the same default values it is
set to with the FINIT/FNINIT instructions (see “FINIT/FNINIT—Initialize Floating-
Point Unit” in this chapter).
The FSAVE/FNSAVE instructions are typically used when the operating system needs
to perform a context switch, an exception handler needs to use the FPU, or an appli-
cation program needs to pass a “clean” FPU to a procedure.
The assembler issues two instructions for the FSAVE instruction (an FWAIT instruc-
tion followed by an FNSAVE instruction), and the processor executes each of these
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
9B DD /6 FSAVE m94/108byte Valid Valid Store FPU state to m94byte or
m108byte after checking for
pending unmasked floating-
point exceptions. Then re-
initialize the FPU.
DD /6 FNSAVE* m94/108byte Valid Valid Store FPU environment to
m94byte or m108byte without
checking for pending unmasked
floating-point exceptions. Then
re-initialize the FPU.
NOTES:
* See IA-32 Architecture Compatibility section below.

Vol. 2A 3-423
INSTRUCTION SET REFERENCE, A-M
FSAVE/FNSAVE—Store x87 FPU State
instructions separately. If an exception is generated for either of these instructions,
the save EIP points to the instruction that caused the exception.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
IA-32 Architecture Compatibility
For Intel math coprocessors and FPUs prior to the Intel Pentium processor, an FWAIT
instruction should be executed before attempting to read from the memory image
stored with a prior FSAVE/FNSAVE instruction. This FWAIT instruction helps ensure
that the storage operation has been completed.
When operating a Pentium or Intel486 processor in MS-DOS compatibility mode, it is
possible (under unusual circumstances) for an FNSAVE instruction to be interrupted
prior to being executed to handle a pending FPU exception. See the section titled
“No-Wait FPU Instructions Can Get FPU Interrupt in Window” in Appendix D of the
Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 1, for a
description of these circumstances. An FNSAVE instruction cannot be interrupted in
this way on a Pentium 4, Intel Xeon, or P6 family processor.
Operation
(* Save FPU State and Registers *)
DEST[FPUControlWord] ← FPUControlWord;
DEST[FPUStatusWord] ← FPUStatusWord;
DEST[FPUTagWord] ← FPUTagWord;
DEST[FPUDataPointer] ← FPUDataPointer;
DEST[FPUInstructionPointer] ← FPUInstructionPointer;
DEST[FPULastInstructionOpcode] ← FPULastInstructionOpcode;
DEST[ST(0)] ← ST(0);
DEST[ST(1)] ← ST(1);
DEST[ST(2)] ← ST(2);
DEST[ST(3)] ← ST(3);
DEST[ST(4)]← ST(4);
DEST[ST(5)] ← ST(5);
DEST[ST(6)] ← ST(6);
DEST[ST(7)] ← ST(7);
(* Initialize FPU *)
FPUControlWord ← 037FH;
FPUStatusWord ← 0;
FPUTagWord ← FFFFH;
FPUDataPointer ← 0;
FPUInstructionPointer ← 0;
FPULastInstructionOpcode ← 0;

3-424 Vol. 2A FSAVE/FNSAVE—Store x87 FPU State
INSTRUCTION SET REFERENCE, A-M
FPU Flags Affected
The C0, C1, C2, and C3 flags are saved and then cleared.
Floating-Point Exceptions
None.
Protected Mode Exceptions
#GP(0) If destination is located in a non-writable segment.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register is used to access memory and it
contains a NULL segment selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.

Vol. 2A 3-425
INSTRUCTION SET REFERENCE, A-M
FSAVE/FNSAVE—Store x87 FPU State
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
3-426 Vol. 2A FSCALE—Scale
INSTRUCTION SET REFERENCE, A-M
FSCALE—Scale
Description
Truncates the value in the source operand (toward 0) to an integral value and adds
that value to the exponent of the destination operand. The destination and source
operands are floating-point values located in registers ST(0) and ST(1), respectively.
This instruction provides rapid multiplication or division by integral powers of 2. The
following table shows the results obtained when scaling various classes of numbers,
assuming that neither overflow nor underflow occurs.
In most cases, only the exponent is changed and the mantissa (significand) remains
unchanged. However, when the value being scaled in ST(0) is a denormal value, the
mantissa is also changed and the result may turn out to be a normalized number.
Similarly, if overflow or underflow results from a scale operation, the resulting
mantissa will differ from the source’s mantissa.
The FSCALE instruction can also be used to reverse the action of the FXTRACT
instruction, as shown in the following example:
FXTRACT;
FSCALE;
FSTP ST(1);
In this example, the FXTRACT instruction extracts the significand and exponent from
the value in ST(0) and stores them in ST(0) and ST(1) respectively. The FSCALE then
scales the significand in ST(0) by the exponent in ST(1), recreating the original value
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D9 FD FSCALE Valid Valid Scale ST(0) by ST(1).
Table 3-44. FSCALE Results
ST(1)
-•− F− 0+ 0+ F+•NaN
- •NaN -•-•-•-•-•NaN
ST(0) − F− 0− F− F− F− F-•NaN
− 0-0-0-0 -0 -0NaN NaN
+ 0+ 0+ 0+ 0 + 0+ 0NaN NaN
+ F+ 0 + F+ F+ F + F+•NaN
+•NaN +•+•+•+•+•NaN
NaN NaN NaN NaN NaN NaN NaN NaN
NOTES:
FMeans finite floating-point value.

Vol. 2A 3-427
INSTRUCTION SET REFERENCE, A-M
FSCALE—Scale
before the FXTRACT operation was performed. The FSTP ST(1) instruction overwrites
the exponent (extracted by the FXTRACT instruction) with the recreated value, which
returns the stack to its original state with only one register [ST(0)] occupied.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
ST(0) ← ST(0) ∗ 2RoundTowardZero(ST(1));
FPU Flags Affected
C1 Set to 0 if stack underflow occurred.
Set if result was rounded up; cleared otherwise.
C0, C2, C3 Undefined.
Floating-Point Exceptions
#IS Stack underflow occurred.
#IA Source operand is an SNaN value or unsupported format.
#D Source operand is a denormal value.
#U Result is too small for destination format.
#O Result is too large for destination format.
#P Value cannot be represented exactly in destination format.
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.

3-428 Vol. 2A FSIN—Sine
INSTRUCTION SET REFERENCE, A-M
FSIN—Sine
Description
Computes the sine of the source operand in register ST(0) and stores the result in
ST(0). The source operand must be given in radians and must be within the range −
263 to +263. The following table shows the results obtained when taking the sine of
various classes of numbers, assuming that underflow does not occur.
If the source operand is outside the acceptable range, the C2 flag in the FPU status
word is set, and the value in register ST(0) remains unchanged. The instruction does
not raise an exception when the source operand is out of range. It is up to the
program to check the C2 flag for out-of-range conditions. Source values outside the
range −263 to +263 can be reduced to the range of the instruction by subtracting an
appropriate integer multiple of 2π or by using the FPREM instruction with a divisor of
2π. See the section titled “Pi” in Chapter 8 of the Intel® 64 and IA-32 Architectures
Software Developer’s Manual, Volume 1, for a discussion of the proper value to use
for π in performing such reductions.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
IF ST(0) < 263
THEN
C2 ← 0;
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D9 FE FSIN Valid Valid Replace ST(0) with its sine.
Table 3-45. FSIN Results
SRC (ST(0)) DEST (ST(0))
- • *
− F− 1 to + 1
− 0−0
+ 0+ 0
+ F- 1 to +1
+ • *
NaN NaN
NOTES:
F Means finite floating-point value.
* Indicates floating-point invalid-arithmetic-operand (#IA) exception.

Vol. 2A 3-429
INSTRUCTION SET REFERENCE, A-M
FSIN—Sine
ST(0) ← sin(ST(0));
ELSE (* Source operand out of range *)
C2 ← 1;
FI;
FPU Flags Affected
C1 Set to 0 if stack underflow occurred.
Set if result was rounded up; cleared otherwise.
C2 Set to 1 if outside range (−263 < source operand < +263); other-
wise, set to 0.
C0, C3 Undefined.
Floating-Point Exceptions
#IS Stack underflow occurred.
#IA Source operand is an SNaN value, ∞, or unsupported format.
#D Source operand is a denormal value.
#P Value cannot be represented exactly in destination format.
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.
3-430 Vol. 2A FSINCOS—Sine and Cosine
INSTRUCTION SET REFERENCE, A-M
FSINCOS—Sine and Cosine
Description
Computes both the sine and the cosine of the source operand in register ST(0),
stores the sine in ST(0), and pushes the cosine onto the top of the FPU register stack.
(This instruction is faster than executing the FSIN and FCOS instructions in succes-
sion.)
The source operand must be given in radians and must be within the range −263 to
+263. The following table shows the results obtained when taking the sine and cosine
of various classes of numbers, assuming that underflow does not occur.
If the source operand is outside the acceptable range, the C2 flag in the FPU status
word is set, and the value in register ST(0) remains unchanged. The instruction does
not raise an exception when the source operand is out of range. It is up to the
program to check the C2 flag for out-of-range conditions. Source values outside the
range −263 to +263 can be reduced to the range of the instruction by subtracting an
appropriate integer multiple of 2π or by using the FPREM instruction with a divisor of
2π. See the section titled “Pi” in Chapter 8 of the Intel® 64 and IA-32 Architectures
Software Developer’s Manual, Volume 1, for a discussion of the proper value to use
for π in performing such reductions.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D9 FB FSINCOS Valid Valid Compute the sine and cosine of ST(0);
replace ST(0) with the sine, and push the
cosine onto the register stack.
Table 3-46. FSINCOS Results
SRC DEST
ST(0) ST(1) Cosine ST(0) Sine
-•**
− F− 1 to + 1− 1 to + 1
− 0+ 1− 0
+ 0+ 1+ 0
+ F− 1 to + 1− 1 to + 1
+•**
NaN NaN NaN
NOTES:
F Means finite floating-point value.
* Indicates floating-point invalid-arithmetic-operand (#IA) exception.

Vol. 2A 3-431
INSTRUCTION SET REFERENCE, A-M
FSINCOS—Sine and Cosine
Operation
IF ST(0) < 263
THEN
C2 ← 0;
TEMP ← cosine(ST(0));
ST(0) ← sine(ST(0));
TOP ← TOP − 1;
ST(0) ← TEMP;
ELSE (* Source operand out of range *)
C2 ← 1;
FI;
FPU Flags Affected
C1 Set to 0 if stack underflow occurred; set to 1 of stack overflow
occurs.
Set if result was rounded up; cleared otherwise.
C2 Set to 1 if outside range (−263 < source operand < +263); other-
wise, set to 0.
C0, C3 Undefined.
Floating-Point Exceptions
#IS Stack underflow or overflow occurred.
#IA Source operand is an SNaN value, ∞, or unsupported format.
#D Source operand is a denormal value.
#U Result is too small for destination format.
#P Value cannot be represented exactly in destination format.
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.

3-432 Vol. 2A FSINCOS—Sine and Cosine
INSTRUCTION SET REFERENCE, A-M
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.
Vol. 2A 3-433
INSTRUCTION SET REFERENCE, A-M
FSQRT—Square Root
FSQRT—Square Root
Description
Computes the square root of the source value in the ST(0) register and stores the
result in ST(0).
The following table shows the results obtained when taking the square root of various
classes of numbers, assuming that neither overflow nor underflow occurs.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
ST(0) ← SquareRoot(ST(0));
FPU Flags Affected
C1 Set to 0 if stack underflow occurred.
Set if result was rounded up; cleared otherwise.
C0, C2, C3 Undefined.
Floating-Point Exceptions
#IS Stack underflow occurred.
#IA Source operand is an SNaN value or unsupported format.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D9 FA FSQRT Valid Valid Computes square root of ST(0) and stores
the result in ST(0).
Table 3-47. FSQRT Results
SRC (ST(0)) DEST (ST(0))
-•*
− F*
− 0− 0
+ 0+ 0
+ F+ F
+•+•
NaN NaN
NOTES:
FMeans finite floating-point value.
* Indicates floating-point invalid-arithmetic-operand (#IA) exception.

3-434 Vol. 2A FSQRT—Square Root
INSTRUCTION SET REFERENCE, A-M
Source operand is a negative value (except for −0).
#D Source operand is a denormal value.
#P Value cannot be represented exactly in destination format.
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.

Vol. 2A 3-435
INSTRUCTION SET REFERENCE, A-M
FST/FSTP—Store Floating Point Value
FST/FSTP—Store Floating Point Value
Description
The FST instruction copies the value in the ST(0) register to the destination operand,
which can be a memory location or another register in the FPU register stack. When
storing the value in memory, the value is converted to single-precision or double-
precision floating-point format.
The FSTP instruction performs the same operation as the FST instruction and then
pops the register stack. To pop the register stack, the processor marks the ST(0)
register as empty and increments the stack pointer (TOP) by 1. The FSTP instruction
can also store values in memory in double extended-precision floating-point format.
If the destination operand is a memory location, the operand specifies the address
where the first byte of the destination value is to be stored. If the destination
operand is a register, the operand specifies a register in the register stack relative to
the top of the stack.
If the destination size is single-precision or double-precision, the significand of the
value being stored is rounded to the width of the destination (according to the
rounding mode specified by the RC field of the FPU control word), and the exponent
is converted to the width and bias of the destination format. If the value being stored
is too large for the destination format, a numeric overflow exception (#O) is gener-
ated and, if the exception is unmasked, no value is stored in the destination operand.
If the value being stored is a denormal value, the denormal exception (#D) is not
generated. This condition is simply signaled as a numeric underflow exception (#U)
condition.
If the value being stored is ±0, ±∞, or a NaN, the least-significant bits of the signifi-
cand and the exponent are truncated to fit the destination format. This operation
preserves the value’s identity as a 0, ∞, or NaN.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D9 /2 FST m32fp Valid Valid Copy ST(0) to m32fp.
DD /2 FST m64fp Valid Valid Copy ST(0) to m64fp.
DD D0+i FST ST(i) Valid Valid Copy ST(0) to ST(i).
D9 /3 FSTP m32fp Valid Valid Copy ST(0) to m32fp and pop register
stack.
DD /3 FSTP m64fp Valid Valid Copy ST(0) to m64fp and pop register
stack.
DB /7 FSTP m80fp Valid Valid Copy ST(0) to m80fp and pop register
stack.
DD D8+i FSTP ST(i) Valid Valid Copy ST(0) to ST(i) and pop register
stack.

3-436 Vol. 2A FST/FSTP—Store Floating Point Value
INSTRUCTION SET REFERENCE, A-M
If the destination operand is a non-empty register, the invalid-operation exception is
not generated.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
DEST ← ST(0);
IF Instruction = FSTP
THEN
PopRegisterStack;
FI;
FPU Flags Affected
C1 Set to 0 if stack underflow occurred.
Indicates rounding direction of if the floating-point inexact
exception (#P) is generated: 0 ← not roundup; 1 ← roundup.
C0, C2, C3 Undefined.
Floating-Point Exceptions
#IS Stack underflow occurred.
#IA Source operand is an SNaN value or unsupported format. Does
not occur if the source operand is in double extended-precision
floating-point format.
#U Result is too small for the destination format.
#O Result is too large for the destination format.
#P Value cannot be represented exactly in destination format.
Protected Mode Exceptions
#GP(0) If the destination is located in a non-writable segment.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register is used to access memory and it
contains a NULL segment selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.

Vol. 2A 3-437
INSTRUCTION SET REFERENCE, A-M
FST/FSTP—Store Floating Point Value
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.

3-438 Vol. 2A FSTCW/FNSTCW—Store x87 FPU Control Word
INSTRUCTION SET REFERENCE, A-M
FSTCW/FNSTCW—Store x87 FPU Control Word
Description
Stores the current value of the FPU control word at the specified destination in
memory. The FSTCW instruction checks for and handles pending unmasked floating-
point exceptions before storing the control word; the FNSTCW instruction does not.
The assembler issues two instructions for the FSTCW instruction (an FWAIT instruc-
tion followed by an FNSTCW instruction), and the processor executes each of these
instructions in separately. If an exception is generated for either of these instruc-
tions, the save EIP points to the instruction that caused the exception.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
IA-32 Architecture Compatibility
When operating a Pentium or Intel486 processor in MS-DOS compatibility mode, it is
possible (under unusual circumstances) for an FNSTCW instruction to be interrupted
prior to being executed to handle a pending FPU exception. See the section titled
“No-Wait FPU Instructions Can Get FPU Interrupt in Window” in Appendix D of the
Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 1, for a
description of these circumstances. An FNSTCW instruction cannot be interrupted in
this way on a Pentium 4, Intel Xeon, or P6 family processor.
Operation
DEST ← FPUControlWord;
FPU Flags Affected
The C0, C1, C2, and C3 flags are undefined.
Floating-Point Exceptions
None.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
9B D9 /7 FSTCW m2byte Valid Valid Store FPU control word to m2byte
after checking for pending unmasked
floating-point exceptions.
D9 /7 FNSTCW* m2byte Valid Valid Store FPU control word to m2byte
without checking for pending
unmasked floating-point exceptions.
NOTES:
* See IA-32 Architecture Compatibility section below.

Vol. 2A 3-439
INSTRUCTION SET REFERENCE, A-M
FSTCW/FNSTCW—Store x87 FPU Control Word
Protected Mode Exceptions
#GP(0) If the destination is located in a non-writable segment.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register is used to access memory and it
contains a NULL segment selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.

3-440 Vol. 2A FSTCW/FNSTCW—Store x87 FPU Control Word
INSTRUCTION SET REFERENCE, A-M
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.

Vol. 2A 3-441
INSTRUCTION SET REFERENCE, A-M
FSTENV/FNSTENV—Store x87 FPU Environment
FSTENV/FNSTENV—Store x87 FPU Environment
Description
Saves the current FPU operating environment at the memory location specified with
the destination operand, and then masks all floating-point exceptions. The FPU oper-
ating environment consists of the FPU control word, status word, tag word, instruc-
tion pointer, data pointer, and last opcode. Figures 8-9 through 8-12 in the Intel® 64
and IA-32 Architectures Software Developer’s Manual, Volume 1, show the layout in
memory of the stored environment, depending on the operating mode of the
processor (protected or real) and the current operand-size attribute (16-bit or
32-bit). In virtual-8086 mode, the real mode layouts are used.
The FSTENV instruction checks for and handles any pending unmasked floating-point
exceptions before storing the FPU environment; the FNSTENV instruction does
not. The saved image reflects the state of the FPU after all floating-point instructions
preceding the FSTENV/FNSTENV instruction in the instruction stream have been
executed.
These instructions are often used by exception handlers because they provide access
to the FPU instruction and data pointers. The environment is typically saved in the
stack. Masking all exceptions after saving the environment prevents floating-point
exceptions from interrupting the exception handler.
The assembler issues two instructions for the FSTENV instruction (an FWAIT instruc-
tion followed by an FNSTENV instruction), and the processor executes each of these
instructions separately. If an exception is generated for either of these instructions,
the save EIP points to the instruction that caused the exception.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
9B D9 /6 FSTENV m14/28byte Valid Valid Store FPU environment to m14byte
or m28byte after checking for
pending unmasked floating-point
exceptions. Then mask all floating-
point exceptions.
D9 /6 FNSTENV*
m14/28byte
Valid Valid Store FPU environment to m14byte
or m28byte without checking for
pending unmasked floating-point
exceptions. Then mask all floating-
point exceptions.
NOTES:
* See IA-32 Architecture Compatibility section below.

3-442 Vol. 2A FSTENV/FNSTENV—Store x87 FPU Environment
INSTRUCTION SET REFERENCE, A-M
IA-32 Architecture Compatibility
When operating a Pentium or Intel486 processor in MS-DOS compatibility mode, it is
possible (under unusual circumstances) for an FNSTENV instruction to be interrupted
prior to being executed to handle a pending FPU exception. See the section titled
“No-Wait FPU Instructions Can Get FPU Interrupt in Window” in Appendix D of the
Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 1, for a
description of these circumstances. An FNSTENV instruction cannot be interrupted in
this way on a Pentium 4, Intel Xeon, or P6 family processor.
Operation
DEST[FPUControlWord] ← FPUControlWord;
DEST[FPUStatusWord] ← FPUStatusWord;
DEST[FPUTagWord] ← FPUTagWord;
DEST[FPUDataPointer] ← FPUDataPointer;
DEST[FPUInstructionPointer] ← FPUInstructionPointer;
DEST[FPULastInstructionOpcode] ← FPULastInstructionOpcode;
FPU Flags Affected
The C0, C1, C2, and C3 are undefined.
Floating-Point Exceptions
None.
Protected Mode Exceptions
#GP(0) If the destination is located in a non-writable segment.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register is used to access memory and it
contains a NULL segment selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.

Vol. 2A 3-443
INSTRUCTION SET REFERENCE, A-M
FSTENV/FNSTENV—Store x87 FPU Environment
#SS If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.

3-444 Vol. 2A FSTSW/FNSTSW—Store x87 FPU Status Word
INSTRUCTION SET REFERENCE, A-M
FSTSW/FNSTSW—Store x87 FPU Status Word
Description
Stores the current value of the x87 FPU status word in the destination location. The
destination operand can be either a two-byte memor y location or the AX register. The
FSTSW instruction checks for and handles pending unmasked floating-point excep-
tions before storing the status word; the FNSTSW instruction does not.
The FNSTSW AX form of the instruction is used primarily in conditional branching (for
instance, after an FPU comparison instruction or an FPREM, FPREM1, or FXAM
instruction), where the direction of the branch depends on the state of the FPU condi-
tion code flags. (See the section titled “Branching and Conditional Moves on FPU
Condition Codes” in Chapter 8 of the Intel® 64 and IA-32 Architectures Software
Developer’s Manual, Volume 1.) This instruction can also be used to invoke exception
handlers (by examining the exception flags) in environments that do not use inter-
rupts. When the FNSTSW AX instruction is executed, the AX register is updated
before the processor executes any further instructions. The status stored in the AX
register is thus guaranteed to be from the completion of the prior FPU instruction.
The assembler issues two instructions for the FSTSW instruction (an FWAIT instruc-
tion followed by an FNSTSW instruction), and the processor executes each of these
instructions separately. If an exception is generated for either of these instructions,
the save EIP points to the instruction that caused the exception.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
9B DD /7 FSTSW m2byte Valid Valid Store FPU status word at
m2byte after checking for
pending unmasked floating-
point exceptions.
9B DF E0 FSTSW AX Valid Valid Store FPU status word in AX
register after checking for
pending unmasked floating-
point exceptions.
DD /7 FNSTSW* m2byte Valid Valid Store FPU status word at
m2byte without checking for
pending unmasked floating-
point exceptions.
DF E0 FNSTSW* AX Valid Valid Store FPU status word in AX
register without checking for
pending unmasked floating-
point exceptions.
NOTES:
* See IA-32 Architecture Compatibility section below.

Vol. 2A 3-445
INSTRUCTION SET REFERENCE, A-M
FSTSW/FNSTSW—Store x87 FPU Status Word
IA-32 Architecture Compatibility
When operating a Pentium or Intel486 processor in MS-DOS compatibility mode, it is
possible (under unusual circumstances) for an FNSTSW instruction to be interrupted
prior to being executed to handle a pending FPU exception. See the section titled
“No-Wait FPU Instructions Can Get FPU Interrupt in Window” in Appendix D of the
Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 1, for a
description of these circumstances. An FNSTSW instruction cannot be interrupted in
this way on a Pentium 4, Intel Xeon, or P6 family processor.
Operation
DEST ← FPUStatusWord;
FPU Flags Affected
The C0, C1, C2, and C3 are undefined.
Floating-Point Exceptions
None.
Protected Mode Exceptions
#GP(0) If the destination is located in a non-writable segment.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register is used to access memory and it
contains a NULL segment selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.

3-446 Vol. 2A FSTSW/FNSTSW—Store x87 FPU Status Word
INSTRUCTION SET REFERENCE, A-M
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.

Vol. 2A 3-447
INSTRUCTION SET REFERENCE, A-M
FSUB/FSUBP/FISUB—Subtract
FSUB/FSUBP/FISUB—Subtract
Description
Subtracts the source operand from the destination operand and stores the difference
in the destination location. The destination operand is always an FPU data register;
the source operand can be a register or a memory location. Source operands in
memory can be in single-precision or double-precision floating-point format or in
word or doubleword integer format.
The no-operand version of the instruction subtracts the contents of the ST(0) register
from the ST(1) register and stores the result in ST(1). The one-operand version
subtracts the contents of a memory location (either a floating-point or an integer
value) from the contents of the ST(0) register and stores the result in ST(0). The
two-operand version, subtracts the contents of the ST(0) register from the ST(i)
register or vice versa.
The FSUBP instructions perform the additional operation of popping the FPU register
stack following the subtraction. To pop the register stack, the processor marks the
ST(0) register as empty and increments the stack pointer (TOP) by 1. The no-
operand version of the floating-point subtract instructions always results in the
register stack being popped. In some assemblers, the mnemonic for this instruction
is FSUB rather than FSUBP.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D8 /4 FSUB m32fp Valid Valid Subtract m32fp from ST(0)
and store result in ST(0).
DC /4 FSUB m64fp Valid Valid Subtract m64fp from ST(0)
and store result in ST(0).
D8 E0+i FSUB ST(0), ST(i) Valid Valid Subtract ST(i) from ST(0) and
store result in ST(0).
DC E8+i FSUB ST(i), ST(0) Valid Valid Subtract ST(0) from ST(i) and
store result in ST(i).
DE E8+i FSUBP ST(i), ST(0) Valid Valid Subtract ST(0) from ST(i),
store result in ST(i), and pop
register stack.
DE E9 FSUBP Valid Valid Subtract ST(0) from ST(1),
store result in ST(1), and pop
register stack.
DA /4 FISUB m32int Valid Valid Subtract m32int from ST(0)
and store result in ST(0).
DE /4 FISUB m16int Valid Valid Subtract m16int from ST(0)
and store result in ST(0).
3-448 Vol. 2A FSUB/FSUBP/FISUB—Subtract
INSTRUCTION SET REFERENCE, A-M
The FISUB instructions convert an integer source operand to double extended-preci-
sion floating-point format before performing the subtraction.
Table 3-48 shows the results obtained when subtracting various classes of numbers
from one another, assuming that neither overflow nor underflow occurs. Here, the
SRC value is subtracted from the DEST value (DEST − SRC = result).
When the difference between two operands of like sign is 0, the result is +0, except
for the round toward −∞ mode, in which case the result is −0. This instruction also
guarantees that +0 − (−0) = +0, and that −0 − (+0) = −0. When the source operand is
an integer 0, it is treated as a +0.
When one operand is ∞, the result is ∞ of the expected sign. If both operands are ∞ of
the same sign, an invalid-operation exception is generated.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
IF Instruction = FISUB
THEN
DEST ← DEST − ConvertToDoubleExtendedPrecisionFP(SRC);
ELSE (* Source operand is floating-point value *)
DEST ← DEST − SRC;
FI;
Table 3-48. FSUB/FSUBP/FISUB Results
SRC
- •− F or − I− 0+ 0+ F or + I+•NaN
- •*-•- •- •- •-•NaN
− F+•±F or ±0 DEST DEST − F-•NaN
DEST − 0+•−SRC ±0− 0− SRC -•NaN
+ 0+•−SRC + 0±0− SRC -•NaN
+ F+•+ F DEST DEST ±F or ±0-•NaN
+•+•+•+•+•+•*NaN
NaN NaN NaN NaN NaN NaN NaN NaN
NOTES:
F Means finite floating-point value.
IMeans integer.
* Indicates floating-point invalid-arithmetic-operand (#IA) exception.

Vol. 2A 3-449
INSTRUCTION SET REFERENCE, A-M
FSUB/FSUBP/FISUB—Subtract
IF Instruction = FSUBP
THEN
PopRegisterStack;
FI;
FPU Flags Affected
C1 Set to 0 if stack underflow occurred.
Set if result was rounded up; cleared otherwise.
C0, C2, C3 Undefined.
Floating-Point Exceptions
#IS Stack underflow occurred.
#IA Operand is an SNaN value or unsupported format.
Operands are infinities of like sign.
#D Source operand is a denormal value.
#U Result is too small for destination format.
#O Result is too large for destination format.
#P Value cannot be represented exactly in destination format.
Protected Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register is used to access memory and it
contains a NULL segment selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#UD If the LOCK prefix is used.

3-450 Vol. 2A FSUB/FSUBP/FISUB—Subtract
INSTRUCTION SET REFERENCE, A-M
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.

Vol. 2A 3-451
INSTRUCTION SET REFERENCE, A-M
FSUBR/FSUBRP/FISUBR—Reverse Subtract
FSUBR/FSUBRP/FISUBR—Reverse Subtract
Description
Subtracts the destination operand from the source operand and stores the difference
in the destination location. The destination operand is always an FPU register; the
source operand can be a register or a memory location. Source operands in memory
can be in single-precision or double-precision floating-point format or in word or
doubleword integer format.
These instructions perform the reverse operations of the FSUB, FSUBP, and FISUB
instructions. They are provided to support more efficient coding.
The no-operand version of the instruction subtracts the contents of the ST(1) register
from the ST(0) register and stores the result in ST(1). The one-operand version
subtracts the contents of the ST(0) register from the contents of a memory location
(either a floating-point or an integer value) and stores the result in ST(0). The two-
operand version, subtracts the contents of the ST(i) register from the ST(0) register
or vice versa.
The FSUBRP instructions perform the additional operation of popping the FPU register
stack following the subtraction. To pop the register stack, the processor marks the
ST(0) register as empty and increments the stack pointer (TOP) by 1. The no-
operand version of the floating-point reverse subtract instructions always results in
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D8 /5 FSUBR m32fp Valid Valid Subtract ST(0) from m32fp and
store result in ST(0).
DC /5 FSUBR m64fp Valid Valid Subtract ST(0) from m64fp and
store result in ST(0).
D8 E8+i FSUBR ST(0), ST(i) Valid Valid Subtract ST(0) from ST(i) and
store result in ST(0).
DC E0+i FSUBR ST(i), ST(0) Valid Valid Subtract ST(i) from ST(0) and
store result in ST(i).
DE E0+i FSUBRP ST(i), ST(0) Valid Valid Subtract ST(i) from ST(0), store
result in ST(i), and pop register
stack.
DE E1 FSUBRP Valid Valid Subtract ST(1) from ST(0),
store result in ST(1), and pop
register stack.
DA /5 FISUBR m32int Valid Valid Subtract ST(0) from m32int and
store result in ST(0).
DE /5 FISUBR m16int Valid Valid Subtract ST(0) from m16int and
store result in ST(0).
3-452 Vol. 2A FSUBR/FSUBRP/FISUBR—Reverse Subtract
INSTRUCTION SET REFERENCE, A-M
the register stack being popped. In some assemblers, the mnemonic for this instruc-
tion is FSUBR rather than FSUBRP.
The FISUBR instructions convert an integer source operand to double extended-
precision floating-point format before performing the subtraction.
The following table shows the results obtained when subtracting various classes of
numbers from one another, assuming that neither overflow nor underflow occurs.
Here, the DEST value is subtracted from the SRC value (SRC − DEST = result).
When the difference between two operands of like sign is 0, the result is +0, except
for the round toward −∞ mode, in which case the result is −0. This instruction also
guarantees that +0 − (−0) = +0, and that −0 − (+0) = −0. When the source operand is
an integer 0, it is treated as a +0.
When one operand is ∞, the result is ∞ of the expected sign. If both operands are ∞ of
the same sign, an invalid-operation exception is generated.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
IF Instruction = FISUBR
THEN
DEST ← ConvertToDoubleExtendedPrecisionFP(SRC) − DEST;
ELSE (* Source operand is floating-point value *)
DEST ← SRC − DEST; FI;
Table 3-49. FSUBR/FSUBRP/FISUBR Results
SRC
-•−F or −I−0+0+F or +I+•NaN
- •*+•+•+•+•+•NaN
− F-•±F or ±0−DEST −DEST + F+•NaN
DEST − 0-•SRC ±0+ 0SRC +•NaN
+ 0-•SRC − 0±0SRC+•NaN
+ F-•− F−DEST −DEST ±F or ±0+•NaN
+•-•-•-•-•-•*NaN
NaN NaN NaN NaN NaN NaN NaN NaN
NOTES:
F Means finite floating-point value.
IMeans integer.
* Indicates floating-point invalid-arithmetic-operand (#IA) exception.

Vol. 2A 3-453
INSTRUCTION SET REFERENCE, A-M
FSUBR/FSUBRP/FISUBR—Reverse Subtract
IF Instruction = FSUBRP
THEN
PopRegisterStack; FI;
FPU Flags Affected
C1 Set to 0 if stack underflow occurred.
Set if result was rounded up; cleared otherwise.
C0, C2, C3 Undefined.
Floating-Point Exceptions
#IS Stack underflow occurred.
#IA Operand is an SNaN value or unsupported format.
Operands are infinities of like sign.
#D Source operand is a denormal value.
#U Result is too small for destination format.
#O Result is too large for destination format.
#P Value cannot be represented exactly in destination format.
Protected Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register is used to access memory and it
contains a NULL segment selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#UD If the LOCK prefix is used.

3-454 Vol. 2A FSUBR/FSUBRP/FISUBR—Reverse Subtract
INSTRUCTION SET REFERENCE, A-M
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Vol. 2A 3-455
INSTRUCTION SET REFERENCE, A-M
FTST—TEST
FTST—TEST
Description
Compares the value in the ST(0) register with 0.0 and sets the condition code flags
C0, C2, and C3 in the FPU status word according to the results (see table below).
This instruction performs an “unordered comparison.” An unordered comparison also
checks the class of the numbers being compared (see “FXAM—Examine ModR/M” in
this chapter). If the value in register ST(0) is a NaN or is in an undefined format, the
condition flags are set to “unordered” and the invalid operation exception is gener-
ated.
The sign of zero is ignored, so that (– 0.0 ← +0.0).
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
CASE (relation of operands) OF
Not comparable: C3, C2, C0 ← 111;
ST(0) > 0.0: C3, C2, C0 ← 000;
ST(0) < 0.0: C3, C2, C0 ← 001;
ST(0) = 0.0: C3, C2, C0 ← 100;
ESAC;
FPU Flags Affected
C1 Set to 0 if stack underflow occurred; otherwise, set to 0.
C0, C2, C3 See Table 3-50.
Floating-Point Exceptions
#IS Stack underflow occurred.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D9 E4 FTST Valid Valid Compare ST(0) with 0.0.
Table 3-50. FTST Results
Condition C3 C2 C0
ST(0) > 0.0 0 0 0
ST(0) < 0.0 0 0 1
ST(0) = 0.0 1 0 0
Unordered 1 1 1

3-456 Vol. 2A FTST—TEST
INSTRUCTION SET REFERENCE, A-M
#IA The source operand is a NaN value or is in an unsupported
format.
#D The source operand is a denormal value.
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.
Vol. 2A 3-457
INSTRUCTION SET REFERENCE, A-M
FUCOM/FUCOMP/FUCOMPP—Unordered Compare Floating Point Values
FUCOM/FUCOMP/FUCOMPP—Unordered Compare Floating Point Values
Description
Performs an unordered comparison of the contents of register ST(0) and ST(i) and
sets condition code flags C0, C2, and C3 in the FPU status word according to the
results (see the table below). If no operand is specified, the contents of registers
ST(0) and ST(1) are compared. The sign of zero is ignored, so that –0.0 is equal to
+0.0.
An unordered comparison checks the class of the numbers being compared (see
“FXAM—Examine ModR/M” in this chapter). The FUCOM/FUCOMP/FUCOMPP instruc-
tions perform the same operations as the FCOM/FCOMP/FCOMPP instructions. The
only difference is that the FUCOM/FUCOMP/FUCOMPP instructions raise the invalid-
arithmetic-operand exception (#IA) only when either or both operands are an SNaN
or are in an unsupported format; QNaNs cause the condition code flags to be set to
unordered, but do not cause an exception to be generated. The
FCOM/FCOMP/FCOMPP instructions raise an invalid-operation exception when either
or both of the operands are a NaN value of any kind or are in an unsupported format.
As with the FCOM/FCOMP/FCOMPP instructions, if the operation results in an invalid-
arithmetic-operand exception being raised, the condition code flags are set only if the
exception is masked.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
DD E0+i FUCOM ST(i) Valid Valid Compare ST(0) with ST(i).
DD E1 FUCOM Valid Valid Compare ST(0) with ST(1).
DD E8+i FUCOMP ST(i) Valid Valid Compare ST(0) with ST(i) and pop
register stack.
DD E9 FUCOMP Valid Valid Compare ST(0) with ST(1) and pop
register stack.
DA E9 FUCOMPP Valid Valid Compare ST(0) with ST(1) and pop
register stack twice.
Table 3-51. FUCOM/FUCOMP/FUCOMPP Results
Comparison Results* C3 C2 C0
ST0 > ST(i) 0 0 0
ST0 < ST(i) 0 0 1
ST0 = ST(i) 1 0 0
Unordered 1 1 1
NOTES:
* Flags not set if unmasked invalid-arithmetic-operand (#IA) exception is generated.

3-458 Vol. 2A FUCOM/FUCOMP/FUCOMPP—Unordered Compare Floating Point Values
INSTRUCTION SET REFERENCE, A-M
The FUCOMP instruction pops the register stack following the comparison operation
and the FUCOMPP instruction pops the register stack twice following the comparison
operation. To pop the register stack, the processor marks the ST(0) register as
empty and increments the stack pointer (TOP) by 1.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
CASE (relation of operands) OF
ST > SRC: C3, C2, C0 ← 000;
ST < SRC: C3, C2, C0 ← 001;
ST = SRC: C3, C2, C0 ← 100;
ESAC;
IF ST(0) or SRC = QNaN, but not SNaN or unsupported format
THEN
C3, C2, C0 ← 111;
ELSE (* ST(0) or SRC is SNaN or unsupported format *)
#IA;
IF FPUControlWord.IM = 1
THEN
C3, C2, C0 ← 111;
FI;
FI;
IF Instruction = FUCOMP
THEN
PopRegisterStack;
FI;
IF Instruction = FUCOMPP
THEN
PopRegisterStack;
FI;
FPU Flags Affected
C1 Set to 0 if stack underflow occurred.
C0, C2, C3 See Table 3-51.
Floating-Point Exceptions
#IS Stack underflow occurred.

Vol. 2A 3-459
INSTRUCTION SET REFERENCE, A-M
FUCOM/FUCOMP/FUCOMPP—Unordered Compare Floating Point Values
#IA One or both operands are SNaN values or have unsupported
formats. Detection of a QNaN value in and of itself does not raise
an invalid-operand exception.
#D One or both operands are denormal values.
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.

3-460 Vol. 2A FXAM—Examine ModR/M
INSTRUCTION SET REFERENCE, A-M
FXAM—Examine ModR/M
Description
Examines the contents of the ST(0) register and sets the condition code flags C0, C2,
and C3 in the FPU status word to indicate the class of value or number in the register
(see the table below).
.
The C1 flag is set to the sign of the value in ST(0), regardless of whether the register
is empty or full.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
C1 ← sign bit of ST; (* 0 for positive, 1 for negative *)
CASE (class of value or number in ST(0)) OF
Unsupported:C3, C2, C0 ← 000;
NaN: C3, C2, C0 ← 001;
Normal: C3, C2, C0 ← 010;
Infinity: C3, C2, C0 ← 011;
Zero: C3, C2, C0 ← 100;
Empty: C3, C2, C0 ← 101;
Denormal: C3, C2, C0 ← 110;
ESAC;
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D9 E5 FXAM Valid Valid Classify value or number in ST(0).
Table 3-52. FXAM Results
Class C3 C2 C0
Unsupported 000
NaN 001
Normal finite number 010
Infinity 011
Zero 100
Empty 101
Denormal number 110

Vol. 2A 3-461
INSTRUCTION SET REFERENCE, A-M
FXAM—Examine ModR/M
FPU Flags Affected
C1 Sign of value in ST(0).
C0, C2, C3 See Table 3-52.
Floating-Point Exceptions
None.
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.

3-462 Vol. 2A FXCH—Exchange Register Contents
INSTRUCTION SET REFERENCE, A-M
FXCH—Exchange Register Contents
Description
Exchanges the contents of registers ST(0) and ST(i). If no source operand is speci-
fied, the contents of ST(0) and ST(1) are exchanged.
This instruction provides a simple means of moving values in the FPU register stack
to the top of the stack [ST(0)], so that they can be operated on by those floating-
point instructions that can only operate on values in ST(0). For example, the
following instruction sequence takes the square root of the third register from the top
of the register stack:
FXCH ST(3);
FSQRT;
FXCH ST(3);
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
IF (Number-of-operands) is 1
THEN
temp ← ST(0);
ST(0) ← SRC;
SRC ← temp;
ELSE
temp ← ST(0);
ST(0) ← ST(1);
ST(1) ← temp;
FI;
FPU Flags Affected
C1 Set to 0 if stack underflow occurred; otherwise, set to 1.
C0, C2, C3 Undefined.
Floating-Point Exceptions
#IS Stack underflow occurred.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D9 C8+i FXCH ST(i) Valid Valid Exchange the contents of ST(0) and
ST(i).
D9 C9 FXCH Valid Valid Exchange the contents of ST(0) and
ST(1).

Vol. 2A 3-463
INSTRUCTION SET REFERENCE, A-M
FXCH—Exchange Register Contents
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.
3-464 Vol. 2A FXRSTOR—Restore x87 FPU, MMX , XMM, and MXCSR State
INSTRUCTION SET REFERENCE, A-M
FXRSTOR—Restore x87 FPU, MMX , XMM, and MXCSR State
Instruction Operand Encoding
Description
Reloads the x87 FPU, MMX technology, XMM, and MXCSR registers from the 512-byte
memory image specified in the source operand. This data should have been written
to memory previously using the FXSAVE instruction, and in the same format as
required by the operating modes. The first byte of the data should be located on a
16-byte boundary. There are three distinct layouts of the FXSAVE state map: one for
legacy and compatibility mode, a second format for 64-bit mode FXSAVE/FXRSTOR
with REX.W=0, and the third format is for 64-bit mode with FXSAVE64/FXRSTOR64.
Table 3-53 shows the layout of the legacy/compatibility mode state information in
memory and describes the fields in the memory image for the FXRSTOR and FXSAVE
instructions. Table 3-56 shows the layout of the 64-bit mode state information when
REX.W is set (FXSAVE64/FXRSTOR64). Table 3-57 shows the layout of the 64-bit
mode state information when REX.W is clear (FXSAVE/FXRSTOR).
The state image referenced with an FXRSTOR instruction must have been saved
using an FXSAVE instruction or be in the same format as required by Table 3-53,
Table 3-56, or Table 3-57. Referencing a state image saved with an FSAVE, FNSAVE
instruction or incompatible field layout will result in an incorrect state restoration.
The FXRSTOR instruction does not flush pending x87 FPU exceptions. To check and
raise exceptions when loading x87 FPU state information with the FXRSTOR instruc-
tion, use an FWAIT instruction after the FXRSTOR instruction.
If the OSFXSR bit in control register CR4 is not set, the FXRSTOR instruction may not
restore the states of the XMM and MXCSR registers. This behavior is implementation
dependent.
If the MXCSR state contains an unmasked exception with a corresponding status flag
also set, loading the register with the FXRSTOR instruction will not result in a SIMD
floating-point error condition being generated. Only the next occurrence of this
unmasked exception will result in the exception being generated.
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F AE /1 FXRSTOR
m512byte
A Valid Valid Restore the x87 FPU, MMX,
XMM, and MXCSR register
state from m512byte.
REX.W+ 0F AE
/1
FXRSTOR64
m512byte
A Valid N.E. Restore the x87 FPU, MMX,
XMM, and MXCSR register
state from m512byte.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (r) NA NA NA

Vol. 2A 3-465
INSTRUCTION SET REFERENCE, A-M
FXRSTOR—Restore x87 FPU, MMX , XMM, and MXCSR State
Bits 16 through 32 of the MXCSR register are defined as reserved and should be set
to 0. Attempting to write a 1 in any of these bits from the saved state image will
result in a general protection exception (#GP) being generated.
Bytes 464:511 of an FXSAVE image are available for software use. FXRSTOR ignores
the content of bytes 464:511 in an FXSAVE state image.
Operation
(x87 FPU, MMX, XMM7-XMM0, MXCSR) ← Load(SRC);
x87 FPU and SIMD Floating-Point Exceptions
None.
Protected Mode Exceptions
#GP(0) For an illegal memory operand effective address in the CS, DS,
ES, FS or GS segments.
If a memory operand is not aligned on a 16-byte boundary,
regardless of segment. (See alignment check exception [#AC]
below.)
For an attempt to set reserved bits in MXCSR.
#SS(0) For an illegal address in the SS segment.
#PF(fault-code) For a page fault.
#NM If CR0.TS[bit 3] = 1.
If CR0.EM[bit 2] = 1.
#UD If CPUID.01H:EDX.FXSR[bit 24] = 0.
If instruction is preceded by a LOCK prefix.
#AC If this exception is disabled a general protection exception
(#GP) is signaled if the memory operand is not aligned on a 16-
byte boundary, as described above. If the alignment check
exception (#AC) is enabled (and the CPL is 3), signaling of #AC
is not guaranteed and may vary with implementation, as
follows. In all implementations where #AC is not signaled, a
general protection exception is signaled in its place. In addition,
the width of the alignment check may also vary with implemen-
tation. For instance, for a given implementation, an alignment
check exception might be signaled for a 2-byte misalignment,
whereas a general protection exception might be signaled for all
other misalignments (4-, 8-, or 16-byte misalignments).
#UD If the LOCK prefix is used.

3-466 Vol. 2A FXRSTOR—Restore x87 FPU, MMX , XMM, and MXCSR State
INSTRUCTION SET REFERENCE, A-M
Real-Address Mode Exceptions
#GP If a memory operand is not aligned on a 16-byte boundary,
regardless of segment.
If any part of the operand lies outside the effective address
space from 0 to FFFFH.
For an attempt to set reserved bits in MXCSR.
#NM If CR0.TS[bit 3] = 1.
If CR0.EM[bit 2] = 1.
#UD If CPUID.01H:EDX.FXSR[bit 24] = 0.
If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
Same exceptions as in real address mode.
#PF(fault-code) For a page fault.
#AC For unaligned memory reference.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
If memory operand is not aligned on a 16-byte boundary,
regardless of segment.
For an attempt to set reserved bits in MXCSR.
#PF(fault-code) For a page fault.
#NM If CR0.TS[bit 3] = 1.
If CR0.EM[bit 2] = 1.
#UD If CPUID.01H:EDX.FXSR[bit 24] = 0.
If instruction is preceded by a LOCK prefix.
#AC If this exception is disabled a general protection exception
(#GP) is signaled if the memory operand is not aligned on a
16-byte boundary, as described above. If the alignment check
exception (#AC) is enabled (and the CPL is 3), signaling of #AC
is not guaranteed and may vary with implementation, as
follows. In all implementations where #AC is not signaled, a
general protection exception is signaled in its place. In addition,
the width of the alignment check may also vary with implemen-

Vol. 2A 3-467
INSTRUCTION SET REFERENCE, A-M
FXRSTOR—Restore x87 FPU, MMX , XMM, and MXCSR State
tation. For instance, for a given implementation, an alignment
check exception might be signaled for a 2-byte misalignment,
whereas a general protection exception might be signaled for all
other misalignments (4-, 8-, or 16-byte misalignments).
3-468 Vol. 2A FXSAVE—Save x87 FPU, MMX Technology, and SSE State
INSTRUCTION SET REFERENCE, A-M
FXSAVE—Save x87 FPU, MMX Technology, and SSE State
Instruction Operand Encoding
Description
Saves the current state of the x87 FPU, MMX technology, XMM, and MXCSR registers
to a 512-byte memory location specified in the destination operand. The content
layout of the 512 byte region depends on whether the processor is operating in non-
64-bit operating modes or 64-bit sub-mode of IA-32e mode.
Bytes 464:511 are available to software use. The processor does not write to bytes
464:511 of an FXSAVE area.
The operation of FXSAVE in non-64-bit modes is described first.
Non-64-Bit Mode Operation
Table 3-53 shows the layout of the state information in memory when the processor
is operating in legacy modes.
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F AE /0 FXSAVE
m512byte
A Valid Valid Save the x87 FPU, MMX,
XMM, and MXCSR register
state to m512byte.
REX.W+ 0F AE
/0
FXSAVE64
m512byte
A Valid N.E. Save the x87 FPU, MMX,
XMM, and MXCSR register
state to m512byte.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (w) NA NA NA
Table 3-53. Non-64-bit-Mode Layout of FXSAVE and FXRSTOR
Memory Region
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
Rsrvd CS FPU IP FOP Rs
rvd
FTW FSW FCW 0
MXCSR_MASK MXCSR Rsrvd DS FPU DP 16
Reserved ST0/MM0 32
Reserved ST1/MM1 48
Reserved ST2/MM2 64
Reserved ST3/MM3 80
Reserved ST4/MM4 96

Vol. 2A 3-469
INSTRUCTION SET REFERENCE, A-M
FXSAVE—Save x87 FPU, MMX Technology, and SSE State
The destination operand contains the first byte of the memory image, and it must be
aligned on a 16-byte boundary. A misaligned destination operand will result in a
general-protection (#GP) exception being generated (or in some cases, an alignment
check exception [#AC]).
Reserved ST5/MM5 112
Reserved ST6/MM6 128
Reserved ST7/MM7 144
XMM0 160
XMM1 176
XMM2 192
XMM3 208
XMM4 224
XMM5 240
XMM6 256
XMM7 272
Reserved 288
Reserved 304
Reserved 320
Reserved 336
Reserved 352
Reserved 368
Reserved 384
Reserved 400
Reserved 416
Reserved 432
Reserved 448
Available 464
Available 480
Available 496
Table 3-53. Non-64-bit-Mode Layout of FXSAVE and FXRSTOR
Memory Region (Contd.)
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0

3-470 Vol. 2A FXSAVE—Save x87 FPU, MMX Technology, and SSE State
INSTRUCTION SET REFERENCE, A-M
The FXSAVE instruction is used when an operating system needs to perform a
context switch or when an exception handler needs to save and examine the current
state of the x87 FPU, MMX technology, and/or XMM and MXCSR registers.
The fields in Table 3-53 are defined in Table 3-54.
Table 3-54. Field Definitions
Field Definition
FCW x87 FPU Control Word (16 bits). See Figure 8-6 in the Intel® 64 and IA-32
Architectures Software Developer’s Manual, Volume 1, for the layout of
the x87 FPU control word.
FSW x87 FPU Status Word (16 bits). See Figure 8-4 in the Intel® 64 and IA-32
Architectures Software Developer’s Manual, Volume 1, for the layout of
the x87 FPU status word.
Abridged FTW x87 FPU Tag Word (8 bits). The tag information saved here is abridged, as
described in the following paragraphs.
FOP x87 FPU Opcode (16 bits). The lower 11 bits of this field contain the
opcode, upper 5 bits are reserved. See Figure 8-8 in the Intel® 64 and IA-32
Architectures Software Developer’s Manual, Volume 1, for the layout of
the x87 FPU opcode field.
FPU IP x87 FPU Instruction Pointer Offset (32 bits). The contents of this field
differ depending on the current addressing mode (32-bit or 16-bit) of the
processor when the FXSAVE instruction was executed:
32-bit mode — 32-bit IP offset.
16-bit mode — low 16 bits are IP offset; high 16 bits are reserved.
See “x87 FPU Instruction and Operand (Data) Pointers” in Chapter 8 of the
Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 1,
for a description of the x87 FPU instruction pointer.
CS x87 FPU Instruction Pointer Selector (16 bits).
FPU DP x87 FPU Instruction Operand (Data) Pointer Offset (32 bits). The contents
of this field differ depending on the current addressing mode (32-bit or 16-
bit) of the processor when the FXSAVE instruction was executed:
32-bit mode — 32-bit DP offset.
16-bit mode — low 16 bits are DP offset; high 16 bits are reserved.
See “x87 FPU Instruction and Operand (Data) Pointers” in Chapter 8 of the
Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 1,
for a description of the x87 FPU operand pointer.
DS x87 FPU Instruction Operand (Data) Pointer Selector (16 bits).

Vol. 2A 3-471
INSTRUCTION SET REFERENCE, A-M
FXSAVE—Save x87 FPU, MMX Technology, and SSE State
The FXSAVE instruction saves an abridged version of the x87 FPU tag word in the
FTW field (unlike the FSAVE instruction, which saves the complete tag word). The tag
information is saved in physical register order (R0 through R7), rather than in top-of-
stack (TOS) order. With the FXSAVE instruction, however, only a single bit (1 for valid
or 0 for empty) is saved for each tag. For example, assume that the tag word is
currently set as follows:
R7 R6 R5 R4 R3 R2 R1 R0
11 xx xx xx 11 11 11 11
Here, 11B indicates empty stack elements and “xx” indicates valid (00B), zero (01B),
or special (10B).
For this example, the FXSAVE instruction saves only the following 8 bits of informa-
tion:
R7 R6 R5 R4 R3 R2 R1 R0
01110000
MXCSR MXCSR Register State (32 bits). See Figure 10-3 in the Intel® 64 and IA-32
Architectures Software Developer’s Manual, Volume 1, for the layout of
the MXCSR register. If the OSFXSR bit in control register CR4 is not set, the
FXSAVE instruction may not save this register. This behavior is
implementation dependent.
MXCSR_
MASK
MXCSR_MASK (32 bits). This mask can be used to adjust values written to
the MXCSR register, ensuring that reserved bits are set to 0. Set the mask
bits and flags in MXCSR to the mode of operation desired for SSE and SSE2
SIMD floating-point instructions. See “Guidelines for Writing to the MXCSR
Register” in Chapter 11 of the Intel® 64 and IA-32 Architectures Software
Developer’s Manual, Volume 1, for instructions for how to determine and
use the MXCSR_MASK value.
ST0/MM0 through
ST7/MM7
x87 FPU or MMX technology registers. These 80-bit fields contain the x87
FPU data registers or the MMX technology registers, depending on the
state of the processor prior to the execution of the FXSAVE instruction. If
the processor had been executing x87 FPU instruction prior to the FXSAVE
instruction, the x87 FPU data registers are saved; if it had been executing
MMX instructions (or SSE or SSE2 instructions that operated on the MMX
technology registers), the MMX technology registers are saved. When the
MMX technology registers are saved, the high 16 bits of the field are
reserved.
XMM0 through
XMM7
XMM registers (128 bits per field). If the OSFXSR bit in control register CR4
is not set, the FXSAVE instruction may not save these registers. This
behavior is implementation dependent.
Table 3-54. Field Definitions (Contd.)
Field Definition
3-472 Vol. 2A FXSAVE—Save x87 FPU, MMX Technology, and SSE State
INSTRUCTION SET REFERENCE, A-M
Here, a 1 is saved for any valid, zero, or special tag, and a 0 is saved for any empty
tag.
The operation of the FXSAVE instruction differs from that of the FSAVE instruction,
the as follows:
•FXSAVE instruction does not check for pending unmasked floating-point
exceptions. (The FXSAVE operation in this regard is similar to the operation of the
FNSAVE instruction).
•After the FXSAVE instruction has saved the state of the x87 FPU, MMX
technology, XMM, and MXCSR registers, the processor retains the contents of the
registers. Because of this behavior, the FXSAVE instruction cannot be used by an
application program to pass a “clean” x87 FPU state to a procedure, since it
retains the current state. To clean the x87 FPU state, an application must
explicitly execute an FINIT instruction after an FXSAVE instruction to reinitialize
the x87 FPU state.
•The format of the memory image saved with the FXSAVE instruction is the same
regardless of the current addressing mode (32-bit or 16-bit) and operating mode
(protected, real address, or system management). This behavior differs from the
FSAVE instructions, where the memory image format is different depending on
the addressing mode and operating mode. Because of the different image
formats, the memory image saved with the FXSAVE instruction cannot be
restored correctly with the FRSTOR instruction, and likewise the state saved with
the FSAVE instruction cannot be restored correctly with the FXRSTOR instruction.
The FSAVE format for FTW can be recreated from the FTW valid bits and the stored
80-bit FP data (assuming the stored data was not the contents of MMX technology
registers) using Table 3-55.
Table 3-55. Recreating FSAVE Format
Exponent
all 1’s
Exponent
all 0’s
Fraction
all 0’s
J and M
bits
FTW valid
bit x87 FTW
0000x1Special 10
0001x1
Valid 00
001001
Special 10
001101
Valid 00
0100x1
Special 10
0101x1
Special 10
011001
Zero 01
011101
Special 10
1001x1
Special 10
1001x1
Special 10

Vol. 2A 3-473
INSTRUCTION SET REFERENCE, A-M
FXSAVE—Save x87 FPU, MMX Technology, and SSE State
The J-bit is defined to be the 1-bit binary integer to the left of the decimal place in the
significand. The M-bit is defined to be the most significant bit of the fractional portion
of the significand (i.e., the bit immediately to the right of the decimal place).
When the M-bit is the most significant bit of the fractional portion of the significand,
it must be 0 if the fraction is all 0’s.
IA-32e Mode Operation
In compatibility sub-mode of IA-32e mode, legacy SSE registers, XMM0 through
XMM7, are saved according to the legacy FXSAVE map. In 64-bit mode, all of the SSE
registers, XMM0 through XMM15, are saved. Additionally, there are two different
layouts of the FXSAVE map in 64-bit mode, corresponding to FXSAVE64 (which
requires REX.W=1) and FXSAVE (REX.W=0). In the FXSAVE64 map (Table 3-56), the
FPU IP and FPU DP pointers are 64-bit wide. In the FXSAVE map for 64-bit mode
(Table 3-57), the FPU IP and FPU DP pointers are 32-bits.
101001Special 10
101101
Special 10
For all legal combinations above. 0Empty 11
Table 3-56. Layout of the 64-bit-mode FXSAVE64 Map
(requires REX.W = 1)
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
FPU IP FOP Re-
served FTW FSW FCW 0
MXCSR_MASK MXCSR FPU DP 16
Reserved ST0/MM0 32
Reserved ST1/MM1 48
Reserved ST2/MM2 64
Reserved ST3/MM3 80
Reserved ST4/MM4 96
Reserved ST5/MM5 112
Reserved ST6/MM6 128
Reserved ST7/MM7 144
XMM0 160
XMM1 176
Table 3-55. Recreating FSAVE Format (Contd.)
Exponent
all 1’s
Exponent
all 0’s
Fraction
all 0’s
J and M
bits
FTW valid
bit x87 FTW

3-474 Vol. 2A FXSAVE—Save x87 FPU, MMX Technology, and SSE State
INSTRUCTION SET REFERENCE, A-M
XMM2 192
XMM3 208
XMM4 224
XMM5 240
XMM6 256
XMM7 272
XMM8 288
XMM9 304
XMM10 320
XMM11 336
XMM12 352
XMM13 368
XMM14 384
XMM15 400
Reserved 416
Reserved 432
Reserved 448
Available 464
Available 480
Available 496
Table 3-57. Layout of the 64-bit-mode FXSAVE Map (REX.W = 0)
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
Reserved CS FPU IP FOP Re-
served FTW FSW FCW 0
MXCSR_MASK MXCSR Re-
served FPU DP 16
Reserved ST0/MM0 32
Reserved ST1/MM1 48
Reserved ST2/MM2 64
Reserved ST3/MM3 80
Table 3-56. Layout of the 64-bit-mode FXSAVE64 Map
(requires REX.W = 1) (Contd.)
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0

Vol. 2A 3-475
INSTRUCTION SET REFERENCE, A-M
FXSAVE—Save x87 FPU, MMX Technology, and SSE State
Operation
IF 64-Bit Mode
THEN
IF REX.W = 1
THEN
Reserved ST4/MM4 96
Reserved ST5/MM5 112
Reserved ST6/MM6 128
Reserved ST7/MM7 144
XMM0 160
XMM1 176
XMM2 192
XMM3 208
XMM4 224
XMM5 240
XMM6 256
XMM7 272
XMM8 288
XMM9 304
XMM10 320
XMM11 336
XMM12 352
XMM13 368
XMM14 384
XMM15 400
Reserved 416
Reserved 432
Reserved 448
Available 464
Available 480
Available 496
Table 3-57. Layout of the 64-bit-mode FXSAVE Map (REX.W = 0) (Contd.) (Contd.)
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0

3-476 Vol. 2A FXSAVE—Save x87 FPU, MMX Technology, and SSE State
INSTRUCTION SET REFERENCE, A-M
DEST ← Save64BitPromotedFxsave(x87 FPU, MMX, XMM7-XMM0,
MXCSR);
ELSE
DEST ← Save64BitDefaultFxsave(x87 FPU, MMX, XMM7-XMM0, MXCSR);
FI;
ELSE
DEST ← SaveLegacyFxsave(x87 FPU, MMX, XMM7-XMM0, MXCSR);
FI;
Protected Mode Exceptions
#GP(0) For an illegal memory operand effective address in the CS, DS,
ES, FS or GS segments.
If a memory operand is not aligned on a 16-byte boundary,
regardless of segment. (See the description of the alignment
check exception [#AC] below.)
#SS(0) For an illegal address in the SS segment.
#PF(fault-code) For a page fault.
#NM If CR0.TS[bit 3] = 1.
If CR0.EM[bit 2] = 1.
#UD If CPUID.01H:EDX.FXSR[bit 24] = 0.
#UD If the LOCK prefix is used.
#AC If this exception is disabled a general protection exception
(#GP) is signaled if the memory operand is not aligned on a
16-byte boundary, as described above. If the alignment check
exception (#AC) is enabled (and the CPL is 3), signaling of #AC
is not guaranteed and may vary with implementation, as
follows. In all implementations where #AC is not signaled, a
general protection exception is signaled in its place. In addition,
the width of the alignment check may also vary with implemen-
tation. For instance, for a given implementation, an alignment
check exception might be signaled for a 2-byte misalignment,
whereas a general protection exception might be signaled for all
other misalignments (4-, 8-, or 16-byte misalignments).
Real-Address Mode Exceptions
#GP If a memory operand is not aligned on a 16-byte boundary,
regardless of segment.
If any part of the operand lies outside the effective address
space from 0 to FFFFH.
#NM If CR0.TS[bit 3] = 1.
If CR0.EM[bit 2] = 1.

Vol. 2A 3-477
INSTRUCTION SET REFERENCE, A-M
FXSAVE—Save x87 FPU, MMX Technology, and SSE State
#UD If CPUID.01H:EDX.FXSR[bit 24] = 0.
If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
Same exceptions as in real address mode.
#PF(fault-code) For a page fault.
#AC For unaligned memory reference.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
If memory operand is not aligned on a 16-byte boundary,
regardless of segment.
#PF(fault-code) For a page fault.
#NM If CR0.TS[bit 3] = 1.
If CR0.EM[bit 2] = 1.
#UD If CPUID.01H:EDX.FXSR[bit 24] = 0.
If the LOCK prefix is used.
#AC If this exception is disabled a general protection exception
(#GP) is signaled if the memory operand is not aligned on a
16-byte boundary, as described above. If the alignment check
exception (#AC) is enabled (and the CPL is 3), signaling of #AC
is not guaranteed and may vary with implementation, as
follows. In all implementations where #AC is not signaled, a
general protection exception is signaled in its place. In addition,
the width of the alignment check may also vary with implemen-
tation. For instance, for a given implementation, an alignment
check exception might be signaled for a 2-byte misalignment,
whereas a general protection exception might be signaled for all
other misalignments (4-, 8-, or 16-byte misalignments).
Implementation Note
The order in which the processor signals general-protection (#GP) and page-fault
(#PF) exceptions when they both occur on an instruction boundary is given in Table
5-2 in the Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume
3B. This order vary for FXSAVE for different processor implementations.

3-478 Vol. 2A FXTRACT—Extract Exponent and Significand
INSTRUCTION SET REFERENCE, A-M
FXTRACT—Extract Exponent and Significand
Description
Separates the source value in the ST(0) register into its exponent and significand,
stores the exponent in ST(0), and pushes the significand onto the register stack.
Following this operation, the new top-of-stack register ST(0) contains the value of
the original significand expressed as a floating-point value. The sign and significand
of this value are the same as those found in the source operand, and the exponent is
3FFFH (biased value for a true exponent of zero). The ST(1) register contains the
value of the original operand’s true (unbiased) exponent expressed as a floating-
point value. (The operation performed by this instruction is a superset of the IEEE-
recommended logb(x) function.)
This instruction and the F2XM1 instruction are useful for performing power and range
scaling operations. The FXTRACT instruction is also useful for converting numbers in
double extended-precision floating-point format to decimal representations (e.g., for
printing or displaying).
If the floating-point zero-divide exception (#Z) is masked and the source operand is
zero, an exponent value of –∞ is stored in register ST(1) and 0 with the sign of the
source operand is stored in register ST(0).
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
TEMP ← Significand(ST(0));
ST(0) ← Exponent(ST(0));
TOP← TOP − 1;
ST(0) ← TEMP;
FPU Flags Affected
C1 Set to 0 if stack underflow occurred; set to 1 if stack overflow
occurred.
C0, C2, C3 Undefined.
Floating-Point Exceptions
#IS Stack underflow or overflow occurred.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D9 F4 FXTRACT Valid Valid Separate value in ST(0) into exponent and
significand, store exponent in ST(0), and
push the significand onto the register
stack.

Vol. 2A 3-479
INSTRUCTION SET REFERENCE, A-M
FXTRACT—Extract Exponent and Significand
#IA Source operand is an SNaN value or unsupported format.
#Z ST(0) operand is ±0.
#D Source operand is a denormal value.
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.
3-480 Vol. 2A FYL2X—Compute y * log2x
INSTRUCTION SET REFERENCE, A-M
FYL2X—Compute y ∗ log2x
Description
Computes (ST(1) ∗ log2 (ST(0))), stores the result in resister ST(1), and pops the
FPU register stack. The source operand in ST(0) must be a non-zero positive number.
The following table shows the results obtained when taking the log of various classes
of numbers, assuming that neither overflow nor underflow occurs.
If the divide-by-zero exception is masked and register ST(0) contains ±0, the instruc-
tion returns ∞ with a sign that is the opposite of the sign of the source operand in
register ST(1).
The FYL2X instruction is designed with a built-in multiplication to optimize the calcu-
lation of logarithms with an arbitrary positive base (b):
logbx ← (log2b)–1 ∗ log2x
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D9 F1 FYL2X Valid Valid Replace ST(1) with (ST(1) ∗ log2ST(0))
and pop the register stack.
Table 3-58. FYL2X Results
ST(0)
-•−F±0 +0<+F<+1 + 1 + F > +
1
+•NaN
-• **+•+•*- •-•NaN
ST(1) −F**** + F− 0− F-•NaN
−0*** + 0− 0− 0*
NaN
+0*** − 0+ 0+ 0*
NaN
+F**** − F+ 0+ F+•NaN
+•**-•-•*+•+•NaN
NaN NaN NaN NaN NaN NaN NaN NaN NaN
NOTES:
F Means finite floating-point value.
* Indicates floating-point invalid-operation (#IA) exception.
** Indicates floating-point zero-divide (#Z) exception.

Vol. 2A 3-481
INSTRUCTION SET REFERENCE, A-M
FYL2X—Compute y * log2x
Operation
ST(1) ← ST(1) ∗ log2ST(0);
PopRegisterStack;
FPU Flags Affected
C1 Set to 0 if stack underflow occurred.
Set if result was rounded up; cleared otherwise.
C0, C2, C3 Undefined.
Floating-Point Exceptions
#IS Stack underflow occurred.
#IA Either operand is an SNaN or unsupported format.
Source operand in register ST(0) is a negative finite value
(not -0).
#Z Source operand in register ST(0) is ±0.
#D Source operand is a denormal value.
#U Result is too small for destination format.
#O Result is too large for destination format.
#P Value cannot be represented exactly in destination format.
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.
3-482 Vol. 2A FYL2XP1—Compute y * log2(x +1)
INSTRUCTION SET REFERENCE, A-M
FYL2XP1—Compute y ∗ log2(x +1)
Description
Computes (ST(1) ∗ log2(ST(0) + 1.0)), stores the result in register ST(1), and pops
the FPU register stack. The source operand in ST(0) must be in the range:
The source operand in ST(1) can range from −∞ to +∞. If the ST(0) operand is outside
of its acceptable range, the result is undefined and software should not rely on an
exception being generated. Under some circumstances exceptions may be generated
when ST(0) is out of range, but this behavior is implementation specific and not
guaranteed.
The following table shows the results obtained when taking the log epsilon of various
classes of numbers, assuming that underflow does not occur.
This instruction provides optimal accuracy for values of epsilon [the value in register
ST(0)] that are close to 0. For small epsilon (ε) values, more significant digits can be
retained by using the FYL2XP1 instruction than by using (ε+1) as an argument to the
FYL2X instruction. The (ε+1) expression is commonly found in compound interest and
annuity calculations. The result can be simply converted into a value in another loga-
rithm base by including a scale factor in the ST(1) source operand. The following
Opcode Instruction 64-Bit
Mode
Compat/
Leg Mode
Description
D9 F9 FYL2XP1 Valid Valid Replace ST(1) with ST(1) ∗ log2(ST(0) +
1.0) and pop the register stack.
Table 3-59. FYL2XP1 Results
ST(0)
−(1 − ( )) to −0-0 +0 +0 to +(1 - ())NaN
-•+•** -•NaN
ST(1) -F +F +0 -0 -F NaN
-0 +0 +0 -0 -0 NaN
+0 -0 -0 +0 +0 NaN
+F -F -0 +0 +F NaN
+•-•** +•NaN
NaN NaN NaN NaN NaN NaN
NOTES:
F Means finite floating-point value.
* Indicates floating-point invalid-operation (#IA) exception.
122⁄–())to 1 2 2⁄–()–
22⁄
22⁄

Vol. 2A 3-483
INSTRUCTION SET REFERENCE, A-M
FYL2XP1—Compute y * log2(x +1)
equation is used to calculate the scale factor for a particular logarithm base, where n
is the logarithm base desired for the result of the FYL2XP1 instruction:
scale factor ← logn 2
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
ST(1) ← ST(1) ∗ log2(ST(0) + 1.0);
PopRegisterStack;
FPU Flags Affected
C1 Set to 0 if stack underflow occurred.
Set if result was rounded up; cleared otherwise.
C0, C2, C3 Undefined.
Floating-Point Exceptions
#IS Stack underflow occurred.
#IA Either operand is an SNaN value or unsupported format.
#D Source operand is a denormal value.
#U Result is too small for destination format.
#O Result is too large for destination format.
#P Value cannot be represented exactly in destination format.
Protected Mode Exceptions
#NM CR0.EM[bit 2] or CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.
3-484 Vol. 2A HADDPD—Packed Double-FP Horizontal Add
INSTRUCTION SET REFERENCE, A-M
HADDPD—Packed Double-FP Horizontal Add
Instruction Operand Encoding
Description
Adds the double-precision floating-point values in the high and low quadwords of the
destination operand and stores the result in the low quadword of the destination
operand.
Adds the double-precision floating-point values in the high and low quadwords of the
source operand and stores the result in the high quadword of the destination operand.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
See Figure 3-19 for HADDPD; see Figure 3-20 for VHADDPD.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 7C /r
HADDPD xmm1, xmm2/m128
A V/V SSE3 Horizontal add packed
double-precision floating-
point values from
xmm2/m128 to xmm1.
VEX.NDS.128.66.0F.WIG 7C /r
VHADDPD xmm1,xmm2,
xmm3/m128
B V/V AVX Horizontal add packed
double-precision floating-
point values from xmm2 and
xmm3/mem.
VEX.NDS.256.66.0F.WIG 7C /r
VHADDPD ymm1, ymm2,
ymm3/m256
B V/V AVX Horizontal add packed
double-precision floating-
point values from ymm2 and
ymm3/mem.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA
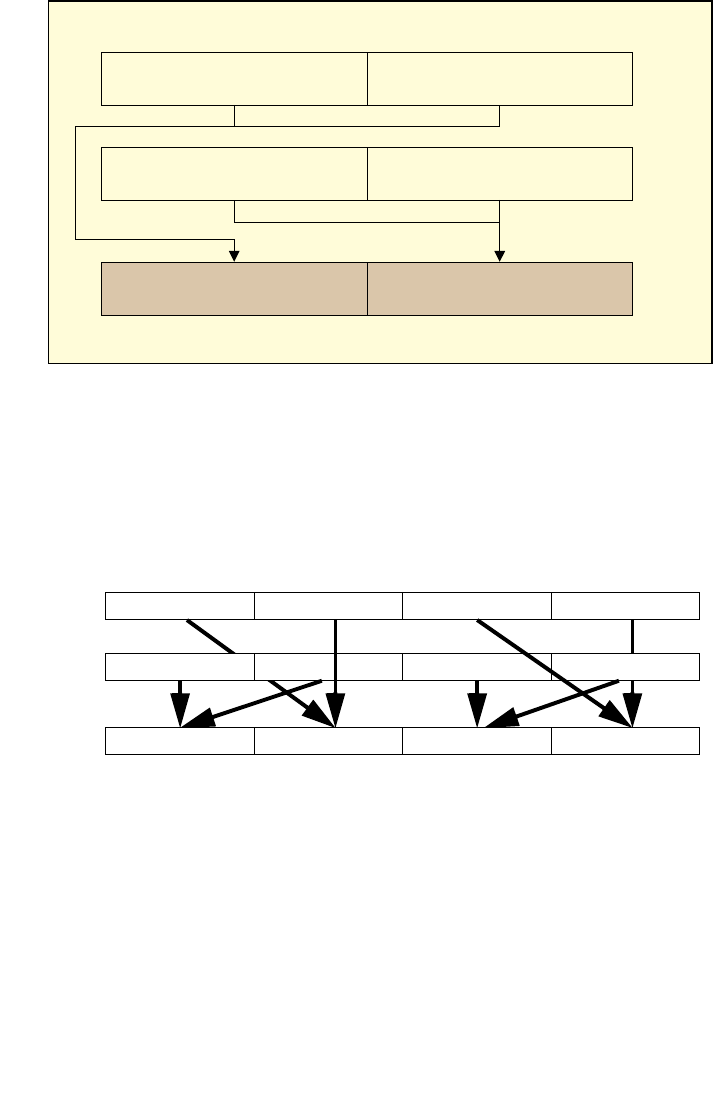
Vol. 2A 3-485
INSTRUCTION SET REFERENCE, A-M
HADDPD—Packed Double-FP Horizontal Add
Figure 3-20. VHADDPD operation
128-bit Legacy SSE version: The second source can be an XMM register or an 128-bit
memory location. The destination is not distinct from the first source XMM register
and the upper bits (VLMAX-1:128) of the corresponding YMM register destination are
unmodified.
Figure 3-19. HADDPD—Packed Double-FP Horizontal Add
20
+$''3'[PP[PPP
[PP
[PP
P
>@>@
>@ >@
>@>@
5HVXOW
[PP
[PPP>@
[PPP>@ [PP>@[PP>@
Y2 + Y3 X2 + X3 Y0 + Y1 X0 + X1DEST
X3 X2
SRC1 X1 X0
Y3 Y2 Y1 Y0
SRC2

3-486 Vol. 2A HADDPD—Packed Double-FP Horizontal Add
INSTRUCTION SET REFERENCE, A-M
VEX.128 encoded version: the first source operand is an XMM register or 128-bit
memory location. The destination operand is an XMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are zeroed.
VEX.256 encoded version: The first source operand is a YMM register. The second
source operand can be a YMM register or a 256-bit memory location. The destination
operand is a YMM register.
Operation
HADDPD (128-bit Legacy SSE version)
DEST[63:0] SRC1[127:64] + SRC1[63:0]
DEST[127:64] SRC2[127:64] + SRC2[63:0]
DEST[VLMAX-1:128] (Unmodified)
VHADDPD (VEX.128 encoded version)
DEST[63:0] SRC1[127:64] + SRC1[63:0]
DEST[127:64] SRC2[127:64] + SRC2[63:0]
DEST[VLMAX-1:128] 0
VHADDPD (VEX.256 encoded version)
DEST[63:0] SRC1[127:64] + SRC1[63:0]
DEST[127:64] SRC2[127:64] + SRC2[63:0]
DEST[191:128] SRC1[255:192] + SRC1[191:128]
DEST[255:192] SRC2[255:192] + SRC2[191:128]
Intel C/C++ Compiler Intrinsic Equivalent
VHADDPD __m256d _mm256_hadd_pd (__m256d a, __m256d b);
HADDPD __m128d _mm_hadd_pd (__m128d a, __m128d b);
Exceptions
When the source operand is a memory operand, the operand must be aligned on a
16-byte boundary or a general-protection exception (#GP) will be generated.
Numeric Exceptions
Overflow, Underflow, Invalid, Precision, Denormal.
Other Exceptions
See Exceptions Type 2.
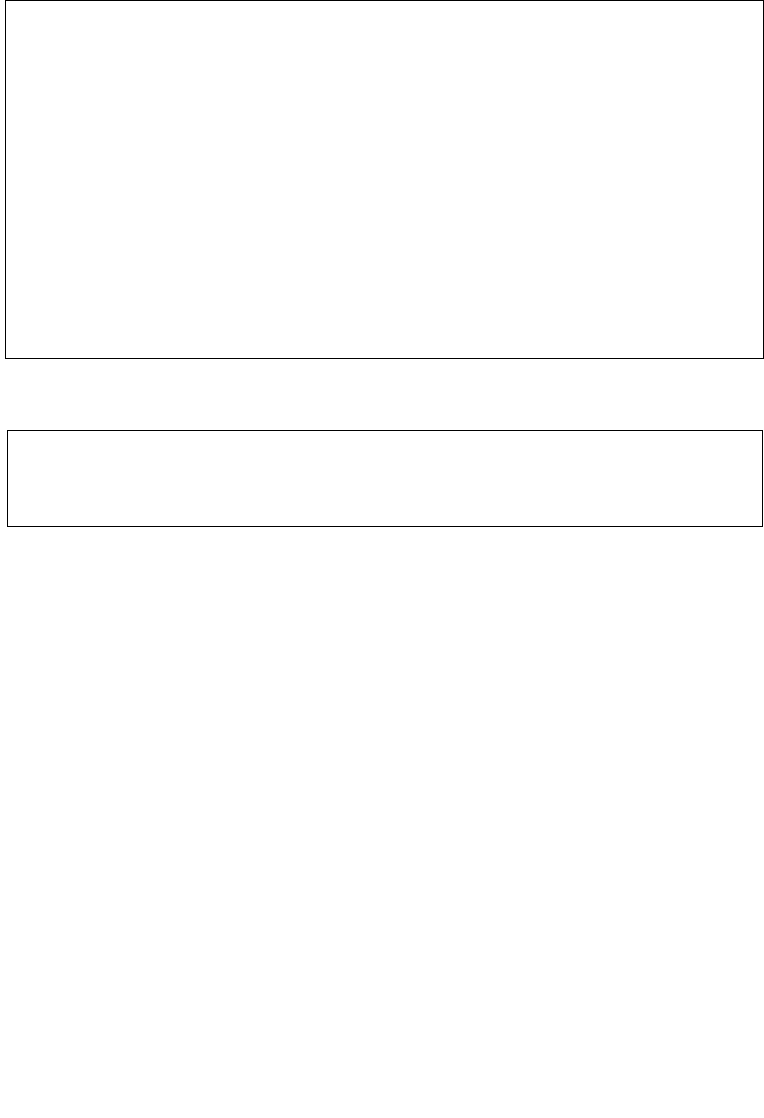
Vol. 2A 3-487
INSTRUCTION SET REFERENCE, A-M
HADDPS—Packed Single-FP Horizontal Add
HADDPS—Packed Single-FP Horizontal Add
Instruction Operand Encoding
Description
Adds the single-precision floating-point values in the first and second dwords of the
destination operand and stores the result in the first dword of the destination
operand.
Adds single-precision floating-point values in the third and fourth dword of the desti-
nation operand and stores the result in the second dword of the destination operand.
Adds single-precision floating-point values in the first and second dword of the
source operand and stores the result in the third dword of the destination operand.
Adds single-precision floating-point values in the third and fourth dword of the source
operand and stores the result in the fourth dword of the destination operand.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F2 0F 7C /r
HADDPS xmm1, xmm2/m128
AV/V SSE3 Horizontal add packed
single-precision floating-
point values from
xmm2/m128 to xmm1.
VEX.NDS.128.F2.0F.WIG 7C /r
VHADDPS xmm1, xmm2,
xmm3/m128
B V/V AVX Horizontal add packed
single-precision floating-
point values from xmm2 and
xmm3/mem.
VEX.NDS.256.F2.0F.WIG 7C /r
VHADDPS ymm1, ymm2,
ymm3/m256
B V/V AVX Horizontal add packed
single-precision floating-
point values from ymm2 and
ymm3/mem.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA
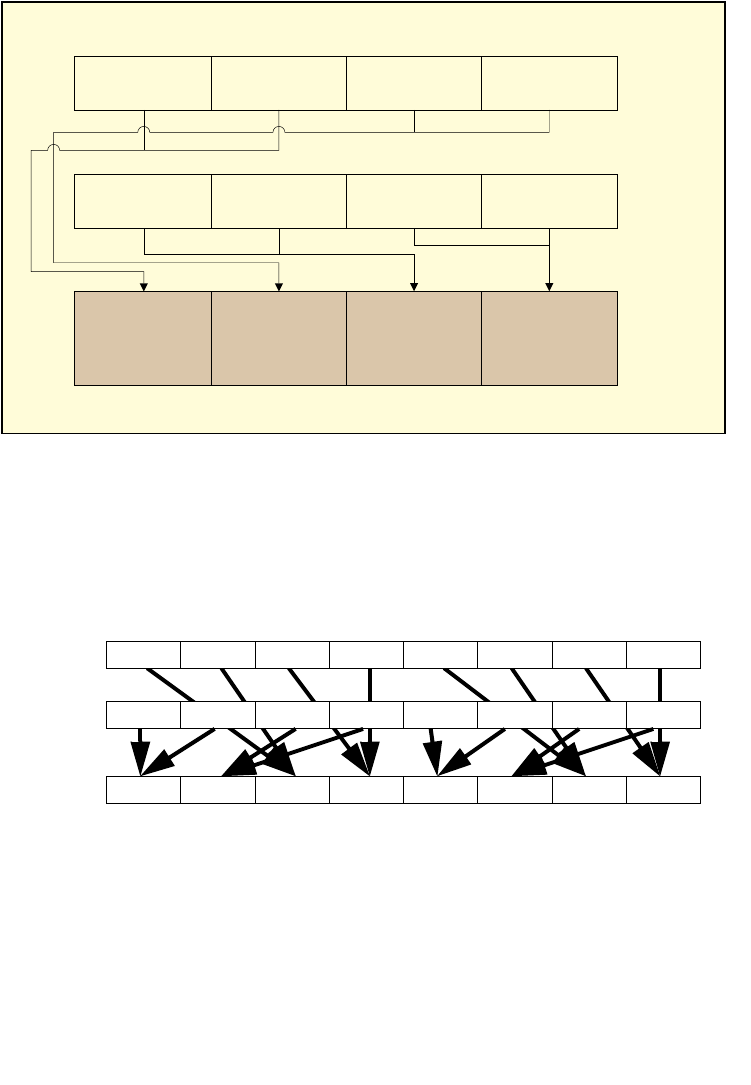
3-488 Vol. 2A HADDPS—Packed Single-FP Horizontal Add
INSTRUCTION SET REFERENCE, A-M
See Figure 3-21 for HADDPS; see Figure 3-22 for VHADDPS.
Figure 3-22. VHADDPS operation
Figure 3-21. HADDPS—Packed Single-FP Horizontal Add
20
+$''36[PP[PPP
5(68/7
[PP
[PP
P
[PP>@
[PP>@
>@
[PP>@
[PP>@
>@
>@ >@
[PP
>@>@
[PPP
>@[PP
P>@
>@
[PPP
>@[PP
P>@
>@
>@ >@
>@>@
Y6+Y7 X6+X7
Y2+Y3
X2+X3
DEST
SRC1 X0
SRC2
X1X2X3X4X5X6X7
Y0Y1Y2Y3Y4Y5Y6Y7
X0+X1
Y4+Y5 X4+X5
Y0+Y1

Vol. 2A 3-489
INSTRUCTION SET REFERENCE, A-M
HADDPS—Packed Single-FP Horizontal Add
128-bit Legacy SSE version: The second source can be an XMM register or an 128-bit
memory location. The destination is not distinct from the first source XMM register
and the upper bits (VLMAX-1:128) of the corresponding YMM register destination are
unmodified.
VEX.128 encoded version: the first source operand is an XMM register or 128-bit
memory location. The destination operand is an XMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are zeroed.
VEX.256 encoded version: The first source operand is a YMM register. The second
source operand can be a YMM register or a 256-bit memory location. The destination
operand is a YMM register.
Operation
HADDPS (128-bit Legacy SSE version)
DEST[31:0] SRC1[63:32] + SRC1[31:0]
DEST[63:32] SRC1[127:96] + SRC1[95:64]
DEST[95:64] SRC2[63:32] + SRC2[31:0]
DEST[127:96] SRC2[127:96] + SRC2[95:64]
DEST[VLMAX-1:128] (Unmodified)
VHADDPS (VEX.128 encoded version)
DEST[31:0] SRC1[63:32] + SRC1[31:0]
DEST[63:32] SRC1[127:96] + SRC1[95:64]
DEST[95:64] SRC2[63:32] + SRC2[31:0]
DEST[127:96] SRC2[127:96] + SRC2[95:64]
DEST[VLMAX-1:128] 0
VHADDPS (VEX.256 encoded version)
DEST[31:0] SRC1[63:32] + SRC1[31:0]
DEST[63:32] SRC1[127:96] + SRC1[95:64]
DEST[95:64] SRC2[63:32] + SRC2[31:0]
DEST[127:96] SRC2[127:96] + SRC2[95:64]
DEST[159:128] SRC1[191:160] + SRC1[159:128]
DEST[191:160] SRC1[255:224] + SRC1[223:192]
DEST[223:192] SRC2[191:160] + SRC2[159:128]
DEST[255:224] SRC2[255:224] + SRC2[223:192]
Intel C/C++ Compiler Intrinsic Equivalent
HADDPS __m128 _mm_hadd_ps (__m128 a, __m128 b);
VHADDPS __m256 _mm256_hadd_ps (__m256 a, __m256 b);

3-490 Vol. 2A HADDPS—Packed Single-FP Horizontal Add
INSTRUCTION SET REFERENCE, A-M
Exceptions
When the source operand is a memory operand, the operand must be aligned on a
16-byte boundary or a general-protection exception (#GP) will be generated.
Numeric Exceptions
Overflow, Underflow, Invalid, Precision, Denormal.
Other Exceptions
See Exceptions Type 2.

Vol. 2A 3-491
INSTRUCTION SET REFERENCE, A-M
HLT—Halt
HLT—Halt
Instruction Operand Encoding
Description
Stops instruction execution and places the processor in a HALT state. An enabled
interrupt (including NMI and SMI), a debug exception, the BINIT# signal, the INIT#
signal, or the RESET# signal will resume execution. If an interrupt (including NMI) is
used to resume execution after a HLT instruction, the saved instruction pointer
(CS:EIP) points to the instruction following the HLT instruction.
When a HLT instruction is executed on an Intel 64 or IA-32 processor supporting Intel
Hyper-Threading Technology, only the logical processor that executes the instruction
is halted. The other logical processors in the physical processor remain active, unless
they are each individually halted by executing a HLT instruction.
The HLT instruction is a privileged instruction. When the processor is running in
protected or virtual-8086 mode, the privilege level of a program or procedure must
be 0 to execute the HLT instruction.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
Enter Halt state;
Flags Affected
None.
Protected Mode Exceptions
#GP(0) If the current privilege level is not 0.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
None.
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
F4 HLT A Valid Valid Halt
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA

3-492 Vol. 2A HLT—Halt
INSTRUCTION SET REFERENCE, A-M
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.
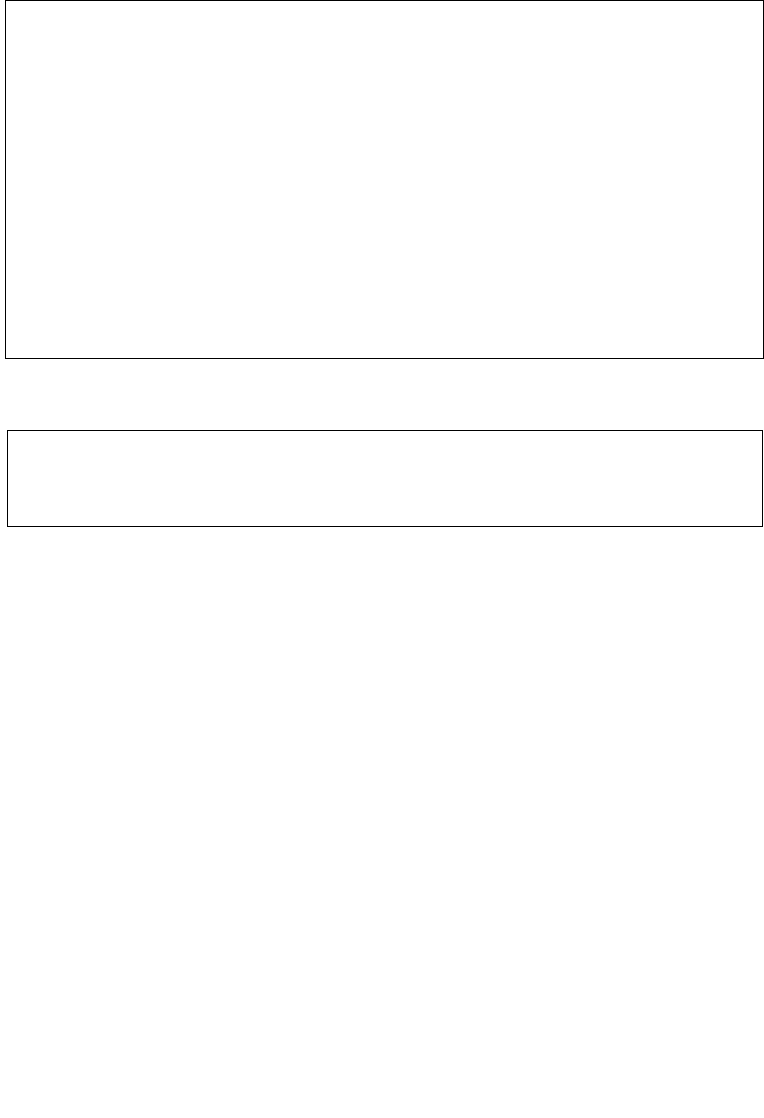
Vol. 2A 3-493
INSTRUCTION SET REFERENCE, A-M
HSUBPD—Packed Double-FP Horizontal Subtract
HSUBPD—Packed Double-FP Horizontal Subtract
Instruction Operand Encoding
Description
The HSUBPD instruction subtracts horizontally the packed DP FP numbers of both
operands.
Subtracts the double-precision floating-point value in the high quadword of the desti-
nation operand from the low quadword of the destination operand and stores the
result in the low quadword of the destination operand.
Subtracts the double-precision floating-point value in the high quadword of the
source operand from the low quadword of the source operand and stores the result in
the high quadword of the destination operand.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 7D /r
HSUBPD xmm1, xmm2/m128
A V/V SSE3 Horizontal subtract packed
double-precision floating-
point values from
xmm2/m128 to xmm1.
VEX.NDS.128.66.0F.WIG 7D /r
VHSUBPD xmm1,xmm2,
xmm3/m128
B V/V AVX Horizontal subtract packed
double-precision floating-
point values from xmm2 and
xmm3/mem.
VEX.NDS.256.66.0F.WIG 7D /r
VHSUBPD ymm1, ymm2,
ymm3/m256
B V/V AVX Horizontal subtract packed
double-precision floating-
point values from ymm2 and
ymm3/mem.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA
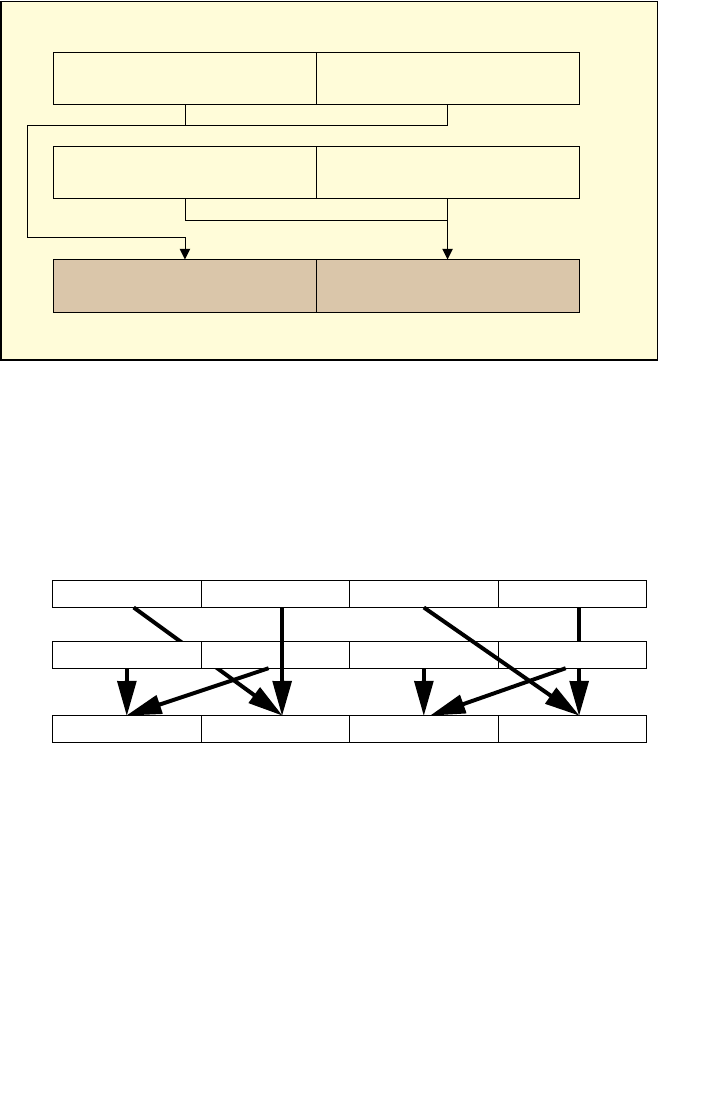
3-494 Vol. 2A HSUBPD—Packed Double-FP Horizontal Subtract
INSTRUCTION SET REFERENCE, A-M
See Figure 3-23 for HSUBPD; see Figure 3-24 for VHSUBPD.
Figure 3-24. VHSUBPD operation
128-bit Legacy SSE version: The second source can be an XMM register or an 128-bit
memory location. The destination is not distinct from the first source XMM register
and the upper bits (VLMAX-1:128) of the corresponding YMM register destination are
unmodified.
Figure 3-23. HSUBPD—Packed Double-FP Horizontal Subtract
20
+68%3'[PP[PPP
[PP
[PP
P
>@>@
>@ >@
>@>@
5HVXOW
[PP
[PPP>@
[PPP>@ [PP>@[PP>@
Y2 - Y3 X2 - X3 Y0 - Y1 X0 - X1DEST
X3 X2
SRC1 X1 X0
Y3 Y2 Y1 Y0
SRC2

Vol. 2A 3-495
INSTRUCTION SET REFERENCE, A-M
HSUBPD—Packed Double-FP Horizontal Subtract
VEX.128 encoded version: the first source operand is an XMM register or 128-bit
memory location. The destination operand is an XMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are zeroed.
VEX.256 encoded version: The first source operand is a YMM register. The second
source operand can be a YMM register or a 256-bit memory location. The destination
operand is a YMM register.
Operation
HSUBPD (128-bit Legacy SSE version)
DEST[63:0] SRC1[63:0] - SRC1[127:64]
DEST[127:64] SRC2[63:0] - SRC2[127:64]
DEST[VLMAX-1:128] (Unmodified)
VHSUBPD (VEX.128 encoded version)
DEST[63:0] SRC1[63:0] - SRC1[127:64]
DEST[127:64] SRC2[63:0] - SRC2[127:64]
DEST[VLMAX-1:128] 0
VHSUBPD (VEX.256 encoded version)
DEST[63:0] SRC1[63:0] - SRC1[127:64]
DEST[127:64] SRC2[63:0] - SRC2[127:64]
DEST[191:128] SRC1[191:128] - SRC1[255:192]
DEST[255:192] SRC2[191:128] - SRC2[255:192]
Intel C/C++ Compiler Intrinsic Equivalent
HSUBPD __m128d _mm_hsub_pd(__m128d a, __m128d b)
VHSUBPD __m256d _mm256_hsub_pd (__m256d a, __m256d b);
Exceptions
When the source operand is a memory operand, the operand must be aligned on a
16-byte boundary or a general-protection exception (#GP) will be generated.
Numeric Exceptions
Overflow, Underflow, Invalid, Precision, Denormal.
Other Exceptions
See Exceptions Type 2.
3-496 Vol. 2A HSUBPS—Packed Single-FP Horizontal Subtract
INSTRUCTION SET REFERENCE, A-M
HSUBPS—Packed Single-FP Horizontal Subtract
Instruction Operand Encoding
Description
Subtracts the single-precision floating-point value in the second dword of the desti-
nation operand from the first dword of the destination operand and stores the result
in the first dword of the destination operand.
Subtracts the single-precision floating-point value in the fourth dword of the destina-
tion operand from the third dword of the destination operand and stores the result in
the second dword of the destination operand.
Subtracts the single-precision floating-point value in the second dword of the source
operand from the first dword of the source operand and stores the result in the third
dword of the destination operand.
Subtracts the single-precision floating-point value in the fourth dword of the source
operand from the third dword of the source operand and stores the result in the
fourth dword of the destination operand.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
See Figure 3-25 for HSUBPS; see Figure 3-26 for VHSUBPS.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F2 0F 7D /r
HSUBPS xmm1, xmm2/m128
A V/V SSE3 Horizontal subtract packed
single-precision floating-
point values from
xmm2/m128 to xmm1.
VEX.NDS.128.F2.0F.WIG 7D /r
VHSUBPS xmm1, xmm2,
xmm3/m128
B V/V AVX Horizontal subtract packed
single-precision floating-
point values from xmm2 and
xmm3/mem.
VEX.NDS.256.F2.0F.WIG 7D /r
VHSUBPS ymm1, ymm2,
ymm3/m256
B V/V AVX Horizontal subtract packed
single-precision floating-
point values from ymm2 and
ymm3/mem.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA
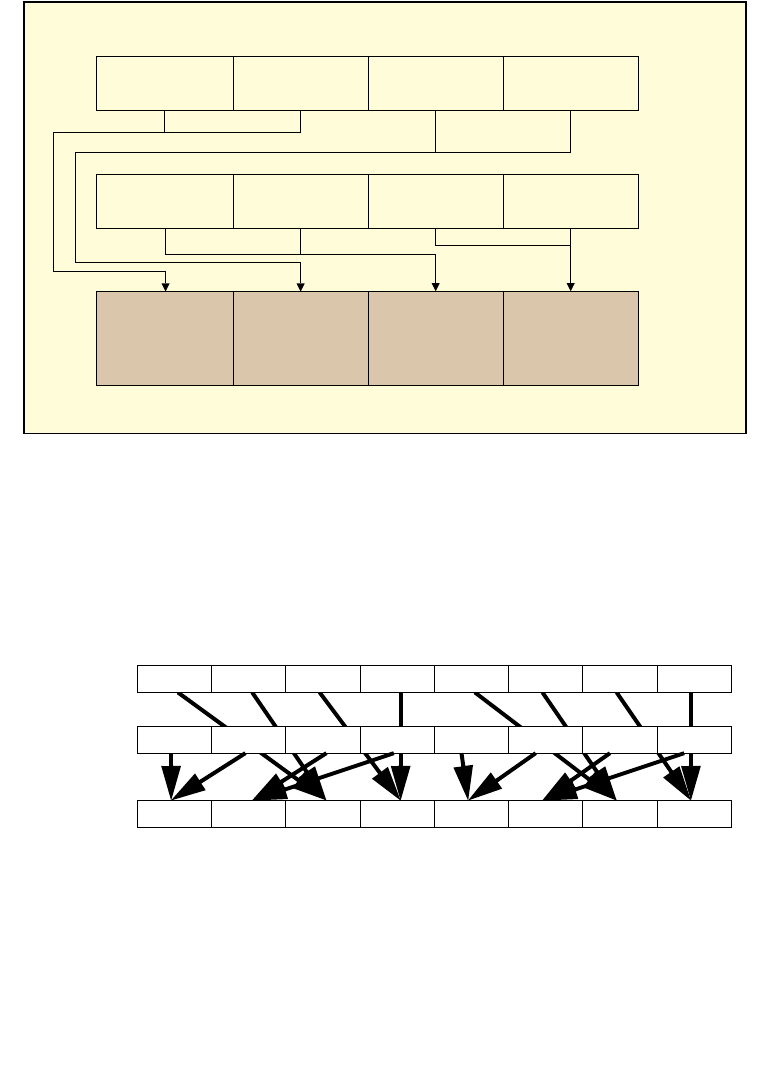
Vol. 2A 3-497
INSTRUCTION SET REFERENCE, A-M
HSUBPS—Packed Single-FP Horizontal Subtract
Figure 3-26. VHSUBPS operation
Figure 3-25. HSUBPS—Packed Single-FP Horizontal Subtract
20
+68%36[PP[PPP
5(68/7
[PP
[PP
P
[PP>@
[PP>@
>@
[PP>@
[PP>@
>@
>@ >@
[PP
>@>@
[PPP
>@[PP
P>@
>@
[PPP
>@[PP
P>@
>@
>@ >@
>@>@
Y6-Y7 X6-X7
Y2-Y3
X2-X3
DEST
SRC1 X0
SRC2
X1X2X3X4X5X6X7
Y0Y1Y2Y3Y4Y5Y6Y7
X0-X1
Y4-Y5 X4-X5
Y0-Y1

3-498 Vol. 2A HSUBPS—Packed Single-FP Horizontal Subtract
INSTRUCTION SET REFERENCE, A-M
128-bit Legacy SSE version: The second source can be an XMM register or an 128-bit
memory location. The destination is not distinct from the first source XMM register
and the upper bits (VLMAX-1:128) of the corresponding YMM register destination are
unmodified.
VEX.128 encoded version: the first source operand is an XMM register or 128-bit
memory location. The destination operand is an XMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are zeroed.
VEX.256 encoded version: The first source operand is a YMM register. The second
source operand can be a YMM register or a 256-bit memory location. The destination
operand is a YMM register.
Operation
HSUBPS (128-bit Legacy SSE version)
DEST[31:0] SRC1[31:0] - SRC1[63:32]
DEST[63:32] SRC1[95:64] - SRC1[127:96]
DEST[95:64] SRC2[31:0] - SRC2[63:32]
DEST[127:96] SRC2[95:64] - SRC2[127:96]
DEST[VLMAX-1:128] (Unmodified)
VHSUBPS (VEX.128 encoded version)
DEST[31:0] SRC1[31:0] - SRC1[63:32]
DEST[63:32] SRC1[95:64] - SRC1[127:96]
DEST[95:64] SRC2[31:0] - SRC2[63:32]
DEST[127:96] SRC2[95:64] - SRC2[127:96]
DEST[VLMAX-1:128] 0
VHSUBPS (VEX.256 encoded version)
DEST[31:0] SRC1[31:0] - SRC1[63:32]
DEST[63:32] SRC1[95:64] - SRC1[127:96]
DEST[95:64] SRC2[31:0] - SRC2[63:32]
DEST[127:96] SRC2[95:64] - SRC2[127:96]
DEST[159:128] SRC1[159:128] - SRC1[191:160]
DEST[191:160] SRC1[223:192] - SRC1[255:224]
DEST[223:192] SRC2[159:128] - SRC2[191:160]
DEST[255:224] SRC2[223:192] - SRC2[255:224]
Intel C/C++ Compiler Intrinsic Equivalent
HSUBPS __m128 _mm_hsub_ps(__m128 a, __m128 b);
VHSUBPS __m256 _mm256_hsub_ps (__m256 a, __m256 b);

Vol. 2A 3-499
INSTRUCTION SET REFERENCE, A-M
HSUBPS—Packed Single-FP Horizontal Subtract
Exceptions
When the source operand is a memory operand, the operand must be aligned on a
16-byte boundary or a general-protection exception (#GP) will be generated.
Numeric Exceptions
Overflow, Underflow, Invalid, Precision, Denormal.
Other Exceptions
See Exceptions Type 2.
3-500 Vol. 2A IDIV—Signed Divide
INSTRUCTION SET REFERENCE, A-M
IDIV—Signed Divide
Instruction Operand Encoding
Description
Divides the (signed) value in the AX, DX:AX, or EDX:EAX (dividend) by the source
operand (divisor) and stores the result in the AX (AH:AL), DX:AX, or EDX:EAX regis-
ters. The source operand can be a general-purpose register or a memory location.
The action of this instruction depends on the operand size (dividend/divisor).
Non-integral results are truncated (chopped) towards 0. The remainder is always less
than the divisor in magnitude. Overflow is indicated with the #DE (divide error)
exception rather than with the CF flag.
In 64-bit mode, the instruction’s default operation size is 32 bits. Use of the REX.R
prefix permits access to additional registers (R8-R15). Use of the REX.W prefix
promotes operation to 64 bits. In 64-bit mode when REX.W is applied, the instruction
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
F6 /7 IDIV r/m8 A Valid Valid Signed divide AX by r/m8,
with result stored in: AL ←
Quotient, AH ← Remainder.
REX + F6 /7 IDIV r/m8* A Valid N.E. Signed divide AX by r/m8,
with result stored in AL ←
Quotient, AH ← Remainder.
F7 /7 IDIV r/m16 A Valid Valid Signed divide DX:AX by
r/m16, with result stored in
AX ← Quotient, DX ←
Remainder.
F7 /7 IDIV r/m32 A Valid Valid Signed divide EDX:EAX by
r/m32, with result stored in
EAX ← Quotient, EDX ←
Remainder.
REX.W + F7 /7 IDIV r/m64 A Valid N.E. Signed divide RDX:RAX by
r/m64, with result stored in
RAX ← Quotient, RDX ←
Remainder.
NOTES:
* In 64-bit mode, r/m8 can not be encoded to access the following byte registers if a REX prefix is
used: AH, BH, CH, DH.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (r) NA NA NA
Vol. 2A 3-501
INSTRUCTION SET REFERENCE, A-M
IDIV—Signed Divide
divides the signed value in RDX:RAX by the source operand. RAX contains a 64-bit
quotient; RDX contains a 64-bit remainder.
See the summary chart at the beginning of this section for encoding data and limits.
See Table 3-60.
Operation
IF SRC = 0
THEN #DE; (* Divide error *)
FI;
IF OperandSize = 8 (* Word/byte operation *)
THEN
temp ← AX / SRC; (* Signed division *)
IF (temp > 7FH) or (temp < 80H)
(* If a positive result is greater than 7FH or a negative result is less than 80H *)
THEN #DE; (* Divide error *)
ELSE
AL ← temp;
AH ← AX SignedModulus SRC;
FI;
ELSE IF OperandSize = 16 (* Doubleword/word operation *)
THEN
temp ← DX:AX / SRC; (* Signed division *)
IF (temp > 7FFFH) or (temp < 8000H)
(* If a positive result is greater than 7FFFH
or a negative result is less than 8000H *)
THEN
#DE; (* Divide error *)
ELSE
AX ← temp;
DX ← DX:AX SignedModulus SRC;
FI;
FI;
Table 3-60. IDIV Results
Operand Size Dividend Divisor Quotient Remainder Quotient Range
Word/byte AX r/m8 AL AH −128 to +127
Doubleword/word DX:AX r/m16 AX DX −32,768 to
+32,767
Quadword/doubleword EDX:EAX r/m32 EAX EDX −231 to 232 − 1
Doublequadword/
quadword
RDX:RAX r/m64 RAX RDX −263 to 264 − 1

3-502 Vol. 2A IDIV—Signed Divide
INSTRUCTION SET REFERENCE, A-M
ELSE IF OperandSize = 32 (* Quadword/doubleword operation *)
temp ← EDX:EAX / SRC; (* Signed division *)
IF (temp > 7FFFFFFFH) or (temp < 80000000H)
(* If a positive result is greater than 7FFFFFFFH
or a negative result is less than 80000000H *)
THEN
#DE; (* Divide error *)
ELSE
EAX ← temp;
EDX ← EDXE:AX SignedModulus SRC;
FI;
FI;
ELSE IF OperandSize = 64 (* Doublequadword/quadword operation *)
temp ← RDX:RAX / SRC; (* Signed division *)
IF (temp > 7FFFFFFFFFFFH) or (temp < 8000000000000000H)
(* If a positive result is greater than 7FFFFFFFFFFFH
or a negative result is less than 8000000000000000H *)
THEN
#DE; (* Divide error *)
ELSE
RAX ← temp;
RDX ← RDE:RAX SignedModulus SRC;
FI;
FI;
FI;
Flags Affected
The CF, OF, SF, ZF, AF, and PF flags are undefined.
Protected Mode Exceptions
#DE If the source operand (divisor) is 0.
The signed result (quotient) is too large for the destination.
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register is used to access memory and it
contains a NULL segment selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.

Vol. 2A 3-503
INSTRUCTION SET REFERENCE, A-M
IDIV—Signed Divide
Real-Address Mode Exceptions
#DE If the source operand (divisor) is 0.
The signed result (quotient) is too large for the destination.
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#DE If the source operand (divisor) is 0.
The signed result (quotient) is too large for the destination.
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#DE If the source operand (divisor) is 0
If the quotient is too large for the designated register.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.

3-504 Vol. 2A IMUL—Signed Multiply
INSTRUCTION SET REFERENCE, A-M
IMUL—Signed Multiply
Instruction Operand Encoding
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
F6 /5 IMUL r/m8* AValid Valid AX← AL ∗ r/m byte.
F7 /5 IMUL r/m16 AValid Valid DX:AX ← AX ∗ r/m word.
F7 /5 IMUL r/m32 AValid Valid EDX:EAX ← EAX ∗ r/m32.
REX.W + F7 /5 IMUL r/m64 A Valid N.E. RDX:RAX ← RAX ∗ r/m64.
0F AF /rIMUL r16, r/m16 BValid Valid word register ← word
register ∗ r/m16.
0F AF /rIMUL r32, r/m32 B Valid Valid doubleword register ←
doubleword register ∗
r/m32.
REX.W + 0F AF
/r
IMUL r64, r/m64 B Valid N.E. Quadword register ←
Quadword register ∗ r/m64.
6B /r ib IMUL r16, r/m16,
imm8
CValid Valid word register ← r/m16 ∗
sign-extended immediate
byte.
6B /r ib IMUL r32, r/m32,
imm8
C Valid Valid doubleword register ←
r/m32 ∗ sign-extended
immediate byte.
REX.W + 6B /r ib IMUL r64, r/m64,
imm8
C Valid N.E. Quadword register ← r/m64
∗ sign-extended immediate
byte.
69 /r iw IMUL r16, r/m16,
imm16
CValid Valid word register ← r/m16 ∗
immediate word.
69 /r id IMUL r32, r/m32,
imm32
C Valid Valid doubleword register ←
r/m32 ∗ immediate
doubleword.
REX.W + 69 /r id IMUL r64, r/m64,
imm32
C Valid N.E. Quadword register ← r/m64
∗ immediate doubleword.
NOTES:
* In 64-bit mode, r/m8 can not be encoded to access the following byte registers if a REX prefix is
used: AH, BH, CH, DH.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (r, w) NA NA NA
B ModRM:reg (r, w) ModRM:r/m (r) NA NA

Vol. 2A 3-505
INSTRUCTION SET REFERENCE, A-M
IMUL—Signed Multiply
Description
Performs a signed multiplication of two operands. This instruction has three forms,
depending on the number of operands.
•One-operand form — This form is identical to that used by the MUL instruction.
Here, the source operand (in a general-purpose register or memory location) is
multiplied by the value in the AL, AX, EAX, or RAX register (depending on the
operand size) and the product is stored in the AX, DX:AX, EDX:EAX, or RDX:RAX
registers, respectively.
•Two-operand form — With this form the destination operand (the first
operand) is multiplied by the source operand (second operand). The destination
operand is a general-purpose register and the source operand is an immediate
value, a general-purpose register, or a memory location. The product is then
stored in the destination operand location.
•Three-operand form — This form requires a destination operand (the first
operand) and two source operands (the second and the third operands). Here,
the first source operand (which can be a general-purpose register or a memory
location) is multiplied by the second source operand (an immediate value). The
product is then stored in the destination operand (a general-purpose register).
When an immediate value is used as an operand, it is sign-extended to the length of
the destination operand format.
The CF and OF flags are set when significant bit (including the sign bit) are carried
into the upper half of the result. The CF and OF flags are cleared when the result
(including the sign bit) fits exactly in the lower half of the result.
The three forms of the IMUL instruction are similar in that the length of the product
is calculated to twice the length of the operands. With the one-operand form, the
product is stored exactly in the destination. With the two- and three- operand forms,
however, the result is truncated to the length of the destination before it is stored in
the destination register. Because of this truncation, the CF or OF flag should be tested
to ensure that no significant bits are lost.
The two- and three-operand forms may also be used with unsigned operands
because the lower half of the product is the same regardless if the operands are
signed or unsigned. The CF and OF flags, however, cannot be used to determine if the
upper half of the result is non-zero.
In 64-bit mode, the instruction’s default operation size is 32 bits. Use of the REX.R
prefix permits access to additional registers (R8-R15). Use of the REX.W prefix
promotes operation to 64 bits. Use of REX.W modifies the three forms of the instruc-
tion as follows.
C ModRM:reg (r, w) ModRM:r/m (r) imm8/16/32 NA
Op/En Operand 1 Operand 2 Operand 3 Operand 4

3-506 Vol. 2A IMUL—Signed Multiply
INSTRUCTION SET REFERENCE, A-M
•One-operand form —The source operand (in a 64-bit general-purpose register or
memory location) is multiplied by the value in the RAX register and the product is
stored in the RDX:RAX registers.
•Two-operand form — The source operand is promoted to 64 bits if it is a
register or a memory location. If the source operand is an immediate, it is sign
extended to 64 bits. The destination operand is promoted to 64 bits.
•Three-operand form — The first source operand (either a register or a memory
location) and destination operand are promoted to 64 bits.
Operation
IF (NumberOfOperands = 1)
THEN IF (OperandSize = 8)
THEN
AX ← AL ∗ SRC (* Signed multiplication *)
IF AL = AX
THEN CF ← 0; OF ← 0;
ELSE CF ← 1; OF ← 1; FI;
ELSE IF OperandSize = 16
THEN
DX:AX ← AX ∗ SRC (* Signed multiplication *)
IF sign_extend_to_32 (AX) = DX:AX
THEN CF ← 0; OF ← 0;
ELSE CF ← 1; OF ← 1; FI;
ELSE IF OperandSize = 32
THEN
EDX:EAX ← EAX ∗ SRC (* Signed multiplication *)
IF EAX = EDX:EAX
THEN CF ← 0; OF ← 0;
ELSE CF ← 1; OF ← 1; FI;
ELSE (* OperandSize = 64 *)
RDX:RAX ← RAX ∗ SRC (* Signed multiplication *)
IF RAX = RDX:RAX
THEN CF ← 0; OF ← 0;
ELSE CF ← 1; OF ← 1; FI;
FI;
FI;
ELSE IF (NumberOfOperands = 2)
THEN
temp ← DEST ∗ SRC (* Signed multiplication; temp is double DEST size *)
DEST ← DEST ∗ SRC (* Signed multiplication *)
IF temp ≠ DEST
THEN CF ← 1; OF ← 1;
ELSE CF ← 0; OF ← 0; FI;

Vol. 2A 3-507
INSTRUCTION SET REFERENCE, A-M
IMUL—Signed Multiply
ELSE (* NumberOfOperands = 3 *)
DEST ← SRC1 ∗ SRC2 (* Signed multiplication *)
temp ← SRC1 ∗ SRC2 (* Signed multiplication; temp is double SRC1 size *)
IF temp ≠ DEST
THEN CF ← 1; OF ← 1;
ELSE CF ← 0; OF ← 0; FI;
FI;
FI;
Flags Affected
For the one operand form of the instruction, the CF and OF flags are set when signif-
icant bits are carried into the upper half of the result and cleared when the result fits
exactly in the lower half of the result. For the two- and three-operand forms of the
instruction, the CF and OF flags are set when the result must be truncated to fit in the
destination operand size and cleared when the result fits exactly in the destination
operand size. The SF, ZF, AF, and PF flags are undefined.
Protected Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register is used to access memory and it
contains a NULL NULL segment selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.

3-508 Vol. 2A IMUL—Signed Multiply
INSTRUCTION SET REFERENCE, A-M
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.

Vol. 2A 3-509
INSTRUCTION SET REFERENCE, A-M
IN—Input from Port
IN—Input from Port
Instruction Operand Encoding
Description
Copies the value from the I/O port specified with the second operand (source
operand) to the destination operand (first operand). The source operand can be a
byte-immediate or the DX register; the destination operand can be register AL, AX,
or EAX, depending on the size of the port being accessed (8, 16, or 32 bits, respec-
tively). Using the DX register as a source operand allows I/O port addresses from 0
to 65,535 to be accessed; using a byte immediate allows I/O port addresses 0 to 255
to be accessed.
When accessing an 8-bit I/O port, the opcode determines the port size; when
accessing a 16- and 32-bit I/O port, the operand-size attribute determines the port
size. At the machine code level, I/O instructions are shorter when accessing 8-bit I/O
ports. Here, the upper eight bits of the port address will be 0.
This instruction is only useful for accessing I/O ports located in the processor’s I/O
address space. See Chapter 13, “Input/Output,” in the Intel® 64 and IA-32 Architec-
tures Software Developer’s Manual, Volume 1, for more information on accessing I/O
ports in the I/O address space.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
E4 ib IN AL, imm8 A Valid Valid Input byte from imm8 I/O
port address into AL.
E5 ib IN AX, imm8 A Valid Valid Input word from imm8 I/O
port address into AX.
E5 ib IN EAX, imm8 A Valid Valid Input dword from imm8 I/O
port address into EAX.
EC IN AL,DX B Valid Valid Input byte from I/O port in
DX into AL.
ED IN AX,DX B Valid Valid Input word from I/O port in
DX into AX.
ED IN EAX,DX B Valid Valid Input doubleword from I/O
port in DX into EAX.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
Aimm8 NA NA NA
BNA NA NA NA

3-510 Vol. 2A IN—Input from Port
INSTRUCTION SET REFERENCE, A-M
Operation
IF ((PE = 1) and ((CPL > IOPL) or (VM = 1)))
THEN (* Protected mode with CPL > IOPL or virtual-8086 mode *)
IF (Any I/O Permission Bit for I/O port being accessed = 1)
THEN (* I/O operation is not allowed *)
#GP(0);
ELSE ( * I/O operation is allowed *)
DEST ← SRC; (* Read from selected I/O port *)
FI;
ELSE (Real Mode or Protected Mode with CPL ≤ IOPL *)
DEST ← SRC; (* Read from selected I/O port *)
FI;
Flags Affected
None.
Protected Mode Exceptions
#GP(0) If the CPL is greater than (has less privilege) the I/O privilege
level (IOPL) and any of the corresponding I/O permission bits in
TSS for the I/O port being accessed is 1.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If any of the I/O permission bits in the TSS for the I/O port being
accessed is 1.
#PF(fault-code) If a page fault occurs.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#GP(0) If the CPL is greater than (has less privilege) the I/O privilege
level (IOPL) and any of the corresponding I/O permission bits in
TSS for the I/O port being accessed is 1.
#UD If the LOCK prefix is used.

Vol. 2A 3-511
INSTRUCTION SET REFERENCE, A-M
INC—Increment by 1
INC—Increment by 1
Instruction Operand Encoding
Description
Adds 1 to the destination operand, while preserving the state of the CF flag. The
destination operand can be a register or a memory location. This instruction allows a
loop counter to be updated without disturbing the CF flag. (Use a ADD instruction
with an immediate operand of 1 to perform an increment operation that does updates
the CF flag.)
This instruction can be used with a LOCK prefix to allow the instruction to be
executed atomically.
In 64-bit mode, INC r16 and INC r32 are not encodable (because opcodes 40H
through 47H are REX prefixes). Otherwise, the instruction’s 64-bit mode default
operation size is 32 bits. Use of the REX.R prefix permits access to additional regis-
ters (R8-R15). Use of the REX.W prefix promotes operation to 64 bits.
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
FE /0 INC r/m8 AValid Valid Increment r/m byte by 1.
REX + FE /0 INC r/m8*A Valid N.E. Increment r/m byte by 1.
FF /0 INC r/m16 AValid Valid Increment r/m word by 1.
FF /0 INC r/m32 AValid Valid Increment r/m doubleword
by 1.
REX.W + FF /0 INC r/m64 A Valid N.E. Increment r/m quadword by
1.
40+ rw** INC r16 B N.E. Valid Increment word register by
1.
40+ rd INC r32 B N.E. Valid Increment doubleword
register by 1.
NOTES:
* In 64-bit mode, r/m8 can not be encoded to access the following byte registers if a REX prefix is
used: AH, BH, CH, DH.
** 40H through 47H are REX prefixes in 64-bit mode.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (r, w) NA NA NA
B reg (r, w) NA NA NA

3-512 Vol. 2A INC—Increment by 1
INSTRUCTION SET REFERENCE, A-M
Operation
DEST ← DEST + 1;
AFlags Affected
The CF flag is not affected. The OF, SF, ZF, AF, and PF flags are set according to the
result.
Protected Mode Exceptions
#GP(0) If the destination operand is located in a non-writable segment.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register is used to access memory and it
contains a NULLsegment selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used but the destination is not a memory
operand.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#UD If the LOCK prefix is used but the destination is not a memory
operand.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used but the destination is not a memory
operand.

Vol. 2A 3-513
INSTRUCTION SET REFERENCE, A-M
INC—Increment by 1
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used but the destination is not a memory
operand.
3-514 Vol. 2A INS/INSB/INSW/INSD—Input from Port to String
INSTRUCTION SET REFERENCE, A-M
INS/INSB/INSW/INSD—Input from Port to String
Instruction Operand Encoding
Description
Copies the data from the I/O port specified with the source operand (second
operand) to the destination operand (first operand). The source operand is an I/O
port address (from 0 to 65,535) that is read from the DX register. The destination
operand is a memory location, the address of which is read from either the ES:DI,
ES:EDI or the RDI registers (depending on the address-size attribute of the instruc-
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
6C INS m8, DX A Valid Valid Input byte from I/O port
specified in DX into memory
location specified in ES:(E)DI
or RDI.*
6D INS m16, DX A Valid Valid Input word from I/O port
specified in DX into memory
location specified in ES:(E)DI
or RDI.1
6D INS m32, DX A Valid Valid Input doubleword from I/O
port specified in DX into
memory location specified in
ES:(E)DI or RDI.1
6C INSB A Valid Valid Input byte from I/O port
specified in DX into memory
location specified with
ES:(E)DI or RDI.1
6D INSW A Valid Valid Input word from I/O port
specified in DX into memory
location specified in ES:(E)DI
or RDI.1
6D INSD A Valid Valid Input doubleword from I/O
port specified in DX into
memory location specified in
ES:(E)DI or RDI.1
NOTES:
* In 64-bit mode, only 64-bit (RDI) and 32-bit (EDI) address sizes are supported. In non-64-bit
mode, only 32-bit (EDI) and 16-bit (DI) address sizes are supported.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA

Vol. 2A 3-515
INSTRUCTION SET REFERENCE, A-M
INS/INSB/INSW/INSD—Input from Port to String
tion, 16, 32 or 64, respectively). (The ES segment cannot be overridden with a
segment override prefix.) The size of the I/O port being accessed (that is, the size of
the source and destination operands) is determined by the opcode for an 8-bit I/O
port or by the operand-size attribute of the instruction for a 16- or 32-bit I/O port.
At the assembly-code level, two forms of this instruction are allowed: the “explicit-
operands” form and the “no-operands” form. The explicit-operands form (specified
with the INS mnemonic) allows the source and destination operands to be specified
explicitly. Here, the source operand must be “DX,” and the destination operand
should be a symbol that indicates the size of the I/O port and the destination
address. This explicit-operands form is provided to allow documentation; however,
note that the documentation provided by this form can be misleading. That is, the
destination operand symbol must specify the correct type (size) of the operand
(byte, word, or doubleword), but it does not have to specify the correct location.
The location is always specified by the ES:(E)DI registers, which must be loaded
correctly before the INS instruction is executed.
The no-operands form provides “short forms” of the byte, word, and doubleword
versions of the INS instructions. Here also DX is assumed by the processor to be the
source operand and ES:(E)DI is assumed to be the destination operand. The size of
the I/O port is specified with the choice of mnemonic: INSB (byte), INSW (word), or
INSD (doubleword).
After the byte, word, or doubleword is transfer from the I/O port to the memory loca-
tion, the DI/EDI/RDI register is incremented or decremented automatically according
to the setting of the DF flag in the EFLAGS register. (If the DF flag is 0, the (E)DI
register is incremented; if the DF flag is 1, the (E)DI register is decremented.) The
(E)DI register is incremented or decremented by 1 for byte operations, by 2 for word
operations, or by 4 for doubleword operations.
The INS, INSB, INSW, and INSD instructions can be preceded by the REP prefix for
block input of ECX bytes, words, or doublewords. See “REP/REPE/REPZ
/REPNE/REPNZ—Repeat String Operation Prefix” in Chapter 4 of the Intel® 64 and
IA-32 Architectures Software Developer’s Manual, Volume 2B, for a description of the
REP prefix.
These instructions are only useful for accessing I/O ports located in the processor’s
I/O address space. See Chapter 13, “Input/Output,” in the Intel® 64 and IA-32
Architectures Software Developer’s Manual, Volume 1, for more information on
accessing I/O ports in the I/O address space.
In 64-bit mode, default address size is 64 bits, 32 bit address size is supported using
the prefix 67H. The address of the memory destination is specified by RDI or EDI.
16-bit address size is not supported in 64-bit mode. The operand size is not
promoted.
Operation
IF ((PE = 1) and ((CPL > IOPL) or (VM = 1)))
THEN (* Protected mode with CPL > IOPL or virtual-8086 mode *)

3-516 Vol. 2A INS/INSB/INSW/INSD—Input from Port to String
INSTRUCTION SET REFERENCE, A-M
IF (Any I/O Permission Bit for I/O port being accessed = 1)
THEN (* I/O operation is not allowed *)
#GP(0);
ELSE (* I/O operation is allowed *)
DEST ← SRC; (* Read from I/O port *)
FI;
ELSE (Real Mode or Protected Mode with CPL IOPL *)
DEST ← SRC; (* Read from I/O port *)
FI;
Non-64-bit Mode:
IF (Byte transfer)
THEN IF DF = 0
THEN (E)DI ← (E)DI + 1;
ELSE (E)DI ← (E)DI – 1; FI;
ELSE IF (Word transfer)
THEN IF DF = 0
THEN (E)DI ← (E)DI + 2;
ELSE (E)DI ← (E)DI – 2; FI;
ELSE (* Doubleword transfer *)
THEN IF DF = 0
THEN (E)DI ← (E)DI + 4;
ELSE (E)DI ← (E)DI – 4; FI;
FI;
FI;
FI64-bit Mode:
IF (Byte transfer)
THEN IF DF = 0
THEN (E|R)DI ← (E|R)DI + 1;
ELSE (E|R)DI ← (E|R)DI – 1; FI;
ELSE IF (Word transfer)
THEN IF DF = 0
THEN (E)DI ← (E)DI + 2;
ELSE (E)DI ← (E)DI – 2; FI;
ELSE (* Doubleword transfer *)
THEN IF DF = 0
THEN (E|R)DI ← (E|R)DI + 4;
ELSE (E|R)DI ← (E|R)DI – 4; FI;
FI;
FI;

Vol. 2A 3-517
INSTRUCTION SET REFERENCE, A-M
INS/INSB/INSW/INSD—Input from Port to String
Flags Affected
None.
Protected Mode Exceptions
#GP(0) If the CPL is greater than (has less privilege) the I/O privilege
level (IOPL) and any of the corresponding I/O permission bits in
TSS for the I/O port being accessed is 1.
If the destination is located in a non-writable segment.
If an illegal memory operand effective address in the ES
segments is given.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If any of the I/O permission bits in the TSS for the I/O port being
accessed is 1.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the CPL is greater than (has less privilege) the I/O privilege
level (IOPL) and any of the corresponding I/O permission bits in
TSS for the I/O port being accessed is 1.
If the memory address is in a non-canonical form.

3-518 Vol. 2A INS/INSB/INSW/INSD—Input from Port to String
INSTRUCTION SET REFERENCE, A-M
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.

Vol. 2A 3-519
INSTRUCTION SET REFERENCE, A-M
VINSERTF128 — Insert Packed Floating-Point Values
VINSERTF128 — Insert Packed Floating-Point Values
Instruction Operand Encoding
Description
Performs an insertion of 128-bits of packed floating-point values from the second
source operand (third operand) into an the destination operand (first operand) at an
128-bit offset from imm8[0]. The remaining portions of the destination are written
by the corresponding fields of the first source operand (second operand). The second
source operand can be either an XMM register or a 128-bit memory location.
The high 7 bits of the immediate are ignored.
Operation
TEMP[255:0] SRC1[255:0]
CASE (imm8[0]) OF
0: TEMP[127:0] SRC2[127:0]
1: TEMP[255:128] SRC2[127:0]
ESAC
DEST TEMP
Intel C/C++ Compiler Intrinsic Equivalent
INSERTF128 __m256 _mm256_insertf128_ps (__m256 a, __m128 b, int offset);
INSERTF128 __m256d _mm256_insertf128_pd (__m256d a, __m128d b, int offset);
INSERTF128 __m256i _mm256_insertf128_si256 (__m256i a, __m128i b, int offset);
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
VEX.NDS.256.66.0F3A.W0 18 /r ib
VINSERTF128 ymm1, ymm2,
xmm3/m128, imm8
A V/V AVX Insert a single precision
floating-point value
selected by imm8 from
xmm2/m32 into xmm1 at
the specified destination
element specified by imm8
and zero out destination
elements in xmm1 as
indicated in imm8.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

3-520 Vol. 2A VINSERTF128 — Insert Packed Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
SIMD Floating-Point Exceptions
None
Other Exceptions
See Exceptions Type 6; additionally
#UD If VEX.W = 1.

Vol. 2A 3-521
INSTRUCTION SET REFERENCE, A-M
INSERTPS — Insert Packed Single Precision Floating-Point Value
INSERTPS — Insert Packed Single Precision Floating-Point Value
Instruction Operand Encoding
Description
(register source form)
Select a single precision floating-point element from second source as indicated by
Count_S bits of the immediate operand and insert it into the first source at the loca-
tion indicated by the Count_D bits of the immediate operand. Store in the destination
and zero out destination elements based on the ZMask bits of the immediate
operand.
(memory source form)
Load a floating-point element from a 32-bit memory location and insert it into the
first source at the location indicated by the Count_D bits of the immediate operand.
Store in the destination and zero out destination elements based on the ZMask bits
of the immediate operand.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 3A 21 /r ib
INSERTPS xmm1, xmm2/m32, imm8
A V/V SSE4_1 Insert a single precision
floating-point value
selected by imm8 from
xmm2/m32 into xmm1 at
the specified destination
element specified by imm8
and zero out destination
elements in xmm1 as
indicated in imm8.
VEX.NDS.128.66.0F3A.WIG 21 /r ib
VINSERTPS xmm1, xmm2,
xmm3/m32, imm8
B V/V AVX Insert a single precision
floating point value selected
by imm8 from xmm3/m32
and merge into xmm2 at the
specified destination
element specified by imm8
and zero out destination
elements in xmm1 as
indicated in imm8.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) imm8 NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

3-522 Vol. 2A INSERTPS — Insert Packed Single Precision Floating-Point Value
INSTRUCTION SET REFERENCE, A-M
128-bit Legacy SSE version: The first source register is an XMM register. The second
source operand is either an XMM register or a 32-bit memory location. The destina-
tion is not distinct from the first source XMM register and the upper bits (VLMAX-
1:128) of the corresponding YMM register destination are unmodified.
VEX.128 encoded version. The destination and first source register is an XMM
register. The second source operand is either an XMM register or a 32-bit memory
location. The upper bits (VLMAX-1:128) of the corresponding YMM register destina-
tion are zeroed.
If VINSERTPS is encoded with VEX.L= 1, an attempt to execute the instruction
encoded with VEX.L= 1 will cause an #UD exception.
Operation
INSERTPS (128-bit Legacy SSE version)
IF (SRC == REG) THEN COUNT_S imm8[7:6]
ELSE COUNT_S 0
COUNT_D imm8[5:4]
ZMASK imm8[3:0]
CASE (COUNT_S) OF
0: TMP SRC[31:0]
1: TMP SRC[63:32]
2: TMP SRC[95:64]
3: TMP SRC[127:96]
ESAC;
CASE (COUNT_D) OF
0: TMP2[31:0] TMP
TMP2[127:32] DEST[127:32]
1: TMP2[63:32] TMP
TMP2[31:0] DEST[31:0]
TMP2[127:64] DEST[127:64]
2: TMP2[95:64] TMP
TMP2[63:0] DEST[63:0]
TMP2[127:96] DEST[127:96]
3: TMP2[127:96] TMP
TMP2[95:0] DEST[95:0]
ESAC;
IF (ZMASK[0] == 1) THEN DEST[31:0] 00000000H
ELSE DEST[31:0] TMP2[31:0]
IF (ZMASK[1] == 1) THEN DEST[63:32] 00000000H
ELSE DEST[63:32] TMP2[63:32]

Vol. 2A 3-523
INSTRUCTION SET REFERENCE, A-M
INSERTPS — Insert Packed Single Precision Floating-Point Value
IF (ZMASK[2] == 1) THEN DEST[95:64] 00000000H
ELSE DEST[95:64] TMP2[95:64]
IF (ZMASK[3] == 1) THEN DEST[127:96] 00000000H
ELSE DEST[127:96] TMP2[127:96]
DEST[VLMAX-1:128] (Unmodified)
VINSERTPS (VEX.128 encoded version)
IF (SRC == REG) THEN COUNT_S imm8[7:6]
ELSE COUNT_S 0
COUNT_D imm8[5:4]
ZMASK imm8[3:0]
CASE (COUNT_S) OF
0: TMP SRC2[31:0]
1: TMP SRC2[63:32]
2: TMP SRC2[95:64]
3: TMP SRC2[127:96]
ESAC;
CASE (COUNT_D) OF
0: TMP2[31:0] TMP
TMP2[127:32] SRC1[127:32]
1: TMP2[63:32] TMP
TMP2[31:0] SRC1[31:0]
TMP2[127:64] SRC1[127:64]
2: TMP2[95:64] TMP
TMP2[63:0] SRC1[63:0]
TMP2[127:96] SRC1[127:96]
3: TMP2[127:96] TMP
TMP2[95:0] SRC1[95:0]
ESAC;
IF (ZMASK[0] == 1) THEN DEST[31:0] 00000000H
ELSE DEST[31:0] TMP2[31:0]
IF (ZMASK[1] == 1) THEN DEST[63:32] 00000000H
ELSE DEST[63:32] TMP2[63:32]
IF (ZMASK[2] == 1) THEN DEST[95:64] 00000000H
ELSE DEST[95:64] TMP2[95:64]
IF (ZMASK[3] == 1) THEN DEST[127:96] 00000000H
ELSE DEST[127:96] TMP2[127:96]
DEST[VLMAX-1:128] 0
Intel C/C++ Compiler Intrinsic Equivalent
INSERTPS __m128 _mm_insert_ps(__m128 dst, __m128 src, const int ndx);

3-524 Vol. 2A INSERTPS — Insert Packed Single Precision Floating-Point Value
INSTRUCTION SET REFERENCE, A-M
SIMD Floating-Point Exceptions
None
Other Exceptions
See Exceptions Type 5.

Vol. 2A 3-525
INSTRUCTION SET REFERENCE, A-M
INT n/INTO/INT 3—Call to Interrupt Procedure
INT n/INTO/INT 3—Call to Interrupt Procedure
Instruction Operand Encoding
Description
The INT n instruction generates a call to the interrupt or exception handler specified
with the destination operand (see the section titled “Interrupts and Exceptions” in
Chapter 6 of the Intel® 64 and IA-32 Architectures Software Developer’s Manual,
Volume 1). The destination operand specifies an interrupt vector number from 0 to
255, encoded as an 8-bit unsigned intermediate value. Each interrupt vector number
provides an index to a gate descriptor in the IDT. The first 32 interrupt vector
numbers are reserved by Intel for system use. Some of these interrupts are used for
internally generated exceptions.
The INT n instruction is the general mnemonic for executing a software-generated
call to an interrupt handler. The INTO instruction is a special mnemonic for calling
overflow exception (#OF), interrupt vector number 4. The overflow interrupt checks
the OF flag in the EFLAGS register and calls the overflow interrupt handler if the OF
flag is set to 1. (The INTO instruction cannot be used in 64-bit mode.)
The INT 3 instruction generates a special one byte opcode (CC) that is intended for
calling the debug exception handler. (This one byte form is valuable because it can be
used to replace the first byte of any instruction with a breakpoint, including other one
byte instructions, without over-writing other code). To further support its function as
a debug breakpoint, the interrupt generated with the CC opcode also differs from the
regular software interrupts as follows:
•Interrupt redirection does not happen when in VME mode; the interrupt is
handled by a protected-mode handler.
•The virtual-8086 mode IOPL checks do not occur. The interrupt is taken without
faulting at any IOPL level.
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
CC INT 3 A Valid Valid Interrupt 3—trap to
debugger.
CD ib INT imm8 B Valid Valid Interrupt vector number
specified by immediate
byte.
CE INTO A Invalid Valid Interrupt 4—if overflow flag
is 1.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA
Bimm8 NA NA NA

3-526 Vol. 2A INT n/INTO/INT 3—Call to Interrupt Procedure
INSTRUCTION SET REFERENCE, A-M
Note that the “normal” 2-byte opcode for INT 3 (CD03) does not have these special
features. Intel and Microsoft assemblers will not generate the CD03 opcode from any
mnemonic, but this opcode can be created by direct numeric code definition or by
self-modifying code.
The action of the INT n instruction (including the INTO and INT 3 instructions) is
similar to that of a far call made with the CALL instruction. The primary difference is
that with the INT n instruction, the EFLAGS register is pushed onto the stack before
the return address. (The return address is a far address consisting of the current
values of the CS and EIP registers.) Returns from interrupt procedures are handled
with the IRET instruction, which pops the EFLAGS information and return address
from the stack.
The interrupt vector number specifies an interrupt descriptor in the interrupt
descriptor table (IDT); that is, it provides index into the IDT. The selected interrupt
descriptor in turn contains a pointer to an interrupt or exception handler procedure.
In protected mode, the IDT contains an array of 8-byte descriptors, each of which
is an interrupt gate, trap gate, or task gate. In real-address mode, the IDT is an
array of 4-byte far pointers (2-byte code segment selector and a 2-byte instruction
pointer), each of which point directly to a procedure in the selected segment. (Note
that in real-address mode, the IDT is called the interrupt vector table, and its
pointers are called interrupt vectors.)
The following decision table indicates which action in the lower portion of the table is
taken given the conditions in the upper portion of the table. Each Y in the lower
section of the decision table represents a procedure defined in the “Operation”
section for this instruction (except #GP).
Table 3-61. Decision Table
PE 01 1 1 1 1 1 1
VM –– – – – 0 1 1
IOPL –– – – – – <3 =3
DPL/CPL
RELATIONSHIP
–DPL<
CPL
–DPL>
CPL
DPL=
CPL or C
DPL<
CPL & NC
––
INTERRUPT TYPE –S/W – – – – – –
GATE TYPE –– TaskTrap or
Interrupt
Trap or
Interrupt
Trap or
Interrupt
Trap or
Interrupt
Trap or
Interrupt
REAL-ADDRESS-
MODE
Y
PROTECTED-MODE YYY Y Y Y Y
TRAP-OR-
INTERRUPT-GATE
YYYYY
INTER-PRIVILEGE-
LEVEL-INTERRUPT
Y
INTRA-PRIVILEGE-
LEVEL-INTERRUPT
Y

Vol. 2A 3-527
INSTRUCTION SET REFERENCE, A-M
INT n/INTO/INT 3—Call to Interrupt Procedure
When the processor is executing in virtual-8086 mode, the IOPL determines the
action of the INT n instruction. If the IOPL is less than 3, the processor generates a
#GP(selector) exception; if the IOPL is 3, the processor executes a protected mode
interrupt to privilege level 0. The interrupt gate's DPL must be set to 3 and the target
CPL of the interrupt handler procedure must be 0 to execute the protected mode
interrupt to privilege level 0.
The interrupt descriptor table register (IDTR) specifies the base linear address and
limit of the IDT. The initial base address value of the IDTR after the processor is
powered up or reset is 0.
Operation
The following operational description applies not only to the INT n and INTO instruc-
tions, but also to external interrupts, nonmaskable interrupts (NMIs), and excep-
tions. Some of these events push onto the stack an error code.
The operational description specifies numerous checks whose failure may result in
delivery of a nested exception. In these cases, the original event is not delivered.
The operational description specifies the error code delivered by any nested excep-
tion. In some cases, the error code is specified with a pseudofunction
error_code(num,idt,ext), where idt and ext are bit values. The pseudofunction
produces an error code as follows: (1) if idt is 0, the error code is (num & FCH) | ext;
(2) if idt is 1, the error code is (num « 3) | 2 | ext.
In many cases, the pseudofunction error_code is invoked with a pseudovariable EXT.
The value of EXT depends on the nature of the event whose delivery encountered a
nested exception: if that event is a software interrupt, EXT is 0; otherwise, EXT is 1.
IF PE = 0
THEN
GOTO REAL-ADDRESS-MODE;
ELSE (* PE = 1 *)
IF (VM = 1 and IOPL < 3 AND INT n)
THEN
#GP(0); (* Bit 0 of error code is 0 because INT n *)
INTERRUPT-FROM-
VIRTUAL-8086-
MODE
Y
TASK-GATE Y
#GP YY Y
NOTES:
−Don't Care.
Y Yes, action taken.
Blank Action not taken.
Table 3-61. Decision Table (Contd.)

3-528 Vol. 2A INT n/INTO/INT 3—Call to Interrupt Procedure
INSTRUCTION SET REFERENCE, A-M
ELSE (* Protected mode, IA-32e mode, or virtual-8086 mode interrupt *)
IF (IA32_EFER.LMA = 0)
THEN (* Protected mode, or virtual-8086 mode interrupt *)
GOTO PROTECTED-MODE;
ELSE (* IA-32e mode interrupt *)
GOTO IA-32e-MODE;
FI;
FI;
FI;
REAL-ADDRESS-MODE:
IF ((vector_number « 2) + 3) is not within IDT limit
THEN #GP; FI;
IF stack not large enough for a 6-byte return information
THEN #SS; FI;
Push (EFLAGS[15:0]);
IF ← 0; (* Clear interrupt flag *)
TF ← 0; (* Clear trap flag *)
AC ← 0; (* Clear AC flag *)
Push(CS);
Push(IP);
(* No error codes are pushed in real-address mode*)
CS ← IDT(Descriptor (vector_number « 2), selector));
EIP ← IDT(Descriptor (vector_number « 2), offset)); (* 16 bit offset AND 0000FFFFH *)
END;
PROTECTED-MODE:
IF ((vector_number « 3) + 7) is not within IDT limits
or selected IDT descriptor is not an interrupt-, trap-, or task-gate type
THEN #GP(error_code(vector_number,1,EXT)); FI;
(* idt operand to error_code set because vector is used *)
IF software interrupt (* Generated by INT n, INT3, or INTO *)
THEN
IF gate DPL < CPL (* PE = 1, DPL < CPL, software interrupt *)
THEN #GP(error_code(vector_number,1,0)); FI;
(* idt operand to error_code set because vector is used *)
(* ext operand to error_code is 0 because INT n, INT3, or INTO*)
FI;
IF gate not present
THEN #NP(error_code(vector_number,1,EXT)); FI;
(* idt operand to error_code set because vector is used *)
IF task gate (* Specified in the selected interrupt table descriptor *)
THEN GOTO TASK-GATE;
ELSE GOTO TRAP-OR-INTERRUPT-GATE; (* PE = 1, trap/interrupt gate *)
FI;

Vol. 2A 3-529
INSTRUCTION SET REFERENCE, A-M
INT n/INTO/INT 3—Call to Interrupt Procedure
END;
IA-32e-MODE:
IF INTO and CS.L = 1 (64-bit mode)
THEN #UD;
FI;
IF ((vector_number « 4) + 15) is not in IDT limits
or selected IDT descriptor is not an interrupt-, or trap-gate type
THEN #GP(error_code(vector_number,1,EXT));
(* idt operand to error_code set because vector is used *)
FI;
IF software interrupt (* Generated by INT n, INT 3, or INTO *)
THEN
IF gate DPL < CPL (* PE = 1, DPL < CPL, software interrupt *)
THEN #GP(error_code(vector_number,1,0));
(* idt operand to error_code set because vector is used *)
(* ext operand to error_code is 0 because INT n, INT3, or INTO*)
FI;
FI;
IF gate not present
THEN #NP(error_code(vector_number,1,EXT));
(* idt operand to error_code set because vector is used *)
FI;
GOTO TRAP-OR-INTERRUPT-GATE; (* Trap/interrupt gate *)
END;
TASK-GATE: (* PE = 1, task gate *)
Read TSS selector in task gate (IDT descriptor);
IF local/global bit is set to local or index not within GDT limits
THEN #GP(error_code(TSS selector,0,EXT)); FI;
(* idt operand to error_code is 0 because selector is used *)
Access TSS descriptor in GDT;
IF TSS descriptor specifies that the TSS is busy (low-order 5 bits set to 00001)
THEN #GP(TSS selector,0,EXT)); FI;
(* idt operand to error_code is 0 because selector is used *)
IF TSS not present
THEN #NP(TSS selector,0,EXT)); FI;
(* idt operand to error_code is 0 because selector is used *)
SWITCH-TASKS (with nesting) to TSS;
IF interrupt caused by fault with error code
THEN
IF stack limit does not allow push of error code
THEN #SS(EXT); FI;
Push(error code);
FI;

3-530 Vol. 2A INT n/INTO/INT 3—Call to Interrupt Procedure
INSTRUCTION SET REFERENCE, A-M
IF EIP not within code segment limit
THEN #GP(EXT); FI;
END;
TRAP-OR-INTERRUPT-GATE:
Read new code-segment selector for trap or interrupt gate (IDT descriptor);
IF new code-segment selector is NULL
THEN #GP(EXT); FI; (* Error code contains NULL selector *)
IF new code-segment selector is not within its descriptor table limits
THEN #GP(error_code(new code-segment selector,0,EXT)); FI;
(* idt operand to error_code is 0 because selector is used *)
Read descriptor referenced by new code-segment selector;
IF descriptor does not indicate a code segment or new code-segment DPL > CPL
THEN #GP(error_code(new code-segment selector,0,EXT)); FI;
(* idt operand to error_code is 0 because selector is used *)
IF new code-segment descriptor is not present,
THEN #NP(error_code(new code-segment selector,0,EXT)); FI;
(* idt operand to error_code is 0 because selector is used *)
IF new code segment is non-conforming with DPL < CPL
THEN
IF VM = 0
THEN
GOTO INTER-PRIVILEGE-LEVEL-INTERRUPT;
(* PE = 1, VM = 0, interrupt or trap gate, nonconforming code segment,
DPL < CPL *)
ELSE (* VM = 1 *)
IF new code-segment DPL ≠ 0
THEN #GP(error_code(new code-segment selector,0,EXT));
(* idt operand to error_code is 0 because selector is used *)
GOTO INTERRUPT-FROM-VIRTUAL-8086-MODE; FI;
(* PE = 1, interrupt or trap gate, DPL < CPL, VM = 1 *)
FI;
ELSE (* PE = 1, interrupt or trap gate, DPL ≥ CPL *)
IF VM = 1
THEN #GP(error_code(new code-segment selector,0,EXT));
(* idt operand to error_code is 0 because selector is used *)
IF new code segment is conforming or new code-segment DPL = CPL
THEN
GOTO INTRA-PRIVILEGE-LEVEL-INTERRUPT;
ELSE (* PE = 1, interrupt or trap gate, nonconforming code segment, DPL > CPL *)
#GP(error_code(new code-segment selector,0,EXT));
(* idt operand to error_code is 0 because selector is used *)
FI;
FI;

Vol. 2A 3-531
INSTRUCTION SET REFERENCE, A-M
INT n/INTO/INT 3—Call to Interrupt Procedure
END;
INTER-PRIVILEGE-LEVEL-INTERRUPT:
(* PE = 1, interrupt or trap gate, non-conforming code segment, DPL < CPL *)
IF (IA32_EFER.LMA = 0) (* Not IA-32e mode *)
THEN
(* Identify stack-segment selector for new privilege level in current TSS *)
IF current TSS is 32-bit
THEN
TSSstackAddress ← (new code-segment DPL « 3) + 4;
IF (TSSstackAddress + 5) > current TSS limit
THEN #TS(error_code(current TSS selector,0,EXT)); FI;
(* idt operand to error_code is 0 because selector is used *)
NewSS ← 2 bytes loaded from (TSS base + TSSstackAddress + 4);
NewESP ← 4 bytes loaded from (TSS base + TSSstackAddress);
ELSE (* current TSS is 16-bit *)
TSSstackAddress ← (new code-segment DPL « 2) + 2
IF (TSSstackAddress + 3) > current TSS limit
THEN #TS(error_code(current TSS selector,0,EXT)); FI;
(* idt operand to error_code is 0 because selector is used *)
NewSS ← 2 bytes loaded from (TSS base + TSSstackAddress + 2);
NewESP ← 2 bytes loaded from (TSS base + TSSstackAddress);
FI;
IF NewSS is NULL
THEN #TS(EXT); FI;
IF NewSS index is not within its descriptor-table limits
or NewSS RPL ≠ new code-segment DPL
THEN #TS(error_code(NewSS,0,EXT)); FI;
(* idt operand to error_code is 0 because selector is used *)
Read new stack-segment descriptor for NewSS in GDT or LDT;
IF new stack-segment DPL ≠ new code-segment DPL
or new stack-segment Type does not indicate writable data segment
THEN #TS(error_code(NewSS,0,EXT)); FI;
(* idt operand to error_code is 0 because selector is used *)
IF NewSS is not present
THEN #SS(error_code(NewSS,0,EXT)); FI;
(* idt operand to error_code is 0 because selector is used *)
ELSE (* IA-32e mode *)
IF IDT-gate IST = 0
THEN TSSstackAddress ← (new code-segment DPL « 3) + 4;
ELSE TSSstackAddress ← (IDT gate IST « 3) + 28;
FI;
IF (TSSstackAddress + 7) > current TSS limit
THEN #TS(error_code(current TSS selector,0,EXT); FI;

3-532 Vol. 2A INT n/INTO/INT 3—Call to Interrupt Procedure
INSTRUCTION SET REFERENCE, A-M
(* idt operand to error_code is 0 because selector is used *)
NewRSP ← 8 bytes loaded from (current TSS base + TSSstackAddress);
NewSS ← new code-segment DPL; (* NULL selector with RPL = new CPL *)
FI;
IF IDT gate is 32-bit
THEN
IF new stack does not have room for 24 bytes (error code pushed)
or 20 bytes (no error code pushed)
THEN #SS(error_code(NewSS,0,EXT)); FI;
(* idt operand to error_code is 0 because selector is used *)
FI
ELSE
IF IDT gate is 16-bit
THEN
IF new stack does not have room for 12 bytes (error code pushed)
or 10 bytes (no error code pushed);
THEN #SS(error_code(NewSS,0,EXT)); FI;
(* idt operand to error_code is 0 because selector is used *)
ELSE (* 64-bit IDT gate*)
IF StackAddress is non-canonical
THEN #SS(EXT); FI; (* Error code contains NULL selector *)
FI;
FI;
IF (IA32_EFER.LMA = 0) (* Not IA-32e mode *)
THEN
IF instruction pointer from IDT gate is not within new code-segment limits
THEN #GP(EXT); FI; (* Error code contains NULL selector *)
ESP ← NewESP;
SS ← NewSS; (* Segment descriptor information also loaded *)
ELSE (* IA-32e mode *)
IF instruction pointer from IDT gate contains a non-canonical address
THEN #GP(EXT); FI; (* Error code contains NULL selector *)
RSP ← NewRSP & FFFFFFFFFFFFFFF0H;
SS ← NewSS;
FI;
IF IDT gate is 32-bit
THEN
CS:EIP ← Gate(CS:EIP); (* Segment descriptor information also loaded *)
ELSE
IF IDT gate 16-bit
THEN
CS:IP ← Gate(CS:IP);
(* Segment descriptor information also loaded *)

Vol. 2A 3-533
INSTRUCTION SET REFERENCE, A-M
INT n/INTO/INT 3—Call to Interrupt Procedure
ELSE (* 64-bit IDT gate *)
CS:RIP ← Gate(CS:RIP);
(* Segment descriptor information also loaded *)
FI;
FI;
IF IDT gate is 32-bit
THEN
Push(far pointer to old stack);
(* Old SS and ESP, 3 words padded to 4 *)
Push(EFLAGS);
Push(far pointer to return instruction);
(* Old CS and EIP, 3 words padded to 4 *)
Push(ErrorCode); (* If needed, 4 bytes *)
ELSE
IF IDT gate 16-bit
THEN
Push(far pointer to old stack);
(* Old SS and SP, 2 words *)
Push(EFLAGS(15-0]);
Push(far pointer to return instruction);
(* Old CS and IP, 2 words *)
Push(ErrorCode); (* If needed, 2 bytes *)
ELSE (* 64-bit IDT gate *)
Push(far pointer to old stack);
(* Old SS and SP, each an 8-byte push *)
Push(RFLAGS); (* 8-byte push *)
Push(far pointer to return instruction);
(* Old CS and RIP, each an 8-byte push *)
Push(ErrorCode); (* If needed, 8-bytes *)
FI;
FI;
CPL ← new code-segment DPL;
CS(RPL) ← CPL;
IF IDT gate is interrupt gate
THEN IF ← 0 (* Interrupt flag set to 0, interrupts disabled *); FI;
TF ← 0;
VM ← 0;
RF ← 0;
NT ← 0;
END;
INTERRUPT-FROM-VIRTUAL-8086-MODE:
(* Identify stack-segment selector for privilege level 0 in current TSS *)
IF current TSS is 32-bit

3-534 Vol. 2A INT n/INTO/INT 3—Call to Interrupt Procedure
INSTRUCTION SET REFERENCE, A-M
THEN
IF TSS limit < 9
THEN #TS(error_code(current TSS selector,0,EXT)); FI;
(* idt operand to error_code is 0 because selector is used *)
NewSS ← 2 bytes loaded from (current TSS base + 8);
NewESP ← 4 bytes loaded from (current TSS base + 4);
ELSE (* current TSS is 16-bit *)
IF TSS limit < 5
THEN #TS(error_code(current TSS selector,0,EXT)); FI;
(* idt operand to error_code is 0 because selector is used *)
NewSS ← 2 bytes loaded from (current TSS base + 4);
NewESP ← 2 bytes loaded from (current TSS base + 2);
FI;
IF NewSS is NULL
THEN #TS(EXT); FI; (* Error code contains NULL selector *)
IF NewSS index is not within its descriptor table limits
or NewSS RPL ≠ 0
THEN #TS(error_code(NewSS,0,EXT)); FI;
(* idt operand to error_code is 0 because selector is used *)
Read new stack-segment descriptor for NewSS in GDT or LDT;
IF new stack-segment DPL ≠ 0 or stack segment does not indicate writable data segment
THEN #TS(error_code(NewSS,0,EXT)); FI;
(* idt operand to error_code is 0 because selector is used *)
IF new stack segment not present
THEN #SS(error_code(NewSS,0,EXT)); FI;
(* idt operand to error_code is 0 because selector is used *)
IF IDT gate is 32-bit
THEN
IF new stack does not have room for 40 bytes (error code pushed)
or 36 bytes (no error code pushed)
THEN #SS(error_code(NewSS,0,EXT)); FI;
(* idt operand to error_code is 0 because selector is used *)
ELSE (* IDT gate is 16-bit)
IF new stack does not have room for 20 bytes (error code pushed)
or 18 bytes (no error code pushed)
THEN #SS(error_code(NewSS,0,EXT)); FI;
(* idt operand to error_code is 0 because selector is used *)
FI;
IF instruction pointer from IDT gate is not within new code-segment limits
THEN #GP(EXT); FI; (* Error code contains NULL selector *)
tempEFLAGS ← EFLAGS;
VM ← 0;
TF ← 0;

Vol. 2A 3-535
INSTRUCTION SET REFERENCE, A-M
INT n/INTO/INT 3—Call to Interrupt Procedure
RF ← 0;
NT ← 0;
IF service through interrupt gate
THEN IF = 0; FI;
TempSS ← SS;
TempESP ← ESP;
SS ← NewSS;
ESP ← NewESP;
(* Following pushes are 16 bits for 16-bit IDT gates and 32 bits for 32-bit IDT gates;
Segment selector pushes in 32-bit mode are padded to two words *)
Push(GS);
Push(FS);
Push(DS);
Push(ES);
Push(TempSS);
Push(TempESP);
Push(TempEFlags);
Push(CS);
Push(EIP);
GS ← 0; (* Segment registers made NULL, invalid for use in protected mode *)
FS ← 0;
DS ← 0;
ES ← 0;
CS:IP ← Gate(CS); (* Segment descriptor information also loaded *)
IF OperandSize = 32
THEN
EIP ← Gate(instruction pointer);
ELSE (* OperandSize is 16 *)
EIP ← Gate(instruction pointer) AND 0000FFFFH;
FI;
(* Start execution of new routine in Protected Mode *)
END;
INTRA-PRIVILEGE-LEVEL-INTERRUPT:
(* PE = 1, DPL = CPL or conforming segment *)
IF IA32_EFER.LMA = 1 (* IA-32e mode *)
IF IDT-descriptor IST ≠ 0
THEN
TSSstackAddress ← (IDT-descriptor IST « 3) + 28;
IF (TSSstackAddress + 7) > TSS limit
THEN #TS(error_code(current TSS selector,0,EXT)); FI;
(* idt operand to error_code is 0 because selector is used *)
NewRSP ← 8 bytes loaded from (current TSS base + TSSstackAddress);
FI;

3-536 Vol. 2A INT n/INTO/INT 3—Call to Interrupt Procedure
INSTRUCTION SET REFERENCE, A-M
IF 32-bit gate (* implies IA32_EFER.LMA = 0 *)
THEN
IF current stack does not have room for 16 bytes (error code pushed)
or 12 bytes (no error code pushed)
THEN #SS(EXT); FI; (* Error code contains NULL selector *)
ELSE IF 16-bit gate (* implies IA32_EFER.LMA = 0 *)
IF current stack does not have room for 8 bytes (error code pushed)
or 6 bytes (no error code pushed)
THEN #SS(EXT); FI; (* Error code contains NULL selector *)
ELSE (* IA32_EFER.LMA = 1, 64-bit gate*)
IF NewRSP contains a non-canonical address
THEN #SS(EXT); (* Error code contains NULL selector *)
FI;
FI;
IF (IA32_EFER.LMA = 0) (* Not IA-32e mode *)
THEN
IF instruction pointer from IDT gate is not within new code-segment limit
THEN #GP(EXT); FI; (* Error code contains NULL selector *)
ELSE
IF instruction pointer from IDT gate contains a non-canonical address
THEN #GP(EXT); FI; (* Error code contains NULL selector *)
RSP ← NewRSP & FFFFFFFFFFFFFFF0H;
FI;
IF IDT gate is 32-bit (* implies IA32_EFER.LMA = 0 *)
THEN
Push (EFLAGS);
Push (far pointer to return instruction); (* 3 words padded to 4 *)
CS:EIP ← Gate(CS:EIP); (* Segment descriptor information also loaded *)
Push (ErrorCode); (* If any *)
ELSE
IF IDT gate is 16-bit (* implies IA32_EFER.LMA = 0 *)
THEN
Push (FLAGS);
Push (far pointer to return location); (* 2 words *)
CS:IP ← Gate(CS:IP);
(* Segment descriptor information also loaded *)
Push (ErrorCode); (* If any *)
ELSE (* IA32_EFER.LMA = 1, 64-bit gate*)
Push(far pointer to old stack);
(* Old SS and SP, each an 8-byte push *)
Push(RFLAGS); (* 8-byte push *)
Push(far pointer to return instruction);
(* Old CS and RIP, each an 8-byte push *)

Vol. 2A 3-537
INSTRUCTION SET REFERENCE, A-M
INT n/INTO/INT 3—Call to Interrupt Procedure
Push(ErrorCode); (* If needed, 8 bytes *)
CS:RIP ← GATE(CS:RIP);
(* Segment descriptor information also loaded *)
FI;
FI;
CS(RPL) ← CPL;
IF IDT gate is interrupt gate
THEN IF ← 0; FI; (* Interrupt flag set to 0; interrupts disabled *)
TF ← 0;
NT ← 0;
VM ← 0;
RF ← 0;
END;
Flags Affected
The EFLAGS register is pushed onto the stack. The IF, TF, NT, AC, RF, and VM flags
may be cleared, depending on the mode of operation of the processor when the INT
instruction is executed (see the “Operation” section). If the interrupt uses a task
gate, any flags may be set or cleared, controlled by the EFLAGS image in the new
task’s TSS.
Protected Mode Exceptions
#GP(error_code) If the instruction pointer in the IDT or in the interrupt-, trap-, or
task gate is beyond the code segment limits.
If the segment selector in the interrupt-, trap-, or task gate is
NULL.
If an interrupt-, trap-, or task gate, code segment, or TSS
segment selector index is outside its descriptor table limits.
If the interrupt vector number is outside the IDT limits.
If an IDT descriptor is not an interrupt-, trap-, or task-descriptor.
If an interrupt is generated by the INT n, INT 3, or INTO instruc-
tion and the DPL of an interrupt-, trap-, or task-descriptor is less
than the CPL.
If the segment selector in an interrupt- or trap-gate does not
point to a segment descriptor for a code segment.
If the segment selector for a TSS has its local/global bit set for
local.
If a TSS segment descriptor specifies that the TSS is busy or not
available.
#SS(error_code) If pushing the return address, flags, or error code onto the stack
exceeds the bounds of the stack segment and no stack switch
occurs.

3-538 Vol. 2A INT n/INTO/INT 3—Call to Interrupt Procedure
INSTRUCTION SET REFERENCE, A-M
If the SS register is being loaded and the segment pointed to is
marked not present.
If pushing the return address, flags, error code, or stack
segment pointer exceeds the bounds of the new stack segment
when a stack switch occurs.
#NP(error_code) If code segment, interrupt-, trap-, or task gate, or TSS is not
present.
#TS(error_code) If the RPL of the stack segment selector in the TSS is not equal
to the DPL of the code segment being accessed by the interrupt
or trap gate.
If DPL of the stack segment descriptor pointed to by the stack
segment selector in the TSS is not equal to the DPL of the code
segment descriptor for the interrupt or trap gate.
If the stack segment selector in the TSS is NULL.
If the stack segment for the TSS is not a writable data segment.
If segment-selector index for stack segment is outside
descriptor table limits.
#PF(fault-code) If a page fault occurs.
#UD If the LOCK prefix is used.
#AC(EXT) If alignment checking is enabled, the gate DPL is 3, and a stack
push is unaligned.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the interrupt vector number is outside the IDT limits.
#SS If stack limit violation on push.
If pushing the return address, flags, or error code onto the stack
exceeds the bounds of the stack segment.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(error_code) (For INT n, INTO, or BOUND instruction) If the IOPL is less than
3 or the DPL of the interrupt-, trap-, or task-gate descriptor is
not equal to 3.
If the instruction pointer in the IDT or in the interrupt-, trap-, or
task gate is beyond the code segment limits.
If the segment selector in the interrupt-, trap-, or task gate is
NULL.
If a interrupt-, trap-, or task gate, code segment, or TSS
segment selector index is outside its descriptor table limits.

Vol. 2A 3-539
INSTRUCTION SET REFERENCE, A-M
INT n/INTO/INT 3—Call to Interrupt Procedure
If the interrupt vector number is outside the IDT limits.
If an IDT descriptor is not an interrupt-, trap-, or task-descriptor.
If an interrupt is generated by the INT n instruction and the DPL
of an interrupt-, trap-, or task-descriptor is less than the CPL.
If the segment selector in an interrupt- or trap-gate does not
point to a segment descriptor for a code segment.
If the segment selector for a TSS has its local/global bit set for
local.
#SS(error_code) If the SS register is being loaded and the segment pointed to is
marked not present.
If pushing the return address, flags, error code, stack segment
pointer, or data segments exceeds the bounds of the stack
segment.
#NP(error_code) If code segment, interrupt-, trap-, or task gate, or TSS is not
present.
#TS(error_code) If the RPL of the stack segment selector in the TSS is not equal
to the DPL of the code segment being accessed by the interrupt
or trap gate.
If DPL of the stack segment descriptor for the TSS’s stack
segment is not equal to the DPL of the code segment descriptor
for the interrupt or trap gate.
If the stack segment selector in the TSS is NULL.
If the stack segment for the TSS is not a writable data segment.
If segment-selector index for stack segment is outside
descriptor table limits.
#PF(fault-code) If a page fault occurs.
#BP If the INT 3 instruction is executed.
#OF If the INTO instruction is executed and the OF flag is set.
#UD If the LOCK prefix is used.
#AC(EXT) If alignment checking is enabled, the gate DPL is 3, and a stack
push is unaligned.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#GP(error_code) If the instruction pointer in the 64-bit interrupt gate or 64-bit
trap gate is non-canonical.
If the segment selector in the 64-bit interrupt or trap gate is
NULL.
If the interrupt vector number is outside the IDT limits.

3-540 Vol. 2A INT n/INTO/INT 3—Call to Interrupt Procedure
INSTRUCTION SET REFERENCE, A-M
If the interrupt vector number points to a gate which is in non-
canonical space.
If the interrupt vector number points to a descriptor which is not
a 64-bit interrupt gate or 64-bit trap gate.
If the descriptor pointed to by the gate selector is outside the
descriptor table limit.
If the descriptor pointed to by the gate selector is in non-canon-
ical space.
If the descriptor pointed to by the gate selector is not a code
segment.
If the descriptor pointed to by the gate selector doesn’t have the
L-bit set, or has both the L-bit and D-bit set.
If the descriptor pointed to by the gate selector has DPL > CPL.
#SS(error_code) If a push of the old EFLAGS, CS selector, EIP, or error code is in
non-canonical space with no stack switch.
If a push of the old SS selector, ESP, EFLAGS, CS selector, EIP, or
error code is in non-canonical space on a stack switch (either
CPL change or no-CPL with IST).
#NP(error_code) If the 64-bit interrupt-gate, 64-bit trap-gate, or code segment is
not present.
#TS(error_code) If an attempt to load RSP from the TSS causes an access to non-
canonical space.
If the RSP from the TSS is outside descriptor table limits.
#PF(fault-code) If a page fault occurs.
#UD If the LOCK prefix is used.
#AC(EXT) If alignment checking is enabled, the gate DPL is 3, and a stack
push is unaligned.

Vol. 2A 3-541
INSTRUCTION SET REFERENCE, A-M
INVD—Invalidate Internal Caches
INVD—Invalidate Internal Caches
Instruction Operand Encoding
Description
Invalidates (flushes) the processor’s internal caches and issues a special-function
bus cycle that directs external caches to also flush themselves. Data held in internal
caches is not written back to main memory.
After executing this instruction, the processor does not wait for the external caches
to complete their flushing operation before proceeding with instruction execution. It
is the responsibility of hardware to respond to the cache flush signal.
The INVD instruction is a privileged instruction. When the processor is running in
protected mode, the CPL of a program or procedure must be 0 to execute this
instruction.
Use this instruction with care. Data cached internally and not written back to main
memory will be lost. Unless there is a specific requirement or benefit to flushing
caches without writing back modified cache lines (for example, testing or fault
recovery where cache coherency with main memory is not a concern), software
should use the WBINVD instruction.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
IA-32 Architecture Compatibility
The INVD instruction is implementation dependent; it may be implemented differ-
ently on different families of Intel 64 or IA-32 processors. This instruction is not
supported on IA-32 processors earlier than the Intel486 processor.
Operation
Flush(InternalCaches);
SignalFlush(ExternalCaches);
Continue (* Continue execution *)
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F 08 INVD A Valid Valid Flush internal caches;
initiate flushing of external
caches.
NOTES:
* See the IA-32 Architecture Compatibility section below.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA

3-542 Vol. 2A INVD—Invalidate Internal Caches
INSTRUCTION SET REFERENCE, A-M
Flags Affected
None.
Protected Mode Exceptions
#GP(0) If the current privilege level is not 0.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) The INVD instruction cannot be executed in virtual-8086 mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.

Vol. 2A 3-543
INSTRUCTION SET REFERENCE, A-M
INVLPG—Invalidate TLB Entry
INVLPG—Invalidate TLB Entry
Instruction Operand Encoding
Description
Invalidates (flushes) the translation lookaside buffer (TLB) entry specified with the
source operand. The source operand is a memory address. The processor determines
the page that contains that address and flushes the TLB entry for that page.
The INVLPG instruction is a privileged instruction. When the processor is running in
protected mode, the CPL of a program or procedure must be 0 to execute this
instruction.
The INVLPG instruction normally flushes the TLB entry only for the specified page;
however, in some cases, it flushes the entire TLB. See “MOV—Move to/from Control
Registers” in this chapter for further information on operations that flush the TLB.
This instruction’s operation is the same in all non-64-bit modes. It also operates the
same in 64-bit mode, except if the memory address is in non-canonical form. In this
case, INVLPG is the same as a NOP.
IA-32 Architecture Compatibility
The INVLPG instruction is implementation dependent, and its function may be imple-
mented differently on different families of Intel 64 or IA-32 processors. This instruc-
tion is not supported on IA-32 processors earlier than the Intel486 processor.
Operation
Flush(RelevantTLBEntries);
Continue; (* Continue execution *)
Flags Affected
None.
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F 01/7 INVLPG mA Valid Valid Invalidate TLB Entry for
page that contains m.
NOTES:
* See the IA-32 Architecture Compatibility section below.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (r) NA NA NA

3-544 Vol. 2A INVLPG—Invalidate TLB Entry
INSTRUCTION SET REFERENCE, A-M
Protected Mode Exceptions
#GP(0) If the current privilege level is not 0.
#UD Operand is a register.
If the LOCK prefix is used.
Real-Address Mode Exceptions
#UD Operand is a register.
If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) The INVLPG instruction cannot be executed at the virtual-8086
mode.
64-Bit Mode Exceptions
#GP(0) If the current privilege level is not 0.
#UD Operand is a register.
If the LOCK prefix is used.

Vol. 2A 3-545
INSTRUCTION SET REFERENCE, A-M
IRET/IRETD—Interrupt Return
IRET/IRETD—Interrupt Return
Instruction Operand Encoding
Description
Returns program control from an exception or interrupt handler to a program or
procedure that was interrupted by an exception, an external interrupt, or a software-
generated interrupt. These instructions are also used to perform a return from a
nested task. (A nested task is created when a CALL instruction is used to initiate a
task switch or when an interrupt or exception causes a task switch to an interrupt or
exception handler.) See the section titled “Task Linking” in Chapter 7 of the Intel® 64
and IA-32 Architectures Software Developer’s Manual, Volume 3A.
IRET and IRETD are mnemonics for the same opcode. The IRETD mnemonic (inter-
rupt return double) is intended for use when returning from an interrupt when using
the 32-bit operand size; however, most assemblers use the IRET mnemonic inter-
changeably for both operand sizes.
In Real-Address Mode, the IRET instruction preforms a far return to the interrupted
program or procedure. During this operation, the processor pops the return instruc-
tion pointer, return code segment selector, and EFLAGS image from the stack to the
EIP, CS, and EFLAGS registers, respectively, and then resumes execution of the inter-
rupted program or procedure.
In Protected Mode, the action of the IRET instruction depends on the settings of the
NT (nested task) and VM flags in the EFLAGS register and the VM flag in the EFLAGS
image stored on the current stack. Depending on the setting of these flags, the
processor performs the following types of interrupt returns:
•Return from virtual-8086 mode.
•Return to virtual-8086 mode.
•Intra-privilege level return.
•Inter-privilege level return.
•Return from nested task (task switch).
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
CF IRET A Valid Valid Interrupt return (16-bit
operand size).
CF IRETD A Valid Valid Interrupt return (32-bit
operand size).
REX.W + CF IRETQ A Valid N.E. Interrupt return (64-bit
operand size).
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA

3-546 Vol. 2A IRET/IRETD—Interrupt Return
INSTRUCTION SET REFERENCE, A-M
If the NT flag (EFLAGS register) is cleared, the IRET instruction performs a far return
from the interrupt procedure, without a task switch. The code segment being
returned to must be equally or less privileged than the interrupt handler routine (as
indicated by the RPL field of the code segment selector popped from the stack).
As with a real-address mode interrupt return, the IRET instruction pops the return
instruction pointer, return code segment selector, and EFLAGS image from the stack
to the EIP, CS, and EFLAGS registers, respectively, and then resumes execution of
the interrupted program or procedure. If the return is to another privilege level, the
IRET instruction also pops the stack pointer and SS from the stack, before resuming
program execution. If the return is to virtual-8086 mode, the processor also pops the
data segment registers from the stack.
If the NT flag is set, the IRET instruction performs a task switch (return) from a
nested task (a task called with a CALL instruction, an interrupt, or an exception) back
to the calling or interrupted task. The updated state of the task executing the IRET
instruction is saved in its TSS. If the task is re-entered later, the code that follows the
IRET instruction is executed.
If the NT flag is set and the processor is in IA-32e mode, the IRET instruction causes
a general protection exception.
In 64-bit mode, the instruction’s default operation size is 32 bits. Use of the REX.W
prefix promotes operation to 64 bits (IRETQ). See the summary chart at the begin-
ning of this section for encoding data and limits.
See “Changes to Instruction Behavior in VMX Non-Root Operation” in Chapter 22 of
the Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 3B, for
more information about the behavior of this instruction in VMX non-root operation.
Operation
IF PE = 0
THEN
GOTO REAL-ADDRESS-MODE;
ELSE
IF (IA32_EFER.LMA = 0)
THEN (* Protected mode *)
GOTO PROTECTED-MODE;
ELSE (* IA-32e mode *)
GOTO IA-32e-MODE;
FI;
FI;
REAL-ADDRESS-MODE;
IF OperandSize = 32
THEN
IF top 12 bytes of stack not within stack limits
THEN #SS; FI;

Vol. 2A 3-547
INSTRUCTION SET REFERENCE, A-M
IRET/IRETD—Interrupt Return
tempEIP ← 4 bytes at end of stack
IF tempEIP[31:16] is not zero THEN #GP(0); FI;
EIP ← Pop();
CS ← Pop(); (* 32-bit pop, high-order 16 bits discarded *)
tempEFLAGS ← Pop();
EFLAGS ← (tempEFLAGS AND 257FD5H) OR (EFLAGS AND 1A0000H);
ELSE (* OperandSize = 16 *)
IF top 6 bytes of stack are not within stack limits
THEN #SS; FI;
EIP ← Pop(); (* 16-bit pop; clear upper 16 bits *)
CS ← Pop(); (* 16-bit pop *)
EFLAGS[15:0] ← Pop();
FI;
END;
PROTECTED-MODE:
IF VM = 1 (* Virtual-8086 mode: PE = 1, VM = 1 *)
THEN
GOTO RETURN-FROM-VIRTUAL-8086-MODE; (* PE = 1, VM = 1 *)
FI;
IF NT = 1
THEN
GOTO TASK-RETURN; (* PE = 1, VM = 0, NT = 1 *)
FI;
IF OperandSize = 32
THEN
IF top 12 bytes of stack not within stack limits
THEN #SS(0); FI;
tempEIP ← Pop();
tempCS ← Pop();
tempEFLAGS ← Pop();
ELSE (* OperandSize = 16 *)
IF top 6 bytes of stack are not within stack limits
THEN #SS(0); FI;
tempEIP ← Pop();
tempCS ← Pop();
tempEFLAGS ← Pop();
tempEIP ← tempEIP AND FFFFH;
tempEFLAGS ← tempEFLAGS AND FFFFH;
FI;
IF tempEFLAGS(VM) = 1 and CPL = 0
THEN
GOTO RETURN-TO-VIRTUAL-8086-MODE;
ELSE

3-548 Vol. 2A IRET/IRETD—Interrupt Return
INSTRUCTION SET REFERENCE, A-M
GOTO PROTECTED-MODE-RETURN;
FI;
IA-32e-MODE:
IF NT = 1
THEN #GP(0);
ELSE IF OperandSize = 32
THEN
IF top 12 bytes of stack not within stack limits
THEN #SS(0); FI;
tempEIP ← Pop();
tempCS ← Pop();
tempEFLAGS ← Pop();
ELSE IF OperandSize = 16
THEN
IF top 6 bytes of stack are not within stack limits
THEN #SS(0); FI;
tempEIP ← Pop();
tempCS ← Pop();
tempEFLAGS ← Pop();
tempEIP ← tempEIP AND FFFFH;
tempEFLAGS ← tempEFLAGS AND FFFFH;
FI;
ELSE (* OperandSize = 64 *)
THEN
tempRIP ← Pop();
tempCS ← Pop();
tempEFLAGS ← Pop();
tempRSP ← Pop();
tempSS ← Pop();
FI;
GOTO IA-32e-MODE-RETURN;
RETURN-FROM-VIRTUAL-8086-MODE:
(* Processor is in virtual-8086 mode when IRET is executed and stays in virtual-8086 mode *)
IF IOPL = 3 (* Virtual mode: PE = 1, VM = 1, IOPL = 3 *)
THEN IF OperandSize = 32
THEN
IF top 12 bytes of stack not within stack limits
THEN #SS(0); FI;
IF instruction pointer not within code segment limits
THEN #GP(0); FI;
EIP ← Pop();
CS ← Pop(); (* 32-bit pop, high-order 16 bits discarded *)
EFLAGS ← Pop();

Vol. 2A 3-549
INSTRUCTION SET REFERENCE, A-M
IRET/IRETD—Interrupt Return
(* VM, IOPL,VIP and VIF EFLAG bits not modified by pop *)
ELSE (* OperandSize = 16 *)
IF top 6 bytes of stack are not within stack limits
THEN #SS(0); FI;
IF instruction pointer not within code segment limits
THEN #GP(0); FI;
EIP ← Pop();
EIP ← EIP AND 0000FFFFH;
CS ← Pop(); (* 16-bit pop *)
EFLAGS[15:0] ← Pop(); (* IOPL in EFLAGS not modified by pop *)
FI;
ELSE
#GP(0); (* Trap to virtual-8086 monitor: PE = 1, VM = 1, IOPL < 3 *)
FI;
END;
RETURN-TO-VIRTUAL-8086-MODE:
(* Interrupted procedure was in virtual-8086 mode: PE = 1, CPL=0, VM = 1 in flag image *)
IF top 24 bytes of stack are not within stack segment limits
THEN #SS(0); FI;
IF instruction pointer not within code segment limits
THEN #GP(0); FI;
CS ← tempCS;
EIP ← tempEIP & FFFFH;
EFLAGS ← tempEFLAGS;
TempESP ← Pop();
TempSS ← Pop();
ES ← Pop(); (* Pop 2 words; throw away high-order word *)
DS ← Pop(); (* Pop 2 words; throw away high-order word *)
FS ← Pop(); (* Pop 2 words; throw away high-order word *)
GS ← Pop(); (* Pop 2 words; throw away high-order word *)
SS:ESP ← TempSS:TempESP;
CPL ← 3;
(* Resume execution in Virtual-8086 mode *)
END;
TASK-RETURN: (* PE = 1, VM = 0, NT = 1 *)
Read segment selector in link field of current TSS;
IF local/global bit is set to local
or index not within GDT limits
THEN #TS (TSS selector); FI;
Access TSS for task specified in link field of current TSS;
IF TSS descriptor type is not TSS or if the TSS is marked not busy

3-550 Vol. 2A IRET/IRETD—Interrupt Return
INSTRUCTION SET REFERENCE, A-M
THEN #TS (TSS selector); FI;
IF TSS not present
THEN #NP(TSS selector); FI;
SWITCH-TASKS (without nesting) to TSS specified in link field of current TSS;
Mark the task just abandoned as NOT BUSY;
IF EIP is not within code segment limit
THEN #GP(0); FI;
END;
PROTECTED-MODE-RETURN: (* PE = 1 *)
IF return code segment selector is NULL
THEN GP(0); FI;
IF return code segment selector addresses descriptor beyond descriptor table limit
THEN GP(selector); FI;
Read segment descriptor pointed to by the return code segment selector;
IF return code segment descriptor is not a code segment
THEN #GP(selector); FI;
IF return code segment selector RPL < CPL
THEN #GP(selector); FI;
IF return code segment descriptor is conforming
and return code segment DPL > return code segment selector RPL
THEN #GP(selector); FI;
IF return code segment descriptor is not present
THEN #NP(selector); FI;
IF return code segment selector RPL > CPL
THEN GOTO RETURN-OUTER-PRIVILEGE-LEVEL;
ELSE GOTO RETURN-TO-SAME-PRIVILEGE-LEVEL; FI;
END;
RETURN-TO-SAME-PRIVILEGE-LEVEL: (* PE = 1, RPL = CPL *)
IF new mode ≠ 64-Bit Mode
THEN
IF tempEIP is not within code segment limits
THEN #GP(0); FI;
EIP ← tempEIP;
ELSE (* new mode = 64-bit mode *)
IF tempRIP is non-canonical
THEN #GP(0); FI;
RIP ← tempRIP;
FI;
CS ← tempCS; (* Segment descriptor information also loaded *)
EFLAGS (CF, PF, AF, ZF, SF, TF, DF, OF, NT) ← tempEFLAGS;
IF OperandSize = 32 or OperandSize = 64

Vol. 2A 3-551
INSTRUCTION SET REFERENCE, A-M
IRET/IRETD—Interrupt Return
THEN EFLAGS(RF, AC, ID) ← tempEFLAGS; FI;
IF CPL ≤ IOPL
THEN EFLAGS(IF) ← tempEFLAGS; FI;
IF CPL = 0
THEN (* VM = 0 in flags image *)
EFLAGS(IOPL) ← tempEFLAGS;
IF OperandSize = 32 or OperandSize = 64
THEN EFLAGS(VIF, VIP) ← tempEFLAGS; FI;
FI;
END;
RETURN-TO-OUTER-PRIVILEGE-LEVEL:
IF OperandSize = 32
THEN
IF top 8 bytes on stack are not within limits
THEN #SS(0); FI;
ELSE (* OperandSize = 16 *)
IF top 4 bytes on stack are not within limits
THEN #SS(0); FI;
FI;
Read return segment selector;
IF stack segment selector is NULL
THEN #GP(0); FI;
IF return stack segment selector index is not within its descriptor table limits
THEN #GP(SSselector); FI;
Read segment descriptor pointed to by return segment selector;
IF stack segment selector RPL ≠ RPL of the return code segment selector
or the stack segment descriptor does not indicate a a writable data segment;
or the stack segment DPL ≠ RPL of the return code segment selector
THEN #GP(SS selector); FI;
IF stack segment is not present
THEN #SS(SS selector); FI;
IF new mode ≠ 64-Bit Mode
THEN
IF tempEIP is not within code segment limits
THEN #GP(0); FI;
EIP ← tempEIP;
ELSE (* new mode = 64-bit mode *)
IF tempRIP is non-canonical
THEN #GP(0); FI;
RIP ← tempRIP;
FI;
CS ← tempCS;

3-552 Vol. 2A IRET/IRETD—Interrupt Return
INSTRUCTION SET REFERENCE, A-M
EFLAGS (CF, PF, AF, ZF, SF, TF, DF, OF, NT) ← tempEFLAGS;
IF OperandSize = 32
THEN EFLAGS(RF, AC, ID) ← tempEFLAGS; FI;
IF CPL ≤ IOPL
THEN EFLAGS(IF) ← tempEFLAGS; FI;
IF CPL = 0
THEN
EFLAGS(IOPL) ← tempEFLAGS;
IF OperandSize = 32
THEN EFLAGS(VM, VIF, VIP) ← tempEFLAGS; FI;
IF OperandSize = 64
THEN EFLAGS(VIF, VIP) ← tempEFLAGS; FI;
FI;
CPL ← RPL of the return code segment selector;
FOR each of segment register (ES, FS, GS, and DS)
DO
IF segment register points to data or non-conforming code segment
and CPL > segment descriptor DPL (* Stored in hidden part of segment register *)
THEN (* Segment register invalid *)
SegmentSelector ← 0; (* NULL segment selector *)
FI;
OD;
END;
IA-32e-MODE-RETURN: (* IA32_EFER.LMA = 1, PE = 1 *)
IF ( (return code segment selector is NULL) or (return RIP is non-canonical) or
(SS selector is NULL going back to compatibility mode) or
(SS selector is NULL going back to CPL3 64-bit mode) or
(RPL <> CPL going back to non-CPL3 64-bit mode for a NULL SS selector) )
THEN GP(0); FI;
IF return code segment selector addresses descriptor beyond descriptor table limit
THEN GP(selector); FI;
Read segment descriptor pointed to by the return code segment selector;
IF return code segment descriptor is not a code segment
THEN #GP(selector); FI;
IF return code segment selector RPL < CPL
THEN #GP(selector); FI;
IF return code segment descriptor is conforming
and return code segment DPL > return code segment selector RPL
THEN #GP(selector); FI;
IF return code segment descriptor is not present
THEN #NP(selector); FI;
IF return code segment selector RPL > CPL

Vol. 2A 3-553
INSTRUCTION SET REFERENCE, A-M
IRET/IRETD—Interrupt Return
THEN GOTO RETURN-OUTER-PRIVILEGE-LEVEL;
ELSE GOTO RETURN-TO-SAME-PRIVILEGE-LEVEL; FI;
END;
Flags Affected
All the flags and fields in the EFLAGS register are potentially modified, depending on
the mode of operation of the processor. If performing a return from a nested task to
a previous task, the EFLAGS register will be modified according to the EFLAGS image
stored in the previous task’s TSS.
Protected Mode Exceptions
#GP(0) If the return code or stack segment selector is NULL.
If the return instruction pointer is not within the return code
segment limit.
#GP(selector) If a segment selector index is outside its descriptor table limits.
If the return code segment selector RPL is greater than the CPL.
If the DPL of a conforming-code segment is greater than the
return code segment selector RPL.
If the DPL for a nonconforming-code segment is not equal to the
RPL of the code segment selector.
If the stack segment descriptor DPL is not equal to the RPL of
the return code segment selector.
If the stack segment is not a writable data segment.
If the stack segment selector RPL is not equal to the RPL of the
return code segment selector.
If the segment descriptor for a code segment does not indicate
it is a code segment.
If the segment selector for a TSS has its local/global bit set for
local.
If a TSS segment descriptor specifies that the TSS is not busy.
If a TSS segment descriptor specifies that the TSS is not avail-
able.
#SS(0) If the top bytes of stack are not within stack limits.
#NP(selector) If the return code or stack segment is not present.
#PF(fault-code) If a page fault occurs.
#AC(0) If an unaligned memory reference occurs when the CPL is 3 and
alignment checking is enabled.
#UD If the LOCK prefix is used.

3-554 Vol. 2A IRET/IRETD—Interrupt Return
INSTRUCTION SET REFERENCE, A-M
Real-Address Mode Exceptions
#GP If the return instruction pointer is not within the return code
segment limit.
#SS If the top bytes of stack are not within stack limits.
Virtual-8086 Mode Exceptions
#GP(0) If the return instruction pointer is not within the return code
segment limit.
IF IOPL not equal to 3.
#PF(fault-code) If a page fault occurs.
#SS(0) If the top bytes of stack are not within stack limits.
#AC(0) If an unaligned memory reference occurs and alignment
checking is enabled.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
#GP(0) If EFLAGS.NT[bit 14] = 1.
Other exceptions same as in Protected Mode.
64-Bit Mode Exceptions
#GP(0) If EFLAGS.NT[bit 14] = 1.
If the return code segment selector is NULL.
If the stack segment selector is NULL going back to compatibility
mode.
If the stack segment selector is NULL going back to CPL3 64-bit
mode.
If a NULL stack segment selector RPL is not equal to CPL going
back to non-CPL3 64-bit mode.
If the return instruction pointer is not within the return code
segment limit.
If the return instruction pointer is non-canonical.
#GP(Selector) If a segment selector index is outside its descriptor table limits.
If a segment descriptor memory address is non-canonical.
If the segment descriptor for a code segment does not indicate
it is a code segment.
If the proposed new code segment descriptor has both the D-bit
and L-bit set.
If the DPL for a nonconforming-code segment is not equal to the
RPL of the code segment selector.
If CPL is greater than the RPL of the code segment selector.

Vol. 2A 3-555
INSTRUCTION SET REFERENCE, A-M
IRET/IRETD—Interrupt Return
If the DPL of a conforming-code segment is greater than the
return code segment selector RPL.
If the stack segment is not a writable data segment.
If the stack segment descriptor DPL is not equal to the RPL of
the return code segment selector.
If the stack segment selector RPL is not equal to the RPL of the
return code segment selector.
#SS(0) If an attempt to pop a value off the stack violates the SS limit.
If an attempt to pop a value off the stack causes a non-canonical
address to be referenced.
#NP(selector) If the return code or stack segment is not present.
#PF(fault-code) If a page fault occurs.
#AC(0) If an unaligned memory reference occurs when the CPL is 3 and
alignment checking is enabled.
#UD If the LOCK prefix is used.

3-556 Vol. 2A Jcc—Jump if Condition Is Met
INSTRUCTION SET REFERENCE, A-M
Jcc—Jump if Condition Is Met
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
77 cb JA rel8 A Valid Valid Jump short if above (CF=0
and ZF=0).
73 cb JAE rel8 A Valid Valid Jump short if above or equal
(CF=0).
72 cb JB rel8 A Valid Valid Jump short if below (CF=1).
76 cb JBE rel8 A Valid Valid Jump short if below or equal
(CF=1 or ZF=1).
72 cb JC rel8 A Valid Valid Jump short if carry (CF=1).
E3 cb JCXZ rel8 AN.E. Valid Jump short if CX register is
0.
E3 cb JECXZ rel8 A Valid Valid Jump short if ECX register is
0.
E3 cb JRCXZ rel8 A Valid N.E. Jump short if RCX register is
0.
74 cb JE rel8 A Valid Valid Jump short if equal (ZF=1).
7F cb JG rel8 A Valid Valid Jump short if greater (ZF=0
and SF=OF).
7D cb JGE rel8 A Valid Valid Jump short if greater or
equal (SF=OF).
7C cb JL rel8 A Valid Valid Jump short if less (SF≠ OF).
7E cb JLE rel8 A Valid Valid Jump short if less or equal
(ZF=1 or SF≠ OF).
76 cb JNA rel8 A Valid Valid Jump short if not above
(CF=1 or ZF=1).
72 cb JNAE rel8 A Valid Valid Jump short if not above or
equal (CF=1).
73 cb JNB rel8 A Valid Valid Jump short if not below
(CF=0).
77 cb JNBE rel8 A Valid Valid Jump short if not below or
equal (CF=0 and ZF=0).
73 cb JNC rel8 A Valid Valid Jump short if not carry
(CF=0).
75 cb JNE rel8 A Valid Valid Jump short if not equal
(ZF=0).
7E cb JNG rel8 A Valid Valid Jump short if not greater
(ZF=1 or SF≠ OF).

Vol. 2A 3-557
INSTRUCTION SET REFERENCE, A-M
Jcc—Jump if Condition Is Met
7C cb JNGE rel8 A Valid Valid Jump short if not greater or
equal (SF≠ OF).
7D cb JNL rel8 A Valid Valid Jump short if not less
(SF=OF).
7F cb JNLE rel8 A Valid Valid Jump short if not less or
equal (ZF=0 and SF=OF).
71 cb JNO rel8 A Valid Valid Jump short if not overflow
(OF=0).
7B cb JNP rel8 A Valid Valid Jump short if not parity
(PF=0).
79 cb JNS rel8 AValid Valid Jump short if not sign
(SF=0).
75 cb JNZ rel8 A Valid Valid Jump short if not zero
(ZF=0).
70 cb JO rel8 A Valid Valid Jump short if overflow
(OF=1).
7A cb JP rel8 A Valid Valid Jump short if parity (PF=1).
7A cb JPE rel8 AValid Valid Jump short if parity even
(PF=1).
7B cb JPO rel8 A Valid Valid Jump short if parity odd
(PF=0).
78 cb JS rel8 A Valid Valid Jump short if sign (SF=1).
74 cb JZ rel8 AValid Valid Jump short if zero (ZF ← 1).
0F 87 cw JA rel16 A N.S. Valid Jump near if above (CF=0
and ZF=0). Not supported in
64-bit mode.
0F 87 cd JA rel32 A Valid Valid Jump near if above (CF=0
and ZF=0).
0F 83 cw JAE rel16 A N.S. Valid Jump near if above or equal
(CF=0). Not supported in 64-
bit mode.
0F 83 cd JAE rel32 A Valid Valid Jump near if above or equal
(CF=0).
0F 82 cw JB rel16 A N.S. Valid Jump near if below (CF=1).
Not supported in 64-bit
mode.
0F 82 cd JB rel32 A Valid Valid Jump near if below (CF=1).
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description

3-558 Vol. 2A Jcc—Jump if Condition Is Met
INSTRUCTION SET REFERENCE, A-M
0F 86 cw JBE rel16 A N.S. Valid Jump near if below or equal
(CF=1 or ZF=1). Not
supported in 64-bit mode.
0F 86 cd JBE rel32 A Valid Valid Jump near if below or equal
(CF=1 or ZF=1).
0F 82 cw JC rel16 A N.S. Valid Jump near if carry (CF=1).
Not supported in 64-bit
mode.
0F 82 cd JC rel32 A Valid Valid Jump near if carry (CF=1).
0F 84 cw JE rel16 A N.S. Valid Jump near if equal (ZF=1).
Not supported in 64-bit
mode.
0F 84 cd JE rel32 A Valid Valid Jump near if equal (ZF=1).
0F 84 cw JZ rel16 A N.S. Valid Jump near if 0 (ZF=1). Not
supported in 64-bit mode.
0F 84 cd JZ rel32 A Valid Valid Jump near if 0 (ZF=1).
0F 8F cw JG rel16 A N.S. Valid Jump near if greater (ZF=0
and SF=OF). Not supported
in 64-bit mode.
0F 8F cd JG rel32 A Valid Valid Jump near if greater (ZF=0
and SF=OF).
0F 8D cw JGE rel16 A N.S. Valid Jump near if greater or
equal (SF=OF). Not
supported in 64-bit mode.
0F 8D cd JGE rel32 A Valid Valid Jump near if greater or
equal (SF=OF).
0F 8C cw JL rel16 A N.S. Valid Jump near if less (SF≠ OF).
Not supported in 64-bit
mode.
0F 8C cd JL rel32 A Valid Valid Jump near if less (SF≠ OF).
0F 8E cw JLE rel16 A N.S. Valid Jump near if less or equal
(ZF=1 or SF≠ OF). Not
supported in 64-bit mode.
0F 8E cd JLE rel32 A Valid Valid Jump near if less or equal
(ZF=1 or SF≠ OF).
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description

Vol. 2A 3-559
INSTRUCTION SET REFERENCE, A-M
Jcc—Jump if Condition Is Met
0F 86 cw JNA rel16 A N.S. Valid Jump near if not above
(CF=1 or ZF=1). Not
supported in 64-bit mode.
0F 86 cd JNA rel32 A Valid Valid Jump near if not above
(CF=1 or ZF=1).
0F 82 cw JNAE rel16 A N.S. Valid Jump near if not above or
equal (CF=1). Not supported
in 64-bit mode.
0F 82 cd JNAE rel32 A Valid Valid Jump near if not above or
equal (CF=1).
0F 83 cw JNB rel16 A N.S. Valid Jump near if not below
(CF=0). Not supported in 64-
bit mode.
0F 83 cd JNB rel32 A Valid Valid Jump near if not below
(CF=0).
0F 87 cw JNBE rel16 A N.S. Valid Jump near if not below or
equal (CF=0 and ZF=0). Not
supported in 64-bit mode.
0F 87 cd JNBE rel32 A Valid Valid Jump near if not below or
equal (CF=0 and ZF=0).
0F 83 cw JNC rel16 A N.S. Valid Jump near if not carry
(CF=0). Not supported in 64-
bit mode.
0F 83 cd JNC rel32 A Valid Valid Jump near if not carry
(CF=0).
0F 85 cw JNE rel16 A N.S. Valid Jump near if not equal
(ZF=0). Not supported in
64-bit mode.
0F 85 cd JNE rel32 A Valid Valid Jump near if not equal
(ZF=0).
0F 8E cw JNG rel16 A N.S. Valid Jump near if not greater
(ZF=1 or SF≠ OF). Not
supported in 64-bit mode.
0F 8E cd JNG rel32 A Valid Valid Jump near if not greater
(ZF=1 or SF≠ OF).
0F 8C cw JNGE rel16 A N.S. Valid Jump near if not greater or
equal (SF≠ OF). Not
supported in 64-bit mode.
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description

3-560 Vol. 2A Jcc—Jump if Condition Is Met
INSTRUCTION SET REFERENCE, A-M
0F 8C cd JNGE rel32 A Valid Valid Jump near if not greater or
equal (SF≠ OF).
0F 8D cw JNL rel16 A N.S. Valid Jump near if not less
(SF=OF). Not supported in
64-bit mode.
0F 8D cd JNL rel32 A Valid Valid Jump near if not less
(SF=OF).
0F 8F cw JNLE rel16 A N.S. Valid Jump near if not less or
equal (ZF=0 and SF=OF).
Not supported in 64-bit
mode.
0F 8F cd JNLE rel32 A Valid Valid Jump near if not less or
equal (ZF=0 and SF=OF).
0F 81 cw JNO rel16 A N.S. Valid Jump near if not overflow
(OF=0). Not supported in
64-bit mode.
0F 81 cd JNO rel32 A Valid Valid Jump near if not overflow
(OF=0).
0F 8B cw JNP rel16 A N.S. Valid Jump near if not parity
(PF=0). Not supported in 64-
bit mode.
0F 8B cd JNP rel32 A Valid Valid Jump near if not parity
(PF=0).
0F 89 cw JNS rel16 A N.S. Valid Jump near if not sign (SF=0).
Not supported in 64-bit
mode.
0F 89 cd JNS rel32 A Valid Valid Jump near if not sign (SF=0).
0F 85 cw JNZ rel16 A N.S. Valid Jump near if not zero
(ZF=0). Not supported in
64-bit mode.
0F 85 cd JNZ rel32 A Valid Valid Jump near if not zero
(ZF=0).
0F 80 cw JO rel16 A N.S. Valid Jump near if overflow
(OF=1). Not supported in
64-bit mode.
0F 80 cd JO rel32 A Valid Valid Jump near if overflow
(OF=1).
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description

Vol. 2A 3-561
INSTRUCTION SET REFERENCE, A-M
Jcc—Jump if Condition Is Met
Instruction Operand Encoding
Description
Checks the state of one or more of the status flags in the EFLAGS register (CF, OF, PF,
SF, and ZF) and, if the flags are in the specified state (condition), performs a jump to
the target instruction specified by the destination operand. A condition code (cc) is
associated with each instruction to indicate the condition being tested for. If the
condition is not satisfied, the jump is not performed and execution continues with the
instruction following the Jcc instruction.
The target instruction is specified with a relative offset (a signed offset relative to the
current value of the instruction pointer in the EIP register). A relative offset (rel8,
rel16, or rel32) is generally specified as a label in assembly code, but at the machine
code level, it is encoded as a signed, 8-bit or 32-bit immediate value, which is added
to the instruction pointer. Instruction coding is most efficient for offsets of –128 to
0F 8A cw JP rel16 A N.S. Valid Jump near if parity (PF=1).
Not supported in 64-bit
mode.
0F 8A cd JP rel32 A Valid Valid Jump near if parity (PF=1).
0F 8A cw JPE rel16 A N.S. Valid Jump near if parity even
(PF=1). Not supported in 64-
bit mode.
0F 8A cd JPE rel32 A Valid Valid Jump near if parity even
(PF=1).
0F 8B cw JPO rel16 A N.S. Valid Jump near if parity odd
(PF=0). Not supported in 64-
bit mode.
0F 8B cd JPO rel32 A Valid Valid Jump near if parity odd
(PF=0).
0F 88 cw JS rel16 A N.S. Valid Jump near if sign (SF=1). Not
supported in 64-bit mode.
0F 88 cd JS rel32 A Valid Valid Jump near if sign (SF=1).
0F 84 cw JZ rel16 A N.S. Valid Jump near if 0 (ZF=1). Not
supported in 64-bit mode.
0F 84 cd JZ rel32 A Valid Valid Jump near if 0 (ZF=1).
Op/En Operand 1 Operand 2 Operand 3 Operand 4
AOffset NA NA NA
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description

3-562 Vol. 2A Jcc—Jump if Condition Is Met
INSTRUCTION SET REFERENCE, A-M
+127. If the operand-size attribute is 16, the upper two bytes of the EIP register are
cleared, resulting in a maximum instruction pointer size of 16 bits.
The conditions for each Jcc mnemonic are given in the “Description” column of the
table on the preceding page. The terms “less” and “greater” are used for compari-
sons of signed integers and the terms “above” and “below” are used for unsigned
integers.
Because a particular state of the status flags can sometimes be interpreted in two
ways, two mnemonics are defined for some opcodes. For example, the JA (jump if
above) instruction and the JNBE (jump if not below or equal) instruction are alternate
mnemonics for the opcode 77H.
The Jcc instruction does not support far jumps (jumps to other code segments).
When the target for the conditional jump is in a different segment, use the opposite
condition from the condition being tested for the Jcc instruction, and then access the
target with an unconditional far jump (JMP instruction) to the other segment. For
example, the following conditional far jump is illegal:
JZ FARLABEL;
To accomplish this far jump, use the following two instructions:
JNZ BEYOND;
JMP FARLABEL;
BEYOND:
The JRCXZ, JECXZ and JCXZ instructions differ from other Jcc instructions because
they do not check status flags. Instead, they check RCX, ECX or CX for 0. The register
checked is determined by the address-size attribute. These instructions are useful
when used at the beginning of a loop that terminates with a conditional loop instruc-
tion (such as LOOPNE). They can be used to prevent an instruction sequence from
entering a loop when RCX, ECX or CX is 0. This would cause the loop to execute 264,
232 or 64K times (not zero times).
All conditional jumps are converted to code fetches of one or two cache lines, regard-
less of jump address or cacheability.
In 64-bit mode, operand size is fixed at 64 bits. JMP Short is RIP = RIP + 8-bit offset
sign extended to 64 bits. JMP Near is RIP = RIP + 32-bit offset sign extended to
64-bits.
Operation
IF condition
THEN
tempEIP ← EIP + SignExtend(DEST);
IF OperandSize = 16
THEN tempEIP ← tempEIP AND 0000FFFFH;
FI;
IF tempEIP is not within code segment limit
THEN #GP(0);

Vol. 2A 3-563
INSTRUCTION SET REFERENCE, A-M
Jcc—Jump if Condition Is Met
ELSE EIP ← tempEIP
FI;
FI;
Protected Mode Exceptions
#GP(0) If the offset being jumped to is beyond the limits of the CS
segment.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If the offset being jumped to is beyond the limits of the CS
segment or is outside of the effective address space from 0 to
FFFFH. This condition can occur if a 32-bit address size override
prefix is used.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
Same exceptions as in real address mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#GP(0) If the memory address is in a non-canonical form.
#UD If the LOCK prefix is used.

3-564 Vol. 2A JMP—Jump
INSTRUCTION SET REFERENCE, A-M
JMP—Jump
Instruction Operand Encoding
Description
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
EB cb JMP rel8 A Valid Valid Jump short, RIP = RIP + 8-bit
displacement sign extended
to 64-bits
E9 cw JMP rel16 A N.S. Valid Jump near, relative,
displacement relative to
next instruction. Not
supported in 64-bit mode.
E9 cd JMP rel32 A Valid Valid Jump near, relative, RIP =
RIP + 32-bit displacement
sign extended to 64-bits
FF /4 JMP r/m16 B N.S. Valid Jump near, absolute indirect,
address = zero-extended
r/m16. Not supported in 64-
bit mode.
FF /4 JMP r/m32 B N.S. Valid Jump near, absolute indirect,
address given in r/m32. Not
supported in 64-bit mode.
FF /4 JMP r/m64 B Valid N.E. Jump near, absolute indirect,
RIP = 64-Bit offset from
register or memory
EA cd JMP ptr16:16 A Inv. Valid Jump far, absolute, address
given in operand
EA cp JMP ptr16:32 A Inv. Valid Jump far, absolute, address
given in operand
FF /5 JMP m16:16 AValid Valid Jump far, absolute indirect,
address given in m16:16
FF /5 JMP m16:32 AValid Valid Jump far, absolute indirect,
address given in m16:32.
REX.W + FF /5 JMP m16:64 A Valid N.E. Jump far, absolute indirect,
address given in m16:64.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
AOffset NA NA NA
B ModRM:r/m (r) NA NA NA

Vol. 2A 3-565
INSTRUCTION SET REFERENCE, A-M
JMP—Jump
Transfers program control to a different point in the instruction stream without
recording return information. The destination (target) operand specifies the address
of the instruction being jumped to. This operand can be an immediate value, a
general-purpose register, or a memory location.
This instruction can be used to execute four different types of jumps:
•Near jump—A jump to an instruction within the current code segment (the
segment currently pointed to by the CS register), sometimes referred to as an
intrasegment jump.
•Short jump—A near jump where the jump range is limited to –128 to +127 from
the current EIP value.
•Far jump—A jump to an instruction located in a different segment than the
current code segment but at the same privilege level, sometimes referred to as
an intersegment jump.
•Task switch—A jump to an instruction located in a different task.
A task switch can only be executed in protected mode (see Chapter 7, in the Intel®
64 and IA-32 Architectures Software Developer’s Manual, Volume 3A, for information
on performing task switches with the JMP instruction).
Near and Short Jumps. When executing a near jump, the processor jumps to the
address (within the current code segment) that is specified with the target operand.
The target operand specifies either an absolute offset (that is an offset from the base
of the code segment) or a relative offset (a signed displacement relative to the
current value of the instruction pointer in the EIP register). A near jump to a relative
offset of 8-bits (rel8) is referred to as a short jump. The CS register is not changed on
near and short jumps.
An absolute offset is specified indirectly in a general-purpose register or a memory
location (r/m16 or r/m32). The operand-size attribute determines the size of the
target operand (16 or 32 bits). Absolute offsets are loaded directly into the EIP
register. If the operand-size attribute is 16, the upper two bytes of the EIP register
are cleared, resulting in a maximum instruction pointer size of 16 bits.
A relative offset (rel8, rel16, or rel32) is generally specified as a label in assembly
code, but at the machine code level, it is encoded as a signed 8-, 16-, or 32-bit
immediate value. This value is added to the value in the EIP register. (Here, the EIP
register contains the address of the instruction following the JMP instruction). When
using relative offsets, the opcode (for short vs. near jumps) and the operand-size
attribute (for near relative jumps) determines the size of the target operand (8, 16,
or 32 bits).
Far Jumps in Real-Address or Virtual-8086 Mode. When executing a far jump in real-
address or virtual-8086 mode, the processor jumps to the code segment and offset
specified with the target operand. Here the target operand specifies an absolute far
address either directly with a pointer (ptr16:16 or ptr16:32) or indirectly with a
memory location (m16:16 or m16:32). With the pointer method, the segment and
address of the called procedure is encoded in the instruction, using a 4-byte (16-bit
operand size) or 6-byte (32-bit operand size) far address immediate. With the indi-

3-566 Vol. 2A JMP—Jump
INSTRUCTION SET REFERENCE, A-M
rect method, the target operand specifies a memory location that contains a 4-byte
(16-bit operand size) or 6-byte (32-bit operand size) far address. The far address is
loaded directly into the CS and EIP registers. If the operand-size attribute is 16, the
upper two bytes of the EIP register are cleared.
Far Jumps in Protected Mode. When the processor is operating in protected mode, the
JMP instruction can be used to perform the following three types of far jumps:
•A far jump to a conforming or non-conforming code segment.
•A far jump through a call gate.
•A task switch.
(The JMP instruction cannot be used to perform inter-privilege-level far jumps.)
In protected mode, the processor always uses the segment selector part of the far
address to access the corresponding descriptor in the GDT or LDT. The descriptor
type (code segment, call gate, task gate, or TSS) and access rights determine the
type of jump to be performed.
If the selected descriptor is for a code segment, a far jump to a code segment at the
same privilege level is performed. (If the selected code segment is at a different priv-
ilege level and the code segment is non-conforming, a general-protection exception
is generated.) A far jump to the same privilege level in protected mode is very similar
to one carried out in real-address or virtual-8086 mode. The target operand specifies
an absolute far address either directly with a pointer (ptr16:16 or ptr16:32) or indi-
rectly with a memory location (m16:16 or m16:32). The operand-size attribute
determines the size of the offset (16 or 32 bits) in the far address. The new code
segment selector and its descriptor are loaded into CS register, and the offset from
the instruction is loaded into the EIP register. Note that a call gate (described in the
next paragraph) can also be used to perform far call to a code segment at the same
privilege level. Using this mechanism provides an extra level of indirection and is the
preferred method of making jumps between 16-bit and 32-bit code segments.
When executing a far jump through a call gate, the segment selector specified by the
target operand identifies the call gate. (The offset part of the target operand is
ignored.) The processor then jumps to the code segment specified in the call gate
descriptor and begins executing the instruction at the offset specified in the call gate.
No stack switch occurs. Here again, the target operand can specify the far address of
the call gate either directly with a pointer (ptr16:16 or ptr16:32) or indirectly with a
memory location (m16:16 or m16:32).
Executing a task switch with the JMP instruction is somewhat similar to executing a
jump through a call gate. Here the target operand specifies the segment selector of
the task gate for the task being switched to (and the offset part of the target operand
is ignored). The task gate in turn points to the TSS for the task, which contains the
segment selectors for the task’s code and stack segments. The TSS also contains the
EIP value for the next instruction that was to be executed before the task was
suspended. This instruction pointer value is loaded into the EIP register so that the
task begins executing again at this next instruction.

Vol. 2A 3-567
INSTRUCTION SET REFERENCE, A-M
JMP—Jump
The JMP instruction can also specify the segment selector of the TSS directly, which
eliminates the indirection of the task gate. See Chapter 7 in Intel® 64 and IA-32
Architectures Software Developer’s Manual, Volume 3A, for detailed information on
the mechanics of a task switch.
Note that when you execute at task switch with a JMP instruction, the nested task
flag (NT) is not set in the EFLAGS register and the new TSS’s previous task link field
is not loaded with the old task’s TSS selector. A return to the previous task can thus
not be carried out by executing the IRET instruction. Switching tasks with the JMP
instruction differs in this regard from the CALL instruction which does set the NT flag
and save the previous task link information, allowing a return to the calling task with
an IRET instruction.
In 64-Bit Mode — The instruction’s operation size is fixed at 64 bits. If a selector
points to a gate, then RIP equals the 64-bit displacement taken from gate; else RIP
equals the zero-extended offset from the far pointer referenced in the instruction.
See the summary chart at the beginning of this section for encoding data and limits.
Operation
IF near jump
IF 64-bit Mode
THEN
IF near relative jump
THEN
tempRIP ← RIP + DEST; (* RIP is instruction following JMP instruction*)
ELSE (* Near absolute jump *)
tempRIP ← DEST;
FI;
ELSE
IF near relative jump
THEN
tempEIP ← EIP + DEST; (* EIP is instruction following JMP instruction*)
ELSE (* Near absolute jump *)
tempEIP ← DEST;
FI;
FI;
IF (IA32_EFER.LMA = 0 or target mode = Compatibility mode)
and tempEIP outside code segment limit
THEN #GP(0); FI
IF 64-bit mode and tempRIP is not canonical
THEN #GP(0);
FI;
IF OperandSize = 32
THEN
EIP ← tempEIP;

3-568 Vol. 2A JMP—Jump
INSTRUCTION SET REFERENCE, A-M
ELSE
IF OperandSize = 16
THEN (* OperandSize = 16 *)
EIP ← tempEIP AND 0000FFFFH;
ELSE (* OperandSize = 64)
RIP ← tempRIP;
FI;
FI;
FI;
IF far jump and (PE = 0 or (PE = 1 AND VM = 1)) (* Real-address or virtual-8086 mode *)
THEN
tempEIP ← DEST(Offset); (* DEST is ptr16:32 or [m16:32] *)
IF tempEIP is beyond code segment limit
THEN #GP(0); FI;
CS ← DEST(segment selector); (* DEST is ptr16:32 or [m16:32] *)
IF OperandSize = 32
THEN
EIP ← tempEIP; (* DEST is ptr16:32 or [m16:32] *)
ELSE (* OperandSize = 16 *)
EIP ← tempEIP AND 0000FFFFH; (* Clear upper 16 bits *)
FI;
FI;
IF far jump and (PE = 1 and VM = 0)
(* IA-32e mode or protected mode, not virtual-8086 mode *)
THEN
IF effective address in the CS, DS, ES, FS, GS, or SS segment is illegal
or segment selector in target operand NULL
THEN #GP(0); FI;
IF segment selector index not within descriptor table limits
THEN #GP(new selector); FI;
Read type and access rights of segment descriptor;
IF (EFER.LMA = 0)
THEN
IF segment type is not a conforming or nonconforming code
segment, call gate, task gate, or TSS
THEN #GP(segment selector); FI;
ELSE
IF segment type is not a conforming or nonconforming code segment
call gate
THEN #GP(segment selector); FI;
FI;
Depending on type and access rights:
GO TO CONFORMING-CODE-SEGMENT;
GO TO NONCONFORMING-CODE-SEGMENT;

Vol. 2A 3-569
INSTRUCTION SET REFERENCE, A-M
JMP—Jump
GO TO CALL-GATE;
GO TO TASK-GATE;
GO TO TASK-STATE-SEGMENT;
ELSE
#GP(segment selector);
FI;
CONFORMING-CODE-SEGMENT:
IF L-Bit = 1 and D-BIT = 1 and IA32_EFER.LMA = 1
THEN GP(new code segment selector); FI;
IF DPL > CPL
THEN #GP(segment selector); FI;
IF segment not present
THEN #NP(segment selector); FI;
tempEIP ← DEST(Offset);
IF OperandSize = 16
THEN tempEIP ← tempEIP AND 0000FFFFH;
FI;
IF (IA32_EFER.LMA = 0 or target mode = Compatibility mode) and
tempEIP outside code segment limit
THEN #GP(0); FI
IF tempEIP is non-canonical
THEN #GP(0); FI;
CS ← DEST[segment selector]; (* Segment descriptor information also loaded *)
CS(RPL) ← CPL
EIP ← tempEIP;
END;
NONCONFORMING-CODE-SEGMENT:
IF L-Bit = 1 and D-BIT = 1 and IA32_EFER.LMA = 1
THEN GP(new code segment selector); FI;
IF (RPL > CPL) OR (DPL ≠ CPL)
THEN #GP(code segment selector); FI;
IF segment not present
THEN #NP(segment selector); FI;
tempEIP ← DEST(Offset);
IF OperandSize = 16
THEN tempEIP ← tempEIP AND 0000FFFFH; FI;
IF (IA32_EFER.LMA = 0 OR target mode = Compatibility mode)
and tempEIP outside code segment limit
THEN #GP(0); FI
IF tempEIP is non-canonical THEN #GP(0); FI;
CS ← DEST[segment selector]; (* Segment descriptor information also loaded *)
CS(RPL) ← CPL;
EIP ← tempEIP;
END;

3-570 Vol. 2A JMP—Jump
INSTRUCTION SET REFERENCE, A-M
CALL-GATE:
IF call gate DPL < CPL
or call gate DPL < call gate segment-selector RPL
THEN #GP(call gate selector); FI;
IF call gate not present
THEN #NP(call gate selector); FI;
IF call gate code-segment selector is NULL
THEN #GP(0); FI;
IF call gate code-segment selector index outside descriptor table limits
THEN #GP(code segment selector); FI;
Read code segment descriptor;
IF code-segment segment descriptor does not indicate a code segment
or code-segment segment descriptor is conforming and DPL > CPL
or code-segment segment descriptor is non-conforming and DPL ≠ CPL
THEN #GP(code segment selector); FI;
IF IA32_EFER.LMA = 1 and (code-segment descriptor is not a 64-bit code segment
or code-segment segment descriptor has both L-Bit and D-bit set)
THEN #GP(code segment selector); FI;
IF code segment is not present
THEN #NP(code-segment selector); FI;
IF instruction pointer is not within code-segment limit
THEN #GP(0); FI;
tempEIP ← DEST(Offset);
IF GateSize = 16
THEN tempEIP ← tempEIP AND 0000FFFFH; FI;
IF (IA32_EFER.LMA = 0 OR target mode = Compatibility mode) AND tempEIP
outside code segment limit
THEN #GP(0); FI
CS ← DEST[SegmentSelector); (* Segment descriptor information also loaded *)
CS(RPL) ← CPL;
EIP ← tempEIP;
END;
TASK-GATE:
IF task gate DPL < CPL
or task gate DPL < task gate segment-selector RPL
THEN #GP(task gate selector); FI;
IF task gate not present
THEN #NP(gate selector); FI;
Read the TSS segment selector in the task-gate descriptor;
IF TSS segment selector local/global bit is set to local
or index not within GDT limits
or TSS descriptor specifies that the TSS is busy
THEN #GP(TSS selector); FI;

Vol. 2A 3-571
INSTRUCTION SET REFERENCE, A-M
JMP—Jump
IF TSS not present
THEN #NP(TSS selector); FI;
SWITCH-TASKS to TSS;
IF EIP not within code segment limit
THEN #GP(0); FI;
END;
TASK-STATE-SEGMENT:
IF TSS DPL < CPL
or TSS DPL < TSS segment-selector RPL
or TSS descriptor indicates TSS not available
THEN #GP(TSS selector); FI;
IF TSS is not present
THEN #NP(TSS selector); FI;
SWITCH-TASKS to TSS;
IF EIP not within code segment limit
THEN #GP(0); FI;
END;
Flags Affected
All flags are affected if a task switch occurs; no flags are affected if a task switch does
not occur.
Protected Mode Exceptions
#GP(0) If offset in target operand, call gate, or TSS is beyond the code
segment limits.
If the segment selector in the destination operand, call gate,
task gate, or TSS is NULL.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register is used to access memory and it
contains a NULL segment selector.
#GP(selector) If the segment selector index is outside descriptor table limits.
If the segment descriptor pointed to by the segment selector in
the destination operand is not for a conforming-code segment,
nonconforming-code segment, call gate, task gate, or task state
segment.
If the DPL for a nonconforming-code segment is not equal to the
CPL
(When not using a call gate.) If the RPL for the segment’s
segment selector is greater than the CPL.
If the DPL for a conforming-code segment is greater than the
CPL.

3-572 Vol. 2A JMP—Jump
INSTRUCTION SET REFERENCE, A-M
If the DPL from a call-gate, task-gate, or TSS segment
descriptor is less than the CPL or than the RPL of the call-gate,
task-gate, or TSS’s segment selector.
If the segment descriptor for selector in a call gate does not indi-
cate it is a code segment.
If the segment descriptor for the segment selector in a task gate
does not indicate an available TSS.
If the segment selector for a TSS has its local/global bit set for
local.
If a TSS segment descriptor specifies that the TSS is busy or not
available.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NP (selector) If the code segment being accessed is not present.
If call gate, task gate, or TSS not present.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3. (Only
occurs when fetching target from memory.)
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If the target operand is beyond the code segment limits.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made. (Only occurs when fetching target from
memory.)
#UD If the LOCK prefix is used.

Vol. 2A 3-573
INSTRUCTION SET REFERENCE, A-M
JMP—Jump
Compatibility Mode Exceptions
Same as 64-bit mode exceptions.
64-Bit Mode Exceptions
#GP(0) If a memory address is non-canonical.
If target offset in destination operand is non-canonical.
If target offset in destination operand is beyond the new code
segment limit.
If the segment selector in the destination operand is NULL.
If the code segment selector in the 64-bit gate is NULL.
#GP(selector) If the code segment or 64-bit call gate is outside descriptor table
limits.
If the code segment or 64-bit call gate overlaps non-canonical
space.
If the segment descriptor from a 64-bit call gate is in non-
canonical space.
If the segment descriptor pointed to by the segment selector in
the destination operand is not for a conforming-code segment,
nonconforming-code segment, 64-bit call gate.
If the segment descriptor pointed to by the segment selector in
the destination operand is a code segment, and has both the
D-bit and the L-bit set.
If the DPL for a nonconforming-code segment is not equal to the
CPL, or the RPL for the segment’s segment selector is greater
than the CPL.
If the DPL for a conforming-code segment is greater than the
CPL.
If the DPL from a 64-bit call-gate is less than the CPL or than the
RPL of the 64-bit call-gate.
If the upper type field of a 64-bit call gate is not 0x0.
If the segment selector from a 64-bit call gate is beyond the
descriptor table limits.
If the code segment descriptor pointed to by the selector in the
64-bit gate doesn't have the L-bit set and the D-bit clear.
If the segment descriptor for a segment selector from the 64-bit
call gate does not indicate it is a code segment.
If the code segment is non-confirming and CPL ≠ DPL.
If the code segment is confirming and CPL < DPL.
#NP(selector) If a code segment or 64-bit call gate is not present.
#UD (64-bit mode only) If a far jump is direct to an absolute address
in memory.

3-574 Vol. 2A JMP—Jump
INSTRUCTION SET REFERENCE, A-M
If the LOCK prefix is used.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.

Vol. 2A 3-575
INSTRUCTION SET REFERENCE, A-M
LAHF—Load Status Flags into AH Register
LAHF—Load Status Flags into AH Register
Instruction Operand Encoding
Description
This instruction executes as described above in compatibility mode and legacy mode.
It is valid in 64-bit mode only if CPUID.80000001H:ECX.LAHF-SAHF[bit 0] = 1.
Operation
IF 64-Bit Mode
THEN
IF CPUID.80000001H:ECX.LAHF-SAHF[bit 0] = 1;
THEN AH ← RFLAGS(SF:ZF:0:AF:0:PF:1:CF);
ELSE #UD;
FI;
ELSE
AH ← EFLAGS(SF:ZF:0:AF:0:PF:1:CF);
FI;
Flags Affected
None. The state of the flags in the EFLAGS register is not affected.
Protected Mode Exceptions
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
9F LAHF A Invalid* Valid Load: AH ←
EFLAGS(SF:ZF:0:AF:0:PF:1:CF).
NOTES:
*Valid in specific steppings. See Description section.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA

3-576 Vol. 2A LAHF—Load Status Flags into AH Register
INSTRUCTION SET REFERENCE, A-M
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#UD If CPUID.80000001H:ECX.LAHF-SAHF[bit 0] = 0.
If the LOCK prefix is used.
Vol. 2A 3-577
INSTRUCTION SET REFERENCE, A-M
LAR—Load Access Rights Byte
LAR—Load Access Rights Byte
Instruction Operand Encoding
Description
Loads the access rights from the segment descriptor specified by the second operand
(source operand) into the first operand (destination operand) and sets the ZF flag in
the flag register. The source operand (which can be a register or a memory location)
contains the segment selector for the segment descriptor being accessed. If the
source operand is a memory address, only 16 bits of data are accessed. The destina-
tion operand is a general-purpose register.
The processor performs access checks as part of the loading process. Once loaded in
the destination register, software can perform additional checks on the access rights
information.
When the operand size is 32 bits, the access rights for a segment descriptor include
the type and DPL fields and the S, P, AVL, D/B, and G flags, all of which are located in
the second doubleword (bytes 4 through 7) of the segment descriptor. The double-
word is masked by 00FXFF00H before it is loaded into the destination operand. When
the operand size is 16 bits, the access rights include the type and DPL fields. Here,
the two lower-order bytes of the doubleword are masked by FF00H before being
loaded into the destination operand.
This instruction performs the following checks before it loads the access rights in the
destination register:
•Checks that the segment selector is not NULL.
•Checks that the segment selector points to a descriptor that is within the limits of
the GDT or LDT being accessed
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F 02 /rLAR r16, r16/m16 AValid Valid r16 ← r16/m16 masked by
FF00H.
0F 02 /rLAR r32,
r32/m161AValid Valid r32 ← r32/m16 masked by
00FxFF00H
REX.W + 0F 02
/r
LAR r64,
r32/m161AValid N.E. r64 ← r32/m16 masked by
00FxFF00H and zero
extended
NOTES:
1. For all loads (regardless of source or destination sizing) only bits 16-0 are used. Other bits are
ignored.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA

3-578 Vol. 2A LAR—Load Access Rights Byte
INSTRUCTION SET REFERENCE, A-M
•Checks that the descriptor type is valid for this instruction. All code and data
segment descriptors are valid for (can be accessed with) the LAR instruction. The
valid system segment and gate descriptor types are given in Table 3-62.
•If the segment is not a conforming code segment, it checks that the specified
segment descriptor is visible at the CPL (that is, if the CPL and the RPL of the
segment selector are less than or equal to the DPL of the segment selector).
If the segment descriptor cannot be accessed or is an invalid type for the instruction,
the ZF flag is cleared and no access rights are loaded in the destination operand.
The LAR instruction can only be executed in protected mode and IA-32e mode.
In 64-bit mode, the instruction’s default operation size is 32 bits. Use of the REX.W
prefix permits access to 64-bit registers as destination.
When the destination operand size is 64 bits, the access rights are loaded from the
second doubleword (bytes 4 through 7) of the segment descriptor. The doubleword is
masked by 00FXFF00H and zero extended to 64 bits before it is loaded into the desti-
nation operand.
Table 3-62. Segment and Gate Types
Type Protected Mode IA-32e Mode
Name Valid Name Valid
0Reserved No Reserved No
1Available 16-bit TSS Yes Reserved No
2LDT Yes LDT No
3Busy 16-bit TSS Yes Reserved No
416-bit call gate Yes Reserved No
516-bit/32-bit task gate Yes Reserved No
616-bit interrupt gate No Reserved No
716-bit trap gate No Reserved No
8Reserved No Reserved No
9Available 32-bit TSS Yes Available 64-bit TSS Yes
AReserved No Reserved No
BBusy 32-bit TSS Yes Busy 64-bit TSS Yes
C32-bit call gate Yes 64-bit call gate Yes
DReserved No Reserved No
E32-bit interrupt gate No 64-bit interrupt gate No
F32-bit trap gate No 64-bit trap gate No

Vol. 2A 3-579
INSTRUCTION SET REFERENCE, A-M
LAR—Load Access Rights Byte
Operation
IF Offset(SRC) > descriptor table limit
THEN
ZF = 0;
ELSE
IF SegmentDescriptor(Type) ≠ conforming code segment
and (CPL > DPL) or (RPL > DPL)
or segment type is not valid for instruction
THEN
ZF ← 0
ELSE
TEMP ← Read segment descriptor ;
IF OperandSize = 64
THEN
DEST ← (ACCESSRIGHTWORD(TEMP) AND 00000000_00FxFF00H);
ELSE (* OperandSize = 32*)
DEST ← (ACCESSRIGHTWORD(TEMP) AND 00FxFF00H);
ELSE (* OperandSize = 16 *)
DEST ← (ACCESSRIGHTWORD(TEMP) AND FF00H);
FI;
FI;
FI;
Flags Affected
The ZF flag is set to 1 if the access rights are loaded successfully; otherwise, it is set
to 0.
Protected Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register is used to access memory and it
contains a NULL segment selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and the memory operand effec-
tive address is unaligned while the current privilege level is 3.
#UD If the LOCK prefix is used.

3-580 Vol. 2A LAR—Load Access Rights Byte
INSTRUCTION SET REFERENCE, A-M
Real-Address Mode Exceptions
#UD The LAR instruction is not recognized in real-address mode.
Virtual-8086 Mode Exceptions
#UD The LAR instruction cannot be executed in virtual-8086 mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If the memory operand effective address referencing the SS
segment is in a non-canonical form.
#GP(0) If the memory operand effective address is in a non-canonical
form.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and the memory operand effec-
tive address is unaligned while the current privilege level is 3.
#UD If the LOCK prefix is used.

Vol. 2A 3-581
INSTRUCTION SET REFERENCE, A-M
LDDQU—Load Unaligned Integer 128 Bits
LDDQU—Load Unaligned Integer 128 Bits
Instruction Operand Encoding
Description
The instruction is functionally similar to (V)MOVDQU ymm/xmm, m256/m128 for
loading from memory. That is: 32/16 bytes of data starting at an address specified by
the source memory operand (second operand) are fetched from memory and placed
in a destination register (first operand). The source operand need not be aligned on
a 32/16-byte boundary. Up to 64/32 bytes may be loaded from memory; this is
implementation dependent.
This instruction may improve performance relative to (V)MOVDQU if the source
operand crosses a cache line boundary. In situations that require the data loaded by
(V)LDDQU be modified and stored to the same location, use (V)MOVDQU or
(V)MOVDQA instead of (V)LDDQU. To move a double quadword to or from memory
locations that are known to be aligned on 16-byte boundaries, use the (V)MOVDQA
instruction.
Implementation Notes
•If the source is aligned to a 32/16-byte boundary, based on the implementation,
the 32/16 bytes may be loaded more than once. For that reason, the usage of
(V)LDDQU should be avoided when using uncached or write-combining (WC)
memory regions. For uncached or WC memory regions, keep using (V)MOVDQU.
•This instruction is a replacement for (V)MOVDQU (load) in situations where cache
line splits significantly affect performance. It should not be used in situations
where store-load forwarding is performance critical. If performance of store-load
forwarding is critical to the application, use (V)MOVDQA store-load pairs when
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F2 0F F0 /r
LDDQU xmm1, mem
A V/V SSE3 Load unaligned data from
mem and return double
quadword in xmm1.
VEX.128.F2.0F.WIG F0 /r
VLDDQU xmm1, m128
A V/V AVX Load unaligned packed
integer values from mem to
xmm1.
VEX.256.F2.0F.WIG F0 /r
VLDDQU ymm1, m256
A V/V AVX Load unaligned packed
integer values from mem to
ymm1.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA

3-582 Vol. 2A LDDQU—Load Unaligned Integer 128 Bits
INSTRUCTION SET REFERENCE, A-M
data is 256/128-bit aligned or (V)MOVDQU store-load pairs when data is
256/128-bit unaligned.
•If the memory address is not aligned on 32/16-byte boundary, some implemen-
tations may load up to 64/32 bytes and return 32/16 bytes in the destination.
Some processor implementations may issue multiple loads to access the
appropriate 32/16 bytes. Developers of multi-threaded or multi-processor
software should be aware that on these processors the loads will be performed in
a non-atomic way.
•If alignment checking is enabled (CR0.AM = 1, RFLAGS.AC = 1, and CPL = 3), an
alignment-check exception (#AC) may or may not be generated (depending on
processor implementation) when the memory address is not aligned on an 8-byte
boundary.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
Note: In VEX-encoded versions, VEX.vvvv is reserved and must be 1111b otherwise
instructions will #UD.
Operation
LDDQU (128-bit Legacy SSE version)
DEST[127:0] SRC[127:0]
DEST[VLMAX-1:128] (Unmodified)
VLDDQU (VEX.128 encoded version)
DEST[127:0] SRC[127:0]
DEST[VLMAX-1:128] 0
VLDDQU (VEX.256 encoded version)
DEST[255:0] SRC[255:0]
Intel C/C++ Compiler Intrinsic Equivalent
LDDQU __m128i _mm_lddqu_si128 (__m128i * p);
LDDQU __m256i _mm256_lddqu_si256 (__m256i * p);
Numeric Exceptions
None.
Other Exceptions
See Exceptions Type 4;
Note treatment of #AC varies.

Vol. 2A 3-583
INSTRUCTION SET REFERENCE, A-M
LDMXCSR—Load MXCSR Register
LDMXCSR—Load MXCSR Register
Instruction Operand Encoding
Description
Loads the source operand into the MXCSR control/status register. The source
operand is a 32-bit memory location. See “MXCSR Control and Status Register” in
Chapter 10, of the Intel® 64 and IA-32 Architectures Software Developer’s Manual,
Volume 1, for a description of the MXCSR register and its contents.
The LDMXCSR instruction is typically used in conjunction with the (V)STMXCSR
instruction, which stores the contents of the MXCSR register in memory.
The default MXCSR value at reset is 1F80H.
If a (V)LDMXCSR instruction clears a SIMD floating-point exception mask bit and sets
the corresponding exception flag bit, a SIMD floating-point exception will not be
immediately generated. The exception will be generated only upon the execution of
the next instruction that meets both conditions below:
•the instruction must operate on an XMM or YMM register operand,
•the instruction causes that particular SIMD floating-point exception to be
reported.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
If VLDMXCSR is encoded with VEX.L= 1, an attempt to execute the instruction
encoded with VEX.L= 1 will cause an #UD exception.
Operation
MXCSR ← m32;
C/C++ Compiler Intrinsic Equivalent
_mm_setcsr(unsigned int i)
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
0F,AE,/2
LDMXCSR m32
A V/V SSE Load MXCSR register from
m32.
VEX.LZ.0F.WIG AE /2
VLDMXCSR m32
A V/V AVX Load MXCSR register from
m32.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (r) NA NA NA

3-584 Vol. 2A LDMXCSR—Load MXCSR Register
INSTRUCTION SET REFERENCE, A-M
Numeric Exceptions
None.
Other Exceptions
See Exceptions Type 9; additionally
#GP For an attempt to set reserved bits in MXCSR.

Vol. 2A 3-585
INSTRUCTION SET REFERENCE, A-M
LDS/LES/LFS/LGS/LSS—Load Far Pointer
LDS/LES/LFS/LGS/LSS—Load Far Pointer
Instruction Operand Encoding
Description
Loads a far pointer (segment selector and offset) from the second operand (source
operand) into a segment register and the first operand (destination operand). The
source operand specifies a 48-bit or a 32-bit pointer in memory depending on the
current setting of the operand-size attribute (32 bits or 16 bits, respectively). The
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
C5 /rLDS r16,m16:16 AInvalid Valid Load DS:r16 with far pointer
from memory.
C5 /rLDS r32,m16:32 AInvalid Valid Load DS:r32 with far pointer
from memory.
0F B2 /rLSS r16,m16:16 AValid Valid Load SS:r16 with far pointer
from memory.
0F B2 /rLSS r32,m16:32 AValid Valid Load SS:r32 with far pointer
from memory.
REX + 0F B2 /rLSS r64,m16:64 AValid N.E. Load SS:r64 with far pointer
from memory.
C4 /rLES r16,m16:16 A Invalid Valid Load ES:r16 with far pointer
from memory.
C4 /rLES r32,m16:32 A Invalid Valid Load ES:r32 with far pointer
from memory.
0F B4 /rLFS r16,m16:16 A Valid Valid Load FS:r16 with far pointer
from memory.
0F B4 /rLFS r32,m16:32 A Valid Valid Load FS:r32 with far pointer
from memory.
REX + 0F B4 /rLFS r64,m16:64 AValid N.E. Load FS:r64 with far pointer
from memory.
0F B5 /rLGS r16,m16:16 AValid Valid Load GS:r16 with far pointer
from memory.
0F B5 /rLGS r32,m16:32 AValid Valid Load GS:r32 with far pointer
from memory.
REX + 0F B5 /rLGS r64,m16:64 AValid N.E. Load GS:r64 with far pointer
from memory.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA

3-586 Vol. 2A LDS/LES/LFS/LGS/LSS—Load Far Pointer
INSTRUCTION SET REFERENCE, A-M
instruction opcode and the destination operand specify a segment register/general-
purpose register pair. The 16-bit segment selector from the source operand is loaded
into the segment register specified with the opcode (DS, SS, ES, FS, or GS). The
32-bit or 16-bit offset is loaded into the register specified with the destination
operand.
If one of these instructions is executed in protected mode, additional information
from the segment descriptor pointed to by the segment selector in the source
operand is loaded in the hidden part of the selected segment register.
Also in protected mode, a NULL selector (values 0000 through 0003) can be loaded
into DS, ES, FS, or GS registers without causing a protection exception. (Any subse-
quent reference to a segment whose corresponding segment register is loaded with
a NULL selector, causes a general-protection exception (#GP) and no memory refer-
ence to the segment occurs.)
In 64-bit mode, the instruction’s default operation size is 32 bits. Using a REX prefix
in the form of REX.W promotes operation to specify a source operand referencing an
80-bit pointer (16-bit selector, 64-bit offset) in memory. Using a REX prefix in the
form of REX.R permits access to additional registers (R8-R15). See the summary
chart at the beginning of this section for encoding data and limits.
Operation
64-BIT_MODE
IF SS is loaded
THEN
IF SegmentSelector = NULL and ( (RPL = 3) or
(RPL ≠ 3 and RPL ≠ CPL) )
THEN #GP(0);
ELSE IF descriptor is in non-canonical space
THEN #GP(0); FI;
ELSE IF Segment selector index is not within descriptor table limits
or segment selector RPL ≠ CPL
or access rights indicate nonwritable data segment
or DPL ≠ CPL
THEN #GP(selector); FI;
ELSE IF Segment marked not present
THEN #SS(selector); FI;
FI;
SS ← SegmentSelector(SRC);
SS ← SegmentDescriptor([SRC]);
ELSE IF attempt to load DS, or ES
THEN #UD;
ELSE IF FS, or GS is loaded with non-NULL segment selector
THEN IF Segment selector index is not within descriptor table limits
or access rights indicate segment neither data nor readable code segment

Vol. 2A 3-587
INSTRUCTION SET REFERENCE, A-M
LDS/LES/LFS/LGS/LSS—Load Far Pointer
or segment is data or nonconforming-code segment
and ( RPL > DPL or CPL > DPL)
THEN #GP(selector); FI;
ELSE IF Segment marked not present
THEN #NP(selector); FI;
FI;
SegmentRegister ← SegmentSelector(SRC) ;
SegmentRegister ← SegmentDescriptor([SRC]);
FI;
ELSE IF FS, or GS is loaded with a NULL selector:
THEN
SegmentRegister ← NULLSelector;
SegmentRegister(DescriptorValidBit) ← 0; FI; (* Hidden flag;
not accessible by software *)
FI;
DEST ← Offset(SRC);
PREOTECTED MODE OR COMPATIBILITY MODE;
IF SS is loaded
THEN
IF SegementSelector = NULL
THEN #GP(0);
ELSE IF Segment selector index is not within descriptor table limits
or segment selector RPL ≠ CPL
or access rights indicate nonwritable data segment
or DPL ≠ CPL
THEN #GP(selector); FI;
ELSE IF Segment marked not present
THEN #SS(selector); FI;
FI;
SS ← SegmentSelector(SRC);
SS ← SegmentDescriptor([SRC]);
ELSE IF DS, ES, FS, or GS is loaded with non-NULL segment selector
THEN IF Segment selector index is not within descriptor table limits
or access rights indicate segment neither data nor readable code segment
or segment is data or nonconforming-code segment
and (RPL > DPL or CPL > DPL)
THEN #GP(selector); FI;
ELSE IF Segment marked not present
THEN #NP(selector); FI;
FI;
SegmentRegister ← SegmentSelector(SRC) AND RPL;
SegmentRegister ← SegmentDescriptor([SRC]);
FI;

3-588 Vol. 2A LDS/LES/LFS/LGS/LSS—Load Far Pointer
INSTRUCTION SET REFERENCE, A-M
ELSE IF DS, ES, FS, or GS is loaded with a NULL selector:
THEN
SegmentRegister ← NULLSelector;
SegmentRegister(DescriptorValidBit) ← 0; FI; (* Hidden flag;
not accessible by software *)
FI;
DEST ← Offset(SRC);
Real-Address or Virtual-8086 Mode
SegmentRegister ← SegmentSelector(SRC); FI;
DEST ← Offset(SRC);
Flags Affected
None.
Protected Mode Exceptions
#UD If source operand is not a memory location.
If the LOCK prefix is used.
#GP(0) If a NULL selector is loaded into the SS register.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register is used to access memory and it
contains a NULL segment selector.
#GP(selector) If the SS register is being loaded and any of the following is true:
the segment selector index is not within the descriptor table
limits, the segment selector RPL is not equal to CPL, the
segment is a non-writable data segment, or DPL is not equal to
CPL.
If the DS, ES, FS, or GS register is being loaded with a non-NULL
segment selector and any of the following is true: the segment
selector index is not within descriptor table limits, the segment
is neither a data nor a readable code segment, or the segment is
a data or nonconforming-code segment and both RPL and CPL
are greater than DPL.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#SS(selector) If the SS register is being loaded and the segment is marked not
present.
#NP(selector) If DS, ES, FS, or GS register is being loaded with a non-NULL
segment selector and the segment is marked not present.
#PF(fault-code) If a page fault occurs.

Vol. 2A 3-589
INSTRUCTION SET REFERENCE, A-M
LDS/LES/LFS/LGS/LSS—Load Far Pointer
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#UD If source operand is not a memory location.
If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#UD If source operand is not a memory location.
If the LOCK prefix is used.
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#GP(0) If the memory address is in a non-canonical form.
If a NULL selector is attempted to be loaded into the SS register
in compatibility mode.
If a NULL selector is attempted to be loaded into the SS register
in CPL3 and 64-bit mode.
If a NULL selector is attempted to be loaded into the SS register
in non-CPL3 and 64-bit mode where its RPL is not equal to CPL.
#GP(Selector) If the FS, or GS register is being loaded with a non-NULL
segment selector and any of the following is true: the segment
selector index is not within descriptor table limits, the memory
address of the descriptor is non-canonical, the segment is
neither a data nor a readable code segment, or the segment is a
data or nonconforming-code segment and both RPL and CPL are
greater than DPL.

3-590 Vol. 2A LDS/LES/LFS/LGS/LSS—Load Far Pointer
INSTRUCTION SET REFERENCE, A-M
If the SS register is being loaded and any of the following is true:
the segment selector index is not within the descriptor table
limits, the memory address of the descriptor is non-canonical,
the segment selector RPL is not equal to CPL, the segment is a
nonwritable data segment, or DPL is not equal to CPL.
#SS(0) If a memory operand effective address is non-canonical
#SS(Selector) If the SS register is being loaded and the segment is marked not
present.
#NP(selector) If FS, or GS register is being loaded with a non-NULL segment
selector and the segment is marked not present.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If source operand is not a memory location.
If the LOCK prefix is used.
Vol. 2A 3-591
INSTRUCTION SET REFERENCE, A-M
LEA—Load Effective Address
LEA—Load Effective Address
Instruction Operand Encoding
Description
Computes the effective address of the second operand (the source operand) and
stores it in the first operand (destination operand). The source operand is a memory
address (offset part) specified with one of the processors addressing modes; the
destination operand is a general-purpose register. The address-size and operand-size
attributes affect the action performed by this instruction, as shown in the following
table. The operand-size attribute of the instruction is determined by the chosen
register; the address-size attribute is determined by the attribute of the code
segment.
Different assemblers may use different algorithms based on the size attribute and
symbolic reference of the source operand.
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
8D /rLEA r16,m A Valid Valid Store effective address for
m in register r16.
8D /rLEA r32,m A Valid Valid Store effective address for
m in register r32.
REX.W + 8D /rLEA r64,m A Valid N.E. Store effective address for
m in register r64.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA
Table 3-63. Non-64-bit Mode LEA Operation with Address and Operand Size
Attributes
Operand Size Address Size Action Performed
16 16 16-bit effective address is calculated and stored in
requested 16-bit register destination.
16 32 32-bit effective address is calculated. The lower 16 bits of
the address are stored in the requested 16-bit register
destination.
32 16 16-bit effective address is calculated. The 16-bit address is
zero-extended and stored in the requested 32-bit register
destination.
32 32 32-bit effective address is calculated and stored in the
requested 32-bit register destination.

3-592 Vol. 2A LEA—Load Effective Address
INSTRUCTION SET REFERENCE, A-M
In 64-bit mode, the instruction’s destination operand is governed by operand size
attribute, the default operand size is 32 bits. Address calculation is governed by
address size attribute, the default address size is 64-bits. In 64-bit mode, address
size of 16 bits is not encodable. See Table 3-64.
Operation
IF OperandSize = 16 and AddressSize = 16
THEN
DEST ← EffectiveAddress(SRC); (* 16-bit address *)
ELSE IF OperandSize = 16 and AddressSize = 32
THEN
temp ← EffectiveAddress(SRC); (* 32-bit address *)
DEST ← temp[0:15]; (* 16-bit address *)
FI;
ELSE IF OperandSize = 32 and AddressSize = 16
THEN
temp ← EffectiveAddress(SRC); (* 16-bit address *)
DEST ← ZeroExtend(temp); (* 32-bit address *)
FI;
ELSE IF OperandSize = 32 and AddressSize = 32
THEN
DEST ← EffectiveAddress(SRC); (* 32-bit address *)
Table 3-64. 64-bit Mode LEA Operation with Address and Operand Size Attributes
Operand Size Address Size Action Performed
16 32 32-bit effective address is calculated (using 67H prefix). The
lower 16 bits of the address are stored in the requested
16-bit register destination (using 66H prefix).
16 64 64-bit effective address is calculated (default address size).
The lower 16 bits of the address are stored in the requested
16-bit register destination (using 66H prefix).
32 32 32-bit effective address is calculated (using 67H prefix) and
stored in the requested 32-bit register destination.
32 64 64-bit effective address is calculated (default address size)
and the lower 32 bits of the address are stored in the
requested 32-bit register destination.
64 32 32-bit effective address is calculated (using 67H prefix),
zero-extended to 64-bits, and stored in the requested 64-
bit register destination (using REX.W).
64 64 64-bit effective address is calculated (default address size)
and all 64-bits of the address are stored in the requested
64-bit register destination (using REX.W).

Vol. 2A 3-593
INSTRUCTION SET REFERENCE, A-M
LEA—Load Effective Address
FI;
ELSE IF OperandSize = 16 and AddressSize = 64
THEN
temp ← EffectiveAddress(SRC); (* 64-bit address *)
DEST ← temp[0:15]; (* 16-bit address *)
FI;
ELSE IF OperandSize = 32 and AddressSize = 64
THEN
temp ← EffectiveAddress(SRC); (* 64-bit address *)
DEST ← temp[0:31]; (* 16-bit address *)
FI;
ELSE IF OperandSize = 64 and AddressSize = 64
THEN
DEST ← EffectiveAddress(SRC); (* 64-bit address *)
FI;
FI;
Flags Affected
None.
Protected Mode Exceptions
#UD If source operand is not a memory location.
If the LOCK prefix is used.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.
3-594 Vol. 2A LEAVE—High Level Procedure Exit
INSTRUCTION SET REFERENCE, A-M
LEAVE—High Level Procedure Exit
Instruction Operand Encoding
Description
Releases the stack frame set up by an earlier ENTER instruction. The LEAVE instruc-
tion copies the frame pointer (in the EBP register) into the stack pointer register
(ESP), which releases the stack space allocated to the stack frame. The old frame
pointer (the frame pointer for the calling procedure that was saved by the ENTER
instruction) is then popped from the stack into the EBP register, restoring the calling
procedure’s stack frame.
A RET instruction is commonly executed following a LEAVE instruction to return
program control to the calling procedure.
See “Procedure Calls for Block-Structured Languages” in Chapter 7 of the Intel® 64
and IA-32 Architectures Software Developer’s Manual, Volume 1, for detailed infor-
mation on the use of the ENTER and LEAVE instructions.
In 64-bit mode, the instruction’s default operation size is 64 bits; 32-bit operation
cannot be encoded. See the summary chart at the beginning of this section for
encoding data and limits.
Operation
IF StackAddressSize = 32
THEN
ESP ← EBP;
ELSE IF StackAddressSize = 64
THEN RSP ← RBP; FI;
ELSE IF StackAddressSize = 16
THEN SP ← BP; FI;
FI;
IF OperandSize = 32
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
C9 LEAVE A Valid Valid Set SP to BP, then pop BP.
C9 LEAVE A N.E. Valid Set ESP to EBP, then pop
EBP.
C9 LEAVE A Valid N.E. Set RSP to RBP, then pop
RBP.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA

Vol. 2A 3-595
INSTRUCTION SET REFERENCE, A-M
LEAVE—High Level Procedure Exit
THEN EBP ← Pop();
ELSE IF OperandSize = 64
THEN RBP ← Pop(); FI;
ELSE IF OperandSize = 16
THEN BP ← Pop(); FI;
FI;
Flags Affected
None.
Protected Mode Exceptions
#SS(0) If the EBP register points to a location that is not within the
limits of the current stack segment.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If the EBP register points to a location outside of the effective
address space from 0 to FFFFH.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If the EBP register points to a location outside of the effective
address space from 0 to FFFFH.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If the stack address is in a non-canonical form.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.

3-596 Vol. 2A LFENCE—Load Fence
INSTRUCTION SET REFERENCE, A-M
LFENCE—Load Fence
Instruction Operand Encoding
Description
Performs a serializing operation on all load-from-memory instructions that were
issued prior the LFENCE instruction. Specifically, LFENCE does not execute until all
prior instructions have completed locally, and no later instruction begins execution
until LFENCE completes. In particular, an instruction that loads from memory and
that precedes an LFENCE receives data from memory prior to completion of the
LFENCE. (An LFENCE that follows an instruction that stores to memory might
complete before the data being stored have become globally visible.) Instructions
following an LFENCE may be fetched from memory before the LFENCE, but they will
not execute until the LFENCE completes.
Weakly ordered memory types can be used to achieve higher processor performance
through such techniques as out-of-order issue and speculative reads. The degree to
which a consumer of data recognizes or knows that the data is weakly ordered varies
among applications and may be unknown to the producer of this data. The LFENCE
instruction provides a performance-efficient way of ensuring load ordering between
routines that produce weakly-ordered results and routines that consume that data.
Processors are free to fetch and cache data speculatively from regions of system
memory that use the WB, WC, and WT memory types. This speculative fetching can
occur at any time and is not tied to instruction execution. Thus, it is not ordered with
respect to executions of the LFENCE instruction; data can be brought into the caches
speculatively just before, during, or after the execution of an LFENCE instruction.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
Wait_On_Following_Instructions_Until(preceding_instructions_complete);
Intel C/C++ Compiler Intrinsic Equivalent
void _mm_lfence(void)
Exceptions (All Modes of Operation)
#UD If CPUID.01H:EDX.SSE2[bit 26] = 0.
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F AE /5 LFENCE A Valid Valid Serializes load operations.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA

Vol. 2A 3-597
INSTRUCTION SET REFERENCE, A-M
LFENCE—Load Fence
If the LOCK prefix is used.
3-598 Vol. 2A LGDT/LIDT—Load Global/Interrupt Descriptor Table Register
INSTRUCTION SET REFERENCE, A-M
LGDT/LIDT—Load Global/Interrupt Descriptor Table Register
Instruction Operand Encoding
Description
Loads the values in the source operand into the global descriptor table register
(GDTR) or the interrupt descriptor table register (IDTR). The source operand speci-
fies a 6-byte memory location that contains the base address (a linear address) and
the limit (size of table in bytes) of the global descriptor table (GDT) or the interrupt
descriptor table (IDT). If operand-size attribute is 32 bits, a 16-bit limit (lower 2
bytes of the 6-byte data operand) and a 32-bit base address (upper 4 bytes of the
data operand) are loaded into the register. If the operand-size attribute is 16 bits,
a 16-bit limit (lower 2 bytes) and a 24-bit base address (third, fourth, and fifth byte)
are loaded. Here, the high-order byte of the operand is not used and the high-order
byte of the base address in the GDTR or IDTR is filled with zeros.
The LGDT and LIDT instructions are used only in operating-system software; they are
not used in application programs. They are the only instructions that directly load a
linear address (that is, not a segment-relative address) and a limit in protected
mode. They are commonly executed in real-address mode to allow processor initial-
ization prior to switching to protected mode.
In 64-bit mode, the instruction’s operand size is fixed at 8+2 bytes (an 8-byte base
and a 2-byte limit). See the summary chart at the beginning of this section for
encoding data and limits.
See “SGDT—Store Global Descriptor Table Register” in Chapter 4, Intel® 64 and
IA-32 Architectures Software Developer’s Manual, Volume 2B, for information on
storing the contents of the GDTR and IDTR.
Operation
IF Instruction is LIDT
THEN
IF OperandSize = 16
THEN
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F 01 /2 LGDT m16&32 A N.E. Valid Load m into GDTR.
0F 01 /3 LIDT m16&32 A N.E. Valid Load m into IDTR.
0F 01 /2 LGDT m16&64 AValid N.E. Load m into GDTR.
0F 01 /3 LIDT m16&64 AValid N.E. Load m into IDTR.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (r) NA NA NA

Vol. 2A 3-599
INSTRUCTION SET REFERENCE, A-M
LGDT/LIDT—Load Global/Interrupt Descriptor Table Register
IDTR(Limit) ← SRC[0:15];
IDTR(Base) ← SRC[16:47] AND 00FFFFFFH;
ELSE IF 32-bit Operand Size
THEN
IDTR(Limit) ← SRC[0:15];
IDTR(Base) ← SRC[16:47];
FI;
ELSE IF 64-bit Operand Size (* In 64-Bit Mode *)
THEN
IDTR(Limit) ← SRC[0:15];
IDTR(Base) ← SRC[16:79];
FI;
FI;
ELSE (* Instruction is LGDT *)
IF OperandSize = 16
THEN
GDTR(Limit) ← SRC[0:15];
GDTR(Base) ← SRC[16:47] AND 00FFFFFFH;
ELSE IF 32-bit Operand Size
THEN
GDTR(Limit) ← SRC[0:15];
GDTR(Base) ← SRC[16:47];
FI;
ELSE IF 64-bit Operand Size (* In 64-Bit Mode *)
THEN
GDTR(Limit) ← SRC[0:15];
GDTR(Base) ← SRC[16:79];
FI;
FI;
FI;
Flags Affected
None.
Protected Mode Exceptions
#UD If source operand is not a memory location.
If the LOCK prefix is used.
#GP(0) If the current privilege level is not 0.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register is used to access memory and it
contains a NULL segment selector.

3-600 Vol. 2A LGDT/LIDT—Load Global/Interrupt Descriptor Table Register
INSTRUCTION SET REFERENCE, A-M
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
Real-Address Mode Exceptions
#UD If source operand is not a memory location.
If the LOCK prefix is used.
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
Virtual-8086 Mode Exceptions
#UD If source operand is not a memory location.
If the LOCK prefix is used.
#GP(0) The LGDT and LIDT instructions are not recognized in virtual-
8086 mode.
#GP If the current privilege level is not 0.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the current privilege level is not 0.
If the memory address is in a non-canonical form.
#UD If source operand is not a memory location.
If the LOCK prefix is used.
#PF(fault-code) If a page fault occurs.

Vol. 2A 3-601
INSTRUCTION SET REFERENCE, A-M
LLDT—Load Local Descriptor Table Register
LLDT—Load Local Descriptor Table Register
Instruction Operand Encoding
Description
Loads the source operand into the segment selector field of the local descriptor table
register (LDTR). The source operand (a general-purpose register or a memory loca-
tion) contains a segment selector that points to a local descriptor table (LDT). After
the segment selector is loaded in the LDTR, the processor uses the segment selector
to locate the segment descriptor for the LDT in the global descriptor table (GDT). It
then loads the segment limit and base address for the LDT from the segment
descriptor into the LDTR. The segment registers DS, ES, SS, FS, GS, and CS are not
affected by this instruction, nor is the LDTR field in the task state segment (TSS) for
the current task.
If bits 2-15 of the source operand are 0, LDTR is marked invalid and the LLDT instruc-
tion completes silently. However, all subsequent references to descriptors in the LDT
(except by the LAR, VERR, VERW or LSL instructions) cause a general protection
exception (#GP).
The operand-size attribute has no effect on this instruction.
The LLDT instruction is provided for use in operating-system software; it should not
be used in application programs. This instruction can only be executed in protected
mode or 64-bit mode.
In 64-bit mode, the operand size is fixed at 16 bits.
Operation
IF SRC(Offset) > descriptor table limit
THEN #GP(segment selector); FI;
IF segment selector is valid
Read segment descriptor;
IF SegmentDescriptor(Type) ≠ LDT
THEN #GP(segment selector); FI;
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F 00 /2 LLDT r/m16 A Valid Valid Load segment selector
r/m16 into LDTR.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (r) NA NA NA

3-602 Vol. 2A LLDT—Load Local Descriptor Table Register
INSTRUCTION SET REFERENCE, A-M
IF segment descriptor is not present
THEN #NP(segment selector); FI;
LDTR(SegmentSelector) ← SRC;
LDTR(SegmentDescriptor) ← GDTSegmentDescriptor;
ELSE LDTR ← INVALID
FI;
Flags Affected
None.
Protected Mode Exceptions
#GP(0) If the current privilege level is not 0.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#GP(selector) If the selector operand does not point into the Global Descriptor
Table or if the entry in the GDT is not a Local Descriptor Table.
Segment selector is beyond GDT limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#NP(selector) If the LDT descriptor is not present.
#PF(fault-code) If a page fault occurs.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#UD The LLDT instruction is not recognized in real-address mode.
Virtual-8086 Mode Exceptions
#UD The LLDT instruction is not recognized in virtual-8086 mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the current privilege level is not 0.
If the memory address is in a non-canonical form.

Vol. 2A 3-603
INSTRUCTION SET REFERENCE, A-M
LLDT—Load Local Descriptor Table Register
#GP(selector) If the selector operand does not point into the Global Descriptor
Table or if the entry in the GDT is not a Local Descriptor Table.
Segment selector is beyond GDT limit.
#NP(selector) If the LDT descriptor is not present.
#PF(fault-code) If a page fault occurs.
#UD If the LOCK prefix is used.

3-604 Vol. 2A LMSW—Load Machine Status Word
INSTRUCTION SET REFERENCE, A-M
LMSW—Load Machine Status Word
Instruction Operand Encoding
Description
Loads the source operand into the machine status word, bits 0 through 15 of register
CR0. The source operand can be a 16-bit general-purpose register or a memory loca-
tion. Only the low-order 4 bits of the source operand (which contains the PE, MP, EM,
and TS flags) are loaded into CR0. The PG, CD, NW, AM, WP, NE, and ET flags of CR0
are not affected. The operand-size attribute has no effect on this instruction.
If the PE flag of the source operand (bit 0) is set to 1, the instruction causes the
processor to switch to protected mode. While in protected mode, the LMSW instruc-
tion cannot be used to clear the PE flag and force a switch back to real-address mode.
The LMSW instruction is provided for use in operating-system software; it should not
be used in application programs. In protected or virtual-8086 mode, it can only be
executed at CPL 0.
This instruction is provided for compatibility with the Intel 286 processor; programs
and procedures intended to run on the Pentium 4, Intel Xeon, P6 family, Pentium,
Intel486, and Intel386 processors should use the MOV (control registers) instruction
to load the whole CR0 register. The MOV CR0 instruction can be used to set and clear
the PE flag in CR0, allowing a procedure or program to switch between protected and
real-address modes.
This instruction is a serializing instruction.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode. Note
that the operand size is fixed at 16 bits.
See “Changes to Instruction Behavior in VMX Non-Root Operation” in Chapter 22 of
the Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 3B, for
more information about the behavior of this instruction in VMX non-root operation.
Operation
CR0[0:3] ← SRC[0:3];
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F 01 /6 LMSW r/m16 A Valid Valid Loads r/m16 in machine
status word of CR0.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (r) NA NA NA

Vol. 2A 3-605
INSTRUCTION SET REFERENCE, A-M
LMSW—Load Machine Status Word
Flags Affected
None.
Protected Mode Exceptions
#GP(0) If the current privilege level is not 0.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register is used to access memory and it
contains a NULL segment selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the current privilege level is not 0.
If the memory address is in a non-canonical form.
#PF(fault-code) If a page fault occurs.
#UD If the LOCK prefix is used.
3-606 Vol. 2A LOCK—Assert LOCK# Signal Prefix
INSTRUCTION SET REFERENCE, A-M
LOCK—Assert LOCK# Signal Prefix
Instruction Operand Encoding
Description
Causes the processor’s LOCK# signal to be asserted during execution of the accom-
panying instruction (turns the instruction into an atomic instruction). In a multipro-
cessor environment, the LOCK# signal ensures that the processor has exclusive use
of any shared memory while the signal is asserted.
Note that, in later Intel 64 and IA-32 processors (including the Pentium 4, Intel Xeon,
and P6 family processors), locking may occur without the LOCK# signal being
asserted. See the “IA-32 Architecture Compatibility” section below.
The LOCK prefix can be prepended only to the following instructions and only to those
forms of the instructions where the destination operand is a memory operand: ADD,
ADC, AND, BTC, BTR, BTS, CMPXCHG, CMPXCH8B, DEC, INC, NEG, NOT, OR, SBB,
SUB, XOR, XADD, and XCHG. If the LOCK prefix is used with one of these instructions
and the source operand is a memory operand, an undefined opcode exception (#UD)
may be generated. An undefined opcode exception will also be generated if the LOCK
prefix is used with any instruction not in the above list. The XCHG instruction always
asserts the LOCK# signal regardless of the presence or absence of the LOCK prefix.
The LOCK prefix is typically used with the BTS instruction to perform a read-modify-
write operation on a memory location in shared memory environment.
The integrity of the LOCK prefix is not affected by the alignment of the memory field.
Memory locking is observed for arbitrarily misaligned fields.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
IA-32 Architecture Compatibility
Beginning with the P6 family processors, when the LOCK prefix is prefixed to an
instruction and the memory area being accessed is cached internally in the
processor, the LOCK# signal is generally not asserted. Instead, only the processor’s
cache is locked. Here, the processor’s cache coherency mechanism ensures that the
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
F0 LOCK A Valid Valid Asserts LOCK# signal for
duration of the
accompanying instruction.
NOTES:
* See IA-32 Architecture Compatibility section below.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA

Vol. 2A 3-607
INSTRUCTION SET REFERENCE, A-M
LOCK—Assert LOCK# Signal Prefix
operation is carried out atomically with regards to memory. See “Effects of a Locked
Operation on Internal Processor Caches” in Chapter 8 of Intel® 64 and IA-32 Archi-
tectures Software Developer’s Manual, Volume 3A, the for more information on
locking of caches.
Operation
AssertLOCK#(DurationOfAccompaningInstruction);
Flags Affected
None.
Protected Mode Exceptions
#UD If the LOCK prefix is used with an instruction not listed: ADD,
ADC, AND, BTC, BTR, BTS, CMPXCHG, CMPXCH8B, DEC, INC,
NEG, NOT, OR, SBB, SUB, XOR, XADD, XCHG.
Other exceptions can be generated by the instruction when the
LOCK prefix is applied.
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.

3-608 Vol. 2A LODS/LODSB/LODSW/LODSD/LODSQ—Load String
INSTRUCTION SET REFERENCE, A-M
LODS/LODSB/LODSW/LODSD/LODSQ—Load String
Instruction Operand Encoding
Description
Loads a byte, word, or doubleword from the source operand into the AL, AX, or EAX
register, respectively. The source operand is a memory location, the address of which
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
AC LODS m8 A Valid Valid For legacy mode, Load byte
at address DS:(E)SI into AL.
For 64-bit mode load byte
at address (R)SI into AL.
AD LODS m16 A Valid Valid For legacy mode, Load word
at address DS:(E)SI into AX.
For 64-bit mode load word
at address (R)SI into AX.
AD LODS m32 A Valid Valid For legacy mode, Load
dword at address DS:(E)SI
into EAX. For 64-bit mode
load dword at address (R)SI
into EAX.
REX.W + AD LODS m64 A Valid N.E. Load qword at address (R)SI
into RAX.
AC LODSB A Valid Valid For legacy mode, Load byte
at address DS:(E)SI into AL.
For 64-bit mode load byte
at address (R)SI into AL.
AD LODSW A Valid Valid For legacy mode, Load word
at address DS:(E)SI into AX.
For 64-bit mode load word
at address (R)SI into AX.
AD LODSD A Valid Valid For legacy mode, Load
dword at address DS:(E)SI
into EAX. For 64-bit mode
load dword at address (R)SI
into EAX.
REX.W + AD LODSQ A Valid N.E. Load qword at address (R)SI
into RAX.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA

Vol. 2A 3-609
INSTRUCTION SET REFERENCE, A-M
LODS/LODSB/LODSW/LODSD/LODSQ—Load String
is read from the DS:ESI or the DS:SI registers (depending on the address-size
attribute of the instruction, 32 or 16, respectively). The DS segment may be over-
ridden with a segment override prefix.
At the assembly-code level, two forms of this instruction are allowed: the “explicit-
operands” form and the “no-operands” form. The explicit-operands form (specified
with the LODS mnemonic) allows the source operand to be specified explicitly. Here,
the source operand should be a symbol that indicates the size and location of the
source value. The destination operand is then automatically selected to match the
size of the source operand (the AL register for byte operands, AX for word operands,
and EAX for doubleword operands). This explicit-operands form is provided to allow
documentation; however, note that the documentation provided by this form can be
misleading. That is, the source operand symbol must specify the correct type (size)
of the operand (byte, word, or doubleword), but it does not have to specify the
correct location. The location is always specified by the DS:(E)SI registers, which
must be loaded correctly before the load string instruction is executed.
The no-operands form provides “short forms” of the byte, word, and doubleword
versions of the LODS instructions. Here also DS:(E)SI is assumed to be the source
operand and the AL, AX, or EAX register is assumed to be the destination operand.
The size of the source and destination operands is selected with the mnemonic:
LODSB (byte loaded into register AL), LODSW (word loaded into AX), or LODSD
(doubleword loaded into EAX).
After the byte, word, or doubleword is transferred from the memory location into the
AL, AX, or EAX register, the (E)SI register is incremented or decremented automati-
cally according to the setting of the DF flag in the EFLAGS register. (If the DF flag is
0, the (E)SI register is incremented; if the DF flag is 1, the ESI register is decre-
mented.) The (E)SI register is incremented or decremented by 1 for byte operations,
by 2 for word operations, or by 4 for doubleword operations.
In 64-bit mode, use of the REX.W prefix promotes operation to 64 bits. LODS/LODSQ
load the quadword at address (R)SI into RAX. The (R)SI register is then incremented
or decremented automatically according to the setting of the DF flag in the EFLAGS
register.
The LODS, LODSB, LODSW, and LODSD instructions can be preceded by the REP
prefix for block loads of ECX bytes, words, or doublewords. More often, however,
these instructions are used within a LOOP construct because further processing of
the data moved into the register is usually necessary before the next transfer can be
made. See “REP/REPE/REPZ /REPNE/REPNZ—Repeat String Operation Prefix” in
Chapter 4 of the Intel® 64 and IA-32 Architectures Software Developer’s Manual,
Volume 2B, for a description of the REP prefix.
Operation
IF AL ← SRC; (* Byte load *)
THEN AL ← SRC; (* Byte load *)
IF DF = 0
THEN (E)SI ← (E)SI + 1;

3-610 Vol. 2A LODS/LODSB/LODSW/LODSD/LODSQ—Load String
INSTRUCTION SET REFERENCE, A-M
ELSE (E)SI ← (E)SI – 1;
FI;
ELSE IF AX ← SRC; (* Word load *)
THEN IF DF = 0
THEN (E)SI ← (E)SI + 2;
ELSE (E)SI ← (E)SI – 2;
IF;
FI;
ELSE IF EAX ← SRC; (* Doubleword load *)
THEN IF DF = 0
THEN (E)SI ← (E)SI + 4;
ELSE (E)SI ← (E)SI – 4;
FI;
FI;
ELSE IF RAX ← SRC; (* Quadword load *)
THEN IF DF = 0
THEN (R)SI ← (R)SI + 8;
ELSE (R)SI ← (R)SI – 8;
FI;
FI;
FI;
Flags Affected
None.
Protected Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.

Vol. 2A 3-611
INSTRUCTION SET REFERENCE, A-M
LODS/LODSB/LODSW/LODSD/LODSQ—Load String
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.

3-612 Vol. 2A LOOP/LOOPcc—Loop According to ECX Counter
INSTRUCTION SET REFERENCE, A-M
LOOP/LOOPcc—Loop According to ECX Counter
Instruction Operand Encoding
Description
Performs a loop operation using the RCX, ECX or CX register as a counter (depending
on whether address size is 64 bits, 32 bits, or 16 bits). Note that the LOOP instruction
ignores REX.W; but 64-bit address size can be over-ridden using a 67H prefix.
Each time the LOOP instruction is executed, the count register is decremented, then
checked for 0. If the count is 0, the loop is terminated and program execution
continues with the instruction following the LOOP instruction. If the count is not zero,
a near jump is performed to the destination (target) operand, which is presumably
the instruction at the beginning of the loop.
The target instruction is specified with a relative offset (a signed offset relative to the
current value of the instruction pointer in the IP/EIP/RIP register). This offset is
generally specified as a label in assembly code, but at the machine code level, it is
encoded as a signed, 8-bit immediate value, which is added to the instruction pointer.
Offsets of –128 to +127 are allowed with this instruction.
Some forms of the loop instruction (LOOPcc) also accept the ZF flag as a condition for
terminating the loop before the count reaches zero. With these forms of the instruc-
tion, a condition code (cc) is associated with each instruction to indicate the condition
being tested for. Here, the LOOPcc instruction itself does not affect the state of the ZF
flag; the ZF flag is changed by other instructions in the loop.
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
E2 cb LOOP rel8 A Valid Valid Decrement count; jump
short if count ≠ 0.
E1 cb LOOPE rel8 A Valid Valid Decrement count; jump
short if count ≠ 0 and ZF =
1.
E0 cb LOOPNE rel8 A Valid Valid Decrement count; jump
short if count ≠ 0 and ZF =
0.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
AOffset NA NA NA

Vol. 2A 3-613
INSTRUCTION SET REFERENCE, A-M
LOOP/LOOPcc—Loop According to ECX Counter
Operation
IF (AddressSize = 32)
THEN Count is ECX;
ELSE IF (AddressSize = 64)
Count is RCX;
ELSE Count is CX;
FI;
Count ← Count – 1;
IF Instruction is not LOOP
THEN
IF (Instruction ← LOOPE) or (Instruction ← LOOPZ)
THEN IF (ZF = 1) and (Count ≠ 0)
THEN BranchCond ← 1;
ELSE BranchCond ← 0;
FI;
ELSE (Instruction = LOOPNE) or (Instruction = LOOPNZ)
IF (ZF = 0 ) and (Count ≠ 0)
THEN BranchCond ← 1;
ELSE BranchCond ← 0;
FI;
FI;
ELSE (* Instruction = LOOP *)
IF (Count ≠ 0)
THEN BranchCond ← 1;
ELSE BranchCond ← 0;
FI;
FI;
IF BranchCond = 1
THEN
IF OperandSize = 32
THEN EIP ← EIP + SignExtend(DEST);
ELSE IF OperandSize = 64
THEN RIP ← RIP + SignExtend(DEST);
FI;
ELSE IF OperandSize = 16
THEN EIP ← EIP AND 0000FFFFH;
FI;
ELSE IF OperandSize = (32 or 64)
THEN IF (R/E)IP < CS.Base or (R/E)IP > CS.Limit
#GP; FI;
FI;

3-614 Vol. 2A LOOP/LOOPcc—Loop According to ECX Counter
INSTRUCTION SET REFERENCE, A-M
FI;
ELSE
Terminate loop and continue program execution at (R/E)IP;
FI;
Flags Affected
None.
Protected Mode Exceptions
#GP(0) If the offset being jumped to is beyond the limits of the CS
segment.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If the offset being jumped to is beyond the limits of the CS
segment or is outside of the effective address space from 0 to
FFFFH. This condition can occur if a 32-bit address size override
prefix is used.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
Same exceptions as in real address mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#GP(0) If the offset being jumped to is in a non-canonical form.
#UD If the LOCK prefix is used.

Vol. 2A 3-615
INSTRUCTION SET REFERENCE, A-M
LSL—Load Segment Limit
LSL—Load Segment Limit
Instruction Operand Encoding
Description
Loads the unscrambled segment limit from the segment descriptor specified with the
second operand (source operand) into the first operand (destination operand) and
sets the ZF flag in the EFLAGS register. The source operand (which can be a register
or a memory location) contains the segment selector for the segment descriptor
being accessed. The destination operand is a general-purpose register.
The processor performs access checks as part of the loading process. Once loaded in
the destination register, software can compare the segment limit with the offset of a
pointer.
The segment limit is a 20-bit value contained in bytes 0 and 1 and in the first 4 bits
of byte 6 of the segment descriptor. If the descriptor has a byte granular segment
limit (the granularity flag is set to 0), the destination operand is loaded with a byte
granular value (byte limit). If the descriptor has a page granular segment limit (the
granularity flag is set to 1), the LSL instruction will translate the page granular limit
(page limit) into a byte limit before loading it into the destination operand. The trans-
lation is performed by shifting the 20-bit “raw” limit left 12 bits and filling the low-
order 12 bits with 1s.
When the operand size is 32 bits, the 32-bit byte limit is stored in the destination
operand. When the operand size is 16 bits, a valid 32-bit limit is computed; however,
the upper 16 bits are truncated and only the low-order 16 bits are loaded into the
destination operand.
This instruction performs the following checks before it loads the segment limit into
the destination register:
•Checks that the segment selector is not NULL.
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F 03 /rLSL r16, r16/m16 AValid Valid Load: r16 ← segment limit,
selector r16/m16.
0F 03 /rLSL r32, r32/m16*AValid Valid Load: r32 ← segment limit,
selector r32/m16.
REX.W + 0F 03
/r
LSL r64, r32/m16*AValid Valid Load: r64 ← segment limit,
selector r32/m16
NOTES:
* For all loads (regardless of destination sizing), only bits 16-0 are used. Other bits are ignored.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA

3-616 Vol. 2A LSL—Load Segment Limit
INSTRUCTION SET REFERENCE, A-M
•Checks that the segment selector points to a descriptor that is within the limits of
the GDT or LDT being accessed
•Checks that the descriptor type is valid for this instruction. All code and data
segment descriptors are valid for (can be accessed with) the LSL instruction. The
valid special segment and gate descriptor types are given in the following table.
•If the segment is not a conforming code segment, the instruction checks that the
specified segment descriptor is visible at the CPL (that is, if the CPL and the RPL
of the segment selector are less than or equal to the DPL of the segment
selector).
If the segment descriptor cannot be accessed or is an invalid type for the instruction,
the ZF flag is cleared and no value is loaded in the destination operand.
Table 3-65. Segment and Gate Descriptor Types
Type Protected Mode IA-32e Mode
Name Valid Name Valid
0Reserved No Upper 8 byte of a 16-
Byte descriptor
Yes
1Available 16-bit TSS Yes Reserved No
2LDT Yes LDT Yes
3Busy 16-bit TSS Yes Reserved No
416-bit call gate No Reserved No
516-bit/32-bit task
gate
No Reserved No
616-bit interrupt gate No Reserved No
716-bit trap gate No Reserved No
8Reserved No Reserved No
9Available 32-bit TSS Yes 64-bit TSS Yes
AReserved No Reserved No
BBusy 32-bit TSS Yes Busy 64-bit TSS Yes
C32-bit call gate No 64-bit call gate No
DReserved No Reserved No
E32-bit interrupt gate No 64-bit interrupt gate No
F32-bit trap gate No 64-bit trap gate No

Vol. 2A 3-617
INSTRUCTION SET REFERENCE, A-M
LSL—Load Segment Limit
Operation
IF SRC(Offset) > descriptor table limit
THEN ZF ← 0; FI;
Read segment descriptor;
IF SegmentDescriptor(Type) ≠ conforming code segment
and (CPL > DPL) OR (RPL > DPL)
or Segment type is not valid for instruction
THEN
ZF ← 0;
ELSE
temp ← SegmentLimit([SRC]);
IF (G ← 1)
THEN temp ← ShiftLeft(12, temp) OR 00000FFFH;
ELSE IF OperandSize = 32
THEN DEST ← temp; FI;
ELSE IF OperandSize = 64 (* REX.W used *)
THEN DEST (* Zero-extended *) ← temp; FI;
ELSE (* OperandSize = 16 *)
DEST ← temp AND FFFFH;
FI;
FI;
Flags Affected
The ZF flag is set to 1 if the segment limit is loaded successfully; otherwise, it is set
to 0.
Protected Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register is used to access memory and it
contains a NULL segment selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and the memory operand effec-
tive address is unaligned while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#UD The LSL instruction cannot be executed in real-address mode.

3-618 Vol. 2A LSL—Load Segment Limit
INSTRUCTION SET REFERENCE, A-M
Virtual-8086 Mode Exceptions
#UD The LSL instruction cannot be executed in virtual-8086 mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If the memory operand effective address referencing the SS
segment is in a non-canonical form.
#GP(0) If the memory operand effective address is in a non-canonical
form.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and the memory operand effec-
tive address is unaligned while the current privilege level is 3.
#UD If the LOCK prefix is used.

Vol. 2A 3-619
INSTRUCTION SET REFERENCE, A-M
LTR—Load Task Register
LTR—Load Task Register
Instruction Operand Encoding
Description
Loads the source operand into the segment selector field of the task register. The
source operand (a general-purpose register or a memory location) contains a
segment selector that points to a task state segment (TSS). After the segment
selector is loaded in the task register, the processor uses the segment selector to
locate the segment descriptor for the TSS in the global descriptor table (GDT). It then
loads the segment limit and base address for the TSS from the segment descriptor
into the task register. The task pointed to by the task register is marked busy, but a
switch to the task does not occur.
The LTR instruction is provided for use in operating-system software; it should not be
used in application programs. It can only be executed in protected mode when the
CPL is 0. It is commonly used in initialization code to establish the first task to be
executed.
The operand-size attribute has no effect on this instruction.
In 64-bit mode, the operand size is still fixed at 16 bits. The instruction references a
16-byte descriptor to load the 64-bit base.
Operation
IF SRC is a NULL selector
THEN #GP(0);
IF SRC(Offset) > descriptor table limit OR IF SRC(type) ≠ global
THEN #GP(segment selector); FI;
Read segment descriptor;
IF segment descriptor is not for an available TSS
THEN #GP(segment selector); FI;
IF segment descriptor is not present
THEN #NP(segment selector); FI;
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F 00 /3 LTR r/m16 A Valid Valid Load r/m16 into task
register.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (r) NA NA NA

3-620 Vol. 2A LTR—Load Task Register
INSTRUCTION SET REFERENCE, A-M
TSSsegmentDescriptor(busy) ← 1;
(* Locked read-modify-write operation on the entire descriptor when setting busy flag *)
TaskRegister(SegmentSelector) ← SRC;
TaskRegister(SegmentDescriptor) ← TSSSegmentDescriptor;
Flags Affected
None.
Protected Mode Exceptions
#GP(0) If the current privilege level is not 0.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the source operand contains a NULL segment selector.
If the DS, ES, FS, or GS register is used to access memory and it
contains a NULL segment selector.
#GP(selector) If the source selector points to a segment that is not a TSS or to
one for a task that is already busy.
If the selector points to LDT or is beyond the GDT limit.
#NP(selector) If the TSS is marked not present.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#UD The LTR instruction is not recognized in real-address mode.
Virtual-8086 Mode Exceptions
#UD The LTR instruction is not recognized in virtual-8086 mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the current privilege level is not 0.
If the memory address is in a non-canonical form.
If the source operand contains a NULL segment selector.

Vol. 2A 3-621
INSTRUCTION SET REFERENCE, A-M
LTR—Load Task Register
#GP(selector) If the source selector points to a segment that is not a TSS or to
one for a task that is already busy.
If the selector points to LDT or is beyond the GDT limit.
If the descriptor type of the upper 8-byte of the 16-byte
descriptor is non-zero.
#NP(selector) If the TSS is marked not present.
#PF(fault-code) If a page fault occurs.
#UD If the LOCK prefix is used.

3-622 Vol. 2A MASKMOVDQU—Store Selected Bytes of Double Quadword
INSTRUCTION SET REFERENCE, A-M
MASKMOVDQU—Store Selected Bytes of Double Quadword
Instruction Operand Encoding1
Description
Stores selected bytes from the source operand (first operand) into an 128-bit
memory location. The mask operand (second operand) selects which bytes from the
source operand are written to memory. The source and mask operands are XMM
registers. The location of the first byte of the memory location is specified by DI/EDI
and DS registers. The memory location does not need to be aligned on a natural
boundary. (The size of the store address depends on the address-size attribute.)
The most significant bit in each byte of the mask operand determines whether the
corresponding byte in the source operand is written to the corresponding byte loca-
tion in memory: 0 indicates no write and 1 indicates write.
The MASKMOVDQU instruction generates a non-temporal hint to the processor to
minimize cache pollution. The non-temporal hint is implemented by using a write
combining (WC) memory type protocol (see “Caching of Temporal vs. Non-Temporal
Data” in Chapter 10, of the Intel® 64 and IA-32 Architectures Software Developer’s
Manual, Volume 1). Because the WC protocol uses a weakly-ordered memory consis-
tency model, a fencing operation implemented with the SFENCE or MFENCE instruc-
tion should be used in conjunction with MASKMOVDQU instructions if multiple
processors might use different memory types to read/write the destination memory
locations.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F F7 /r
MASKMOVDQU xmm1, xmm2
A V/V SSE2 Selectively write bytes from
xmm1 to memory location
using the byte mask in
xmm2. The default memory
location is specified by
DS:EDI/RDI.
VEX.128.66.0F.WIG F7 /r
VMASKMOVDQU xmm1, xmm2
A V/V AVX Selectively write bytes from
xmm1 to memory location
using the byte mask in
xmm2. The default memory
location is specified by
DS:DI/EDI/RDI.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r) ModRM:r/m (r) NA NA
1.ModRM.MOD = 011B required

Vol. 2A 3-623
INSTRUCTION SET REFERENCE, A-M
MASKMOVDQU—Store Selected Bytes of Double Quadword
Behavior with a mask of all 0s is as follows:
•No data will be written to memory.
•Signaling of breakpoints (code or data) is not guaranteed; different processor
implementations may signal or not signal these breakpoints.
•Exceptions associated with addressing memory and page faults may still be
signaled (implementation dependent).
•If the destination memory region is mapped as UC or WP, enforcement of
associated semantics for these memory types is not guaranteed (that is, is
reserved) and is implementation-specific.
The MASKMOVDQU instruction can be used to improve performance of algorithms
that need to merge data on a byte-by-byte basis. MASKMOVDQU should not cause a
read for ownership; doing so generates unnecessary bandwidth since data is to be
written directly using the byte-mask without allocating old data prior to the store.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
Note: In VEX-encoded versions, VEX.vvvv is reserved and must be 1111b otherwise
instructions will #UD.
If VMASKMOVDQU is encoded with VEX.L= 1, an attempt to execute the instruction
encoded with VEX.L= 1 will cause an #UD exception.
Operation
IF (MASK[7] = 1)
THEN DEST[DI/EDI] ← SRC[7:0] ELSE (* Memory location unchanged *); FI;
IF (MASK[15] = 1)
THEN DEST[DI/EDI +1] ← SRC[15:8] ELSE (* Memory location unchanged *); FI;
(* Repeat operation for 3rd through 14th bytes in source operand *)
IF (MASK[127] = 1)
THEN DEST[DI/EDI +15] ← SRC[127:120] ELSE (* Memory location unchanged *); FI;
Intel C/C++ Compiler Intrinsic Equivalent
void _mm_maskmoveu_si128(__m128i d, __m128i n, char * p)
Other Exceptions
See Exceptions Type 4; additionally
#UD If VEX.L= 1
If VEX.vvvv != 1111B.

3-624 Vol. 2A VMASKMOV—Conditional SIMD Packed Loads and Stores
INSTRUCTION SET REFERENCE, A-M
VMASKMOV—Conditional SIMD Packed Loads and Stores
Instruction Operand Encoding
Description
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
VEX.NDS.128.66.0F38.W0 2C /r
VMASKMOVPS xmm1, xmm2, m128
A V/V AVX Conditionally load packed
single-precision values from
m128 using mask in xmm2
and store in xmm1.
VEX.NDS.256.66.0F38.W0 2C /r
VMASKMOVPS ymm1, ymm2, m256
A V/V AVX Conditionally load packed
single-precision values from
m256 using mask in ymm2
and store in ymm1.
VEX.NDS.128.66.0F38.W0 2D /r
VMASKMOVPD xmm1, xmm2, m128
A V/V AVX Conditionally load packed
double-precision values
from m128 using mask in
xmm2 and store in xmm1.
VEX.NDS.256.66.0F38.W0 2D /r
VMASKMOVPD ymm1, ymm2, m256
A V/V AVX Conditionally load packed
double-precision values
from m256 using mask in
ymm2 and store in ymm1.
VEX.NDS.128.66.0F38.W0 2E /r
VMASKMOVPS m128, xmm1, xmm2
B V/V AVX Conditionally store packed
single-precision values from
xmm2 using mask in xmm1.
VEX.NDS.256.66.0F38.W0 2E /r
VMASKMOVPS m256, ymm1, ymm2
B V/V AVX Conditionally store packed
single-precision values from
ymm2 using mask in ymm1.
VEX.NDS.128.66.0F38.W0 2F /r
VMASKMOVPD m128, xmm1, xmm2
B V/V AVX Conditionally store packed
double-precision values
from xmm2 using mask in
xmm1.
VEX.NDS.256.66.0F38.W0 2F /r
VMASKMOVPD m256, ymm1, ymm2
B V/V AVX Conditionally store packed
double-precision values
from ymm2 using mask in
ymm1.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA
B ModRM:r/m (w) VEX.vvvv (r) ModRM:r/m (r) NA

Vol. 2A 3-625
INSTRUCTION SET REFERENCE, A-M
VMASKMOV—Conditional SIMD Packed Loads and Stores
Conditionally moves packed data elements from the second source operand into the
corresponding data element of the destination operand, depending on the mask bits
associated with each data element. The mask bits are specified in the first source
operand.
The mask bit for each data element is the most significant bit of that element in the
first source operand. If a mask is 1, the corresponding data element is copied from
the second source operand to the destination operand. If the mask is 0, the corre-
sponding data element is set to zero in the load form of these instructions, and
unmodified in the store form.
The second source operand is a memory address for the load form of these instruc-
tion. The destination operand is a memory address for the store form of these
instructions. The other operands are both XMM registers (for VEX.128 version) or
YMM registers (for VEX.256 version).
Faults occur only due to mask-bit required memory accesses that caused the faults.
Faults will not occur due to referencing any memory location if the corresponding
mask bit for that memory location is 0. For example, no faults will be detected if the
mask bits are all zero.
Unlike previous MASKMOV instructions (MASKMOVQ and MASKMOVDQU), a nontem-
poral hint is not applied to these instructions
Instruction behavior on alignment check reporting with mask bits of less than all 1s
are the same as with mask bits of all 1s.
VMASKMOV should not be used to access memory mapped I/O and un-cached
memory as the access and the ordering of the individual loads or stores it does is
implementation specific.
In cases where mask bits indicate data should not be loaded or stored paging A and
D bits will be set in an implementation dependent way. However, A and D bits are
always set for pages where data is actually loaded/stored.
Note: for load forms, the first source (the mask) is encoded in VEX.vvvv; the second
source is encoded in rm_field, and the destination register is encoded in reg_field.
Note: for store forms, the first source (the mask) is encoded in VEX.vvvv; the second
source register is encoded in reg_field, and the destination memory location is
encoded in rm_field.
Operation
VMASKMOVPS -128-bit load
DEST[31:0] IF (SRC1[31]) Load_32(mem) ELSE 0
DEST[63:32] IF (SRC1[63]) Load_32(mem + 4) ELSE 0
DEST[95:64] IF (SRC1[95]) Load_32(mem + 8) ELSE 0
DEST[127:97] IF (SRC1[127]) Load_32(mem + 12) ELSE 0
DEST[VLMAX-1:128] 0
VMASKMOVPS - 256-bit load

3-626 Vol. 2A VMASKMOV—Conditional SIMD Packed Loads and Stores
INSTRUCTION SET REFERENCE, A-M
DEST[31:0] IF (SRC1[31]) Load_32(mem) ELSE 0
DEST[63:32] IF (SRC1[63]) Load_32(mem + 4) ELSE 0
DEST[95:64] IF (SRC1[95]) Load_32(mem + 8) ELSE 0
DEST[127:96] IF (SRC1[127]) Load_32(mem + 12) ELSE 0
DEST[159:128] IF (SRC1[159]) Load_32(mem + 16) ELSE 0
DEST[191:160] IF (SRC1[191]) Load_32(mem + 20) ELSE 0
DEST[223:192] IF (SRC1[223]) Load_32(mem + 24) ELSE 0
DEST[255:224] IF (SRC1[255]) Load_32(mem + 28) ELSE 0
VMASKMOVPD - 128-bit load
DEST[63:0] IF (SRC1[63]) Load_64(mem) ELSE 0
DEST[127:64] IF (SRC1[127]) Load_64(mem + 16) ELSE 0
DEST[VLMAX-1:128] 0
VMASKMOVPD - 256-bit load
DEST[63:0] IF (SRC1[63]) Load_64(mem) ELSE 0
DEST[127:64] IF (SRC1[127]) Load_64(mem + 8) ELSE 0
DEST[195:128] IF (SRC1[191]) Load_64(mem + 16) ELSE 0
DEST[255:196] IF (SRC1[255]) Load_64(mem + 24) ELSE 0
VMASKMOVPS - 128-bit store
IF (SRC1[31]) DEST[31:0] SRC2[31:0]
IF (SRC1[63]) DEST[63:32] SRC2[63:32]
IF (SRC1[95]) DEST[95:64] SRC2[95:64]
IF (SRC1[127]) DEST[127:96] SRC2[127:96]
VMASKMOVPS - 256-bit store
IF (SRC1[31]) DEST[31:0] SRC2[31:0]
IF (SRC1[63]) DEST[63:32] SRC2[63:32]
IF (SRC1[95]) DEST[95:64] SRC2[95:64]
IF (SRC1[127]) DEST[127:96] SRC2[127:96]
IF (SRC1[159]) DEST[159:128] SRC2[159:128]
IF (SRC1[191]) DEST[191:160] SRC2[191:160]
IF (SRC1[223]) DEST[223:192] SRC2[223:192]
IF (SRC1[255]) DEST[255:224] SRC2[255:224]
VMASKMOVPD - 128-bit store
IF (SRC1[63]) DEST[63:0] SRC2[63:0]
IF (SRC1[127]) DEST[127:64] SRC2[127:64]
VMASKMOVPD - 256-bit store
IF (SRC1[63]) DEST[63:0] SRC2[63:0]
IF (SRC1[127]) DEST[127:64] SRC2[127:64]

Vol. 2A 3-627
INSTRUCTION SET REFERENCE, A-M
VMASKMOV—Conditional SIMD Packed Loads and Stores
IF (SRC1[191]) DEST[191:128] SRC2[191:128]
IF (SRC1[255]) DEST[255:192] SRC2[255:192]
Intel C/C++ Compiler Intrinsic Equivalent
__m256 _mm256_maskload_ps(float const *a, __m256i mask)
void _mm256_maskstore_ps(float *a, __m256i mask, __m256 b)
__m256d _mm256_maskload_pd(double *a, __m256i mask);
void _mm256_maskstore_pd(double *a, __m256i mask, __m256d b);
__m128 _mm256_maskload_ps(float const *a, __m128i mask)
void _mm256_maskstore_ps(float *a, __m128i mask, __m128 b)
__m128d _mm256_maskload_pd(double *a, __m128i mask);
void _mm256_maskstore_pd(double *a, __m128i mask, __m128d b);
SIMD Floating-Point Exceptions
None
Other Exceptions
See Exceptions Type 6 (No AC# reported for any mask bit combinations);
additionally
#UD If VEX.W = 1.
3-628 Vol. 2A MASKMOVQ—Store Selected Bytes of Quadword
INSTRUCTION SET REFERENCE, A-M
MASKMOVQ—Store Selected Bytes of Quadword
Instruction Operand Encoding
Description
Stores selected bytes from the source operand (first operand) into a 64-bit memory
location. The mask operand (second operand) selects which bytes from the source
operand are written to memory. The source and mask operands are MMX technology
registers. The location of the first byte of the memory location is specified by DI/EDI
and DS registers. (The size of the store address depends on the address-size
attribute.)
The most significant bit in each byte of the mask operand determines whether the
corresponding byte in the source operand is written to the corresponding byte loca-
tion in memory: 0 indicates no write and 1 indicates write.
The MASKMOVQ instruction generates a non-temporal hint to the processor to mini-
mize cache pollution. The non-temporal hint is implemented by using a write
combining (WC) memory type protocol (see “Caching of Temporal vs. Non-Temporal
Data” in Chapter 10, of the Intel® 64 and IA-32 Architectures Software Developer’s
Manual, Volume 1). Because the WC protocol uses a weakly-ordered memory consis-
tency model, a fencing operation implemented with the SFENCE or MFENCE instruc-
tion should be used in conjunction with MASKMOVQ instructions if multiple
processors might use different memory types to read/write the destination memory
locations.
This instruction causes a transition from x87 FPU to MMX technology state (that is,
the x87 FPU top-of-stack pointer is set to 0 and the x87 FPU tag word is set to all 0s
[valid]).
The behavior of the MASKMOVQ instruction with a mask of all 0s is as follows:
•No data will be written to memory.
•Transition from x87 FPU to MMX technology state will occur.
•Exceptions associated with addressing memory and page faults may still be
signaled (implementation dependent).
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F F7 /rMASKMOVQ mm1,
mm2
A Valid Valid Selectively write bytes from
mm1 to memory location
using the byte mask in mm2.
The default memory
location is specified by
DS:EDI/RDI.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r) ModRM:r/m (r) NA NA

Vol. 2A 3-629
INSTRUCTION SET REFERENCE, A-M
MASKMOVQ—Store Selected Bytes of Quadword
•Signaling of breakpoints (code or data) is not guaranteed (implementation
dependent).
•If the destination memory region is mapped as UC or WP, enforcement of
associated semantics for these memory types is not guaranteed (that is, is
reserved) and is implementation-specific.
The MASKMOVQ instruction can be used to improve performance for algorithms that
need to merge data on a byte-by-byte basis. It should not cause a read for owner-
ship; doing so generates unnecessary bandwidth since data is to be written directly
using the byte-mask without allocating old data prior to the store.
In 64-bit mode, the memory address is specified by DS:RDI.
Operation
IF (MASK[7] = 1)
THEN DEST[DI/EDI] ← SRC[7:0] ELSE (* Memory location unchanged *); FI;
IF (MASK[15] = 1)
THEN DEST[DI/EDI +1] ← SRC[15:8] ELSE (* Memory location unchanged *); FI;
(* Repeat operation for 3rd through 6th bytes in source operand *)
IF (MASK[63] = 1)
THEN DEST[DI/EDI +15] ← SRC[63:56] ELSE (* Memory location unchanged *); FI;
Intel C/C++ Compiler Intrinsic Equivalent
void _mm_maskmove_si64(__m64d, __m64n, char * p)
Protected Mode Exceptions
#GP(0) For an illegal memory operand effective address in the CS, DS,
ES, FS or GS segments (even if mask is all 0s).
If the destination operand is in a nonwritable segment.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) For an illegal address in the SS segment (even if mask is all 0s).
#PF(fault-code) For a page fault (implementation specific).
#NM If CR0.TS[bit 3] = 1.
#MF If there is a pending FPU exception.
#UD If CR0.EM[bit 2] = 1.
If CPUID.01H:EDX.SSE[bit 25] = 0.
If Mod field of the ModR/M byte not 11B.
If the LOCK prefix is used.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.

3-630 Vol. 2A MASKMOVQ—Store Selected Bytes of Quadword
INSTRUCTION SET REFERENCE, A-M
Real-Address Mode Exceptions
GP If any part of the operand lies outside the effective address
space from 0 to FFFFH. (even if mask is all 0s).
#NM If CR0.TS[bit 3] = 1.
#MF If there is a pending FPU exception.
#UD If CR0.EM[bit 2] = 1.
If CR4.OSFXSR[bit 9] = 0.
If CPUID.01H:EDX.SSE[bit 25] = 0.
If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
Same exceptions as in real address mode.
#PF(fault-code) For a page fault (implementation specific).
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#GP(0) If the memory address is in a non-canonical form.
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#PF(fault-code) For a page fault (implementation specific).
#NM If CR0.TS[bit 3] = 1.
#MF If there is a pending FPU exception.
#UD If CR0.EM[bit 2] = 1.
If CR4.OSFXSR[bit 9] = 0.
If CPUID.01H:EDX.SSE[bit 25] = 0.
If Mod field of the ModR/M byte not 11B.
If the LOCK prefix is used.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.

Vol. 2A 3-631
INSTRUCTION SET REFERENCE, A-M
MAXPD—Return Maximum Packed Double-Precision Floating-Point Values
MAXPD—Return Maximum Packed Double-Precision Floating-Point
Values
Instruction Operand Encoding
Description
Performs an SIMD compare of the packed double-precision floating-point values in
the first source operand and the second source operand and returns the maximum
value for each pair of values to the destination operand.
If the values being compared are both 0.0s (of either sign), the value in the second
operand (source operand) is returned. If a value in the second operand is an SNaN,
that SNaN is forwarded unchanged to the destination (that is, a QNaN version of the
SNaN is not returned).
If only one value is a NaN (SNaN or QNaN) for this instruction, the second operand
(source operand), either a NaN or a valid floating-point value, is written to the result.
If instead of this behavior, it is required that the NaN source operand (from either the
first or second operand) be returned, the action of MAXPD can be emulated using a
sequence of instructions, such as, a comparison followed by AND, ANDN and OR.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
128-bit Legacy SSE version: The second source can be an XMM register or an 128-bit
memory location. The destination is not distinct from the first source XMM register
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 5F /r
MAXPD xmm1, xmm2/m128
A V/V SSE2 Return the maximum
double-precision floating-
point values between
xmm2/m128 and xmm1.
VEX.NDS.128.66.0F.WIG 5F /r
VMAXPD xmm1,xmm2,
xmm3/m128
B V/V AVX Return the maximum
double-precision floating-
point values between xmm2
and xmm3/mem.
VEX.NDS.256.66.0F.WIG 5F /r
VMAXPD ymm1, ymm2,
ymm3/m256
B V/V AVX Return the maximum
packed double-precision
floating-point values
between ymm2 and
ymm3/mem.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

3-632 Vol. 2A MAXPD—Return Maximum Packed Double-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
and the upper bits (VLMAX-1:128) of the corresponding YMM register destination are
unmodified.
VEX.128 encoded version: the first source operand is an XMM register or 128-bit
memory location. The destination operand is an XMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are zeroed.
VEX.256 encoded version: The first source operand is a YMM register. The second
source operand can be a YMM register or a 256-bit memory location. The destination
operand is a YMM register.
Operation
MAX(SRC1, SRC2)
{
IF ((SRC1 = 0.0) and (SRC2 = 0.0)) THEN DEST SRC2;
ELSE IF (SRC1 = SNaN) THEN DEST SRC2; FI;
ELSE IF (SRC2 = SNaN) THEN DEST SRC2; FI;
ELSE IF (SRC1 > SRC2) THEN DEST SRC1;
ELSE DEST SRC2;
FI;
}
MAXPD (128-bit Legacy SSE version)
DEST[63:0] MAX(DEST[63:0], SRC[63:0])
DEST[127:64] MAX(DEST[127:64], SRC[127:64])
DEST[VLMAX-1:128] (Unmodified)
VMAXPD (VEX.128 encoded version)
DEST[63:0] MAX(SRC1[63:0], SRC2[63:0])
DEST[127:64] MAX(SRC1[127:64], SRC2[127:64])
DEST[VLMAX-1:128] 0
VMAXPD (VEX.256 encoded version)
DEST[63:0] MAX(SRC1[63:0], SRC2[63:0])
DEST[127:64] MAX(SRC1[127:64], SRC2[127:64])
DEST[191:128] MAX(SRC1[191:128], SRC2[191:128])
DEST[255:192] MAX(SRC1[255:192], SRC2[255:192])
Intel C/C++ Compiler Intrinsic Equivalent
MAXPD __m128d _mm_max_pd(__m128d a, __m128d b);
VMAXPD __m256d _mm256_max_pd (__m256d a, __m256d b);

Vol. 2A 3-633
INSTRUCTION SET REFERENCE, A-M
MAXPD—Return Maximum Packed Double-Precision Floating-Point Values
SIMD Floating-Point Exceptions
Invalid (including QNaN source operand), Denormal.
Other Exceptions
See Exceptions Type 2.
3-634 Vol. 2A MAXPS—Return Maximum Packed Single-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
MAXPS—Return Maximum Packed Single-Precision Floating-Point
Values
Instruction Operand Encoding
Description
Performs an SIMD compare of the packed single-precision floating-point values in the
first source operand and the second source operand and returns the maximum value
for each pair of values to the destination operand.
If the values being compared are both 0.0s (of either sign), the value in the second
operand (source operand) is returned. If a value in the second operand is an SNaN,
that SNaN is forwarded unchanged to the destination (that is, a QNaN version of the
SNaN is not returned).
If only one value is a NaN (SNaN or QNaN) for this instruction, the second operand
(source operand), either a NaN or a valid floating-point value, is written to the result.
If instead of this behavior, it is required that the NaN source operand (from either the
first or second operand) be returned, the action of MAXPS can be emulated using a
sequence of instructions, such as, a comparison followed by AND, ANDN and OR.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
128-bit Legacy SSE version: The second source can be an XMM register or an 128-bit
memory location. The destination is not distinct from the first source XMM register
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
0F 5F /r
MAXPS xmm1, xmm2/m128
A V/V SSE Return the maximum single-
precision floating-point
values between
xmm2/m128 and xmm1.
VEX.NDS.128.0F.WIG 5F /r
VMAXPS xmm1,xmm2, xmm3/m128
B V/V AVX Return the maximum single-
precision floating-point
values between xmm2 and
xmm3/mem.
VEX.NDS.256.0F.WIG 5F /r
VMAXPS ymm1, ymm2,
ymm3/m256
B V/V AVX Return the maximum single
double-precision floating-
point values between ymm2
and ymm3/mem.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

Vol. 2A 3-635
INSTRUCTION SET REFERENCE, A-M
MAXPS—Return Maximum Packed Single-Precision Floating-Point Values
and the upper bits (VLMAX-1:128) of the corresponding YMM register destination are
unmodified.
VEX.128 encoded version: the first source operand is an XMM register or 128-bit
memory location. The destination operand is an XMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are zeroed.
VEX.256 encoded version: The first source operand is a YMM register. The second
source operand can be a YMM register or a 256-bit memory location. The destination
operand is a YMM register.
Operation
MAX(SRC1, SRC2)
{
IF ((SRC1 = 0.0) and (SRC2 = 0.0)) THEN DEST SRC2;
ELSE IF (SRC1 = SNaN) THEN DEST SRC2; FI;
ELSE IF SRC2 = SNaN) THEN DEST SRC2; FI;
ELSE IF (SRC1 > SRC2) THEN DEST SRC1;
ELSE DEST SRC2;
FI;
}
MAXPS (128-bit Legacy SSE version)
DEST[31:0] MAX(DEST[31:0], SRC[31:0])
DEST[63:32] MAX(DEST[63:32], SRC[63:32])
DEST[95:64] MAX(DEST[95:64], SRC[95:64])
DEST[127:96] MAX(DEST[127:96], SRC[127:96])
DEST[VLMAX-1:128] (Unmodified)
VMAXPS (VEX.128 encoded version)
DEST[31:0] MAX(SRC1[31:0], SRC2[31:0])
DEST[63:32] MAX(SRC1[63:32], SRC2[63:32])
DEST[95:64] MAX(SRC1[95:64], SRC2[95:64])
DEST[127:96] MAX(SRC1[127:96], SRC2[127:96])
DEST[VLMAX-1:128] 0
VMAXPS (VEX.256 encoded version)
DEST[31:0] MAX(SRC1[31:0], SRC2[31:0])
DEST[63:32] MAX(SRC1[63:32], SRC2[63:32])
DEST[95:64] MAX(SRC1[95:64], SRC2[95:64])
DEST[127:96] MAX(SRC1[127:96], SRC2[127:96])
DEST[159:128] MAX(SRC1[159:128], SRC2[159:128])
DEST[191:160] MAX(SRC1[191:160], SRC2[191:160])
DEST[223:192] MAX(SRC1[223:192], SRC2[223:192])

3-636 Vol. 2A MAXPS—Return Maximum Packed Single-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
DEST[255:224] MAX(SRC1[255:224], SRC2[255:224])
Intel C/C++ Compiler Intrinsic Equivalent
MAXPS __m128 _mm_max_ps (__m128 a, __m128 b);
VMAXPS __m256 _mm256_max_ps (__m256 a, __m256 b);
SIMD Floating-Point Exceptions
Invalid (including QNaN source operand), Denormal.
Other Exceptions
See Exceptions Type 2.

Vol. 2A 3-637
INSTRUCTION SET REFERENCE, A-M
MAXSD—Return Maximum Scalar Double-Precision Floating-Point Value
MAXSD—Return Maximum Scalar Double-Precision Floating-Point
Value
Instruction Operand Encoding
Description
Compares the low double-precision floating-point values in the first source operand
and second the source operand, and returns the maximum value to the low quad-
word of the destination operand. The second source operand can be an XMM register
or a 64-bit memory location. The first source and destination operands are XMM
registers. When the second source operand is a memory operand, only 64 bits are
accessed. The high quadword of the destination operand is copied from the same bits
of first source operand.
If the values being compared are both 0.0s (of either sign), the value in the second
source operand is returned. If a value in the second source operand is an SNaN, that
SNaN is returned unchanged to the destination (that is, a QNaN version of the SNaN
is not returned).
If only one value is a NaN (SNaN or QNaN) for this instruction, the second source
operand, either a NaN or a valid floating-point value, is written to the result. If
instead of this behavior, it is required that the NaN of either source operand be
returned, the action of MAXSD can be emulated using a sequence of instructions,
such as, a comparison followed by AND, ANDN and OR.
The second source operand can be an XMM register or a 64-bit memory location. The
first source and destination operands are XMM registers.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F2 0F 5F /r
MAXSD xmm1, xmm2/m64
A V/V SSE2 Return the maximum scalar
double-precision floating-
point value between
xmm2/mem64 and xmm1.
VEX.NDS.LIG.F2.0F.WIG 5F /r
VMAXSD xmm1, xmm2, xmm3/m64
B V/V AVX Return the maximum scalar
double-precision floating-
point value between
xmm3/mem64 and xmm2.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

3-638 Vol. 2A MAXSD—Return Maximum Scalar Double-Precision Floating-Point Value
INSTRUCTION SET REFERENCE, A-M
128-bit Legacy SSE version: The destination and first source operand are the same.
Bits (VLMAX-1:64) of the corresponding YMM destination register remain unchanged.
VEX.128 encoded version: Bits (127:64) of the XMM register destination are copied
from corresponding bits in the first source operand. Bits (VLMAX-1:128) of the desti-
nation YMM register are zeroed.
Operation
MAX(SRC1, SRC2)
{
IF ((SRC1 = 0.0) and (SRC2 = 0.0)) THEN DEST SRC2;
ELSE IF (SRC1 = SNaN) THEN DEST SRC2; FI;
ELSE IF SRC2 = SNaN) THEN DEST SRC2; FI;
ELSE IF (SRC1 > SRC2) THEN DEST SRC1;
ELSE DEST SRC2;
FI;
}
MAXSD (128-bit Legacy SSE version)
DEST[63:0] MAX(DEST[63:0], SRC[63:0])
DEST[VLMAX-1:64] (Unmodified)
VMAXSD (VEX.128 encoded version)
DEST[63:0] MAX(SRC1[63:0], SRC2[63:0])
DEST[127:64] SRC1[127:64]
DEST[VLMAX-1:128] 0
Intel C/C++ Compiler Intrinsic Equivalent
MAXSD __m128d _mm_max_sd(__m128d a, __m128d b)
SIMD Floating-Point Exceptions
Invalid (including QNaN source operand), Denormal.
Other Exceptions
See Exceptions Type 3.

Vol. 2A 3-639
INSTRUCTION SET REFERENCE, A-M
MAXSS—Return Maximum Scalar Single-Precision Floating-Point Value
MAXSS—Return Maximum Scalar Single-Precision Floating-Point Value
Instruction Operand Encoding
Description
Compares the low single-precision floating-point values in the first source operand
and the second source operand, and returns the maximum value to the low double-
word of the destination operand.
If the values being compared are both 0.0s (of either sign), the value in the second
source operand is returned. If a value in the second source operand is an SNaN, that
SNaN is returned unchanged to the destination (that is, a QNaN version of the SNaN
is not returned).
If only one value is a NaN (SNaN or QNaN) for this instruction, the second source
operand, either a NaN or a valid floating-point value, is written to the result. If
instead of this behavior, it is required that the NaN from either source operand be
returned, the action of MAXSS can be emulated using a sequence of instructions,
such as, a comparison followed by AND, ANDN and OR.
The second source operand can be an XMM register or a 32-bit memory location. The
first source and destination operands are XMM registers.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
128-bit Legacy SSE version: The destination and first source operand are the same.
Bits (VLMAX-1:32) of the corresponding YMM destination register remain unchanged.
VEX.128 encoded version: Bits (127:32) of the XMM register destination are copied
from corresponding bits in the first source operand. Bits (VLMAX-1:128) of the desti-
nation YMM register are zeroed.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F3 0F 5F /r
MAXSS xmm1, xmm2/m32
A V/V SSE Return the maximum scalar
single-precision floating-
point value between
xmm2/mem32 and xmm1.
VEX.NDS.LIG.F3.0F.WIG 5F /r
VMAXSS xmm1, xmm2, xmm3/m32
B V/V AVX Return the maximum scalar
single-precision floating-
point value between
xmm3/mem32 and xmm2.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

3-640 Vol. 2A MAXSS—Return Maximum Scalar Single-Precision Floating-Point Value
INSTRUCTION SET REFERENCE, A-M
Operation
MAX(SRC1, SRC2)
{
IF ((SRC1 = 0.0) and (SRC2 = 0.0)) THEN DEST SRC2;
ELSE IF (SRC1 = SNaN) THEN DEST SRC2; FI;
ELSE IF SRC2 = SNaN) THEN DEST SRC2; FI;
ELSE IF (SRC1 > SRC2) THEN DEST SRC1;
ELSE DEST SRC2;
FI;
}
MAXSS (128-bit Legacy SSE version)
DEST[31:0] MAX(DEST[31:0], SRC[31:0])
DEST[VLMAX-1:32] (Unmodified)
VMAXSS (VEX.128 encoded version)
DEST[31:0] MAX(SRC1[31:0], SRC2[31:0])
DEST[127:32] SRC1[127:32]
DEST[VLMAX-1:128] 0
Intel C/C++ Compiler Intrinsic Equivalent
__m128d _mm_max_ss(__m128d a, __m128d b)
SIMD Floating-Point Exceptions
Invalid (including QNaN source operand), Denormal.
Other Exceptions
See Exceptions Type 3.

Vol. 2A 3-641
INSTRUCTION SET REFERENCE, A-M
MFENCE—Memory Fence
MFENCE—Memory Fence
Instruction Operand Encoding
Description
Performs a serializing operation on all load-from-memory and store-to-memory
instructions that were issued prior the MFENCE instruction. This serializing operation
guarantees that every load and store instruction that precedes the MFENCE instruc-
tion in program order becomes globally visible before any load or store instruction
that follows the MFENCE instruction.1 The MFENCE instruction is ordered with respect
to all load and store instructions, other MFENCE instructions, any LFENCE and
SFENCE instructions, and any serializing instructions (such as the CPUID instruc-
tion). MFENCE does not serialize the instruction stream.
Weakly ordered memory types can be used to achieve higher processor performance
through such techniques as out-of-order issue, speculative reads, write-combining,
and write-collapsing. The degree to which a consumer of data recognizes or knows
that the data is weakly ordered varies among applications and may be unknown to
the producer of this data. The MFENCE instruction provides a performance-efficient
way of ensuring load and store ordering between routines that produce weakly-
ordered results and routines that consume that data.
Processors are free to fetch and cache data speculatively from regions of system
memory that use the WB, WC, and WT memory types. This speculative fetching can
occur at any time and is not tied to instruction execution. Thus, it is not ordered with
respect to executions of the MFENCE instruction; data can be brought into the caches
speculatively just before, during, or after the execution of an MFENCE instruc-
tion.Processors are free to fetch and cache data speculatively from regions of system
memory that use the WB, WC, and WT memory types. This speculative fetching can
occur at any time and is not tied to instruction execution. Thus, it is not ordered with
respect to executions of the MFENCE instruction; data can be brought into the caches
speculatively just before, during, or after the execution of an MFENCE instruction.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F AE /6 MFENCE A Valid Valid Serializes load and store
operations.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA
1. A load instruction is considered to become globally visible when the value to be loaded into its
destination register is determined.

3-642 Vol. 2A MFENCE—Memory Fence
INSTRUCTION SET REFERENCE, A-M
Operation
Wait_On_Following_Loads_And_Stores_Until(preceding_loads_and_stores_globally_visible);
Intel C/C++ Compiler Intrinsic Equivalent
void _mm_mfence(void)
Exceptions (All Modes of Operation)
#UD If CPUID.01H:EDX.SSE2[bit 26] = 0.
If the LOCK prefix is used.

Vol. 2A 3-643
INSTRUCTION SET REFERENCE, A-M
MINPD—Return Minimum Packed Double-Precision Floating-Point Values
MINPD—Return Minimum Packed Double-Precision Floating-Point
Values
Instruction Operand Encoding
Description
Performs an SIMD compare of the packed double-precision floating-point values in
the first source operand and the second source operand and returns the minimum
value for each pair of values to the destination operand.
If the values being compared are both 0.0s (of either sign), the value in the second
operand (source operand) is returned. If a value in the second operand is an SNaN,
that SNaN is forwarded unchanged to the destination (that is, a QNaN version of the
SNaN is not returned).
If only one value is a NaN (SNaN or QNaN) for this instruction, the second operand
(source operand), either a NaN or a valid floating-point value, is written to the result.
If instead of this behavior, it is required that the NaN source operand (from either the
first or second operand) be returned, the action of MINPD can be emulated using a
sequence of instructions, such as, a comparison followed by AND, ANDN and OR.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
128-bit Legacy SSE version: The second source can be an XMM register or an 128-bit
memory location. The destination is not distinct from the first source XMM register
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 5D /r
MINPD xmm1, xmm2/m128
A V/V SSE2 Return the minimum double-
precision floating-point
values between
xmm2/m128 and xmm1.
VEX.NDS.128.66.0F.WIG 5D /r
VMINPD xmm1,xmm2, xmm3/m128
B V/V AVX Return the minimum double-
precision floating-point
values between xmm2 and
xmm3/mem.
VEX.NDS.256.66.0F.WIG 5D /r
VMINPD ymm1, ymm2, ymm3/m256
B V/V AVX Return the minimum packed
double-precision floating-
point values between ymm2
and ymm3/mem.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

3-644 Vol. 2A MINPD—Return Minimum Packed Double-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
and the upper bits (VLMAX-1:128) of the corresponding YMM register destination are
unmodified.
VEX.128 encoded version: the first source operand is an XMM register or 128-bit
memory location. The destination operand is an XMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are zeroed.
Operation
MIN(SRC1, SRC2)
{
IF ((SRC1 = 0.0) and (SRC2 = 0.0)) THEN DEST SRC2;
ELSE IF (SRC1 = SNaN) THEN DEST SRC2; FI;
ELSE IF (SRC2 = SNaN) THEN DEST SRC2; FI;
ELSE IF (SRC1 < SRC2) THEN DEST SRC1;
ELSE DEST SRC2;
FI;
}
MINPD (128-bit Legacy SSE version)
DEST[63:0] MIN(SRC1[63:0], SRC2[63:0])
DEST[127:64] MIN(SRC1[127:64], SRC2[127:64])
DEST[VLMAX-1:128] (Unmodified)
VMINPD (VEX.128 encoded version)
DEST[63:0] MIN(SRC1[63:0], SRC2[63:0])
DEST[127:64] MIN(SRC1[127:64], SRC2[127:64])
DEST[VLMAX-1:128] 0
VMINPD (VEX.256 encoded version)
DEST[63:0] MIN(SRC1[63:0], SRC2[63:0])
DEST[127:64] MIN(SRC1[127:64], SRC2[127:64])
DEST[191:128] MIN(SRC1[191:128], SRC2[191:128])
DEST[255:192] MIN(SRC1[255:192], SRC2[255:192])
Intel C/C++ Compiler Intrinsic Equivalent
MINPD __m128d _mm_min_pd(__m128d a, __m128d b);
VMINPD __m256d _mm256_min_pd (__m256d a, __m256d b);
SIMD Floating-Point Exceptions
Invalid (including QNaN source operand), Denormal.

Vol. 2A 3-645
INSTRUCTION SET REFERENCE, A-M
MINPD—Return Minimum Packed Double-Precision Floating-Point Values
Other Exceptions
See Exceptions Type 2.
3-646 Vol. 2A MINPS—Return Minimum Packed Single-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
MINPS—Return Minimum Packed Single-Precision Floating-Point
Values
Instruction Operand Encoding
Description
Performs an SIMD compare of the packed single-precision floating-point values in the
first source operand and the second source operand and returns the minimum value
for each pair of values to the destination operand.
If the values being compared are both 0.0s (of either sign), the value in the second
operand (source operand) is returned. If a value in the second operand is an SNaN,
that SNaN is forwarded unchanged to the destination (that is, a QNaN version of the
SNaN is not returned).
If only one value is a NaN (SNaN or QNaN) for this instruction, the second operand
(source operand), either a NaN or a valid floating-point value, is written to the result.
If instead of this behavior, it is required that the NaN source operand (from either the
first or second operand) be returned, the action of MINPS can be emulated using a
sequence of instructions, such as, a comparison followed by AND, ANDN and OR.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
128-bit Legacy SSE version: The second source can be an XMM register or an 128-bit
memory location. The destination is not distinct from the first source XMM register
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
0F 5D /r
MINPS xmm1, xmm2/m128
A V/V SSE Return the minimum single-
precision floating-point
values between
xmm2/m128 and xmm1.
VEX.NDS.128.0F.WIG 5D /r
VMINPS xmm1,xmm2, xmm3/m128
B V/V AVX Return the minimum single-
precision floating-point
values between xmm2 and
xmm3/mem.
VEX.NDS.256.0F.WIG 5D /r
VMINPS ymm1, ymm2, ymm3/m256
B V/V AVX Return the minimum single
double-precision floating-
point values between ymm2
and ymm3/mem.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

Vol. 2A 3-647
INSTRUCTION SET REFERENCE, A-M
MINPS—Return Minimum Packed Single-Precision Floating-Point Values
and the upper bits (VLMAX-1:128) of the corresponding YMM register destination are
unmodified.
VEX.128 encoded version: the first source operand is an XMM register or 128-bit
memory location. The destination operand is an XMM register. The upper bits
(VLMAX-1:128) of the corresponding YMM register destination are zeroed.
VEX.256 encoded version: The first source operand is a YMM register. The second
source operand can be a YMM register or a 256-bit memory location. The destination
operand is a YMM register.
Operation
MIN(SRC1, SRC2)
{
IF ((SRC1 = 0.0) and (SRC2 = 0.0)) THEN DEST SRC2;
ELSE IF (SRC1 = SNaN) THEN DEST SRC2; FI;
ELSE IF (SRC2 = SNaN) THEN DEST SRC2; FI;
ELSE IF (SRC1 < SRC2) THEN DEST SRC1;
ELSE DEST SRC2;
FI;
}
MINPS (128-bit Legacy SSE version)
DEST[31:0] MIN(SRC1[31:0], SRC2[31:0])
DEST[63:32] MIN(SRC1[63:32], SRC2[63:32])
DEST[95:64] MIN(SRC1[95:64], SRC2[95:64])
DEST[127:96] MIN(SRC1[127:96], SRC2[127:96])
DEST[VLMAX-1:128] (Unmodified)
VMINPS (VEX.128 encoded version)
DEST[31:0] MIN(SRC1[31:0], SRC2[31:0])
DEST[63:32] MIN(SRC1[63:32], SRC2[63:32])
DEST[95:64] MIN(SRC1[95:64], SRC2[95:64])
DEST[127:96] MIN(SRC1[127:96], SRC2[127:96])
DEST[VLMAX-1:128] 0
VMINPS (VEX.256 encoded version)
DEST[31:0] MIN(SRC1[31:0], SRC2[31:0])
DEST[63:32] MIN(SRC1[63:32], SRC2[63:32])
DEST[95:64] MIN(SRC1[95:64], SRC2[95:64])
DEST[127:96] MIN(SRC1[127:96], SRC2[127:96])
DEST[159:128] MIN(SRC1[159:128], SRC2[159:128])
DEST[191:160] MIN(SRC1[191:160], SRC2[191:160])
DEST[223:192] MIN(SRC1[223:192], SRC2[223:192])

3-648 Vol. 2A MINPS—Return Minimum Packed Single-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
DEST[255:224] MIN(SRC1[255:224], SRC2[255:224])
Intel C/C++ Compiler Intrinsic Equivalent
MINPS __m128d _mm_min_ps(__m128d a, __m128d b);
VMINPS __m256 _mm256_min_ps (__m256 a, __m256 b);
SIMD Floating-Point Exceptions
Invalid (including QNaN source operand), Denormal.
Other Exceptions
See Exceptions Type 2.

Vol. 2A 3-649
INSTRUCTION SET REFERENCE, A-M
MINSD—Return Minimum Scalar Double-Precision Floating-Point Value
MINSD—Return Minimum Scalar Double-Precision Floating-Point Value
Instruction Operand Encoding
Description
Compares the low double-precision floating-point values in the first source operand
and the second source operand, and returns the minimum value to the low quadword
of the destination operand. When the source operand is a memory operand, only the
64 bits are accessed. The high quadword of the destination operand is copied from
the same bits in the first source operand.
If the values being compared are both 0.0s (of either sign), the value in the second
source operand is returned. If a value in the second source operand is an SNaN, that
SNaN is returned unchanged to the destination (that is, a QNaN version of the SNaN
is not returned).
If only one value is a NaN (SNaN or QNaN) for this instruction, the second source
operand, either a NaN or a valid floating-point value, is written to the result. If
instead of this behavior, it is required that the NaN source operand (from either the
first or second source) be returned, the action of MINSD can be emulated using a
sequence of instructions, such as, a comparison followed by AND, ANDN and OR.
The second source operand can be an XMM register or a 64-bit memory location. The
first source and destination operands are XMM registers.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
128-bit Legacy SSE version: The destination and first source operand are the same.
Bits (VLMAX-1:64) of the corresponding YMM destination register remain unchanged.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F2 0F 5D /r
MINSD xmm1, xmm2/m64
A V/V SSE2 Return the minimum scalar
double-precision floating-
point value between
xmm2/mem64 and xmm1.
VEX.NDS.LIG.F2.0F.WIG 5D /r
VMINSD xmm1, xmm2, xmm3/m64
B V/V AVX Return the minimum scalar
double precision floating-
point value between
xmm3/mem64 and xmm2.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

3-650 Vol. 2A MINSD—Return Minimum Scalar Double-Precision Floating-Point Value
INSTRUCTION SET REFERENCE, A-M
VEX.128 encoded version: Bits (127:64) of the XMM register destination are copied
from corresponding bits in the first source operand. Bits (VLMAX-1:128) of the desti-
nation YMM register are zeroed.
Operation
MIN(SRC1, SRC2)
{
IF ((SRC1 = 0.0) and (SRC2 = 0.0)) THEN DEST SRC2;
ELSE IF (SRC1 = SNaN) THEN DEST SRC2; FI;
ELSE IF SRC2 = SNaN) THEN DEST SRC2; FI;
ELSE IF (SRC1 < SRC2) THEN DEST SRC1;
ELSE DEST SRC2;
FI;
}
MINSD (128-bit Legacy SSE version)
DEST[63:0] MIN(SRC1[63:0], SRC2[63:0])
DEST[VLMAX-1:64] (Unmodified)
MINSD (VEX.128 encoded version)
DEST[63:0] MIN(SRC1[63:0], SRC2[63:0])
DEST[127:64] SRC1[127:64]
DEST[VLMAX-1:128] 0
Intel C/C++ Compiler Intrinsic Equivalent
MINSD __m128d _mm_min_sd(__m128d a, __m128d b)
SIMD Floating-Point Exceptions
Invalid (including QNaN source operand), Denormal.
Other Exceptions
See Exceptions Type 3.

Vol. 2A 3-651
INSTRUCTION SET REFERENCE, A-M
MINSS—Return Minimum Scalar Single-Precision Floating-Point Value
MINSS—Return Minimum Scalar Single-Precision Floating-Point Value
Instruction Operand Encoding
Description
Compares the low single-precision floating-point values in the first source operand
and the second source operand and returns the minimum value to the low double-
word of the destination operand.
If the values being compared are both 0.0s (of either sign), the value in the second
source operand is returned. If a value in the second operand is an SNaN, that SNaN
is returned unchanged to the destination (that is, a QNaN version of the SNaN is not
returned).
If only one value is a NaN (SNaN or QNaN) for this instruction, the second source
operand, either a NaN or a valid floating-point value, is written to the result. If
instead of this behavior, it is required that the NaN in either source operand be
returned, the action of MINSD can be emulated using a sequence of instructions,
such as, a comparison followed by AND, ANDN and OR.
The second source operand can be an XMM register or a 32-bit memory location. The
first source and destination operands are XMM registers.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
128-bit Legacy SSE version: The destination and first source operand are the same.
Bits (VLMAX-1:32) of the corresponding YMM destination register remain unchanged.
VEX.128 encoded version: Bits (127:32) of the XMM register destination are copied
from corresponding bits in the first source operand. Bits (VLMAX-1:128) of the desti-
nation YMM register are zeroed.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F3 0F 5D /r
MINSS xmm1, xmm2/m32
A V/V SSE Return the minimum scalar
single-precision floating-
point value between
xmm2/mem32 and xmm1.
VEX.NDS.LIG.F3.
0F.WIG 5D /r
VMINSS
xmm1,xmm2,
xmm3/m32
B V/V AVX Return the minimum scalar
single precision floating-
point value between
xmm3/mem32 and xmm2.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

3-652 Vol. 2A MINSS—Return Minimum Scalar Single-Precision Floating-Point Value
INSTRUCTION SET REFERENCE, A-M
Operation
MIN(SRC1, SRC2)
{
IF ((SRC1 = 0.0) and (SRC2 = 0.0)) THEN DEST SRC2;
ELSE IF (SRC1 = SNaN) THEN DEST SRC2; FI;
ELSE IF SRC2 = SNaN) THEN DEST SRC2; FI;
ELSE IF (SRC1 < SRC2) THEN DEST SRC1;
ELSE DEST SRC2;
FI;
}
MINSS (128-bit Legacy SSE version)
DEST[31:0] MIN(SRC1[31:0], SRC2[31:0])
DEST[VLMAX-1:32] (Unmodified)
VMINSS (VEX.128 encoded version)
DEST[31:0] MIN(SRC1[31:0], SRC2[31:0])
DEST[127:32] SRC1[127:32]
DEST[VLMAX-1:128] 0
Intel C/C++ Compiler Intrinsic Equivalent
MINSS __m128d _mm_min_ss(__m128d a, __m128d b)
SIMD Floating-Point Exceptions
Invalid (including QNaN source operand), Denormal.
Other Exceptions
See Exceptions Type 3.

Vol. 2A 3-653
INSTRUCTION SET REFERENCE, A-M
MONITOR—Set Up Monitor Address
MONITOR—Set Up Monitor Address
Instruction Operand Encoding
Description
The MONITOR instruction arms address monitoring hardware using an address spec-
ified in EAX (the address range that the monitoring hardware checks for store opera-
tions can be determined by using CPUID). A store to an address within the specified
address range triggers the monitoring hardware. The state of monitor hardware is
used by MWAIT.
The content of EAX is an effective address (in 64-bit mode, RAX is used). By default,
the DS segment is used to create a linear address that is monitored. Segment over-
rides can be used.
ECX and EDX are also used. They communicate other information to MONITOR. ECX
specifies optional extensions. EDX specifies optional hints; it does not change the
architectural behavior of the instruction. For the Pentium 4 processor (family 15,
model 3), no extensions or hints are defined. Undefined hints in EDX are ignored by
the processor; undefined extensions in ECX raises a general protection fault.
The address range must use memory of the write-back type. Only write-back
memory will correctly trigger the monitoring hardware. Additional information on
determining what address range to use in order to prevent false wake-ups is
described in Chapter 8, “Multiple-Processor Management” of the Intel® 64 and IA-32
Architectures Software Developer’s Manual, Volume 3A.
The MONITOR instruction is ordered as a load operation with respect to other
memory transactions. The instruction is subject to the permission checking and faults
associated with a byte load. Like a load, MONITOR sets the A-bit but not the D-bit in
page tables.
The MONITOR CPUID feature flag (ECX bit 3; CPUID executed EAX = 1) indicates the
availability of MONITOR and MWAIT in the processor. When set, MONITOR may be
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F 01 C8 MONITOR A Valid Valid Sets up a linear address
range to be monitored by
hardware and activates the
monitor. The address range
should be a write-back
memory caching type. The
address is DS:EAX (DS:RAX
in 64-bit mode).
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA

3-654 Vol. 2A MONITOR—Set Up Monitor Address
INSTRUCTION SET REFERENCE, A-M
executed only at privilege level 0 (use at any other privilege level results in an
invalid-opcode exception). The operating system or system BIOS may disable this
instruction by using the IA32_MISC_ENABLE MSR; disabling MONITOR clears the
CPUID feature flag and causes execution to generate an illegal opcode exception.
The instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
MONITOR sets up an address range for the monitor hardware using the content of
EAX (RAX in 64-bit mode) as an effective address and puts the monitor hardware in
armed state. Always use memory of the write-back caching type. A store to the spec-
ified address range will trigger the monitor hardware. The content of ECX and EDX
are used to communicate other information to the monitor hardware.
Intel C/C++ Compiler Intrinsic Equivalent
MONITOR void _mm_monitor(void const *p, unsigned extensions,unsigned hints)
Numeric Exceptions
None
Protected Mode Exceptions
#GP(0) If the value in EAX is outside the CS, DS, ES, FS, or GS segment
limit.
If the DS, ES, FS, or GS register is used to access memory and it
contains a NULL segment selector.
If ECX ≠ 0.
#SS(0) If the value in EAX is outside the SS segment limit.
#PF(fault-code) For a page fault.
#UD If CPUID.01H:ECX.MONITOR[bit 3] = 0.
If current privilege level is not 0.
Real Address Mode Exceptions
#GP If the CS, DS, ES, FS, or GS register is used to access memory
and the value in EAX is outside of the effective address space
from 0 to FFFFH.
If ECX ≠ 0.
#SS If the SS register is used to access memory and the value in EAX
is outside of the effective address space from 0 to FFFFH.
#UD If CPUID.01H:ECX.MONITOR[bit 3] = 0.

Vol. 2A 3-655
INSTRUCTION SET REFERENCE, A-M
MONITOR—Set Up Monitor Address
Virtual 8086 Mode Exceptions
#UD The MONITOR instruction is not recognized in virtual-8086 mode
(even if CPUID.01H:ECX.MONITOR[bit 3] = 1).
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#GP(0) If the linear address of the operand in the CS, DS, ES, FS, or GS
segment is in a non-canonical form.
If RCX ≠ 0.
#SS(0) If the SS register is used to access memory and the value in EAX
is in a non-canonical form.
#PF(fault-code) For a page fault.
#UD If the current privilege level is not 0.
If CPUID.01H:ECX.MONITOR[bit 3] = 0.

3-656 Vol. 2A MOV—Move
INSTRUCTION SET REFERENCE, A-M
MOV—Move
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
88 /rMOV r/m8,r8 AValid Valid Move r8 to r/m8.
REX + 88 /rMOV r/m8***,r8*** AValid N.E. Move r8 to r/m8.
89 /rMOV r/m16,r16 AValid Valid Move r16 to r/m16.
89 /rMOV r/m32,r32 AValid Valid Move r32 to r/m32.
REX.W + 89 /rMOV r/m64,r64 AValid N.E. Move r64 to r/m64.
8A /rMOV r8,r/m8 BValid Valid Move r/m8 to r8.
REX + 8A /rMOV
r8***,r/m8***
BValid N.E. Move r/m8 to r8.
8B /rMOV r16,r/m16 BValid Valid Move r/m16 to r16.
8B /rMOV r32,r/m32 BValid Valid Move r/m32 to r32.
REX.W + 8B /rMOV r64,r/m64 BValid N.E. Move r/m64 to r64.
8C /rMOV r/m16,Sreg** A Valid Valid Move segment register to
r/m16.
REX.W + 8C /rMOV r/m64,Sreg** A Valid Valid Move zero extended 16-bit
segment register to r/m64.
8E /rMOV Sreg,r/m16** B Valid Valid Move r/m16 to segment
register.
REX.W + 8E /rMOV Sreg,r/m64** B Valid Valid Move lower 16 bits of
r/m64 to segment register.
A0 MOV AL,moffs8* C Valid Valid Move byte at (seg:offset) to
AL.
REX.W + A0 MOV AL,moffs8*C Valid N.E. Move byte at (offset) to AL.
A1 MOV AX,moffs16* C Valid Valid Move word at (seg:offset) to
AX.
A1 MOV
EAX,moffs32*
C Valid Valid Move doubleword at
(seg:offset) to EAX.
REX.W + A1 MOV
RAX,moffs64*
C Valid N.E. Move quadword at (offset)
to RAX.
A2 MOV moffs8,AL D Valid Valid Move AL to (seg:offset).
REX.W + A2 MOV moffs8***,AL D Valid N.E. Move AL to (offset).
A3 MOV moffs16*,AX D Valid Valid Move AX to (seg:offset).
A3 MOV
moffs32*,EAX
D Valid Valid Move EAX to (seg:offset).

Vol. 2A 3-657
INSTRUCTION SET REFERENCE, A-M
MOV—Move
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
REX.W + A3 MOV
moffs64*,RAX
DValid N.E. Move RAX to (offset).
B0+ rb MOV r8, imm8 EValid Valid Move imm8 to r8.
REX + B0+ rb MOV r8***, imm8 EValid N.E. Move imm8 to r8.
B8+ rw MOV r16, imm16 EValid Valid Move imm16 to r16.
B8+ rd MOV r32, imm32 EValid Valid Move imm32 to r32.
REX.W + B8+ rd MOV r64, imm64 EValid N.E. Move imm64 to r64.
C6 /0MOV r/m8, imm8 FValid Valid Move imm8 to r/m8.
REX + C6 /0MOV r/m8***,
imm8
FValid N.E. Move imm8 to r/m8.
C7 /0MOV r/m16,
imm16
FValid Valid Move imm16 to r/m16.
C7 /0MOV r/m32,
imm32
FValid Valid Move imm32 to r/m32.
REX.W + C7 /0MOV r/m64,
imm32
FValid N.E. Move imm32 sign extended
to 64-bits to r/m64.
NOTES:
*The moffs8, moffs16, moffs32 and moffs64 operands specify a simple offset relative to the
segment base, where 8, 16, 32 and 64 refer to the size of the data. The address-size attribute
of the instruction determines the size of the offset, either 16, 32 or 64 bits.
** In 32-bit mode, the assembler may insert the 16-bit operand-size prefix with this instruction
(see the following “Description” section for further information).
***In 64-bit mode, r/m8 can not be encoded to access the following byte registers if a REX prefix
is used: AH, BH, CH, DH.

3-658 Vol. 2A MOV—Move
INSTRUCTION SET REFERENCE, A-M
Instruction Operand Encoding
Description
Copies the second operand (source operand) to the first operand (destination
operand). The source operand can be an immediate value, general-purpose register,
segment register, or memory location; the destination register can be a general-
purpose register, segment register, or memory location. Both operands must be the
same size, which can be a byte, a word, a doubleword, or a quadword.
The MOV instruction cannot be used to load the CS register. Attempting to do so
results in an invalid opcode exception (#UD). To load the CS register, use the far JMP,
CALL, or RET instruction.
If the destination operand is a segment register (DS, ES, FS, GS, or SS), the source
operand must be a valid segment selector. In protected mode, moving a segment
selector into a segment register automatically causes the segment descriptor infor-
mation associated with that segment selector to be loaded into the hidden (shadow)
part of the segment register. While loading this information, the segment selector
and segment descriptor information is validated (see the “Operation” algorithm
below). The segment descriptor data is obtained from the GDT or LDT entry for the
specified segment selector.
A NULL segment selector (values 0000-0003) can be loaded into the DS, ES, FS, and
GS registers without causing a protection exception. However, any subsequent
attempt to reference a segment whose corresponding segment register is loaded
with a NULL value causes a general protection exception (#GP) and no memory
reference occurs.
Loading the SS register with a MOV instruction inhibits all interrupts until after the
execution of the next instruction. This operation allows a stack pointer to be loaded
into the ESP register with the next instruction (MOV ESP, stack-pointer value)
before an interrupt occurs1. Be aware that the LSS instruction offers a more efficient
method of loading the SS and ESP registers.
When operating in 32-bit mode and moving data between a segment register and a
general-purpose register, the 32-bit IA-32 processors do not require the use of the
16-bit operand-size prefix (a byte with the value 66H) with this instruction, but most
assemblers will insert it if the standard form of the instruction is used (for example,
MOV DS, AX). The processor will execute this instruction correctly, but it will usually
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (w) ModRM:reg (r) NA NA
B ModRM:reg (w) ModRM:r/m (r) NA NA
C AL/AX/EAX/RAX Displacement NA NA
D Displacement AL/AX/EAX/RAX NA NA
E reg (w) imm8/16/32/64 NA NA
F ModRM:r/m (w) imm8/16/32/64 NA NA

Vol. 2A 3-659
INSTRUCTION SET REFERENCE, A-M
MOV—Move
require an extra clock. With most assemblers, using the instruction form MOV DS,
EAX will avoid this unneeded 66H prefix. When the processor executes the instruc-
tion with a 32-bit general-purpose register, it assumes that the 16 least-significant
bits of the general-purpose register are the destination or source operand. If the
register is a destination operand, the resulting value in the two high-order bytes of
the register is implementation dependent. For the Pentium 4, Intel Xeon, and P6
family processors, the two high-order bytes are filled with zeros; for earlier 32-bit
IA-32 processors, the two high order bytes are undefined.
In 64-bit mode, the instruction’s default operation size is 32 bits. Use of the REX.R
prefix permits access to additional registers (R8-R15). Use of the REX.W prefix
promotes operation to 64 bits. See the summary chart at the beginning of this
section for encoding data and limits.
Operation
DEST ← SRC;
Loading a segment register while in protected mode results in special checks and
actions, as described in the following listing. These checks are performed on the
segment selector and the segment descriptor to which it points.
IF SS is loaded
THEN
IF segment selector is NULL
THEN #GP(0); FI;
IF segment selector index is outside descriptor table limits
or segment selector's RPL ≠ CPL
or segment is not a writable data segment
or DPL ≠ CPL
THEN #GP(selector); FI;
IF segment not marked present
THEN #SS(selector);
ELSE
SS ← segment selector;
SS ← segment descriptor; FI;
1. If a code instruction breakpoint (for debug) is placed on an instruction located immediately after
a MOV SS instruction, the breakpoint may not be triggered. However, in a sequence of instruc-
tions that load the SS register, only the first instruction in the sequence is guaranteed to delay
an interrupt.
In the following sequence, interrupts may be recognized before MOV ESP, EBP executes:
MOV SS, EDX
MOV SS, EAX
MOV ESP, EBP

3-660 Vol. 2A MOV—Move
INSTRUCTION SET REFERENCE, A-M
FI;
IF DS, ES, FS, or GS is loaded with non-NULL selector
THEN
IF segment selector index is outside descriptor table limits
or segment is not a data or readable code segment
or ((segment is a data or nonconforming code segment)
and (both RPL and CPL > DPL))
THEN #GP(selector); FI;
IF segment not marked present
THEN #NP(selector);
ELSE
SegmentRegister ← segment selector;
SegmentRegister ← segment descriptor; FI;
FI;
IF DS, ES, FS, or GS is loaded with NULL selector
THEN
SegmentRegister ← segment selector;
SegmentRegister ← segment descriptor;
FI;
Flags Affected
None.
Protected Mode Exceptions
#GP(0) If attempt is made to load SS register with NULL segment
selector.
If the destination operand is in a non-writable segment.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#GP(selector) If segment selector index is outside descriptor table limits.
If the SS register is being loaded and the segment selector's RPL
and the segment descriptor’s DPL are not equal to the CPL.
If the SS register is being loaded and the segment pointed to is a
non-writable data segment.
If the DS, ES, FS, or GS register is being loaded and the
segment pointed to is not a data or readable code segment.
If the DS, ES, FS, or GS register is being loaded and the
segment pointed to is a data or nonconforming code segment,
but both the RPL and the CPL are greater than the DPL.

Vol. 2A 3-661
INSTRUCTION SET REFERENCE, A-M
MOV—Move
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#SS(selector) If the SS register is being loaded and the segment pointed to is
marked not present.
#NP If the DS, ES, FS, or GS register is being loaded and the
segment pointed to is marked not present.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If attempt is made to load the CS register.
If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#UD If attempt is made to load the CS register.
If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If attempt is made to load the CS register.
If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#GP(0) If the memory address is in a non-canonical form.
If an attempt is made to load SS register with NULL segment
selector when CPL = 3.
If an attempt is made to load SS register with NULL segment
selector when CPL < 3 and CPL ≠ RPL.

3-662 Vol. 2A MOV—Move
INSTRUCTION SET REFERENCE, A-M
#GP(selector) If segment selector index is outside descriptor table limits.
If the memory access to the descriptor table is non-canonical.
If the SS register is being loaded and the segment selector's RPL
and the segment descriptor’s DPL are not equal to the CPL.
If the SS register is being loaded and the segment pointed to is
a nonwritable data segment.
If the DS, ES, FS, or GS register is being loaded and the
segment pointed to is not a data or readable code segment.
If the DS, ES, FS, or GS register is being loaded and the
segment pointed to is a data or nonconforming code segment,
but both the RPL and the CPL are greater than the DPL.
#SS(0) If the stack address is in a non-canonical form.
#SS(selector) If the SS register is being loaded and the segment pointed to is
marked not present.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If attempt is made to load the CS register.
If the LOCK prefix is used.
Vol. 2A 3-663
INSTRUCTION SET REFERENCE, A-M
MOV—Move to/from Control Registers
MOV—Move to/from Control Registers
Instruction Operand Encoding
Description
Moves the contents of a control register (CR0, CR2, CR3, CR4, or CR8) to a general-
purpose register or the contents of a general purpose register to a control register.
The operand size for these instructions is always 32 bits in non-64-bit modes,
regardless of the operand-size attribute. (See “Control Registers” in Chapter 2 of the
Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 3A, for a
detailed description of the flags and fields in the control registers.) This instruction
can be executed only when the current privilege level is 0.
At the opcode level, the reg field within the ModR/M byte specifies which of the
control registers is loaded or read. The 2 bits in the mod field are ignored. The r/m
field specifies the general-purpose register loaded or read. Attempts to reference
CR1, CR5, CR6, CR7, and CR9–CR15 result in undefined opcode (#UD) exceptions.
When loading control registers, programs should not attempt to change the reserved
bits; that is, always set reserved bits to the value previously read. An attempt to
change CR4's reserved bits will cause a general protection fault. Reserved bits in CR0
and CR3 remain clear after any load of those registers; attempts to set them have no
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F 20/rMOV r32, CR0–
CR7
A N.E. Valid Move control register to r32
0F 20/rMOV r64, CR0–
CR7
A Valid N.E. Move extended control
register to r64.
REX.R + 0F 20
/0
MOV r64, CR8 A Valid N.E. Move extended CR8 to
r64.1
0F 22 /rMOV CR0–CR7,
r32
AN.E. Valid Move r32 to control register
0F 22 /rMOV CR0–CR7,
r64
AValid N.E. Move r64 to extended
control register.
REX.R + 0F 22
/0
MOV CR8, r64 AValid N.E. Move r64 to extended
CR8.1
NOTE:
1. MOV CR* instructions, except for MOV CR8, are serializing instructions. MOV CR8 is not
architecturally defined as a serializing instruction. For more information, see Chapter 8 in Intel®
64 and IA-32 Architectures Software Developer’s Manual, Volume 3A.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA

3-664 Vol. 2A MOV—Move to/from Control Registers
INSTRUCTION SET REFERENCE, A-M
impact. On Pentium 4, Intel Xeon and P6 family processors, CR0.ET remains set after
any load of CR0; attempts to clear this bit have no impact.
In certain cases, these instructions have the side effect of invalidating entries in the
TLBs and the paging-structure caches. See Section 4.10.4.1, “Operations that Inval-
idate TLBs and Paging-Structure Caches,” in the Intel® 64 and IA-32 Architectures
Software Developer’s Manual, Volume 3A for details.
The following side effects are implementation-specific for the Pentium 4, Intel Xeon,
and P6 processor family: when modifying PE or PG in register CR0, or PSE or PAE in
register CR4, all TLB entries are flushed, including global entries. Software should not
depend on this functionality in all Intel 64 or IA-32 processors.
In 64-bit mode, the instruction’s default operation size is 64 bits. The REX.R prefix
must be used to access CR8. Use of REX.B permits access to additional registers (R8-
R15). Use of the REX.W prefix or 66H prefix is ignored. Use of the REX.R prefix to
specify a register other than CR8 causes an invalid-opcode exception. See the
summary chart at the beginning of this section for encoding data and limits.
If CR4.PCIDE = 1, bit 63 of the source operand to MOV to CR3 determines whether
the instruction invalidates entries in the TLBs and the paging-structure caches (see
Section 4.10.4.1, “Operations that Invalidate TLBs and Paging-Structure Caches,” in
the Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 3A).
The instruction does not modify bit 63 of CR3, which is reserved and always 0.
See “Changes to Instruction Behavior in VMX Non-Root Operation” in Chapter 22 of
the Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 3B, for
more information about the behavior of this instruction in VMX non-root operation.
Operation
DEST ← SRC;
Flags Affected
The OF, SF, ZF, AF, PF, and CF flags are undefined.
Protected Mode Exceptions
#GP(0) If the current privilege level is not 0.
If an attempt is made to write invalid bit combinations in CR0
(such as setting the PG flag to 1 when the PE flag is set to 0, or
setting the CD flag to 0 when the NW flag is set to 1).
If an attempt is made to write a 1 to any reserved bit in CR4.
If an attempt is made to write 1 to CR4.PCIDE.
If any of the reserved bits are set in the page-directory pointers
table (PDPT) and the loading of a control register causes the
PDPT to be loaded into the processor.
#UD If the LOCK prefix is used.

Vol. 2A 3-665
INSTRUCTION SET REFERENCE, A-M
MOV—Move to/from Control Registers
If an attempt is made to access CR1, CR5, CR6, or CR7.
Real-Address Mode Exceptions
#GP If an attempt is made to write a 1 to any reserved bit in CR4.
If an attempt is made to write 1 to CR4.PCIDE.
If an attempt is made to write invalid bit combinations in CR0
(such as setting the PG flag to 1 when the PE flag is set to 0).
#UD If the LOCK prefix is used.
If an attempt is made to access CR1, CR5, CR6, or CR7.
Virtual-8086 Mode Exceptions
#GP(0) These instructions cannot be executed in virtual-8086 mode.
Compatibility Mode Exceptions
#GP(0) If the current privilege level is not 0.
If an attempt is made to write invalid bit combinations in CR0
(such as setting the PG flag to 1 when the PE flag is set to 0, or
setting the CD flag to 0 when the NW flag is set to 1).
If an attempt is made to change CR4.PCIDE from 0 to 1 while
CR3[11:0] ≠ 000H.
If an attempt is made to clear CR0.PG[bit 31] while
CR4.PCIDE = 1.
If an attempt is made to write a 1 to any reserved bit in CR3.
If an attempt is made to leave IA-32e mode by clearing
CR4.PAE[bit 5].
#UD If the LOCK prefix is used.
If an attempt is made to access CR1, CR5, CR6, or CR7.
64-Bit Mode Exceptions
#GP(0) If the current privilege level is not 0.
If an attempt is made to write invalid bit combinations in CR0
(such as setting the PG flag to 1 when the PE flag is set to 0, or
setting the CD flag to 0 when the NW flag is set to 1).
If an attempt is made to change CR4.PCIDE from 0 to 1 while
CR3[11:0] ≠ 000H.
If an attempt is made to clear CR0.PG[bit 31].
If an attempt is made to write a 1 to any reserved bit in CR4.
If an attempt is made to write a 1 to any reserved bit in CR8.
If an attempt is made to write a 1 to any reserved bit in CR3.

3-666 Vol. 2A MOV—Move to/from Control Registers
INSTRUCTION SET REFERENCE, A-M
If an attempt is made to leave IA-32e mode by clearing
CR4.PAE[bit 5].
#UD If the LOCK prefix is used.
If an attempt is made to access CR1, CR5, CR6, or CR7.
If the REX.R prefix is used to specify a register other than CR8.

Vol. 2A 3-667
INSTRUCTION SET REFERENCE, A-M
MOV—Move to/from Debug Registers
MOV—Move to/from Debug Registers
Instruction Operand Encoding
Description
Moves the contents of a debug register (DR0, DR1, DR2, DR3, DR4, DR5, DR6, or
DR7) to a general-purpose register or vice versa. The operand size for these instruc-
tions is always 32 bits in non-64-bit modes, regardless of the operand-size attribute.
(See Chapter 20, “Introduction to Virtual-Machine Extensions”, of the Intel® 64 and
IA-32 Architectures Software Developer’s Manual, Volume 3A, for a detailed descrip-
tion of the flags and fields in the debug registers.)
The instructions must be executed at privilege level 0 or in real-address mode.
When the debug extension (DE) flag in register CR4 is clear, these instructions
operate on debug registers in a manner that is compatible with Intel386 and Intel486
processors. In this mode, references to DR4 and DR5 refer to DR6 and DR7, respec-
tively. When the DE flag in CR4 is set, attempts to reference DR4 and DR5 result in
an undefined opcode (#UD) exception. (The CR4 register was added to the IA-32
Architecture beginning with the Pentium processor.)
At the opcode level, the reg field within the ModR/M byte specifies which of the debug
registers is loaded or read. The two bits in the mod field are ignored. The r/m field
specifies the general-purpose register loaded or read.
In 64-bit mode, the instruction’s default operation size is 64 bits. Use of the REX.B
prefix permits access to additional registers (R8–R15). Use of the REX.W or 66H
prefix is ignored. Use of the REX.R prefix causes an invalid-opcode exception. See
the summary chart at the beginning of this section for encoding data and limits.
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F 21/rMOV r32, DR0–
DR7
A N.E. Valid Move debug register to r32
0F 21/rMOV r64, DR0–
DR7
A Valid N.E. Move extended debug
register to r64.
0F 23 /rMOV DR0–DR7,
r32
AN.E. Valid Move r32 to debug register
0F 23 /rMOV DR0–DR7,
r64
AValid N.E. Move r64 to extended
debug register.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA

3-668 Vol. 2A MOV—Move to/from Debug Registers
INSTRUCTION SET REFERENCE, A-M
Operation
IF ((DE = 1) and (SRC or DEST = DR4 or DR5))
THEN
#UD;
ELSE
DEST ← SRC;
FI;
Flags Affected
The OF, SF, ZF, AF, PF, and CF flags are undefined.
Protected Mode Exceptions
#GP(0) If the current privilege level is not 0.
#UD If CR4.DE[bit 3] = 1 (debug extensions) and a MOV instruction
is executed involving DR4 or DR5.
If the LOCK prefix is used.
#DB If any debug register is accessed while the DR7.GD[bit 13] = 1.
Real-Address Mode Exceptions
#UD If CR4.DE[bit 3] = 1 (debug extensions) and a MOV instruction
is executed involving DR4 or DR5.
If the LOCK prefix is used.
#DB If any debug register is accessed while the DR7.GD[bit 13] = 1.
Virtual-8086 Mode Exceptions
#GP(0) The debug registers cannot be loaded or read when in virtual-
8086 mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#GP(0) If the current privilege level is not 0.
#UD If CR4.DE[bit 3] = 1 (debug extensions) and a MOV instruction
is executed involving DR4 or DR5.
If the LOCK prefix is used.
If the REX.R prefix is used.
#DB If any debug register is accessed while the DR7.GD[bit 13] = 1.

Vol. 2A 3-669
INSTRUCTION SET REFERENCE, A-M
MOVAPD—Move Aligned Packed Double-Precision Floating-Point Values
MOVAPD—Move Aligned Packed Double-Precision Floating-Point
Values
Instruction Operand Encoding
Description
Moves 2 or 4 double-precision floating-point values from the source operand (second
operand) to the destination operand (first operand). This instruction can be used to
load an XMM or YMM register from an 128-bit or 256-bit memory location, to store
the contents of an XMM or YMM register into a 128-bit or 256-bit memory location, or
to move data between two XMM or two YMM registers. When the source or destina-
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 28 /r
MOVAPD xmm1, xmm2/m128
AV/V SSE2 Move packed double-
precision floating-point
values from xmm2/m128 to
xmm1.
66 0F 29 /r
MOVAPD xmm2/m128, xmm1
BV/V SSE2 Move packed double-
precision floating-point
values from xmm1 to
xmm2/m128.
VEX.128.66.0F.WIG 28 /r
VMOVAPD xmm1, xmm2/m128
A V/V AVX Move aligned packed
double-precision floating-
point values from
xmm2/mem to xmm1.
VEX.128.66.0F.WIG 29 /r
VMOVAPD xmm2/m128, xmm1
B V/V AVX Move aligned packed
double-precision floating-
point values from xmm1 to
xmm2/mem.
VEX.256.66.0F.WIG 28 /r
VMOVAPD ymm1, ymm2/m256
A V/V AVX Move aligned packed
double-precision floating-
point values from
ymm2/mem to ymm1.
VEX.256.66.0F.WIG 29 /r
VMOVAPD ymm2/m256, ymm1
B V/V AVX Move aligned packed
double-precision floating-
point values from ymm1 to
ymm2/mem.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA
B ModRM:r/m (w) ModRM:reg (r) NA NA

3-670 Vol. 2A MOVAPD—Move Aligned Packed Double-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
tion operand is a memory operand, the operand must be aligned on a 16-byte (128-
bit version) or 32-byte (VEX.256 encoded version) boundary or a general-protection
exception (#GP) will be generated.
To move double-precision floating-point values to and from unaligned memory loca-
tions, use the (V)MOVUPD instruction.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
Note: In VEX-encoded versions, VEX.vvvv is reserved and must be 1111b otherwise
instructions will #UD.
128-bit versions:
Moves 128 bits of packed double-precision floating-point values from the source
operand (second operand) to the destination operand (first operand). This instruction
can be used to load an XMM register from a 128-bit memory location, to store the
contents of an XMM register into a 128-bit memory location, or to move data
between two XMM registers. When the source or destination operand is a memory
operand, the operand must be aligned on a 16-byte boundary or a general-protection
exception (#GP) will be generated. To move single-precision floating-point values to
and from unaligned memory locations, use the VMOVUPD instruction.
128-bit Legacy SSE version: Bits (VLMAX-1:128) of the corresponding YMM destina-
tion register remain unchanged.
VEX.128 encoded version: Bits (VLMAX-1:128) of the destination YMM register desti-
nation are zeroed.
VEX.256 encoded version:
Moves 256 bits of packed double-precision floating-point values from the source
operand (second operand) to the destination operand (first operand). This instruction
can be used to load a YMM register from a 256-bit memory location, to store the
contents of a YMM register into a 256-bit memory location, or to move data between
two YMM registers. When the source or destination operand is a memory operand,
the operand must be aligned on a 32-byte boundary or a general-protection excep-
tion (#GP) will be generated. To move single-precision floating-point values to and
from unaligned memory locations, use the VMOVUPD instruction.
Operation
MOVAPD (128-bit load- and register-copy- form Legacy SSE version)
DEST[127:0] SRC[127:0]
DEST[VLMAX-1:128] (Unmodified)
(V)MOVAPD (128-bit store-form version)
DEST[127:0] SRC[127:0]
VMOVAPD (VEX.128 encoded version)
DEST[127:0] SRC[127:0]

Vol. 2A 3-671
INSTRUCTION SET REFERENCE, A-M
MOVAPD—Move Aligned Packed Double-Precision Floating-Point Values
DEST[VLMAX-1:128] 0
VMOVAPD (VEX.256 encoded version)
DEST[255:0] SRC[255:0]
Intel C/C++ Compiler Intrinsic Equivalent
MOVAPD __m128d _mm_load_pd (double const * p);
MOVAPD _mm_store_pd(double * p, __m128d a);
VMOVAPD __m256d _mm256_load_pd (double const * p);
VMOVAPD _mm256_store_pd(double * p, __m256d a);
SIMD Floating-Point Exceptions
None.
Other Exceptions
See Exceptions Type 1.SSE2; additionally
#UD If VEX.vvvv != 1111B.

3-672 Vol. 2A MOVAPS—Move Aligned Packed Single-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
MOVAPS—Move Aligned Packed Single-Precision Floating-Point Values
Instruction Operand Encoding
Description
Moves 4 or8 single-precision floating-point values from the source operand (second
operand) to the destination operand (first operand). This instruction can be used to
load an XMM or YMM register from an 128-bit or 256-bit memory location, to store
the contents of an XMM or YMM register into a 128-bit or 256-bit memory location, or
to move data between two XMM or two YMM registers. When the source or destina-
tion operand is a memory operand, the operand must be aligned on a 16-byte (128-
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
0F 28 /r
MOVAPS xmm1, xmm2/m128
A V/V SSE Move packed single-
precision floating-point
values from xmm2/m128 to
xmm1.
0F 29 /r
MOVAPS xmm2/m128, xmm1
B V/V SSE Move packed single-
precision floating-point
values from xmm1 to
xmm2/m128.
VEX.128.0F.WIG 28 /r
VMOVAPS xmm1, xmm2/m128
A V/V AVX Move aligned packed single-
precision floating-point
values from xmm2/mem to
xmm1.
VEX.128.0F.WIG 29 /r
VMOVAPS xmm2/m128, xmm1
B V/V AVX Move aligned packed single-
precision floating-point
values from xmm1 to
xmm2/mem.
VEX.256.0F.WIG 28 /r
VMOVAPS ymm1, ymm2/m256
A V/V AVX Move aligned packed single-
precision floating-point
values from ymm2/mem to
ymm1.
VEX.256.0F.WIG 29 /r
VMOVAPS ymm2/m256, ymm1
B V/V AVX Move aligned packed single-
precision floating-point
values from ymm1 to
ymm2/mem.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA
B ModRM:r/m (w) ModRM:reg (r) NA NA

Vol. 2A 3-673
INSTRUCTION SET REFERENCE, A-M
MOVAPS—Move Aligned Packed Single-Precision Floating-Point Values
bit version) or 32-byte (VEX.256 encoded version) boundary or a general-protection
exception (#GP) will be generated.
To move single-precision floating-point values to and from unaligned memory loca-
tions, use the (V)MOVUPS instruction.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
Note: In VEX-encoded versions, VEX.vvvv is reserved and must be 1111b otherwise
instructions will #UD.
128-bit versions:
Moves 128 bits of packed single-precision floating-point values from the source
operand (second operand) to the destination operand (first operand). This instruction
can be used to load an XMM register from a 128-bit memory location, to store the
contents of an XMM register into a 128-bit memory location, or to move data
between two XMM registers. When the source or destination operand is a memory
operand, the operand must be aligned on a 16-byte boundary or a general-protection
exception (#GP) will be generated. To move single-precision floating-point values to
and from unaligned memory locations, use the VMOVUPS instruction.
128-bit Legacy SSE version: Bits (VLMAX-1:128) of the corresponding YMM destina-
tion register remain unchanged.
VEX.128 encoded version: Bits (VLMAX-1:128) of the destination YMM register are
zeroed.
VEX.256 encoded version:
Moves 256 bits of packed single-precision floating-point values from the source
operand (second operand) to the destination operand (first operand). This instruction
can be used to load a YMM register from a 256-bit memory location, to store the
contents of a YMM register into a 256-bit memory location, or to move data between
two YMM registers.
Operation
MOVAPS (128-bit load- and register-copy- form Legacy SSE version)
DEST[127:0] SRC[127:0]
DEST[VLMAX-1:128] (Unmodified)
(V)MOVAPS (128-bit store form)
DEST[127:0] SRC[127:0]
VMOVAPS (VEX.128 encoded version)
DEST[127:0] SRC[127:0]
DEST[VLMAX-1:128] 0
VMOVAPS (VEX.256 encoded version)

3-674 Vol. 2A MOVAPS—Move Aligned Packed Single-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
DEST[255:0] SRC[255:0]
Intel C/C++ Compiler Intrinsic Equivalent
MOVAPS __m128 _mm_load_ps (float const * p);
MOVAPS _mm_store_ps(float * p, __m128 a);
VMOVAPS __m256 _mm256_load_ps (float const * p);
VMOVAPS _mm256_store_ps(float * p, __m256 a);
SIMD Floating-Point Exceptions
None.
Other Exceptions
See Exceptions Type 1.SSE; additionally
#UD If VEX.vvvv != 1111B.
Vol. 2A 3-675
INSTRUCTION SET REFERENCE, A-M
MOVBE—Move Data After Swapping Bytes
MOVBE—Move Data After Swapping Bytes
Instruction Operand Encoding
Description
Performs a byte swap operation on the data copied from the second operand (source
operand) and store the result in the first operand (destination operand). The source
operand can be a general-purpose register, or memory location; the destination
register can be a general-purpose register, or a memory location; however, both
operands can not be registers, and only one operand can be a memory location. Both
operands must be the same size, which can be a word, a doubleword or quadword.
The MOVBE instruction is provided for swapping the bytes on a read from memory or
on a write to memory; thus providing support for converting little-endian values to
big-endian format and vice versa.
In 64-bit mode, the instruction's default operation size is 32 bits. Use of the REX.R
prefix permits access to additional registers (R8-R15). Use of the REX.W prefix
promotes operation to 64 bits. See the summary chart at the beginning of this
section for encoding data and limits.
Operation
TEMP ← SRC
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F 38 F0 /rMOVBE r16, m16 A Valid Valid Reverse byte order in m16
and move to r16
0F 38 F0 /rMOVBE r32, m32 A Valid Valid Reverse byte order in m32
and move to r32
REX.W + 0F 38
F0 /r
MOVBE r64, m64 A Valid N.E. Reverse byte order in m64
and move to r64.
0F 38 F1 /rMOVBE m16, r16 B Valid Valid Reverse byte order in r16
and move to m16
0F 38 F1 /rMOVBE m32, r32 B Valid Valid Reverse byte order in r32
and move to m32
REX.W + 0F 38
F1 /r
MOVBE m64, r64 B Valid N.E. Reverse byte order in r64
and move to m64.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA
B ModRM:r/m (w) ModRM:reg (r) NA NA

3-676 Vol. 2A MOVBE—Move Data After Swapping Bytes
INSTRUCTION SET REFERENCE, A-M
IF ( OperandSize = 16)
THEN
DEST[7:0] ← TEMP[15:8];
DEST[15:8] ← TEMP[7:0];
ELES IF ( OperandSize = 32)
DEST[7:0] ← TEMP[31:24];
DEST[15:8] ← TEMP[23:16];
DEST[23:16] ← TEMP[15:8];
DEST[31:23] ← TEMP[7:0];
ELSE IF ( OperandSize = 64)
DEST[7:0] ← TEMP[63:56];
DEST[15:8] ← TEMP[55:48];
DEST[23:16] ← TEMP[47:40];
DEST[31:24] ← TEMP[39:32];
DEST[39:32] ← TEMP[31:24];
DEST[47:40] ← TEMP[23:16];
DEST[55:48] ← TEMP[15:8];
DEST[63:56] ← TEMP[7:0];
FI;
Flags Affected
None.
Protected Mode Exceptions
#GP(0) If the destination operand is in a non-writable segment.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If CPUID.01H:ECX.MOVBE[bit 22] = 0 .
If the LOCK prefix is used.
If REP (F3H) prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.

Vol. 2A 3-677
INSTRUCTION SET REFERENCE, A-M
MOVBE—Move Data After Swapping Bytes
#SS If a memory operand effective address is outside the SS
segment limit.
#UD If CPUID.01H:ECX.MOVBE[bit 22] = 0 .
If the LOCK prefix is used.
If REP (F3H) prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#UD If CPUID.01H:ECX.MOVBE[bit 22] = 0 .
If the LOCK prefix is used.
If REP (F3H) prefix is used.
If REPNE (F2H) prefix is used and CPUID.01H:ECX.SSE4_2[bit
20] = 0.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#GP(0) If the memory address is in a non-canonical form.
#SS(0) If the stack address is in a non-canonical form.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If CPUID.01H:ECX.MOVBE[bit 22] = 0 .
If the LOCK prefix is used.
If REP (F3H) prefix is used.

3-678 Vol. 2A MOVD/MOVQ—Move Doubleword/Move Quadword
INSTRUCTION SET REFERENCE, A-M
MOVD/MOVQ—Move Doubleword/Move Quadword
Instruction Operand Encoding
Description
Copies a doubleword from the source operand (second operand) to the destination
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
0F 6E /r
MOVD mm, r/m32
A V/V SSE2 Move doubleword from
r/m32 to mm.
REX.W + 0F 6E /r
MOVQ mm, r/m64
AV/N.E. SSE2 Move quadword from r/m64
to mm.
0F 7E /r
MOVD r/m32, mm
B V/V SSE2 Move doubleword from mm
to r/m32.
REX.W + 0F 7E /r
MOVQ r/m64, mm
BV/N.E. SSE2 Move quadword from mm to
r/m64.
VEX.128.66.0F.W0 6E /
VMOVD xmm1, r32/m32
AV/V AVX Move doubleword from
r/m32 to xmm1.
VEX.128.66.0F.W1 6E /r
VMOVQ xmm1, r64/m64
A V/N.E. AVX Move quadword from r/m64
to xmm1.
66 0F 6E /r
MOVD xmm, r/m32
A V/V SSE2 Move doubleword from
r/m32 to xmm.
66 REX.W 0F 6E /r
MOVQ xmm, r/m64
AV/N.E. SSE2 Move quadword from r/m64
to xmm.
66 0F 7E /r
MOVD r/m32, xmm
B V/V SSE2 Move doubleword from
xmm register to r/m32.
66 REX.W 0F 7E /r
MOVQ r/m64, xmm
B V/N.E. SSE2 Move quadword from xmm
register to r/m64.
VEX.128.66.0F.W0 7E /r
VMOVD r32/m32, xmm1
BV/V AVX Move doubleword from
xmm1 register to r/m32.
VEX.128.66.0F.W1 7E /r
VMOVQ r64/m64, xmm1
BV/N.E. AVX Move quadword from xmm1
register to r/m64.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA
B ModRM:r/m (w) ModRM:reg (r) NA NA

Vol. 2A 3-679
INSTRUCTION SET REFERENCE, A-M
MOVD/MOVQ—Move Doubleword/Move Quadword
operand (first operand). The source and destination operands can be general-
purpose registers, MMX technology registers, XMM registers, or 32-bit memory loca-
tions. This instruction can be used to move a doubleword to and from the low double-
word of an MMX technology register and a general-purpose register or a 32-bit
memory location, or to and from the low doubleword of an XMM register and a
general-purpose register or a 32-bit memory location. The instruction cannot be
used to transfer data between MMX technology registers, between XMM registers,
between general-purpose registers, or between memory locations.
When the destination operand is an MMX technology register, the source operand is
written to the low doubleword of the register, and the register is zero-extended to 64
bits. When the destination operand is an XMM register, the source operand is written
to the low doubleword of the register, and the register is zero-extended to 128 bits.
In 64-bit mode, the instruction’s default operation size is 32 bits. Use of the REX.R
prefix permits access to additional registers (R8-R15). Use of the REX.W prefix
promotes operation to 64 bits. See the summary chart at the beginning of this
section for encoding data and limits.
Operation
MOVD (when destination operand is MMX technology register)
DEST[31:0] ← SRC;
DEST[63:32] ← 00000000H;
MOVD (when destination operand is XMM register)
DEST[31:0] ← SRC;
DEST[127:32] ← 000000000000000000000000H;
DEST[VLMAX-1:128] (Unmodified)
MOVD (when source operand is MMX technology or XMM register)
DEST ← SRC[31:0];
VMOVD (VEX-encoded version when destination is an XMM register)
DEST[31:0] SRC[31:0]
DEST[VLMAX-1:32] 0
MOVQ (when destination operand is XMM register)
DEST[63:0] ← SRC[63:0];
DEST[127:64] ← 0000000000000000H;
DEST[VLMAX-1:128] (Unmodified)
MOVQ (when destination operand is r/m64)
DEST[63:0] ← SRC[63:0];
MOVQ (when source operand is XMM register or r/m64)
DEST ← SRC[63:0];

3-680 Vol. 2A MOVD/MOVQ—Move Doubleword/Move Quadword
INSTRUCTION SET REFERENCE, A-M
VMOVQ (VEX-encoded version when destination is an XMM register)
DEST[63:0] SRC[63:0]
DEST[VLMAX-1:64] 0
Intel C/C++ Compiler Intrinsic Equivalent
MOVD __m64 _mm_cvtsi32_si64 (int i )
MOVD int _mm_cvtsi64_si32 ( __m64m )
MOVD __m128i _mm_cvtsi32_si128 (int a)
MOVD int _mm_cvtsi128_si32 ( __m128i a)
Flags Affected
None.
SIMD Floating-Point Exceptions
None.
Other Exceptions
See Exceptions Type 5; additionally
#UD If VEX.L = 1.
If VEX.vvvv != 1111B.

Vol. 2A 3-681
INSTRUCTION SET REFERENCE, A-M
MOVDDUP—Move One Double-FP and Duplicate
MOVDDUP—Move One Double-FP and Duplicate
Instruction Operand Encoding
Description
The linear address corresponds to the address of the least-significant byte of the
referenced memory data. When a memory address is indicated, the 8 bytes of data
at memory location m64 are loaded. When the register-register form of this opera-
tion is used, the lower half of the 128-bit source register is duplicated and copied into
the 128-bit destination register. See Figure 3-27.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F2 0F 12 /r
MOVDDUP xmm1, xmm2/m64
A V/V SSE3 Move one double-precision
floating-point value from
the lower 64-bit operand in
xmm2/m64 to xmm1 and
duplicate.
VEX.128.F2.0F.WIG 12 /r
VMOVDDUP xmm1, xmm2/m64
AV/V AVX Move double-precision
floating-point values from
xmm2/mem and duplicate
into xmm1.
VEX.256.F2.0F.WIG 12 /r
VMOVDDUP ymm1, ymm2/m256
AV/V AVX Move even index double-
precision floating-point
values from ymm2/mem and
duplicate each element into
ymm1.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA
3-682 Vol. 2A MOVDDUP—Move One Double-FP and Duplicate
INSTRUCTION SET REFERENCE, A-M
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
Operation
IF (Source = m64)
THEN
(* Load instruction *)
xmm1[63:0] = m64;
xmm1[127:64] = m64;
ELSE
(* Move instruction *)
xmm1[63:0] = xmm2[63:0];
xmm1[127:64] = xmm2[63:0];
FI;
MOVDDUP (128-bit Legacy SSE version)
DEST[63:0] SRC[63:0]
DEST[127:64] SRC[63:0]
DEST[VLMAX-1:128] (Unmodified)
VMOVDDUP (VEX.128 encoded version)
DEST[63:0] SRC[63:0]
DEST[127:64] SRC[63:0]
Figure 3-27. MOVDDUP—Move One Double-FP and Duplicate
20
[PP>@[PPP>@ [PP>@[PPP>@
>@
>@ >@
029''83[PP[PPP
5(68/7
[PP
[PPP

Vol. 2A 3-683
INSTRUCTION SET REFERENCE, A-M
MOVDDUP—Move One Double-FP and Duplicate
DEST[VLMAX-1:128] 0
VMOVDDUP (VEX.256 encoded version)
DEST[63:0] SRC[63:0]
DEST[127:64] SRC[63:0]
DEST[191:128] SRC[191:128]
DEST[255:192] SRC[191:128]
Intel C/C++ Compiler Intrinsic Equivalent
MOVDDUP __m128d _mm_movedup_pd(__m128d a)
MOVDDUP __m128d _mm_loaddup_pd(double const * dp)
SIMD Floating-Point Exceptions
None
Other Exceptions
See Exceptions Type 5; additionally
#UD If VEX.vvvv != 1111B.
3-684 Vol. 2A MOVDQA—Move Aligned Double Quadword
INSTRUCTION SET REFERENCE, A-M
MOVDQA—Move Aligned Double Quadword
Instruction Operand Encoding
Description
128-bit versions:
Moves 128 bits of packed integer values from the source operand (second operand)
to the destination operand (first operand). This instruction can be used to load an
XMM register from a 128-bit memory location, to store the contents of an XMM
register into a 128-bit memory location, or to move data between two XMM registers.
When the source or destination operand is a memory operand, the operand must be
aligned on a 16-byte boundary or a general-protection exception (#GP) will be
generated. To move integer data to and from unaligned memory locations, use the
VMOVDQU instruction.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 6F /r
MOVDQA xmm1, xmm2/m128
A V/V SSE2 Move aligned double
quadword from
xmm2/m128 to xmm1.
66 0F 7F /r
MOVDQA xmm2/m128, xmm1
B V/V SSE2 Move aligned double
quadword from xmm1 to
xmm2/m128.
VEX.128.66.0F.WIG 6F /r
VMOVDQA xmm1, xmm2/m128
A V/V AVX Move aligned packed integer
values from xmm2/mem to
xmm1.
VEX.128.66.0F.WIG 7F /r
VMOVDQA xmm2/m128, xmm1
B V/V AVX Move aligned packed integer
values from xmm1 to
xmm2/mem.
VEX.256.66.0F.WIG 6F /r
VMOVDQA ymm1, ymm2/m256
A V/V AVX Move aligned packed integer
values from ymm2/mem to
ymm1.
VEX.256.66.0F.WIG 7F /r
VMOVDQA ymm2/m256, ymm1
B V/V AVX Move aligned packed integer
values from ymm1 to
ymm2/mem.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA
B ModRM:r/m (w) ModRM:reg (r) NA NA

Vol. 2A 3-685
INSTRUCTION SET REFERENCE, A-M
MOVDQA—Move Aligned Double Quadword
128-bit Legacy SSE version: Bits (VLMAX-1:128) of the corresponding YMM destina-
tion register remain unchanged.
VEX.128 encoded version: Bits (VLMAX-1:128) of the destination YMM register are
zeroed.
VEX.256 encoded version:
Moves 256 bits of packed integer values from the source operand (second operand)
to the destination operand (first operand). This instruction can be used to load a YMM
register from a 256-bit memory location, to store the contents of a YMM register into
a 256-bit memory location, or to move data between two YMM registers.
When the source or destination operand is a memory operand, the operand must be
aligned on a 32-byte boundary or a general-protection exception (#GP) will be
generated. To move integer data to and from unaligned memory locations, use the
VMOVDQU instruction.
Note: In VEX-encoded versions, VEX.vvvv is reserved and must be 1111b otherwise
instructions will #UD.
Operation
MOVDQA (128-bit load- and register- form Legacy SSE version)
DEST[127:0] SRC[127:0]
DEST[VLMAX-1:128] (Unmodified)
(* #GP if SRC or DEST unaligned memory operand *)
(V)MOVDQA (128-bit store forms)
DEST[127:0] SRC[127:0]
VMOVDQA (VEX.128 encoded version)
DEST[127:0] SRC[127:0]
DEST[VLMAX-1:128] 0
VMOVDQA (VEX.256 encoded version)
DEST[255:0] SRC[255:0]
Intel C/C++ Compiler Intrinsic Equivalent
MOVDQA __m128i _mm_load_si128 ( __m128i *p)
MOVDQA void _mm_store_si128 ( __m128i *p, __m128i a)
VMOVDQA __m256i _mm256_load_si256 (__m256i * p);
VMOVDQA _mm256_store_si256(_m256i *p, __m256i a);

3-686 Vol. 2A MOVDQA—Move Aligned Double Quadword
INSTRUCTION SET REFERENCE, A-M
SIMD Floating-Point Exceptions
None.
Other Exceptions
See Exceptions Type 1.SSE2; additionally
#UD If VEX.vvvv != 1111B.

Vol. 2A 3-687
INSTRUCTION SET REFERENCE, A-M
MOVDQU—Move Unaligned Double Quadword
MOVDQU—Move Unaligned Double Quadword
Instruction Operand Encoding
Description
128-bit versions:
Moves 128 bits of packed integer values from the source operand (second operand)
to the destination operand (first operand). This instruction can be used to load an
XMM register from a 128-bit memory location, to store the contents of an XMM
register into a 128-bit memory location, or to move data between two XMM registers.
When the source or destination operand is a memory operand, the operand may be
unaligned on a 16-byte boundary without causing a general-protection exception
(#GP) to be generated.1
To move a double quadword to or from memory locations that are known to be
aligned on 16-byte boundaries, use the MOVDQA instruction.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F3 0F 6F /r
MOVDQU xmm1, xmm2/m128
A V/V SSE2 Move unaligned double
quadword from
xmm2/m128 to xmm1.
F3 0F 7F /r
MOVDQU xmm2/m128, xmm1
B V/V SSE2 Move unaligned double
quadword from xmm1 to
xmm2/m128.
VEX.128.F3.0F.WIG 6F /r
VMOVDQU xmm1, xmm2/m128
A V/V AVX Move unaligned packed
integer values from
xmm2/mem to xmm1.
VEX.128.F3.0F.WIG 7F /r
VMOVDQU xmm2/m128, xmm1
B V/V AVX Move unaligned packed
integer values from xmm1
to xmm2/mem.
VEX.256.F3.0F.WIG 6F /r
VMOVDQU ymm1, ymm2/m256
A V/V AVX Move unaligned packed
integer values from
ymm2/mem to ymm1.
VEX.256.F3.0F.WIG 7F /r
VMOVDQU ymm2/m256, ymm1
B V/V AVX Move unaligned packed
integer values from ymm1
to ymm2/mem.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA
B ModRM:r/m (w) ModRM:reg (r) NA NA

3-688 Vol. 2A MOVDQU—Move Unaligned Double Quadword
INSTRUCTION SET REFERENCE, A-M
While executing in 16-bit addressing mode, a linear address for a 128-bit data access
that overlaps the end of a 16-bit segment is not allowed and is defined as reserved
behavior. A specific processor implementation may or may not generate a general-
protection exception (#GP) in this situation, and the address that spans the end of
the segment may or may not wrap around to the beginning of the segment.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
128-bit Legacy SSE version: Bits (VLMAX-1:128) of the corresponding YMM desti-
nation register remain unchanged.
When the source or destination operand is a memory operand, the operand may be
unaligned to any alignment without causing a general-protection exception (#GP) to
be generated
VEX.128 encoded version: Bits (VLMAX-1:128) of the destination YMM register
are zeroed.
VEX.256 encoded version:
Moves 256 bits of packed integer values from the source operand (second operand)
to the destination operand (first operand). This instruction can be used to load a YMM
register from a 256-bit memory location, to store the contents of a YMM register into
a 256-bit memory location, or to move data between two YMM registers.
Note: In VEX-encoded versions, VEX.vvvv is reserved and must be 1111b otherwise
instructions will #UD.
Operation
MOVDQU load and register copy (128-bit Legacy SSE version)
DEST[127:0] SRC[127:0]
DEST[VLMAX-1:128] (Unmodified)
(V)MOVDQU 128-bit store-form versions
DEST[127:0] SRC[127:0]
VMOVDQU (VEX.128 encoded version)
DEST[127:0] SRC[127:0]
DEST[VLMAX-1:128] 0
VMOVDQU (VEX.256 encoded version)
DEST[255:0] SRC[255:0]
1. If alignment checking is enabled (CR0.AM = 1, RFLAGS.AC = 1, and CPL = 3), an alignment-check
exception (#AC) may or may not be generated (depending on processor implementation) when
the operand is not aligned on an 8-byte boundary.

Vol. 2A 3-689
INSTRUCTION SET REFERENCE, A-M
MOVDQU—Move Unaligned Double Quadword
Intel C/C++ Compiler Intrinsic Equivalent
MOVDQU void _mm_storeu_si128 ( __m128i *p, __m128i a)
MOVDQU __m128i _mm_loadu_si128 ( __m128i *p)
VMOVDQU __m256i _mm256_loadu_si256 (__m256i * p);
VMOVDQU _mm256_storeu_si256(_m256i *p, __m256i a);
SIMD Floating-Point Exceptions
None.
Other Exceptions
See Exceptions Type 4; additionally
#UD If VEX.vvvv != 1111B.

3-690 Vol. 2A MOVDQ2Q—Move Quadword from XMM to MMX Technology Register
INSTRUCTION SET REFERENCE, A-M
MOVDQ2Q—Move Quadword from XMM to MMX Technology Register
Instruction Operand Encoding
Description
Moves the low quadword from the source operand (second operand) to the destina-
tion operand (first operand). The source operand is an XMM register and the destina-
tion operand is an MMX technology register.
This instruction causes a transition from x87 FPU to MMX technology operation (that
is, the x87 FPU top-of-stack pointer is set to 0 and the x87 FPU tag word is set to all
0s [valid]). If this instruction is executed while an x87 FPU floating-point exception is
pending, the exception is handled before the MOVDQ2Q instruction is executed.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
Operation
DEST ← SRC[63:0];
Intel C/C++ Compiler Intrinsic Equivalent
MOVDQ2Q __m64 _mm_movepi64_pi64 ( __m128i a)
SIMD Floating-Point Exceptions
None.
Protected Mode Exceptions
#NM If CR0.TS[bit 3] = 1.
#UD If CR0.EM[bit 2] = 1.
If CR4.OSFXSR[bit 9] = 0.
If CPUID.01H:EDX.SSE2[bit 26] = 0.
If the LOCK prefix is used.
#MF If there is a pending x87 FPU exception.
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
F2 0F D6 MOVDQ2Q mm,
xmm
A Valid Valid Move low quadword from
xmm to mmx register.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:reg (r) NA NA

Vol. 2A 3-691
INSTRUCTION SET REFERENCE, A-M
MOVDQ2Q—Move Quadword from XMM to MMX Technology Register
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.
3-692 Vol. 2A MOVHLPS— Move Packed Single-Precision Floating-Point Values High to Low
INSTRUCTION SET REFERENCE, A-M
MOVHLPS— Move Packed Single-Precision Floating-Point Values High
to Low
Instruction Operand Encoding
Description
This instruction cannot be used for memory to register moves.
128-bit two-argument form:
Moves two packed single-precision floating-point values from the high quadword of
the second XMM argument (second operand) to the low quadword of the first XMM
register (first argument). The high quadword of the destination operand is left
unchanged. Bits (VLMAX-1:64) of the corresponding YMM destination register are
unmodified.
128-bit three-argument form
Moves two packed single-precision floating-point values from the high quadword of
the third XMM argument (third operand) to the low quadword of the destination (first
operand). Copies the high quadword from the second XMM argument (second
operand) to the high quadword of the destination (first operand). Bits (VLMAX-
1:128) of the destination YMM register are zeroed.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
If VMOVHLPS is encoded with VEX.L= 1, an attempt to execute the instruction
encoded with VEX.L= 1 will cause an #UD exception.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
0F 12 /r
MOVHLPS xmm1, xmm2
A V/V SSE3 Move two packed single-
precision floating-point
values from high quadword
of xmm2 to low quadword
of xmm1.
VEX.NDS.128.0F.WIG 12 /r
VMOVHLPS xmm1, xmm2, xmm3
BV/V AVX Merge two packed single-
precision floating-point
values from high quadword
of xmm3 and low quadword
of xmm2.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:reg (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

Vol. 2A 3-693
INSTRUCTION SET REFERENCE, A-M
MOVHLPS— Move Packed Single-Precision Floating-Point Values High to Low
Operation
MOVHLPS (128-bit two-argument form)
DEST[63:0] SRC[127:64]
DEST[VLMAX-1:64] (Unmodified)
VMOVHLPS (128-bit three-argument form)
DEST[63:0] SRC2[127:64]
DEST[127:64] SRC1[127:64]
DEST[VLMAX-1:128] 0
Intel C/C++ Compiler Intrinsic Equivalent
MOVHLPS __m128 _mm_movehl_ps(__m128 a, __m128 b)
SIMD Floating-Point Exceptions
None.
Other Exceptions
See Exceptions Type 7; additionally
#UD If VEX.L= 1.
3-694 Vol. 2A MOVHPD—Move High Packed Double-Precision Floating-Point Value
INSTRUCTION SET REFERENCE, A-M
MOVHPD—Move High Packed Double-Precision Floating-Point Value
Instruction Operand Encoding
Description
This instruction cannot be used for register to register or memory to memory moves.
128-bit Legacy SSE load:
Moves a double-precision floating-point value from the source 64-bit memory
operand and stores it in the high 64-bits of the destination XMM register. The lower
64bits of the XMM register are preserved. The upper 128-bits of the corresponding
YMM destination register are preserved.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
VEX.128 encoded load:
Loads a double-precision floating-point value from the source 64-bit memory
operand (third operand) and stores it in the upper 64-bits of the destination XMM
register (first operand). The low 64-bits from second XMM register (second operand)
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 16 /r
MOVHPD xmm, m64
A V/V SSE2 Move double-precision
floating-point value from
m64 to high quadword of
xmm.
66 0F 17 /r
MOVHPD m64, xmm
B V/V SSE2 Move double-precision
floating-point value from
high quadword of xmm to
m64.
VEX.NDS.128.66.0F.WIG 16 /r
VMOVHPD xmm2, xmm1, m64
C V/V AVX Merge double-precision
floating-point value from
m64 and the low quadword
of xmm1.
VEX128.66.0F.WIG 17/r
VMOVHPD m64, xmm1
BV/V AVX Move double-precision
floating-point values from
high quadword of xmm1 to
m64.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:r/m (w) ModRM:reg (r) NA NA
C ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

Vol. 2A 3-695
INSTRUCTION SET REFERENCE, A-M
MOVHPD—Move High Packed Double-Precision Floating-Point Value
are stored in the lower 64-bits of the destination. The upper 128-bits of the destina-
tion YMM register are zeroed.
128-bit store:
Stores a double-precision floating-point value from the high 64-bits of the XMM
register source (second operand) to the 64-bit memory location (first operand).
Note: VMOVHPD (store) (VEX.128.66.0F 17 /r) is legal and has the same behavior as
the existing 66 0F 17 store. For VMOVHPD (store) (VEX.128.66.0F 17 /r) instruction
version, VEX.vvvv is reserved and must be 1111b otherwise instruction will #UD.
If VMOVHPD is encoded with VEX.L= 1, an attempt to execute the instruction
encoded with VEX.L= 1 will cause an #UD exception.
Operation
MOVHPD (128-bit Legacy SSE load)
DEST[63:0] (Unmodified)
DEST[127:64] SRC[63:0]
DEST[VLMAX-1:128] (Unmodified)
VMOVHPD (VEX.128 encoded load)
DEST[63:0] SRC1[63:0]
DEST[127:64] SRC2[63:0]
DEST[VLMAX-1:128] 0
VMOVHPD (store)
DEST[63:0] SRC[127:64]
Intel C/C++ Compiler Intrinsic Equivalent
MOVHPD __m128d _mm_loadh_pd ( __m128d a, double *p)
MOVHPD void _mm_storeh_pd (double *p, __m128d a)
SIMD Floating-Point Exceptions
None.
Other Exceptions
See Exceptions Type 5; additionally
#UD If VEX.L= 1.
3-696 Vol. 2A MOVHPS—Move High Packed Single-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
MOVHPS—Move High Packed Single-Precision Floating-Point Values
Instruction Operand Encoding
Description
This instruction cannot be used for register to register or memory to memory moves.
128-bit Legacy SSE load:
Moves two packed single-precision floating-point values from the source 64-bit
memory operand and stores them in the high 64-bits of the destination XMM register.
The lower 64bits of the XMM register are preserved. The upper 128-bits of the corre-
sponding YMM destination register are preserved.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
VEX.128 encoded load:
Loads two single-precision floating-point values from the source 64-bit memory
operand (third operand) and stores it in the upper 64-bits of the destination XMM
register (first operand). The low 64-bits from second XMM register (second operand)
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
0F 16 /r
MOVHPS xmm, m64
A V/V SSE Move two packed single-
precision floating-point
values from m64 to high
quadword of xmm.
0F 17 /r
MOVHPS m64, xmm
B V/V SSE Move two packed single-
precision floating-point
values from high quadword
of xmm to m64.
VEX.NDS.128.0F.WIG 16 /r
VMOVHPS xmm2, xmm1, m64
CV/V AVX Merge two packed single-
precision floating-point
values from m64 and the
low quadword of xmm1.
VEX.128.0F.WIG 17/r
VMOVHPS m64, xmm1
B V/V AVX Move two packed single-
precision floating-point
values from high quadword
of xmm1to m64.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:r/m (w) ModRM:reg (r) NA NA
C ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

Vol. 2A 3-697
INSTRUCTION SET REFERENCE, A-M
MOVHPS—Move High Packed Single-Precision Floating-Point Values
are stored in the lower 64-bits of the destination. The upper 128-bits of the destina-
tion YMM register are zeroed.
128-bit store:
Stores two packed single-precision floating-point values from the high 64-bits of the
XMM register source (second operand) to the 64-bit memory location (first operand).
Note: VMOVHPS (store) (VEX.NDS.128.0F 17 /r) is legal and has the same behavior
as the existing 0F 17 store. For VMOVHPS (store) (VEX.NDS.128.0F 17 /r) instruc-
tion version, VEX.vvvv is reserved and must be 1111b otherwise instruction will
#UD.
If VMOVHPS is encoded with VEX.L= 1, an attempt to execute the instruction
encoded with VEX.L= 1 will cause an #UD exception.
Operation
MOVHPS (128-bit Legacy SSE load)
DEST[63:0] (Unmodified)
DEST[127:64] SRC[63:0]
DEST[VLMAX-1:128] (Unmodified)
VMOVHPS (VEX.128 encoded load)
DEST[63:0] SRC1[63:0]
DEST[127:64] SRC2[63:0]
DEST[VLMAX-1:128] 0
VMOVHPS (store)
DEST[63:0] SRC[127:64]
Intel C/C++ Compiler Intrinsic Equivalent
MOVHPS __m128d _mm_loadh_pi ( __m128d a, __m64 *p)
MOVHPS void _mm_storeh_pi (__m64 *p, __m128d a)
SIMD Floating-Point Exceptions
None.
Other Exceptions
See Exceptions Type 5; additionally
#UD If VEX.L= 1.
3-698 Vol. 2A MOVLHPS—Move Packed Single-Precision Floating-Point Values Low to High
INSTRUCTION SET REFERENCE, A-M
MOVLHPS—Move Packed Single-Precision Floating-Point Values Low to
High
Instruction Operand Encoding
Description
This instruction cannot be used for memory to register moves.
128-bit two-argument form:
Moves two packed single-precision floating-point values from the low quadword of
the second XMM argument (second operand) to the high quadword of the first XMM
register (first argument). The low quadword of the destination operand is left
unchanged. The upper 128 bits of the corresponding YMM destination register are
unmodified.
128-bit three-argument form
Moves two packed single-precision floating-point values from the low quadword of
the third XMM argument (third operand) to the high quadword of the destination
(first operand). Copies the low quadword from the second XMM argument (second
operand) to the low quadword of the destination (first operand). The upper 128-bits
of the destination YMM register are zeroed.
If VMOVLHPS is encoded with VEX.L= 1, an attempt to execute the instruction
encoded with VEX.L= 1 will cause an #UD exception.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
0F 16 /r
MOVLHPS xmm1, xmm2
A V/V SSE Move two packed single-
precision floating-point
values from low quadword
of xmm2 to high quadword
of xmm1.
VEX.NDS.128.0F.WIG 16 /r
VMOVLHPS xmm1, xmm2, xmm3
BV/V AVX Merge two packed single-
precision floating-point
values from low quadword
of xmm3 and low quadword
of xmm2.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:reg (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

Vol. 2A 3-699
INSTRUCTION SET REFERENCE, A-M
MOVLHPS—Move Packed Single-Precision Floating-Point Values Low to High
Operation
MOVLHPS (128-bit two-argument form)
DEST[63:0] (Unmodified)
DEST[127:64] SRC[63:0]
DEST[VLMAX-1:128] (Unmodified)
VMOVLHPS (128-bit three-argument form)
DEST[63:0] SRC1[63:0]
DEST[127:64] SRC2[63:0]
DEST[VLMAX-1:128] 0
Intel C/C++ Compiler Intrinsic Equivalent
MOVHLPS __m128 _mm_movelh_ps(__m128 a, __m128 b)
SIMD Floating-Point Exceptions
None.
Other Exceptions
See Exceptions Type 7; additionally
#UD If VEX.L= 1.
3-700 Vol. 2A MOVLPD—Move Low Packed Double-Precision Floating-Point Value
INSTRUCTION SET REFERENCE, A-M
MOVLPD—Move Low Packed Double-Precision Floating-Point Value
Instruction Operand Encoding
Description
This instruction cannot be used for register to register or memory to memory moves.
128-bit Legacy SSE load:
Moves a double-precision floating-point value from the source 64-bit memory
operand and stores it in the low 64-bits of the destination XMM register. The upper
64bits of the XMM register are preserved. The upper 128-bits of the corresponding
YMM destination register are preserved.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
VEX.128 encoded load:
Loads a double-precision floating-point value from the source 64-bit memory
operand (third operand), merges it with the upper 64-bits of the first source XMM
register (second operand), and stores it in the low 128-bits of the destination XMM
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 12 /r
MOVLPD xmm, m64
A V/V SSE2 Move double-precision
floating-point value from
m64 to low quadword of
xmm register.
66 0F 13 /r
MOVLPD m64, xmm
B V/V SSE2 Move double-precision
floating-point nvalue from
low quadword of xmm
register to m64.
VEX.NDS.128.66.0F.WIG 12 /r
VMOVLPD xmm2, xmm1, m64
C V/V AVX Merge double-precision
floating-point value from
m64 and the high quadword
of xmm1.
VEX.128.66.0F.WIG 13/r
VMOVLPD m64, xmm1
BV/V AVX Move double-precision
floating-point values from
low quadword of xmm1 to
m64.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:r/m (w) ModRM:reg (r) NA NA
C ModRM:r/m (r) ModRM:reg (r, w) VEX.vvvv (r) NA

Vol. 2A 3-701
INSTRUCTION SET REFERENCE, A-M
MOVLPD—Move Low Packed Double-Precision Floating-Point Value
register (first operand). The upper 128-bits of the destination YMM register are
zeroed.
128-bit store:
Stores a double-precision floating-point value from the low 64-bits of the XMM
register source (second operand) to the 64-bit memory location (first operand).
Note: VMOVLPD (store) (VEX.128.66.0F 13 /r) is legal and has the same behavior as
the existing 66 0F 13 store. For VMOVLPD (store) (VEX.128.66.0F 13 /r) instruction
version, VEX.vvvv is reserved and must be 1111b otherwise instruction will #UD.
If VMOVLPD is encoded with VEX.L= 1, an attempt to execute the instruction
encoded with VEX.L= 1 will cause an #UD exception.
Operation
MOVLPD (128-bit Legacy SSE load)
DEST[63:0] SRC[63:0]
DEST[VLMAX-1:64] (Unmodified)
VMOVLPD (VEX.128 encoded load)
DEST[63:0] SRC2[63:0]
DEST[127:64] SRC1[127:64]
DEST[VLMAX-1:128] 0
VMOVLPD (store)
DEST[63:0] SRC[63:0]
Intel C/C++ Compiler Intrinsic Equivalent
MOVLPD __m128d _mm_loadl_pd ( __m128d a, double *p)
MOVLPD void _mm_storel_pd (double *p, __m128d a)
SIMD Floating-Point Exceptions
None.
Other Exceptions
See Exceptions Type 5; additionally
#UD If VEX.L= 1.
If VEX.vvvv != 1111B.
3-702 Vol. 2A MOVLPS—Move Low Packed Single-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
MOVLPS—Move Low Packed Single-Precision Floating-Point Values
Instruction Operand Encoding
Description
This instruction cannot be used for register to register or memory to memory moves.
128-bit Legacy SSE load:
Moves two packed single-precision floating-point values from the source 64-bit
memory operand and stores them in the low 64-bits of the destination XMM register.
The upper 64bits of the XMM register are preserved. The upper 128-bits of the corre-
sponding YMM destination register are preserved.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
VEX.128 encoded load:
Loads two packed single-precision floating-point values from the source 64-bit
memory operand (third operand), merges them with the upper 64-bits of the first
source XMM register (second operand), and stores them in the low 128-bits of the
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
0F 12 /r
MOVLPS xmm, m64
A V/V SSE Move two packed single-
precision floating-point
values from m64 to low
quadword of xmm.
0F 13 /r
MOVLPS m64, xmm
B V/V SSE Move two packed single-
precision floating-point
values from low quadword
of xmm to m64.
VEX.NDS.128.0F.WIG 12 /r
VMOVLPS xmm2, xmm1, m64
CV/V AVX Merge two packed single-
precision floating-point
values from m64 and the
high quadword of xmm1.
VEX.128.0F.WIG 13/r
VMOVLPS m64, xmm1
B V/V AVX Move two packed single-
precision floating-point
values from low quadword
of xmm1 to m64.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:r/m (w) ModRM:reg (r) NA NA
C ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

Vol. 2A 3-703
INSTRUCTION SET REFERENCE, A-M
MOVLPS—Move Low Packed Single-Precision Floating-Point Values
destination XMM register (first operand). The upper 128-bits of the destination YMM
register are zeroed.
128-bit store:
Loads two packed single-precision floating-point values from the low 64-bits of the
XMM register source (second operand) to the 64-bit memory location (first operand).
Note: VMOVLPS (store) (VEX.128.0F 13 /r) is legal and has the same behavior as the
existing 0F 13 store. For VMOVLPS (store) (VEX.128.0F 13 /r) instruction version,
VEX.vvvv is reserved and must be 1111b otherwise instruction will #UD.
If VM OVL PS i s en cod ed w ith VEX.L = 1, a n attempt to execute the instruction encoded
with VEX.L= 1 will cause an #UD exception.
Operation
MOVLPS (128-bit Legacy SSE load)
DEST[63:0] SRC[63:0]
DEST[VLMAX-1:64] (Unmodified)
VMOVLPS (VEX.128 encoded load)
DEST[63:0] SRC2[63:0]
DEST[127:64] SRC1[127:64]
DEST[VLMAX-1:128] 0
VMOVLPS (store)
DEST[63:0] SRC[63:0]
Intel C/C++ Compiler Intrinsic Equivalent
MOVLPS __m128 _mm_loadl_pi ( __m128 a, __m64 *p)
MOVLPS void _mm_storel_pi (__m64 *p, __m128 a)
SIMD Floating-Point Exceptions
None.
Other Exceptions
See Exceptions Type 5; additionally
#UD If VEX.L= 1.
If VEX.vvvv != 1111B.
3-704 Vol. 2A MOVMSKPD—Extract Packed Double-Precision Floating-Point Sign Mask
INSTRUCTION SET REFERENCE, A-M
MOVMSKPD—Extract Packed Double-Precision Floating-Point Sign
Mask
Instruction Operand Encoding
Description
Extracts the sign bits from the packed double-precision floating-point values in the
source operand (second operand), formats them into a 2-bit mask, and stores the
mask in the destination operand (first operand). The source operand is an XMM
register, and the destination operand is a general-purpose register. The mask is
stored in the 2 low-order bits of the destination operand. Zero-extend the upper bits
of the destination.
In 64-bit mode, the instruction can access additional registers (XMM8-XMM15,
R8-R15) when used with a REX.R prefix. The default operand size is 64-bit in 64-bit
mode.
128-bit versions: The source operand is a YMM register. The destination operand is a
general purpose register.
VEX.256 encoded version: The source operand is a YMM register. The destination
operand is a general purpose register.
Note: In VEX-encoded versions, VEX.vvvv is reserved and must be 1111b, otherwise
instructions will #UD.
Operation
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 50 /r
MOVMSKPD reg, xmm
A V/V SSE2 Extract 2-bit sign mask from
xmm and store in reg. The
upper bits of r32 or r64 are
filled with zeros.
VEX.128.66.0F.WIG 50 /r
VMOVMSKPD reg, xmm2
A V/V AVX Extract 2-bit sign mask from
xmm2 and store in reg. The
upper bits of r32 or r64 are
zeroed.
VEX.256.66.0F.WIG 50 /r
VMOVMSKPD reg, ymm2
A V/V AVX Extract 4-bit sign mask from
ymm2 and store in reg. The
upper bits of r32 or r64 are
zeroed.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:reg (r) NA NA

Vol. 2A 3-705
INSTRUCTION SET REFERENCE, A-M
MOVMSKPD—Extract Packed Double-Precision Floating-Point Sign Mask
(V)MOVMSKPD (128-bit versions)
DEST[0] SRC[63]
DEST[1] SRC[127]
IF DEST = r32
THEN DEST[31:2] 0;
ELSE DEST[63:2] 0;
FI
VMOVMSKPD (VEX.256 encoded version)
DEST[0] SRC[63]
DEST[1] SRC[127]
DEST[2] SRC[191]
DEST[3] SRC[255]
IF DEST = r32
THEN DEST[31:4] 0;
ELSE DEST[63:4] 0;
FI
Intel C/C++ Compiler Intrinsic Equivalent
MOVMSKPD int _mm_movemask_pd ( __m128d a)
SIMD Floating-Point Exceptions
None.
Other Exceptions
See Exceptions Type 7; additionally
#UD If VEX.vvvv != 1111B.
3-706 Vol. 2A MOVMSKPS—Extract Packed Single-Precision Floating-Point Sign Mask
INSTRUCTION SET REFERENCE, A-M
MOVMSKPS—Extract Packed Single-Precision Floating-Point Sign Mask
Instruction Operand Encoding1
Description
Extracts the sign bits from the packed single-precision floating-point values in the
source operand (second operand), formats them into a 4- or 8-bit mask, and stores
the mask in the destination operand (first operand). The source operand is an XMM
or YMM register, and the destination operand is a general-purpose register. The mask
is stored in the 4 or 8 low-order bits of the destination operand. The upper bits of the
destination operand beyond the mask are filled with zeros.
In 64-bit mode, the instruction can access additional registers (XMM8-XMM15,
R8-R15) when used with a REX.R prefix. The default operand size is 64-bit in 64-bit
mode.
128-bit versions: The source operand is a YMM register. The destination operand is a
general purpose register.
VEX.256 encoded version: The source operand is a YMM register. The destination
operand is a general purpose register.
Note: In VEX-encoded versions, VEX.vvvv is reserved and must be 1111b, otherwise
instructions will #UD.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
0F 50 /r
MOVMSKPS reg, xmm
A V/V SSE Extract 4-bit sign mask from
xmm and store in reg. The
upper bits of r32 or r64 are
filled with zeros.
VEX.128.0F.WIG 50 /r
VMOVMSKPS reg, xmm2
A V/V AVX Extract 4-bit sign mask from
xmm2 and store in reg. The
upper bits of r32 or r64 are
zeroed.
VEX.256.0F.WIG 50 /r
VMOVMSKPS reg, ymm2
A V/V AVX Extract 8-bit sign mask from
ymm2 and store in reg. The
upper bits of r32 or r64 are
zeroed.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA
1. ModRM.MOD = 011B required

Vol. 2A 3-707
INSTRUCTION SET REFERENCE, A-M
MOVMSKPS—Extract Packed Single-Precision Floating-Point Sign Mask
Operation
DEST[0] ← SRC[31];
DEST[1] ← SRC[63];
DEST[2] ← SRC[95];
DEST[3] ← SRC[127];
IF DEST = r32
THEN DEST[31:4] ← ZeroExtend;
ELSE DEST[63:4] ← ZeroExtend;
FI;
(V)MOVMSKPS (128-bit version)
DEST[0] SRC[31]
DEST[1] SRC[63]
DEST[2] SRC[95]
DEST[3] SRC[127]
IF DEST = r32
THEN DEST[31:4] 0;
ELSE DEST[63:4] 0;
FI
VMOVMSKPS (VEX.256 encoded version)
DEST[0] SRC[31]
DEST[1] SRC[63]
DEST[2] SRC[95]
DEST[3] SRC[127]
DEST[4] SRC[159]
DEST[5] SRC[191]
DEST[6] SRC[223]
DEST[7] SRC[255]
IF DEST = r32
THEN DEST[31:8] 0;
ELSE DEST[63:8] 0;
FI
Intel C/C++ Compiler Intrinsic Equivalent
int _mm_movemask_ps(__m128 a)
int _mm256_movemask_ps(__m256 a)
SIMD Floating-Point Exceptions
None.

3-708 Vol. 2A MOVMSKPS—Extract Packed Single-Precision Floating-Point Sign Mask
INSTRUCTION SET REFERENCE, A-M
Other Exceptions
See Exceptions Type 7; additionally
#UD If VEX.vvvv != 1111B.

Vol. 2A 3-709
INSTRUCTION SET REFERENCE, A-M
MOVNTDQA — Load Double Quadword Non-Temporal Aligned Hint
MOVNTDQA — Load Double Quadword Non-Temporal Aligned Hint
Instruction Operand Encoding
Description
MOVNTDQA loads a double quadword from the source operand (second operand) to
the destination operand (first operand) using a non-temporal hint. A processor
implementation may make use of the non-temporal hint associated with this instruc-
tion if the memory source is WC (write combining) memory type. An implementation
may also make use of the non-temporal hint associated with this instruction if the
memory source is WB (write back) memory type.
A processor’s implementation of the non-temporal hint does not override the effec-
tive memory type semantics, but the implementation of the hint is processor depen-
dent. For example, a processor implementation may choose to ignore the hint and
process the instruction as a normal MOVDQA for any memory type. Another imple-
mentation of the hint for WC memory type may optimize data transfer throughput of
WC reads. A third implementation may optimize cache reads generated by
MOVNTDQA on WB memory type to reduce cache evictions.
WC Streaming Load Hint
For WC memory type in particular, the processor never appears to read the data into
the cache hierarchy. Instead, the non-temporal hint may be implemented by loading
a temporary internal buffer with the equivalent of an aligned cache line without filling
this data to the cache. Any memory-type aliased lines in the cache will be snooped
and flushed. Subsequent MOVNTDQA reads to unread portions of the WC cache line
will receive data from the temporary internal buffer if data is available. The tempo-
rary internal buffer may be flushed by the processor at any time for any reason, for
example:
•A load operation other than a MOVNTDQA which references memory already
resident in a temporary internal buffer.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 38 2A /r
MOVNTDQA xmm1, m128
A V/V SSE4_1 Move double quadword
from m128 to xmm using
non-temporal hint if WC
memory type.
VEX.128.66.0F38.WIG 2A /r
VMOVNTDQA xmm1, m128
A V/V AVX Move double quadword from
m128 to xmm using non-
temporal hint if WC memory
type.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA

3-710 Vol. 2A MOVNTDQA — Load Double Quadword Non-Temporal Aligned Hint
INSTRUCTION SET REFERENCE, A-M
•A non-WC reference to memory already resident in a temporary internal buffer.
•Interleaving of reads and writes to memory currently residing in a single
temporary internal buffer.
•Repeated (V)MOVNTDQA loads of a particular 16-byte item in a streaming line.
•Certain micro-architectural conditions including resource shortages, detection of
a mis-speculation condition, and various fault conditions
The memory type of the region being read can override the non-temporal hint, if the
memory address specified for the non-temporal read is not a WC memory region.
Information on non-temporal reads and writes can be found in Chapter 11, “Memory
Cache Control” of Intel® 64 and IA-32 Architectures Software Developer’s Manual,
Volume 3A.
Because the WC protocol uses a weakly-ordered memory consistency model, an
MFENCE or locked instruction should be used in conjunction with MOVNTDQA instruc-
tions if multiple processors might reference the same WC memory locations or in
order to synchronize reads of a processor with writes by other agents in the system.
Because of the speculative nature of fetching due to MOVNTDQA, Streaming loads
must not be used to reference memory addresses that are mapped to I/O devices
having side effects or when reads to these devices are destructive. For additional
information on MOVNTDQA usages, see Section 12.10.3 in Chapter 12, “Program-
ming with SSE3, SSSE3 and SSE4” of Intel® 64 and IA-32 Architectures Software
Developer’s Manual, Volume 1.
The 128-bit (V)MOVNTDQA addresses must be 16-byte aligned or the instruction will
cause a #GP.
Note: In VEX-128 encoded versions, VEX.vvvv is reserved and must be 1111b, VEX.L
must be 0; otherwise instructions will #UD.
Operation
MOVNTDQA (128bit- Legacy SSE form)
DEST SRC
DEST[VLMAX-1:128] (Unmodified)
VMOVNTDQA (VEX.128 encoded form)
DEST SRC
DEST[VLMAX-1:128] 0
Intel C/C++ Compiler Intrinsic Equivalent
MOVNTDQA __m128i _mm_stream_load_si128 (__m128i *p);
Flags Affected
None

Vol. 2A 3-711
INSTRUCTION SET REFERENCE, A-M
MOVNTDQA — Load Double Quadword Non-Temporal Aligned Hint
Other Exceptions
See Exceptions Type 1.SSE4.1; additionally
#UD If VEX.L= 1.
If VEX.vvvv != 1111B.

3-712 Vol. 2A MOVNTDQ—Store Double Quadword Using Non-Temporal Hint
INSTRUCTION SET REFERENCE, A-M
MOVNTDQ—Store Double Quadword Using Non-Temporal Hint
Instruction Operand Encoding1
Description
Moves the packed integers in the source operand (second operand) to the destination
operand (first operand) using a non-temporal hint to prevent caching of the data
during the write to memory. The source operand is an XMM register or YMM register,
which is assumed to contain integer data (packed bytes, words, doublewords, or
quadwords). The destination operand is a 128-bit or 256-bit memory location. The
memory operand must be aligned on a 16-byte (128-bit version) or 32-byte
(VEX.256 encoded version) boundary otherwise a general-protection exception
(#GP) will be generated.
The non-temporal hint is implemented by using a write combining (WC) memory
type protocol when writing the data to memory. Using this protocol, the processor
does not write the data into the cache hierarchy, nor does it fetch the corresponding
cache line from memory into the cache hierarchy. The memory type of the region
being written to can override the non-temporal hint, if the memory address specified
for the non-temporal store is in an uncacheable (UC) or write protected (WP)
memory region. For more information on non-temporal stores, see “Caching of
Temporal vs. Non-Temporal Data” in Chapter 10 in the Intel® 64 and IA-32 Architec-
tures Software Developer’s Manual, Volume 1.
Because the WC protocol uses a weakly-ordered memory consistency model, a
fencing operation implemented with the SFENCE or MFENCE instruction should be
used in conjunction with MOVNTDQ instructions if multiple processors might use
different memory types to read/write the destination memory locations.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F E7 /r
MOVNTDQ m128, xmm
A V/V SSE2 Move double quadword
from xmm to m128 using
non-temporal hint.
VEX.128.66.0F.WIG E7 /r
VMOVNTDQ m128, xmm1
A V/V AVX Move packed integer values
in xmm1 to m128 using
non-temporal hint.
VEX.256.66.0F.WIG E7 /r
VMOVNTDQ m256, ymm1
A V/V AVX Move packed integer values
in ymm1 to m256 using
non-temporal hint.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (w) ModRM:reg (r) NA NA
1. ModRM.MOD = 011B required

Vol. 2A 3-713
INSTRUCTION SET REFERENCE, A-M
MOVNTDQ—Store Double Quadword Using Non-Temporal Hint
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
Note: In VEX-128 encoded versions, VEX.vvvv is reserved and must be 1111b, VEX.L
must be 0; otherwise instructions will #UD.
Operation
DEST ← SRC;
Intel C/C++ Compiler Intrinsic Equivalent
MOVNTDQ void _mm_stream_pd( double* p, __m128d a)
VMOVNTDQ void _mm256_stream_si256 (__m256i * p, __m256i a);
SIMD Floating-Point Exceptions
None.
Other Exceptions
See Exceptions Type 1.SSE2; additionally
#UD If VEX.vvvv != 1111B.
3-714 Vol. 2A MOVNTI—Store Doubleword Using Non-Temporal Hint
INSTRUCTION SET REFERENCE, A-M
MOVNTI—Store Doubleword Using Non-Temporal Hint
Instruction Operand Encoding
Description
Moves the doubleword integer in the source operand (second operand) to the desti-
nation operand (first operand) using a non-temporal hint to minimize cache pollution
during the write to memory. The source operand is a general-purpose register. The
destination operand is a 32-bit memory location.
The non-temporal hint is implemented by using a write combining (WC) memory
type protocol when writing the data to memory. Using this protocol, the processor
does not write the data into the cache hierarchy, nor does it fetch the corresponding
cache line from memory into the cache hierarchy. The memory type of the region
being written to can override the non-temporal hint, if the memory address specified
for the non-temporal store is in an uncacheable (UC) or write protected (WP)
memory region. For more information on non-temporal stores, see “Caching of
Temporal vs. Non-Temporal Data” in Chapter 10 in the Intel® 64 and IA-32 Architec-
tures Software Developer’s Manual, Volume 1.
Because the WC protocol uses a weakly-ordered memory consistency model, a
fencing operation implemented with the SFENCE or MFENCE instruction should be
used in conjunction with MOVNTI instructions if multiple processors might use
different memory types to read/write the destination memory locations.
In 64-bit mode, the instruction’s default operation size is 32 bits. Use of the REX.R
prefix permits access to additional registers (R8-R15). Use of the REX.W prefix
promotes operation to 64 bits. See the summary chart at the beginning of this
section for encoding data and limits.
Operation
DEST ← SRC;
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F C3 /rMOVNTI m32, r32 A Valid Valid Move doubleword from r32
to m32 using non-temporal
hint.
REX.W + 0F C3
/r
MOVNTI m64, r64 A Valid N.E. Move quadword from r64 to
m64 using non-temporal
hint.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (w) ModRM:reg (r) NA NA

Vol. 2A 3-715
INSTRUCTION SET REFERENCE, A-M
MOVNTI—Store Doubleword Using Non-Temporal Hint
Intel C/C++ Compiler Intrinsic Equivalent
MOVNTI void _mm_stream_si32 (int *p, int a)
SIMD Floating-Point Exceptions
None.
Protected Mode Exceptions
#GP(0) For an illegal memory operand effective address in the CS, DS,
ES, FS or GS segments.
#SS(0) For an illegal address in the SS segment.
#PF(fault-code) For a page fault.
#UD If CPUID.01H:EDX.SSE2[bit 26] = 0.
If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand is not aligned on a 16-byte boundary,
regardless of segment.
If any part of the operand lies outside the effective address
space from 0 to FFFFH.
#UD If CPUID.01H:EDX.SSE2[bit 26] = 0.
If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
Same exceptions as in real address mode.
#PF(fault-code) For a page fault.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#PF(fault-code) For a page fault.
#UD If CPUID.01H:EDX.SSE2[bit 26] = 0.
If the LOCK prefix is used.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
3-716 Vol. 2A MOVNTPD—Store Packed Double-Precision Floating-Point Values Using Non-Temporal
Hint
INSTRUCTION SET REFERENCE, A-M
MOVNTPD—Store Packed Double-Precision Floating-Point Values Using
Non-Temporal Hint
Instruction Operand Encoding1
Description
Moves the packed double-precision floating-point values in the source operand
(second operand) to the destination operand (first operand) using a non-temporal
hint to prevent caching of the data during the write to memory. The source operand
is an XMM register or YMM register, which is assumed to contain packed double-preci-
sion, floating-pointing data. The destination operand is a 128-bit or 256-bit memory
location. The memory operand must be aligned on a 16-byte (128-bit version) or 32-
byte (VEX.256 encoded version) boundary otherwise a general-protection exception
(#GP) will be generated.
The non-temporal hint is implemented by using a write combining (WC) memory
type protocol when writing the data to memory. Using this protocol, the processor
does not write the data into the cache hierarchy, nor does it fetch the corresponding
cache line from memory into the cache hierarchy. The memory type of the region
being written to can override the non-temporal hint, if the memory address specified
for the non-temporal store is in an uncacheable (UC) or write protected (WP)
memory region. For more information on non-temporal stores, see “Caching of
Temporal vs. Non-Temporal Data” in Chapter 10 in the Intel® 64 and IA-32 Architec-
tures Software Developer’s Manual, Volume 1.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 2B /r
MOVNTPD m128, xmm
AV/V SSE2 Move packed double-
precision floating-point
values from xmm to m128
using non-temporal hint.
VEX.128.66.0F.WIG 2B /r
VMOVNTPD m128, xmm1
AV/V AVX Move packed double-
precision values in xmm1 to
m128 using non-temporal
hint.
VEX.256.66.0F.WIG 2B /r
VMOVNTPD m256, ymm1
AV/V AVX Move packed double-
precision values in ymm1 to
m256 using non-temporal
hint.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (w) ModRM:reg (r) NA NA
1. ModRM.MOD = 011B required

Vol. 2A 3-717
INSTRUCTION SET REFERENCE, A-M
MOVNTPD—Store Packed Double-Precision Floating-Point Values Using Non-Temporal
Hint
Because the WC protocol uses a weakly-ordered memory consistency model, a
fencing operation implemented with the SFENCE or MFENCE instruction should be
used in conjunction with MOVNTPD instructions if multiple processors might use
different memory types to read/write the destination memory locations.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
Note: In VEX-128 encoded versions, VEX.vvvv is reserved and must be 1111b, VEX.L
must be 0; otherwise instructions will #UD.
Operation
DEST ← SRC;
Intel C/C++ Compiler Intrinsic Equivalent
MOVNTPD void _mm_stream_pd(double *p, __m128d a)
VMOVNTPD void _mm256_stream_pd (double * p, __m256d a);
SIMD Floating-Point Exceptions
None.
Other Exceptions
See Exceptions Type 1.SSE2; additionally
#UD If VEX.vvvv != 1111B.
3-718 Vol. 2A MOVNTPS—Store Packed Single-Precision Floating-Point Values Using Non-Temporal
Hint
INSTRUCTION SET REFERENCE, A-M
MOVNTPS—Store Packed Single-Precision Floating-Point Values Using
Non-Temporal Hint
Instruction Operand Encoding1
Description
Moves the packed single-precision floating-point values in the source operand
(second operand) to the destination operand (first operand) using a non-temporal
hint to prevent caching of the data during the write to memory. The source operand
is an XMM register or YMM register, which is assumed to contain packed single-preci-
sion, floating-pointing. The destination operand is a 128-bit or 256-bitmemory loca-
tion. The memory operand must be aligned on a 16-byte (128-bit version) or 32-byte
(VEX.256 encoded version) boundary otherwise a general-protection exception
(#GP) will be generated.
The non-temporal hint is implemented by using a write combining (WC) memory
type protocol when writing the data to memory. Using this protocol, the processor
does not write the data into the cache hierarchy, nor does it fetch the corresponding
cache line from memory into the cache hierarchy. The memory type of the region
being written to can override the non-temporal hint, if the memory address specified
for the non-temporal store is in an uncacheable (UC) or write protected (WP)
memory region. For more information on non-temporal stores, see “Caching of
Temporal vs. Non-Temporal Data” in Chapter 10 in the Intel® 64 and IA-32 Architec-
tures Software Developer’s Manual, Volume 1.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
0F 2B /r
MOVNTPS m128, xmm
A V/V SSE Move packed single-
precision floating-point
values from xmm to m128
using non-temporal hint.
VEX.128.0F.WIG 2B /r
VMOVNTPS m128, xmm1
AV/V AVX Move packed single-
precision values xmm1 to
mem using non-temporal
hint.
VEX.256.0F.WIG 2B /r
VMOVNTPS m256, ymm1
AV/V AVX Move packed single-
precision values ymm1 to
mem using non-temporal
hint.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (w) ModRM:reg (r) NA NA
1. ModRM.MOD = 011B required

Vol. 2A 3-719
INSTRUCTION SET REFERENCE, A-M
MOVNTPS—Store Packed Single-Precision Floating-Point Values Using Non-Temporal
Hint
Because the WC protocol uses a weakly-ordered memory consistency model, a
fencing operation implemented with the SFENCE or MFENCE instruction should be
used in conjunction with MOVNTPS instructions if multiple processors might use
different memory types to read/write the destination memory locations.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
Note: In VEX-encoded versions, VEX.vvvv is reserved and must be 1111b otherwise
instructions will #UD.
Operation
DEST ← SRC;
Intel C/C++ Compiler Intrinsic Equivalent
MOVNTDQ void _mm_stream_ps(float * p, __m128 a)
VMOVNTPS void _mm256_stream_ps (float * p, __m256 a);
SIMD Floating-Point Exceptions
None.
Other Exceptions
See Exceptions Type 1.SSE; additionally
#UD If VEX.vvvv != 1111B.

3-720 Vol. 2A MOVNTQ—Store of Quadword Using Non-Temporal Hint
INSTRUCTION SET REFERENCE, A-M
MOVNTQ—Store of Quadword Using Non-Temporal Hint
Instruction Operand Encoding
Description
Moves the quadword in the source operand (second operand) to the destination
operand (first operand) using a non-temporal hint to minimize cache pollution during
the write to memory. The source operand is an MMX technology register, which is
assumed to contain packed integer data (packed bytes, words, or doublewords). The
destination operand is a 64-bit memory location.
The non-temporal hint is implemented by using a write combining (WC) memory
type protocol when writing the data to memory. Using this protocol, the processor
does not write the data into the cache hierarchy, nor does it fetch the corresponding
cache line from memory into the cache hierarchy. The memory type of the region
being written to can override the non-temporal hint, if the memory address specified
for the non-temporal store is in an uncacheable (UC) or write protected (WP)
memory region. For more information on non-temporal stores, see “Caching of
Temporal vs. Non-Temporal Data” in Chapter 10 in the Intel® 64 and IA-32 Architec-
tures Software Developer’s Manual, Volume 1.
Because the WC protocol uses a weakly-ordered memory consistency model, a
fencing operation implemented with the SFENCE or MFENCE instruction should be
used in conjunction with MOVNTQ instructions if multiple processors might use
different memory types to read/write the destination memory locations.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
Operation
DEST ← SRC;
Intel C/C++ Compiler Intrinsic Equivalent
MOVNTQ void _mm_stream_pi(__m64 * p, __m64 a)
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F E7 /rMOVNTQ m64,
mm
A Valid Valid Move quadword from mm to
m64 using non-temporal
hint.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (w) ModRM:reg (r) NA NA

Vol. 2A 3-721
INSTRUCTION SET REFERENCE, A-M
MOVNTQ—Store of Quadword Using Non-Temporal Hint
SIMD Floating-Point Exceptions
None.
Protected Mode Exceptions
#GP(0) For an illegal memory operand effective address in the CS, DS,
ES, FS or GS segments.
#SS(0) For an illegal address in the SS segment.
#PF(fault-code) For a page fault.
#NM If CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If CR0.EM[bit 2] = 1.
If CPUID.01H:EDX.SSE[bit 25] = 0.
If the LOCK prefix is used.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
Real-Address Mode Exceptions
#GP If a memory operand is not aligned on a 16-byte boundary,
regardless of segment.
If any part of the operand lies outside the effective address
space from 0 to FFFFH.
#NM If CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If CR0.EM[bit 2] = 1.
If CPUID.01H:EDX.SSE2[bit 26] = 0.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
Same exceptions as in real address mode.
#PF(fault-code) For a page fault.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.

3-722 Vol. 2A MOVNTQ—Store of Quadword Using Non-Temporal Hint
INSTRUCTION SET REFERENCE, A-M
#GP(0) If the memory address is in a non-canonical form.
#PF(fault-code) For a page fault.
#NM If CR0.TS[bit 3] = 1.
#MF If there is a pending x87 FPU exception.
#UD If CR0.EM[bit 2] = 1.
If CPUID.01H:EDX.SSE[bit 25] = 0.
If the LOCK prefix is used.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.

Vol. 2A 3-723
INSTRUCTION SET REFERENCE, A-M
MOVQ—Move Quadword
MOVQ—Move Quadword
Instruction Operand Encoding
Description
Copies a quadword from the source operand (second operand) to the destination
operand (first operand). The source and destination operands can be MMX tech-
nology registers, XMM registers, or 64-bit memory locations. This instruction can be
used to move a quadword between two MMX technology registers or between an
MMX technology register and a 64-bit memory location, or to move data between two
XMM registers or between an XMM register and a 64-bit memory location. The
instruction cannot be used to transfer data between memory locations.
When the source operand is an XMM register, the low quadword is moved; when the
destination operand is an XMM register, the quadword is stored to the low quadword
of the register, and the high quadword is cleared to all 0s.
In 64-bit mode, use of the REX prefix in the form of REX.R permits this instruction to
access additional registers (XMM8-XMM15).
Operation
MOVQ instruction when operating on MMX technology registers and memory locations:
DEST ← SRC;
MOVQ instruction when source and destination operands are XMM registers:
DEST[63:0] ← SRC[63:0];
DEST[127:64] ← 0000000000000000H;
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F 6F /rMOVQ mm,
mm/m64
AValid Valid Move quadword from
mm/m64 to mm.
0F 7F /rMOVQ mm/m64,
mm
B Valid Valid Move quadword from mm to
mm/m64.
F3 0F 7E MOVQ xmm1,
xmm2/m64
AValid Valid Move quadword from
xmm2/mem64 to xmm1.
66 0F D6 MOVQ
xmm2/m64,
xmm1
B Valid Valid Move quadword from xmm1
to xmm2/mem64.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA
B ModRM:r/m (w) ModRM:reg (r) NA NA

3-724 Vol. 2A MOVQ—Move Quadword
INSTRUCTION SET REFERENCE, A-M
MOVQ instruction when source operand is XMM register and destination
operand is memory location:
DEST ← SRC[63:0];
MOVQ instruction when source operand is memory location and destination
operand is XMM register:
DEST[63:0] ← SRC;
DEST[127:64] ← 0000000000000000H;
Flags Affected
None.
Intel C/C++ Compiler Intrinsic Equivalent
MOVQ m128i _mm_mov_epi64(__m128i a)
SIMD Floating-Point Exceptions
None.
Protected Mode Exceptions
#GP(0) If the destination operand is in a non-writable segment.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#UD If CR0.EM[bit 2] = 1.
128-bit operations will generate #UD only if CR4.OSFXSR[bit 9]
= 0. Execution of 128-bit instructions on a non-SSE2 capable
processor (one that is MMX technology capable) will result in the
instruction operating on the mm registers, not #UD.
If the LOCK prefix is used.
#NM If CR0.TS[bit 3] = 1.
#MF (MMX register operations only) If there is a pending FPU
exception.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.

Vol. 2A 3-725
INSTRUCTION SET REFERENCE, A-M
MOVQ—Move Quadword
Real-Address Mode Exceptions
#GP If any part of the operand lies outside of the effective address
space from 0 to FFFFH.
#UD If CR0.EM[bit 2] = 1.
128-bit operations will generate #UD only if CR4.OSFXSR[bit 9]
= 0. Execution of 128-bit instructions on a non-SSE2 capable
processor (one that is MMX technology capable) will result in the
instruction operating on the mm registers, not #UD.
If the LOCK prefix is used.
#NM If CR0.TS[bit 3] = 1.
#MF (MMX register operations only) If there is a pending FPU
exception.
Virtual-8086 Mode Exceptions
Same exceptions as in real address mode.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#UD If CR0.EM[bit 2] = 1.
(XMM register operations only) If CR4.OSFXSR[bit 9] = 0.
(XMM register operations only) If CPUID.01H:EDX.SSE2[bit 26]
= 0.
If the LOCK prefix is used.
#NM If CR0.TS[bit 3] = 1.
#MF (MMX register operations only) If there is a pending FPU
exception.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.

3-726 Vol. 2A MOVQ2DQ—Move Quadword from MMX Technology to XMM Register
INSTRUCTION SET REFERENCE, A-M
MOVQ2DQ—Move Quadword from MMX Technology to XMM Register
Instruction Operand Encoding
Description
Moves the quadword from the source operand (second operand) to the low quadword
of the destination operand (first operand). The source operand is an MMX technology
register and the destination operand is an XMM register.
This instruction causes a transition from x87 FPU to MMX technology operation (that
is, the x87 FPU top-of-stack pointer is set to 0 and the x87 FPU tag word is set to all
0s [valid]). If this instruction is executed while an x87 FPU floating-point exception is
pending, the exception is handled before the MOVQ2DQ instruction is executed.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
Operation
DEST[63:0] ← SRC[63:0];
DEST[127:64] ← 00000000000000000H;
Intel C/C++ Compiler Intrinsic Equivalent
MOVQ2DQ __128i _mm_movpi64_pi64 ( __m64 a)
SIMD Floating-Point Exceptions
None.
Protected Mode Exceptions
#NM If CR0.TS[bit 3] = 1.
#UD If CR0.EM[bit 2] = 1.
If CR4.OSFXSR[bit 9] = 0.
If CPUID.01H:EDX.SSE2[bit 26] = 0.
If the LOCK prefix is used.
#MF If there is a pending x87 FPU exception.
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
F3 0F D6 MOVQ2DQ xmm,
mm
A Valid Valid Move quadword from mmx
to low quadword of xmm.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:reg (r) NA NA

Vol. 2A 3-727
INSTRUCTION SET REFERENCE, A-M
MOVQ2DQ—Move Quadword from MMX Technology to XMM Register
Real-Address Mode Exceptions
Same exceptions as in protected mode.
Virtual-8086 Mode Exceptions
Same exceptions as in protected mode.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
Same exceptions as in protected mode.

3-728 Vol. 2A MOVS/MOVSB/MOVSW/MOVSD/MOVSQ—Move Data from String to String
INSTRUCTION SET REFERENCE, A-M
MOVS/MOVSB/MOVSW/MOVSD/MOVSQ—Move Data from
String to String
\
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
A4 MOVS m8, m8 A Valid Valid For legacy mode, Move byte
from address DS:(E)SI to
ES:(E)DI. For 64-bit mode
move byte from address
(R|E)SI to (R|E)DI.
A5 MOVS m16, m16 A Valid Valid For legacy mode, move
word from address DS:(E)SI
to ES:(E)DI. For 64-bit mode
move word at address
(R|E)SI to (R|E)DI.
A5 MOVS m32, m32 A Valid Valid For legacy mode, move
dword from address DS:(E)SI
to ES:(E)DI. For 64-bit mode
move dword from address
(R|E)SI to (R|E)DI.
REX.W + A5 MOVS m64, m64 A Valid N.E. Move qword from address
(R|E)SI to (R|E)DI.
A4 MOVSB A Valid Valid For legacy mode, Move byte
from address DS:(E)SI to
ES:(E)DI. For 64-bit mode
move byte from address
(R|E)SI to (R|E)DI.
A5 MOVSW A Valid Valid For legacy mode, move
word from address DS:(E)SI
to ES:(E)DI. For 64-bit mode
move word at address
(R|E)SI to (R|E)DI.
A5 MOVSD A Valid Valid For legacy mode, move
dword from address DS:(E)SI
to ES:(E)DI. For 64-bit mode
move dword from address
(R|E)SI to (R|E)DI.
REX.W + A5 MOVSQ A Valid N.E. Move qword from address
(R|E)SI to (R|E)DI.

Vol. 2A 3-729
INSTRUCTION SET REFERENCE, A-M
MOVS/MOVSB/MOVSW/MOVSD/MOVSQ—Move Data from String to String
Instruction Operand Encoding
Description
Moves the byte, word, or doubleword specified with the second operand (source
operand) to the location specified with the first operand (destination operand). Both
the source and destination operands are located in memory. The address of the
source operand is read from the DS:ESI or the DS:SI registers (depending on the
address-size attribute of the instruction, 32 or 16, respectively). The address of the
destination operand is read from the ES:EDI or the ES:DI registers (again depending
on the address-size attribute of the instruction). The DS segment may be overridden
with a segment override prefix, but the ES segment cannot be overridden.
At the assembly-code level, two forms of this instruction are allowed: the “explicit-
operands” form and the “no-operands” form. The explicit-operands form (specified
with the MOVS mnemonic) allows the source and destination operands to be speci-
fied explicitly. Here, the source and destination operands should be symbols that
indicate the size and location of the source value and the destination, respectively.
This explicit-operands form is provided to allow documentation; however, note that
the documentation provided by this form can be misleading. That is, the source and
destination operand symbols must specify the correct type (size) of the operands
(bytes, words, or doublewords), but they do not have to specify the correct location.
The locations of the source and destination operands are always specified by the
DS:(E)SI and ES:(E)DI registers, which must be loaded correctly before the move
string instruction is executed.
The no-operands form provides “short forms” of the byte, word, and doubleword
versions of the MOVS instructions. Here also DS:(E)SI and ES:(E)DI are assumed to
be the source and destination operands, respectively. The size of the source and
destination operands is selected with the mnemonic: MOVSB (byte move), MOVSW
(word move), or MOVSD (doubleword move).
After the move operation, the (E)SI and (E)DI registers are incremented or decre-
mented automatically according to the setting of the DF flag in the EFLAGS register.
(If the DF flag is 0, the (E)SI and (E)DI register are incremented; if the DF flag is 1,
the (E)SI and (E)DI registers are decremented.) The registers are incremented or
decremented by 1 for byte operations, by 2 for word operations, or by 4 for double-
word operations.
The MOVS, MOVSB, MOVSW, and MOVSD instructions can be preceded by the REP
prefix (see “REP/REPE/REPZ /REPNE/REPNZ—Repeat String Operation Prefix” in
Chapter 4 of the Intel® 64 and IA-32 Architectures Software Developer’s Manual,
Volume 2B, for a description of the REP prefix) for block moves of ECX bytes, words,
or doublewords.
In 64-bit mode, the instruction’s default address size is 64 bits, 32-bit address size is
supported using the prefix 67H. The 64-bit addresses are specified by RSI and RDI;
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA

3-730 Vol. 2A MOVS/MOVSB/MOVSW/MOVSD/MOVSQ—Move Data from String to String
INSTRUCTION SET REFERENCE, A-M
32-bit address are specified by ESI and EDI. Use of the REX.W prefix promotes
doubleword operation to 64 bits. See the summary chart at the beginning of this
section for encoding data and limits.
Operation
DEST ← SRC;
Non-64-bit Mode:
IF (Byte move)
THEN IF DF = 0
THEN
(E)SI ← (E)SI + 1;
(E)DI ← (E)DI + 1;
ELSE
(E)SI ← (E)SI – 1;
(E)DI ← (E)DI – 1;
FI;
ELSE IF (Word move)
THEN IF DF = 0
(E)SI ← (E)SI + 2;
(E)DI ← (E)DI + 2;
FI;
ELSE
(E)SI ← (E)SI – 2;
(E)DI ← (E)DI – 2;
FI;
ELSE IF (Doubleword move)
THEN IF DF = 0
(E)SI ← (E)SI + 4;
(E)DI ← (E)DI + 4;
FI;
ELSE
(E)SI ← (E)SI – 4;
(E)DI ← (E)DI – 4;
FI;
FI;
64-bit Mode:
IF (Byte move)
THEN IF DF = 0
THEN
(R|E)SI ← (R|E)SI + 1;
(R|E)DI ← (R|E)DI + 1;

Vol. 2A 3-731
INSTRUCTION SET REFERENCE, A-M
MOVS/MOVSB/MOVSW/MOVSD/MOVSQ—Move Data from String to String
ELSE
(R|E)SI ← (R|E)SI – 1;
(R|E)DI ← (R|E)DI – 1;
FI;
ELSE IF (Word move)
THEN IF DF = 0
(R|E)SI ← (R|E)SI + 2;
(R|E)DI ← (R|E)DI + 2;
FI;
ELSE
(R|E)SI ← (R|E)SI – 2;
(R|E)DI ← (R|E)DI – 2;
FI;
ELSE IF (Doubleword move)
THEN IF DF = 0
(R|E)SI ← (R|E)SI + 4;
(R|E)DI ← (R|E)DI + 4;
FI;
ELSE
(R|E)SI ← (R|E)SI – 4;
(R|E)DI ← (R|E)DI – 4;
FI;
ELSE IF (Quadword move)
THEN IF DF = 0
(R|E)SI ← (R|E)SI + 8;
(R|E)DI ← (R|E)DI + 8;
FI;
ELSE
(R|E)SI ← (R|E)SI – 8;
(R|E)DI ← (R|E)DI – 8;
FI;
FI;
Flags Affected
None.
Protected Mode Exceptions
#GP(0) If the destination is located in a non-writable segment.
If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.

3-732 Vol. 2A MOVS/MOVSB/MOVSW/MOVSD/MOVSQ—Move Data from String to String
INSTRUCTION SET REFERENCE, A-M
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Vol. 2A 3-733
INSTRUCTION SET REFERENCE, A-M
MOVSD—Move Scalar Double-Precision Floating-Point Value
MOVSD—Move Scalar Double-Precision Floating-Point Value
Instruction Operand Encoding
Description
MOVSD moves a scalar double-precision floating-point value from the source
operand (second operand) to the destination operand (first operand). The source and
destination operands can be XMM registers or 64-bit memory locations. This instruc-
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F2 0F 10 /r
MOVSD xmm1, xmm2/m64
A V/V SSE2 Move scalar double-
precision floating-point
value from xmm2/m64 to
xmm1 register.
VEX.NDS.LIG.F2.0F.WIG 10 /r
VMOVSD xmm1, xmm2, xmm3
BV/V AVX Merge scalar double-
precision floating-point
value from xmm2 and
xmm3 to xmm1 register.
VEX.LIG.F2.0F.WIG 10 /r
VMOVSD xmm1, m64
D V/V AVX Load scalar double-precision
floating-point value from
m64 to xmm1 register.
F2 0F 11 /r
MOVSD xmm2/m64, xmm1
C V/V SSE2 Move scalar double-
precision floating-point
value from xmm1 register
to xmm2/m64.
VEX.NDS.LIG.F2.0F.WIG 11 /r
VMOVSD xmm1, xmm2, xmm3
EV/V AVX Merge scalar double-
precision floating-point
value from xmm2 and
xmm3 registers to xmm1.
VEX.LIG.F2.0F.WIG 11 /r
VMOVSD m64, xmm1
C V/V AVX Move scalar double-
precision floating-point
value from xmm1 register
to m64.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA
C ModRM:r/m (w) ModRM:reg (r) NA NA
D ModRM:reg (w) ModRM:r/m (r) NA NA
E ModRM:r/m (w) VEX.vvvv (r) ModRM:reg (r) NA

3-734 Vol. 2A MOVSD—Move Scalar Double-Precision Floating-Point Value
INSTRUCTION SET REFERENCE, A-M
tion can be used to move a double-precision floating-point value to and from the low
quadword of an XMM register and a 64-bit memory location, or to move a double-
precision floating-point value between the low quadwords of two XMM registers. The
instruction cannot be used to transfer data between memory locations.
For non-VEX encoded instruction syntax and when the source and destination oper-
ands are XMM registers, the high quadword of the destination operand remains
unchanged. When the source operand is a memory location and destination operand
is an XMM registers, the high quadword of the destination operand is cleared to all 0s.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
Note: For the “VMOVSD m64, xmm1” (memory store form) instruction version,
VEX.vvvv is reserved and must be 1111b, otherwise instruction will #UD.
Note: For the “VMOVSD xmm1, m64” (memory load form) instruction version,
VEX.vvvv is reserved and must be 1111b otherwise instruction will #UD.
VEX encoded instruction syntax supports two source operands and a destination
operand if ModR/M.mod field is 11B. VEX.vvvv is used to encode the first source
operand (the second operand). The low 128 bits of the destination operand stores the
result of merging the low quadword of the second source operand with the quad word
in bits 127:64 of the first source operand. The upper bits of the destination operand
are cleared.
Operation
MOVSD (128-bit Legacy SSE version: MOVSD XMM1, XMM2)
DEST[63:0] SRC[63:0]
DEST[VLMAX-1:64] (Unmodified)
MOVSD/VMOVSD (128-bit versions: MOVSD m64, xmm1 or VMOVSD m64, xmm1)
DEST[63:0] SRC[63:0]
MOVSD (128-bit Legacy SSE version: MOVSD XMM1, m64)
DEST[63:0] SRC[63:0]
DEST[127:64] 0
DEST[VLMAX-1:128] (Unmodified)
VMOVSD (VEX.NDS.128.F2.0F 11 /r: VMOVSD xmm1, xmm2, xmm3)
DEST[63:0] SRC2[63:0]
DEST[127:64] SRC1[127:64]
DEST[VLMAX-1:128] 0
VMOVSD (VEX.NDS.128.F2.0F 10 /r: VMOVSD xmm1, xmm2, xmm3)
DEST[63:0] SRC2[63:0]
DEST[127:64] SRC1[127:64]

Vol. 2A 3-735
INSTRUCTION SET REFERENCE, A-M
MOVSD—Move Scalar Double-Precision Floating-Point Value
DEST[VLMAX-1:128] 0
VMOVSD (VEX.NDS.128.F2.0F 10 /r: VMOVSD xmm1, m64)
DEST[63:0] SRC[63:0]
DEST[VLMAX-1:64] 0
Intel C/C++ Compiler Intrinsic Equivalent
MOVSD __m128d _mm_load_sd (double *p)
MOVSD void _mm_store_sd (double *p, __m128d a)
MOVSD __m128d _mm_store_sd (__m128d a, __m128d b)
SIMD Floating-Point Exceptions
None.
Other Exceptions
See Exceptions Type 5; additionally
#UD If VEX.vvvv != 1111B.

3-736 Vol. 2A MOVSHDUP—Move Packed Single-FP High and Duplicate
INSTRUCTION SET REFERENCE, A-M
MOVSHDUP—Move Packed Single-FP High and Duplicate
Instruction Operand Encoding
Description
The linear address corresponds to the address of the least-significant byte of the
referenced memory data. When a memory address is indicated, the 16 bytes of data
at memory location m128 are loaded and the single-precision elements in positions 1
and 3 are duplicated. When the register-register form of this operation is used, the
same operation is performed but with data coming from the 128-bit source register.
See Figure 3-28.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F3 0F 16 /r
MOVSHDUP xmm1, xmm2/m128
A V/V SSE3 Move two single-precision
floating-point values from
the higher 32-bit operand of
each qword in xmm2/m128
to xmm1 and duplicate each
32-bit operand to the lower
32-bits of each qword.
VEX.128.F3.0F.WIG 16 /r
VMOVSHDUP xmm1, xmm2/m128
A V/V AVX Move odd index single-
precision floating-point
values from xmm2/mem
and duplicate each element
into xmm1.
VEX.256.F3.0F.WIG 16 /r
VMOVSHDUP ymm1, ymm2/m256
A V/V AVX Move odd index single-
precision floating-point
values from ymm2/mem and
duplicate each element into
ymm1.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA
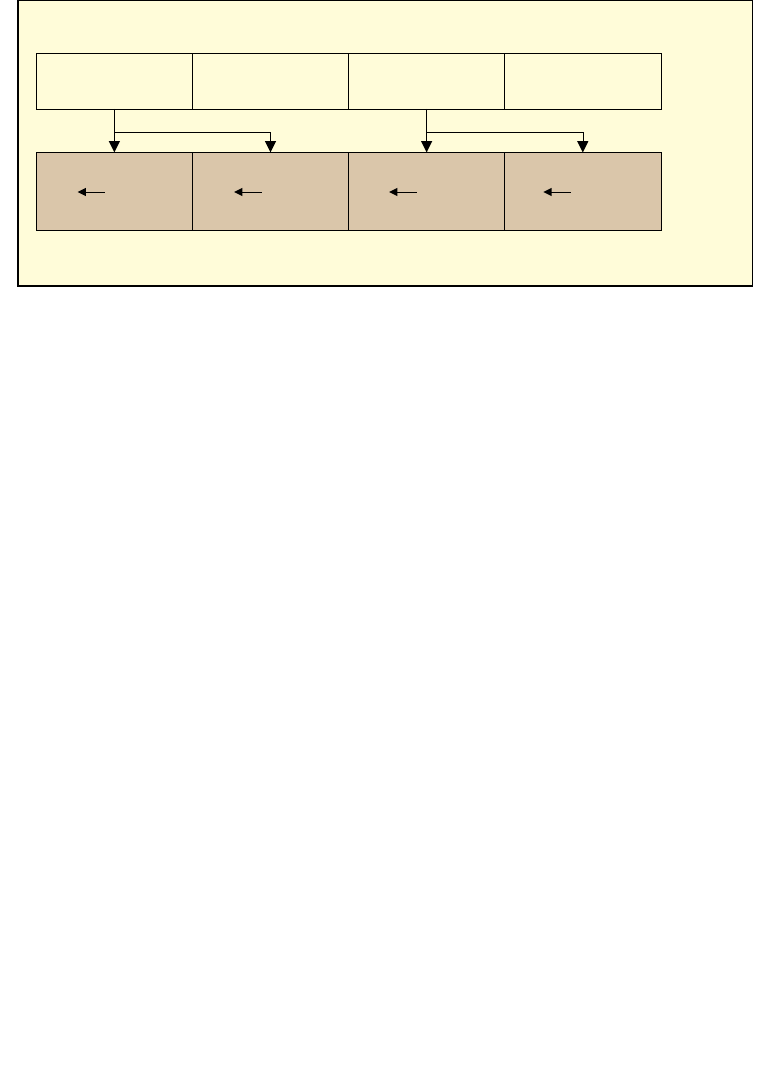
Vol. 2A 3-737
INSTRUCTION SET REFERENCE, A-M
MOVSHDUP—Move Packed Single-FP High and Duplicate
In 64-bit mode, use of the REX prefix in the form of REX.R permits this instruction to
access additional registers (XMM8-XMM15).
128-bit Legacy SSE version: Bits (VLMAX-1:128) of the corresponding YMM destina-
tion register remain unchanged.
VEX.128 encoded version: Bits (VLMAX-1:128) of the destination YMM register are
zeroed.
Note: In VEX-encoded versions, VEX.vvvv is reserved and must be 1111b otherwise
instructions will #UD.
Operation
MOVSHDUP (128-bit Legacy SSE version)
DEST[31:0] SRC[63:32]
DEST[63:32] SRC[63:32]
DEST[95:64] SRC[127:96]
DEST[127:96] SRC[127:96]
DEST[VLMAX-1:128] (Unmodified)
VMOVSHDUP (VEX.128 encoded version)
DEST[31:0] SRC[63:32]
DEST[63:32] SRC[63:32]
DEST[95:64] SRC[127:96]
DEST[127:96] SRC[127:96]
Figure 3-28. MOVSHDUP—Move Packed Single-FP High and Duplicate
20
0296+'83[PP[PPP
5(68/7
[PP
[PP
P
[PP>@
[PP
P>@
>@
[PP>@
[PP
P>@
>@
[PP>@
[PP
P>@
>@
[PP>@
[PP
P>@
>@
>@ >@ >@ >@

3-738 Vol. 2A MOVSHDUP—Move Packed Single-FP High and Duplicate
INSTRUCTION SET REFERENCE, A-M
DEST[VLMAX-1:128] 0
VMOVSHDUP (VEX.256 encoded version)
DEST[31:0] SRC[63:32]
DEST[63:32] SRC[63:32]
DEST[95:64] SRC[127:96]
DEST[127:96] SRC[127:96]
DEST[159:128] SRC[191:160]
DEST[191:160] SRC[191:160]
DEST[223:192] SRC[255:224]
DEST[255:224] SRC[255:224]
Intel C/C++ Compiler Intrinsic Equivalent
(V)MOVSHDUP __m128 _mm_movehdup_ps(__m128 a)
VMOVSHDUP __m256 _mm256_movehdup_ps (__m256 a);
Exceptions
General protection exception if not aligned on 16-byte boundary, regardless of
segment.
Numeric Exceptions
None
Other Exceptions
See Exceptions Type 2.
Vol. 2A 3-739
INSTRUCTION SET REFERENCE, A-M
MOVSLDUP—Move Packed Single-FP Low and Duplicate
MOVSLDUP—Move Packed Single-FP Low and Duplicate
Instruction Operand Encoding
Description
The linear address corresponds to the address of the least-significant byte of the
referenced memory data. When a memory address is indicated, the 16 bytes of data
at memory location m128 are loaded and the single-precision elements in positions 0
and 2 are duplicated. When the register-register form of this operation is used, the
same operation is performed but with data coming from the 128-bit source register.
See Figure 3-29.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F3 0F 12 /r
MOVSLDUP xmm1, xmm2/m128
A V/V SSE3 Move two single-precision
floating-point values from
the lower 32-bit operand of
each qword in xmm2/m128
to xmm1 and duplicate each
32-bit operand to the higher
32-bits of each qword.
VEX.128.F3.0F.WIG 12 /r
VMOVSLDUP xmm1, xmm2/m128
AV/V AVX Move even index single-
precision floating-point
values from xmm2/mem
and duplicate each element
into xmm1.
VEX.256.F3.0F.WIG 12 /r
VMOVSLDUP ymm1, ymm2/m256
AV/V AVX Move even index single-
precision floating-point
values from ymm2/mem and
duplicate each element into
ymm1.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA
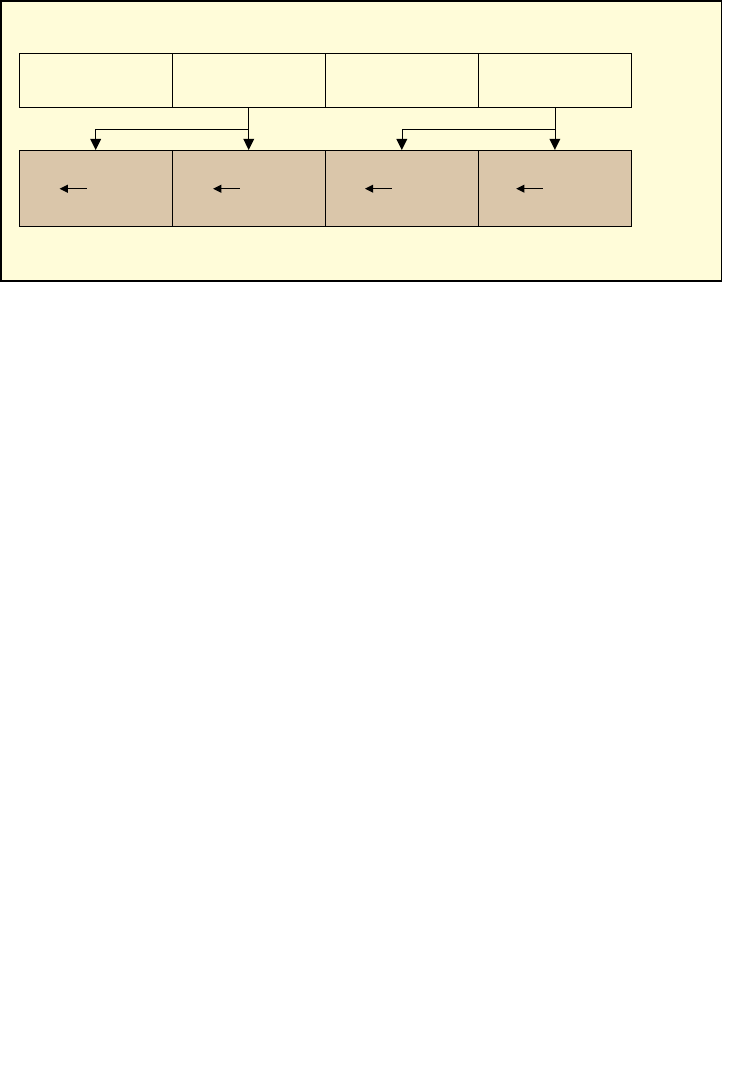
3-740 Vol. 2A MOVSLDUP—Move Packed Single-FP Low and Duplicate
INSTRUCTION SET REFERENCE, A-M
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
128-bit Legacy SSE version: Bits (VLMAX-1:128) of the corresponding YMM destina-
tion register remain unchanged.
VEX.128 encoded version: Bits (VLMAX-1:128) of the destination YMM register are
zeroed.
Note: In VEX-encoded versions, VEX.vvvv is reserved and must be 1111b otherwise
instructions will #UD.
Operation
MOVSLDUP (128-bit Legacy SSE version)
DEST[31:0] SRC[31:0]
DEST[63:32] SRC[31:0]
DEST[95:64] SRC[95:64]
DEST[127:96] SRC[95:64]
DEST[VLMAX-1:128] (Unmodified)
VMOVSLDUP (VEX.128 encoded version)
DEST[31:0] SRC[31:0]
DEST[63:32] SRC[31:0]
DEST[95:64] SRC[95:64]
DEST[127:96] SRC[95:64]
Figure 3-29. MOVSLDUP—Move Packed Single-FP Low and Duplicate
20
0296/'83[PP[PPP
5(68/7
[PP
[PP
P
[PP>@
[PP
P>@
>@
[PP>@
[PP
P>@
>@
[PP>@
[PP
P>@
>@
[PP>@
[PP
P>@
>@
>@ >@ >@ >@

Vol. 2A 3-741
INSTRUCTION SET REFERENCE, A-M
MOVSLDUP—Move Packed Single-FP Low and Duplicate
DEST[VLMAX-1:128] 0
VMOVSLDUP (VEX.256 encoded version)
DEST[31:0] SRC[31:0]
DEST[63:32] SRC[31:0]
DEST[95:64] SRC[95:64]
DEST[127:96] SRC[95:64]
DEST[159:128] SRC[159:128]
DEST[191:160] SRC[159:128]
DEST[223:192] SRC[223:192]
DEST[255:224] SRC[223:192]
Intel C/C++ Compiler Intrinsic Equivalent
(V)MOVSLDUP __m128 _mm_moveldup_ps(__m128 a)
VMOVSLDUP __m256 _mm256_moveldup_ps (__m256 a);
Exceptions
General protection exception if not aligned on 16-byte boundary, regardless of
segment.
Numeric Exceptions
None.
Other Exceptions
See Exceptions Type 4; additionally
#UD If VEX.vvvv != 1111B.
3-742 Vol. 2A MOVSS—Move Scalar Single-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
MOVSS—Move Scalar Single-Precision Floating-Point Values
Instruction Operand Encoding
Description
Moves a scalar single-precision floating-point value from the source operand (second
operand) to the destination operand (first operand). The source and destination
operands can be XMM registers or 32-bit memory locations. This instruction can be
used to move a single-precision floating-point value to and from the low doubleword
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F3 0F 10 /r
MOVSS xmm1, xmm2/m32
AV/V SSE Move scalar single-precision
floating-point value from
xmm2/m32 to xmm1
register.
VEX.NDS.LIG.F3.0F.WIG 10 /r
VMOVSS xmm1, xmm2, xmm3
BV/V AVX Merge scalar single-
precision floating-point
value from xmm2 and
xmm3 to xmm1 register.
VEX.LIG.F3.0F.WIG 10 /r
VMOVSS xmm1, m32
D V/V AVX Load scalar single-precision
floating-point value from
m32 to xmm1 register.
F3 0F 11 /r
MOVSS xmm2/m32, xmm
CV/V SSE Move scalar single-precision
floating-point value from
xmm1 register to
xmm2/m32.
VEX.NDS.LIG.F3.0F.WIG 11 /r
VMOVSS xmm1, xmm2, xmm3
E V/V AVX Move scalar single-precision
floating-point value from
xmm2 and xmm3 to xmm1
register.
VEX.LIG.F3.0F.WIG 11 /r
VMOVSS m32, xmm1
C V/V AVX Move scalar single-precision
floating-point value from
xmm1 register to m32.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA
C ModRM:r/m (w) ModRM:reg (r) NA NA
D ModRM:reg (w) ModRM:r/m (r) NA NA
E ModRM:r/m (w) VEX.vvvv (r) ModRM:reg (r) NA

Vol. 2A 3-743
INSTRUCTION SET REFERENCE, A-M
MOVSS—Move Scalar Single-Precision Floating-Point Values
of an XMM register and a 32-bit memory location, or to move a single-precision
floating-point value between the low doublewords of two XMM registers. The instruc-
tion cannot be used to transfer data between memory locations.
For non-VEX encoded syntax and when the source and destination operands are XMM
registers, the high doublewords of the destination operand remains unchanged.
When the source operand is a memory location and destination operand is an XMM
registers, the high doublewords of the destination operand is cleared to all 0s.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
VEX encoded instruction syntax supports two source operands and a destination
operand if ModR/M.mod field is 11B. VEX.vvvv is used to encode the first source
operand (the second operand). The low 128 bits of the destination operand stores the
result of merging the low dword of the second source operand with three dwords in
bits 127:32 of the first source operand. The upper bits of the destination operand are
cleared.
Note: For the “VMOVSS m32, xmm1” (memory store form) instruction version,
VEX.vvvv is reserved and must be 1111b otherwise instruction will #UD.
Note: For the “VMOVSS xmm1, m32” (memory load form) instruction version,
VEX.vvvv is reserved and must be 1111b otherwise instruction will #UD.
Operation
MOVSS (Legacy SSE version when the source and destination operands are both XMM
registers)
DEST[31:0] SRC[31:0]
DEST[VLMAX-1:32] (Unmodified)
MOVSS/VMOVSS (when the source operand is an XMM register and the destination is
memory)
DEST[31:0] SRC[31:0]
MOVSS (Legacy SSE version when the source operand is memory and the destination is an
XMM register)
DEST[31:0] SRC[31:0]
DEST[127:32] 0
DEST[VLMAX-1:128] (Unmodified)
VMOVSS (VEX.NDS.128.F3.0F 11 /r where the destination is an XMM register)
DEST[31:0] SRC2[31:0]
DEST[127:32] SRC1[127:32]
DEST[VLMAX-1:128] 0
VMOVSS (VEX.NDS.128.F3.0F 10 /r where the source and destination are XMM registers)

3-744 Vol. 2A MOVSS—Move Scalar Single-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
DEST[31:0] SRC2[31:0]
DEST[127:32] SRC1[127:32]
DEST[VLMAX-1:128] 0
VMOVSS (VEX.NDS.128.F3.0F 10 /r when the source operand is memory and the destination
is an XMM register)
DEST[31:0] SRC[31:0]
DEST[VLMAX-1:32] 0
Intel C/C++ Compiler Intrinsic Equivalent
MOVSS __m128 _mm_load_ss(float * p)
MOVSS void _mm_store_ss(float * p, __m128 a)
MOVSS __m128 _mm_move_ss(__m128 a, __m128 b)
SIMD Floating-Point Exceptions
None.
Other Exceptions
See Exceptions Type 5; additionally
#UD If VEX.vvvv != 1111B.

Vol. 2A 3-745
INSTRUCTION SET REFERENCE, A-M
MOVSX/MOVSXD—Move with Sign-Extension
MOVSX/MOVSXD—Move with Sign-Extension
Instruction Operand Encoding
Description
Copies the contents of the source operand (register or memory location) to the desti-
nation operand (register) and sign extends the value to 16 or 32 bits (see Figure 7-6
in the Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 1).
The size of the converted value depends on the operand-size attribute.
In 64-bit mode, the instruction’s default operation size is 32 bits. Use of the REX.R
prefix permits access to additional registers (R8-R15). Use of the REX.W prefix
promotes operation to 64 bits. See the summary chart at the beginning of this
section for encoding data and limits.
Operation
DEST ← SignExtend(SRC);
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F BE /rMOVSX r16, r/m8 A Valid Valid Move byte to word with
sign-extension.
0F BE /rMOVSX r32, r/m8 A Valid Valid Move byte to doubleword
with sign-extension.
REX + 0F BE /rMOVSX r64, r/m8* A Valid N.E. Move byte to quadword
with sign-extension.
0F BF /rMOVSX r32,
r/m16
A Valid Valid Move word to doubleword,
with sign-extension.
REX.W + 0F BF
/r
MOVSX r64,
r/m16
A Valid N.E. Move word to quadword
with sign-extension.
REX.W** + 63 /rMOVSXD r64,
r/m32
A Valid N.E. Move doubleword to
quadword with sign-
extension.
NOTES:
* In 64-bit mode, r/m8 can not be encoded to access the following byte registers if a REX prefix is
used: AH, BH, CH, DH.
** The use of MOVSXD without REX.W in 64-bit mode is discouraged, Regular MOV should be used
instead of using MOVSXD without REX.W.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA

3-746 Vol. 2A MOVSX/MOVSXD—Move with Sign-Extension
INSTRUCTION SET REFERENCE, A-M
Flags Affected
None.
Protected Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.

Vol. 2A 3-747
INSTRUCTION SET REFERENCE, A-M
MOVSX/MOVSXD—Move with Sign-Extension
#UD If the LOCK prefix is used.

3-748 Vol. 2A MOVUPD—Move Unaligned Packed Double-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
MOVUPD—Move Unaligned Packed Double-Precision Floating-Point
Values
Instruction Operand Encoding
Description
128-bit versions:
Moves a double quadword containing two packed double-precision floating-point
values from the source operand (second operand) to the destination operand (first
operand). This instruction can be used to load an XMM register from a 128-bit
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 10 /r
MOVUPD xmm1, xmm2/m128
AV/V SSE2 Move packed double-
precision floating-point
values from xmm2/m128 to
xmm1.
VEX.128.66.0F.WIG 10 /r
VMOVUPD xmm1, xmm2/m128
A V/V AVX Move unaligned packed
double-precision floating-
point from xmm2/mem to
xmm1.
VEX.256.66.0F.WIG 10 /r
VMOVUPD ymm1, ymm2/m256
A V/V AVX Move unaligned packed
double-precision floating-
point from ymm2/mem to
ymm1.
66 0F 11 /r
MOVUPD xmm2/m128, xmm
BV/V SSE2 Move packed double-
precision floating-point
values from xmm1 to
xmm2/m128.
VEX.128.66.0F.WIG 11 /r
VMOVUPD xmm2/m128, xmm1
B V/V AVX Move unaligned packed
double-precision floating-
point from xmm1 to
xmm2/mem.
VEX.256.66.0F.WIG 11 /r
VMOVUPD ymm2/m256, ymm1
B V/V AVX Move unaligned packed
double-precision floating-
point from ymm1 to
ymm2/mem.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA
B ModRM:r/m (w) ModRM:reg (r) NA NA

Vol. 2A 3-749
INSTRUCTION SET REFERENCE, A-M
MOVUPD—Move Unaligned Packed Double-Precision Floating-Point Values
memory location, store the contents of an XMM register into a 128-bit memory loca-
tion, or move data between two XMM registers.
128-bit Legacy SSE version: Bits (VLMAX-1:128) of the corresponding YMM destination
register remain unchanged.
When the source or destination operand is a memory operand, the operand may be
unaligned on a 16-byte boundary without causing a general-protection exception
(#GP) to be generated.1
To move double-precision floating-point values to and from memory locations that
are known to be aligned on 16-byte boundaries, use the MOVAPD instruction.
While executing in 16-bit addressing mode, a linear address for a 128-bit data access
that overlaps the end of a 16-bit segment is not allowed and is defined as reserved
behavior. A specific processor implementation may or may not generate a general-
protection exception (#GP) in this situation, and the address that spans the end of
the segment may or may not wrap around to the beginning of the segment.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
VEX.128 encoded version: Bits (VLMAX-1:128) of the destination YMM register are
zeroed.
VEX.256 encoded version:
Moves 256 bits of packed double-precision floating-point values from the source
operand (second operand) to the destination operand (first operand). This instruction
can be used to load a YMM register from a 256-bit memory location, to store the
contents of a YMM register into a 256-bit memory location, or to move data between
two YMM registers.
Note: In VEX-encoded versions, VEX.vvvv is reserved and must be 1111b otherwise
instructions will #UD.
Operation
MOVUPD (128-bit load and register-copy form Legacy SSE version)
DEST[127:0] SRC[127:0]
DEST[VLMAX-1:128] (Unmodified)
(V)MOVUPD (128-bit store form)
DEST[127:0] SRC[127:0]
1. If alignment checking is enabled (CR0.AM = 1, RFLAGS.AC = 1, and CPL = 3), an alignment-check
exception (#AC) may or may not be generated (depending on processor implementation) when
the operand is not aligned on an 8-byte boundary.

3-750 Vol. 2A MOVUPD—Move Unaligned Packed Double-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
VMOVUPD (VEX.128 encoded version)
DEST[127:0] SRC[127:0]
DEST[VLMAX-1:128] 0
VMOVUPD (VEX.256 encoded version)
DEST[255:0] SRC[255:0]
Intel C/C++ Compiler Intrinsic Equivalent
MOVUPD __m128 _mm_loadu_pd(double * p)
MOVUPD void _mm_storeu_pd(double *p, __m128 a)
VMOVUPD __m256d _mm256_loadu_pd (__m256d * p);
VMOVUPD _mm256_storeu_pd(_m256d *p, __m256d a);
SIMD Floating-Point Exceptions
None.
Other Exceptions
See Exceptions Type 4
Note treatment of #AC varies; additionally
#UD If VEX.vvvv != 1111B.

Vol. 2A 3-751
INSTRUCTION SET REFERENCE, A-M
MOVUPS—Move Unaligned Packed Single-Precision Floating-Point Values
MOVUPS—Move Unaligned Packed Single-Precision Floating-Point
Values
Instruction Operand Encoding
Description
128-bit versions: Moves a double quadword containing four packed single-precision
floating-point values from the source operand (second operand) to the destination
operand (first operand). This instruction can be used to load an XMM register from a
128-bit memory location, store the contents of an XMM register into a 128-bit
memory location, or move data between two XMM registers.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
0F 10 /r
MOVUPS xmm1, xmm2/m128
A V/V SSE Move packed single-
precision floating-point
values from xmm2/m128 to
xmm1.
VEX.128.0F.WIG 10 /r
VMOVUPS xmm1, xmm2/m128
A V/V AVX Move unaligned packed
single-precision floating-
point from xmm2/mem to
xmm1.
VEX.256.0F.WIG 10 /r
VMOVUPS ymm1, ymm2/m256
A V/V AVX Move unaligned packed
single-precision floating-
point from ymm2/mem to
ymm1.
0F 11 /r
MOVUPS xmm2/m128, xmm1
B V/V SSE Move packed single-
precision floating-point
values from xmm1 to
xmm2/m128.
VEX.128.0F.WIG 11 /r
VMOVUPS xmm2/m128, xmm1
B V/V AVX Move unaligned packed
single-precision floating-
point from xmm1 to
xmm2/mem.
VEX.256.0F.WIG 11 /r
VMOVUPS ymm2/m256, ymm1
B V/V AVX Move unaligned packed
single-precision floating-
point from ymm1 to
ymm2/mem.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA
B ModRM:r/m (w) ModRM:reg (r) NA NA

3-752 Vol. 2A MOVUPS—Move Unaligned Packed Single-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
128-bit Legacy SSE version: Bits (VLMAX-1:128) of the corresponding YMM destination
register remain unchanged.
When the source or destination operand is a memory operand, the operand may be
unaligned on a 16-byte boundary without causing a general-protection exception
(#GP) to be generated.1
To move packed single-precision floating-point values to and from memory locations
that are known to be aligned on 16-byte boundaries, use the MOVAPS instruction.
While executing in 16-bit addressing mode, a linear address for a 128-bit data access
that overlaps the end of a 16-bit segment is not allowed and is defined as reserved
behavior. A specific processor implementation may or may not generate a general-
protection exception (#GP) in this situation, and the address that spans the end of
the segment may or may not wrap around to the beginning of the segment.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
VEX.128 encoded version: Bits (VLMAX-1:128) of the destination YMM register are
zeroed.
VEX.256 encoded version: Moves 256 bits of packed single-precision floating-point
values from the source operand (second operand) to the destination operand (first
operand). This instruction can be used to load a YMM register from a 256-bit memory
location, to store the contents of a YMM register into a 256-bit memory location, or
to move data between two YMM registers.
Note: In VEX-encoded versions, VEX.vvvv is reserved and must be 1111b otherwise
instructions will #UD.
Operation
MOVUPS (128-bit load and register-copy form Legacy SSE version)
DEST[127:0] SRC[127:0]
DEST[VLMAX-1:128] (Unmodified)
(V)MOVUPS (128-bit store form)
DEST[127:0] SRC[127:0]
VMOVUPS (VEX.128 encoded load-form)
DEST[127:0] SRC[127:0]
DEST[VLMAX-1:128] 0
VMOVUPS (VEX.256 encoded version)
1. If alignment checking is enabled (CR0.AM = 1, RFLAGS.AC = 1, and CPL = 3), an alignment-check
exception (#AC) may or may not be generated (depending on processor implementation) when
the operand is not aligned on an 8-byte boundary.

Vol. 2A 3-753
INSTRUCTION SET REFERENCE, A-M
MOVUPS—Move Unaligned Packed Single-Precision Floating-Point Values
DEST[255:0] SRC[255:0]
Intel C/C++ Compiler Intrinsic Equivalent
MOVUPS __m128 _mm_loadu_ps(double * p)
MOVUPS void _mm_storeu_ps(double *p, __m128 a)
VMOVUPS __m256 _mm256_loadu_ps (__m256 * p);
VMOVUPS _mm256_storeu_ps(_m256 *p, __m256 a);
SIMD Floating-Point Exceptions
None.
Other Exceptions
See Exceptions Type 4
Note treatment of #AC varies; additionally
#UD If VEX.vvvv != 1111B.
3-754 Vol. 2A MOVZX—Move with Zero-Extend
INSTRUCTION SET REFERENCE, A-M
MOVZX—Move with Zero-Extend
Instruction Operand Encoding
Description
Copies the contents of the source operand (register or memory location) to the desti-
nation operand (register) and zero extends the value. The size of the converted value
depends on the operand-size attribute.
In 64-bit mode, the instruction’s default operation size is 32 bits. Use of the REX.R
prefix permits access to additional registers (R8-R15). Use of the REX.W prefix
promotes operation to 64 bit operands. See the summary chart at the beginning of
this section for encoding data and limits.
Operation
DEST ← ZeroExtend(SRC);
Flags Affected
None.
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F B6 /rMOVZX r16, r/m8 A Valid Valid Move byte to word with
zero-extension.
0F B6 /rMOVZX r32, r/m8 A Valid Valid Move byte to doubleword,
zero-extension.
REX.W + 0F B6
/r
MOVZX r64, r/m8* A Valid N.E. Move byte to quadword,
zero-extension.
0F B7 /rMOVZX r32,
r/m16
AValid Valid Move word to doubleword,
zero-extension.
REX.W + 0F B7
/r
MOVZX r64,
r/m16
A Valid N.E. Move word to quadword,
zero-extension.
NOTES:
* In 64-bit mode, r/m8 can not be encoded to access the following byte registers if the REX prefix
is used: AH, BH, CH, DH.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (w) ModRM:r/m (r) NA NA

Vol. 2A 3-755
INSTRUCTION SET REFERENCE, A-M
MOVZX—Move with Zero-Extend
Protected Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
3-756 Vol. 2A MPSADBW — Compute Multiple Packed Sums of Absolute Difference
INSTRUCTION SET REFERENCE, A-M
MPSADBW — Compute Multiple Packed Sums of Absolute Difference
Instruction Operand Encoding
Description
MPSADBW sums the absolute difference (SAD) of a pair of unsigned bytes for a group
of 4 byte pairs, and produces 8 SAD results (one for each 4 byte-pairs) stored as 8
word integers in the destination operand (first operand). Each 4 byte pairs are
selected from the source operand (first opeand) and the destination according to the
bit fields specified in the immediate byte (third operand).
The immediate byte provides two bit fields:
SRC_OFFSET: the value of Imm8[1:0]*32 specifies the offset of the 4 sequential
source bytes in the source operand.
DEST_OFFSET: the value of Imm8[2]*32 specifies the offset of the first of 8 groups
of 4 sequential destination bytes in the destination operand. The next four destina-
tion bytes starts at DEST_OFFSET + 8, etc.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 3A 42 /r ib
MPSADBW xmm1, xmm2/m128,
imm8
AV/V SSE4_1Sums absolute 8-bit integer
difference of adjacent
groups of 4 byte integers in
xmm1 and xmm2/m128
and writes the results in
xmm1. Starting offsets
within xmm1 and
xmm2/m128 are
determined by imm8.
VEX.NDS.128.66.0F3A.WIG 42 /r ib
VMPSADBW xmm1, xmm2,
xmm3/m128, imm8
B V/V AVX Sums absolute 8-bit integer
difference of adjacent
groups of 4 byte integers in
xmm2 and xmm3/m128 and
writes the results in xmm1.
Starting offsets within
xmm2 and xmm3/m128 are
determined by imm8.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) imm8 NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

Vol. 2A 3-757
INSTRUCTION SET REFERENCE, A-M
MPSADBW — Compute Multiple Packed Sums of Absolute Difference
The SAD operation is repeated 8 times, each time using the same 4 source bytes but
selecting the next group of 4 destination bytes starting at the next higher byte in the
destination. Each 16-bit sum is written to destination.
128-bit Legacy SSE version: The first source and destination are the same. Bits
(VLMAX-1:128) of the corresponding YMM destination register remain unchanged.
VEX.128 encoded version: Bits (VLMAX-1:128) of the destination YMM register are
zeroed.
If VMPSADBW is encoded with VEX.L= 1, an attempt to execute the instruction
encoded with VEX.L= 1 will cause an #UD exception.
Operation
MPSADBW (128-bit Legacy SSE version)
SRC_OFFSET imm8[1:0]*32
DEST_OFFSET imm8[2]*32
DEST_BYTE0 DEST[DEST_OFFSET+7:DEST_OFFSET]
DEST_BYTE1 DEST[DEST_OFFSET+15:DEST_OFFSET+8]
DEST_BYTE2 DEST[DEST_OFFSET+23:DEST_OFFSET+16]
DEST_BYTE3 DEST[DEST_OFFSET+31:DEST_OFFSET+24]
DEST_BYTE4 DEST[DEST_OFFSET+39:DEST_OFFSET+32]
DEST_BYTE5 DEST[DEST_OFFSET+47:DEST_OFFSET+40]
DEST_BYTE6 DEST[DEST_OFFSET+55:DEST_OFFSET+48]
DEST_BYTE7 DEST[DEST_OFFSET+63:DEST_OFFSET+56]
DEST_BYTE8 DEST[DEST_OFFSET+71:DEST_OFFSET+64]
DEST_BYTE9 DEST[DEST_OFFSET+79:DEST_OFFSET+72]
DEST_BYTE10 DEST[DEST_OFFSET+87:DEST_OFFSET+80]
SRC_BYTE0 SRC[SRC_OFFSET+7:SRC_OFFSET]
SRC_BYTE1 SRC[SRC_OFFSET+15:SRC_OFFSET+8]
SRC_BYTE2 SRC[SRC_OFFSET+23:SRC_OFFSET+16]
SRC_BYTE3 SRC[SRC_OFFSET+31:SRC_OFFSET+24]
TEMP0 ABS( DEST_BYTE0 - SRC_BYTE0)
TEMP1 ABS( DEST_BYTE1 - SRC_BYTE1)
TEMP2 ABS( DEST_BYTE2 - SRC_BYTE2)
TEMP3 ABS( DEST_BYTE3 - SRC_BYTE3)
DEST[15:0] TEMP0 + TEMP1 + TEMP2 + TEMP3
TEMP0 ABS( DEST_BYTE1 - SRC_BYTE0)
TEMP1 ABS( DEST_BYTE2 - SRC_BYTE1)
TEMP2 ABS( DEST_BYTE3 - SRC_BYTE2)
TEMP3 ABS( DEST_BYTE4 - SRC_BYTE3)
DEST[31:16] TEMP0 + TEMP1 + TEMP2 + TEMP3

3-758 Vol. 2A MPSADBW — Compute Multiple Packed Sums of Absolute Difference
INSTRUCTION SET REFERENCE, A-M
TEMP0 ABS( DEST_BYTE2 - SRC_BYTE0)
TEMP1 ABS( DEST_BYTE3 - SRC_BYTE1)
TEMP2 ABS( DEST_BYTE4 - SRC_BYTE2)
TEMP3 ABS( DEST_BYTE5 - SRC_BYTE3)
DEST[47:32] TEMP0 + TEMP1 + TEMP2 + TEMP3
TEMP0 ABS( DEST_BYTE3 - SRC_BYTE0)
TEMP1 ABS( DEST_BYTE4 - SRC_BYTE1)
TEMP2 ABS( DEST_BYTE5 - SRC_BYTE2)
TEMP3 ABS( DEST_BYTE6 - SRC_BYTE3)
DEST[63:48] TEMP0 + TEMP1 + TEMP2 + TEMP3
TEMP0 ABS( DEST_BYTE4 - SRC_BYTE0)
TEMP1 ABS( DEST_BYTE5 - SRC_BYTE1)
TEMP2 ABS( DEST_BYTE6 - SRC_BYTE2)
TEMP3 ABS( DEST_BYTE7 - SRC_BYTE3)
DEST[79:64] TEMP0 + TEMP1 + TEMP2 + TEMP3
TEMP0 ABS( DEST_BYTE5 - SRC_BYTE0)
TEMP1 ABS( DEST_BYTE6 - SRC_BYTE1)
TEMP2 ABS( DEST_BYTE7 - SRC_BYTE2)
TEMP3 ABS( DEST_BYTE8 - SRC_BYTE3)
DEST[95:80] TEMP0 + TEMP1 + TEMP2 + TEMP3
TEMP0 ABS( DEST_BYTE6 - SRC_BYTE0)
TEMP1 ABS( DEST_BYTE7 - SRC_BYTE1)
TEMP2 ABS( DEST_BYTE8 - SRC_BYTE2)
TEMP3 ABS( DEST_BYTE9 - SRC_BYTE3)
DEST[111:96] TEMP0 + TEMP1 + TEMP2 + TEMP3
TEMP0 ABS( DEST_BYTE7 - SRC_BYTE0)
TEMP1 ABS( DEST_BYTE8 - SRC_BYTE1)
TEMP2 ABS( DEST_BYTE9 - SRC_BYTE2)
TEMP3 ABS( DEST_BYTE10 - SRC_BYTE3)
DEST[127:112] TEMP0 + TEMP1 + TEMP2 + TEMP3
DEST[VLMAX-1:128] (Unmodified)
VMPSADBW (VEX.128 encoded version)
SRC2_OFFSET imm8[1:0]*32
SRC1_OFFSET imm8[2]*32
SRC1_BYTE0 SRC1[SRC1_OFFSET+7:SRC1_OFFSET]
SRC1_BYTE1 SRC1[SRC1_OFFSET+15:SRC1_OFFSET+8]

Vol. 2A 3-759
INSTRUCTION SET REFERENCE, A-M
MPSADBW — Compute Multiple Packed Sums of Absolute Difference
SRC1_BYTE2 SRC1[SRC1_OFFSET+23:SRC1_OFFSET+16]
SRC1_BYTE3 SRC1[SRC1_OFFSET+31:SRC1_OFFSET+24]
SRC1_BYTE4 SRC1[SRC1_OFFSET+39:SRC1_OFFSET+32]
SRC1_BYTE5 SRC1[SRC1_OFFSET+47:SRC1_OFFSET+40]
SRC1_BYTE6 SRC1[SRC1_OFFSET+55:SRC1_OFFSET+48]
SRC1_BYTE7 SRC1[SRC1_OFFSET+63:SRC1_OFFSET+56]
SRC1_BYTE8 SRC1[SRC1_OFFSET+71:SRC1_OFFSET+64]
SRC1_BYTE9 SRC1[SRC1_OFFSET+79:SRC1_OFFSET+72]
SRC1_BYTE10 SRC1[SRC1_OFFSET+87:SRC1_OFFSET+80]
SRC2_BYTE0 SRC2[SRC2_OFFSET+7:SRC2_OFFSET]
SRC2_BYTE1 SRC2[SRC2_OFFSET+15:SRC2_OFFSET+8]
SRC2_BYTE2 SRC2[SRC2_OFFSET+23:SRC2_OFFSET+16]
SRC2_BYTE3 SRC2[SRC2_OFFSET+31:SRC2_OFFSET+24]
TEMP0 ABS(SRC1_BYTE0 - SRC2_BYTE0)
TEMP1 ABS(SRC1_BYTE1 - SRC2_BYTE1)
TEMP2 ABS(SRC1_BYTE2 - SRC2_BYTE2)
TEMP3 ABS(SRC1_BYTE3 - SRC2_BYTE3)
DEST[15:0] TEMP0 + TEMP1 + TEMP2 + TEMP3
TEMP0 ABS(SRC1_BYTE1 - SRC2_BYTE0)
TEMP1 ABS(SRC1_BYTE2 - SRC2_BYTE1)
TEMP2 ABS(SRC1_BYTE3 - SRC2_BYTE2)
TEMP3 ABS(SRC1_BYTE4 - SRC2_BYTE3)
DEST[31:16] TEMP0 + TEMP1 + TEMP2 + TEMP3
TEMP0 ABS(SRC1_BYTE2 - SRC2_BYTE0)
TEMP1 ABS(SRC1_BYTE3 - SRC2_BYTE1)
TEMP2 ABS(SRC1_BYTE4 - SRC2_BYTE2)
TEMP3 ABS(SRC1_BYTE5 - SRC2_BYTE3)
DEST[47:32] TEMP0 + TEMP1 + TEMP2 + TEMP3
TEMP0 ABS(SRC1_BYTE3 - SRC2_BYTE0)
TEMP1 ABS(SRC1_BYTE4 - SRC2_BYTE1)
TEMP2 ABS(SRC1_BYTE5 - SRC2_BYTE2)
TEMP3 ABS(SRC1_BYTE6 - SRC2_BYTE3)
DEST[63:48] TEMP0 + TEMP1 + TEMP2 + TEMP3
TEMP0 ABS(SRC1_BYTE4 - SRC2_BYTE0)
TEMP1 ABS(SRC1_BYTE5 - SRC2_BYTE1)
TEMP2 ABS(SRC1_BYTE6 - SRC2_BYTE2)
TEMP3 ABS(SRC1_BYTE7 - SRC2_BYTE3)
DEST[79:64] TEMP0 + TEMP1 + TEMP2 + TEMP3
TEMP0 ABS(SRC1_BYTE5 - SRC2_BYTE0)
TEMP1 ABS(SRC1_BYTE6 - SRC2_BYTE1)
TEMP2 ABS(SRC1_BYTE7 - SRC2_BYTE2)

3-760 Vol. 2A MPSADBW — Compute Multiple Packed Sums of Absolute Difference
INSTRUCTION SET REFERENCE, A-M
TEMP3 ABS(SRC1_BYTE8 - SRC2_BYTE3)
DEST[95:80] TEMP0 + TEMP1 + TEMP2 + TEMP3
TEMP0 ABS(SRC1_BYTE6 - SRC2_BYTE0)
TEMP1 ABS(SRC1_BYTE7 - SRC2_BYTE1)
TEMP2 ABS(SRC1_BYTE8 - SRC2_BYTE2)
TEMP3 ABS(SRC1_BYTE9 - SRC2_BYTE3)
DEST[111:96] TEMP0 + TEMP1 + TEMP2 + TEMP3
TEMP0 ABS(SRC1_BYTE7 - SRC2_BYTE0)
TEMP1 ABS(SRC1_BYTE8 - SRC2_BYTE1)
TEMP2 ABS(SRC1_BYTE9 - SRC2_BYTE2)
TEMP3 ABS(SRC1_BYTE10 - SRC2_BYTE3)
DEST[127:112] TEMP0 + TEMP1 + TEMP2 + TEMP3
DEST[VLMAX-1:128] 0
Intel C/C++ Compiler Intrinsic Equivalent
MPSADBW __m128i _mm_mpsadbw_epu8 (__m128i s1, __m128i s2, const int mask);
Flags Affected
None
Other Exceptions
See Exceptions Type 4; additionally
#UD If VEX.L = 1.
Vol. 2A 3-761
INSTRUCTION SET REFERENCE, A-M
MUL—Unsigned Multiply
MUL—Unsigned Multiply
Instruction Operand Encoding
Description
Performs an unsigned multiplication of the first operand (destination operand) and
the second operand (source operand) and stores the result in the destination
operand. The destination operand is an implied operand located in register AL, AX or
EAX (depending on the size of the operand); the source operand is located in a
general-purpose register or a memory location. The action of this instruction and the
location of the result depends on the opcode and the operand size as shown in Table
3-66.
The result is stored in register AX, register pair DX:AX, or register pair EDX:EAX
(depending on the operand size), with the high-order bits of the product contained in
register AH, DX, or EDX, respectively. If the high-order bits of the product are 0, the
CF and OF flags are cleared; otherwise, the flags are set.
In 64-bit mode, the instruction’s default operation size is 32 bits. Use of the REX.R
prefix permits access to additional registers (R8-R15). Use of the REX.W prefix
promotes operation to 64 bits.
See the summary chart at the beginning of this section for encoding data and limits.
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
F6 /4 MUL r/m8 A Valid Valid Unsigned multiply (AX ← AL
∗ r/m8).
REX + F6 /4 MUL r/m8*A Valid N.E. Unsigned multiply (AX ← AL
∗ r/m8).
F7 /4 MUL r/m16 A Valid Valid Unsigned multiply (DX:AX ←
AX ∗ r/m16).
F7 /4 MUL r/m32 A Valid Valid Unsigned multiply (EDX:EAX
← EAX ∗ r/m32).
REX.W + F7 /4 MUL r/m64 A Valid N.E. Unsigned multiply (RDX:RAX
← RAX ∗ r/m64.
NOTES:
* In 64-bit mode, r/m8 can not be encoded to access the following byte registers if a REX prefix is
used: AH, BH, CH, DH.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:r/m (r) NA NA NA

3-762 Vol. 2A MUL—Unsigned Multiply
INSTRUCTION SET REFERENCE, A-M
Operation
IF (Byte operation)
THEN
AX ← AL ∗ SRC;
ELSE (* Word or doubleword operation *)
IF OperandSize = 16
THEN
DX:AX ← AX ∗ SRC;
ELSE IF OperandSize = 32
THEN EDX:EAX ← EAX ∗ SRC; FI;
ELSE (* OperandSize = 64 *)
RDX:RAX ← RAX ∗ SRC;
FI;
FI;
Flags Affected
The OF and CF flags are set to 0 if the upper half of the result is 0; otherwise, they
are set to 1. The SF, ZF, AF, and PF flags are undefined.
Protected Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
If the DS, ES, FS, or GS register contains a NULL segment
selector.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
#UD If the LOCK prefix is used.
Table 3-66. MUL Results
Operand Size Source 1 Source 2 Destination
Byte AL r/m8 AX
Word AX r/m16 DX:AX
Doubleword EAX r/m32 EDX:EAX
Quadword RAX r/m64 RDX:RAX

Vol. 2A 3-763
INSTRUCTION SET REFERENCE, A-M
MUL—Unsigned Multiply
Real-Address Mode Exceptions
#GP If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS If a memory operand effective address is outside the SS
segment limit.
#UD If the LOCK prefix is used.
Virtual-8086 Mode Exceptions
#GP(0) If a memory operand effective address is outside the CS, DS,
ES, FS, or GS segment limit.
#SS(0) If a memory operand effective address is outside the SS
segment limit.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made.
#UD If the LOCK prefix is used.
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#SS(0) If a memory address referencing the SS segment is in a non-
canonical form.
#GP(0) If the memory address is in a non-canonical form.
#PF(fault-code) If a page fault occurs.
#AC(0) If alignment checking is enabled and an unaligned memory
reference is made while the current privilege level is 3.
3-764 Vol. 2A MULPD—Multiply Packed Double-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
MULPD—Multiply Packed Double-Precision Floating-Point Values
Instruction Operand Encoding
Description
Performs a SIMD multiply of the two or four packed double-precision floating-point
values from the source operand (second operand) and the destination operand (first
operand), and stores the packed double-precision floating-point results in the desti-
nation operand. The source operand can be an XMM register or a 128-bit memory
location. The destination operand is an XMM register. See Figure 11-3 in the Intel®
64 and IA-32 Architectures Software Developer’s Manual, Volume 1, for an illustra-
tion of a SIMD double-precision floating-point operation.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
128-bit Legacy SSE version: The second source can be an XMM register or an 128-bit
memory location. The destination is not distinct from the first source XMM register
and the upper bits (VLMAX-1:128) of the corresponding YMM register destination are
unmodified.
VEX.128 encoded version: the first source operand is an XMM register or 128-bit
memory location. The destination operand is an XMM register. The upper bits
(VLMAX-1:128) of the destination YMM register destination are zeroed.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
66 0F 59 /r
MULPD xmm1, xmm2/m128
A V/V SSE2 Multiply packed double-
precision floating-point
values in xmm2/m128 by
xmm1.
VEX.NDS.128.66.0F.WIG 59 /r
VMULPD xmm1,xmm2, xmm3/m128
B V/V AVX Multiply packed double-
precision floating-point
values from xmm3/mem to
xmm2 and stores result in
xmm1.
VEX.NDS.256.66.0F.WIG 59 /r
VMULPD ymm1, ymm2,
ymm3/m256
B V/V AVX Multiply packed double-
precision floating-point
values from ymm3/mem to
ymm2 and stores result in
ymm1.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

Vol. 2A 3-765
INSTRUCTION SET REFERENCE, A-M
MULPD—Multiply Packed Double-Precision Floating-Point Values
VEX.256 encoded version: The first source operand is a YMM register. The second
source operand can be a YMM register or a 256-bit memory location. The destination
operand is a YMM register.
Operation
MULPD (128-bit Legacy SSE version)
DEST[63:0] DEST[63:0] * SRC[63:0]
DEST[127:64] DEST[127:64] * SRC[127:64]
DEST[VLMAX-1:128] (Unmodified)
VMULPD (VEX.128 encoded version)
DEST[63:0] SRC1[63:0] * SRC2[63:0]
DEST[127:64] SRC1[127:64] * SRC2[127:64]
DEST[VLMAX-1:128] 0
VMULPD (VEX.256 encoded version)
DEST[63:0] SRC1[63:0] * SRC2[63:0]
DEST[127:64] SRC1[127:64] * SRC2[127:64]
DEST[191:128] SRC1[191:128] * SRC2[191:128]
DEST[255:192] SRC1[255:192] * SRC2[255:192]
Intel C/C++ Compiler Intrinsic Equivalent
MULPD __m128d _mm_mul_pd (m128d a, m128d b)
VMULPD __m256d _mm256_mul_pd (__m256d a, __m256d b);
SIMD Floating-Point Exceptions
Overflow, Underflow, Invalid, Precision, Denormal.
Other Exceptions
See Exceptions Type 2
3-766 Vol. 2A MULPS—Multiply Packed Single-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
MULPS—Multiply Packed Single-Precision Floating-Point Values
Instruction Operand Encoding
Description
Performs a SIMD multiply of the four packed single-precision floating-point values
from the source operand (second operand) and the destination operand (first
operand), and stores the packed single-precision floating-point results in the desti-
nation operand. See Figure 10-5 in the Intel® 64 and IA-32 Architectures Software
Developer’s Manual, Volume 1, for an illustration of a SIMD single-precision floating-
point operation.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
128-bit Legacy SSE version: The second source can be an XMM register or an 128-bit
memory location. The destination is not distinct from the first source XMM register
and the upper bits (VLMAX-1:128) of the corresponding YMM register destination are
unmodified.
VEX.128 encoded version: the first source operand is an XMM register or 128-bit
memory location. The destination operand is an XMM register. The upper bits
(VLMAX-1:128) of the destination YMM register destination are zeroed.
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
0F 59 /r
MULPS xmm1, xmm2/m128
A V/V SSE Multiply packed single-
precision floating-point
values in xmm2/mem by
xmm1.
VEX.NDS.128.0F.WIG 59 /r
VMULPS xmm1,xmm2, xmm3/m128
B V/V AVX Multiply packed single-
precision floating-point
values from xmm3/mem to
xmm2 and stores result in
xmm1.
VEX.NDS.256.0F.WIG 59 /r
VMULPS ymm1, ymm2, ymm3/m256
B V/V AVX Multiply packed single-
precision floating-point
values from ymm3/mem to
ymm2 and stores result in
ymm1.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

Vol. 2A 3-767
INSTRUCTION SET REFERENCE, A-M
MULPS—Multiply Packed Single-Precision Floating-Point Values
VEX.256 encoded version: The first source operand is a YMM register. The second
source operand can be a YMM register or a 256-bit memory location. The destination
operand is a YMM register.
Operation
MULPS (128-bit Legacy SSE version)
DEST[31:0] SRC1[31:0] * SRC2[31:0]
DEST[63:32] SRC1[63:32] * SRC2[63:32]
DEST[95:64] SRC1[95:64] * SRC2[95:64]
DEST[127:96] SRC1[127:96] * SRC2[127:96]
DEST[VLMAX-1:128] (Unmodified)
VMULPS (VEX.128 encoded version)
DEST[31:0] SRC1[31:0] * SRC2[31:0]
DEST[63:32] SRC1[63:32] * SRC2[63:32]
DEST[95:64] SRC1[95:64] * SRC2[95:64]
DEST[127:96] SRC1[127:96] * SRC2[127:96]
DEST[VLMAX-1:128] 0
VMULPS (VEX.256 encoded version)
DEST[31:0] SRC1[31:0] * SRC2[31:0]
DEST[63:32] SRC1[63:32] * SRC2[63:32]
DEST[95:64] SRC1[95:64] * SRC2[95:64]
DEST[127:96] SRC1[127:96] * SRC2[127:96]
DEST[159:128] SRC1[159:128] * SRC2[159:128]
DEST[191:160] SRC1[191:160] * SRC2[191:160]
DEST[223:192] SRC1[223:192] * SRC2[223:192]
DEST[255:224] SRC1[255:224] * SRC2[255:224].
Intel C/C++ Compiler Intrinsic Equivalent
MULPS __m128 _mm_mul_ps(__m128 a, __m128 b)
VMULPS __m256 _mm256_mul_ps (__m256 a, __m256 b);
SIMD Floating-Point Exceptions
Overflow, Underflow, Invalid, Precision, Denormal.
Other Exceptions
See Exceptions Type 2
3-768 Vol. 2A MULSD—Multiply Scalar Double-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
MULSD—Multiply Scalar Double-Precision Floating-Point Values
Instruction Operand Encoding
Description
Multiplies the low double-precision floating-point value in the source operand
(second operand) by the low double-precision floating-point value in the destination
operand (first operand), and stores the double-precision floating-point result in the
destination operand. The source operand can be an XMM register or a 64-bit memory
location. The destination operand is an XMM register. The high quadword of the desti-
nation operand remains unchanged. See Figure 11-4 in the Intel® 64 and IA-32
Architectures Software Developer’s Manual, Volume 1, for an illustration of a scalar
double-precision floating-point operation.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
128-bit Legacy SSE version: The first source operand and the destination operand
are the same. Bits (VLMAX-1:64) of the corresponding YMM destination register
remain unchanged.
VEX.128 encoded version: Bits (VLMAX-1:128) of the destination YMM register are
zeroed.
Operation
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F2 0F 59 /r
MULSD xmm1, xmm2/m64
A V/V SSE2 Multiply the low double-
precision floating-point
value in xmm2/mem64 by
low double-precision
floating-point value in
xmm1.
VEX.NDS.LIG.F2.0F.WIG 59/r
VMULSD xmm1,xmm2, xmm3/m64
B V/V AVX Multiply the low double-
precision floating-point
value in xmm3/mem64 by
low double precision
floating-point value in
xmm2.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

Vol. 2A 3-769
INSTRUCTION SET REFERENCE, A-M
MULSD—Multiply Scalar Double-Precision Floating-Point Values
MULSD (128-bit Legacy SSE version)
DEST[63:0] DEST[63:0] * SRC[63:0]
DEST[VLMAX-1:64] (Unmodified)
VMULSD (VEX.128 encoded version)
DEST[63:0] SRC1[63:0] * SRC2[63:0]
DEST[127:64] SRC1[127:64]
DEST[VLMAX-1:128] 0
Intel C/C++ Compiler Intrinsic Equivalent
MULSD __m128d _mm_mul_sd (m128d a, m128d b)
SIMD Floating-Point Exceptions
Overflow, Underflow, Invalid, Precision, Denormal.
Other Exceptions
See Exceptions Type 3

3-770 Vol. 2A MULSS—Multiply Scalar Single-Precision Floating-Point Values
INSTRUCTION SET REFERENCE, A-M
MULSS—Multiply Scalar Single-Precision Floating-Point Values
Instruction Operand Encoding
Description
Multiplies the low single-precision floating-point value from the source operand
(second operand) by the low single-precision floating-point value in the destination
operand (first operand), and stores the single-precision floating-point result in the
destination operand. The source operand can be an XMM register or a 32-bit memory
location. The destination operand is an XMM register. The three high-order double-
words of the destination operand remain unchanged. See Figure 10-6 in the Intel®
64 and IA-32 Architectures Software Developer’s Manual, Volume 1, for an illustra-
tion of a scalar single-precision floating-point operation.
In 64-bit mode, use of the REX.R prefix permits this instruction to access additional
registers (XMM8-XMM15).
128-bit Legacy SSE version: The first source operand and the destination operand
are the same. Bits (VLMAX-1:32) of the corresponding YMM destination register
remain unchanged.
VEX.128 encoded version: Bits (VLMAX-1:128) of the destination YMM register are
zeroed.
Operation
MULSS (128-bit Legacy SSE version)
Opcode/
Instruction
Op/
En
64/32-bit
Mode
CPUID
Feature
Flag
Description
F3 0F 59 /r
MULSS xmm1, xmm2/m32
A V/V SSE Multiply the low single-
precision floating-point
value in xmm2/mem by the
low single-precision
floating-point value in
xmm1.
VEX.NDS.LIG.F3.0F.WIG 59 /r
VMULSS xmm1,xmm2, xmm3/m32
B V/V AVX Multiply the low single-
precision floating-point
value in xmm3/mem by the
low single-precision floating-
point value in xmm2.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
A ModRM:reg (r, w) ModRM:r/m (r) NA NA
B ModRM:reg (w) VEX.vvvv (r) ModRM:r/m (r) NA

Vol. 2A 3-771
INSTRUCTION SET REFERENCE, A-M
MULSS—Multiply Scalar Single-Precision Floating-Point Values
DEST[31:0] DEST[31:0] * SRC[31:0]
DEST[VLMAX-1:32] (Unmodified)
VMULSS (VEX.128 encoded version)
DEST[31:0] SRC1[31:0] * SRC2[31:0]
DEST[127:32] SRC1[127:32]
DEST[VLMAX-1:128] 0
Intel C/C++ Compiler Intrinsic Equivalent
MULSS __m128 _mm_mul_ss(__m128 a, __m128 b)
SIMD Floating-Point Exceptions
Overflow, Underflow, Invalid, Precision, Denormal.
Other Exceptions
See Exceptions Type 3

3-772 Vol. 2A MWAIT—Monitor Wait
INSTRUCTION SET REFERENCE, A-M
MWAIT—Monitor Wait
Instruction Operand Encoding
Description
MWAIT instruction provides hints to allow the processor to enter an implementation-
dependent optimized state. There are two principal targeted usages: address-range
monitor and advanced power management. Both usages of MWAIT require the use of
the MONITOR instruction.
A CPUID feature flag (ECX bit 3; CPUID executed EAX = 1) indicates the availability
of MONITOR and MWAIT in the processor. When set, MWAIT may be executed only at
privilege level 0 (use at any other privilege level results in an invalid-opcode excep-
tion). The operating system or system BIOS may disable this instruction by using the
IA32_MISC_ENABLE MSR; disabling MWAIT clears the CPUID feature flag and causes
execution to generate an illegal opcode exception.
This instruction’s operation is the same in non-64-bit modes and 64-bit mode.
MWAIT for Address Range Monitoring
For address-range monitoring, the MWAIT instruction operates with the MONITOR
instruction. The two instructions allow the definition of an address at which to wait
(MONITOR) and a implementation-dependent-optimized operation to commence at
the wait address (MWAIT). The execution of MWAIT is a hint to the processor that it
can enter an implementation-dependent-optimized state while waiting for an event
or a store operation to the address range armed by MONITOR.
ECX specifies optional extensions for the MWAIT instruction. EAX may contain hints
such as the preferred optimized state the processor should enter.
For Pentium 4 processors (CPUID signature family 15 and model 3), non-zero values
for EAX and ECX are reserved. Later processors defined ECX=1 as a valid extension
(see below).
Opcode Instruction Op/
En
64-Bit
Mode
Compat/
Leg Mode
Description
0F 01 C9 MWAIT A Valid Valid A hint that allow the
processor to stop
instruction execution and
enter an implementation-
dependent optimized state
until occurrence of a class of
events.
Op/En Operand 1 Operand 2 Operand 3 Operand 4
ANA NA NA NA

Vol. 2A 3-773
INSTRUCTION SET REFERENCE, A-M
MWAIT—Monitor Wait
The following cause the processor to exit the implementation-dependent-optimized
state: a store to the address range armed by the MONITOR instruction, an NMI or
SMI, a debug exception, a machine check exception, the BINIT# signal, the INIT#
signal, and the RESET# signal. Other implementation-dependent events may also
cause the processor to exit the implementation-dependent-optimized state.
In addition, an external interrupt causes the processor to exit the implementation-
dependent-optimized state if either (1) the interrupt would be delivered to software
(e.g., if HLT had been executed instead of MWAIT); or (2) ECX[0] = 1. Implementa-
tion-specific conditions may result in an interrupt causing the processor to exit the
implementation-dependent-optimized state even if interrupts are masked and
ECX[0] = 0.
Following exit from the implementation-dependent-optimized state, control passes
to the instruction following the MWAIT instruction. A pending interrupt that is not
masked (including an NMI or an SMI) may be delivered before execution of that
instruction. Unlike the HLT instruction, the MWAIT instruction does not support a
restart at the MWAIT instruction following the handling of an SMI.
If the preceding MONITOR instruction did not successfully arm an address range or if
the MONITOR instruction has not been executed prior to executing MWAIT, then the
processor will not enter the implementation-dependent-optimized state. Execution
will resume at the instruction following the MWAIT.
MWAIT for Power Management
MWAIT accepts a hint and optional extension to the processor that it can enter a
specified target C state while waiting for an event or a store operation to the address
range armed by MONITOR. Support for MWAIT extensions for power management is
indicated by CPUID.05H.ECX[0] reporting 1.
EAX and ECX will be used to communicate the additional information to the MWAIT
instruction, such as the kind of optimized state the processor should enter. ECX spec-
ifies optional extensions for the MWAIT instruction. EAX may contain hints such as
the preferred optimized state the processor should enter. Implementation-specific
conditions may cause a processor to ignore the hint and enter a different optimized
state. Future processor implementations may implement several optimized “waiting”
states and will select among those states based on the hint argument.
Table 3-67 describes the meaning of ECX and EAX registers for MWAIT extensions.
Table 3-67. MWAIT Extension Register (ECX)
Bits Description
0Treat masked interrupts as break events (e.g., if EFLAGS.IF=0). May be set
only if CPUID.01H:ECX.MONITOR[bit 3] = 1.
31: 1 Reserved

3-774 Vol. 2A MWAIT—Monitor Wait
INSTRUCTION SET REFERENCE, A-M
Note that if MWAIT is used to enter any of the C-states that are numerically higher
than C1, a store to the address range armed by the MONITOR instruction will cause
the processor to exit MWAIT only if the store was originated by other processor
agents. A store from non-processor agent might not cause the processor to exit
MWAIT in such cases.
For additional details of MWAIT extensions, see Chapter 14, “Power and Thermal
Management,” of Intel® 64 and IA-32 Architectures Software Developer’s Manual,
Volume 3A.
Operation
(* MWAIT takes the argument in EAX as a hint extension and is architected to take the argument in
ECX as an instruction extension MWAIT EAX, ECX *)
{
WHILE ( ("Monitor Hardware is in armed state")) {
implementation_dependent_optimized_state(EAX, ECX); }
Set the state of Monitor Hardware as triggered;
}
Intel C/C++ Compiler Intrinsic Equivalent
MWAIT void _mm_mwait(unsigned extensions, unsigned hints)
Example
MONITOR/MWAIT instruction pair must be coded in the same loop because execution
of the MWAIT instruction will trigger the monitor hardware. It is not a proper usage
to execute MONITOR once and then execute MWAIT in a loop. Setting up MONITOR
without executing MWAIT has no adverse effects.
Typically the MONITOR/MWAIT pair is used in a sequence, such as:
EAX = Logical Address(Trigger)
ECX = 0 (*Hints *)
Table 3-68. MWAIT Hints Register (EAX)
Bits Description
3 : 0 Sub C-state within a C-state, indicated by bits [7:4]
7 : 4 Target C-state*
Value of 0 means C1; 1 means C2 and so on
Value of 01111B means C0
Note: Target C states for MWAIT extensions are processor-specific C-
states, not ACPI C-states
31: 8 Reserved

Vol. 2A 3-775
INSTRUCTION SET REFERENCE, A-M
MWAIT—Monitor Wait
EDX = 0 (* Hints *)
IF ( !trigger_store_happened) {
MONITOR EAX, ECX, EDX
IF ( !trigger_store_happened ) {
MWAIT EAX, ECX
}
}
The above code sequence makes sure that a triggering store does not happen
between the first check of the trigger and the execution of the monitor instruction.
Without the second check that triggering store would go un-noticed. Typical usage of
MONITOR and MWAIT would have the above code sequence within a loop.
Numeric Exceptions
None
Protected Mode Exceptions
#GP(0) If ECX[31:1] ≠ 0.
If ECX[0] = 1 and CPUID.05H:ECX[bit 3] = 0.
#UD If CPUID.01H:ECX.MONITOR[bit 3] = 0.
If current privilege level is not 0.
Real Address Mode Exceptions
#GP If ECX[31:1] ≠ 0.
If ECX[0] = 1 and CPUID.05H:ECX[bit 3] = 0.
#UD If CPUID.01H:ECX.MONITOR[bit 3] = 0.
Virtual 8086 Mode Exceptions
#UD The MWAIT instruction is not recognized in virtual-8086 mode
(even if CPUID.01H:ECX.MONITOR[bit 3] = 1).
Compatibility Mode Exceptions
Same exceptions as in protected mode.
64-Bit Mode Exceptions
#GP(0) If RCX[63:1] ≠ 0.
If RCX[0] = 1 and CPUID.05H:ECX[bit 3] = 0.
#UD If the current privilege level is not 0.
If CPUID.01H:ECX.MONITOR[bit 3] = 0.

3-776 Vol. 2A MWAIT—Monitor Wait
INSTRUCTION SET REFERENCE, A-M
